
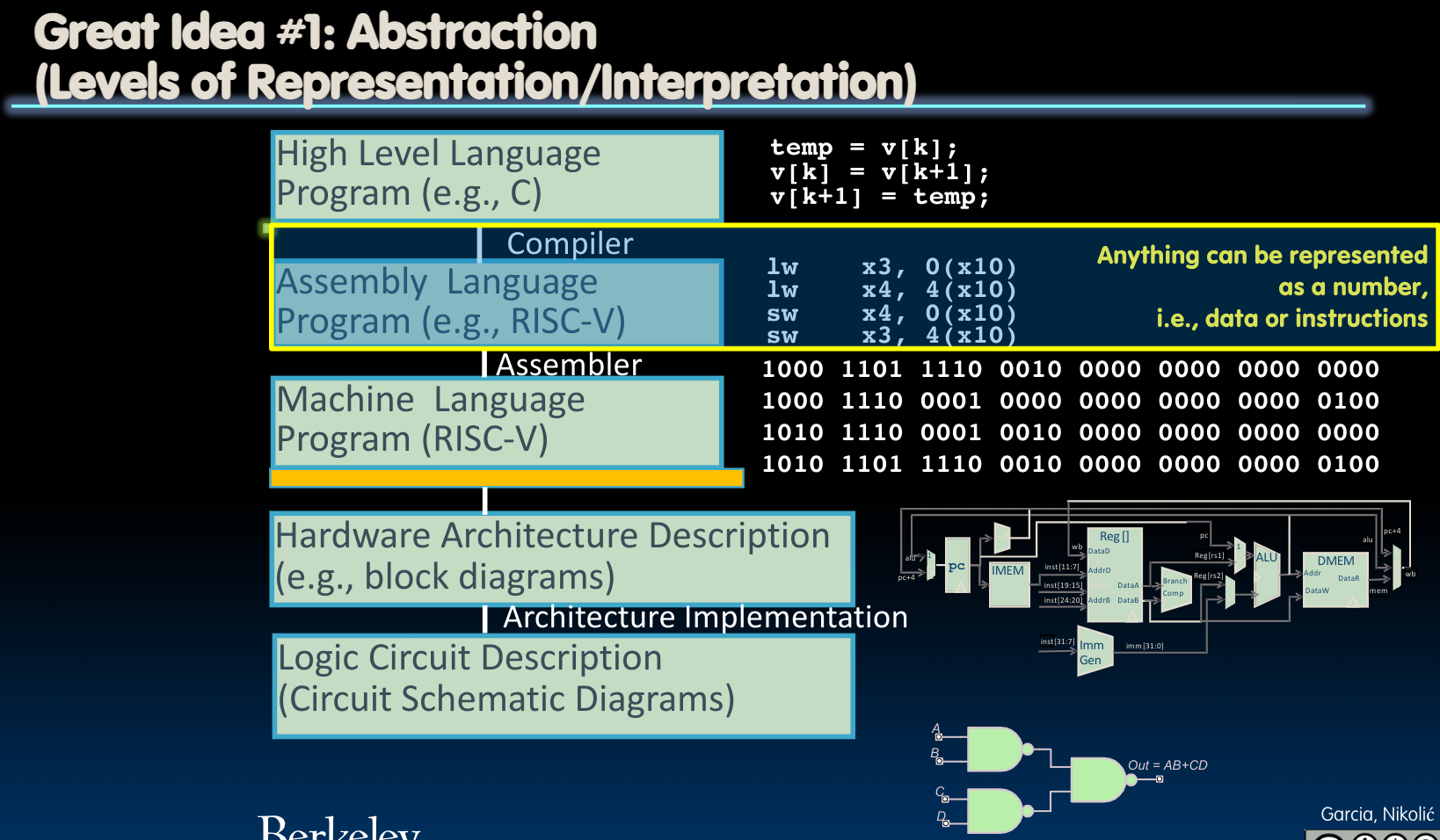


Number representation
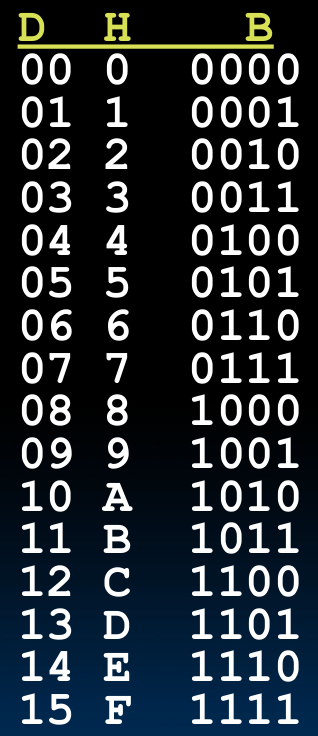
- 进制转换表:
- Number representations
共有五种表示方法,其中较为常用的,比较适用于计算机使用的方法有三种。
Unsigned
这种方法即不带有符号的表示方法,是最简单的一种表示,当我们有五位可以用来表示数字的时候,无符号表示方法可以记录0~31的数字,但是接下来的有符号表示只能记录-16~15的区间了(因为最高位用以记录正负–没有免费午餐定理)。
Sign and Magnitude
这种方法根据老师的描述,就是我们数电课程中学过的原码:

这种方法主要有两大缺点:
- 零位重合
- 正数与负数的计算方向是相反的(依上图)
One's Complement
这种方法就是反码:
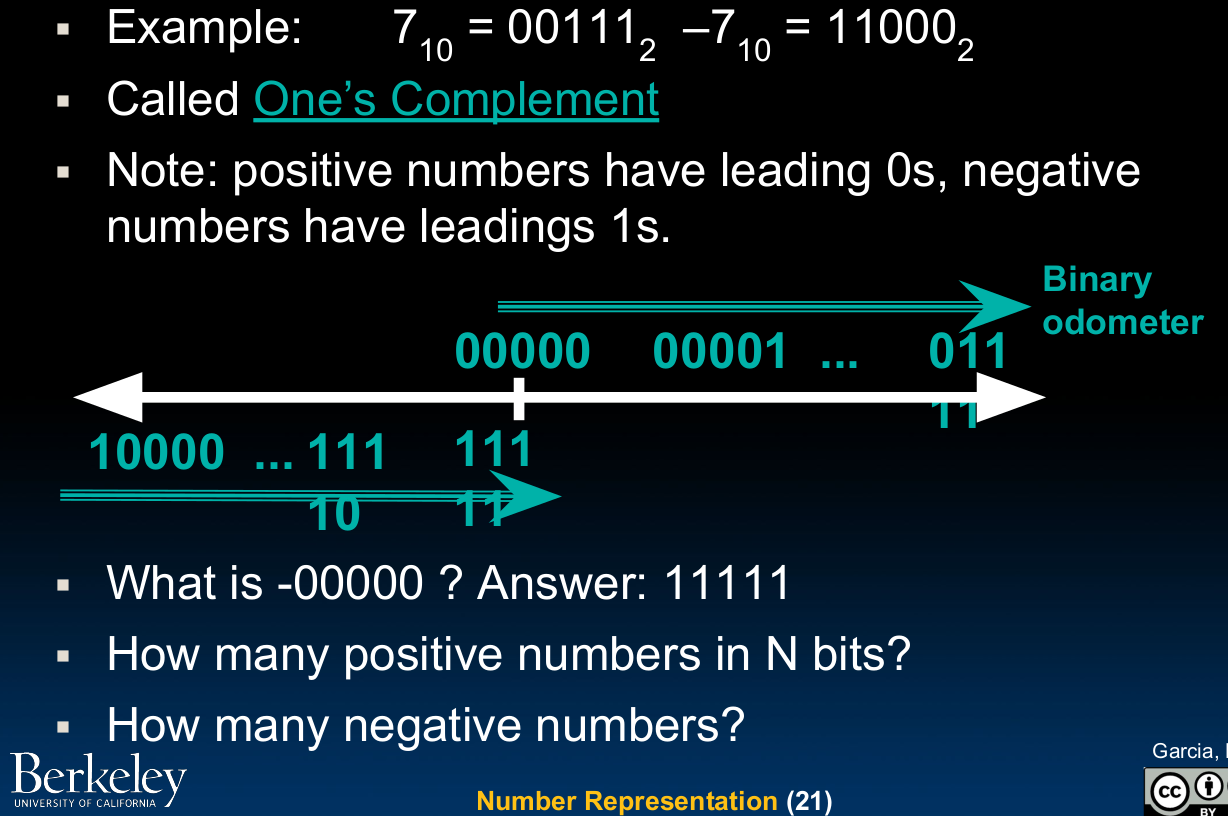
反码相比源码,虽然从负数到正数的计算方向保持了一致,但是仍然存在零位重合的问题。
Two's Complement
这就是我们所说的补码了:

根据上图我们可以看出,补码完美的解决了先前方法存在的问题,11111这里不再是-0,而是-1了。公式:补码=反码+1.(正数的反码与补码均是其本身)
Bias Encoding
这种编码方式常用于将一个unsigned representation转化成signed的形式(比如要把一段在$$x$$轴上方的正弦波抬到中轴处),我们通过给入程序一个bias为$$-(2^{N-1}-1)$$的数值来辅助实现这一变换,在进行了$$unsigned+bias$$的操作之后,他最终形成的表示范围(以$$N=5$$为例)是-15~16(与补码不同)!也就是说,原本的00000现在变成了最小的那一个负数了:

在上述的众多方法中,我们常使用的是unsigned,two's complement,bias encoding.
- overflow
在计算的过程中,可能会发生溢出的情况,那到底什么时候才算做溢出呢?当我们舍弃掉最高位进位后,如果发现运算结果是错的,那就说明确实是溢出了,一般来讲,我们使用双高位判定法来判断是否发生溢出:
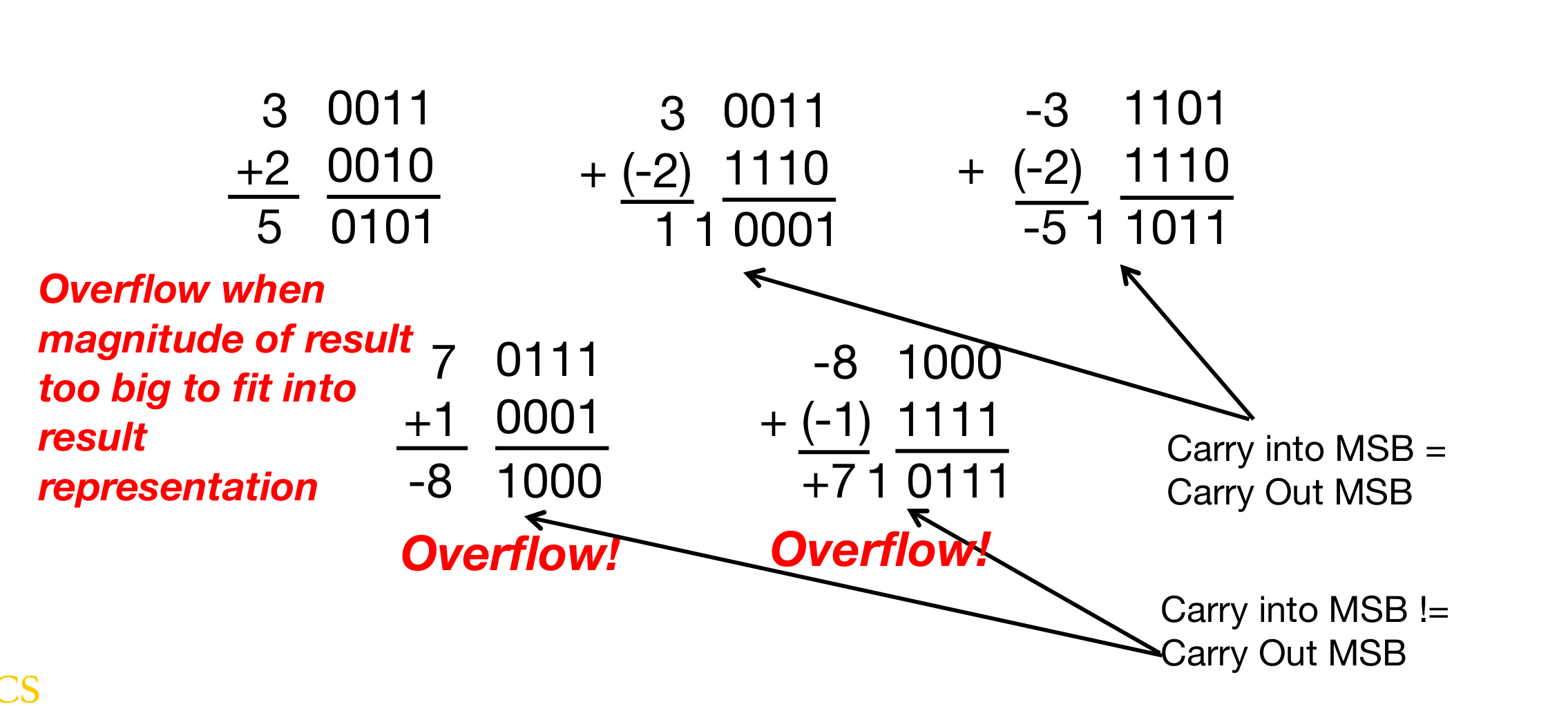
当最高数据位向符号位进位不等于符号位进位时,即发生溢出!在硬件电路的实现中,我们可以通过异或来实现这一点。
这种判定方法是针对有符号数字而言,如果我们面对的是无符号数字,那么只要最高位进位1,就发生溢出。
C Programming
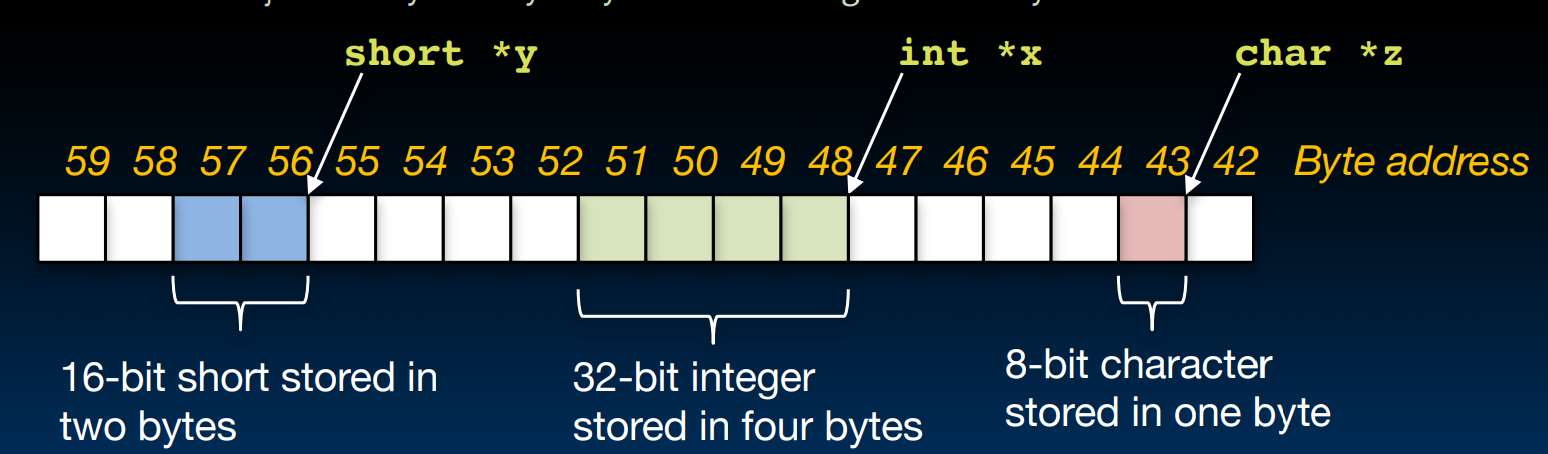
Pointing to Different Size Objects
32?64?
首先我们要有存储单元的概念,在现代的微型存储器中,一个存储单元是8个bit,也就是一个byte,换句话说:这些机器是byte-addressable的 – 微型存储器的容量是以byte为最小单位计算的。
需要注意的是,当我们谈论32位机器或者64位机器(cpu)时,我们所指的是它一次能够处理的数据的长度,也就是寄存器的位数,也被叫做字长(word length),它和我们所说的数据总线,地址总线等没有直接关系。
数据总线的长度一般要等于cpu的字长,这是为了保证cpu的数据处理能力得到充分利用,所以我们可以说字长由微处理器对外数据通路的数据总线条数决定。同时,由于指针也是数据,所以地址在进行数据传送时会被匹配到同样的位数,但这不代表地址总线长度要和字长或者数据总线的长度一样,地址总线的长度由cpu自身设计决定,与cpu的位数没有直接关系,但由于地址总线决定了cpu的寻址能力,所以地址总线所能够支持的寻址一定要大于等于数据总线的位数,不论通过什么方法来实现这一要求。
总得来说,内存的大小是由硬件以及操作系统共同决定的,硬件对应着地址总线,而操作系统对应了我们在后边将会提到的虚拟内存。
word alignment
在实际使用时,我们常常会遇到内存对齐的说法,什么是内存对齐?为什么我们需要这样做?
比如对于一个32位的处理器,它一次能够处理数据的能力为32 bits,换算成内存单元就是4 bytes。cpu正是按照这个4 bytes的块(chunk)来读写内存的,块的大小被我们定义为内存访问粒度。
我们可以把内存想成一个无穷大的array,寻址从0位开始,我们的数据存储也正是从这个地址开始,如果内存访问粒度是4 bytes,那么0,4,8等等都是aligned address。
那如果我们的数据没有做到word alignment会发生什么后果呢?对于某些处理器而言,这会让它们进行多次的内存访存(速度变慢),分别访问每一个内存单元,读取其中需要的数据,最后再把多个单元读取到的数据进行merge,放到寄存器中。而对于某些cpu,则不会支持非内存对齐的数据存储形式,会直接产生报错。
根据这里的文章,在每一个chip内,都有多个bank,每一个bank就是一个二维平面上的矩阵,矩阵中的每一个元素就是一个字节。实际上,bank是按照如下的排列方式存在的:
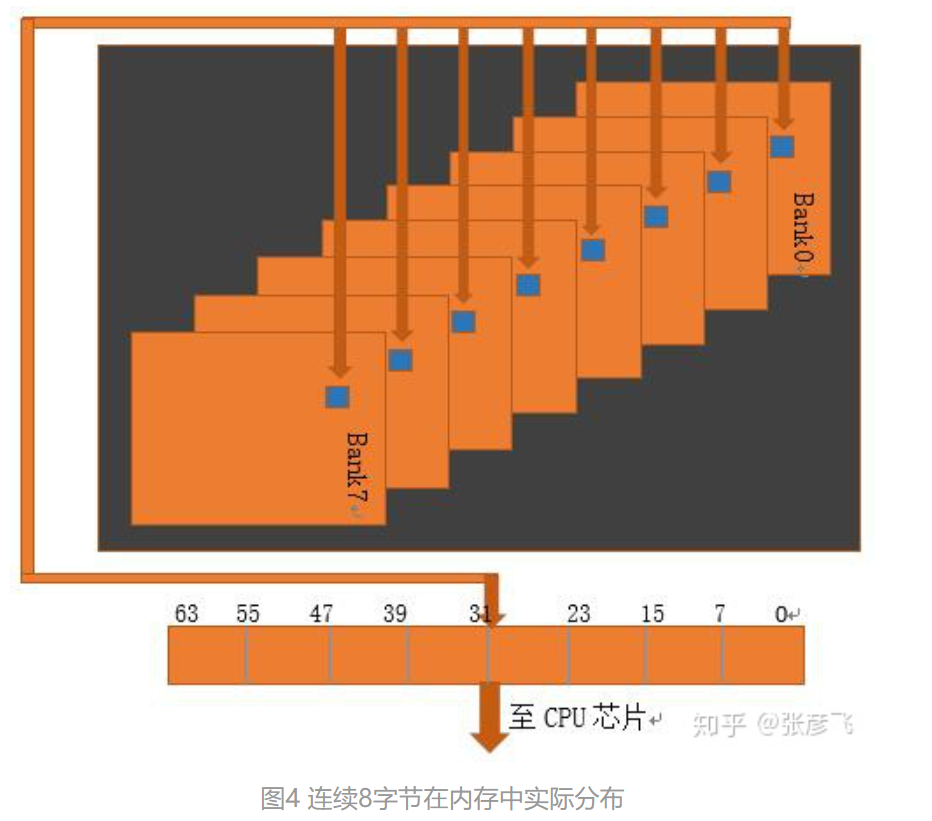
这种设计允许在读写数据时几个地址并行工作,提升电路效率。所以如果我们不按照内存对其的方式存储,每次读取数据时,电路操作的次数就要更多,
some notice on pointers
这里还是记录一下关于指针的使用事项。

上面的这幅图很好的包含了我们需要注意的关键点。首先我们可以看到:指针与整型均占4个bytes,之后我们声明了一个包含4个元素的整型数组,所以占据了28、32、36、40总共4个内存单元。
而在此之后,我们调用malloc函数,分配了一段内存,并让先前定义的指针p指向了这块我们刚刚分配的内存,但此时,这段新分配的内存里边的值还是垃圾值。相应的,指针p的值就变成了指向的那个地址,也就是40了!
我们一定要先分配内存再使用内存,如果在定义指针后没有使用
malloc分配内存就直接*p=1,是不可以的。
最后,我们注意到对于数组a,a与&a的值是一样的,**不同于先前我们所定义的变量的表现!**这一点我们在CS 106L的课程笔记中也有提过,该课程的汇编部分会再次提到这一话题。
需要注意的是,数组名称不可以被重新赋值(
reassigned),所以我们也不能对其进行++a的操作。这一点也是与指针有很大差异的一点.
- 此外,我们还要注意,在实际编程中,我们可能经常需要向一个函数传递数组,如果我们想在函数内部利用
sizeof操作符获取数组大小,那么由于传入函数的是一个指针,我们只会得到指针的大小而非实际的数组大小–此时我们必须要向函数传递一个额外的size参数;当然,如果我们在处理一个字符数组,我们完全可以利用其null terminator的特征来定位整个数组。 - 在C中使用字符串(字符数组)时,末尾的
\0在ASCII码中对应了NUL,即ASCII码中的0!所以我们在判定字符串是否到达末尾时,可以直接将*str++*作为判定条件,而无需和\0比较。我们需要注意,当使用字符数组来储存字符形成字符串时,我们需要手动添加一个\0,但是在使用string literals会自动添加,不需要我们手动操作.
Memory locations
首先关于声明:
- Structure declaration does not allocate memory.
- Variable declaration does allocate memory.
在先前的**C++**课程中,其实也简短的提到过,变量的生命周期(storage duration)有三种,我们形容为static,automatic,dynamic.分别对应着静态、全局变量;局部变量;动态分配内存的变量.
相应的,这三种不同的变量也被存储在不同类型的内存池中:
- Static storage:储存全局变量,生命周期为整个程序运行的时间
- The Stack: 储存局部变量、函数参数、返回地址
- The heap: 使用
malloc动态分配的数据,直到free生命周期结束(这里的生命周期结束其实并非变量消失,后便会提到)
Memory management
在一个程序中,共有四种类型的地址空间,除了在上一小节中提到的三种内存池之外,还包括code段,他们的分布形式如下图所示:

从上至下,地址空间从最高一直到0;与之相对应的,分别用以存储stack,heap,static data以及code:
- 当我们向
stack中存入数据时,它会向下分配新的内存,而heap则是向上分配内存(我们不需要在这里考虑两个内存池发生重叠的问题,CS 162会介绍处理方法). static data与code均是在程序运行过程中不会发生改变的内存区域,code主要用以存储运行需要的代码,在程序一开始即生成。
Stack
在上边我们提到,stack用于存储以下三种类型的数据:
Return "instruction" addressParametersSpace for other local variables
stack区的内存分配是连续的。他有一个栈指针(stack pointer),指向当前栈顶的位置(随着新开辟的栈区域不断地向下改变位置):

当我们结束了一个procedure时,栈内存被自动"释放",之所以这里加了引号,是因为栈内存释放的方式与我们常理解的释放不同,它在释放的过程中将栈指针不断上移到上一个还没有被释放的栈块的栈顶,而先前存放在已经被"释放"额区域内的数据,其实仍然保留在其中!
栈内存的分配与释放都是很快的!
Heap
与栈不同,堆的内存分配不是连续的。两段看起来应当被分配在前后未知的动态内存,很可能彼此离得很远。相应地,**堆的内存分配和释放过程相比起栈是很慢的!**在使用堆时,我们想尽量避免碎片(fragmentation)化的出现:
In this case, we might have many free bytes but not be able to satisfy a large request since the free bytes are not contiguous in memory.
那么堆内存的分配和释放等等过程究竟是如何实现的呢?
每一块堆内存的头部都有这样两组数据:
- 该块的大小(
size of the block) - 指向下一个块的指针(
a pointer to the next block)–有点像指针
所有的空内存块被保存在一个循环链表中!(在一块已经被分配走的内存中,上述的pointer field是处于不被使用的状态)。
而函数malloc便会从这个循环链表中替我们寻找可用的内存,寻找的方法有这样几种:
best-fit:在循环链表中选择满足大小要求的最小的内存块first-fit:选择第一个满足大小要求的内存块next-fit:进行first-fit,但是记忆上一次搜索完的位置,下一次从此处继续搜索可用内存
而相对应地,free函数在将指针指向的内存块释放后会检查前后的内存区域是否也是空内存块,
- 如果是,则将几段内存
merge; - 如果不是,则将刚被释放的内存加入循环链表中
When memory goes bad
在课程中,提到了几种应当避免出现的内存分配和释放问题,这里说几个:

这个情况其实很tricky,观察结果我们发现,第一次使用content和第二次的结果不一样,why?
注意到这里我们把指向栈内数据的指针作为了函数返回值,当栈内存被释放后,根据前边的描述,其中的数据其实并没有被抹掉,所以我们仍能够通过返回的指针stackAddr获取原先的数据,所以第一个printf没有问题。
但是printf也是一个函数,也被分配到了栈上,由于栈内存是连续分配的,他恰好占用了原本数据y的位置,导致y被毁掉了–这就导致第二次我们再次尝试获取y的数据时,指针把我们带到了垃圾值上!
Realloc
Realloc函数也是可能诱发内存分配问题的:

在使用realloc时,如果程序发现接下来的空堆内存块不够扩展到指定大小,他会将原来的数据一起搬运到新的能够存放整体大小的内存块上!这就导致我们原本指向foo的指针g现在不可用了。
calloc
除了malloc和realloc外,我们还有一个calloc函数,可以避免我们忘记了初始化刚分配的内存空间的问题:
// define a n*m matrix of int
int **mat = (int **)calloc(n, sizeof(int *));
for (int i = 0; i < n; ++i) {
mat[i] = (int *)calloc(m, sizeof(int));
}
需要注意的是,该函数可以直接给出初始化的空间+初始化值–0(真正意义上的0,比如NULL或者数值的0之类的…)
几种会出现segfault的情况:

some notice on memory menagement
- 对于程序中定义的常数(
constants),它可能存放的位置有:
- Code段:
x=x+1,其中1在编译阶段直接被存储到machine instruction中,以及#define y 5时 - static段:全局变量:
const int x = 1中的1 - stack段:将常量定义在函数中:
int total = 1
此外,
string literals被存放在static段中,具体可见这里.与**C++**不同的是,C中没有引用的说法,所以当我们在对一些数据结构比如链表进行内存的分配和释放时,我们不能够传递指针的引用,需要传递指针的指针.
Stream
这里主要说一下关于C中的流这一概念,以及之前我一直没懂的FILE这个对象。
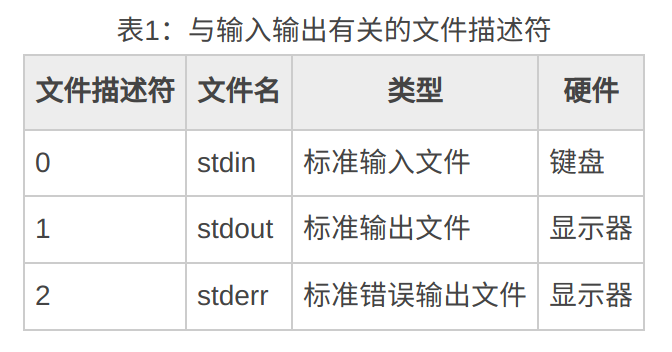
其中,stdin是输入流,因为在linux中一切皆文件,所以他也是标准输入文件。同理,stdout是输出流–标准输出文件。
我们也可以这样理解:linux通过文件的形式实现了输入/输出流,文件们分别对应着不同的文件描述符,每当我们打开文件(也是广义的!)时,就有一个代表着该打开文件的文件描述符,程序启动时默认打开三个I/O设备文件:标准输入文件stdin,标准输出文件stdout,标准错误输出文件stderr,分别得到文件描述符 0, 1, 2:
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开.
在Stanford CS 106L最开始的笔记章节中,我们对stream对象做了很多的分析,有了初步的了解。stdin默认从键盘接收输入,stdout默认将内容输出到屏幕上,但这不是它们唯一可行的路径和流入(出)方式,比如读入/写入文件当中,我们可以使用redirection(重定向)的方法改变其输入/输出的对象.
</>重定向在使用gdb调试时也可使用
需要注意的是,我们经常使用的FILE和我们日常所说的狭义的文件没有任何关系!根据**C++**官方文档:
Object containing information to control a stream
Object type that identifies a stream and contains the information needed to control it, including a pointer to its buffer, its position indicator and all its state indicators.
换句话说,他可以用来表示一个stream对象。这也是为什么我们在函数fgetc(FILE *stream)中,可以使用fgetc(stdin)的原因。
Bit operation
在Fa 2021 lab 02中,我们需要解决三个位操作的函数,查看Github仓库。分别为:
- 获取某位
- 改变某位
- 翻转(
flip)某位
在后两种操作中,我们需要注意的是使用一个所有位均为1的参考值辅助操作,同时将原本的二进制数分为前后两个部分加以处理(flip)可以将需要flip的位单独拿出来,最后使用|合并.
Floating Point
这一节来处理浮点数.
Basic Representation
首先,我们如何把一个二进制浮点数计算成我们习惯的十进制的样子?
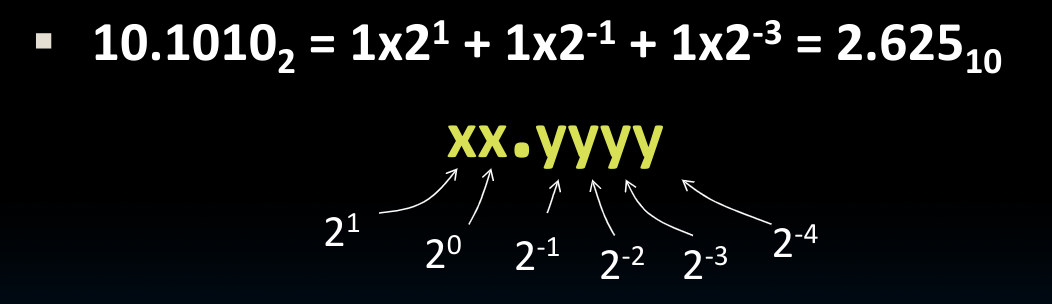
为什么叫floating point?这是因为在一开始,我们思考的储存方式是固定小数点的位置,这种方法被称为fixed point,而与之相对应地floating point则是允许小数点在数字之间移动–这种表示模式允许我们记录更大范围的数字:

为了表示一个floating point,我们的基本思路是用一段bits表示需要记录的数字部分,再用另一段bits表示小数点所在的位置:
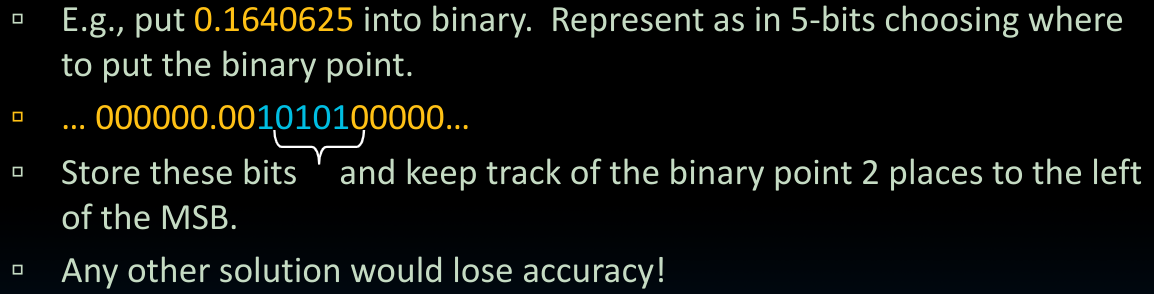
按照如上的思想,我们需要将浮点数在内存中用如下方式表示:

float共使用32bits记录,其中,浮点数本身的最前边的1我们不在这里单独记录–因为除了0,其他的任何一个浮点数按照**科学计数法(Normalization)**的模式,都需要有一个1在前边。(后边我们会看到,即使是0,我们也有办法在不使用这个开头的数字的前提下表示出来!)
float(Single Precision)的储存形式整体上分为三个部分:
Sign bit-1 bitExponent bits-8 bits(对于double为11 bits)Signtificand bits-23 bits(对于double(Double Precision),为52 bits)
我们可以先对这种表示模式进行一下思考:其中的Exponent部分应当使用一种类似于Two's complement的表示方法,因为我们需要最终表示形式的指数部分可正可负。Significand部分则是直接存储了二进制浮点数小数点后的二进制数字序列。
但是使用Two's Complement的一个问题在于,当机器上不存在用于浮点数比较的硬件(如早期的计算机)时,我们无法直接通过整数比较的方法来比较浮点数,并且,即使存在用于浮点数比较的硬件,浮点数比较的过程也是远远慢于整数比较的!
当我们使用Two's Complement来表示Exponent时,当Ex所记录的整数越大,我们并不能够得出对应的float越大的结论(在其他部分相同的前提下)– 当Ex从00...0到11...1,实际的Exponent值,在此时也可以用于表示实际的浮点数值会从0~+MAX,再到-MAX~0变化!
于是我们想到了Bias Encoding/Notation!在这种表示模式下,Ex所代表的整数的变化趋势与实际值的变化趋势是完全一致的,所以对于float,我们使用bias=-127,相对应地,double中bias=-1023.
这样一来,我们的比较过程可以设计为:
sort the sign field by just +/-sort by more significant exponentIf Exponent the same, using mantissa sorting
于是,以float32为例,最终我们的计算公式为:
$$(-1)^S\times (1+significand)\times 2^{(Exponent - 127)}$$
同时,显然,这种表示方法对于数字范围是存在限制的,这意味着我们会遇到overflow:

Special Numbers
∞
在浮点数的表示方法中,我们可以表示一些特殊数字,比如首先我们会想到表示正/负无穷。那么IEEE 754是如何表示∞的呢?
- Most positive exponent reserved for ∞
- Significands all zeros
也就是说,当我们从1111110|11...1再加一个1,就变成∞了!如果sign bit为1,那么就是-∞.
0
其实严格意义上来讲,0并不能算作special number,因为他的表示与一般的方法是一样的,需要注意的是,在浮点数中,有一个+0,也有一个-0,从数学意义上来说,这两个0并非真正的0,而是指的从两个方向无限趋近于真正的0。他们都是合理的:
+0: 0 00000000 00000000000000000000000 -0: 1 00000000 00000000000000000000000
如此一来,我们用significand和Exponent均为0的方法来表示数字0(或者说数字0和这种表示方法是等价的)–>这允许我们不使用整数部分的数字,也能够表示0了.
所以我们在偌大的浮点数数字范围中,还有哪些区域的数字表示没有被使用?我们还需要表示那些特殊数字?

根据上图,我们还有两个数字区域没有使用,分别是Exponent为0以及255,且significand(小数部分)不为0的情况.
为什么我们把正常数字的
Exponent范围限制到1-254?这是因为我们刻意为special numbers保留了范围.
NaN
我们使用Exponent为255,Significand不为0的情况,来表示所谓的NaN(Not-a-Number).也即是说,当我们从inf再往前走一步,就回到了Nan sea.
那么NaN有什么用呢?
- 可以提供
debug讯息 - op(NaN, X)=NaN
需要注意的是,NaN与任何东西比较的结果都是false,并且NaN != NaN.
Denorms
首先,什么是normalization? 通俗地讲,normalization就是将一个数字表示成科学计数法的1打头的表示,那么如果我们想把开头的数字搞成0而非1,这就叫denorm.
对于浮点数,我们当然希望它的尺度是均衡的,换句话说,我们希望在一段范围内,浮点数之间的距离是恒定的.
我们来计算一下现在的情况是否满足这一条款:

显然,从0到a的距离…实在是相比起来有点太大了…
所以我们怎么解决这个巨大的gap的问题?奔着制造一个尺度均衡分布的数字范围的目标,我们利用还没有被分配任务的Exponent为0,且significand不为0的范围,提出DEnormalizaed number:
No leading 1, implicit exponent = -126 (rather than -127)
如此一来:

需要注意的是,随着Exponent部分的变化,我们在significand的每一段的尺度也会发生变化,在最开始时每一段的间隔为$$2^{-149}$$,当Exponent加1之后,significand的间隔会变为$$2^{-149}\times 2$$. 换句话说:
Exponent tells Significand how much (2^i) to count by (…, 1/4, 1/2, 1, 2, …).
当存储内部的Exponent为150时,significand的间隔会变为1($$2^{(150-127)}\times 2^{-23}=1$$)
最终,我们得到了完整的浮点数表示:

当我们试图从
00...0一直加到11...1时,浮点数的大小变化范围和我们先前提到的Sign and magnitude(原码)一致!
Attributes
首先,浮点数运算不具备关联性:

其次,正如我们在写程序中经常遇到的,浮点数存在rounding这一机制,通常,浮点数硬件带有额外的两个bit,之后使用rounding机制将浮点数表示为合适的值。rounding发生在将double转为float时,也发生在将float转为int时:

需要注意的是,当浮点数恰好位于rounding的分界线上时,我们将浮点数rounding到偶数上。
再者,浮点数的加法运算并不像整数的加法运算那样简单,我们可能先需要将浮点数denormalize,以匹配其指数部分,在完成significands的加法运算后,再将结果normalize.
我们可以使用强制转换机制,这一机制在内部通过rounding来实现。需要注意的是,由于浮点数尺度的问题,它并不能表示某些整数!所以:


除了上述的float以及double之外,还有其他一些表示方式:

特别的是,由于机器学习并不需要太高的精度要求,bfloat16类型被使用在ML中,它牺牲了一部分significand空间以换取更大的范围(Exponent).
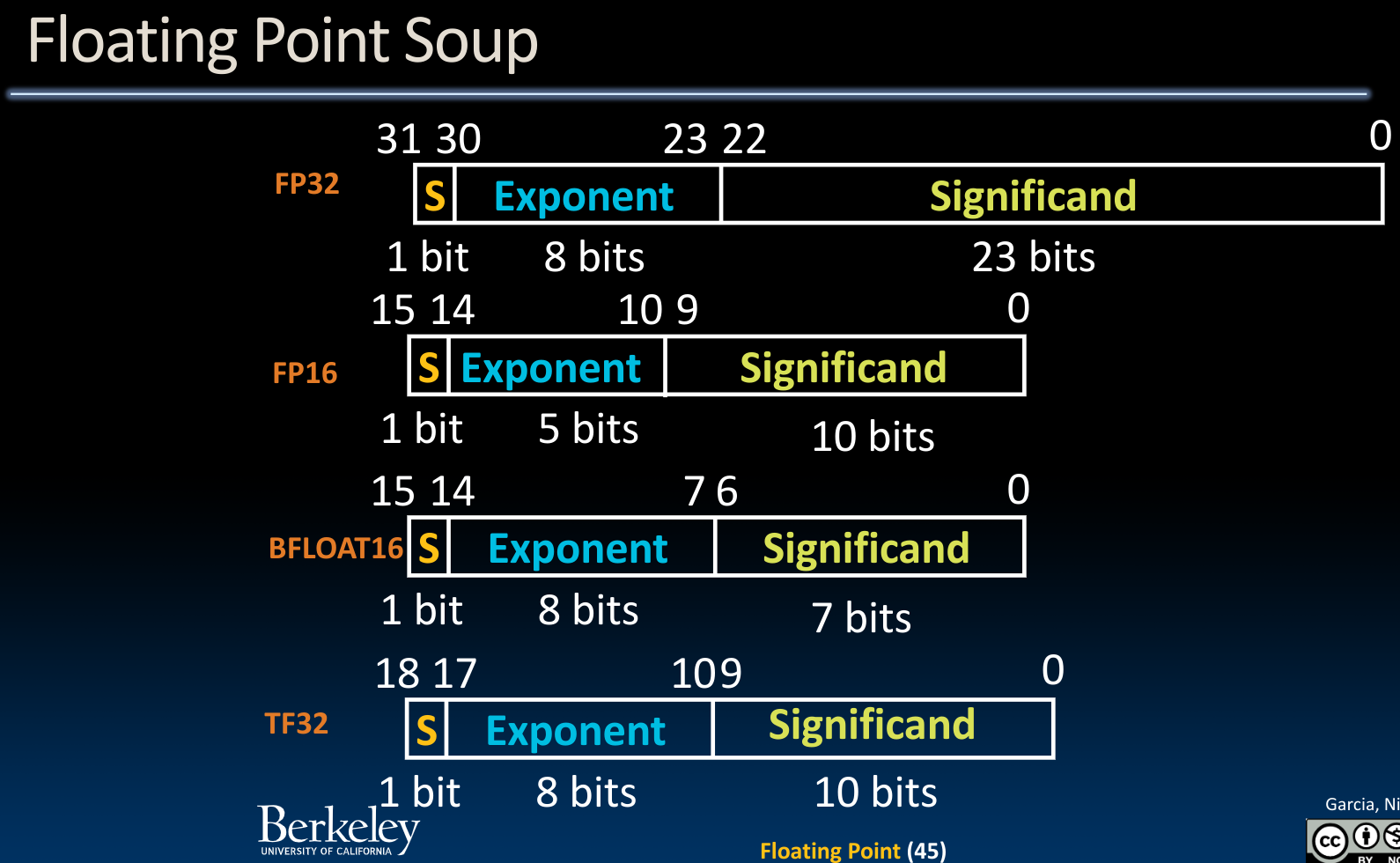
特别的是,有一种观点提出,我们可以对float point做进一步优化,使得Exponent和Significant的长度都可以变化,以适应不同的场景。同时,携带一个u-bit来表示这个浮点数是否经过了rounding.换而言之,他是一个准确的值还是一个估计值。
RISC-V Instructions
汇编语言的操作数(operand)是寄存器(register)!
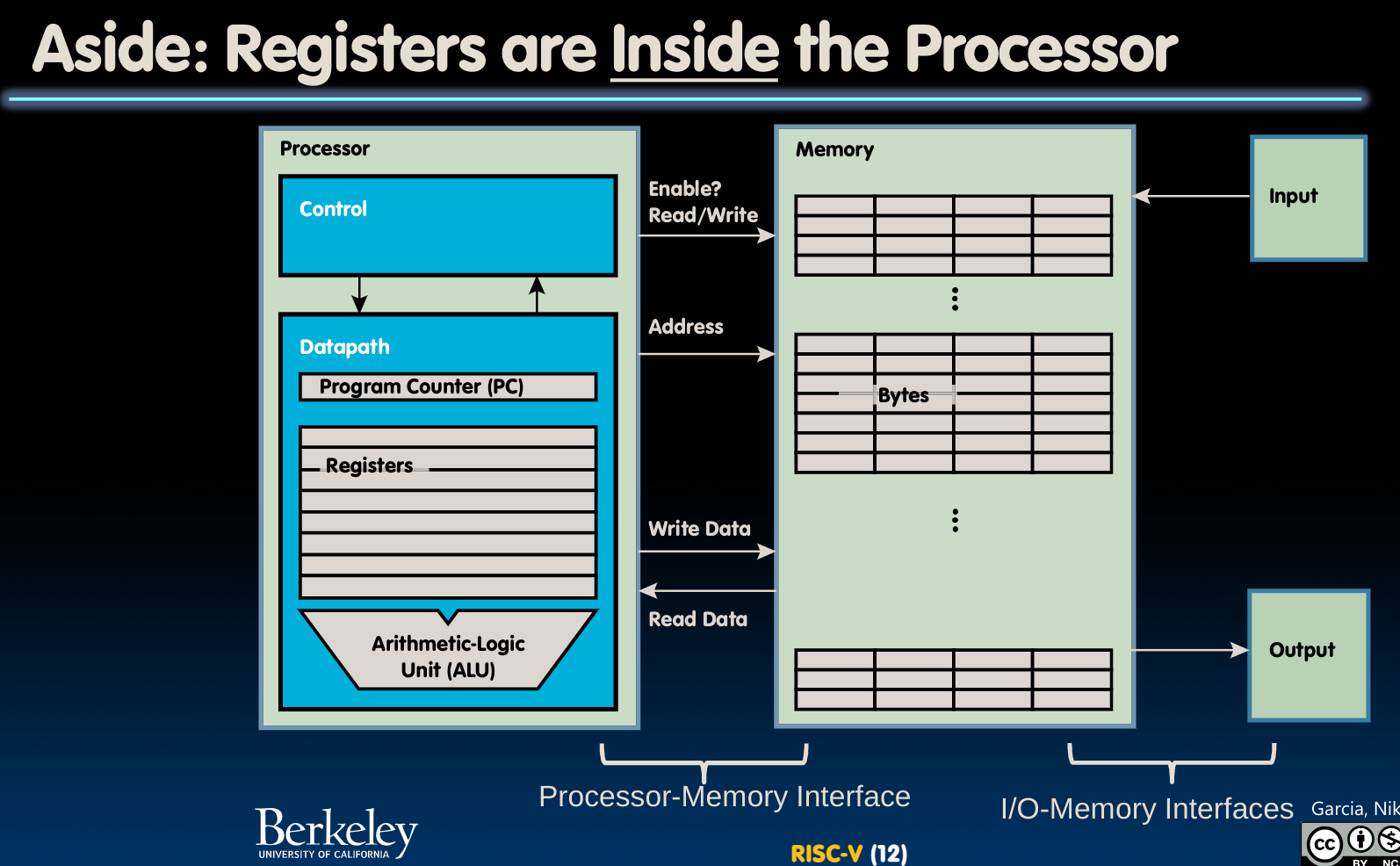
在RISC-V中,共有32个寄存器,其中x0是最特殊的,他始终保有0值!这意味着我们只允许使用其他31个寄存器来存储变量!
关于RISC-V的几个基本的操作,如add,addi,sub这里不详述.
storing data in memory
我们首先要知道CPU与内存交互的两种基本模式:
- Write Data – Store To Memory
- Read Data – Load from Memory
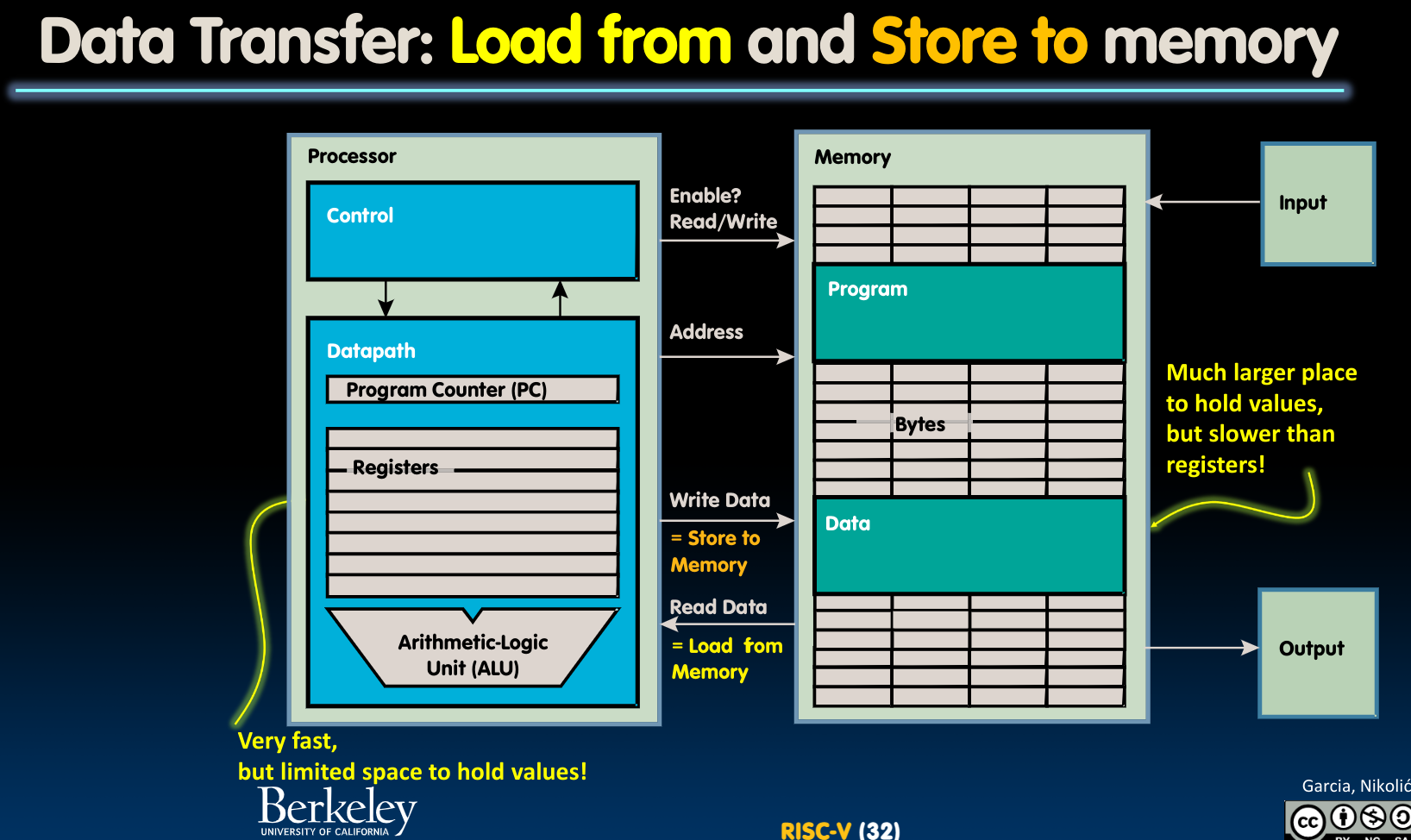
其次,在word alignment的一节我们已经提到过,一个8bit的块被称为byte,是一个微型存储单元(byte-addressable)。字(word)在32位CPU中,是4 bytes,内存读取按照word读取(内存访问粒度)……(参见原章节)
那么每一个word在内存中是以什么样的格式存储的呢?在这里,我们的存储方式为Little-endian convention:

Word address is same as address of rightmost byte – least-significant byte.
也就是说,word中最低的那一个byte被安排在了最小的地址上。与之相对的是Big-endian convention:

需要注意的是,无论是哪一种bytes的存储方式,其中bits的存储方式是不变的.
Data Transfer Instructions
在RISC-V中,一个寄存器为4bytes,共有32个寄存器,也就是128bytes。而相对应的Memory有2GB-64GB,这也意味着寄存器一定要比内存(DRAM)更快,大概是它的50~500倍。所以我们更想让指令(Instructions)在寄存器中被操作,而不是直接在内存中操作–这就需要内存与寄存器的双向数据交互。
- Load word from Memory to Register

lw这个语句的含义是将储存在x15中的base pointer的值加上12bytes的地址里储存的内容,即A[3]复制到x10中. 与之相对应地,是从寄存器向内存中储存内容的sw:
- Store word from Register to Memory

除了对于word存取的操作指令外,我们还可以直接对Bytes进行操作:
- Loading and Storing Bytes
分别于lw,sw相对应地:
- lb
- sb
E.g.
lb x10,3(x11)
该指令将指针指向的内容复制到寄存器x10的low byte position.
Sign-extend
sign-extend的意义在于保证一个有符号数字(可能不到32bits)在被储存进寄存器(32bits)时仍然保证是一个有符号数字:
如果在前边所有的高位里都存储0,那么对于这个寄存器内的32位数字来说,就始终是一个
positive number了.
所以,在lb中采用了如下方法:

需要注意的是,在sb中没有sign-extend的说法,我们只需要将寄存器中的内容取出来就好,sign-extend在sb中没有意义。
RISC-V也有一种储存
unsigned byte的方法:lbu,顾名思义,是使用zero extend的方法来填充寄存器.
Why need addi?
我们发现,这两种写法具有相同的效果:
// first
lw x10,12(x5)
add x12,x12,x10
// second
addi x12, value
那为什么我们需要addi这个指令呢?(RISC-V提出了最小指令集的要求)这是因为第一种写法要求从memory加载数据,这一操作相对较慢,而直接使用immediate value可以利用寄存器序列中的temporary(专门用于存储临时值的寄存器)来实现运算.
Decision Making
什么是Decision Making?就是我们在高级语言中常用的if判断等.
Conditional Branch
beq reg1, reg2, L1
L1 branch if reg1 == reg2
bne reg1, reg2, L1
L1 branch if reg1 != reg2
bge reg1, reg2, L1
L1 branch if reg1 >= reg2
blt reg1, reg2, L1
L1 branch if reg1 < reg2
- unsigned version–
bltu,bgeu

Unconditional branch
j Label(jump Label)
Loop
书写循环的关键在于使用Conditional branch:

Logical instructions

and-andi(
andi x5, x6, 3)sll-slli(
slli x11, x12, 2)srl-srli(
Right shifting)…
不存在NOT这一指令的,因为我们可以使用
xor 1111111。Arithmetic Shifting
又名Shift right arithmetic: sra-srai,应用于signed numbers。这两条指令使用sign bit填充右移需要的位。这一操作看起来像是将原本的数除以2,但事实并非如此。这是因为C语言要求round towards zero.
A bit about Machine Program
我们的高级语言程序在经过处理之后成为汇编指令(Instructions),储存在memory中:
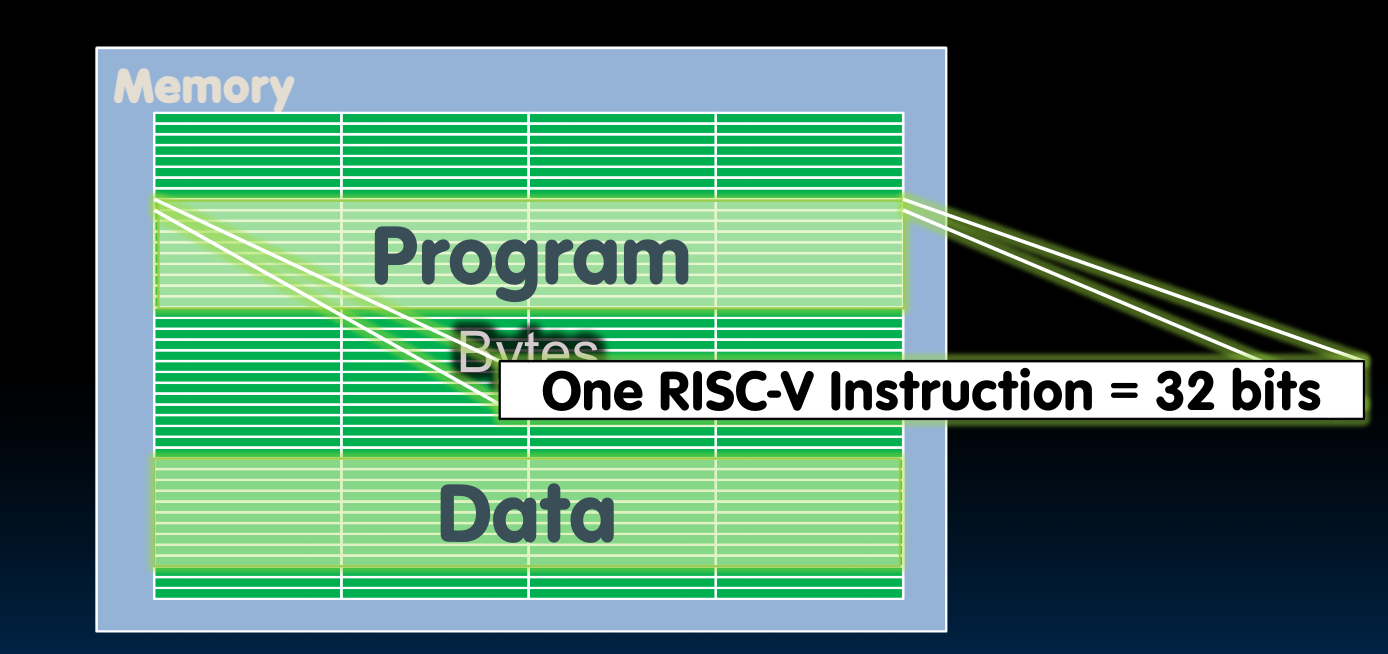
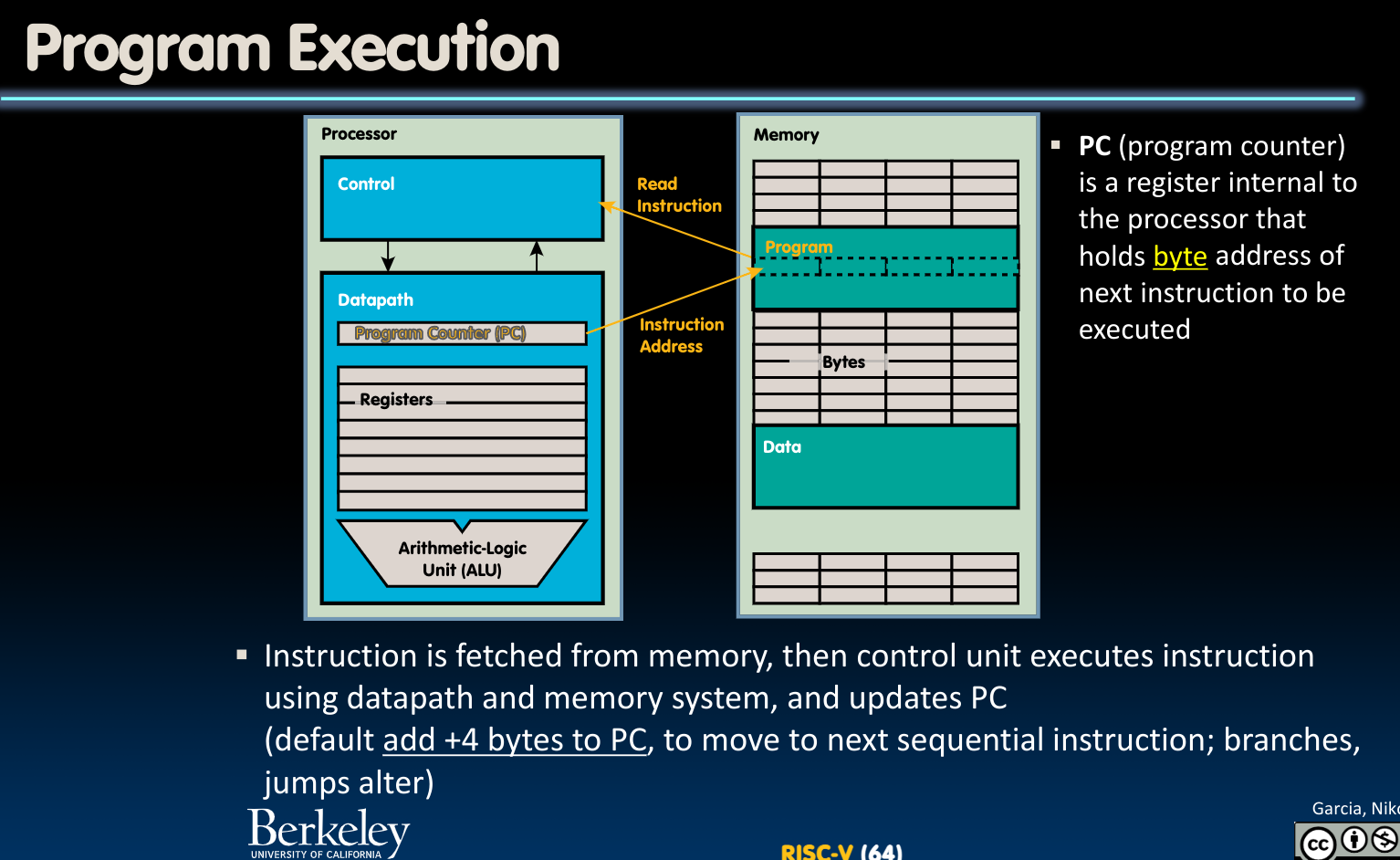
那么程序是如何被执行的呢?
从宏观上讲,当然是通过CPU与内存的交互–CPU从内存中读取指令+数据,之后将数据写入内存。
进一步分析,是CPU的Control Unit(控制器)读取指令,控制CPU中Datapath(运算器)里的寄存器们,并由CPU内部的PC(Program Counter)寄存器记录需要执行的指令的byte address(update PC)实现的:
Helpful Assembler Features
- Symbolic register names
- a0-a7 (x10-x17): eight argument registers to pass parameters & two return values (a0-a1)
- ra (x1): one return address register to return to the point of origin
- s0-s1(x8-x9), s2-s11(x18-x27): saved registers
- …(More)
- Pseudo-instructions
- mv rd, rs(addi rd, rs, 0)(actually copy)
- li rd, 13(addi rd, x0, 13)
- nop(addi x0, x0, 0)
Function calls (single/nested)
在RISC-V中的函数调用需要经过哪些步骤?

需要注意的是,对于RISC-V,所有的指令都是4 bytes,被存储在memory中,就如同data一样.
我们以一段程序为例,展示这一过程:

在函数调用之前,我们先要将被储存在saved register中的两个变量a, b放入用于储存函数参数的寄存器a0与a1中。(如果此时这几个寄存器的容量不足以存储函数参数,那么需要借助stack,这个后边会提到)。在函数执行时,我们把结果(return value)放到寄存器a0中。
之后我们需要把函数调用结束后需要返回的位置存储在寄存器ra中(link),再跳转到函数的位置执行函数代码(相当于把控制权交给函数)(jump)。
当函数调用结束后,我们通过jr ra的指令返回储存的需要跳转回的位置。之所以不在这里使用j label的指令,是因为函数可能在程序中被多次在不同位置调用,所以我们需要把跳转回的位置储存在一个变量中(该语句也是函数代码的一部分)
jump in Function calls
在上述函数调用的过程中,我们首先将return address储存在寄存器ra中,之后使用j指令跳转,这两条指令可以合并为一句(jump and link):
jal sum # ra=1012, goto sum
这也是一个pseudo-instruction,真正的指令为jump-and-link:
jal x1, sum
与之类似的,jr也是一个pseudo-instruction,对应的base-instruction为jump-and-link register:
jalr rd, rs, imm
指令jr ra还可以缩写为ret。

Nested Calls & Register Conventions
在写出具体的解决方案之前,我们先来思考如下的案例:
int leaf(int g, int h, int i, int j) {
int f;
f = (g + h) - (i + j);
return f;
}
我们需要用到寄存器a0, a1, a2, a3来储存函数参数与函数返回值,同时s0, s1这两个saved register被用来存储我们的local variables.
那么问题来了,既然我们需要用到这么多寄存器?那原本存储在寄存器中的值怎么办?直接毁掉(clobber)吗?当然不是,我们需要保存原本储存在寄存器中的值–借助stack来实现:

在有的汇编语言指令集中,是有push和pop这两个指令的,但是RISC-V没有,所以需要我们自己去实现它。
复习一下先前关于stack的知识:

举个例子,对于函数leaf,编译后是这样:
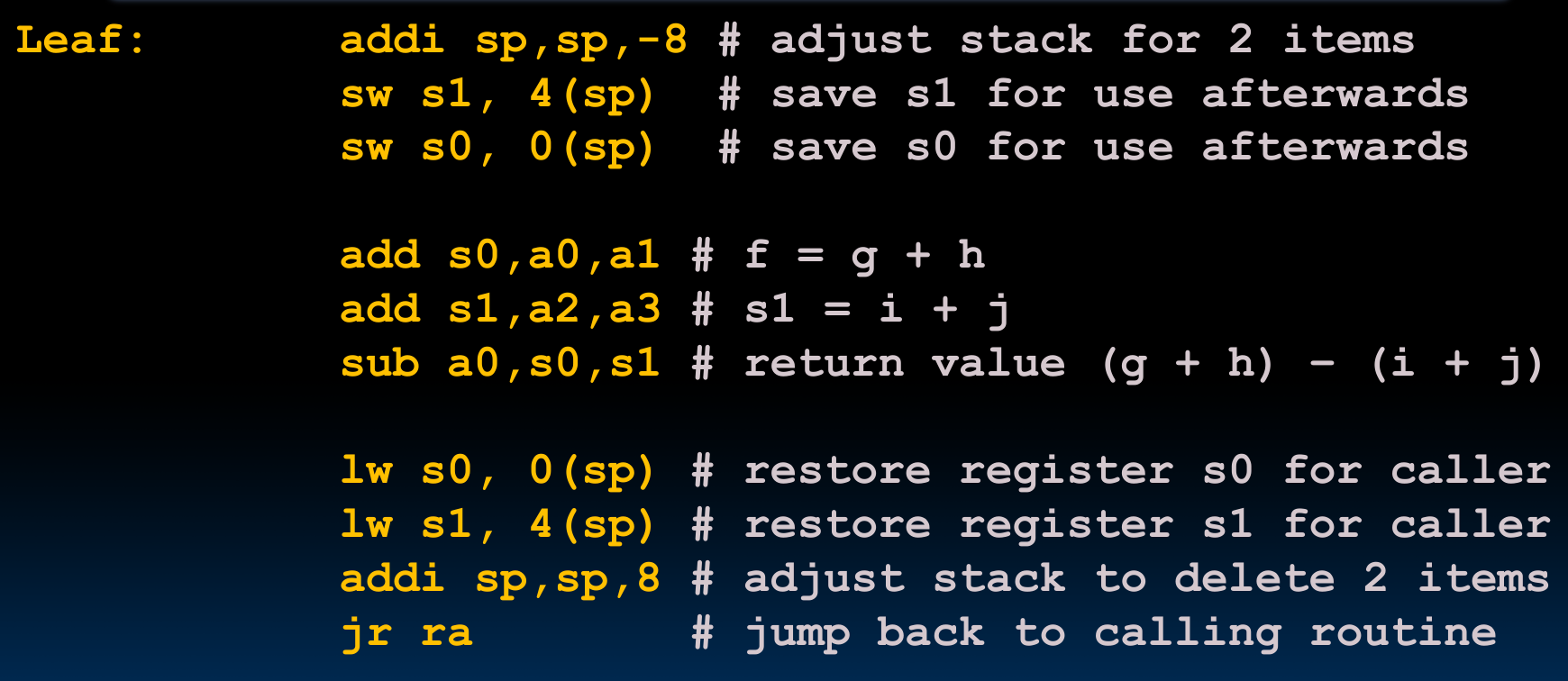
可以看到,在函数最开始我们调整栈顶指针的位置,开辟新的栈空间,同时将寄存器s0,s1存入刚开辟的栈空间内。在程序结束之后,恢复寄存器的内容,并释放栈空间。这前后两段操作分别被称为prologue与epilogue。
那么问题来了,如果我们面对的是嵌套函数调用,怎么办?哪些寄存器里的内容应当暂时被放到栈内保存?(因为要考虑用于存储函数参数与函数返回地址的寄存器的内容了)
int sumSquare(int x, int y) {
return mult(x,x)+ y;
}
一个与嵌套函数调用相关的是在RISC-V中使用递归,我写了一个递归版本的斐波那契,在我的Github仓库中。在课程提供的lab3中,也有几个递归调用的例子。
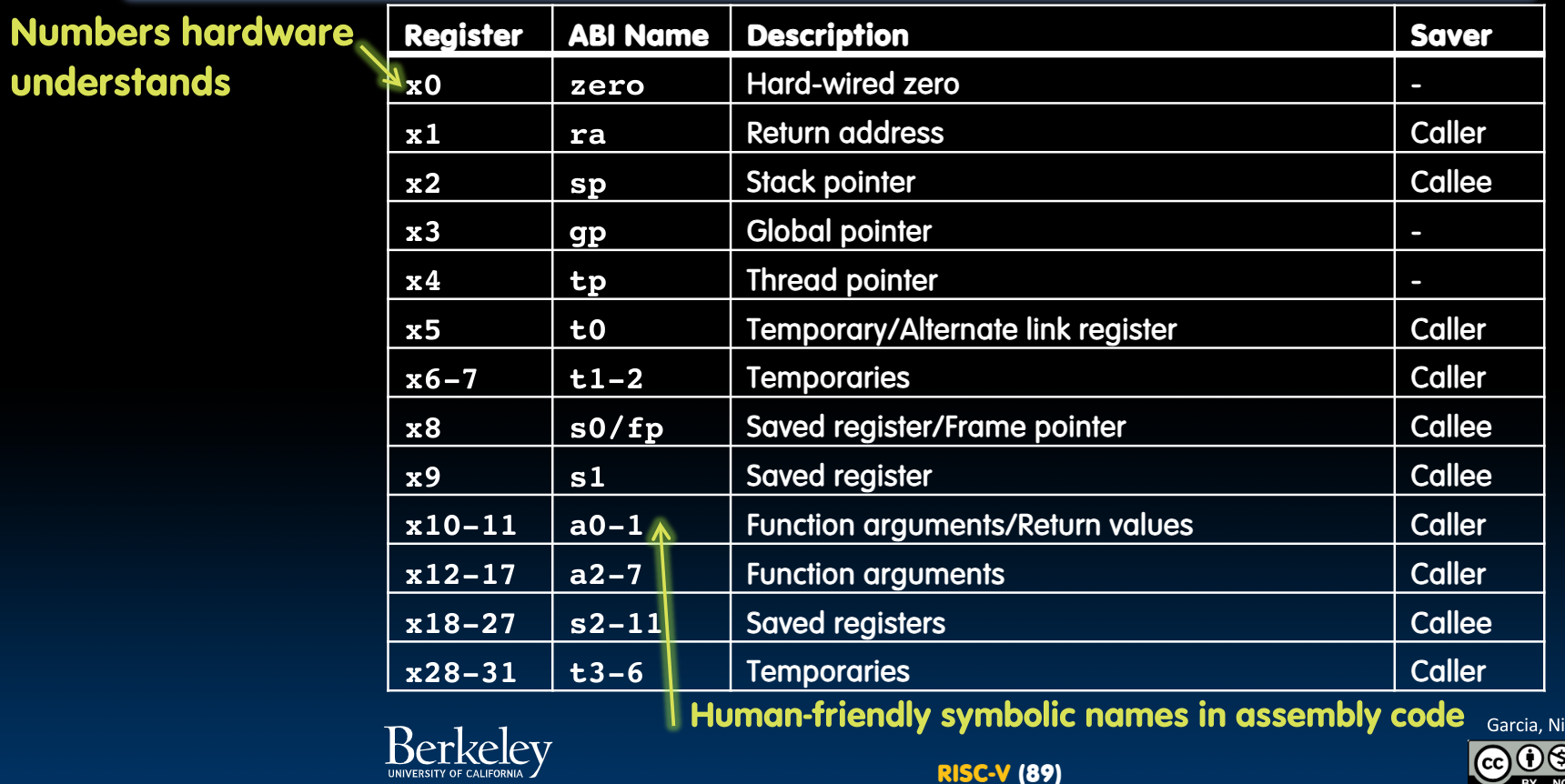
Register Conventions
区分caller与callee:

caller表示调用函数的那个“人”,callee表示被调用的函数。根据register convention,我们将寄存器分为这两大类:

对于第一类,caller假定这几个寄存器中的内容在函数调用的过程中不会发生改变–所以如果内容有改变,那这是callee应该负责的事情;
而与之相对应地,caller不能够认为第二类寄存器里的内容在函数调用的过程中不发生改变–所以如果内容需要改变,caller应当首先把这些个寄存器中的内容push到栈中。
Memory Allocation
一个问题,如果寄存器的空间不够储存一个局部变量咋办?
使用栈解决问题!
Procedure frame or activation record: segment of stack with saved registers and local variables.
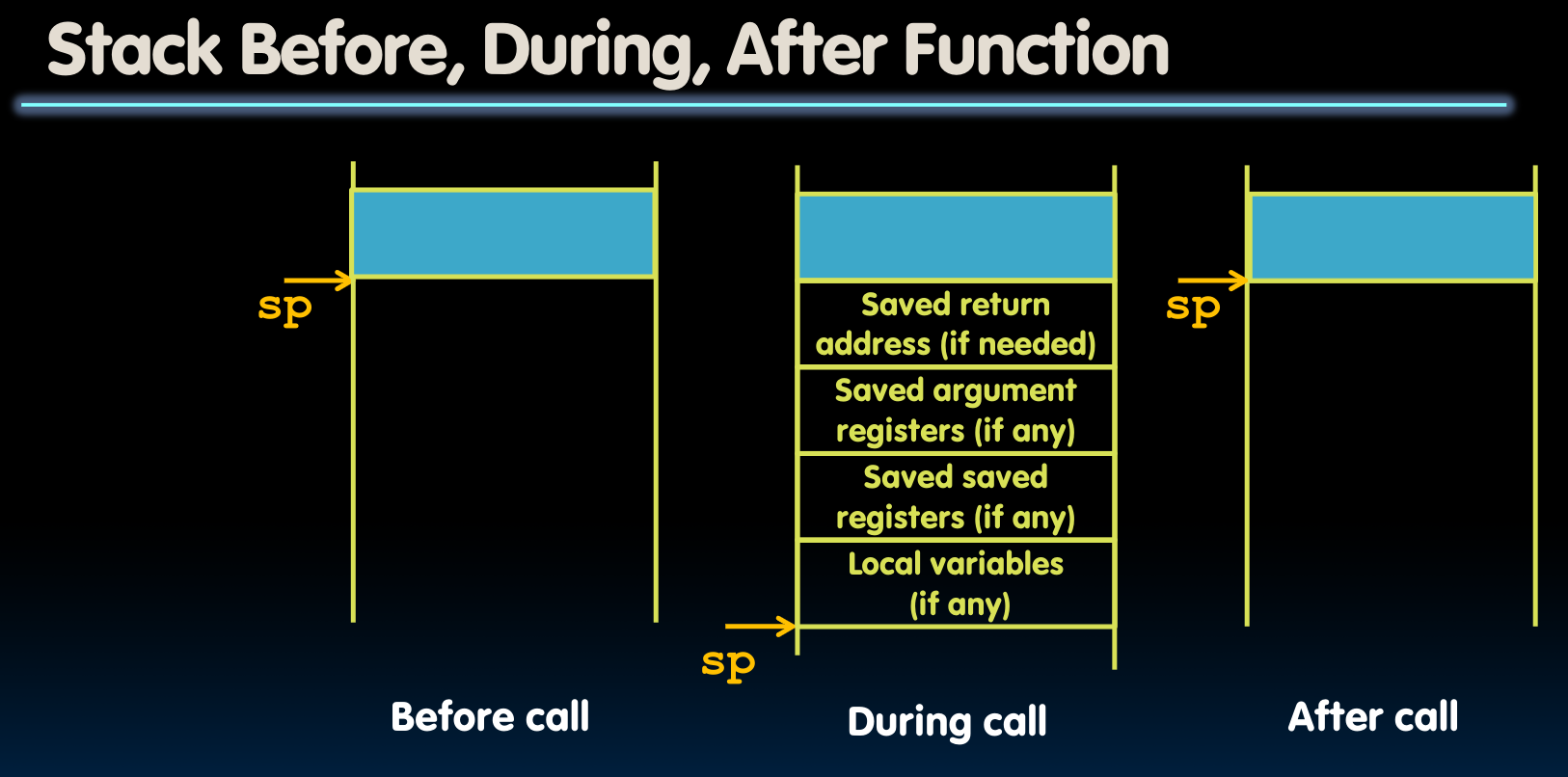
当我们想在栈内分配新空间时,就将栈指针减去需要的内存大小!
所以,对于之前的嵌套函数调用,RISC-V代码如下(包含了push与pop的过程):

代码也符合上图我们Procedure frame中分配的顺序:首先储存ra,之后储存a1,即函数参数。在函数调用结束后,pop栈内存,恢复寄存器内容。
在调用SumSquare之前,我们要先把它需要的两个参数储存到正确的寄存器-a0 & a1中,之后我们使用上边的代码调用该函数–因为需要嵌套函数调用,我们要开辟一个栈空间来存储可能改变的寄存器。接下来,我们开始对内部函数的调用做些准备–比如把参数存放到指定的寄存器里。
在调用函数结束之后,恢复栈内存与寄存器内容,并把控制权转移给上一级函数(jr ra).
我们不要把jal指令默认成函数调用的唯一方式,我们之所以使用jal来调用函数,是因为函数的调用通常通过给入一个label的方式来实现(在内部其实是通过程序自动计算
PC-relative offset来完成指定函数调用)。但是,jalr其实也是可以调用函数的,他调用函数的方式一般是通过
absolute address而不是PC-relative address实现。我们把一个地址存放到某个寄存器中,然后把它交给jalr指令。
Stack/Heap/Static/Code
这里列出他们在RISC-V32中的储存位置:
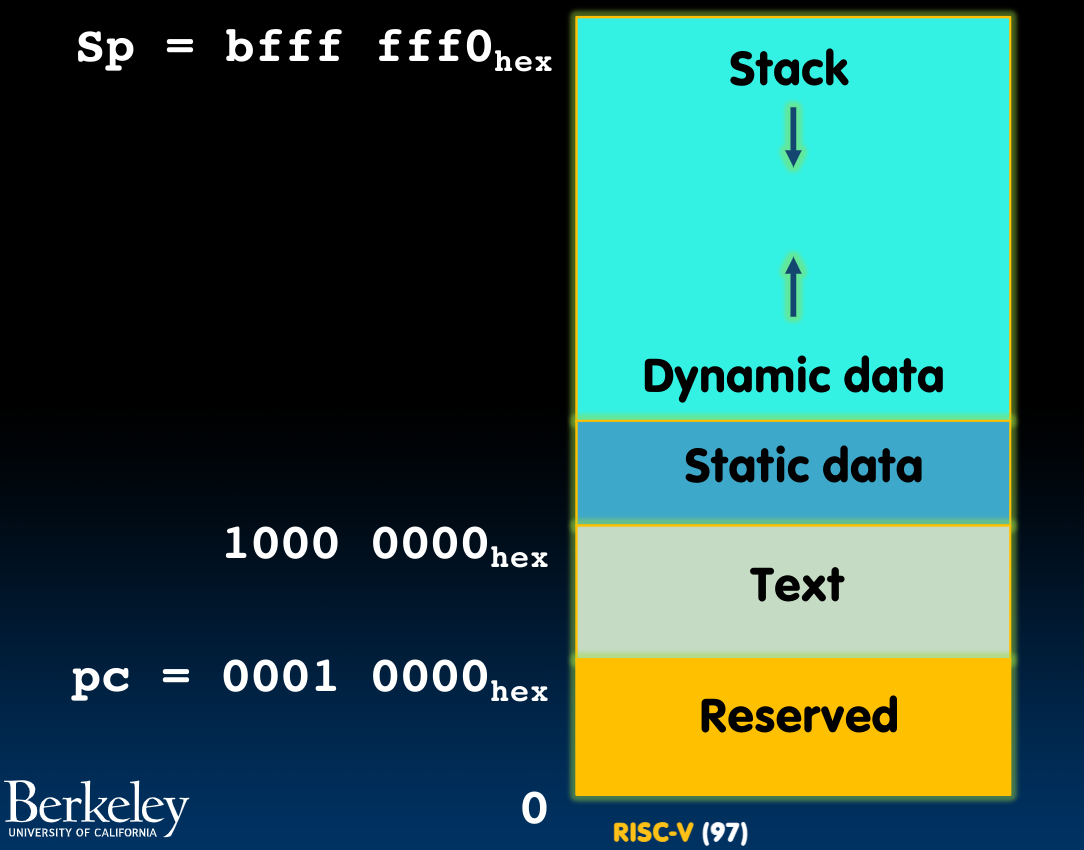
- PC段存储了系统运行的关键信息
- Stack must be aligned on 16-byte boundary here
- RISC-V convention global pointer (gp) points to static
Instruction formats
现在需要解决的问题是,机器是如何理解我们写出的汇编代码的?或者说,前边所述的这些汇编代码对应的二进制表示是什么?

- Everything Has a Memory Address
在介绍他们的二进制表示之前,我们首先要清楚,这些指令(Instruction)是如何被机器执行的。我们知道,无论是指令还是数据,都是存放在内存(memory)区域的,并对应着不同的地址(address)。而前边我们提到过,需要执行的指令的地址是保存在**PC(Program Counter)**中的:
- Basically a pointer to memory
- Intel calls it Instruction Pointer (IP)
我们正是通过不断更新PC的值,来告诉机器我们将要执行的指令在哪里。
- Binary Compatibility
另一方面,由于产品需要不断的更新迭代,当时我们不想在每一次更新迭代产品之后都需要重新为原本的软件和应用准备一套新的二进制代码表示,或者说我们想要在新的机器上运行旧的程序,这就需要指令集具备backward-compatible的特征。
在正式开始介绍之前,我们需要知道:无论是RV32,RV64还是RV128,他们使用的都是32-bit的指令集。
Different Instruction formats
为了让机器明白我们的汇编代码包含哪些信息,需要执行哪些功能,我们将这个32-bit的指令分成了很多个field.
根据field被划分的不同的格式,指令被分为如下六种:
- R-format for register-register arithmetic operations
- I-format for register-immediate arithmetic operations and loads
- S-format for stores
- B-format for branches (minor variant of S-format)
- U-format for 20-bit upper immediate instructions
- J-format for jumps (minor variant of U-format)

观察上图我们可以发现,所有需要的寄存器或者是立即数,基本都被存放在同一段位置,这是为了方便电脑进行查找与运算。正是为了这一特性,可以看到,可能一个立即数被分成了几段来存放。
- 其中,
opcode指定了这几个不同的指令类型–在同一类指令中,它们将永远一样。 - 由于我们总共有32个寄存器,所以我们需要使用5 bits来表示使用的寄存器。
funct帮助我们确定同一类指令中的具体指令。
R-Format


slt: set-less-than (
rd = (rs1 < rs2) ? 1 : 0)
同时我们注意到,在R-Format中的funct7段,指令sub与sra的次高位是1–这表示,它们的操作需要进行sign extension.
I-Format
之所以要单独出现一个立即数格式,是因为汇编指令在将立即数指令转化为二进制代码时,是需要将立即数编入二进制代码的。而如果我们直接将R-Format中的rd段作为立即数使用,很明显,我们只能表示一个极为有限的立即数范围。所以我们需要一种新的指令格式。

需要注意的是,立即数被在算术运算中使用时,需要sign-extend到32 bits.
另一方面,由于这里用于表示具体指令的段只有funct3这一个,而我们总共需要表示9种I-Format指令,我们需要使用一种特殊技巧:

因为对于32位寄存器而言,我们再进行移位操作时最多移动$$2^5$$位,所以我们不需要使用12位来表示这里的立即数,从而,如同R-Format所述,我们可以利用次高位表示是否进行sign-extend.
Loads(also I-type)

12位的立即数(offset)被加到base register,rs1中存储的地址中,得到新的地址,并放入dest register内。

需要注意的是,load指令的opcode与i-type中的不同。在这里,我们引入了一个新的指令lh与lhu,传入一个2 bytes的数据,之后将其(un)sign extend到32 bits.
S-Format
这种指令格式是给存储指令设计的:

在格式上类似于R-Format,但是存储指令不向寄存器内部写数据,而是像内存写数据。这种将立即数分段设计的原因我们在先前提到过,是为了保证机器查找寄存器未知的方便。
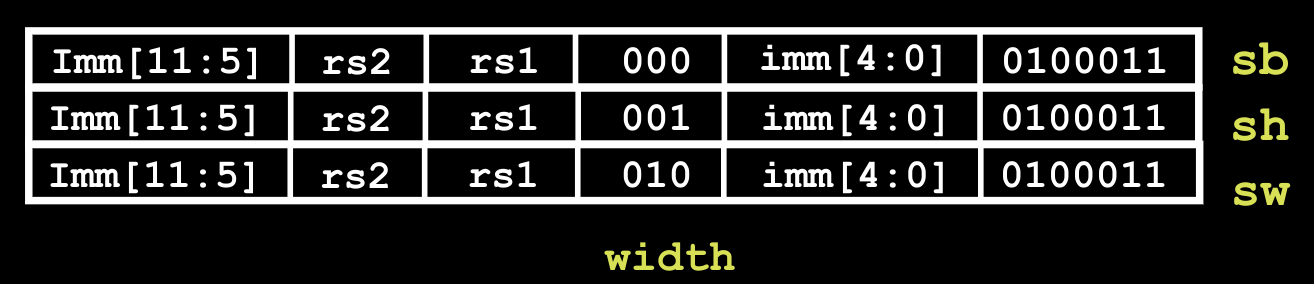
B-Format
这种格式应用于条件跳转指令。branches常被用于循环中(while, for, if-else).这一类循环通常间隔的指令较少,如果我们需要跳转到一个很远的地方,那么此时我们可能需要jump instructions(J-Format).
而由于指令的地址被存放在Program Counter中,我们可以使用PC-Relative Addressing的方法来实现指令的跳转,我们使用立即数实现这一操作,由于立即数共有12位可供使用,所以范围为$$\pm 2^{11}$$-unit:

需要特别注意的是,我们在这里使用的跳转单位并不是byte,因为一条指令的大小是4 bytes,这样做我们会跳转到指令的中间位置,无任何意义。
但同时我们要考虑的一点是,存在一种Compressed Instructions,他的每条指令的大小是16 bits,一般使用在廉价微型电子产品中。为了与这种压缩指令集相兼容,我们将跳转单位设定为2 bytes,而非4 bytes:

所以我们可以跳转的总的相对地址范围是$$\pm 2^{11}\times 16$$-bit也即$$\pm 2^{10}\times 32$$-bit.
所以,对于Program Counter来说:
- Don’t take the branch:
$$PC = PC + 4$$
- Take the branch
$$PC = PC + imm*2$$

在这种表示方法中,我们虽然只有12位立即数空间表示,但是却可以表示13位的signed bit offsets,原因是每次跳转的最小单位是2 bytes,所以地址一定是偶数(even)!也就是说,最低一位一定是0.也正是基于这个原因,我们无须储存这个最低位。
Immediate Encoding
前边提到过,所有的立即数(Immediate)在进行算术运算时,都会被sign extend到32 bits:
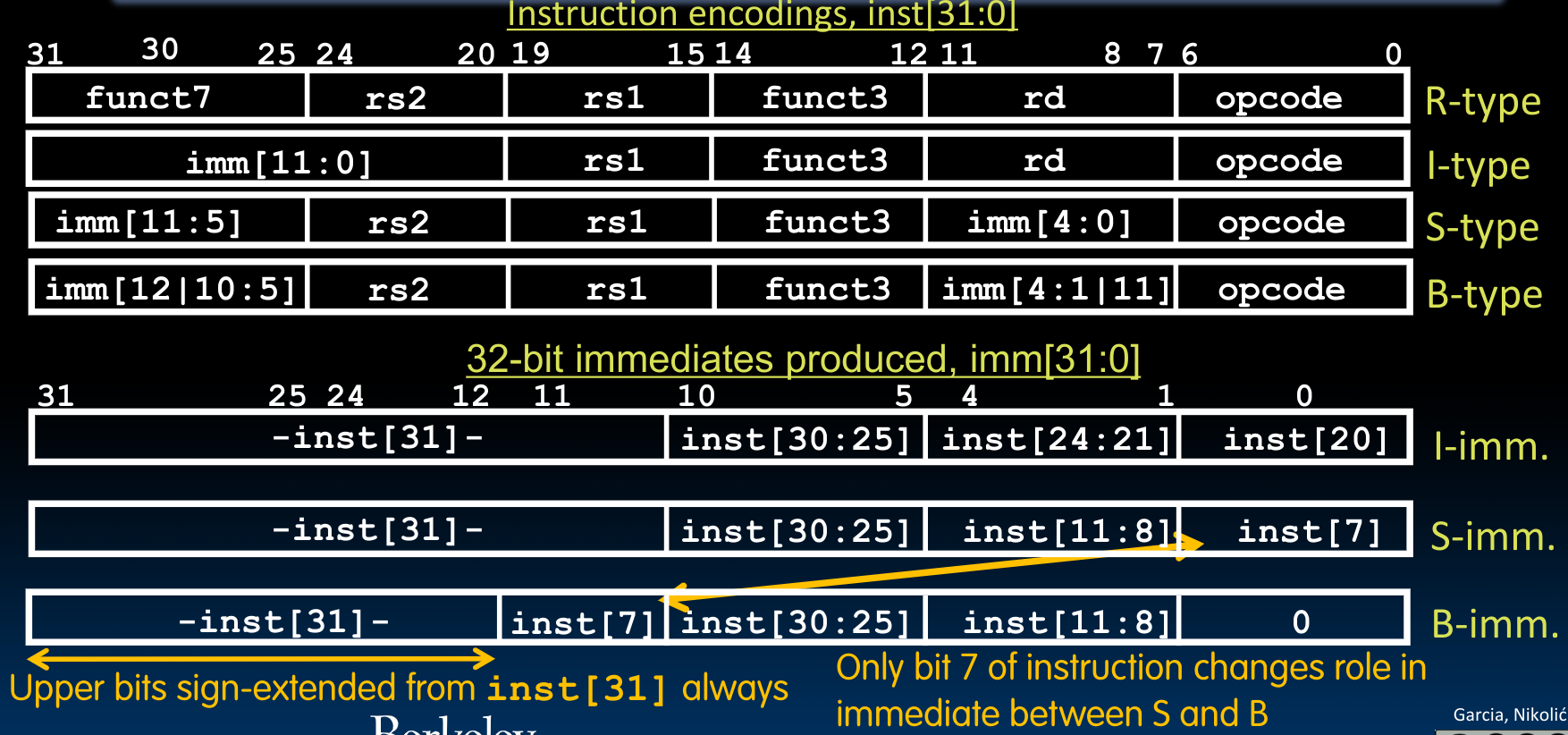
可以看到,这些格式中一致的立即数存储位置,这对提高存储器的处理速度很有帮助。

U-Format(long immediates)
现在的问题是,如果需要跳转的指令距离我们大于$$2^{10}$$条指令咋办?于是我们有U-Format,用于处理高20位的立即数数据:
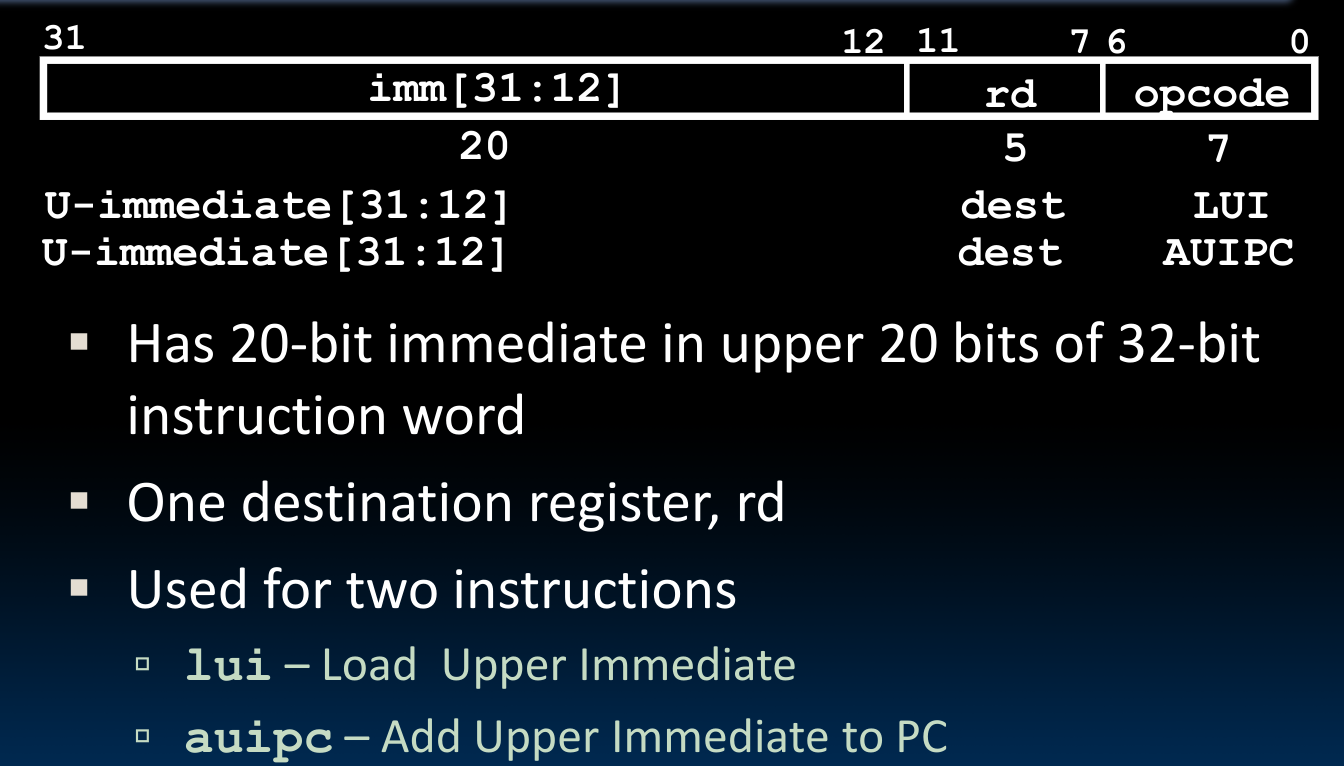
我们当然可以把高位立即数处理与低位立即数处理结合起来使用:




J-Format

我们所使用的**jal rd offset指令,就是遵循了J-Format**:

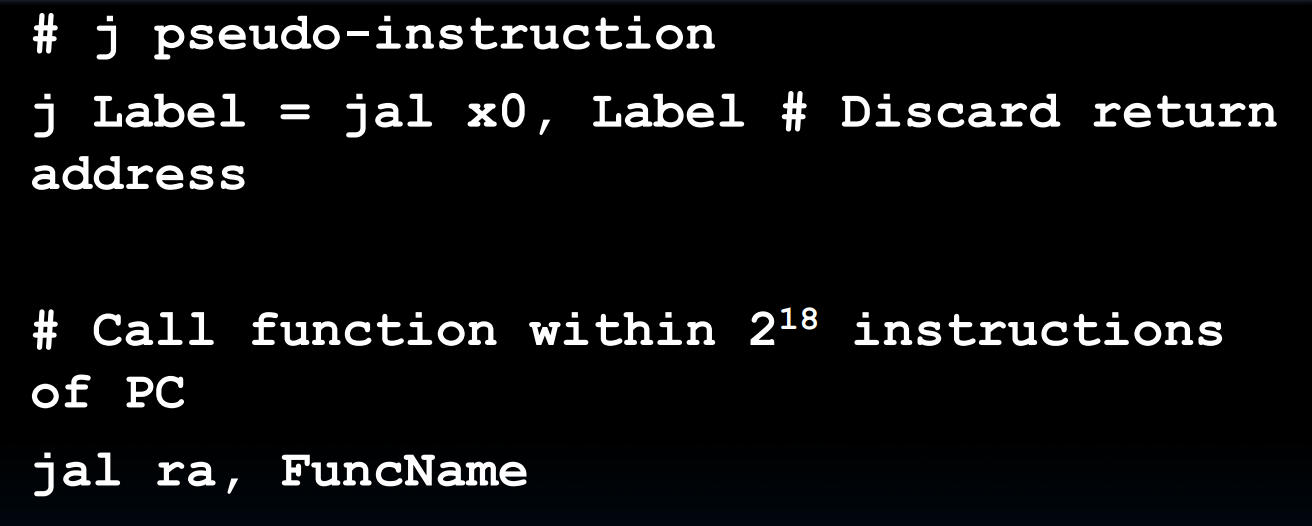
我们注意到,指令jal/j只能最多只能允许我们使用一个20位的立即数来进行指令跳转,如果我们需要更远的跳转距离,比如我们就是需要32位的立即数,那么我们需要分为两个部分写入跳转地址需要借助指令**jalr rd, rs, imm**来实现:
指令jalr:

很明显,指令jalr是jal的“对立”指令,因为它允许我们使用32-20=12位的立即数偏移跳转–如此一来,如果我们切实需要上述情况,即跳转到一个更远的地址(需要一个更大的偏移量),那么我们可以考虑将其分为upper imm与lower imm两部分两条指令处理:
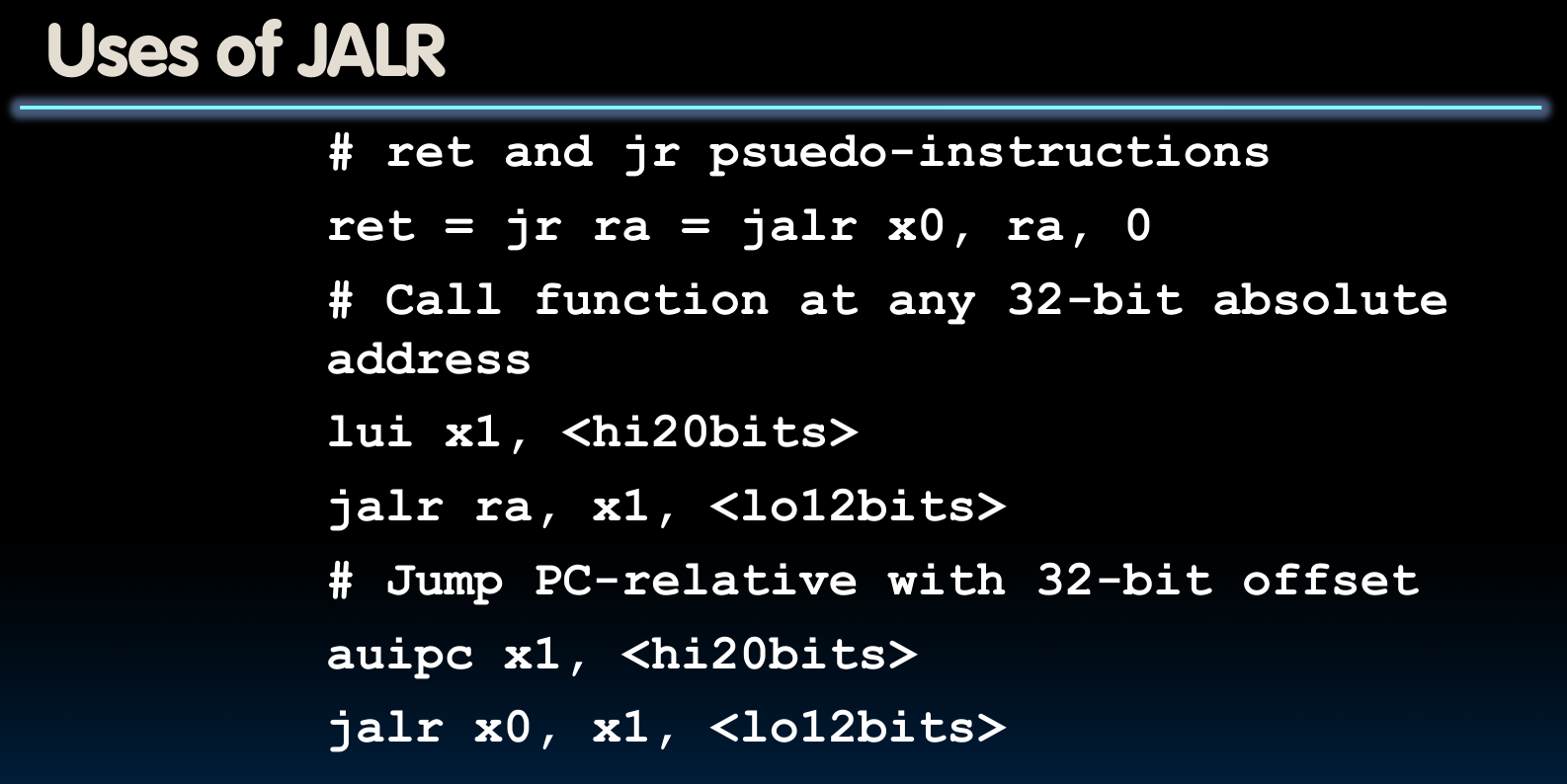
而RISC-V也提供了相关的pseudo-instruction:

有趣的是,在上述的使用方法中我们可以看到,虽然jalr的使用方法是利用absolute address操作,即直接设置地址值来决定下一步去哪里;我们也可以通过结合PC并给入offset的方式,进行类似PC-Relative的跳转操作(但还是借助于绝对地址的值)。
Tail Call Optimization?
在CS 61A中,我们学习过Tail Call Optimization的相关知识,比如如下的语句就是一个尾调用(Tail Call):
{
// lots of code
return foo(y);
}
而尾调用优化,一般对于递归调用会有比较明显的提升效果:比如对于如上的代码,按照一般的递归调用流程,当前层函数的函数栈会一直存在,程序会在内存中不断建立新的函数栈,而直到这些递归调用的函数一层一层返回后,才会将原本开辟的函数栈一个一个的释放掉。
而Tail Call Optimization允许我们在进入下一层函数调用的时候,就把当前层的函数栈释放掉,具体从指令集角度而言:
- Evaluate the arguments for
foo()and place them ina0-a7 - Restore
ra, all callee saved registers, andsp - Then call
foo()with j or tail
如此一来,当我们最终完成了所有的递归调用之后,程序就会直接返回到最开始的位置,或者说最终应当返回以继续程序运行的位置。
所以由此我们也知道,这种形式的递归调用是不能够做优化的!因为我们还需要在当前层函数栈中的变量:
{
// lots of code
return n * foo(n - 1);
}
CALL (Running a Program)
这部分写入先前的有关C/C++文件编译执行过程的博文中(CS基础课程2)。
Introduction to Synchronous Digital Systems
- Switches
- Transistors
- Signals & Waveforms
处理器的硬件部分就是一个同步数字系统。所谓同步,即所有的操作都是由一个内部的中心时钟协同完成的。而“数字”表示所有的值都是离散的。电信号被表示为1与0.
- Switches
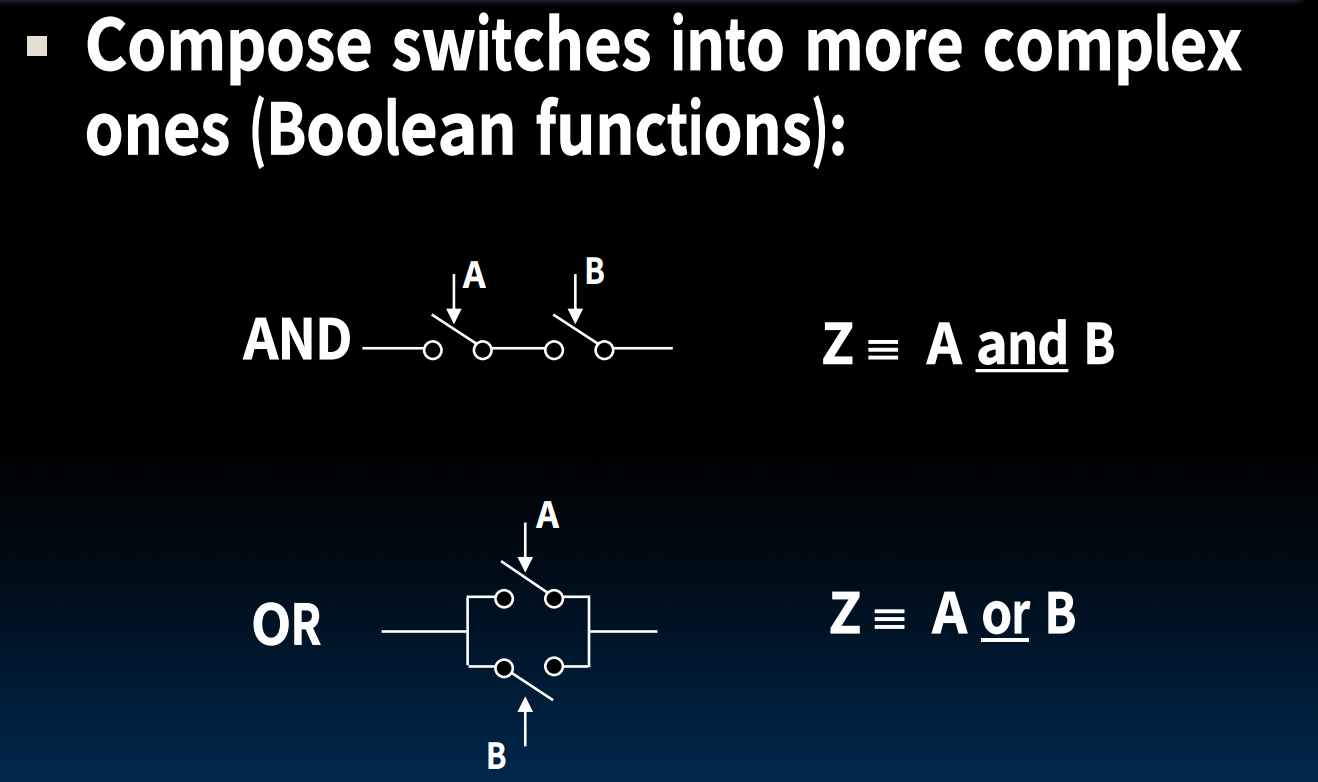
- Transistors
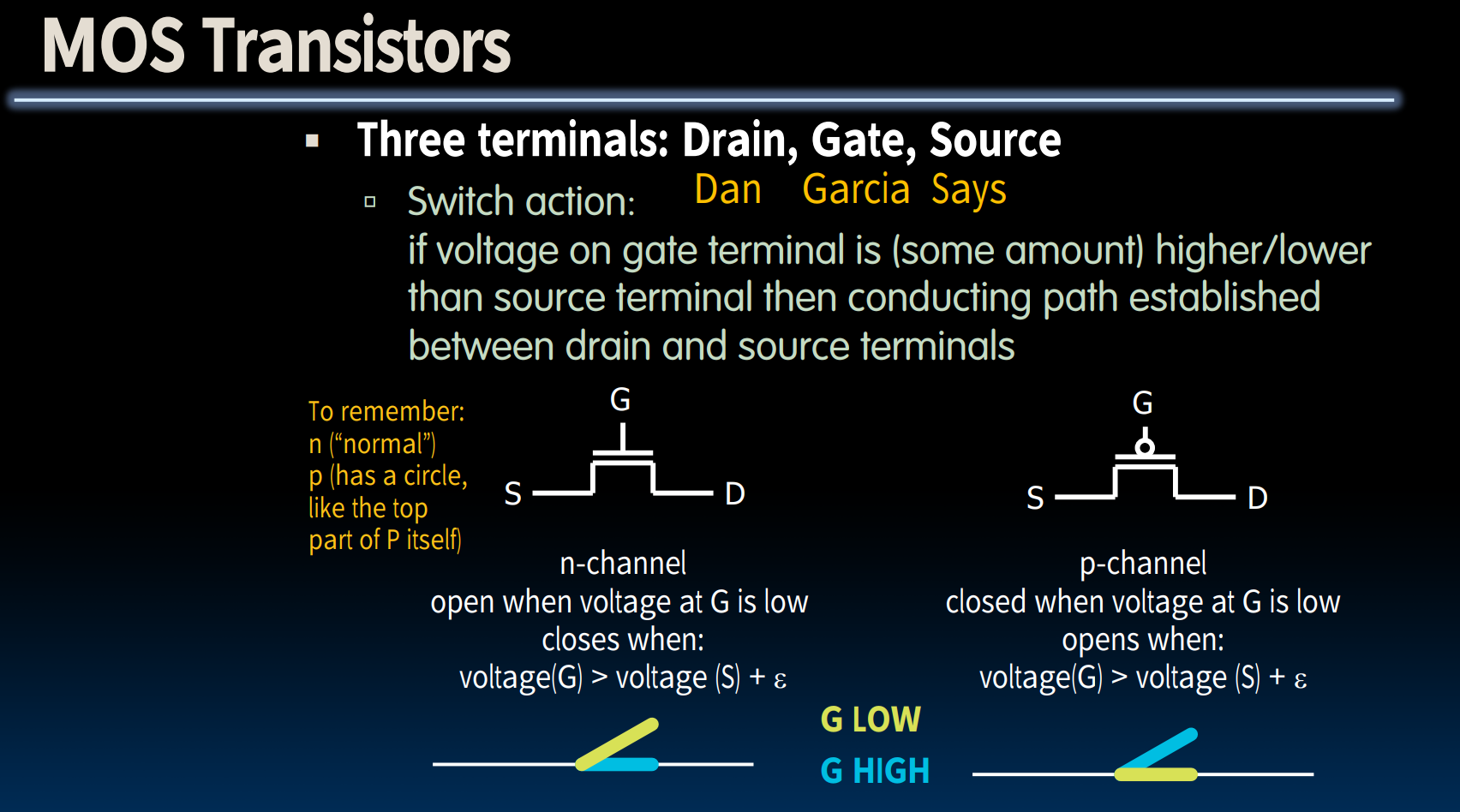

- Clocks

Type of Circuits

State (machines) & Combinational Logic
本章节内容在课程主页提供的几个notes(sds,state,boolean,block)中有详尽的描述,我将其上传到自己的图床中,这里不再赘述。
RISC-V Processor Design
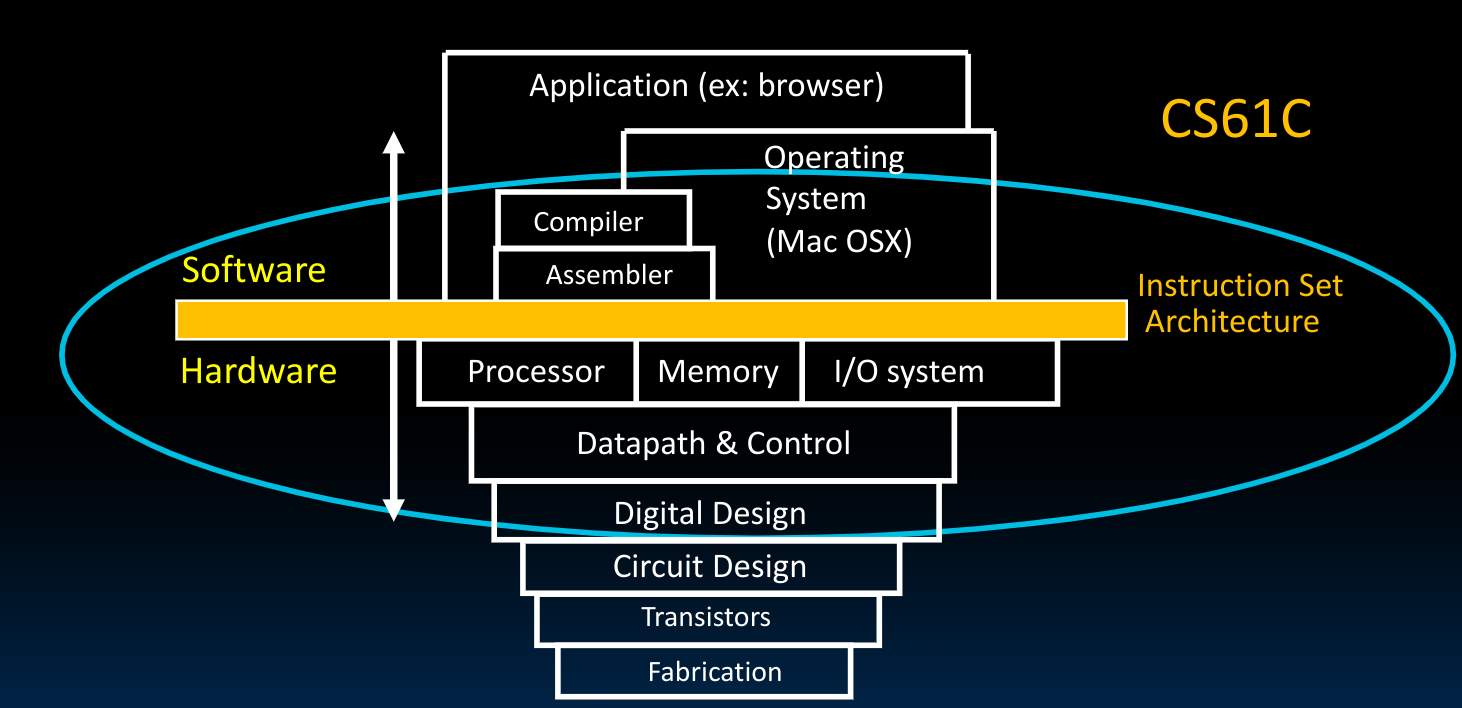
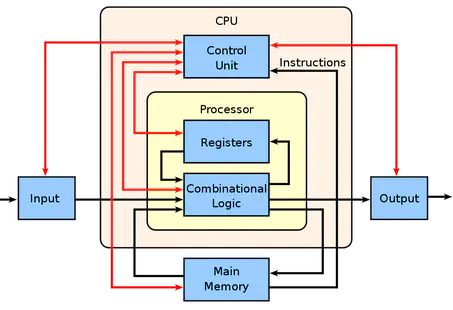
我们再来温习一下之前使用过的这张图:
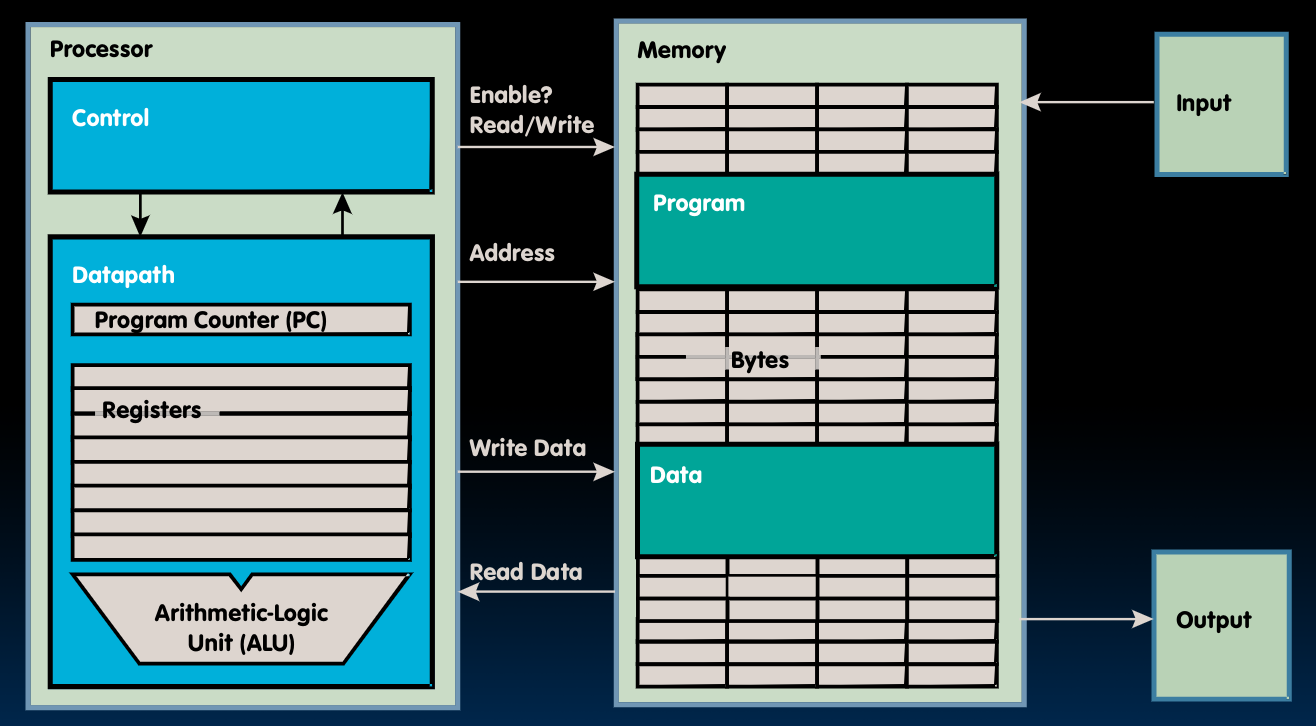
在这张图中,我们对CPU里各部分的功能做一个定义:
- Processor(CPU): the active part of the computer that does all the work (data manipulation and decision-making)
- Datapath: portion of the processor that contains hardware necessary to perform operations required by the processor (the brawn)
- Control: portion of the processor (also in hardware) that tells the datapath what needs to be done (the brain)
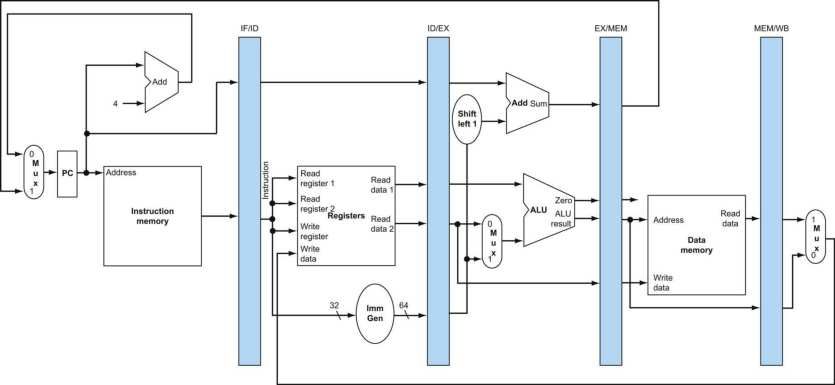
我们采用如下的设计模式来设计CPU,需要注意的是,在当前阶段,我们还采用在一个时钟周期内完成包括取出指令、执行指令等的一系列过程:
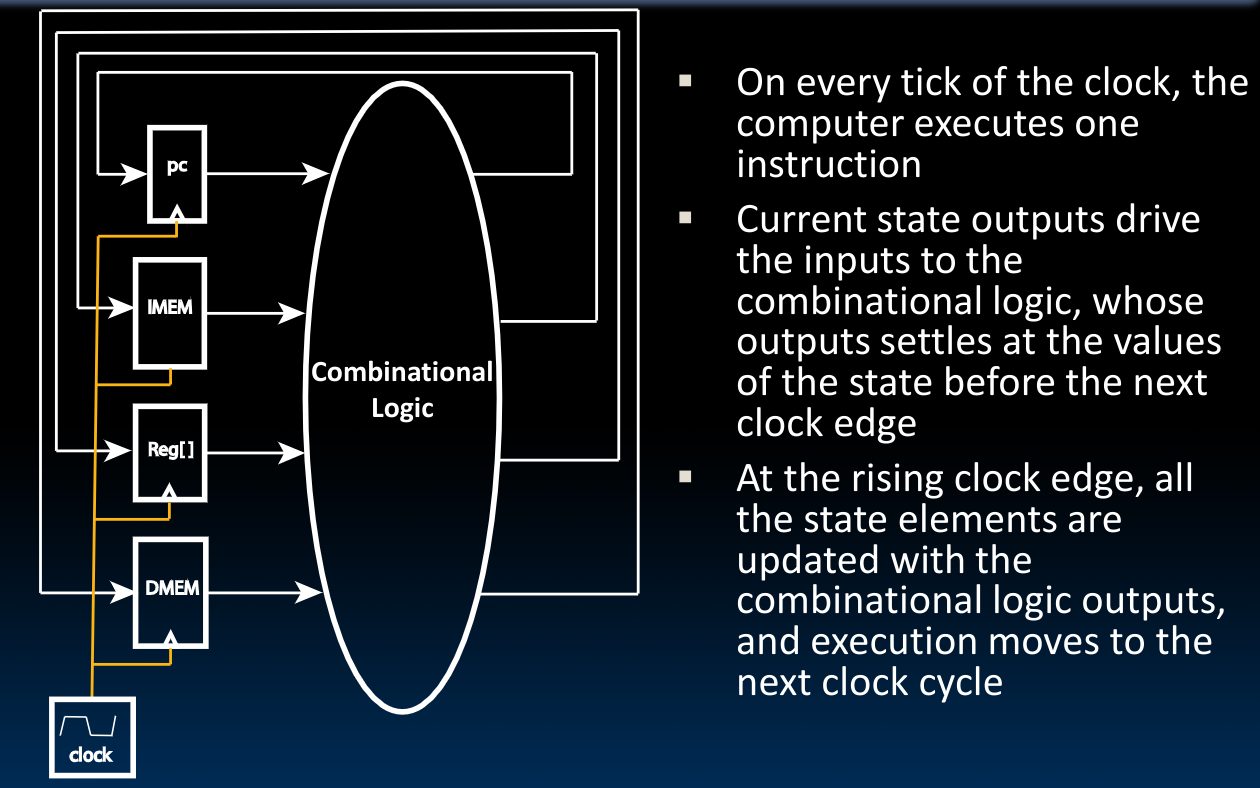
Datapath中对一个指令的操作过程可以分为五个阶段:
- Instruction Fetch (IF)
- Instruction Decode (ID)
- Execute (EX) - ALU
- Memory Access (MEM)–
lw,sw - Write Back to Register (WB)
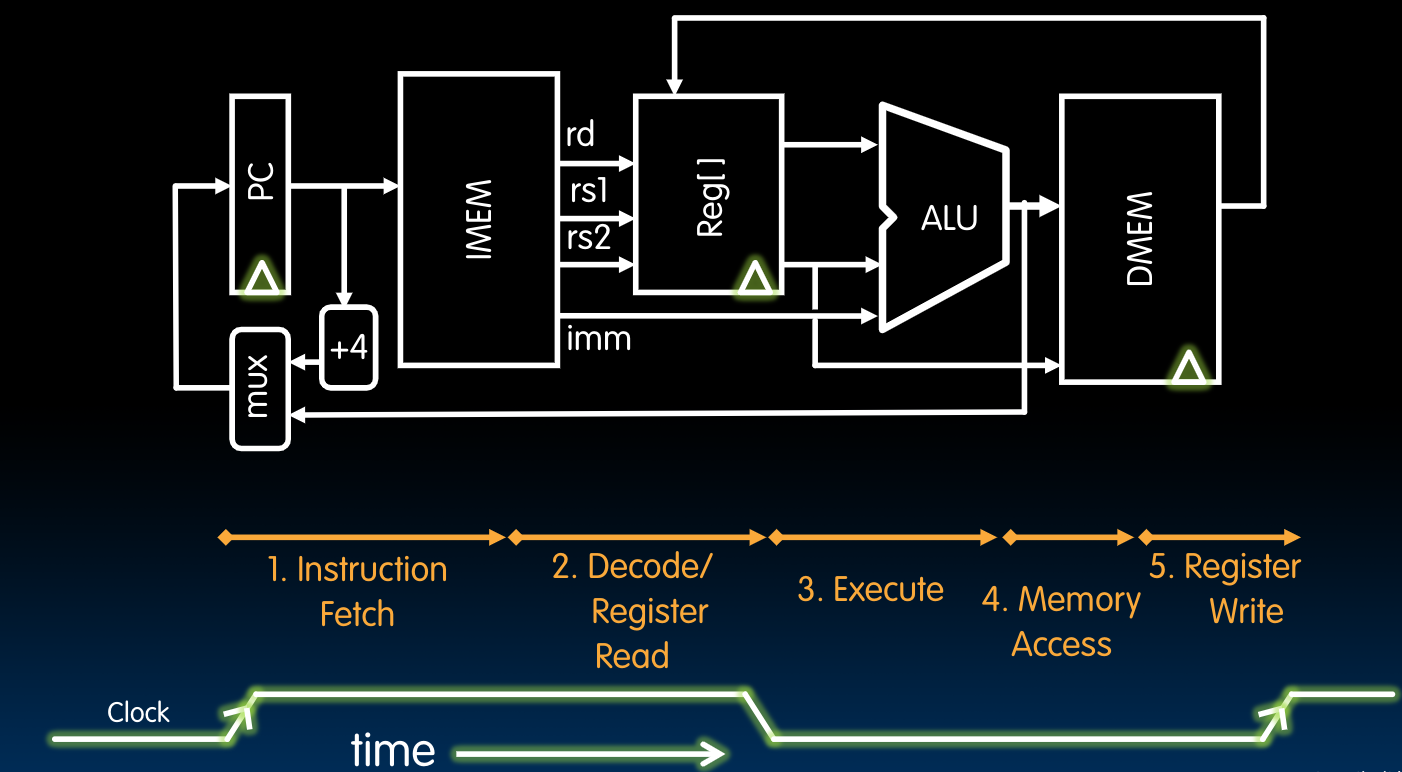
上图中包含的模块可以作如下定义:

细节见PPT.
需要注意的是,这里我们将存放指令的内存–IMEM与存放数据的内存–DMEM放在不同的位置(使用了两块内存).
接下来,我们需要根据先前介绍的不同的指令种类来决定我们所使用的Datapath构造。这里只对一些重要的结果和流程进行记录,详细参见授课PPT.
R-Type Add Datapath
首先假定我们只需要处理ADD这一个指令,那么我们的构造应当如下图所示:
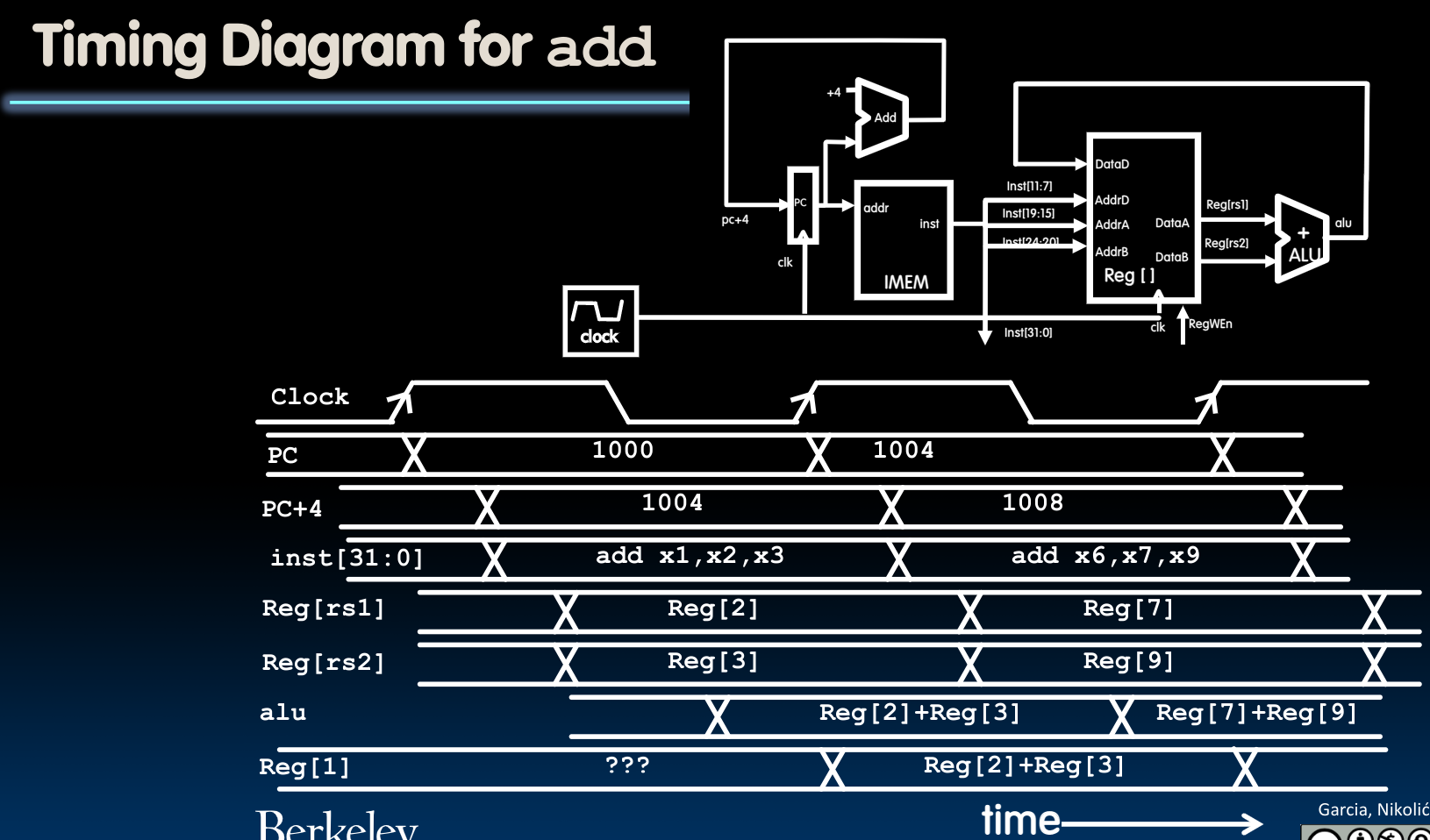
需要注意,上图中有两个操作是在第二个时钟周期的上升沿给出的:
- Program Counter中的地址+4–被存入Program counter内部
- 经过ALU计算得到的结果被写入寄存器中
而如果我们想利用上边的电路来实现SUB指令的话,我们需要对他作如下修改:
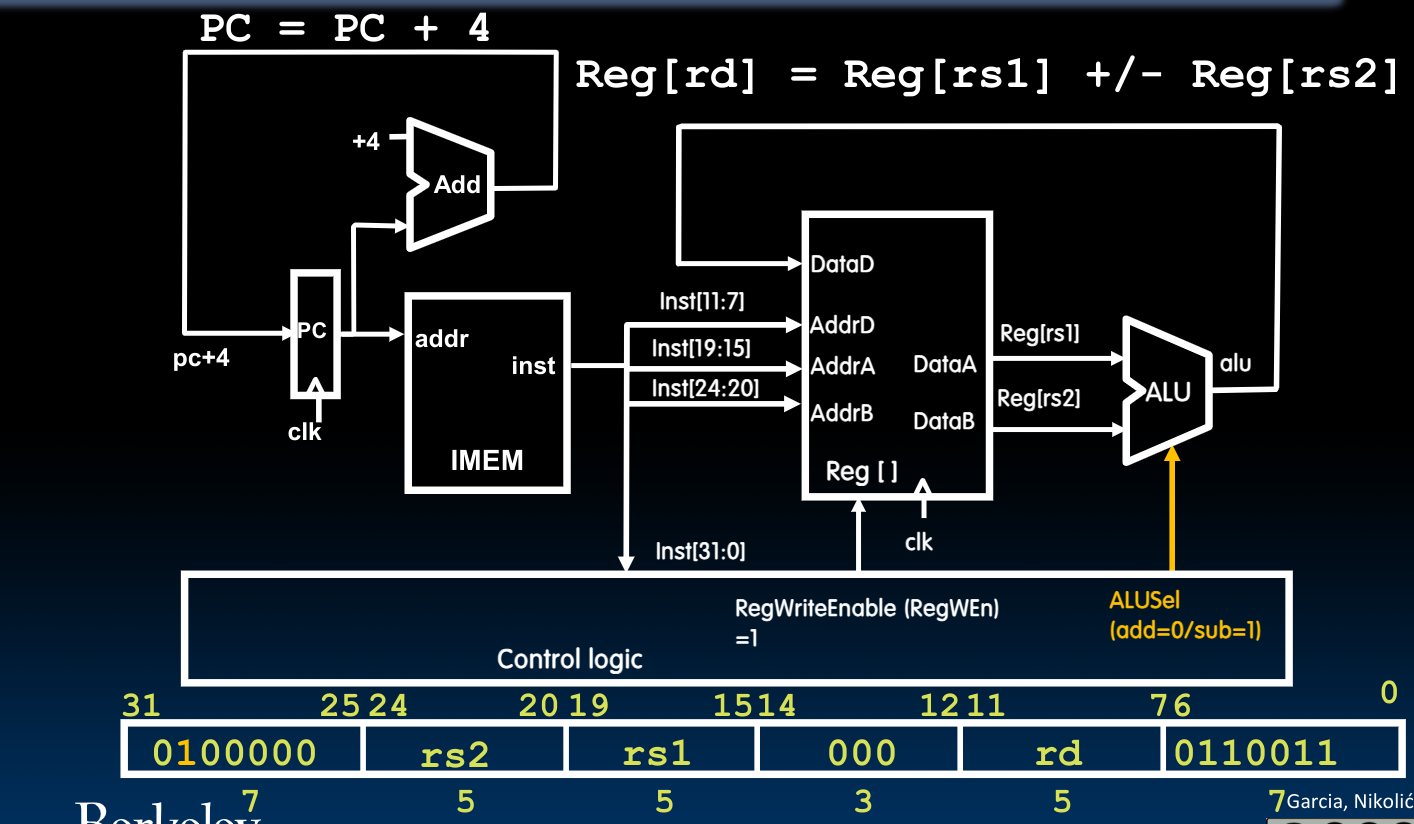
在控制单元内的0/1控制字正是根据指令中开头部分的次高位得到的。至于在ALU内部如何进行加减计算,在先前的notes(block)中已经有过详细论述。
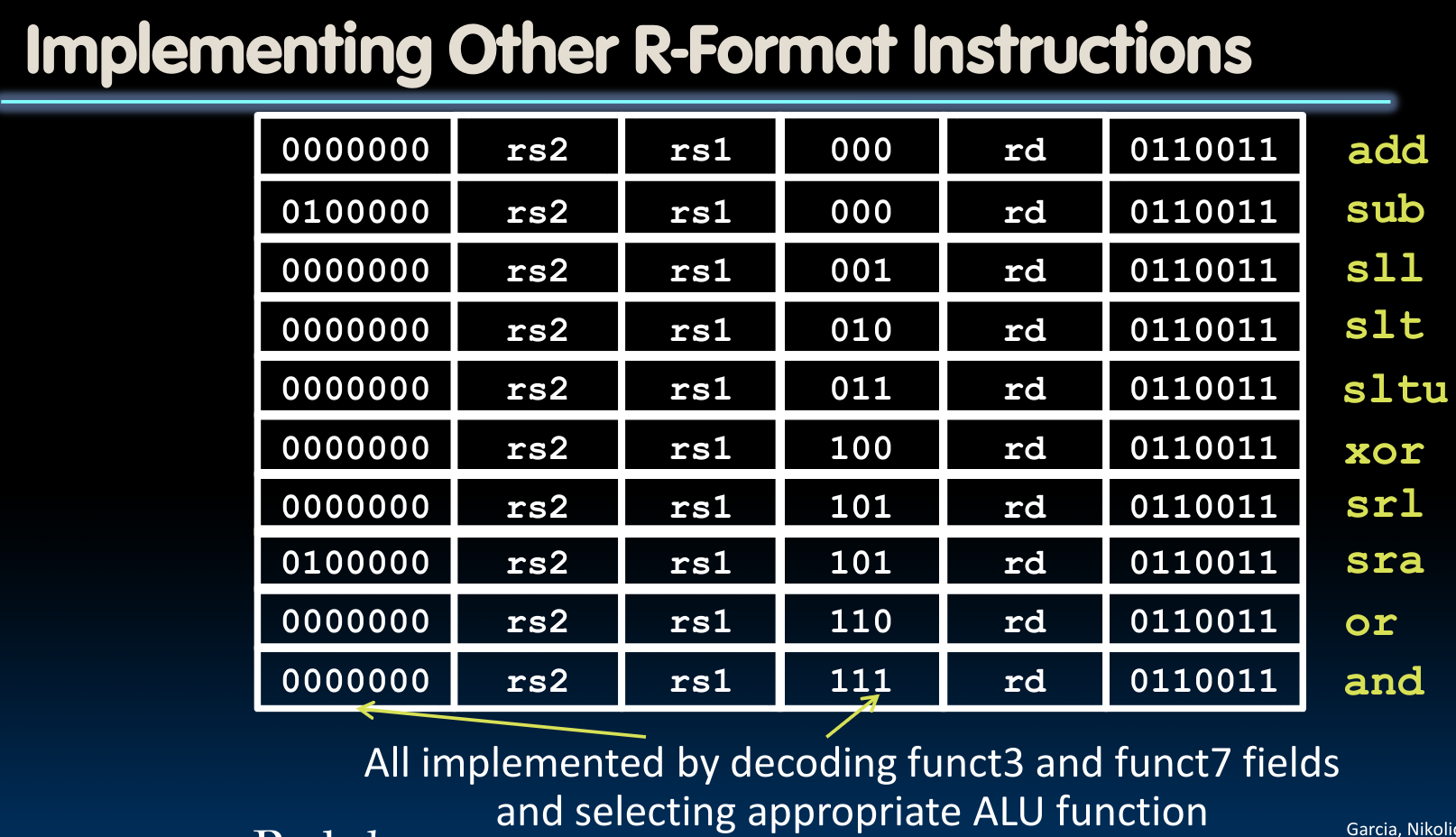
Datapath With Immediates
与R类指令所不同的是,立即数指令将第二个源寄存器改成了一个立即数,所以:
在控制单元内,我们设置了一个ImmSel,他在这里被设置为I type. 而由于在I指令里立即数只有12位,所以我们需要进行sign-extend:

与R指令系列中的其他指令的处理方法一样,我们可以通过更改控制单元内的ALUSel来决定到底使用哪一个具体的I指令计算。
对于R/I type的指令,均不需要包含第4阶段的指令操作过程,因为它们无需从DMEM中获取数据。
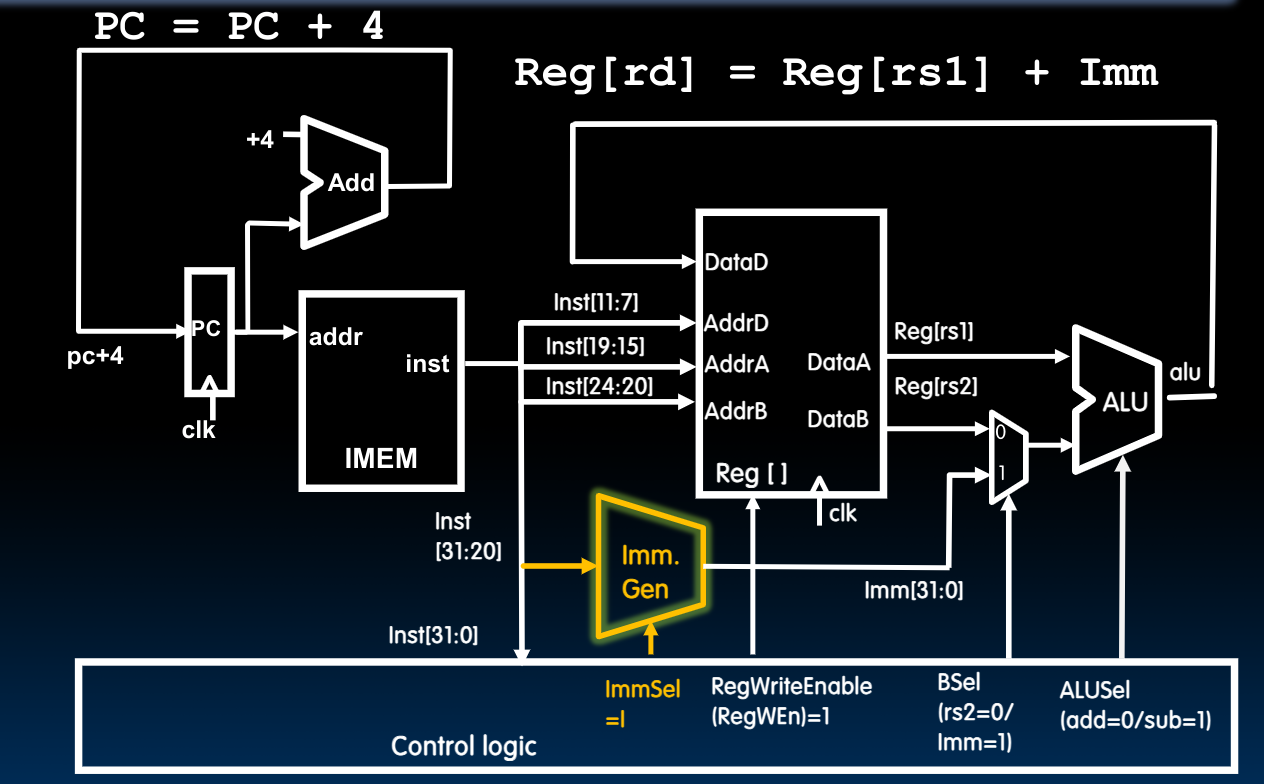
Datapath For Loads
需要注意的是,在这里控制单元通过将ALUSel设置为ADD来表示进行立即数+起始地址的计算,最终得到目的地址。
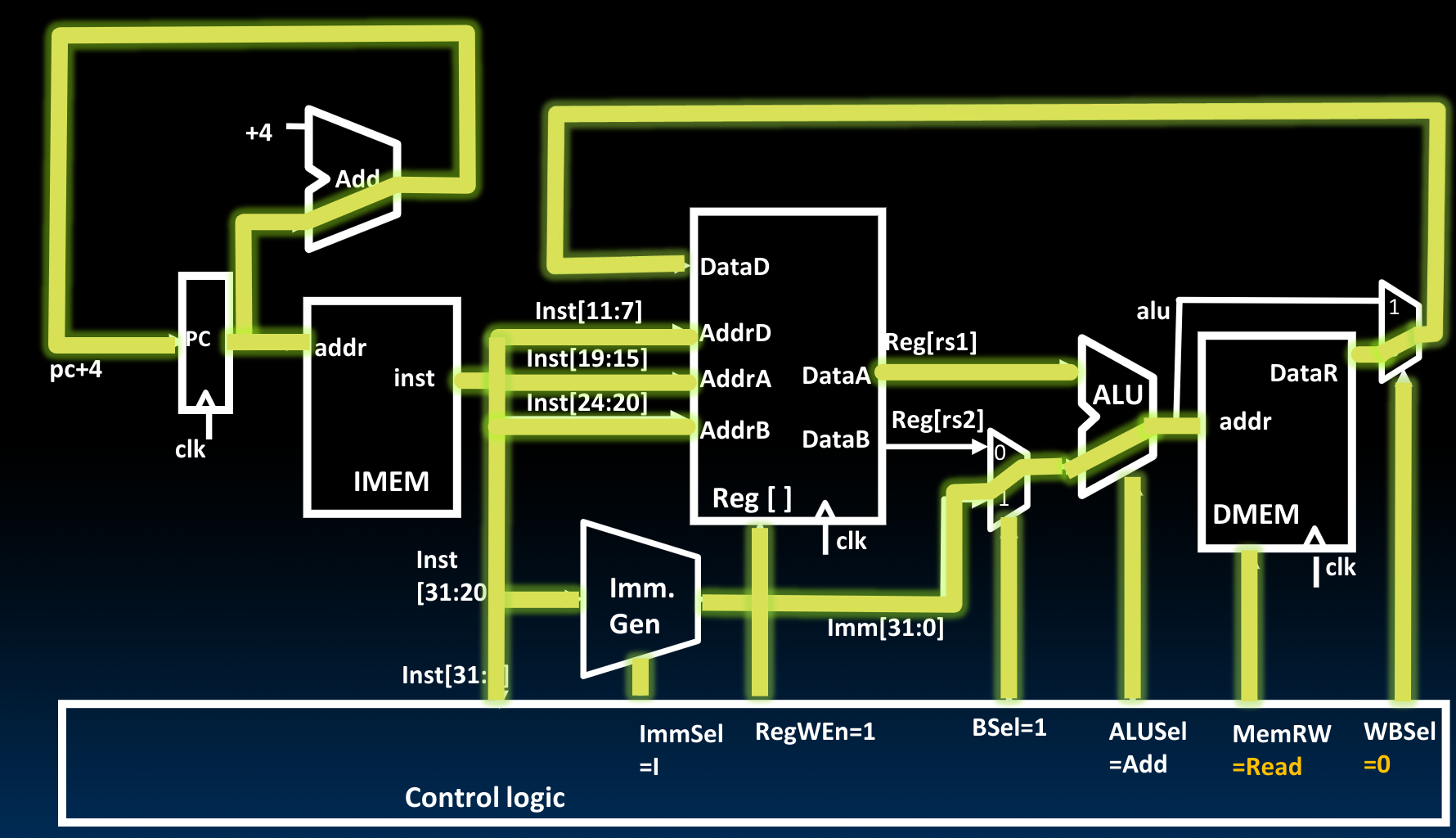
Datapath For Store
这里的DataB输出的是寄存器内的数据,我们通过将控制单元的MemRW设置为Write,表示当下一个时钟上升沿到来时,将该数据写入内存中。

为了在控制单元中同时支持I与S两种立即数表示形式,我们可以使用一个MUX,决定到底使用inst中的[11:7]还是[24:20].
Implementing Branches
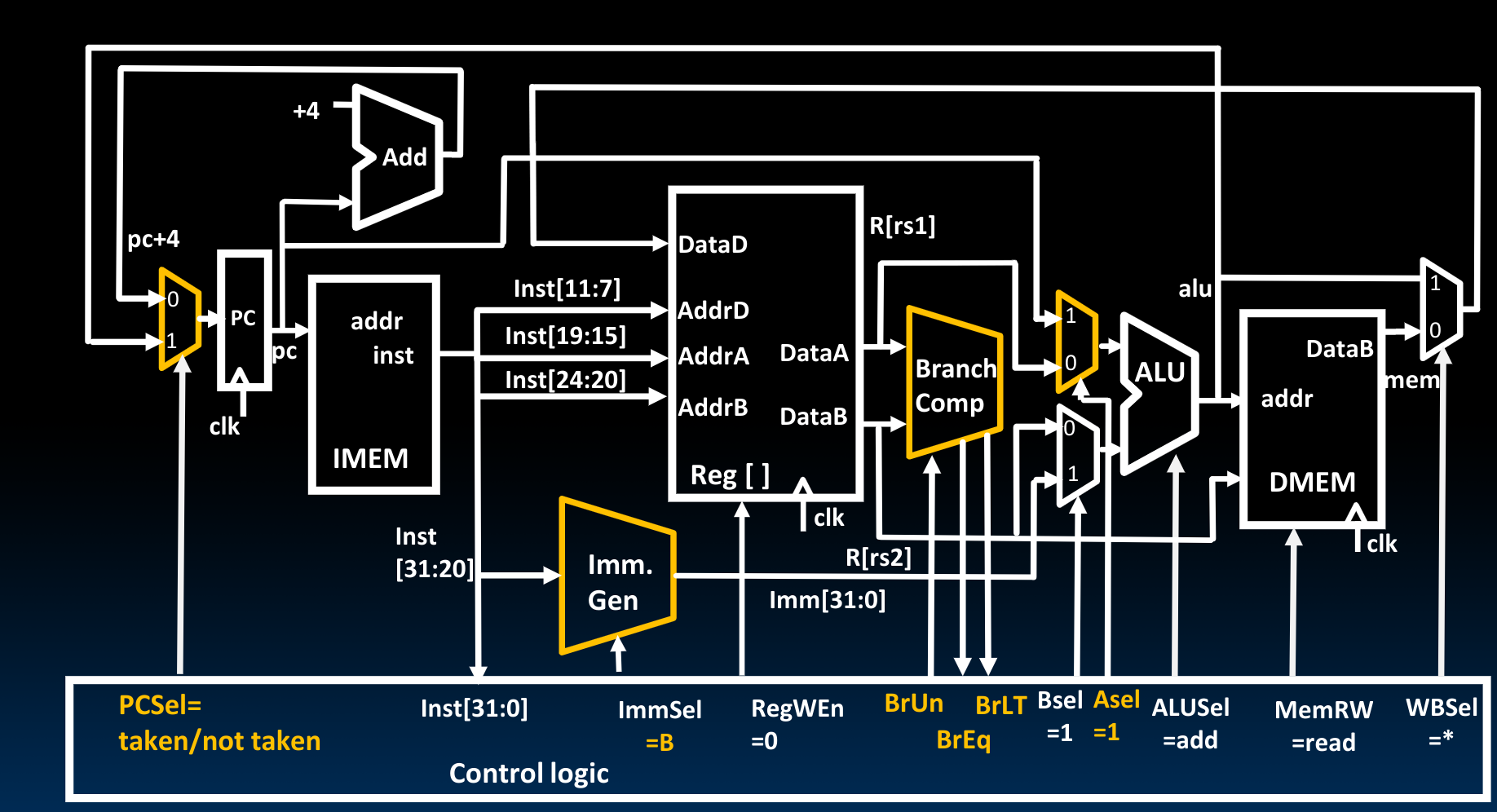
在Branch Comp的部分,我们需要输入signed/unsigned,并输出BrEq/BrLT.此时的ALU单元被用来对Program counter中的地址加上进行了sign-extend之后的立即数。最后,我们把得到的新的跳转地址放入Program counter内。
得益于RISC-V指令集设计的便利,在Imm Gen模块内部,我们不需要做太多变化——因为按照一般的习惯,我们需要作如下的操作以获取B format的立即数:

由于B format需要在最后补一个0, 这样的形式意味着我们在11位立即数的每一个bit以及需要增补0的位置(共12个)都需要一个mux input来决定到底使用原输入(inst)的哪一位。而在RISC-V中:
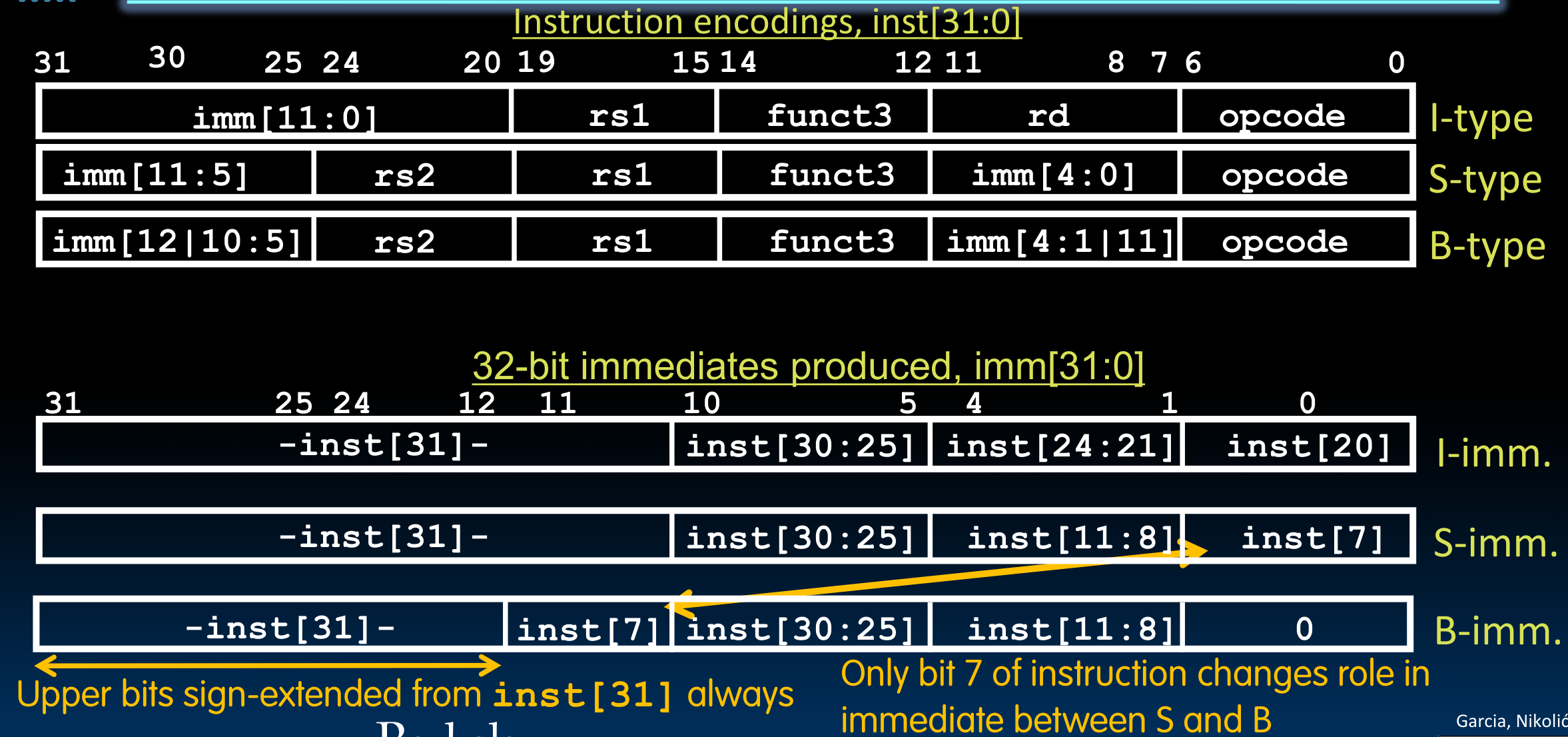
对于I, S, B这三种拥有不同的立即数格式的指令,我们可以使用两个2-way mux来解决问题:
- 处理I: 如前一节所述,这帮助我们决定到底使用
inst的哪一部分. - 处理S, B: 如果是B format,那么我们需要将
inst[7]换下位置,并用0填补空缺.
Adding JALR To Datapath
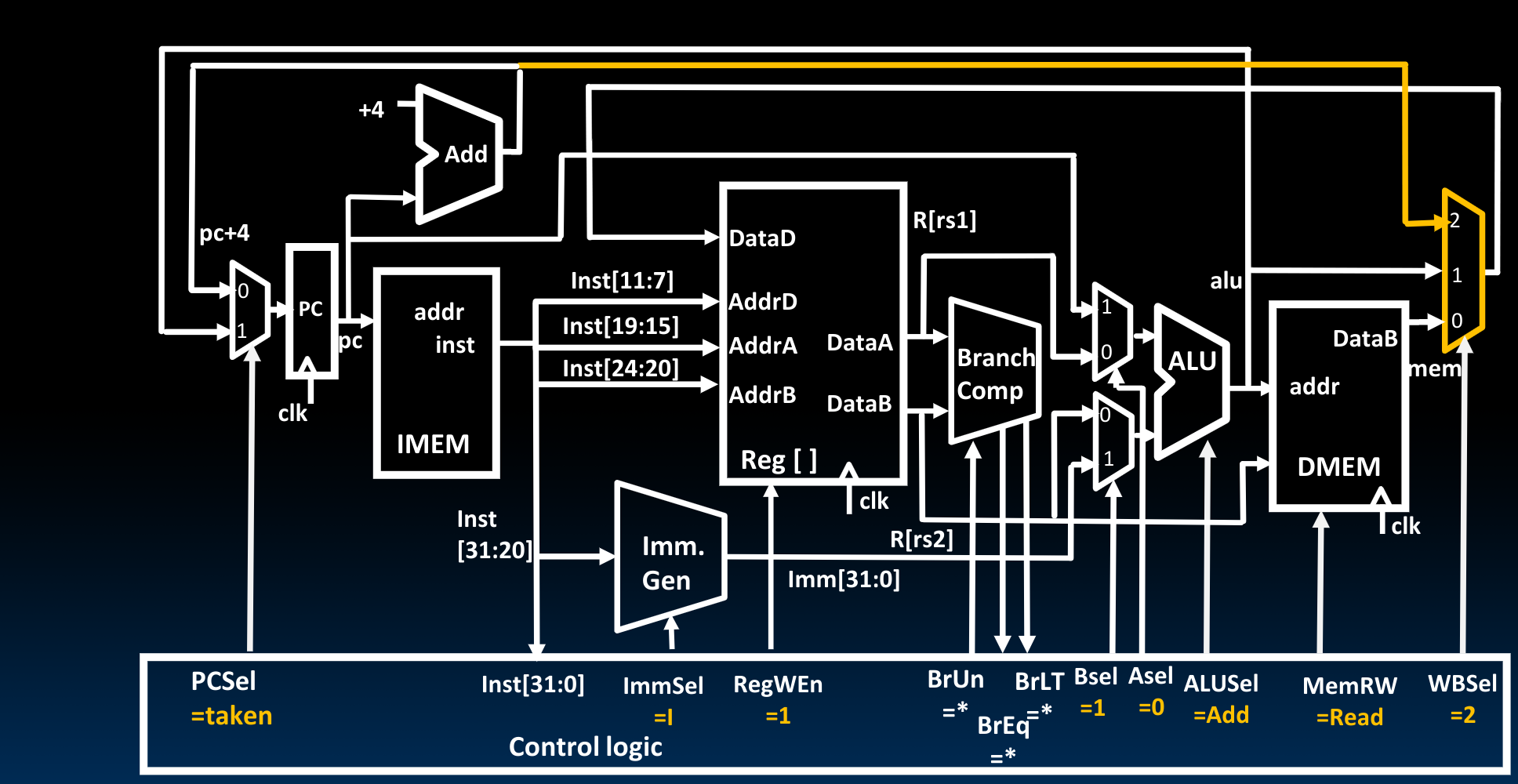
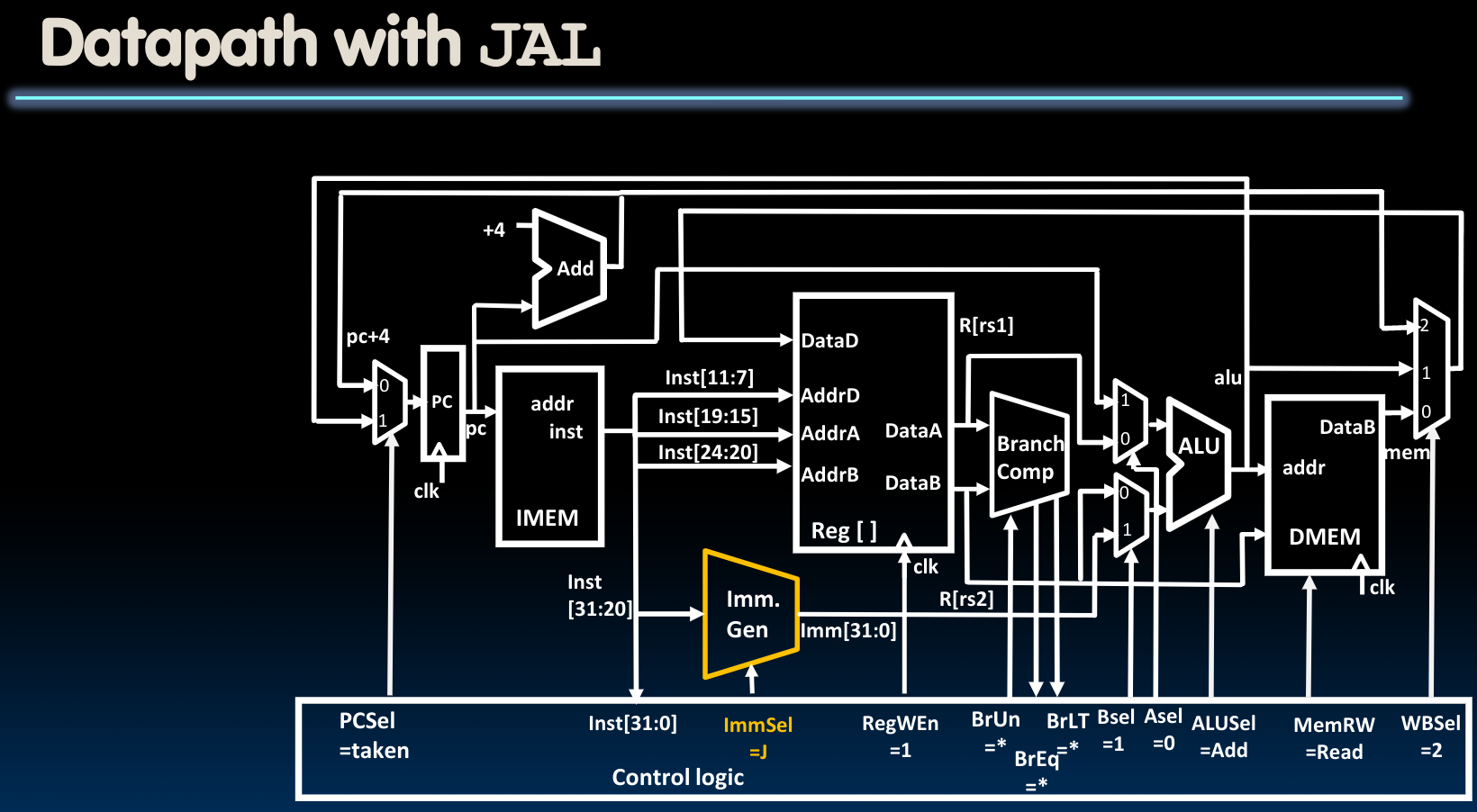
Adding JAL To Datapath
这种模式我们只需要在上图的基础上将ImmSel改为J即可.
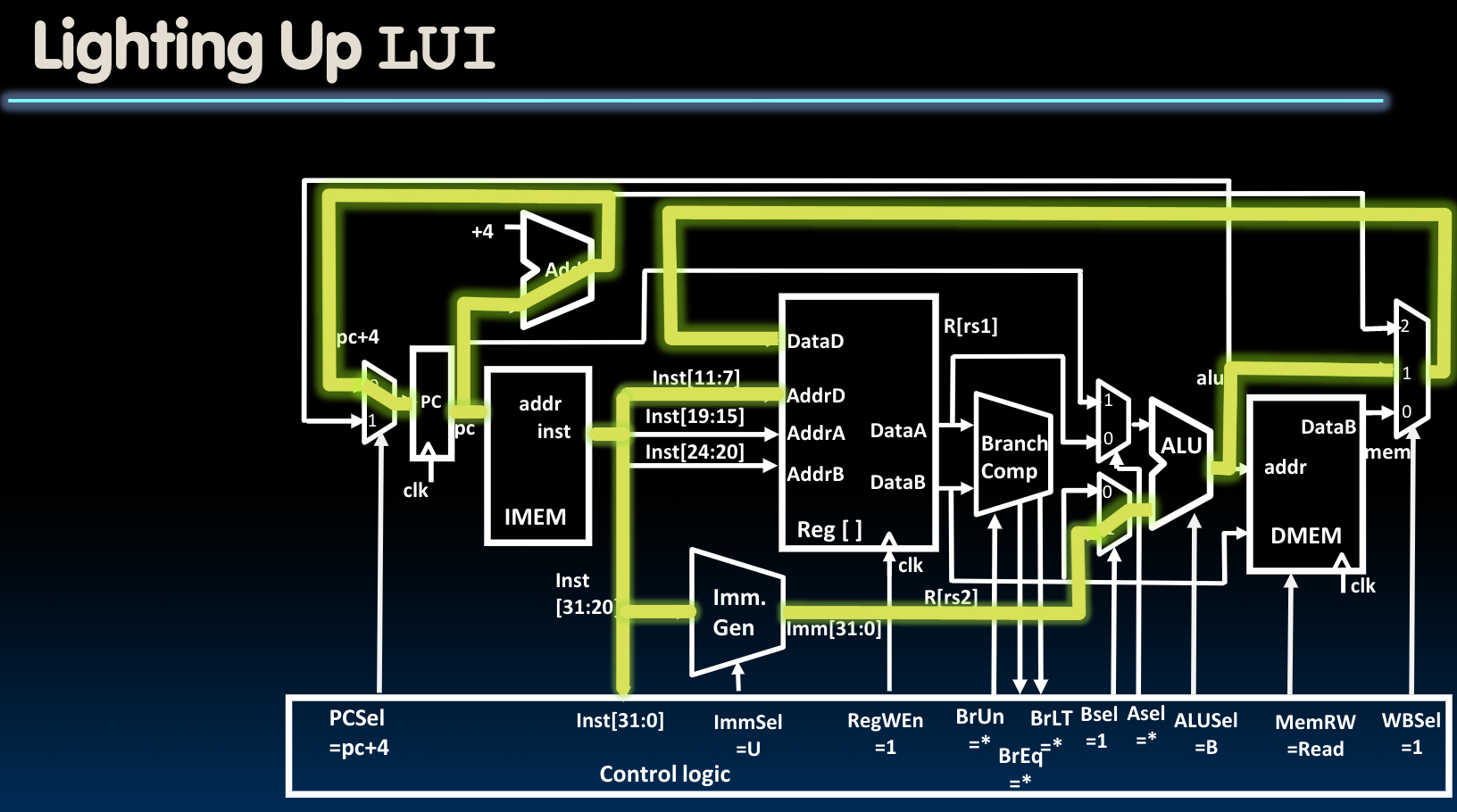
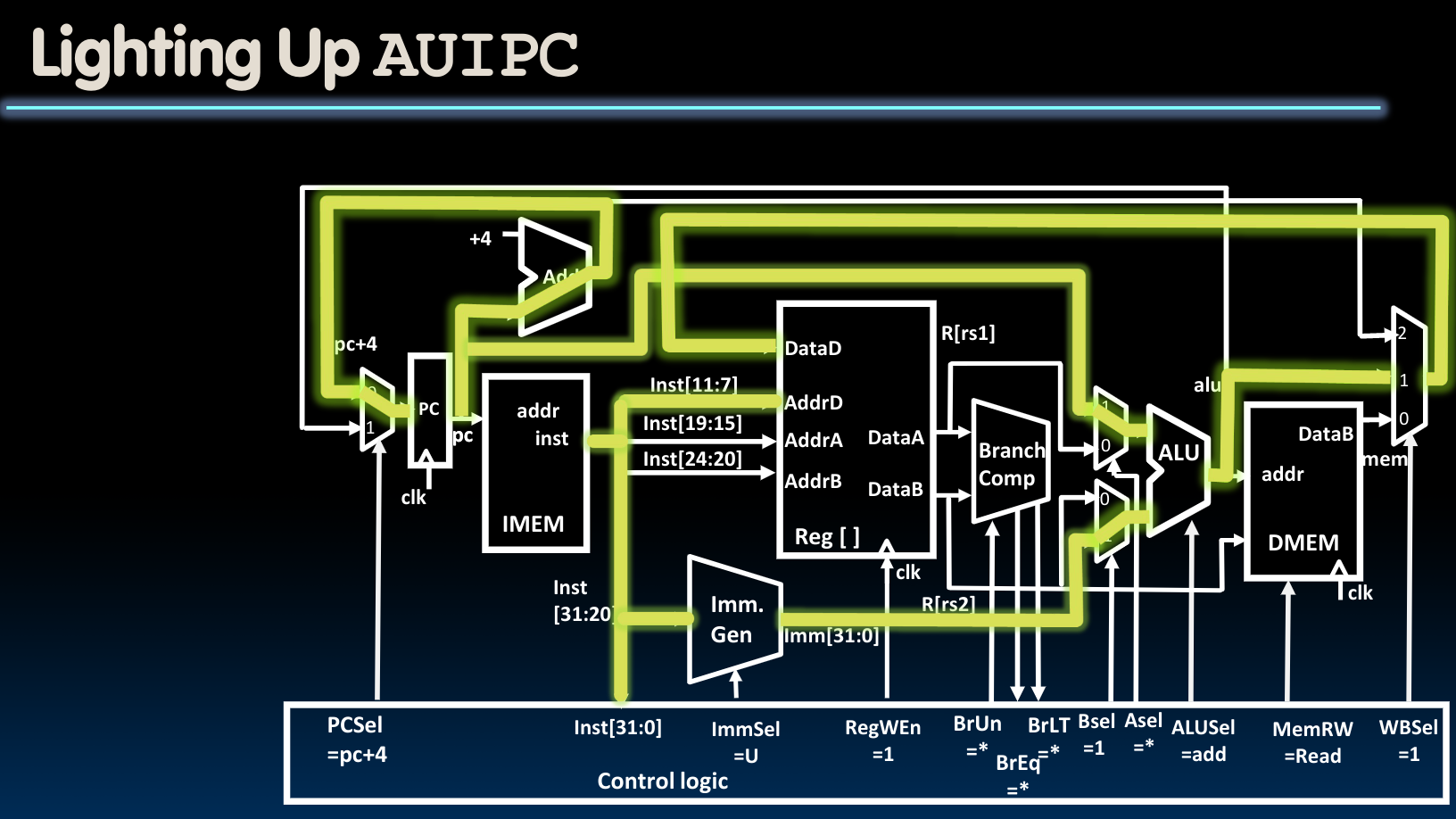
Adding U-Type To Datapath

这种模式我们只需要在上图的基础上将ImmSel改为U即可.同时可能需要切换ALUSel.因为对于LUI指令来说,我们只需要计算单元将B端口的内容输出即可:
Control and Status Registers
这一类寄存器如果简单理解,可以认为是用于保存和检查当前某个“系统”状态的,他们独立于我们前边所介绍的32个整数寄存器。可以总计有4096个该类寄存器($$2^{12}$$)。
它们不存在于基本的指令集中,但是在实际实现中却是必须的。我们有如下几种操作CSR的指令:


# read sstatus value into a0
csrr a0, sstatus
# pseudoinstruction: only perform writing rs1 to csr
csrw csr, rs1
# equal to
csrrw x0, csr, rs1
# pseudoinstruction: only perform writing uimm to csr
csrwi csr, uimm
# equal to
csrrwi x0, csr, uimm
Datapath Control
对于Datapath的运行过程,这里补充几点:
- 在课程一开始时提到过,从内存获取数据的时间要远大于从寄存器获取数据的时间,但是在Datapath中我们使用的IMEM实质上是cache,所以大致是与Program counter一个速度的。
- 在Datapath中存在两条路线,一条是走寄存器内部并获取数据,另一条是立即数的判定与运算。这两条路线相比较起来,立即数的路线要耗费相对多一些时间,因为我们要确定它是一个什么类型的立即数,从而将其补全到32位。(但我们还是可以将这两条路线视为同时进行的)
- 当Inst[31:0]被输入
Control Unit时,后续一系列可以被设置的flag将被设置。 - 对于B format的指令,当我们
fetch instruction并将指令传入control unit之后,是不可以立即设置PCSel位的。因为我们需要根据具体指令的比较结果设置的BrEq和BrLT位决定是否进入由label指定的位置中–到底是执行pc+4还是pc+imm。 - 在对
Program Counter操作(PC+4)的同时进行fetch instruction。
Instruction timing
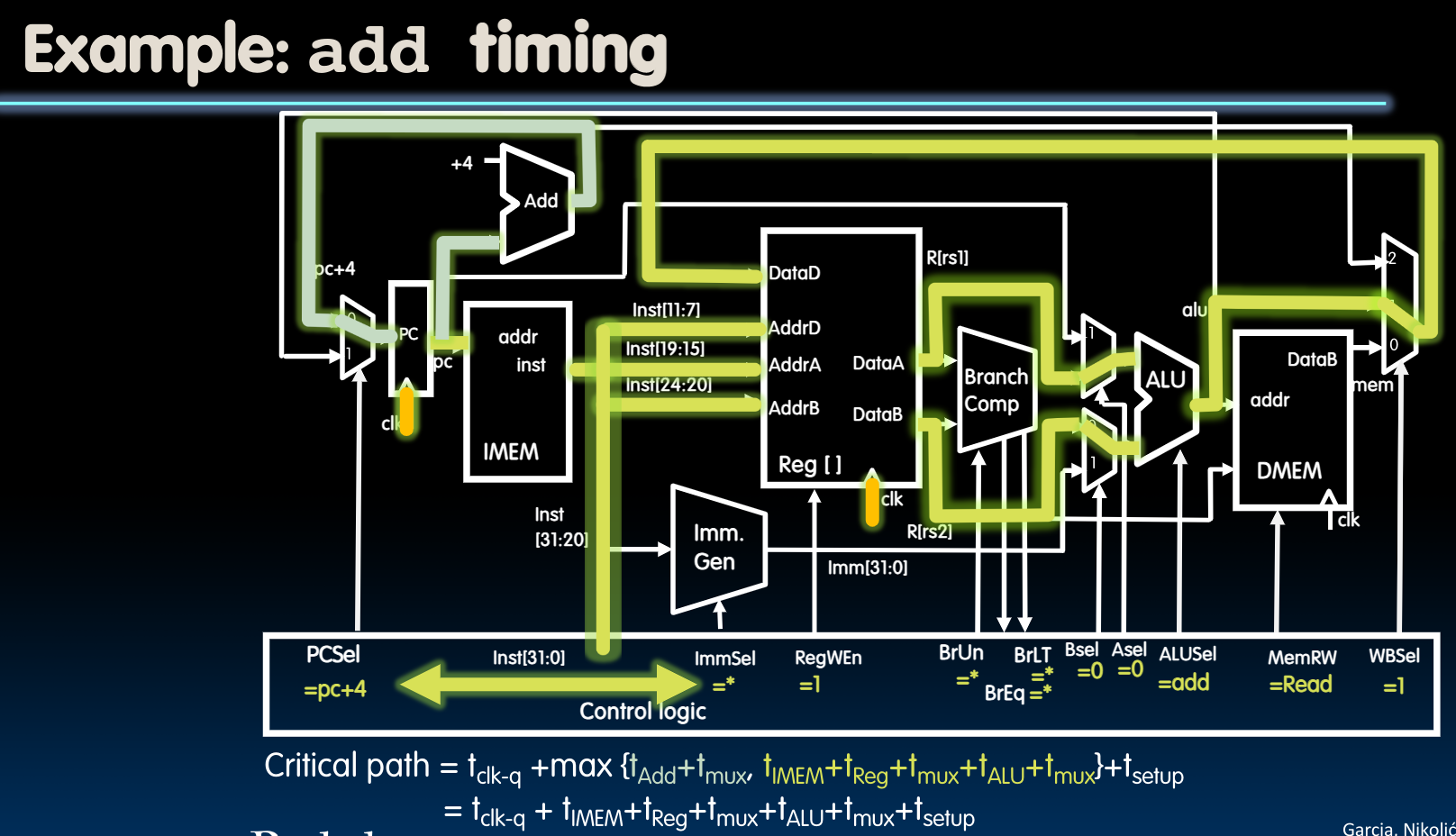
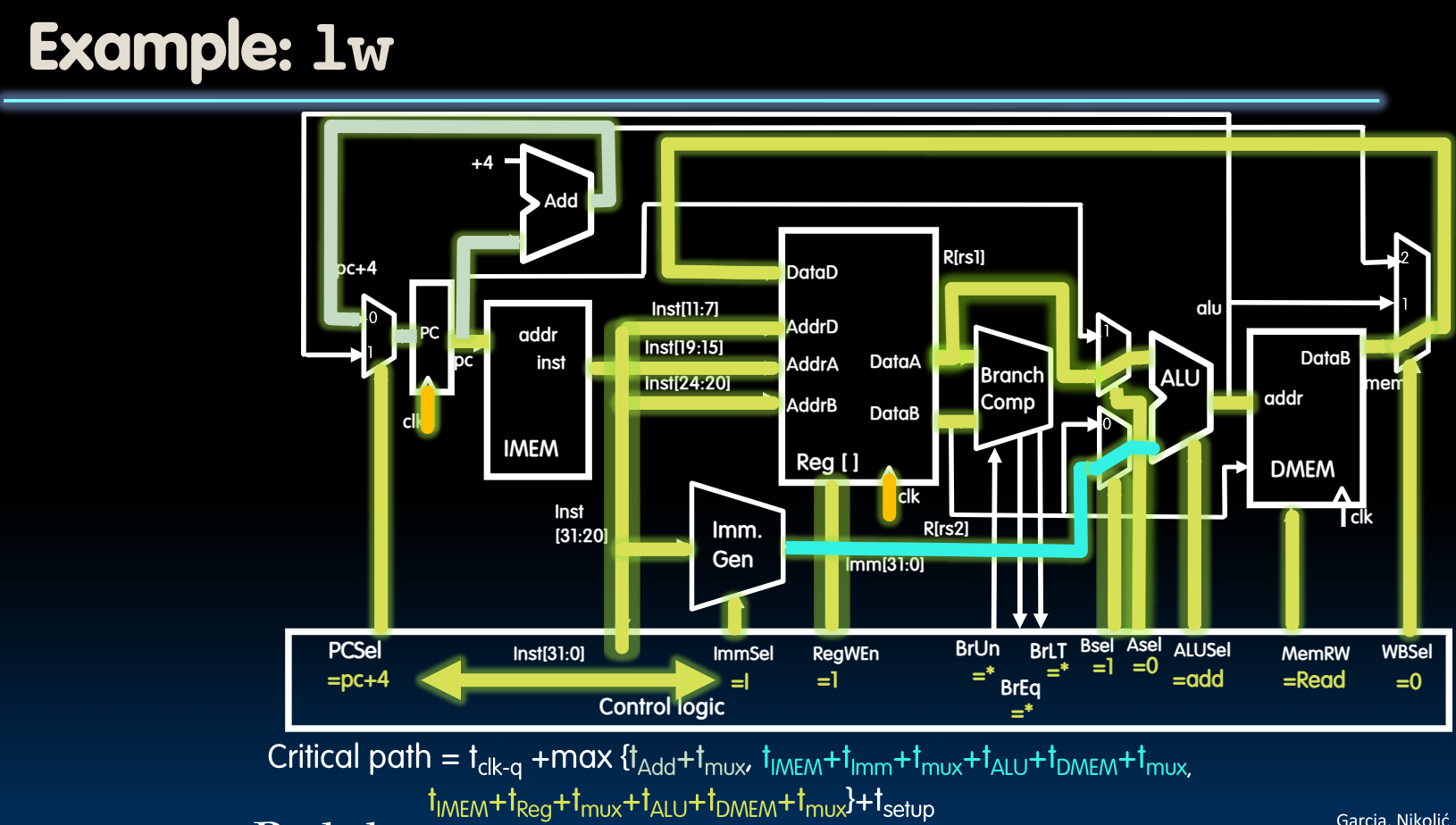
我们以指令add为例:
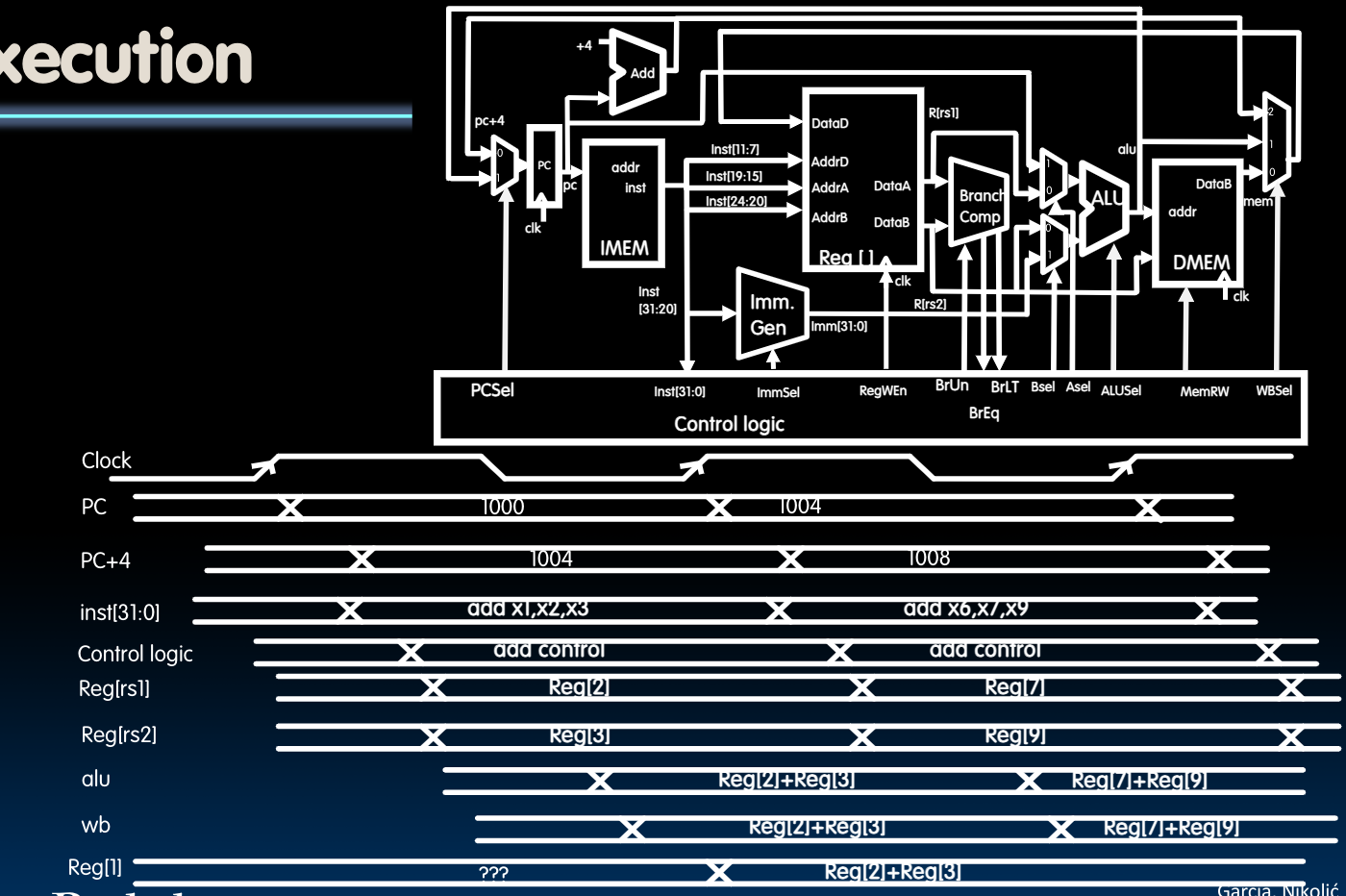
在上图中,我们可以观察到以下几点:
- 观察
inst[31:0]与PC+4的稳定时间可以发现,PC+4要稍微滞后一些,这是因为对于Program Counter来说,它的所有bits都会在同一时刻被设置(same type of flip-flops),但是根据我们先前介绍的adder的设计方法,它的最低位会最先被设置好,一直到最高位。而我们在途中考察的应当以最后整体被设置好的时间为准。故PC+4的时间应当比fetch instruction稍稍滞后。 - 对于新的PC以及从内存读取的数据会在下一个rising edge经过
clk-to-q后被设置(或写入寄存器中),但是我们务必确保在寄存器或者PC的setup time之前,信号就已经稳定了吗,这意味着时钟的周期不能太短,否则当在setup time中时,信号还没稳定下来。 - 根据ISA的设计,ALUSel需要4bits,根据control unit的设计,WBSel需要2bits。
如果我们将上述详尽的时间表划分出之前提到过的5个指令执行的阶段:
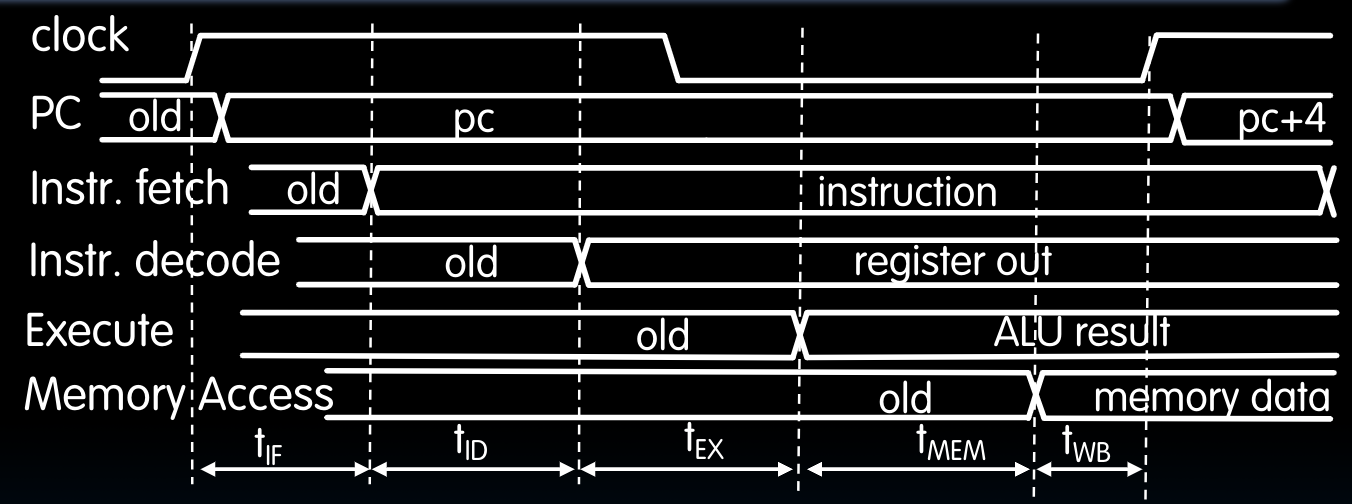
接下来,我们可以考虑一些关于delay的问题。
同时我们可以尝试计算出系统允许的最大时钟频率:

同时,在disc 6中我总结了以下几个关于delay的问题:
Regs can hold until the earliest possible time its input might change:
$$MAX_HOLD = clk-to-q(from\ prev\ reg) + CL_{shortest}$$
这个等式之所以成立,是因为我们是从一个新的rising edge开始考虑的。
Clock cycle must be lage enough to account for clk-to-q times, setup times and CL times:
$$MIN_CLOCK = clk-to-q(starting\ reg) + CL_{longest} + setup(ending\ reg)$$
这个等式之所以成立,可以从如下两个角度描述:
- 如果一个周期内无法包含这三项,那么意味着某一个时刻的
setup time会与clk-to-q发生交汇,会导致亚稳态。 - 我们从先前的简单模型:adder+reg的角度来看,如果不满足,则在一个周期内,$$S_i$$的值无法被成功更新。
Control Logic Design
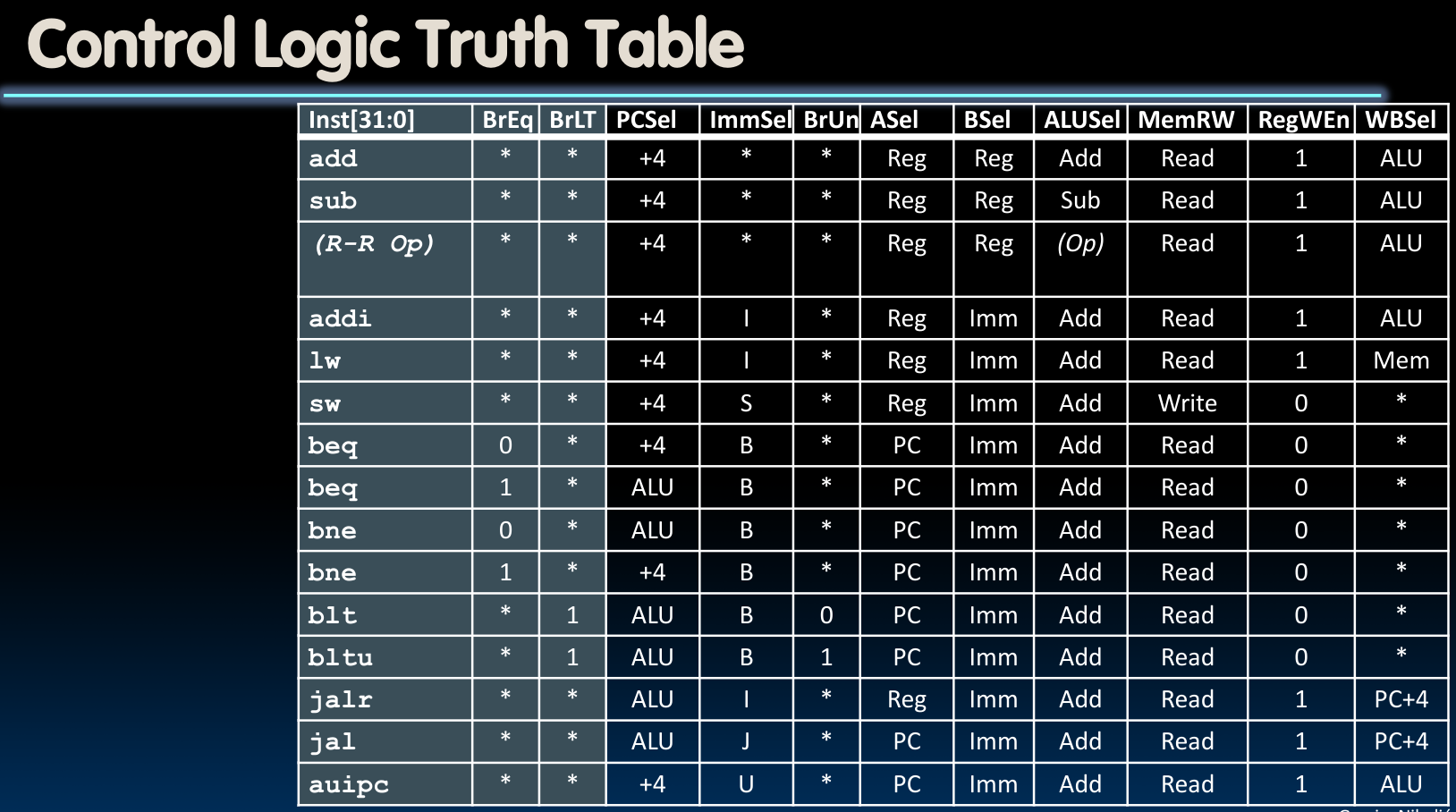
一般来说,有两种实现控制逻辑的方法,即ROM与CL:
其中,ROM的一般做法是直接将不同的control words存储起来,当我们需要增加指令或者构建复杂指令集时,就向其中增加新的控制字。
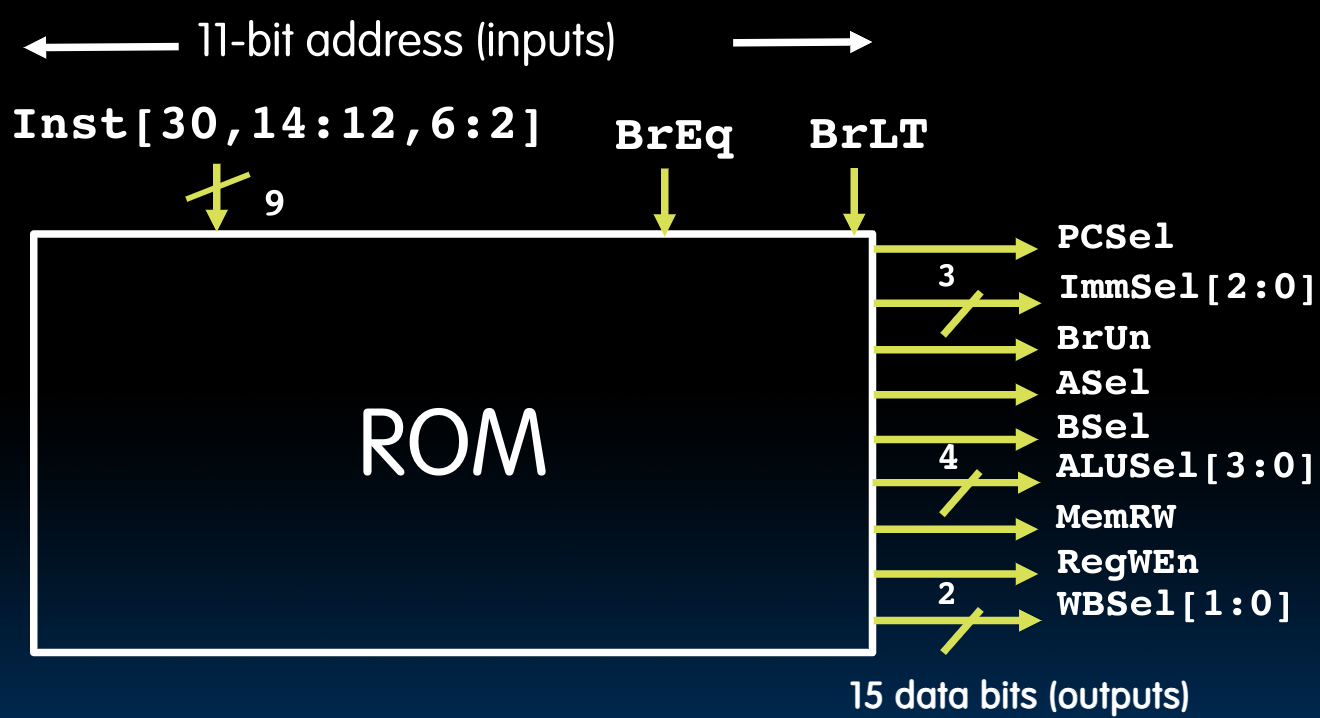
对于RISC-V来说,我们也将它称为Nine-Bit ISA,因为只有9个bits为我们提供了必要的信息:
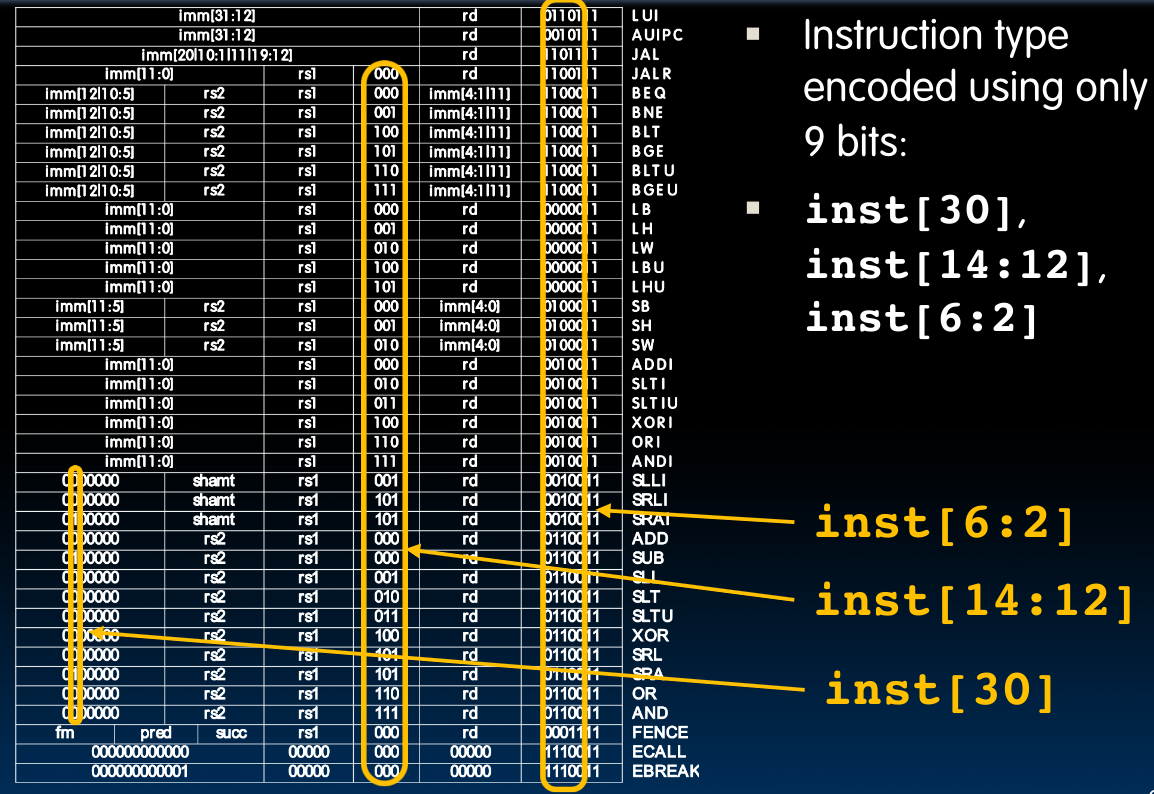
此外,根据先前的控制电路设计,我们知道还提供了BrEq与BrLT这两个输入,所以总计11个:
而如果我们将上图抽象一下,则会发现这种结构类似于一个and加上一个or的结构:
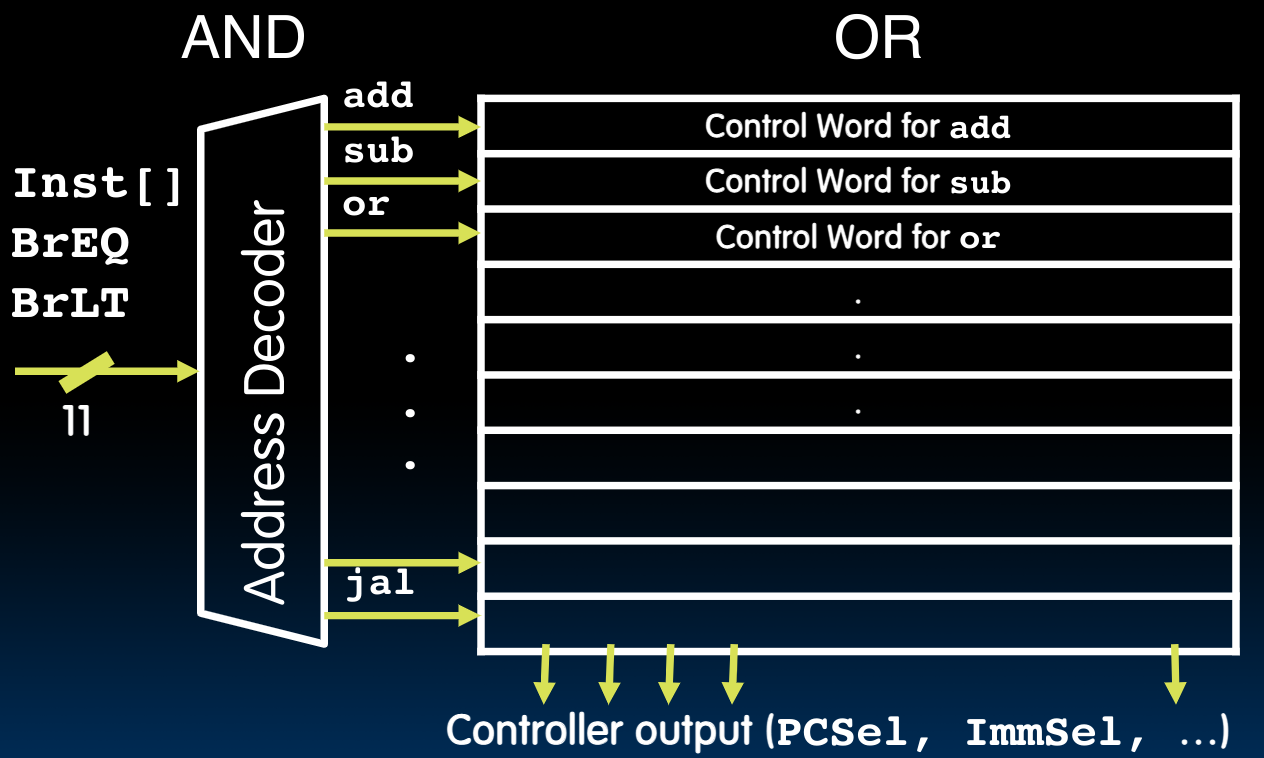
故而我们可以尝试使用CL来设计控制单元,这里提供一个指令add的Address Decoder:
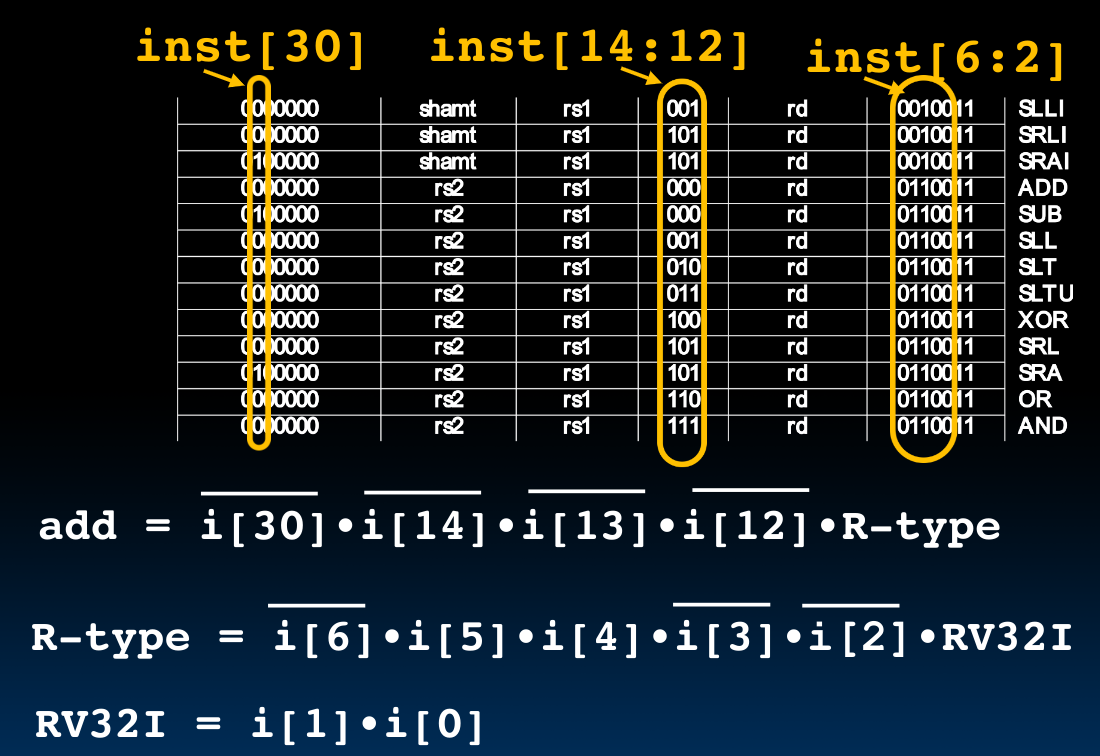
如果我们需要增添指令,那么就可以对opcode的后两位下手。它们代表着RV32I
Pipelining
Pipelining主题的意义在于提升处理器的Performance Measurement & Improvement。我们想通过某种方式使得处理器能够一次(即一个时钟周期内)执行多次任务。
在解决这个问题之前,我们首先要知道如何评价一个处理器的性能,如果我们使用轿车与公交车的例子与电脑处理器进行对比,我们可以有如下的结论:
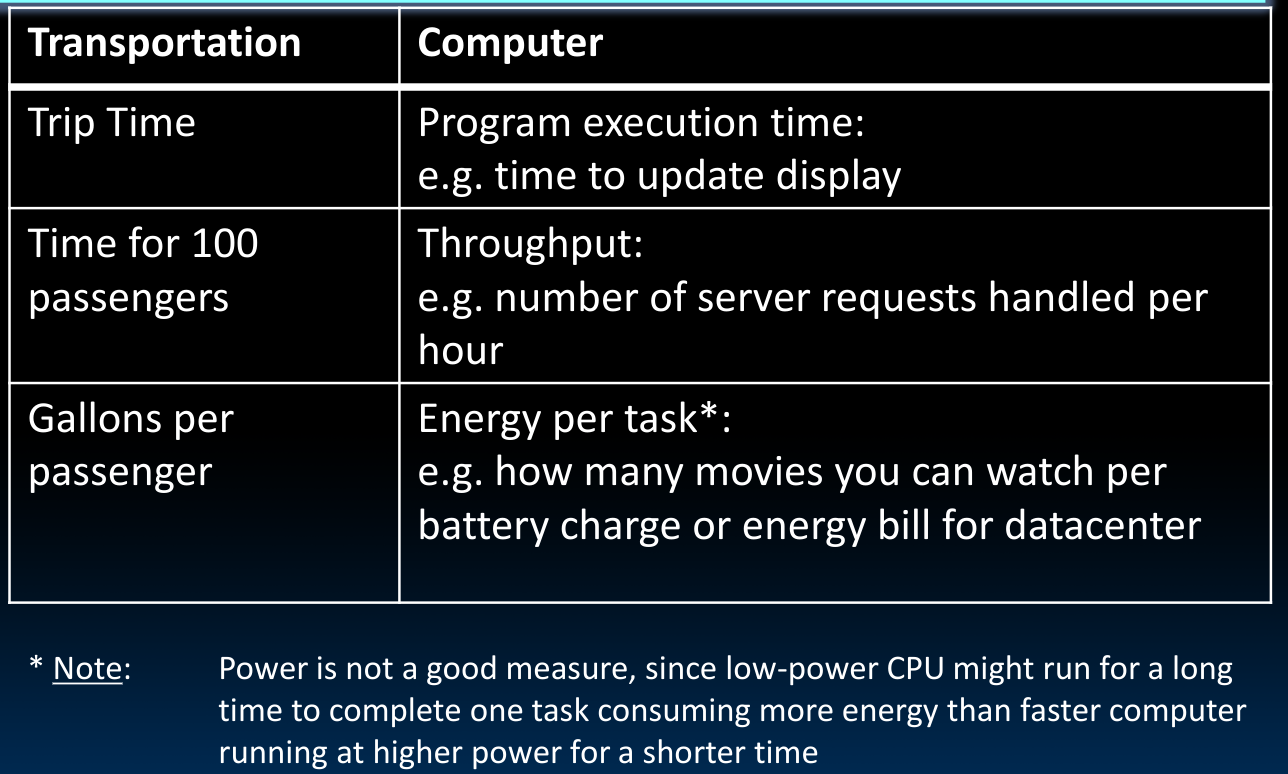
其中,energy对应着“能量”;power对应着“功率”。需要注意的是,power在这里并不是一个好的衡量指标,因为功率的单位是J/s,低功率的机器执行任务的时间会比大功率的机器多,这意味着消耗的总能量未必小于大功率的机器。
Iron Law
如何量化评价一个处理器的性能?
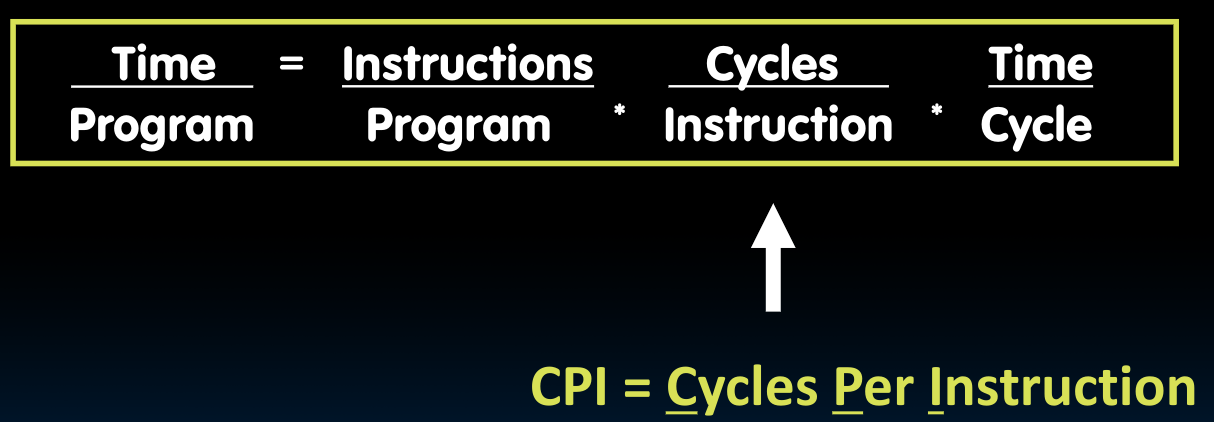
CPI指的是处理一条指令需要的时钟周期数.
对于上述三个因子,我们逐个论述:
Instructions per Program
取决于:
- Task
- Algorithm
- Programming language
- Compiler
- Instruction Set Architecture (ISA)
CPI
取决于:
- ISA
- Processor implementation (
microarchitecture) - Complex instructions (
CPI >> 1) - Superscalar processors (
CPI < 1)
Frequency
取决于:
- Processor microarchitecture (determines critical path through logic gates)
- Technology (5nm vs. 28nm)
- Power budget (lower voltages reduce transistor speed)
Energy efficiency
我们一般使用CMOS来制作各种门电路:
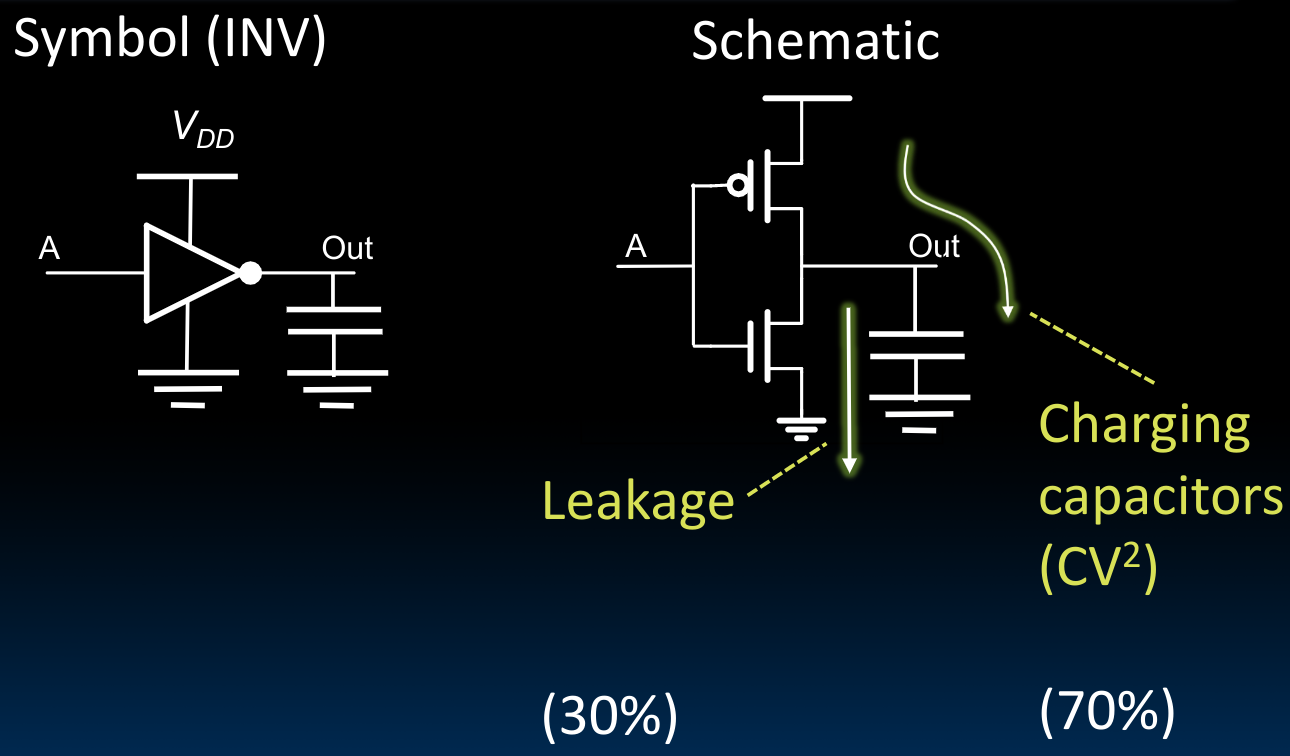
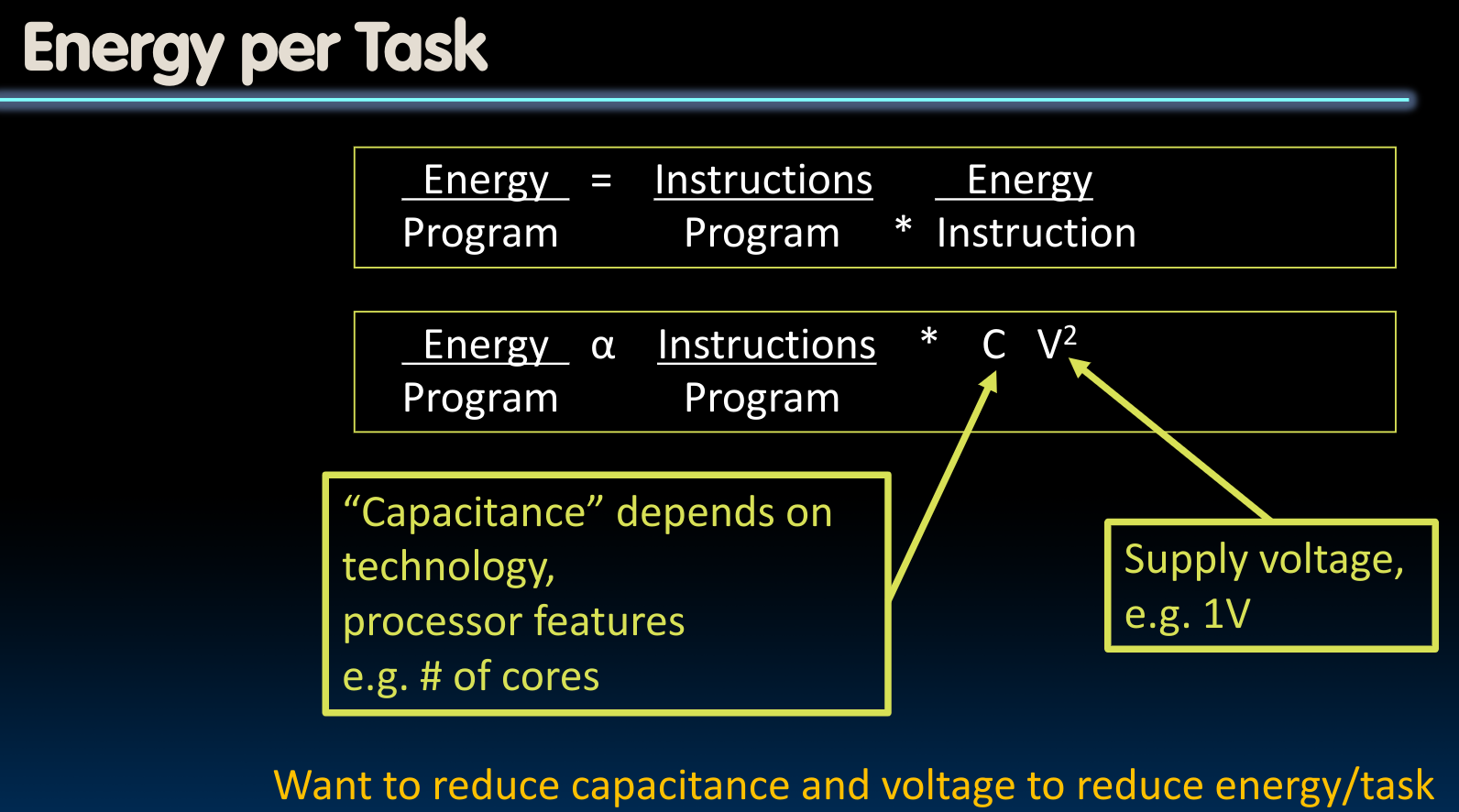
从上图中我们可以看出,显然电压V相对于当前电路的总电容C是一个更加“有力”的因子。但需要注意,如果我们将电压下降的太厉害,那么晶体管的运行速度会更慢,这是一个trade-off。同时,电压的下降会导致leakage的比率变高。另一方面,为了控制电路总电容C,我们往往会将电路在three dimension的方向扩展(因为相当于并联电容)。

最终,我们总结出了如下的规律:

Energy “Iron Law”
能量效率为什么如此重要?

Pipelining RISC-V
对于Pipeline的介绍这里略过,详见课件内容。
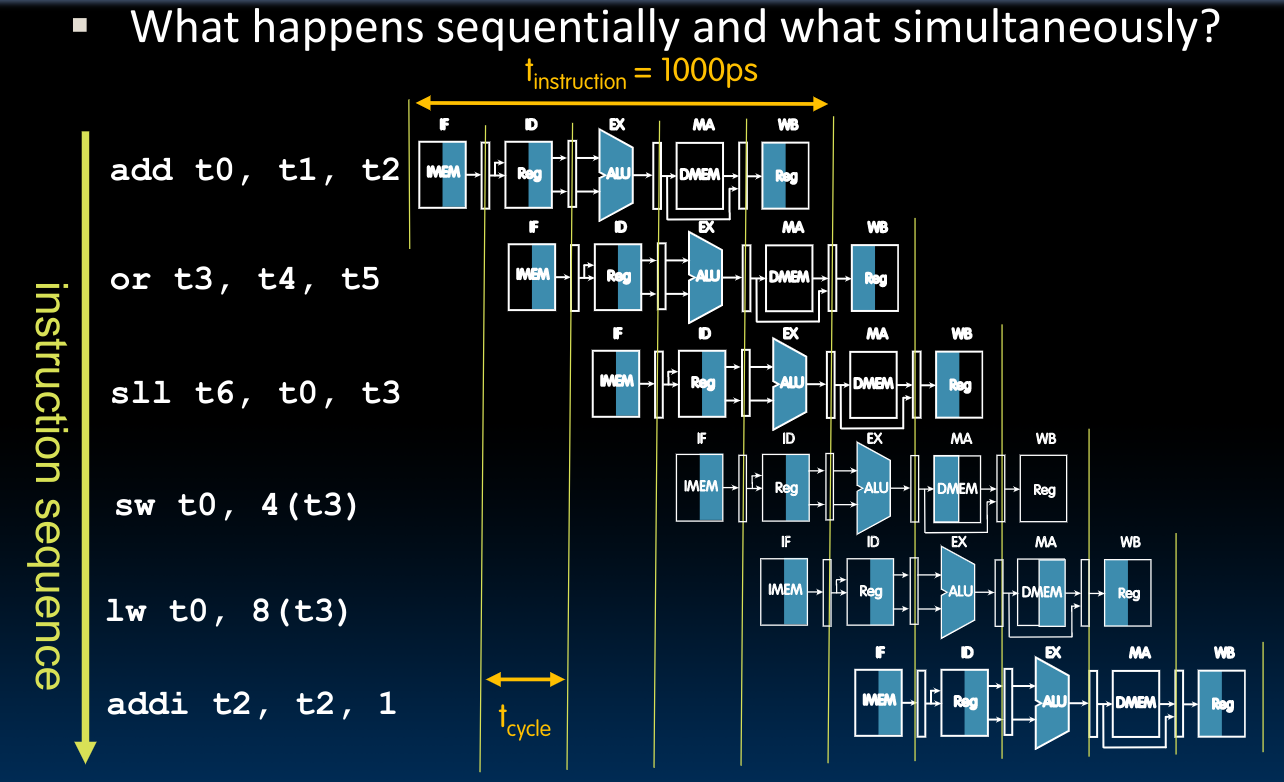
需要注意的是,如果每一段的耗时不同,那么我们必须给每一段分配对应的最长的时间段,以确保在该阶段内的指令能够执行完成.
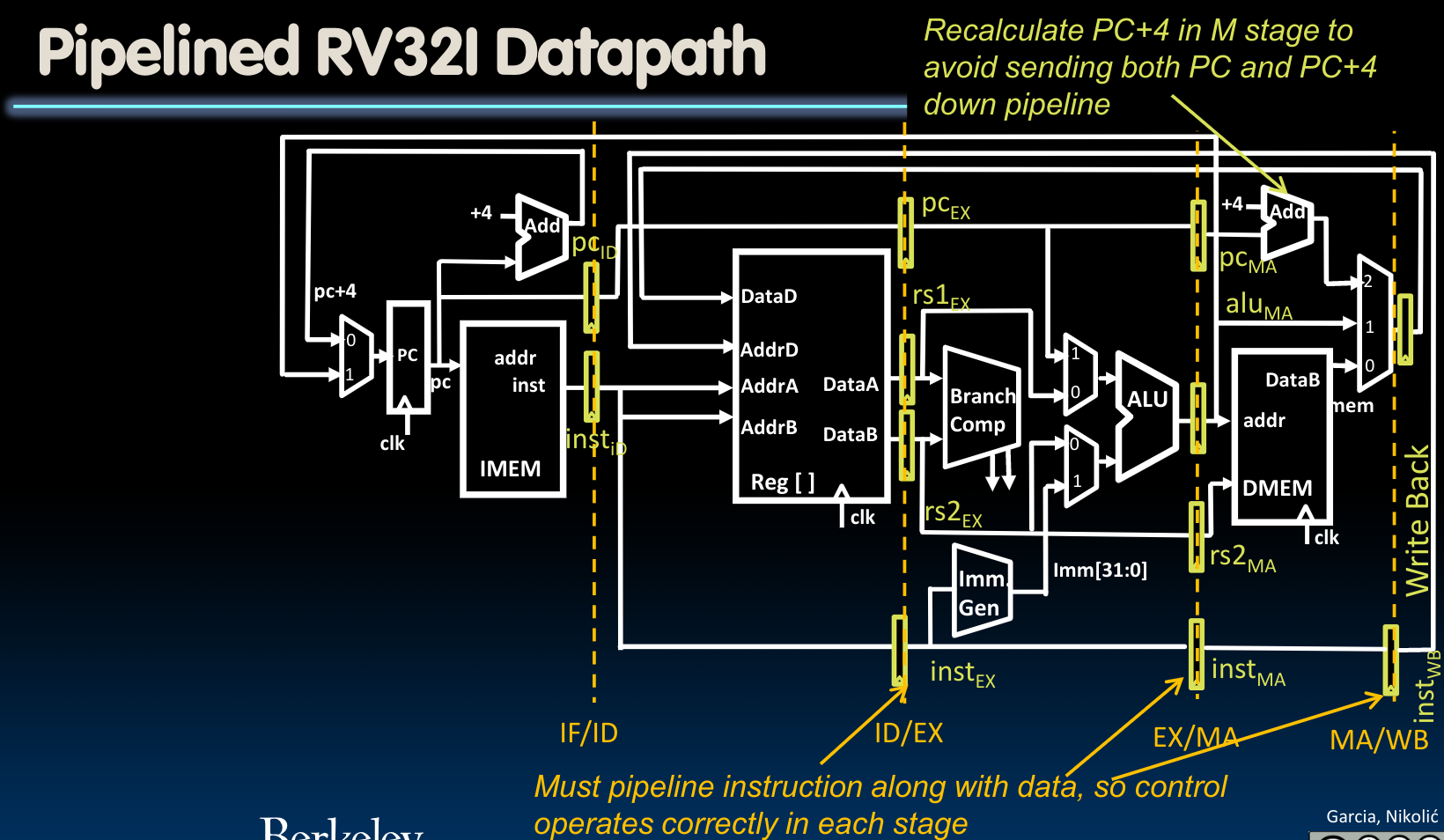
于是我们可以借助寄存器保存当前的状态直到下一个时钟时刻到来的时候的性质,将5个指令的子执行过程在我们先前设计的single-cycle CPU中划分出来,这种设计的理由参见先前在Introduction to SDS部分上传的pipeline文档中。于是在这里,我们使用寄存器保存下每一个阶段结束后的状态:
如果没有寄存器,会怎么样?
如果我们不添加寄存器,也就是说不适用寄存器来保存当前状态,那么自遇到
rising edge起,系统就会开始处理指令,由于当前我们假定的系统并非single-cycle,所以在一个时钟周期内,一条指令无法执行完成。这就带来一个问题——在导线上的信号传递速度是无限快的,由于我们没有保存好前方已经被传入的指令的信息,如PC和control bits,那么在指令需要用到他们的时候,这些值可能已经被后来的指令的信息替代了.
在这里,我们需要注意以下几点:
- 用于保存
Program Counter的寄存器始终储存着PC,而非PC + 4,在需要使用到PC + 4的值的地方使用一个adder来重新计算,这种设计避免了我们将两者都传递下去(因为我们可以看到,在通路中间有需要用到PC的地方) - 在上图的下侧,在每个阶段都有寄存器保存了指令的二进制代码:
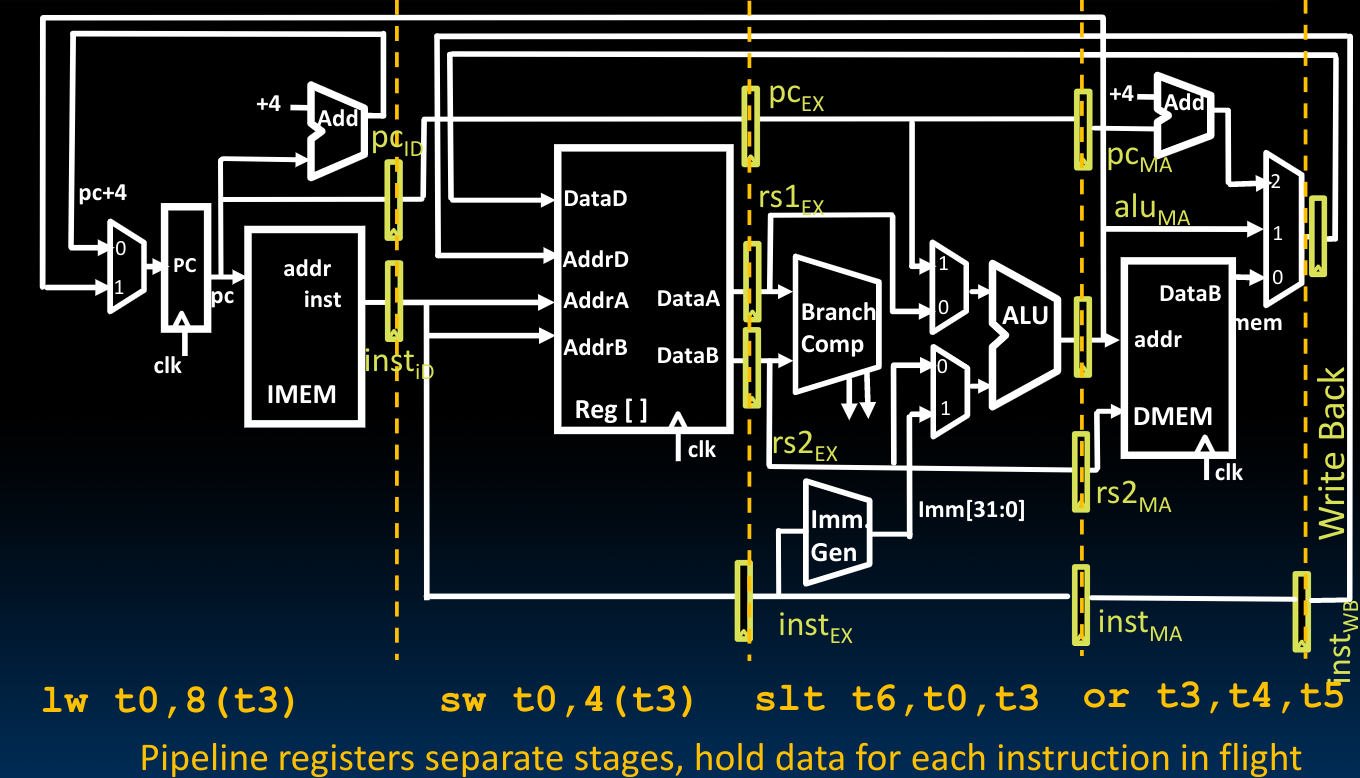
同时在这些储存着指令的寄存器(move the instruction along the pipeline)中,我们还需要储存control bits:随着阶段的后移,我们需要储存的control bits应当是越来越少的,我们只需要在其中保留余下阶段的控制字即可:
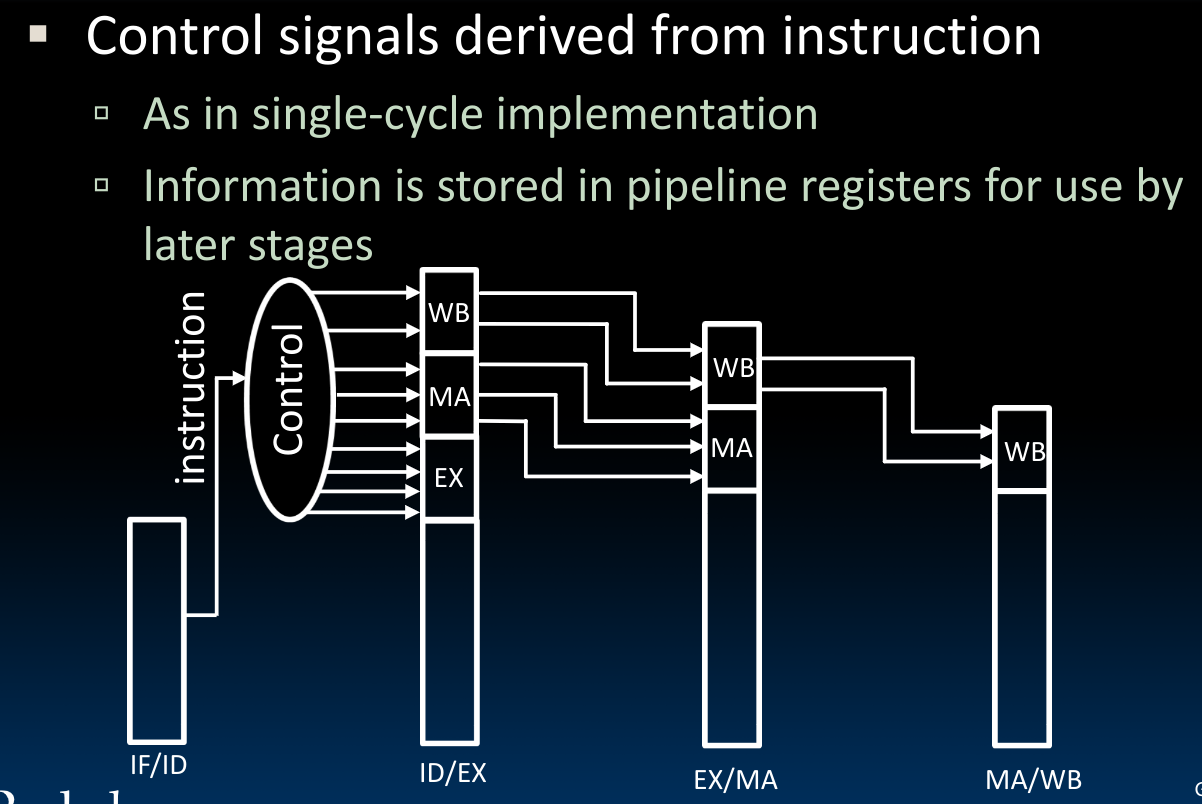
- 我们可以将上图中这些隔离开的小寄存器理解为几个大寄存器,每个寄存器保存了在当前状态下需要的所有信息,这也意味着更多的bits,比如在IF/ID阶段,就需要
64bits的寄存器。同时根据前边对于control bits的描述我们知道,在ID/EX阶段的大寄存器应当包含7bits的控制字:
Pipeline Hazards
There are situations in pipelining when the next instruction cannot execute in the following clock cycle. These events are called hazards.
共有三种类型的hazard:
- Structual hazard
It means that the hardware cannot support the combination of instructions that we want to execute in the same clock cycle.
A required resource is busy (e.g. 如果
PC+4的过程也需要用到ALU,那么在pipeline进行的过程中,就会形成resource compete)
- Data hazard
Data hazards occur when the pipeline must be stalled because one step must wait for another to complete.
- Data dependency between instructions
- Need to wait for previous instruction to complete its data read/write
关于Data hazard,我们在之后会详细论述.
- Control hazard
Also called branch hazard. When the proper instruction cannot execute in the proper pipeline clock cycle because the instruction that was fetched is not the one that is needed; that is, the flow of instruction addresses is not what the pipeline expected.
How to solve pipeline hazards?
Structural Hazard
共有两种解决方案:

那么在实际的设计过程中我们是如何解决Structual Hazards的呢?
首先,我们要确保reg file具备3个端口–2 for read, 1 for write.
其次,为了能够在同一个clock cycle中(可能需要)完成对内存的读和写,我们需要一个IMEM和一个DMEM.
真正的内存位于DRAM中,但是在处理器上的cache块保证了我们这一功能,也就是说cache可以被分为I cache与D cache
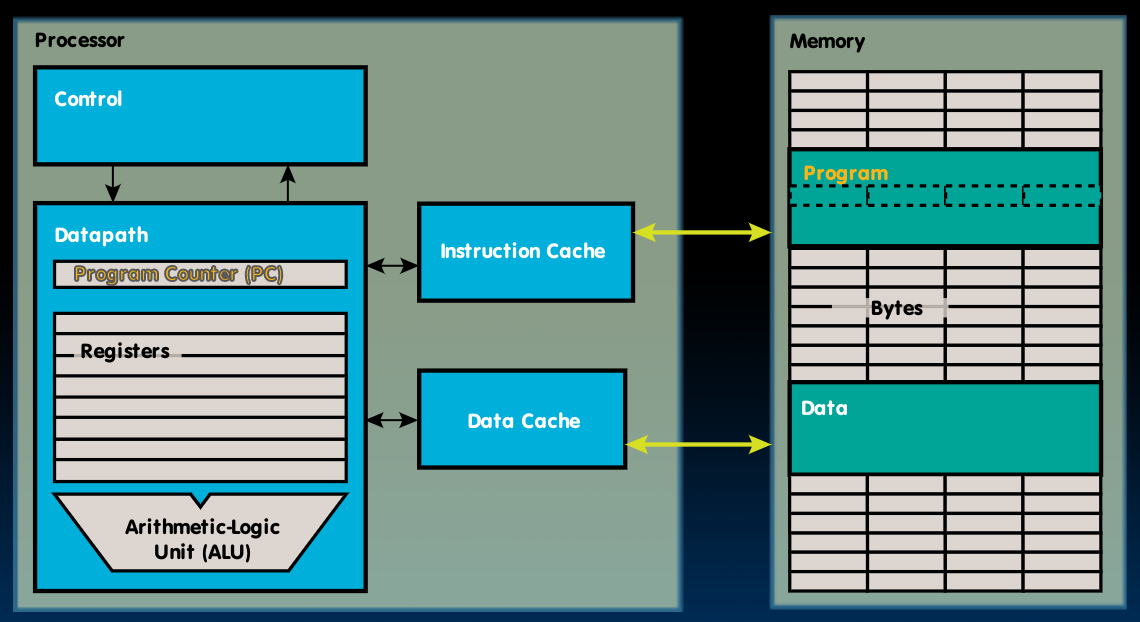
最后,我们的ISA设计也在规避structural hazards的发生,这由保证一个指令中仅进行一次内存操作实现。
Data Hazard
在data hazards的主题下,我们也分成两个小问题来讨论。
Register Access
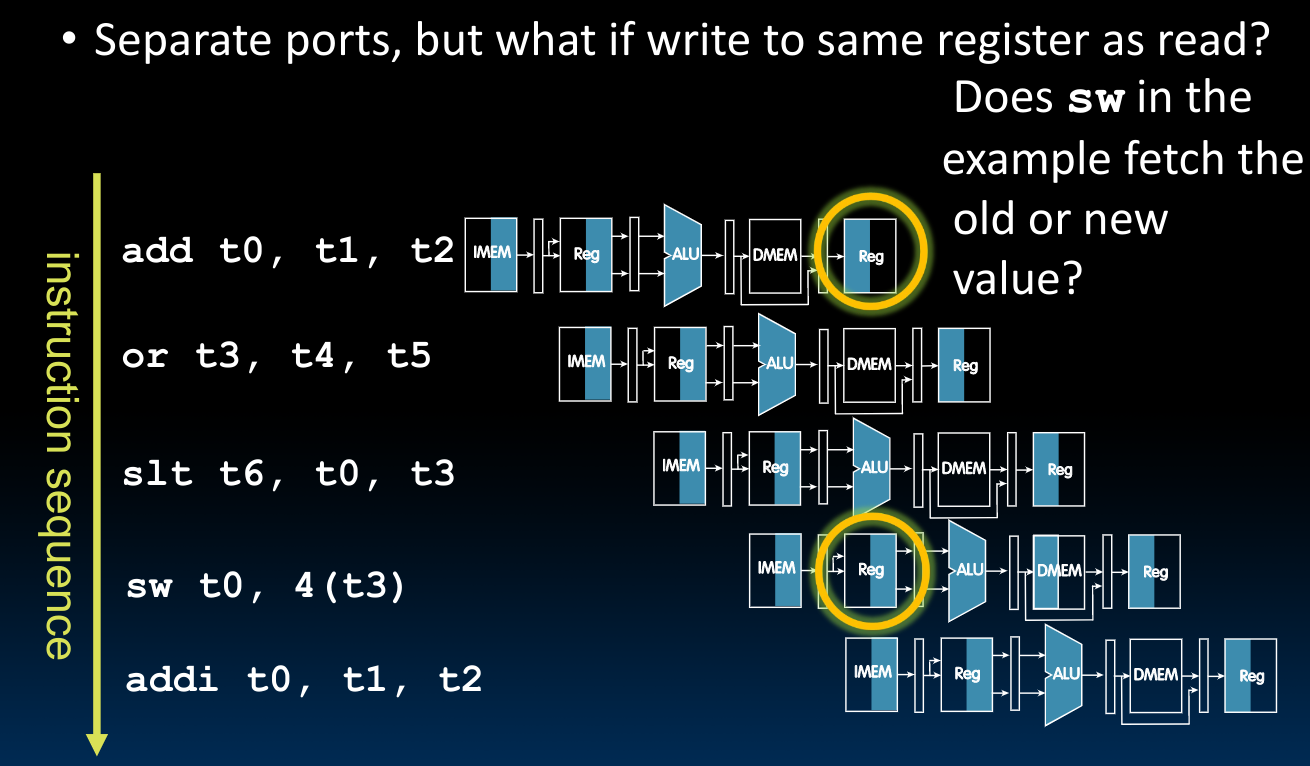
在上图中我们可以看到,在一个时钟周期内,我们对同一个寄存器进行了读和写。为了解决这个问题,有double pumping的解决方案:
Exploit high speed of register file (100 ps)
- WB updates value
- ID reads new value
在200ps的时间里,我们使用前100ps完成写入,利用后100ps完成读取。需要注意的是,在面对一些高频率的处理器设计时,这种快速的先写再读的方法不一定能够实现。
ALU Result
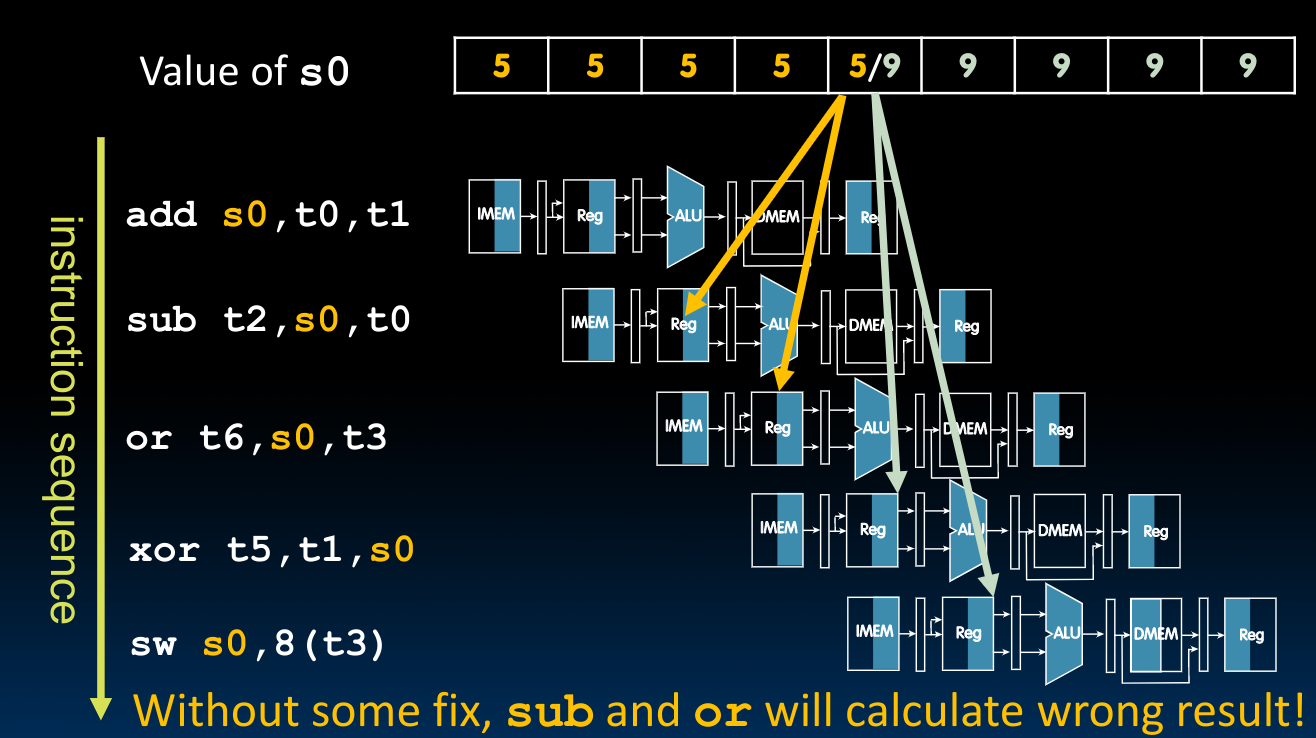
为了解决上图所示的问题,我们有两种方法:
- 既然我们在后续指令中要用到的结果还没有被成功更新,那我们不妨等一等,这就是我们的第一种思路——stalling:
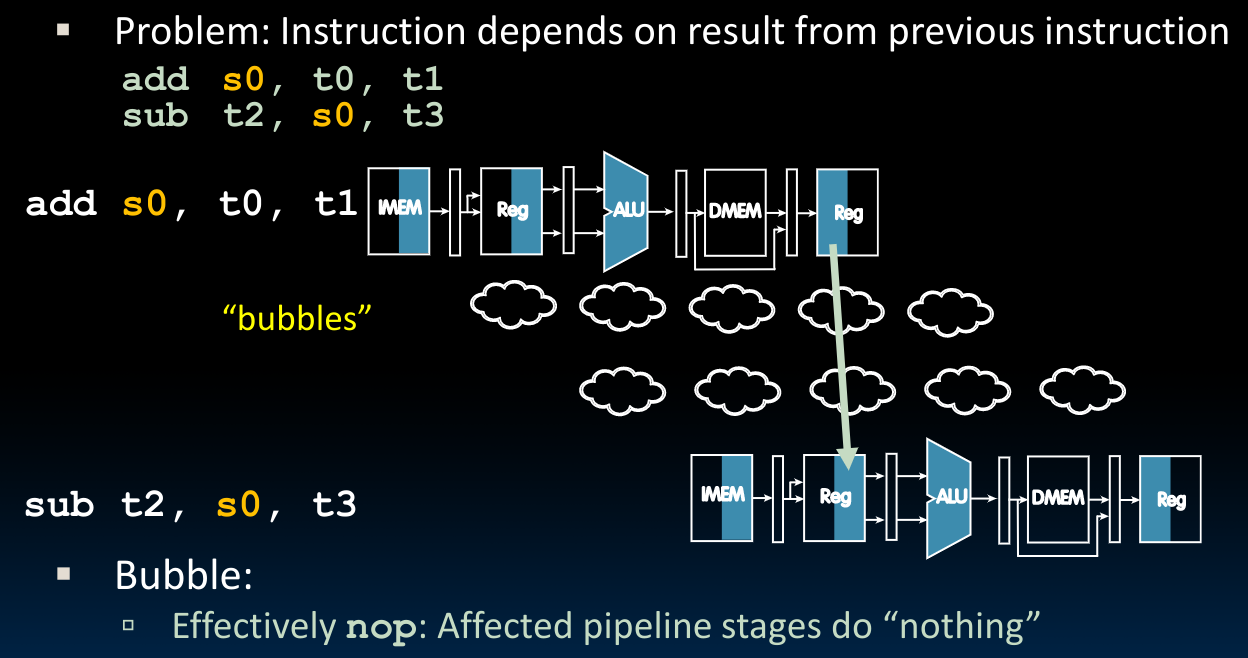
需要注意的是,在实际的实现过程中,编译器会把一些不与当前指令存在data hazards的指令先执行,当不存在此种指令时,编译器会使用我们上图中表示出来的nop方法,对于RISC-V来说是:
addi x0, x0, 0
但这种方法显然存在一个弊端,就是会减慢运行速度,削弱性能表现。
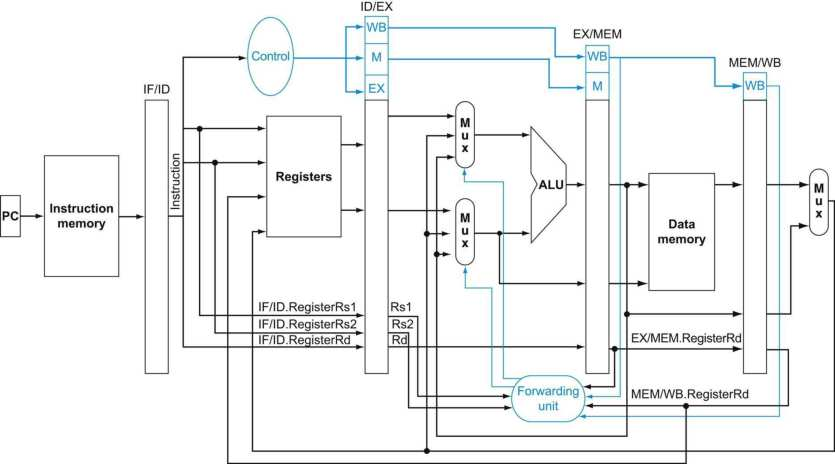
- 我们来思考,是否能够借助第一条指令EX之后的结果,利用逻辑电路把已经计算好但没有储存在寄存器或者内存中的结果传递给需要他们的指令,换而言之,我们从Pipeline中抓取结果,而非寄存器?这就是我们的第二种思路–Forwarding
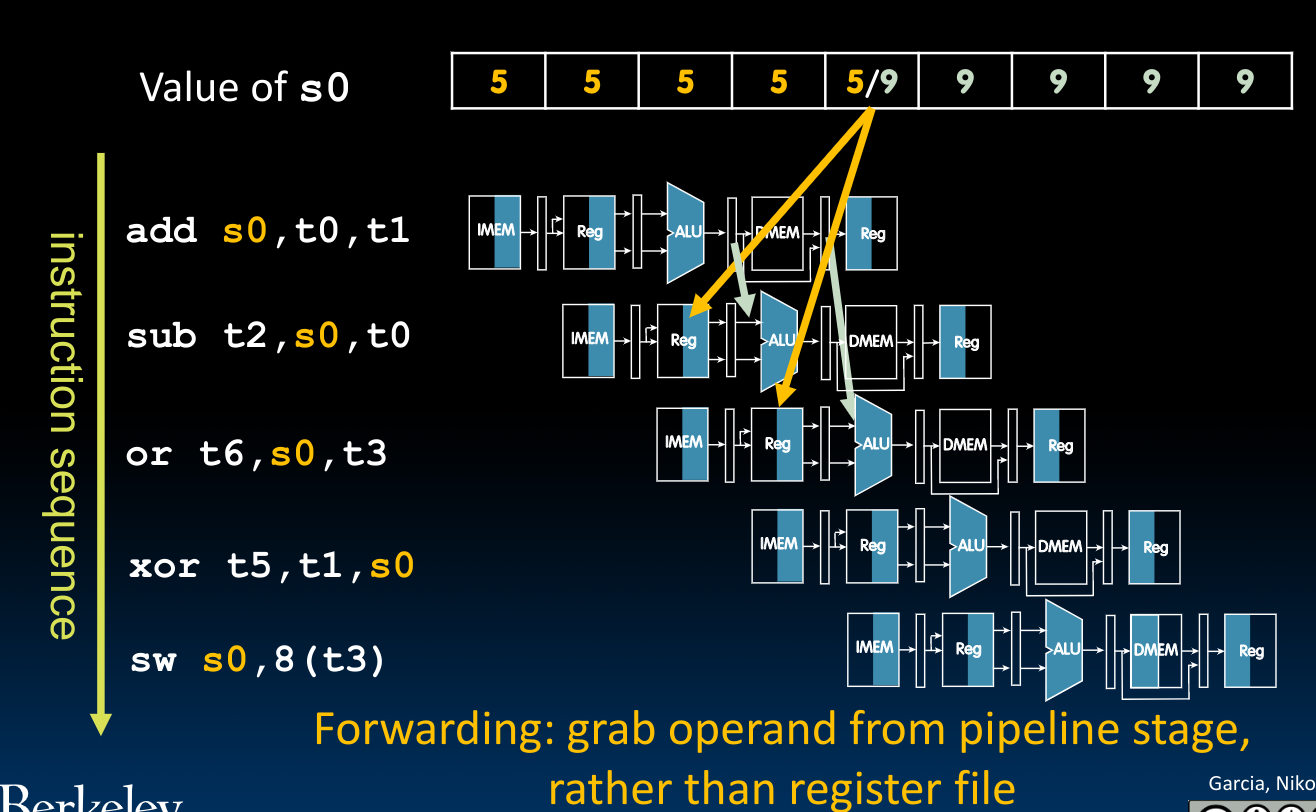
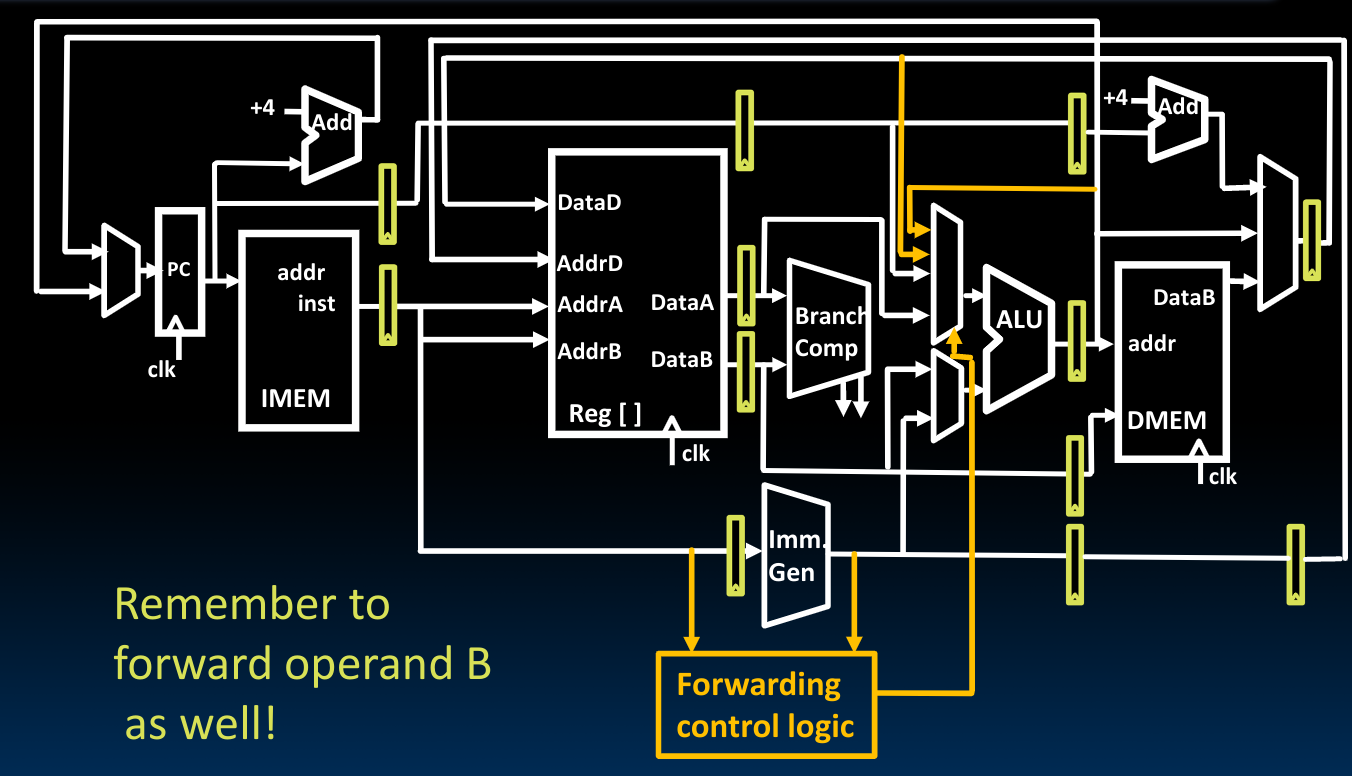
为了判定究竟什么时候才需要将Pipeline中的结果传递,我们可以借助先前在Datapath中为了划分(储存)阶段信息的寄存器们,通过比较前一阶段与后一阶段指令寄存器中的信息,我们可以判定上述情况,即后一个指令是否在使用前一个指令还未将结果写入的寄存器:

为什么需要无视向
x0写入的情况?因为当我们向
x0中写入时,ALU计算得到的结果并非是最终的结果(最终的结果始终为0),如果这时我们还是把前一指令的ALU计算结果写入下一个运算单元的输入,那么显然是不对的!为了实现这个“无视”的操作,我们需要判断上图两个寄存器中对应位置是否为0.
最后借助mux将电路串联起来吗,如此一来我们就可以选择到底是否做一个等价的操作数替换(将分配给下一次指令计算的寄存器中的内容在ALU计算之前替换成已经在上一条指令中计算好的结果):
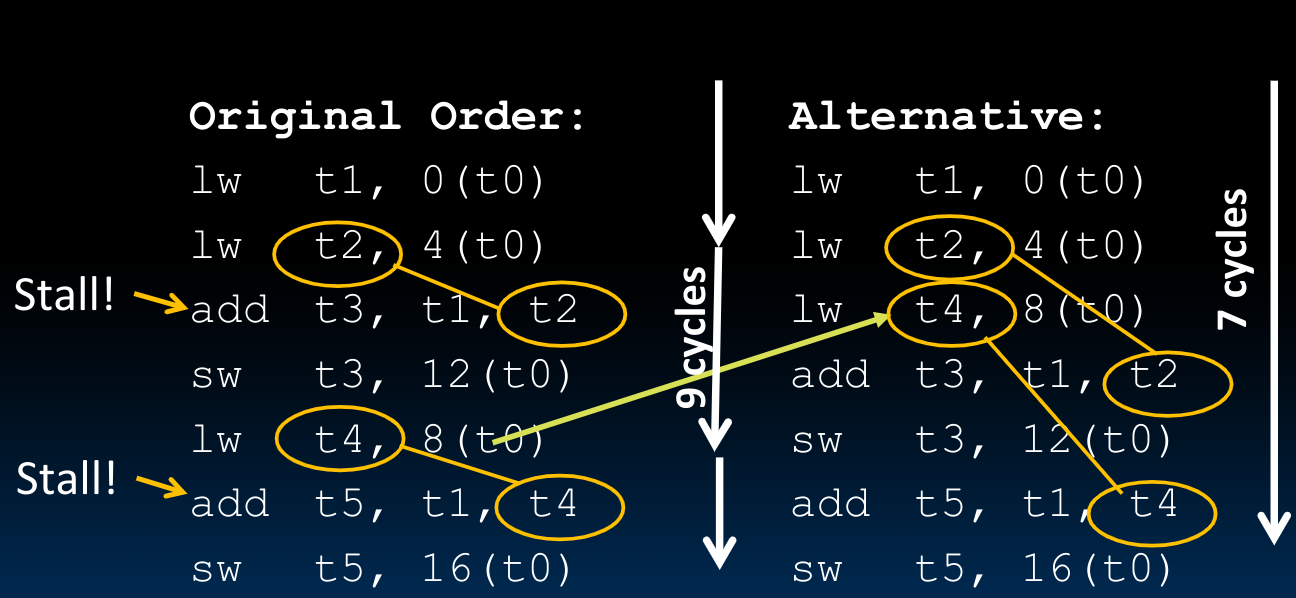
Load Data Hazard
当我们的指令序列中含有load并且遇到了hazards时,这需要我们单独处理。原因在于,我们无法实现先前所述的forwarding操作:
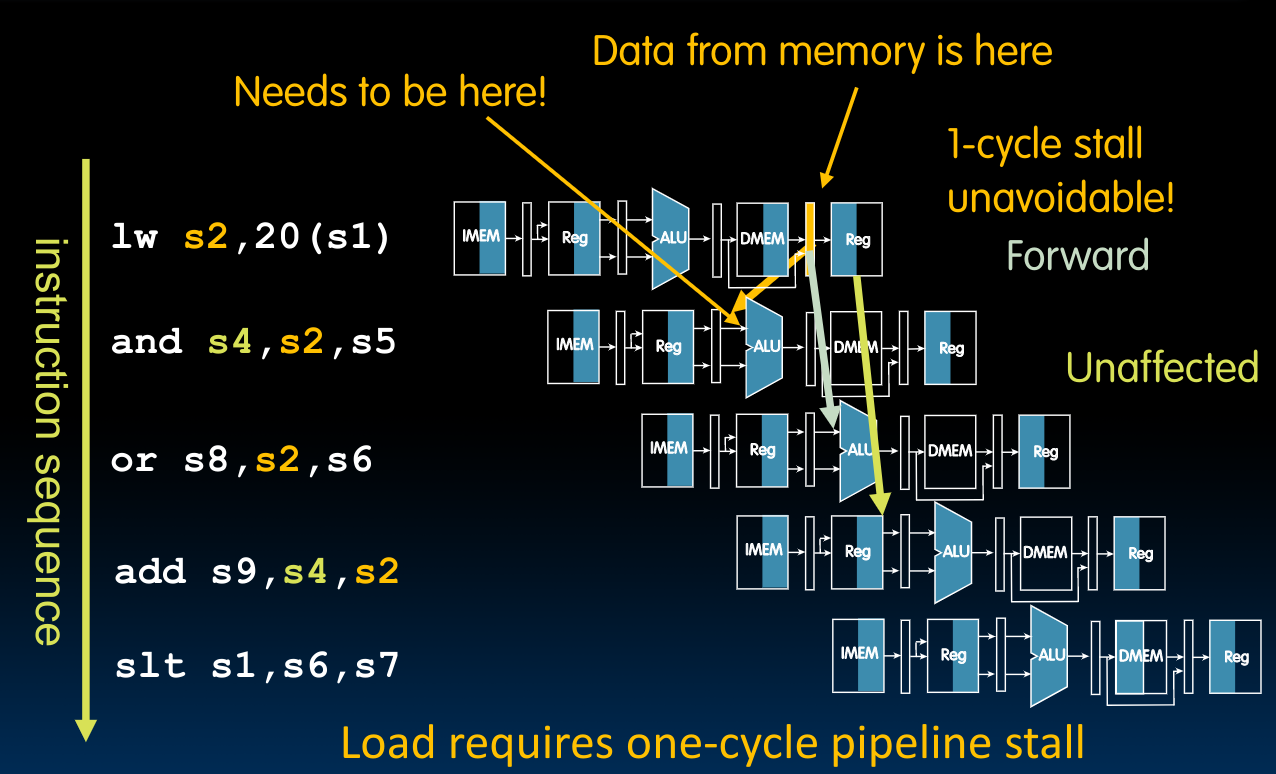
在上图中,出现了一个backward,这是不可能实现的。
所以我们最简单直接的处理方法就是stall pipeline,在stall之后,再执行第二条指令。
对于上图所示的情况,我们也有具体的行为定义:

上述的处理方式等效于添加一个第二条指令,即nop,但这种处理方式会毫无疑问的拉低性能。
如何将指令转化为nop?
首先我们需要检测到lw指令,之后在这一时钟周期内,将所有写操作的控制字都设置成不写入,比如寄存器的写、DMEM的写、PC的写等.
于是我们想到:
**可以将无关的指令放入load delay slot**来解决这个问题:
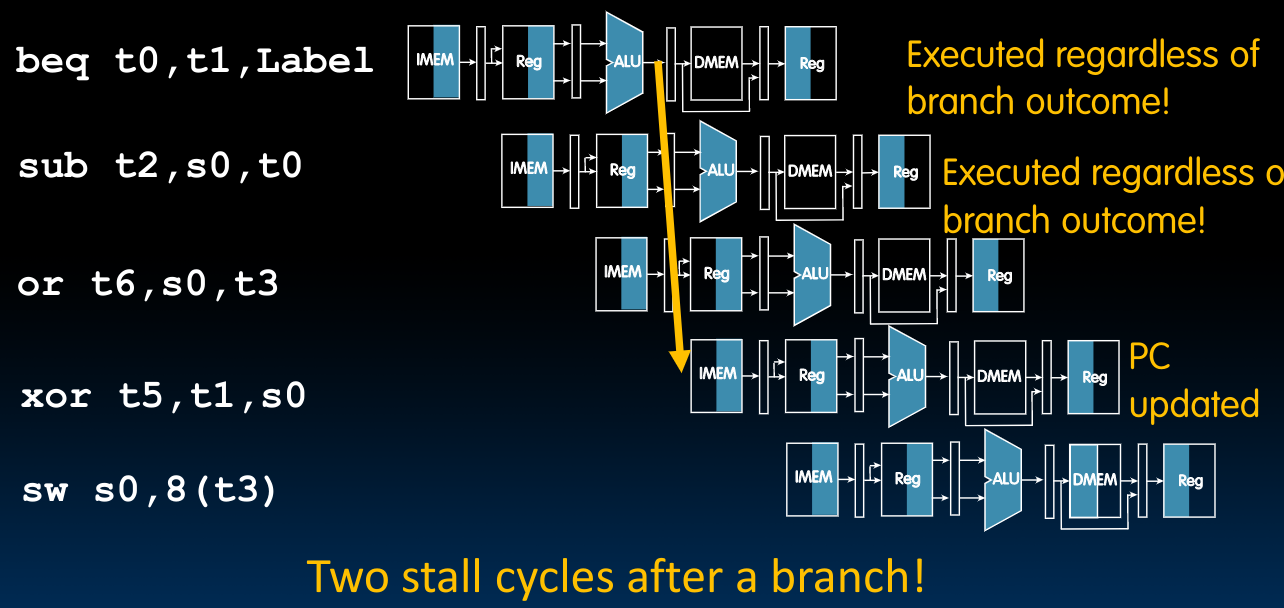
Control Hazards
这种hazards来源于分支指令:只有在分支指令执行完毕EX这一阶段后,我们才能够确定此时的PC是多少,这意味着在分支指令的紧随其后的两条指令,都有可能是错误的!(Executed regardless of branch outcome). 接下来的第三条指令则是正确的,因为此时我们可以根据**已经更新的PC**来确定到底执行哪一条指令:
一开始想到的处理方法如下图所示:

也就是说,仅在taken branch时,将pipeline中的相关指令使用在上一节中介绍的相同方法转化为nop。
在当前的情景设置下,我们有50%的几率判定失误,因为此时我们的策略是先去执行紧随其后的两条指令,如果后来发现不对,再将他们改成nop,于是为了提升性能,我们想做一个branch prediction——只有当branch prediction错误的时候,才flush pipeline.
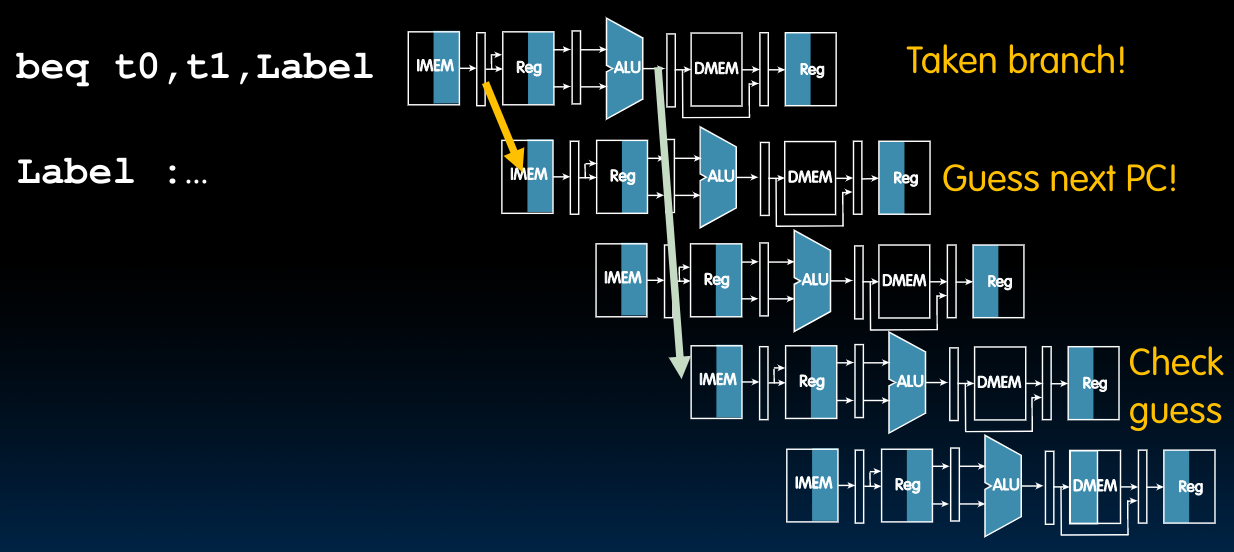
需要注意的是,使用分支指令的大多数时候都是想做一个loop,于是最简单的branch prediction正是依托这种想法:如果我们上一次执行了分支,则继续执行分支,这大大提高了我们的判定准确率(当然还有更复杂的机构我们可以选择)。关于branch predictor,我们在后续的cache部分会做更详细的介绍。但总而言之,这是一个研究热点问题,并且对于处理器的性能表现起到了至关重要的作用,在CS 152这门课程中将会介绍一些应用的相关技术。
在上图中,我们首先经过预测之后决定执行分支,并在两条指令之后通过比较PC的预测值与真实值(将ALU结果传入)来确定是否要将前两条正执行了一半的指令设置成nop.
Superscalar Processors
总得来说,提升处理器性能的方法有三种:

需要注意在使用pipeline时,越多的pipeline将带来更大的hazards可能性!这可能会导致最终需要的CPI大于1.
对于
pipeline操作,当指令极多时,假如不存在任何hazards,那么CPI将无限趋近于1,
什么是superscalar Processor?就是在处理器中安放多个不同的处理单元,比如add,lw,sub等等,在每个处理单元中pipeline执行指令(multiple pipeline),这一操作允许我们在同一时刻执行更多指令,故可以有CPI<1的结果。这时,我们可以用IPC来描述结果。
为了将指令放入不同的处理单元执行,我们需要Out-of-Order execution:



disc08
- latency(延迟): the time for one instruction for finish
- throughput(吞吐量): the number of instructions processed per unit time
当我们考虑pipelined Datapath时,关于EX段的最短时间计算——在ALU计算单元完成之后,传出的数据会立即被传递到PC之前的mux处,从而我们可以得到正确的下一条指令的地址。(这也是B format的运作流程之一)详见Performance Analysis讨论.
- Why is the speedup of pipelined datapth is lees than what is expected?
- The necessity of adding pipeline registers, which have clk-to-q and setup times;
- The need to set the clock to the maxmium of the five stages, which takes different amount of time;
Because of hazards, which require addtional logic to resolve, the actual speedup would be even less.
Caches
Binary Prefix
本部分内容见课件。
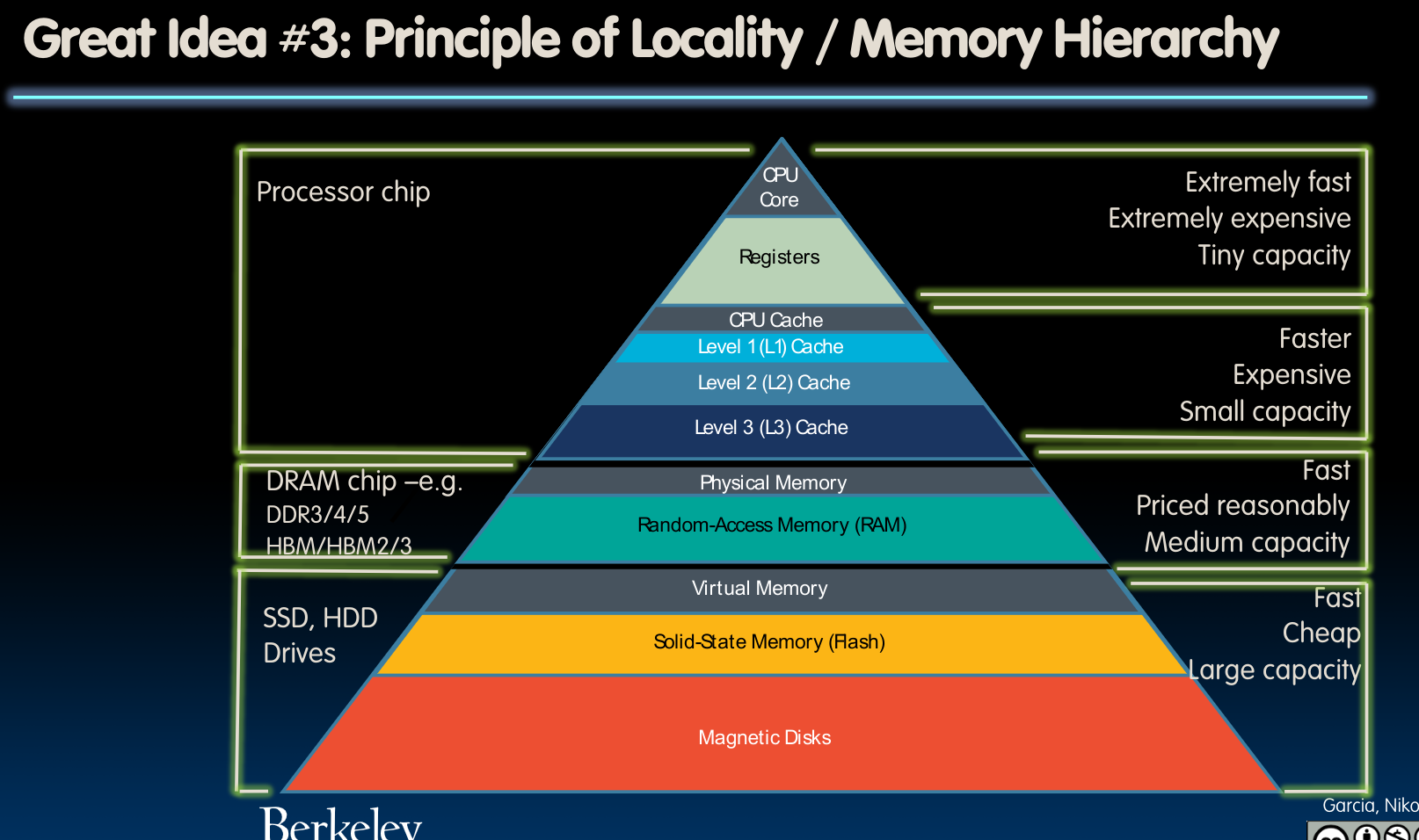
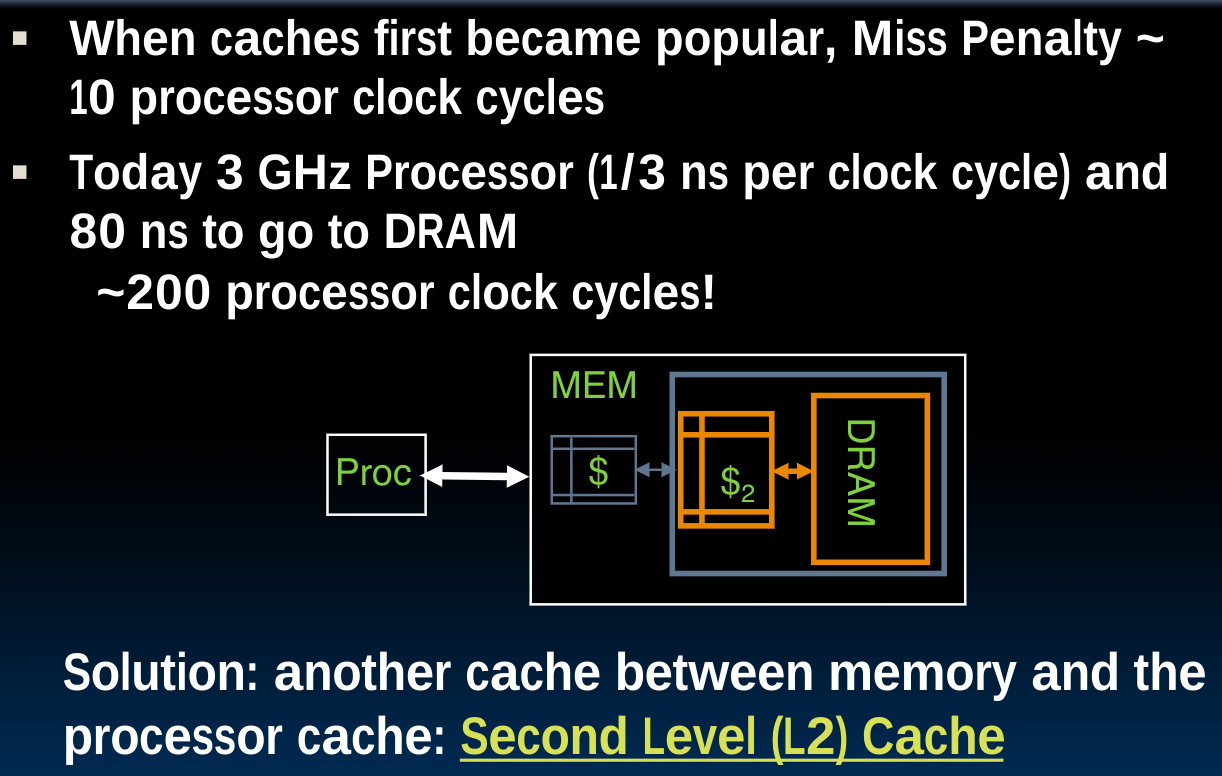
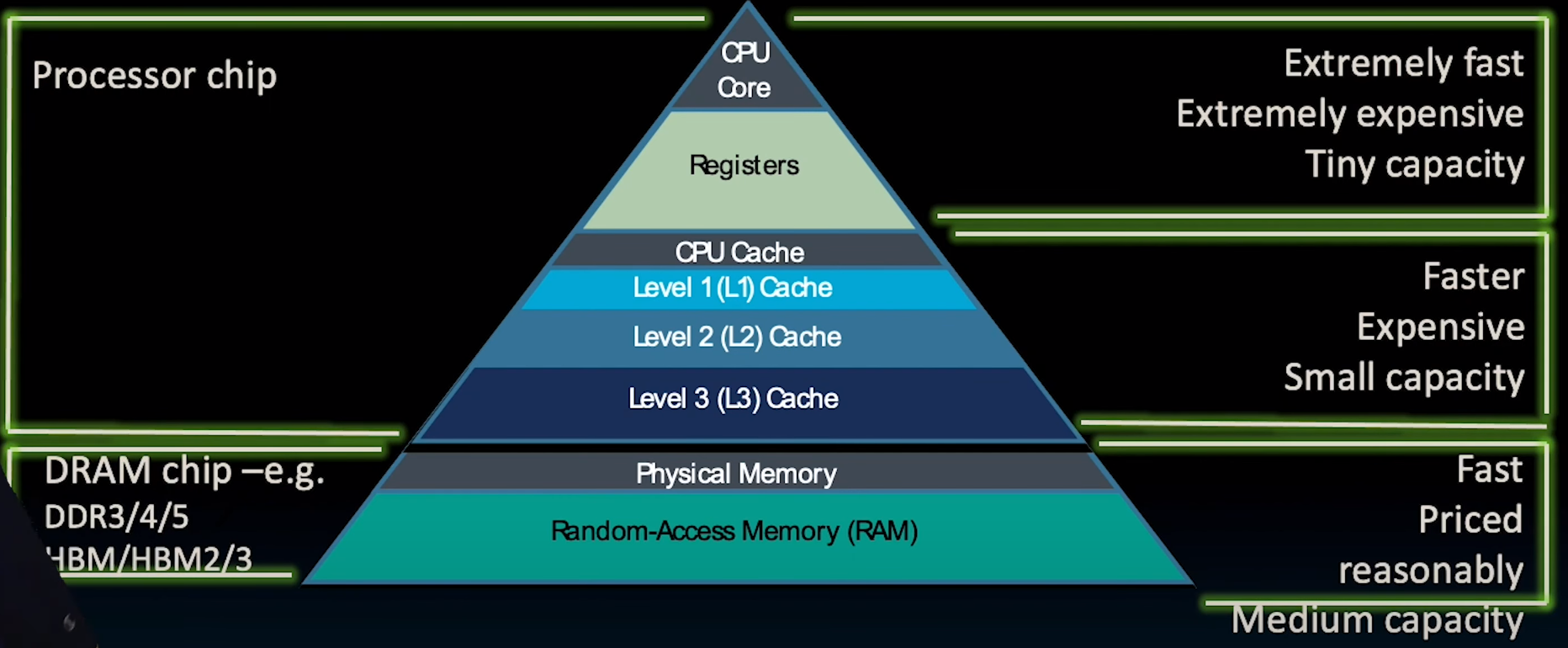
Memory Hierarchy
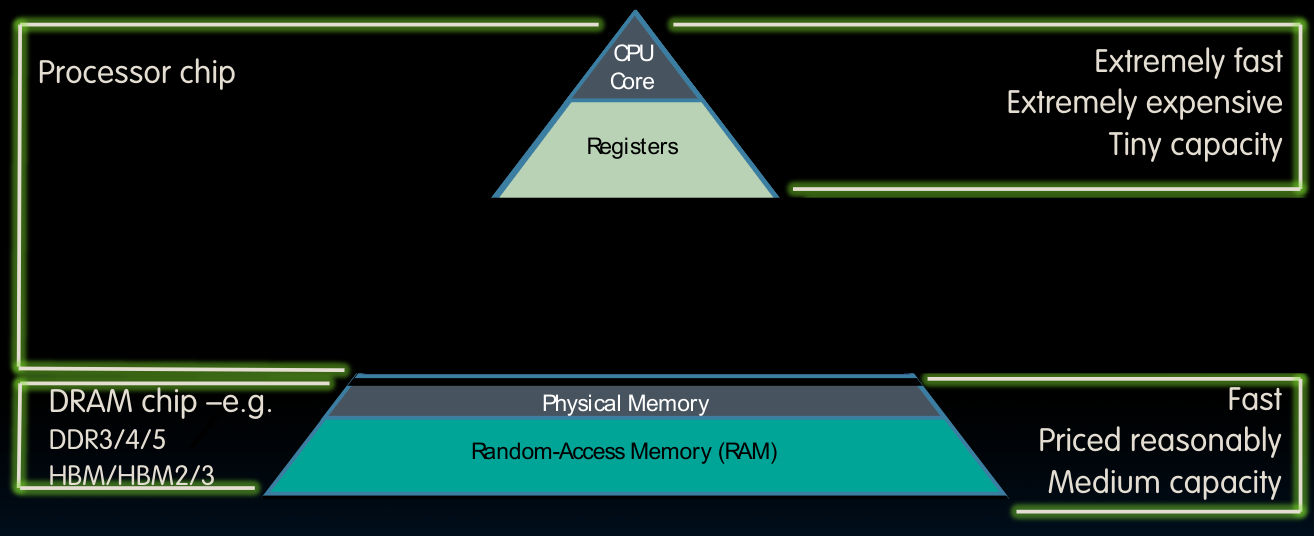
上图中空缺的部分就是cache,对于绝大多数的处理器来说,他们具备独立的instruction cache与data cache.一般来讲,cache都会与cpu集成在同一块主板上。而距离cpu越远,则速度越慢,但相应地可以具备更大的储存量。
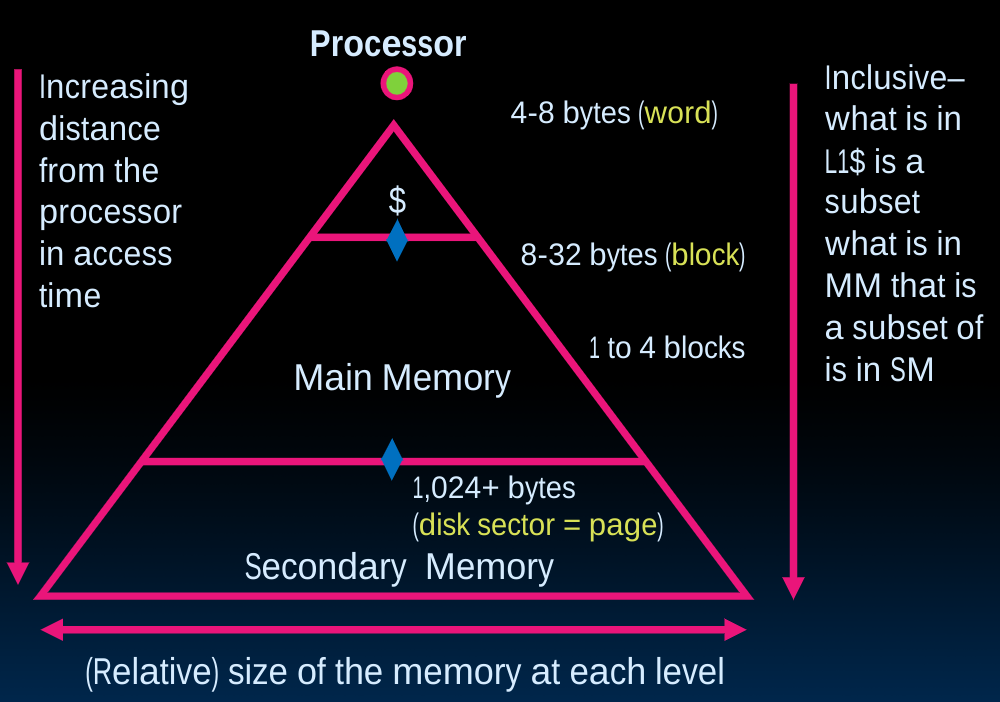
在这幅图中,我们留意到不同的处理器内存层级,需要注意它们inclusive的特性,即上层是下层的subset.具体的讲,memory即DRAM是disk的子集复制品,cache又是memory的子集,寄存器中的内容又是把cache的内容复制进去(这一点在前几个章节的Datapath中我们已经看到)
在CS基础课程2的博客中,我们介绍了loader的作用,正是将可执行文件从disk复制到memory里。
Locality, Design, Management
cache的工作原理基于如下两大特性:
- Temporal locality
- Spatial locality

如上图所示,对于temporal locality,我们保存了最近使用的数据在距离处理器很近的位置;而spacial locality则基于我们很有可能使用刚获取的内存为止附近的地址中的资源的想法,将邻近的内存块储存到cache中。
How is the Hierarchy Managed?


Direct Mapped Caches
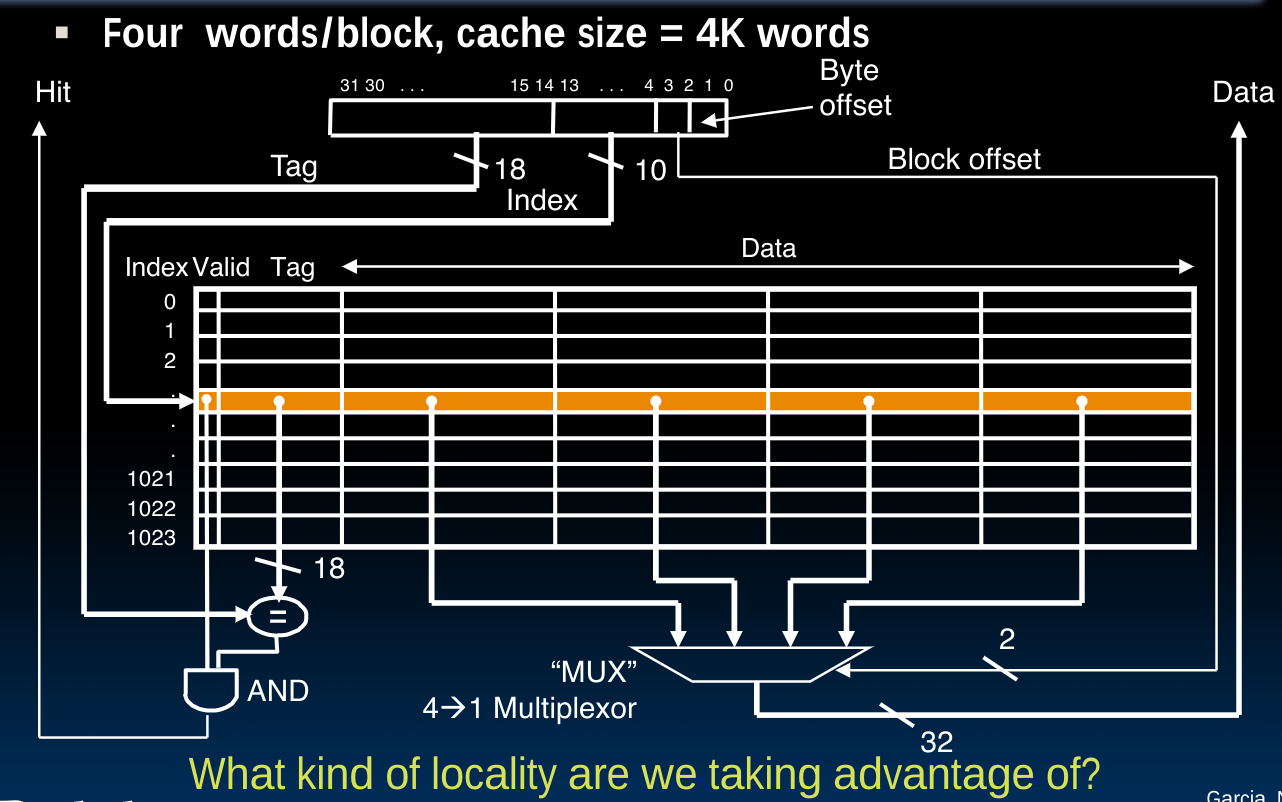
在这种cache的表示模式中,每一个内存地址都与cache中的一个block相关联。block是类似于寄存器与内存之间的最小传递单位word一样的存在:
Block is the unit of transfer between cache and memory.
在进行cache的相关计算时我们应当把cache画成和memory一样宽度来方便后续计算。
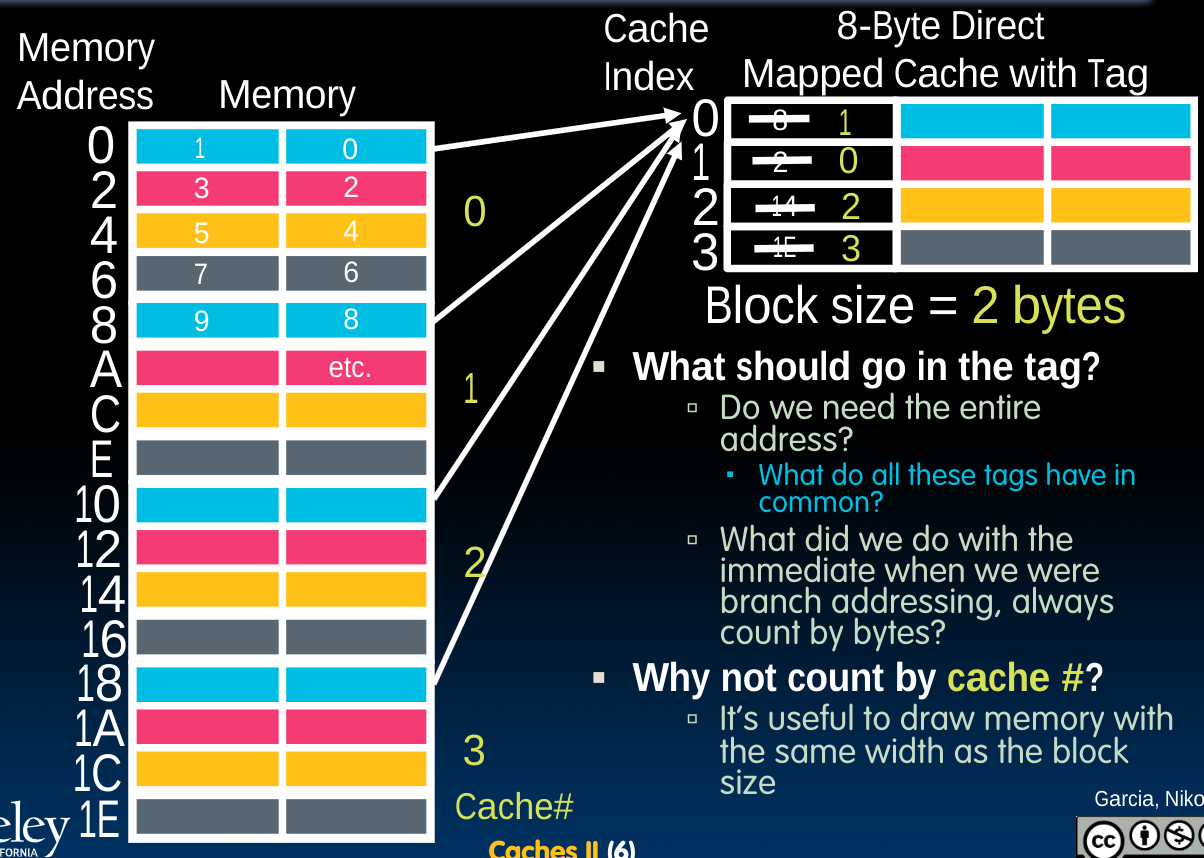
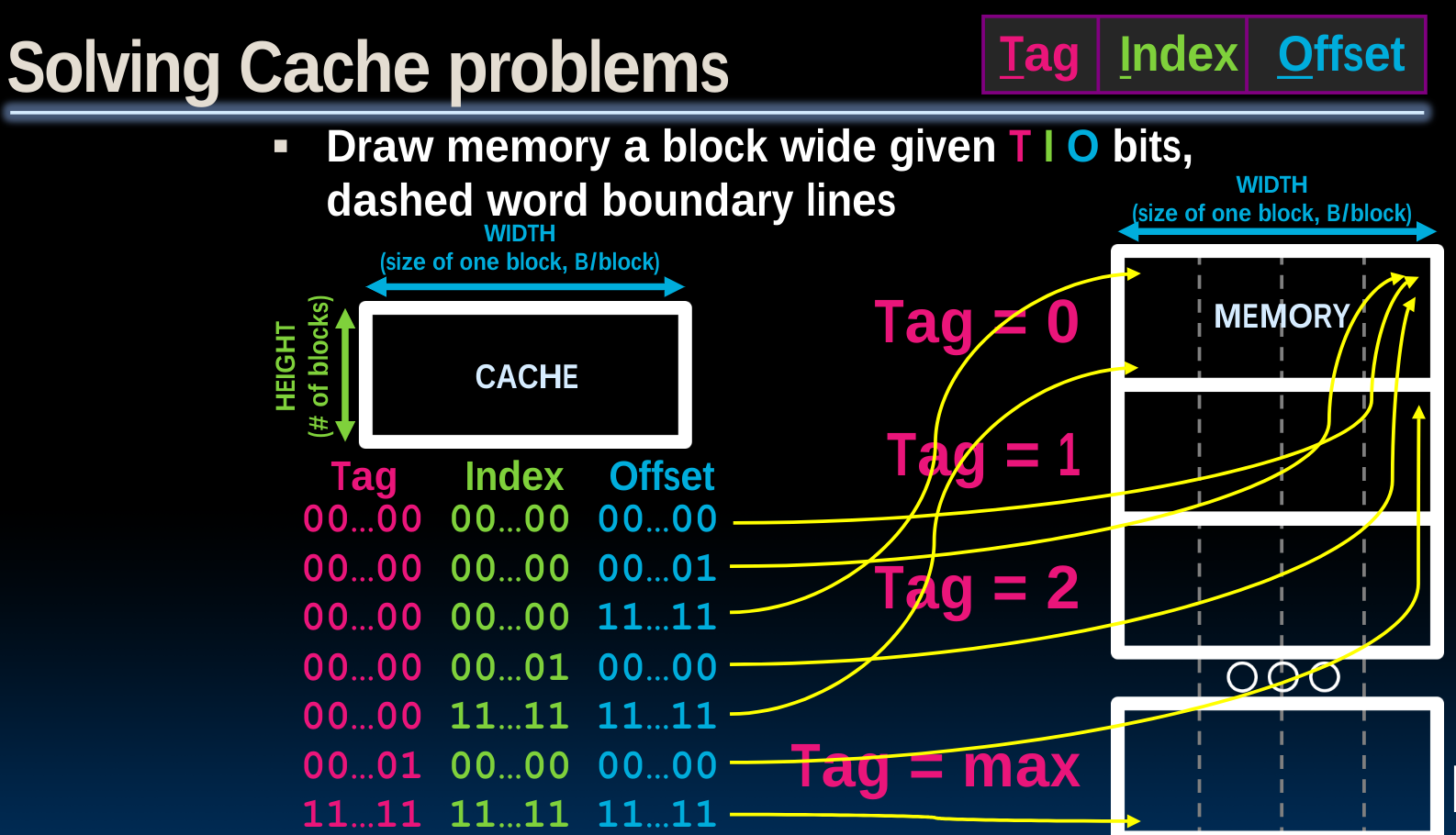
我们将memory按照cache的大小划分为0,1,2,3……个区域,每个cache中又包含了几个block。这样做的目的是尝试在cache与memory之间建立一种映射,使得我们可以通过内存地址判定出他应当存放的cache位置;反过来也可以通过cache位置判定出数据来自于哪个内存地址中。
而我们发现,由于对于一个固定的cache,其行和列也是一定的,所以我们想到为了完成上述这种映射,并不需要把内存地址完整的记录下来,比如对于想储存8,2,14,1E的这种情况,我们可以省略后几个bits,因为内存地址中后边的几个bits在当前的模式下会表示数据将会位于cache的哪一行和哪一列。而这些行列对应的储存位置将保持固定,如图中不同颜色所示。
所以我们需要记录前边的一些bits,从而在cache中保存内存地址的所有信息,完成完整的映射。这些bits即上图开始的1,0,2,3,称为tags。

于是我们可以将内存地址划分为三块:
- tag
the remaining bits after offset and index are determined; these are used to distinguish between all the memory addresses that map to the same location
- index
specifies the cache index (which “row”/block of the cache we should look in)
- offset
once we’ve found correct block, specifies which byte within the block we want
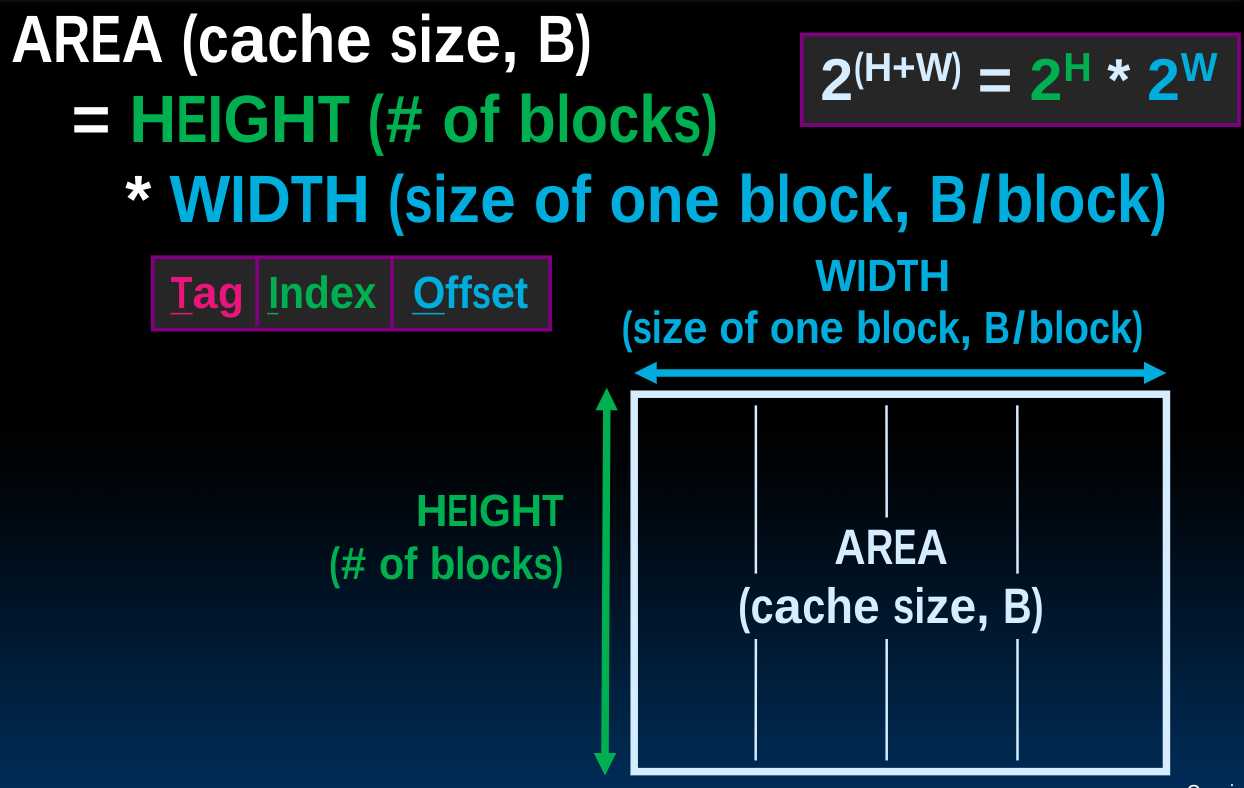
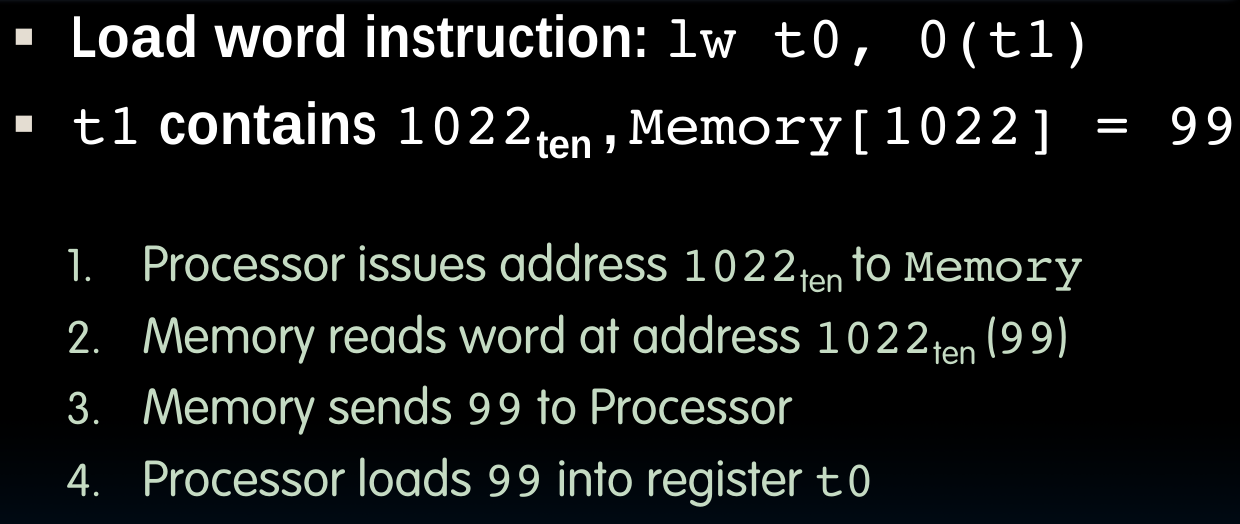
Memory access with/without cache
无论内存的获取是否经由cache,我们先前设计的Datapath都可以适用,从内存或者cache中获取数据的过程对于processor来说是一个generated process.当不使用cache时:
如果使用cache:
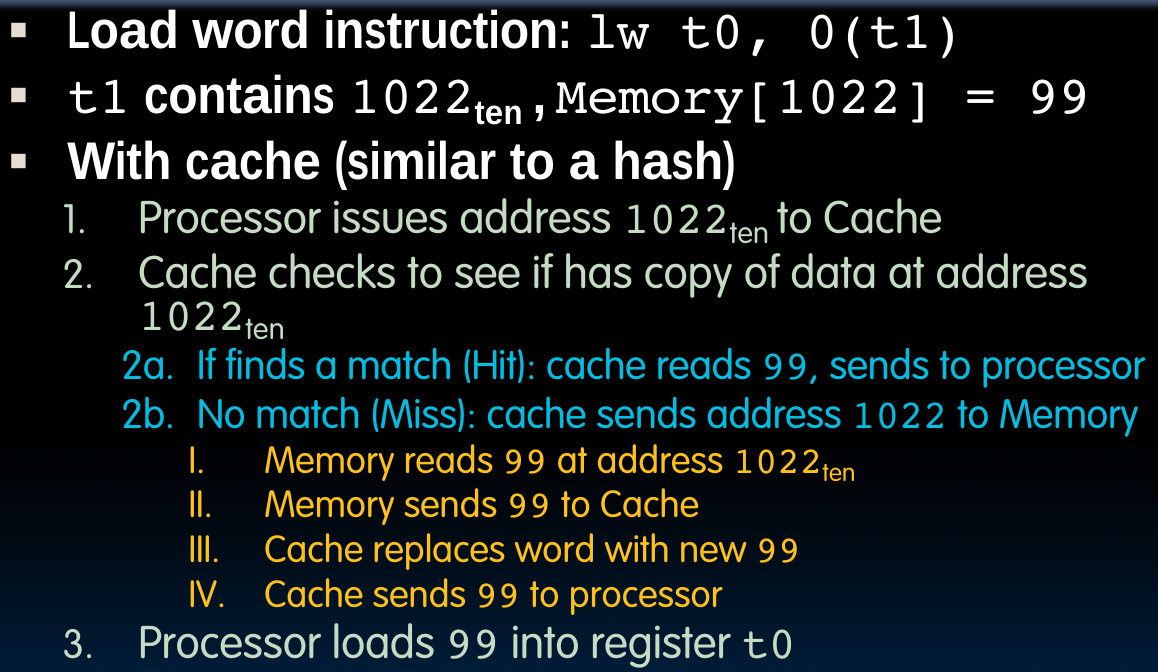
处理器会把地址交给cache,cache会首先检查它是否存储了指定地址对应的block,如果没有,再去内存中读取数据并存入cache中,最后由cache发送数据给处理器。
Cache Terminology


access可以被理解为find & retrieve.
需要注意的是,这里的Miss penalty本意并非replace,而是get:
Miss Penalty refers to the extra time required to bring the data into cache from the Main memory whenever there is a “miss” in the cache.
需要注意的是,如果发生cache miss,我们需要首先从内存中取出数据放入cache,之后还需要一次Hit才行,所以miss penalty要从total delay time中减去一个Hit time.
而Hit time的计算则需要加上tag comparison的时间。
最后再来解决一个问题,即当一个新程序开始运行时,即cold cache,我们如何获知此时的tag entry是否合理?即使在执行了一些指令之后,许多block可能仍然是空着的。为了解决这个问题,我们想要给cache增加一个额外的Valid Bit:

The most common method is to add a valid bit to indicate whether an entry contains a valid address. If the bit is not set, there cannot be a match for this block.
该标志位为invalid的情况不仅仅有初始情况这一种,当我们面对coherence miss时,如果其他处理器内核更新了其中的cache内容,那么我们也要将其他的内核中的cache设置为invalid。这表明valid bit存在的意义可以被理解为“我们是否需要从内存中获取新的数据”。
Directed-map Read Example
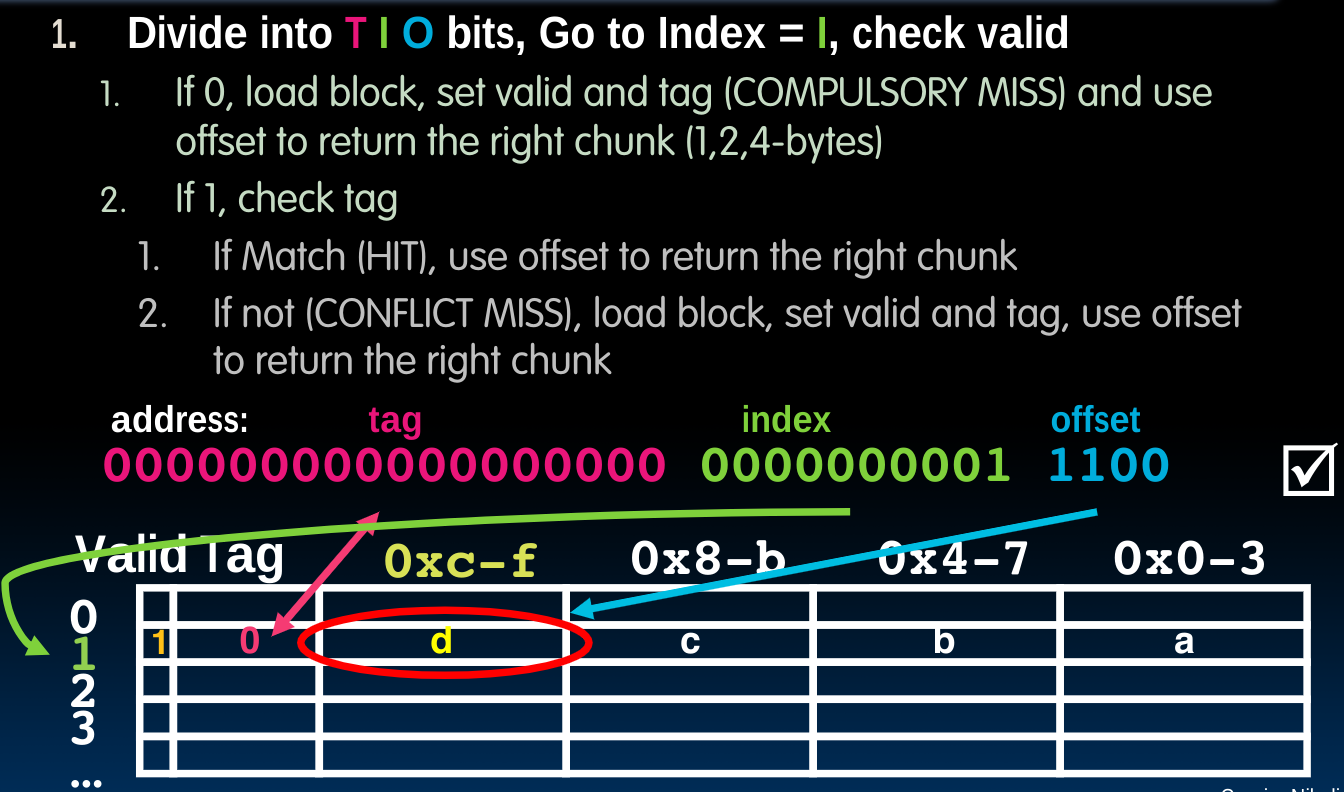
根据上图,从cache中获取数据分为如下几步:
首先根据index,找到可以存储的行,在该行上,判定Valid Bit,如果为0,则意味着这是一次compulsory miss,接下来需要从内存中取出数据放入cache中并根据指定的offset返回对应的数据(并把Valid Bit设为1)。如果Valid Bit为1,则我们需要判定tag是否产生了conflict miss(并重复上述的操作过程)。
Writes, Block, Sizes, Misses
我们使用如下的逻辑电路设计Multiword-Block Direct-Mapped Cache的写操作:
可以看到,判定是否cache hit的方法是将tags与Valid Bit做and操作。在右侧,通过一个mux选择出需要的数据(在哪个offset中)。
What to do on a write hit?
有两种方法实现写操作:
- Write-through
我们仍然把memory当做目标点(终点),所以不仅要更新cache也要更新memory.
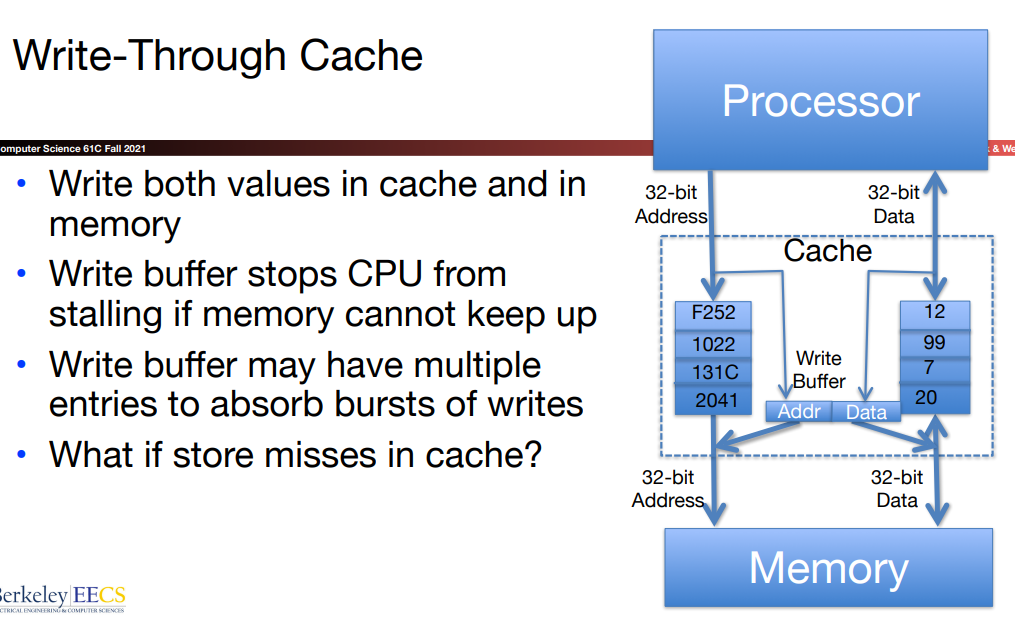
使用write-buffer的原因如下:
TLDR The write buffer makes the machine faster, because the program doesn’t have to wait until data is written back to RAM.
When a program reads from memory, and the data is already in the cache, it is called a cache hit and the program moves on.
When the data is not in the cache, the data is read from RAM and put into the cache. This is called a cache miss.
The hardware chooses a cache location for the new data. The previous stuff in that cache location (the cache is always full) is called the victim.
If the victim data has not been written, it will be the same as the data in RAM for that address. This is called a clean victim or a clean miss.
If the victim data has been written since it was originally put into cache, it may be different than the data in RAM for that address. In order to not lose those changes, the victim must be written back to RAM. This is called a dirty victim or dirty miss.
Obviously, you have to write the dirty victim data back to RAM before you overwrite it with the new data coming from RAM (for a different address), but if you do the memory write first (for the victim data) and the memory read (for the new data) second, the program will have to wait twice as long.
Smart people realized that you don’t have to do the write first. The victim data was chosen to be the victim because it wasn’t being used by the program. This idea led to the write-buffer. The victim data is not immediately written back to RAM, it is stashed away in the write-buffer and then written back to RAM later as time permits.
This lets the hardware do the memory read for the new data first, which speeds up the program because it doesn’t have to wait longer for a dirty miss than it does for a clean miss.
简单来说,write-through下的write-buffer的存在允许系统不需要先等待数据被完全写入内存再将数据读入对应的cache位置。
- Write-back
这种方法,我们将cache作为一般情况下的最终目标区域,这意味着我们允许memory与cache的数据可以不同(allow memory word to be "stale")。而正是为了辅助我们判定两者的数据到底是否相同(可以存在向cache中存储了恰好与memory相同数据的特殊情况),以此决定是否需要将cache的数据复制回memory中,于是我们增设一个dirty bit:
- indicate memory & Cache inconsistent
- needs to be updated when block is replaced(cache only writes data up the hierarchy when a cache line is evicted)——…OS flushes cache before I/O…(then the
dirty bitwill be set to 0)
Write-back means that on a write hit, data is exclusively written to the cache. In addition, after the write, the dirty bit for the block that was just written becomes 1 (mental check: what does having a dirty bit of 1 mean?). Writing to the cache is quite fast, so the write latency in write-back caches is usually quite small. However, when a block is evicted from a write-back cache, if its dirty bit is 1, then the memory must be updated with the contents of that block, as it currently contains changes that are not reflected in memory. Thanks to this, write-back caches tend to be more difficult to implement in hardware.
当然,这两种方法存在Performance trade-off:

使用write-back策略时,如果write-hit,则不需要再访问内存(0),如果write-miss,则需要从内存中读取新tag的block更新cache,此时看dirty-bit,若为0,则无需将cache内容写入内存(1),否则需要更新内存中的内容(2).
除此之外,在lab 7中还提到了一个模式:
- Write-around means that in every situation, data is written to main memory only, kind of like an opposite version of the write-back policy. An important thing to keep in mind is if the block we just updated in the main memory is also in our cache, then we need to change the cache block’s valid bit to invalid. This is because our cache no longer has the most up-to-date memory. In addition, under the Write-Around policy, there is no such thing as a write-hit, as it effectively does the exact same thing as a write-miss.
When write miss:

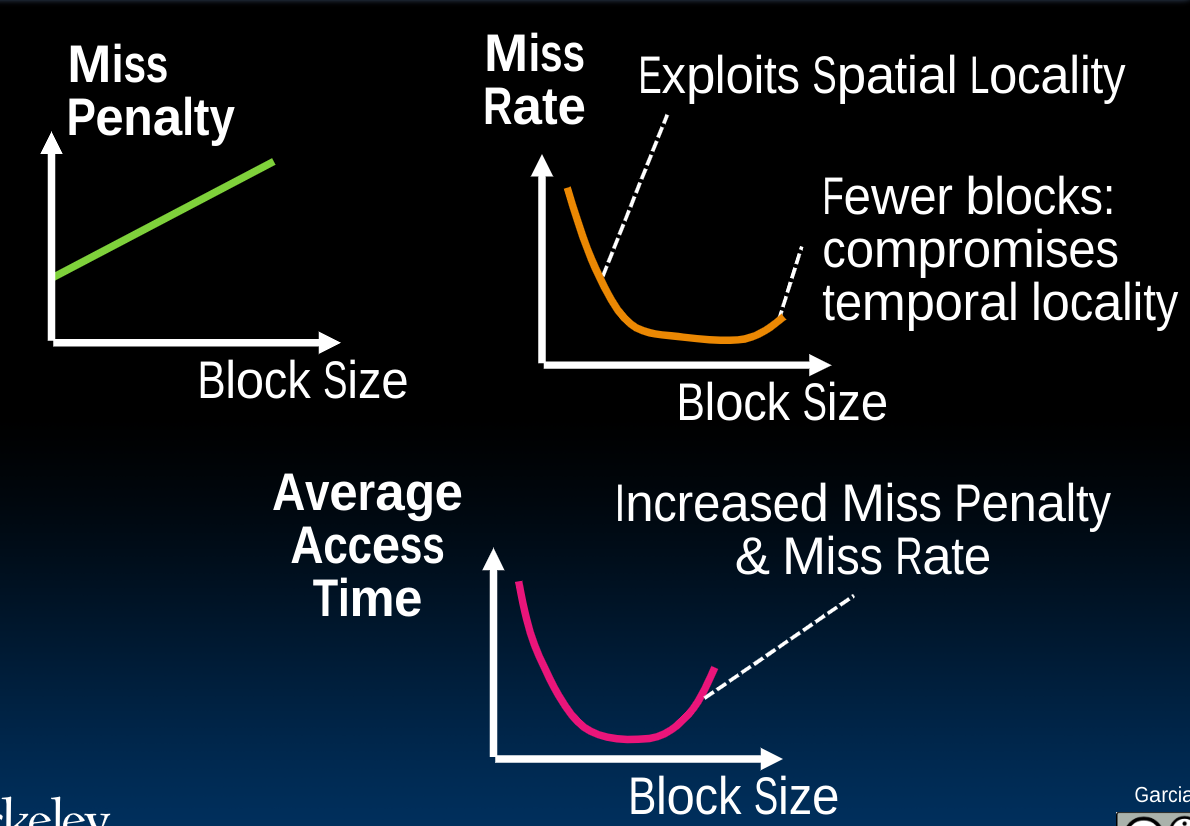
Block Size Tradeoff

关于过大的Block size带来的负面影响,首先是因为Block中的元素太多,所以必需耗费更长的miss penalty.另一方面,当Block size接近Cache size时,比如可以假想一种极端情况,即One Big Block:

这意味着基本没一次取数据都会发生conflict miss,这被叫做Ping Pong Effect.
随着Block size的增大,miss rate首先会减少,这是因为更加充分地利用了Spatial Locality,在这之后它便会开始增加,而这正是由于上述原因,即趋近于Cache size,这导致temporal locality几乎失效。
如果我们综合考虑Miss Penalty与Miss rate,以及两者的乘积Average Access Time,则会得到如下的曲线图:
Fully-Associative Caches & Type of Cache misses
Fully-Associative Cache的思路很简单,就是想要避免conflict miss,故而在Memory address fields中取消了Index的部分,但同时这也意味着当试图读取数据时,我们必须在整个cache中比较所有tags(一般是并行进行),以寻找数据位置。
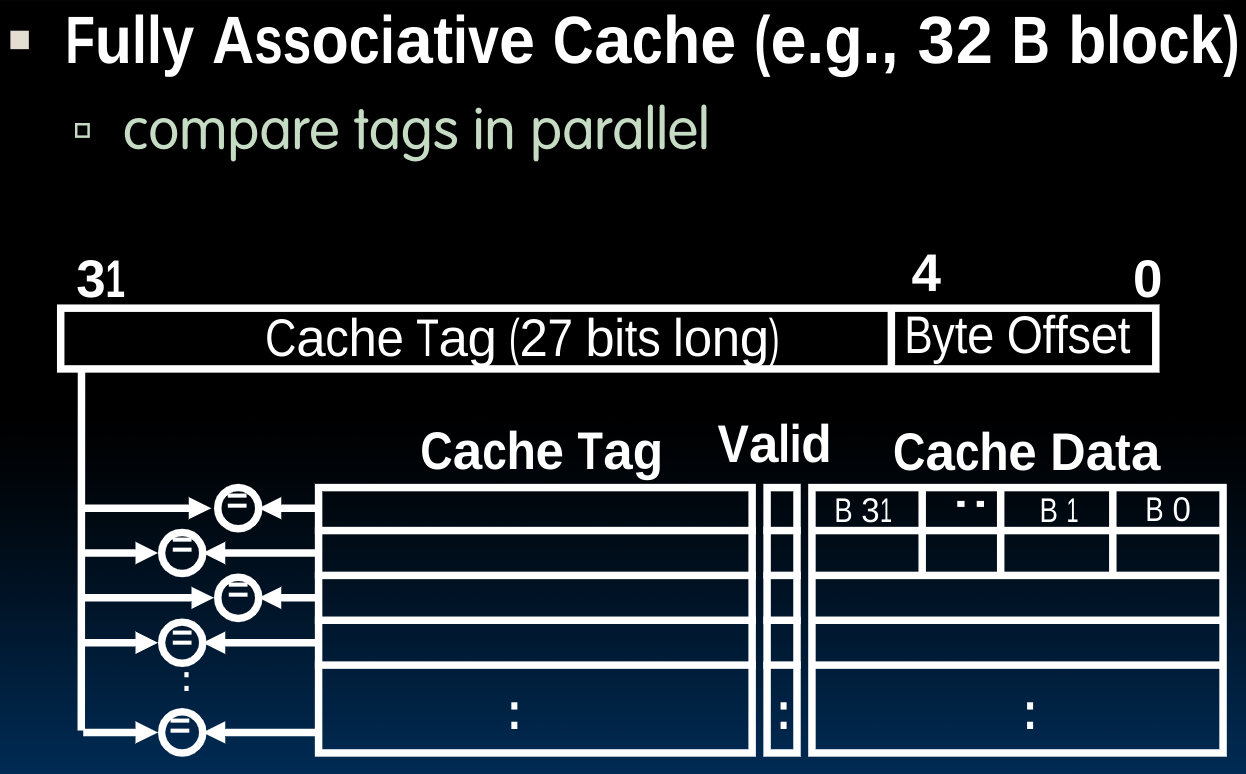
当然这种设计也是有优劣的:

Types of Cache misses

需要注意的是,我们使用valid bit的目的是应对empty cache的情况,也就是说当valid bit没有被设置时(程序刚开始运行),我们一定会遇到compulsory miss。但这并不意味着complusory miss仅有这一种情况。它的定义为第一次获取某块数据时,那么我们如何得知获取数据的历史呢?历史记录由硬件实现,比如我们使用的LRU替换策略就会记录历史所使用的block.
与之相对应的conflict miss则定义为:
A conflict miss occurs when a block is needed which existed in the cache before, but was evicted in favor of another block that had to be mapped to the same slot.

在这第二种解决conflict miss的方法里,就是我们先前描述的Fully-Associative Caches。

用简短的语言描述第三种,就是因为cache的容量不够导致的,如果我们将cache扩展到与memory相同的容量,那么就不会出现这种情况了。当使用fully-associative model时,由于cache的容量不够,便可能会产生该问题.
但实际上,上述的定义是十分模糊的,对于conflict miss与capacity miss,还是难以分辨,我们可以使用如下方法。
Cache Miss judgement
我们可以使用如下的算法来判定miss的类型:

需要注意的是,当我们遇到需要判定cache miss类型的题目时,一般需要同时画出original cache与相同大小的fully-associative cache(LRU).因为我们需要依据准则“If you hypothetically ran the ENTIRE string of memory accesses with a fully
associative cache (with an LRU replacement policy) of the same size as your cache, and it was a miss for that specific access, then this miss is a capacity miss.”
换句话说,在fully-associative cache里,无论cache的大小是多少,始终不会发生conflict miss.
compulsory miss的判定方法很简单,当且仅当我们检查了一块先前从未见过的block,那么就会遇到compulsory miss. 如果不是,那么我们就要从剩下两种miss中选一种。如果我们发现对应大小的
fullu-associative cache(LRU)中不会出现miss,那就是conflict miss;反之则为capacity miss.
当产生write miss时,我们有两种策略:
- Write-allocate means that on a write miss, you also pull the block you missed on into the cache. For example, for write-back, write-allocate caches, memory is never written to directly. This is because we are only ever writing to the cache (thanks to the write-back policy), and we only end up updating the memory upon eviction of the (potentially) updated block.
- No write-allocate means that on a write miss, you do not pull the block you missed on into the cache. Only memory is updated.
Set-Associative Caches
这种cache的表示方法将地址的Index域作为一个set进行看待:

在每一个set内含有多个block,当我们根据Index找到对应的set后,必须使用与fully-associative caches中相同的方法,即逐个比较set中每一个元素的tag,来确定数据的具体位置。(每一个set都是一个具有N个元素的fully-associative block)

对于这种设计方法来说,即使当使用2-way set assoc cache时,我们会避免很多conflict miss。三种cache的关系可以形容为:

4-Way Set Associative Cache Circuit
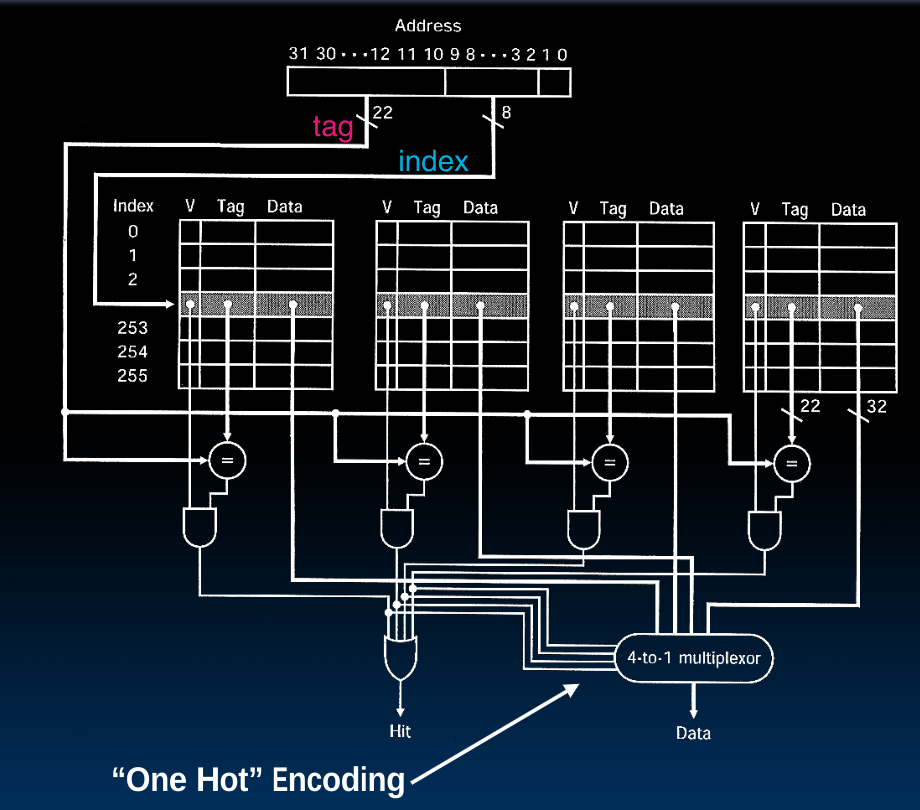
- 判定cache hit的方法是将四个结果用or组合起来,在每一个set内都需要进行N次比较,当然一般他们也是
parallel comparator. - 选取data时使用了一个
4-1 mux,需要注意的是他是4脚判定,而非先前我们见到过的2脚判定。这种方法叫做One Hot Encoding.
cost

Block Replacement
现在需要解决一个问题,当我们发现需要进行Block repalcement时,应当使用什么策略呢?
LRU(Least Recently Used)

这种方法借助temporal locality,硬件系统需要记住不同block的访问顺序,并在需要时将最先前访问的也就是最老的那一个排除掉,但这种方法在set-associative的N稍大一些时,需要保存的情况太多,为了能够记录下所有的可能情况,即$$N!$$,需要辅之以大量硬件。
FIFO
这种方法忽视access,直接将最先加入的那一个block踢出去。
Random
当temporal locality较小时,这种方法可能真的是一种不错的方法!
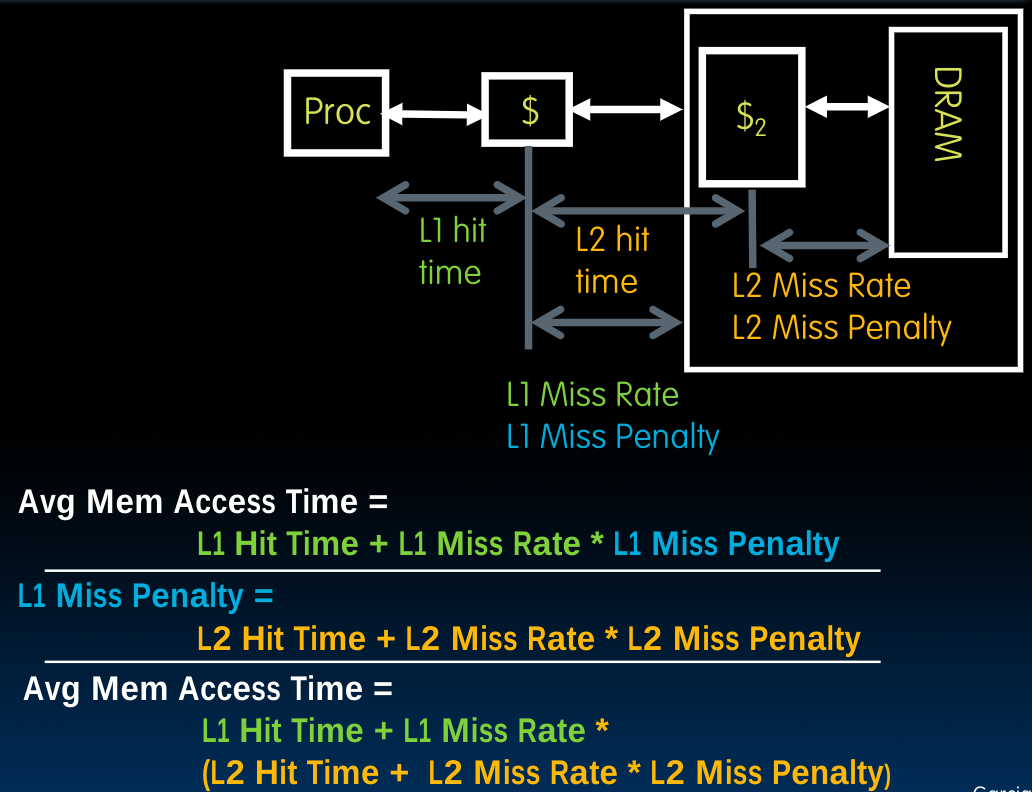
Average Memory Access Time (AMAT)
我们将它作为一种性能指标。

需要注意的是,$$Hit\ Time$$之后不需要乘上$$Hit\ Rate$$,原因是在miss并将数据从内存中取出来放入cache后还需要进行一次hit才可以把数据取出来。
于是我们思考,如何通过改变参数或者硬件的方式提升性能表现?
Increasing Associativity?

注意这里miss penalty的变化,这里的逻辑在于:替换策略与从内存或者上级高速缓存中取出数据的过程是并行的:如果在发现miss后,先要去寻找哪个位置是我们要替换的,再从内存中取出需要的数据,那么很显然,当associativity很大时(比如fully-associativity),我们自然需要更长的时间在对应的set中寻找替换的位置。但实际上,寻找替换位置(也可能根本不需要所谓的寻找,比如LRU硬件就会记录需要替换的位置,并在替换之后立即指向下一个LRU)的过程与从内存中取出数据的过程是同时进行的。
Increasing # Entries?

越大的内存速度越慢!使大存储器运行的更快总是要难一些的。
虽然内存越大,向其中写入的速度也可能会相应变慢,但对于miss penalty,根据课上教授的说法,向其中写入数据的同时我们可以向处理器发送数据(两者并行),故miss penalty不会被影响。
Increasing Block Size?

Hit time之所以基本不变,首先block size变大意味着我们在选择数据时需要一个更大的mux,不过这无伤大雅。同时更大的block size会带来更少的tag位数,这会减少我们比较的时间。
此时的miss penalty会变大,因为我们需要传输更多的数据。
Improving Miss Penalty
针对上边的这个公式,我们尝试降低miss penalty:
这种设计基于recursion,由于直接去一个很远的地方(memory)取数据需要很长的时间,所以我们想把过程分解,即增加几级新的cache。需要注意的是,这种设计会使得距离CPU越远的cache中存储的数据越好,即有更低的miss rate;我们可以用递归的思路来理解这个结论,比如在只有一层,即base case时,所谓的L2 cache其实就是memory了,当然,设计始终遵循越小的存储空间(越靠近CPU的存储是它的上一层级的子集这一原则).
Analyzing Multi-level cache hierarchy
递归的计算原则:
具体的案例在课件中给出了,我们会发现,通过加上一级cache,性能表现(AMAT)提升了将近四倍。
实际应用的cache常呈以下数据:

还有L3 cache,它是由多核CPU所共用的,并非如同前两级cache一样在每一个CPU核内都有.
Reduce Miss rate

我们使用如下公式计算global/local miss rate:


可以看到,在下方的公式中,整体的miss rate等于级联的local miss rate的乘积。
Cache Analyze
在软件层面,对于cache的了解可以帮我们更好的规划代码结构,比如对于如下的例子:

这种stride access在代码中经常出现。我们在lab 07中以及CSAPP中也看到过关于这部分优化的介绍。在谈到优化策略之前,先说以下可能出现所谓miss/failure的原因,并根据在树莓派上的实验数据得到一些相关结论。
Failure? WHY?

capacity miss会出现在数据容量大于cache容量时,这是一件很显然的事情。

除了capacity miss之外,如果我们在每一次将一个block的数据从内存搬运到cache后,只对它们进行一次原本需要的数据的访问,那么显然会造成spacial locality的浪费!这种情况的临界条件出现在:
$$stride*sizeof(int)==block\ size$$
试想如下情况:

虽然我们并没有向cache中输入足够将所有block塞满的数据量,但还是出现了miss. 因为这是conflict miss.我们的数据位置发生了重叠,需要进行eviction.
SHOW ME THE DATA!
在展示数据之前,先要明晰一些事项:

从一个抽象的认识上,我们知道L2 cache的容量或者类似于associavity之类的东西都要比L1 cache更大,但这里我们拎出两个重要的特性line size与associativity来看下为什么.
首先,从测试的角度来说,我们必须保证能够出现L1 miss, L2 hit这种情况。而无论是L1 cache还是L2 cache,数据都是从内存中取出或者是被处理器写入的。在这个前提下,加入我们遇到了L1 miss,那么就想要到下一级缓存中寻找数据,而如果下一级的line size或者associativity反而更小,那么在绝大多数情况下,也会发生L2 miss,这样一来,下一级缓存就失去了意义。
现在,来分析一下课程中给出的实验数据。
L1
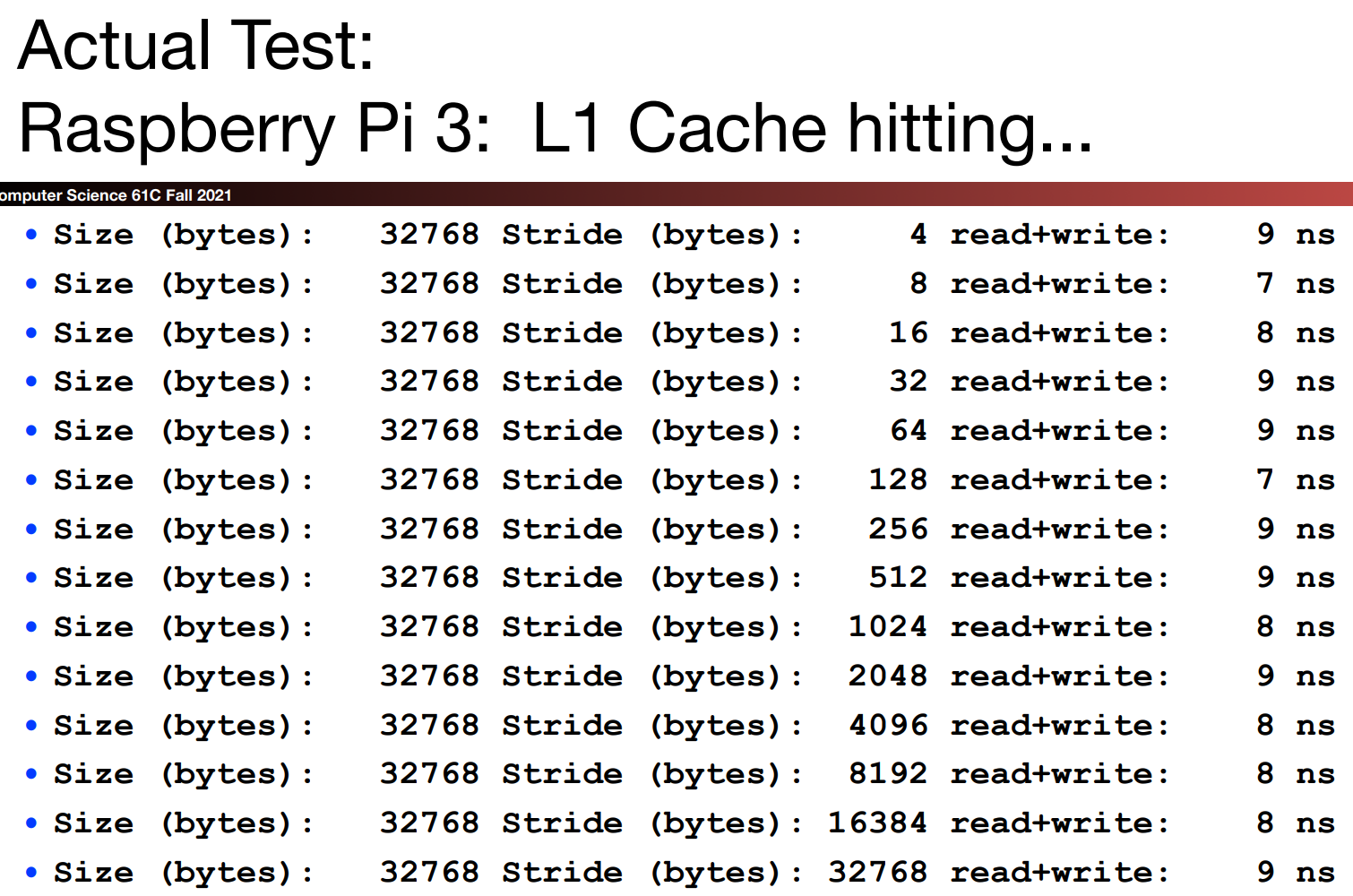

对于L1 cache,当array_size为32kb时,所有的AMAT均被控制在10ns以内,说明没有出现任何miss,说明此时还未达到cache size. 而在64kb时出现了多次miss(10ns及以上),故cache size为32kb.(一般来讲,cache size都是2的指数)
而在64kb的测试内部我们观察到,当stride在128bytes之前AMAT均被控制在10ns以下,不过这里的数据不是特别有说服力,因为测试时间过短,即使出现多次miss可能最终结果也很贴近。如果根据判定依据:当array_size为cache_size的两倍时,如果$$stride*sizeof(int)==block\ size$$,那么我们每一行的数据只被使用了一次,没有利用spacial locality,那么这张图会告诉我们block size大致为128bytes. 但基于AMAT过短的原因(8ns与10ns也很近,L2的存在一定程度上缓解了AMAT的变化),block size为64bytes也是有可能的。
而在这张测试数据图的最后,我们发现当元素个数为1,2,4时,均没有出现miss,但是在8元素处出现miss,说明这是一个4-way set associative cache.
从AMAT的变化趋势可以看出,一开始
stride很小,所以每次我们从内存或者下一级cache取回一个block的数据时,可以miss hit很多次(但是因为srray_size为cache size的两倍,所以之后会出现capacity miss)随着
stride的不断增加,超过了一个block的大小,我们每一次数据读写的间隔越来越大,这也意味着cache不会全部用完,如先前的分析所述,此时会产生很多conflict miss,读写间隔越大,conflict miss的可能性越高。直到,我们仅仅需要读写几次数据,这些数据可以被N-way set associative cache所容纳。
L2
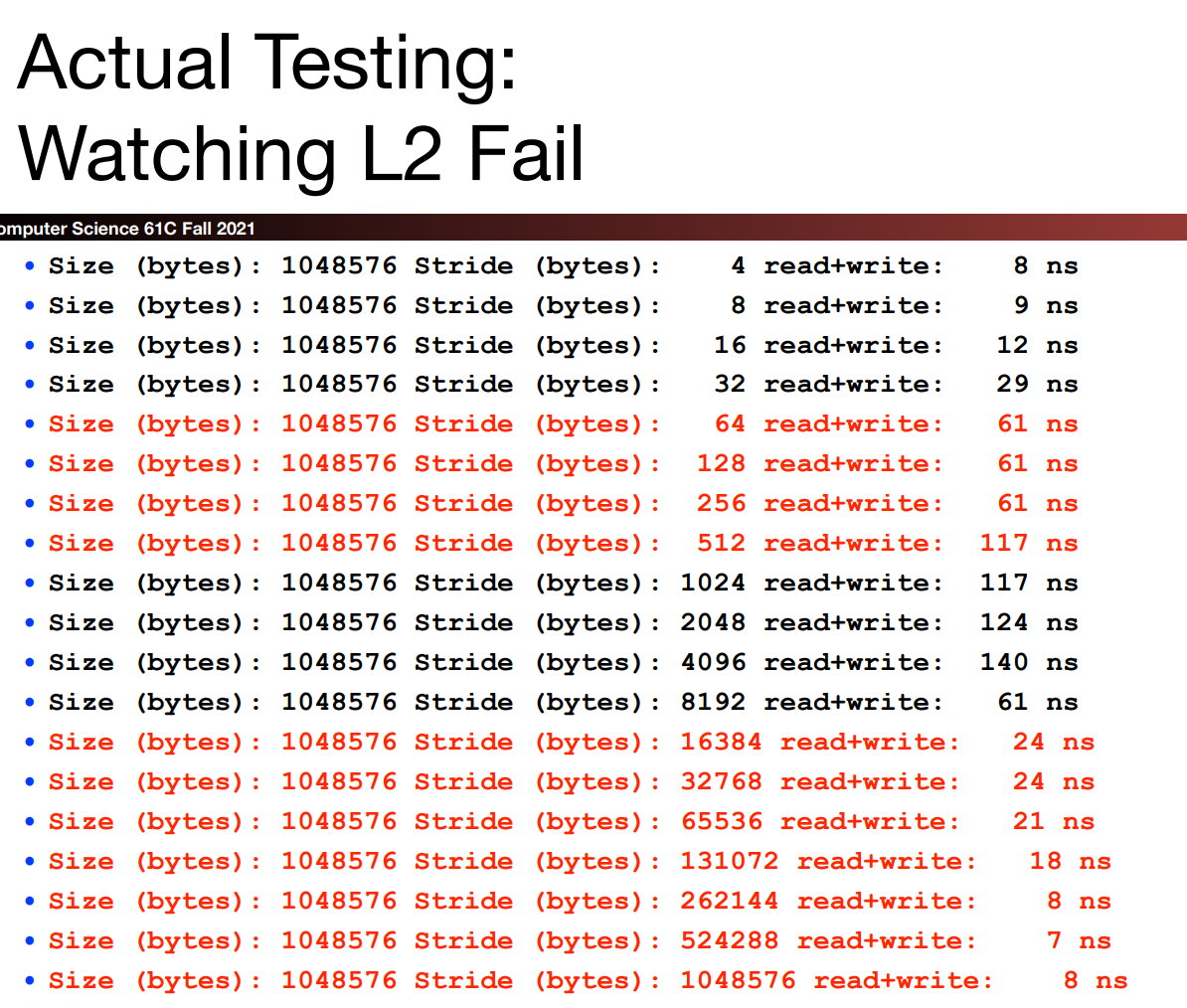
这组数据使用了1024kb的array_size,意味着在array_size为512kb时并没有出现L2 miss的情况,故L2的cache size为512kb.
我们可以更加清晰的看到当stride为64bytes时出现了一个明显的Fall Off A Cliff的情况,说明我们达到了每行只使用一次数据的最坏情况(no spacial locality)。而L1 cache与L2 cache的line size应相同,故两者均为64bytes.
随着stride的变大,根据我们对L1 cache的分析,会产生更多的conflict miss,于是处理器就会想要前往L2 cache中寻找数据(每一次内存传输的数据实质上并不止一个block的大小),一开始还是可以找到的,后来随着stride的继续增大,L2 cache中也找不到了,于是AMAT进一步增长。
Performance drops by an order of magnitude when you exceed the capabilities of the cache even by not that much!
最后的3行数据为L1 hit,4-7行为L1 miss, L2 hit. 于是我们可以猜测L2大概是一个64-way set associative cache.
但是事实果真如此吗?
Some complication technology
实际上,L2 cache并非64-way set associative cache。因为涉及到一些比较复杂的细节:

首先,对于内存的抓取并非真的完全按照我们所说的“每次抓取一个cache block”.而是每次抓取更多的内容,或者进行prefetching以更好地预备cache中的数据读写,其包括数据预取和指令预取,可以通过处理器硬件或者编译器软件实现,是一个较为复杂的主题。
其次,除了主缓存之外,我们还有victim cache.
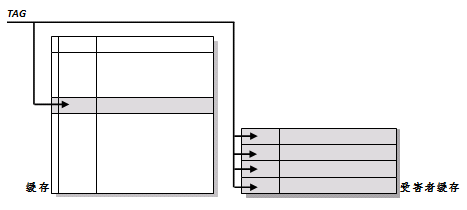
根据维基百科:
所谓受害者缓存(
Victim Cache),是一个与直接匹配或低相联缓存并用的、容量很小的全相联缓存。当一个数据块被逐出缓存时,并不直接丢弃,而是暂先进入受害者缓存。如果受害者缓存已满,就替换掉其中一项。当进行缓存标签匹配时,在与索引指向标签匹配的同时,并行查看受害者缓存,如果在受害者缓存发现匹配,就将其此数据块与缓存中的不匹配数据块做交换,同时返回给处理器。受害者缓存的意图是弥补因为低相联度造成的频繁替换所损失的时间局部性。
所以,实质上在树莓派中的L2 cache为16-way set associative cache,但是victim cache的存在让它看起来像是一个64-way set associative cache:

Loop! Improve Performance?
change innerloop stride
对于如下这样一个例子:
int j, k, array[256*256];
for (k = 0; k < 255; k++){
for (j = 0; j < 256; j++){
array[256*j] += array[256*j + k + 1]
}}
我们并没有在内层循环中很好地利用cache的spacial locality.而如果我们将它改为这样:
int j, k, array[256*256];
for (j = 0; j < 256; j++){
for (k = 0; k < 255; k++){
array[256*j] += array[256*j + k + 1]
}}
在内层循环中,stride从两个256变为一个0和一个1——很好的利用了termporal locality和spacial locality.
Blocking-out Data

在上边的这个二层循环中,如果数组B过大,那么会产生多次capacity miss.

我们可以将矩阵变成多个block,至于为什么这样做能够优化?CMU 15-213设置了更详细的CacheLab,从数据的角度出发详细分析这个过程。这里有一片较为详细的分析文章。但是大致可以总结为如下原因:
当我们面对一个很大的矩阵时,矩阵本身的维度是cache的block size的好几倍,假如cache size为8*8,array_size为16*16,如果我们使用朴素的矩阵转置算法,那么在在每一行转置位置超过了矩阵维度的一半时,矩阵B将会由于index部分在[0-7]与[8-15]的重合,在cache中发生多次eviction。
但是如果此时我们将矩阵分为四块,那么对角矩阵的转置将不会出现反复eviction的情况。
需要注意的是,如果array_size过小,则根本没有分块处理的必要,因为cache足够容纳整个矩阵,分块处理反而会增加处理时间。
而如果block size过小,则也不会起到很好的优化效果,原因是没有充分利用spacial locality.
我们也可以从数学的角度粗浅分析为什么blocking更好.
Some other caches
Branch Predictor

在先前control hazards的部分,简单来说,我们曾提到过branch predictor. branch predictor也是一种cache:

如果我们在该缓存区中没有找到对应的跳转地址,说明这是第一次遇到该跳转,针对这种情况,如果是forward branch则预测为not taken,如果是backward branch则预测为taken.
forward branch为一般的if跳转指令;backward branch为loop结构的跳转.
一个简单的branch predictor设计如下:

这里我们选择存储10个地址低位,由于在我们当前使用的RISC-V中,每个指令都是4byte,所以我们可以选择不存储最低的两位地址数据。我们在history cache中存储曾经跳转到的地址的低位,并设置一个bit表示先前是否跳转进入该地址。

我们可以在IF阶段进行branch predict,也可以在之后的ID阶段进行,显然如果在ID阶段预测,那么紧随其后的一条指令是无论如何也会被抓取的。
关于这里的stall数量的问题,需要注意这里的taken/not-taken指的是最后的结果,而并非我们的预测。
Branch Target Buffer
除了B format的跳转指令之外,我们还有J format的跳转指令,显然在这里,我们也会在pipeline中加载不必要的指令,所以最好也进行预测,以在一定程度上减少stall的几率:

首先,只要jal/jalr向寄存器ra中写入,我们就把下一条指令的地址PC+4写入一个维护的stack中。当我们意识到函数即将返回–jalr从ra读取并将x0作为目的寄存器时,就从维护的stack中读出顶层数据–一定会成功的预测返回地址,因为是非条件跳转指令,只要我们不超过stack的存储深度。
除了上述这种在读取ra内的返回地址时使用预测,在某些情况下,我们也需要在“jalr跳转到函数”–jalr ra t0的步骤,即上图中向ra写入数据时做预测:

在上图中,如果我们使用foo.bar()的调用方式(可以留意以下这里对virtual function table的使用方式),我们可以保存一个cache,里边记录先前跳转的函数地址。这种想法是基于“之前跳转过的函数地址,下一次可能还要使用”。我们通过将PC设置为这个cache中的函数地址来实现预测。
Cache and Multiprocessors

为了避免pipeline中出现structual hazards,在每一个处理器上都有独立的cache。现在问题来了,如果多个处理器想要访问同一块内存要怎么办?它们各自含有的cache应当做出什么样的反应?
读取内存相对简单,因为虽然不同的处理器内有独立的cache,但是它们都应当具有相同的内容(如果此时允许被读取的话)。如果我们想要向内存中写入数据,那么需要一些额外的操作:
Multiple Processors writing

我们需要一个coherency的理念,即当我们通过一个处理器向内存中写入数据时,在一小段时间后,其他的处理器应当能够获知:数据更新了。
为了达到这个目的,我们使用一种Broadcasting的技巧。

为了让数据可以在不同的处理器之间通信,我们可以让他们具备shared bus或者建立一种类似于计算机网络的传输数据结构。



由此引出一种新的cache miss类型,即coherence.
Coherence miss

coherence miss出现在当一个或多个处理器想要写入某块内存,但是正有其他处理器正尝试读取该块内存内容时,因为只要存在写入,那个其他cache上的该块数据就应当被标记为invalid.
这也是为什么在现代CPU的设计中会存在一块很大的shared cache的原因!这避免了出现大量coherence miss的情况。
Incoherence miss

所谓working sets,就是在程序运行时“真正需要的(actually really using)”内存大小,而不是系统分配给的内存大小(或者说是程序请求的)。
Actual CPU

Operating Systems & Virtual memory & I/O
在本章节中,我们将该Memory Hierarchy补充完整:
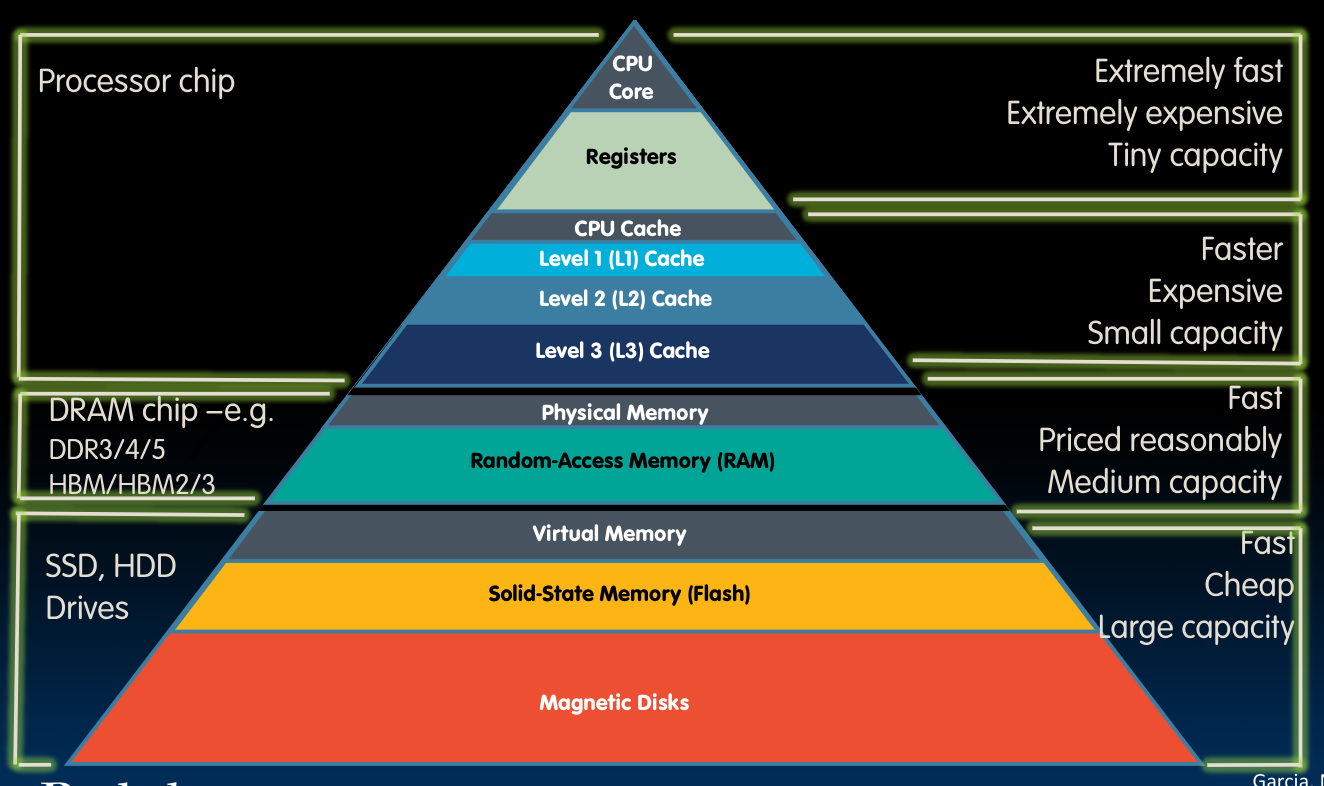
同时,对I/O交互有基本的理解:
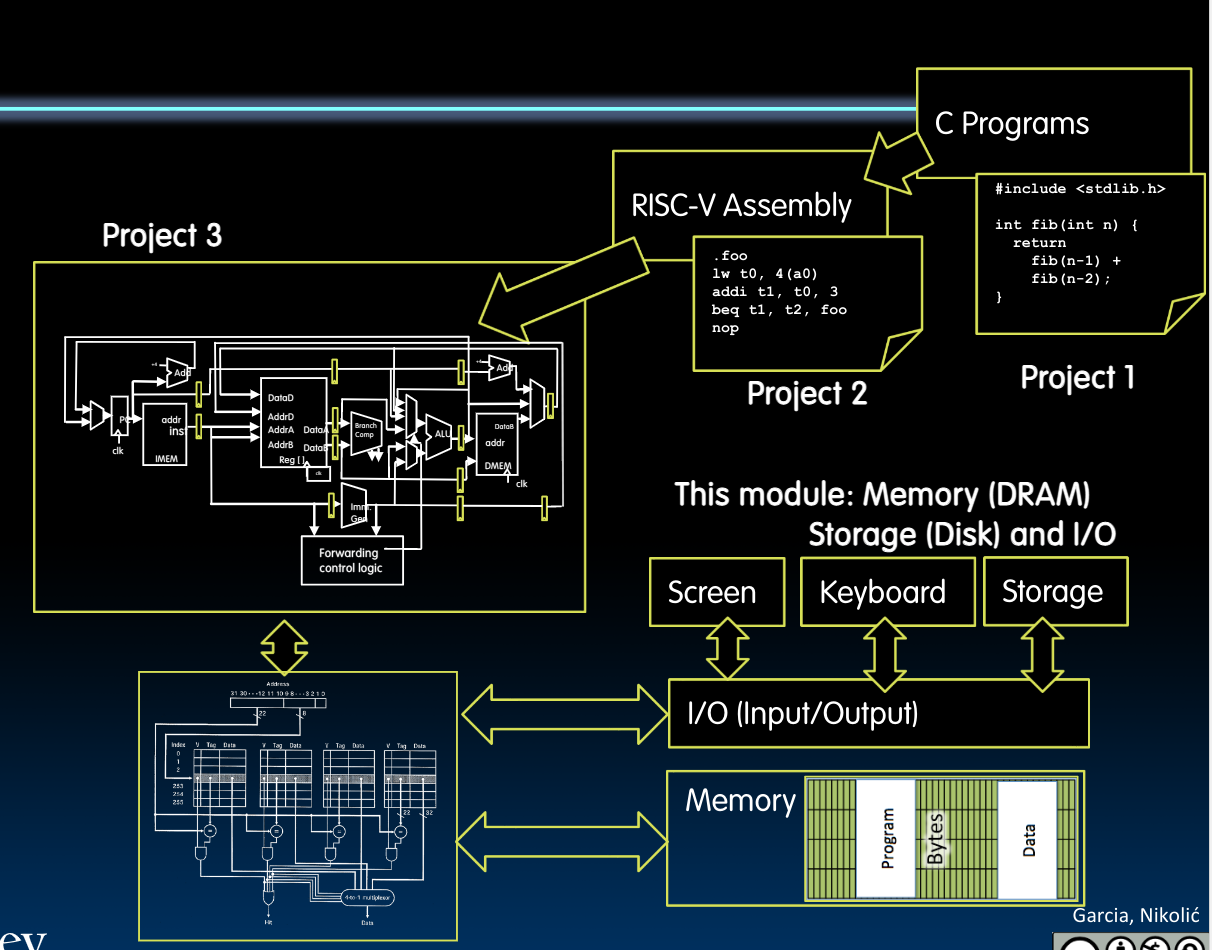
Operating System Basics
首先熟悉一些操作系统的基本知识,由于本课程并非OS课,详细的内容在CS 162中.
操作系统主要干什么?它的工作流程是什么?
- 操作系统是计算机打开时第一个运行的“程序”
- 在开启操作系统后,操作系统负责找到并控制所有
devices,使用hardware-specific device drivers. - 接下来,它启动所谓的
services,包括file system,network stack(Ethernet, WiFi, Bluetooth...),TTY(keyboard)等 - 最后,它会加载、运行和管理
Programs.在这一步中,操作系统保证以下三个特性:
- Multiple programs at the same time (time-sharing)
- Isolate programs from each other (isolation)
- Multiplex resources between applications(所有的程序共同分享相同的系统资源)
总得来说,OS内核(在supervisor mode下运行的操作系统核心)完成了如下使命:

为了实现进程间通信,UNIX系统提供了两种机制:pipe与shared memory,pipe可以允许我们以stream的形式发送和接收数据,而shared memory顾名思义是共享内存的意思。但无论如何,在使用他们之前,OS必须首先set it up.
What does OS need from hardware
我们先前构建的dataPath其实已经可以运行一部分操作系统的基本功能了,但是如果添加上用以满足以下功能的硬件,那么就可以运行一个简单的操作系统了:
- Memory translation

显然,许多程序,比如我们先前所使用的Venus都尝试使用所谓的“同一片内存区域”,为了解决这个问题,操作系统会进行virtual address与physical address的转换。这样即使对于程序本身来说,看起来是使用了同一块内存,实际上那只是virtual address而已,操作系统为他们分配到了DRAM上不同的physical address.
- Protection and Privilege

如果我们放任程序运行,他们可能会对系统本身的正常工作和运行造成干扰甚至损坏,所以OS设置了两种模式(RISC-V有三种).Supervisor mode可以改变memory mapping,在这种模式下,操作系统可以将不同的内存块以不同的memory mapping的方式分配给不同的用户. 这是通过设置CSR实现的。
- Traps & Interrupts

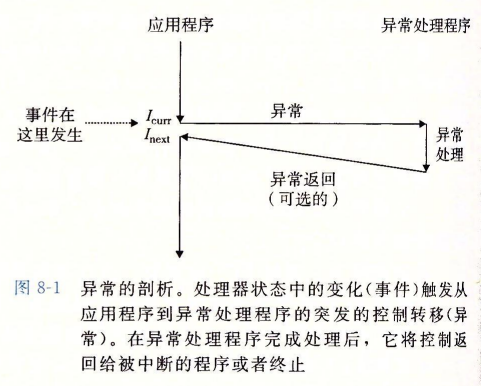
这种情况我们之后会详细介绍,根据《深入理解计算机系统》,处理器会检测“状态”是否有变化,如果检测到有事件发生,则会通过异常表(exception table)进行一个间接过程调用(异常),到一个专门设计用来处理这类事件的操作系统子程序,即异常处理程序(exception handler)。在这门课中,我们称之为执行Trap handler(被操作系统以supervisor mode调用),如上图所示。
当异常处理程序完成处理后,根据引起异常的事件类型,会发生以下三种情况:
- 处理程序将控制返回给当前指令$$I_{curr}$$,即当事件发生时正在执行的指令
- 处理程序将控制返回给$$I_{next}$$,如果没有发生异常将会执行的下一条指令
- 处理程序终止被中断的那个程序运行
Control and Status Registers

需要注意的是,并非只有在supervisor mode下可以控制CSR,但是在user level下我们不能控制supervisor-level CSR.
What Happens at Boot
当计算机被打开时,CPU会从某个预设好的起始地址开始执行指令,这个起始地址指令一开始是被存放在Flash ROM中的,一般来说,我们可以直接读取Flash ROM中的指令内容,但是习惯上我们将它复制到memory(memory-mapped I/O)里的那个预设起始地址再开始读取并执行。当我们在启动电脑时可以进入的BIOS界面就是它了。
Flash ROM在极少情况下需要“写”操作,比如只有在我们进行BIOS更新的时候才需要用到,对于他本身来说,写操作是较慢的,读操作是很快的.
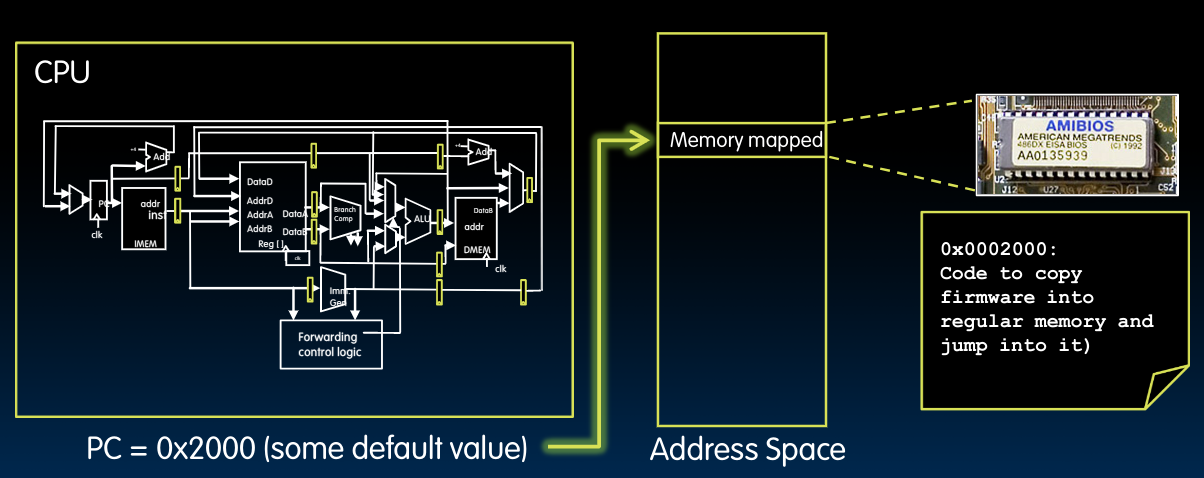
那么在Boot的时候发生了什么呢?
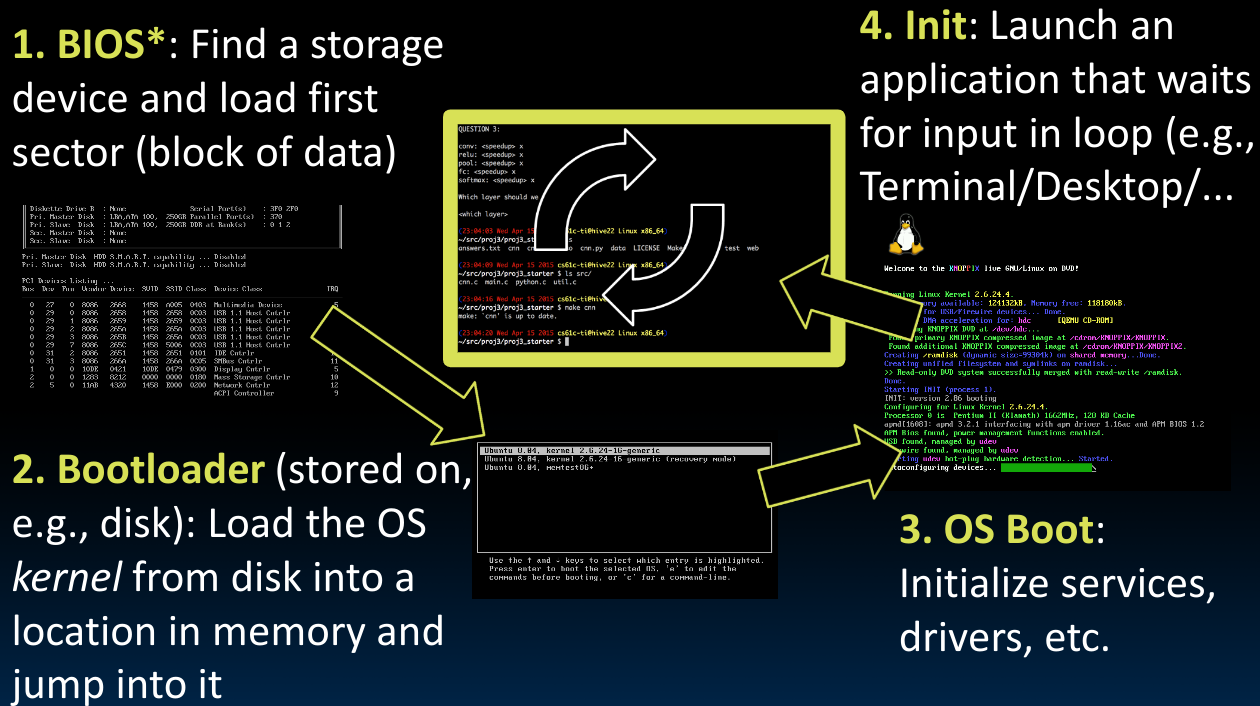
首先,计算机根据我们上述的描述,开始执行BIOS(
EFI firmware),它会找到一个存储设备(disk),同时加载找到的存储设备中的第一块数据并开始执行其中的内容。在这第一块数据里存储了许多重要信息,包括Bootloader程序,他帮助我们执行一些最基本的操作系统函数,将操作系统内核加载入内存并跳转到操作系统内核处。需要注意的是,BootLoader可以支持多个不同版本的操作系统的启动(如同我们会在BIOS界面中见到的那样)。
接下来,操作系统就开始执行它应该做的工作,正如前边所介绍的那样——找到
device drivers并启动services.最后,当操作系统完成上述工作后,它会进入循环,等待用户输入,或者等待程序被启动…
Operating System Functions
Launching Applications

一个进程可以含有多个线程,但无论是对于进程还是线程,由于他们的数量很多,即使是多核CPU也不可能仅仅在一个核内执行一个任务,为了多进程/线程运行,采用的方法正是先前在CS 106L课程结尾部分提到的multithreading机制,操作系统控制进程在核内执行一段时间后将其移出,让另一个进程占据内核执行,如此循环。当然这个过程是以极快的速度完成的。
为了launch application,我们通过system call的方式实现:对于Linux来说,它使用fork创建新的进程,并使用ececve加载应用。
通过调用fork(),原本的进程会被克隆一份,也就是变成父进程+子进程,创建完子进程之后,父进程仍然继续运行原本的代码,子进程用来执行新的任务。子进程把父进程的**Process Control Block(PCB)**克隆了一份,除了其中的pid没有复制,子进程获取了一份新的pid,这样一来操作系统就可以根据pid来区分子进程和父进程了.
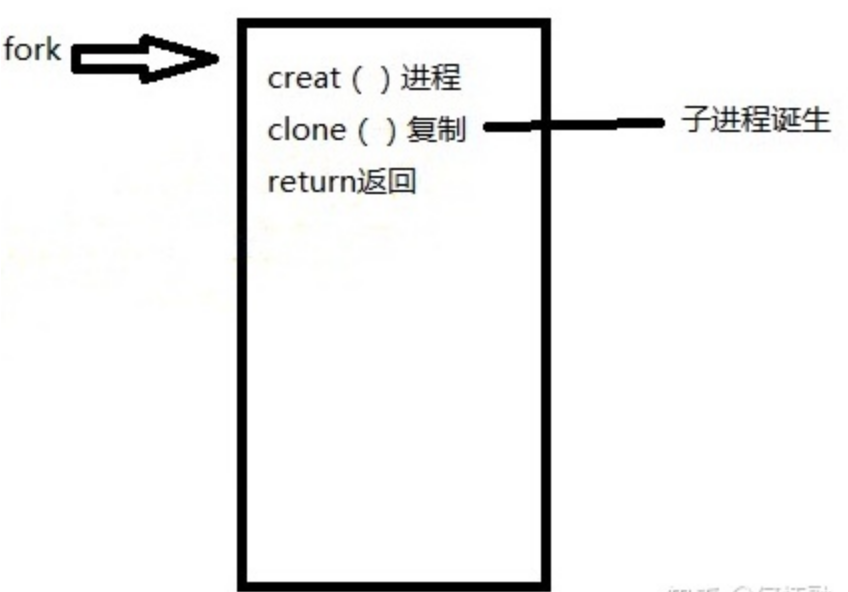
而加载应用的过程,因为也是在调用可执行文件,其实与我们先前对程序运行流程的loader部分的介绍如出一辙。
当子进程消亡后,返回.(如果在子进程还没有消亡时,父进程就消亡,则此时父进程会作为一个zombie process,直到子进程消亡后消失)具体的过程留到CS 162再解决。
fork()函数被调用一次,但返回两次:一次是在父进程中,一次是在新创建的子进程中。在父进程中,fork返回子进程的PID;在子进程中,fork返回0.父进程和子进程是并发执行的独立进程。内核能够以任意方式交替执行它们的逻辑控制流中的指令。我们决不能对不同进程中指令的交替执行做任何假设。

Supervisor Mode


操作系统将应用对于系统资源的使用施加了一些限制,比如对于内存以及设备等,在user mode下我们不能直接访问内核代码和数据,只能通过syscall接口来访问。如此一来即使应用崩溃了也不会对系统整体造成影响。
相比于user mode,supervisor mode下我们可以执行更多的指令,多出来的指令都是CSR相关的。这些特权指令(privileged instruction)包括停止处理器、改变模式位,或者发起一个I/O操作等等。而进入supervisor mode时,在硬件层面,其实我们也只是简单的翻转了几个CSR的相关bits.需要注意的是,对进程本身来说,他可以脱离Supervisor mode,但是除了使用interrrupt来进入Supervisor mode之外,别无他法.
当我们在Supervisor mode下遇到错误时,很可能对操作系统的运行产生灾难性的影响,比如在Win下遇到的蓝屏。
Syscalls
对于一些基本的底层的任务,我们不想在每一个软件中都单独设置模块来完成和实现它们,操作系统为我们提供了解决这一问题的方法,即syscalls.

调用syscalls的方法也很简单,正如先前在Venus中使用的ECALL指令那样,我们通过给寄存器一些特殊的指定的bits来告诉操作系统执行哪一个对应的syscalls,而操作系统接下来会通过调用专门生成software interrrupt的指令来实现操作(ECALL). 实际上,software interrupt并非属于interrupt的异常类型,它是由运行的程序本身产生的,并非基于硬件的中断。
借由software interrupts,操作系统会接管当前程序运行(进入Supervisor mode),在完成操作(比如通过WiFi发送数据啊…)之后会将控制权交还给user mode.也就是说,系统调用是从用户态切换到内核态的一种方法,后边我们会看到,只要发生了中断/异常(系统调用也是一种异常),系统需要使用trap handler来处理它们,便需要进入到内核态中去。
也正是借由这种方式,操作系统保证了可以在同一时间内运行多个此类进程,而不会发生冲突。

Interrupts, Exceptions
这两种不同的“中断”模式的区别如下:

需要注意的是,interrupts并不需要我们在发生中断时立刻解决问题(丢下手头的工作),但是exceptions需要我们这么做!这就导致exception处理的硬件设计要比interrupt难。
这里我们给出了Trap的定义。而在先前我们提到,我们通过Trap handler来控制interrupts/exceptions.
按照更为详细的分类标准,
interrupts又被称为异步中断,是其他硬件依照CPU时钟信号随机产生的,又叫做硬件中断。interrupts/异步中断/硬件中断又可分为:
- 可屏蔽硬件中断(CPU可以延迟)
- 不可屏蔽硬件中断(CPU不可延迟)
这里的
exception为异常,也被称为同步中断,是当指令执行时CPU控制单元产生的,系统调用就是一种异常。包含trap(陷阱)+fault(错误)+abort(终止),被称为故障指令(faulting instruction)。之后介绍的page fault就是一种fault异常.而
software interrupts即软件中断,和复位中断、按键中断、串口中断本质上是一类,都是属于真正的中断,只不过软件中断它触发的方式比较奇怪,它是由代码触发的。需要注意的是,还有一种中断名为
软中断(softIRQ),它和软件中断不是一个东西,软中断主要用于执行系统调用即*int 0x80*以及给调试程序通报一个特定的事件,所以软中断是异常的一种,属于同步中断。这里不去深入探讨,根据百科内容:软中断的一种典型应用就是所谓的"下半部"(bottom half),它的得名来自于将硬件中断处理分离成"上半部"和"下半部"两个阶段的机制:上半部在屏蔽中断的上下文中运行,用于完成关键性的处理动作;而下半部则相对来说并不是非常紧急的,通常还是比较耗时的,因此由系统自行安排运行时机,不在中断服务上下文中执行。bottom half的应用也是激励内核发展出的软中断机制的原因。
Trap Handling
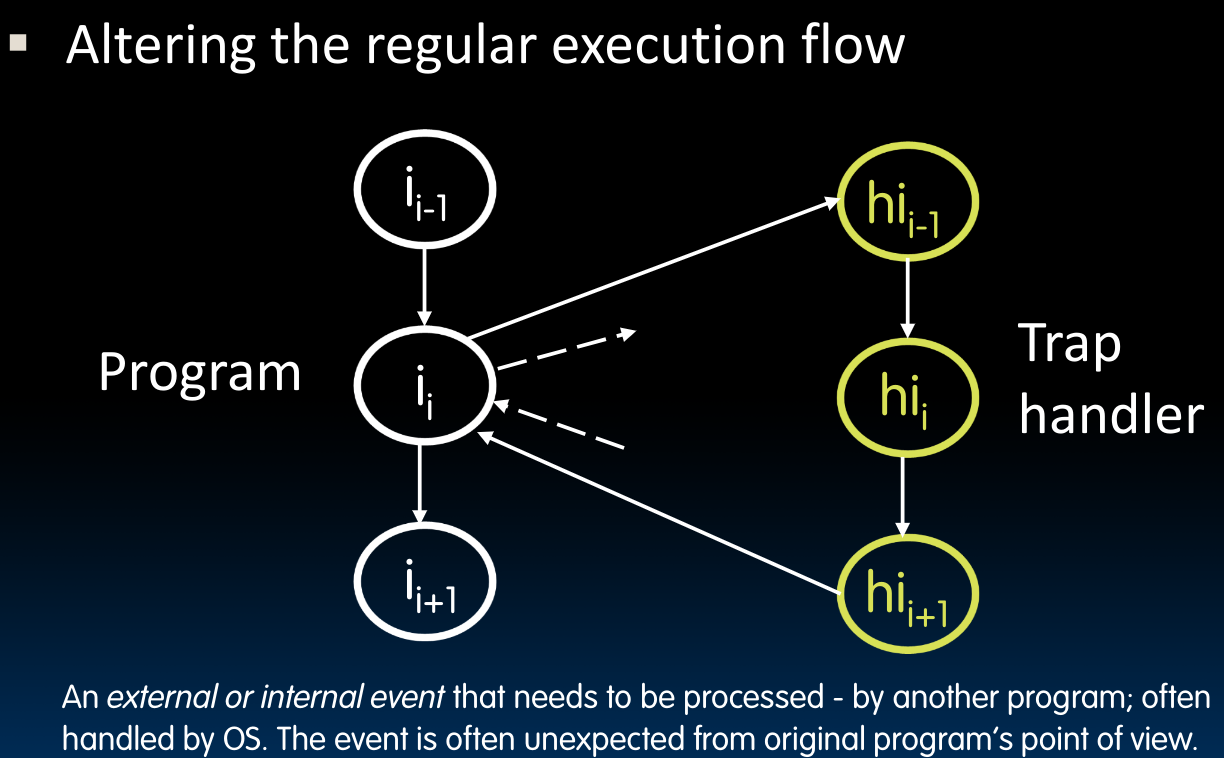
这张图的视角是
Trap handler,对于程序本身而言,在执行完异常处理程序之后,未必返回到$$I_{curr}$$.要看具体情况.
Precise Trap

由于Trap handler是软件层面的东西,既然Trap handler假定先前所有指令执行完成而后续指令均未开始,那么处理的重点就放到了硬件层面上,故而硬件设计要比软件上麻烦得多。
每次需要用到Trap handler时,将目前系统的状态(类似于函数调用,但这里我们将所有寄存器中的内容存储起来)保存起来,当Trap handler处理完事情之后,将状态恢复到中断还没有发生时的模样。
pipeline handling
需要注意的是,对于pipeline中的Trap handling,我们应当给予特别的注意,因为当在某个指令的某一阶段探测到需要进行Trap handling时,由于pipeline的存在,后续一些指令可能已经被加载,而显然这些已经被加载的后续指令不应该在Trap handling结束之前被继续执行。于是我们可以采用与解决hazards问题相同的方法,即:


what does hardware & software do?
为了成功处理异常,需要硬件和软件分工合作。根据《深入理解计算机系统》,当系统启动时,操作系统分配和初始化一张成为异常表的跳转表,每种异常被分配了一个唯一的非负整数的异常号(exception number),其中一部分是处理器的设计者分配的,另一部分是OS内核的设计者分配的。在硬件层面,处理器触发异常,通过异常表来形成适当的异常处理程序(Trap handler)的地址:
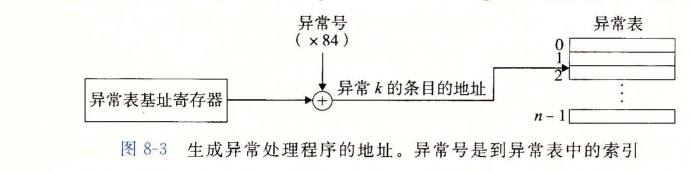
一旦硬件触发了异常,剩下的工作就交给trap handler,在软件中完成。在处理程序处理完异常之后,就通过一条特殊的**“从中断返回”**指令,可选地返回到被中断的程序,该指令将适当的状态弹回到处理器的控制和数据寄存器中。
所以,具体来说当发生异常/中断时,硬件做什么?
下边提到的
Atomic即原子操作,意味着对于程序本身来说,所有的步骤都是同时发生的.
- adjust the privilege level (change some bits of the CSR)–>
supervisor mode - Disable interrputs
- Write the old
program counterinto thesepcCSR (It is the PC that triggered the exception or the first instruction that hasn’t yet executed if an interrupt) - Write the reason into the
scauseCSR - Set the PC to the value in the
stvecCSR (address of theTrap Handler, which is the single function that handles ALL exceptions and interrupts)
那么相应的软件又要完成什么功能呢?
- Save all the registers (Intent is to make the previous program think that nothing whatsoever actually happened!)
- Figure out what the exception or interrpt is (Read the appropriate CSRs and other pieces ot do what is necessary)
- Restore all the registers
- Return to the right point in execution
Save registers?

Figure out what to do!

Now to Return

使用指令SRET,我们的任务回到了硬件层面,这是一个返回指令,在处理完硬件层面之后就可以装作无事发生的继续执行程序了:
- Reenable interrupts
- Reset back down to user level
- Restore the PC to the value in
sepc - And now the program continues on like nothing ever happend
结合以上描述,我们知道这一段中断的过程对于程序本身其实是不易被察觉的,当使用ECALL时,类似于进行了一个function call,在其他情况下,就好比无事发生。但是另一方面,cache可能会变成垃圾值,因为有别的任务(Trap handler)在使用内存。
In fact, for security reasons the OS often needs to flush all caches before returning flow to the program
不仅仅是在Trap handling interrupts/exception时,上述规则表明,在每一次context switch之后我们都会在cache中得到大量的compulsory miss.
写到这里,我们可以认清一个事实,就是处理异常是需要耗费高昂的代价的,我们必须刷新pipeline,保存和恢复寄存器,同时cache也需要被刷新…
Multiprogramming/context switching


为了能够在用一个CPU核内执行多个进程,我们使用context switch的方法,简单来说,就是通过在进程间的不断跳转(去+回)的方式保证多个进程可以“同时”运行:
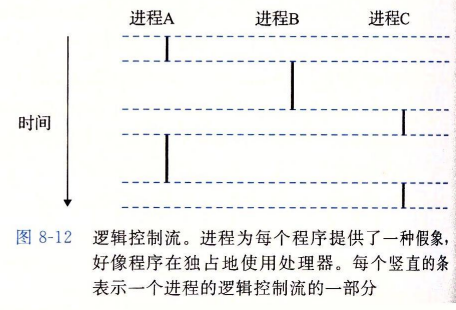
在上图中,进程A和进程C的执行在时间上重叠,故为并行流(concurrent flow).
在执行一个进程时,硬件触发timer interrupt,触发中断后trap handler执行context switch:
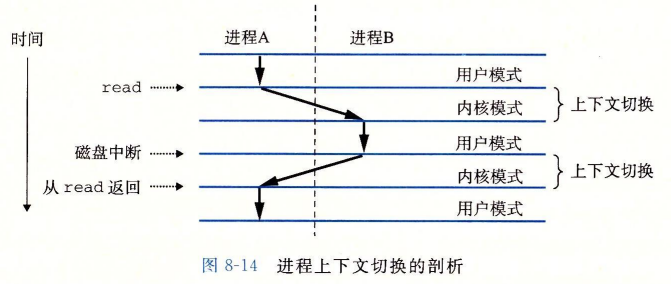
为了能够在下一次调度器(scheduler)处理时可以返回这个行程——重建行程并继续运算,在context switch之前我们需要先将行程状态保存到该行程对应的bookkepping data structure中,这个用于保存状态的机构被叫做Process Control Block(PCB)。
行程状态主要包括通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器(CSR)、内核栈和各种内核数据结构,比如描述地址空间的
page table,包含当前进程信息的进程表,以及包含进程已打开文件的信息的文件表.
在储存了上一个进程的状态之后,调度器加载下一个要被执行的进程的状态到指定的寄存器中,由于是新的进程,同时出于安全因素的考量,cache刷新内容,避免旧数据被利用。最后使用sret指令返回原先指令的下一条指令。
这种规划和执行进程的过程被称为scheduling.

I/O Basics
这里介绍一部分I/O的基本内容,之后会详细介绍。
Instruction Set Architecture for I/O

需要注意的是,计算机在CPU与外部设备之间执行输入输出操作有两种方法:
- 独立输入输出(
isolated I/O,port-mapped I.O)
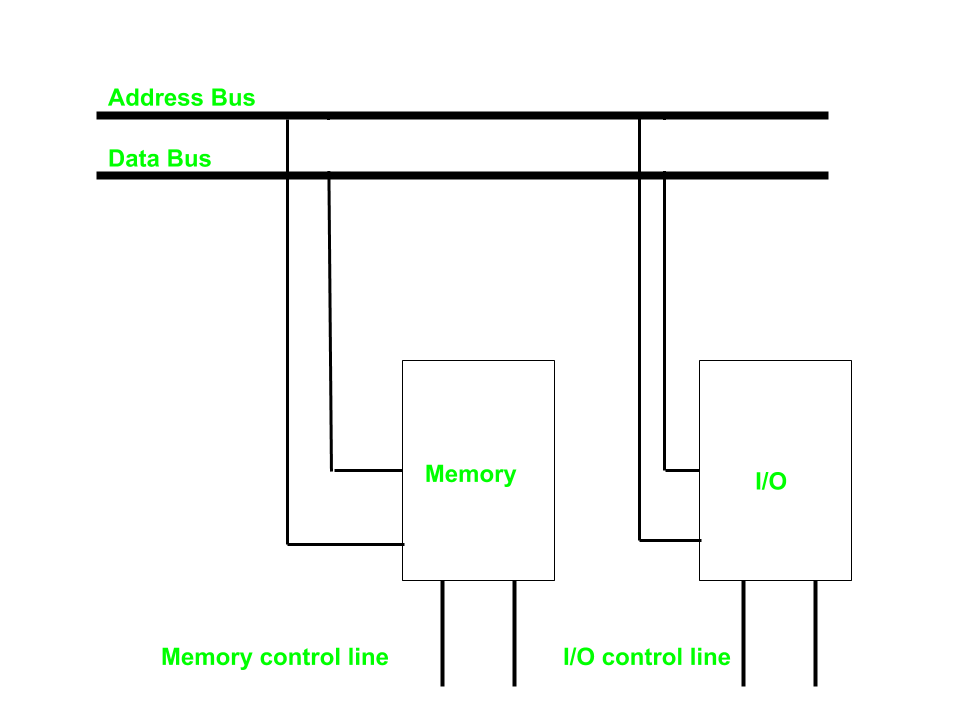
可以看到,内存与I/O使用共同的地址总线与数据总线,但是有独立的控制总线,这意味着我们对于内存的读写(如lw/sw)和对I/O的读写要使用不同的内部指令+硬件设计。
- 内存映射输入输出(
Memory-mapped I/O)
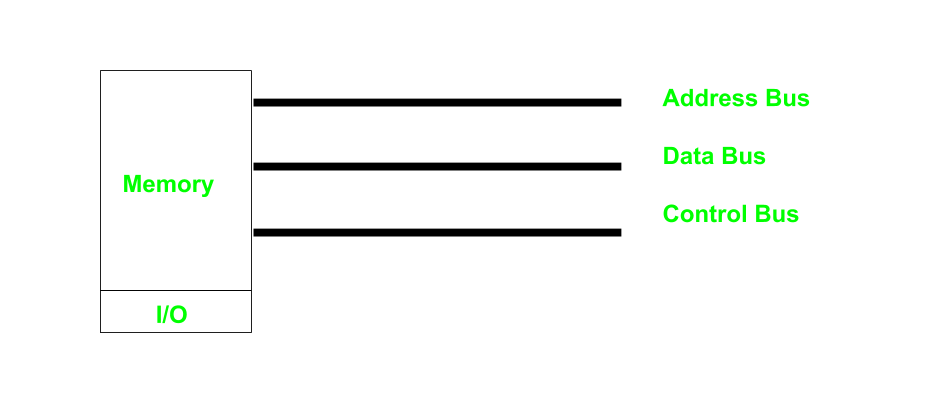
此时,地址总线、数据总线和控制总线都是一样的,这也是当前比较流行的做法。我们对内存的读取操作和对I/O的操作使用相同的指令(lw/sw).这种模式要求I/O设备上的设备内存和寄存器都已经被映射到内存空间的某个地址。为了实现CPU对MMI/O设备的访问,相应的地址空间必须给这些设备保留,并且不能再分配给系统物理内存。这可以是永久保留,也可以是暂时性的保留。通常来说X86架构都是永久保留的,而在Commodore 64中,由于采用了I/O设备和普通内存之间的堆交换技术(bank switching),可以做到暂时性保留。
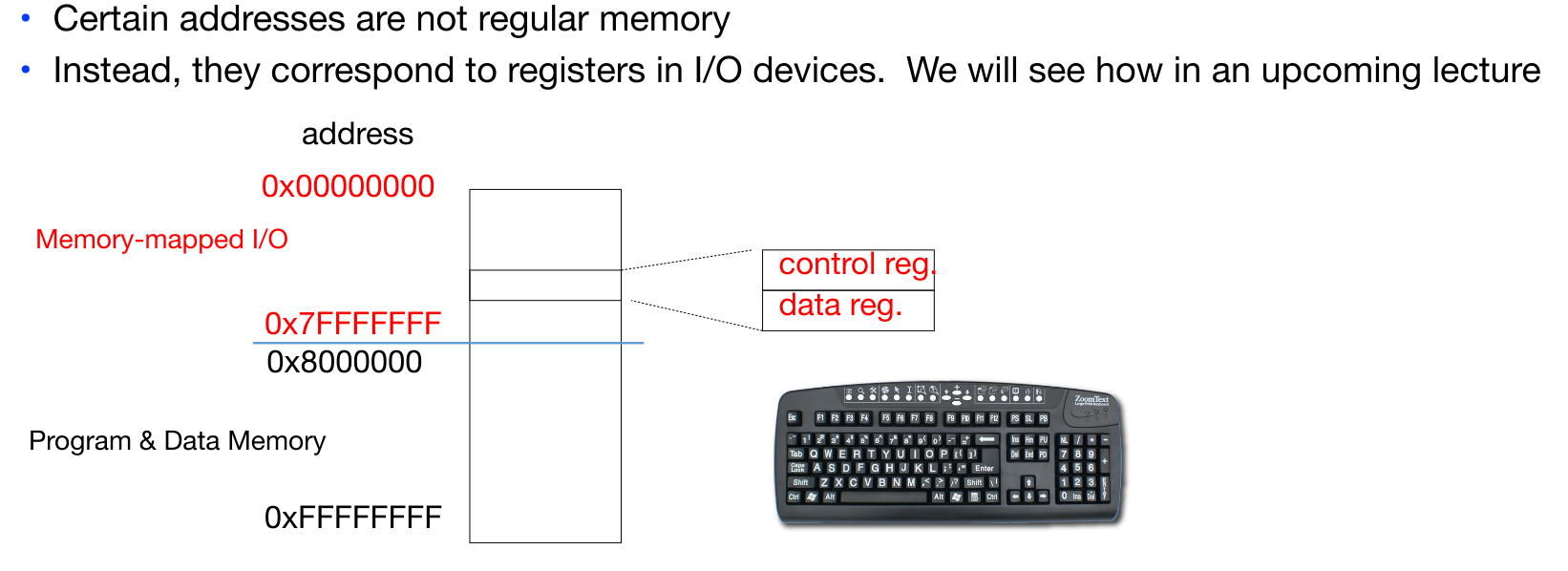
在虚拟内存的最后部分,我们会介绍Memory-mapped I/O的优点。
Processor-I/O speed mismatch

这里我们可以得到的结论是I/O与CPU的速度不匹配,那么我们如何检测I/O的读写操作呢?

无论如何,I/O的处理绕不开OS本身.
polling
第一种方法是轮询。

简单来说,就是循环着一直查询,直到我们发现control register告诉我们可以读/写了,就从Data register中读取/写入数据。

polling的方法在所需的轮询次数较少时可以胜任,但是当所需的polling次数太多,我们会消耗CPU大量资源,这是不可接受的:
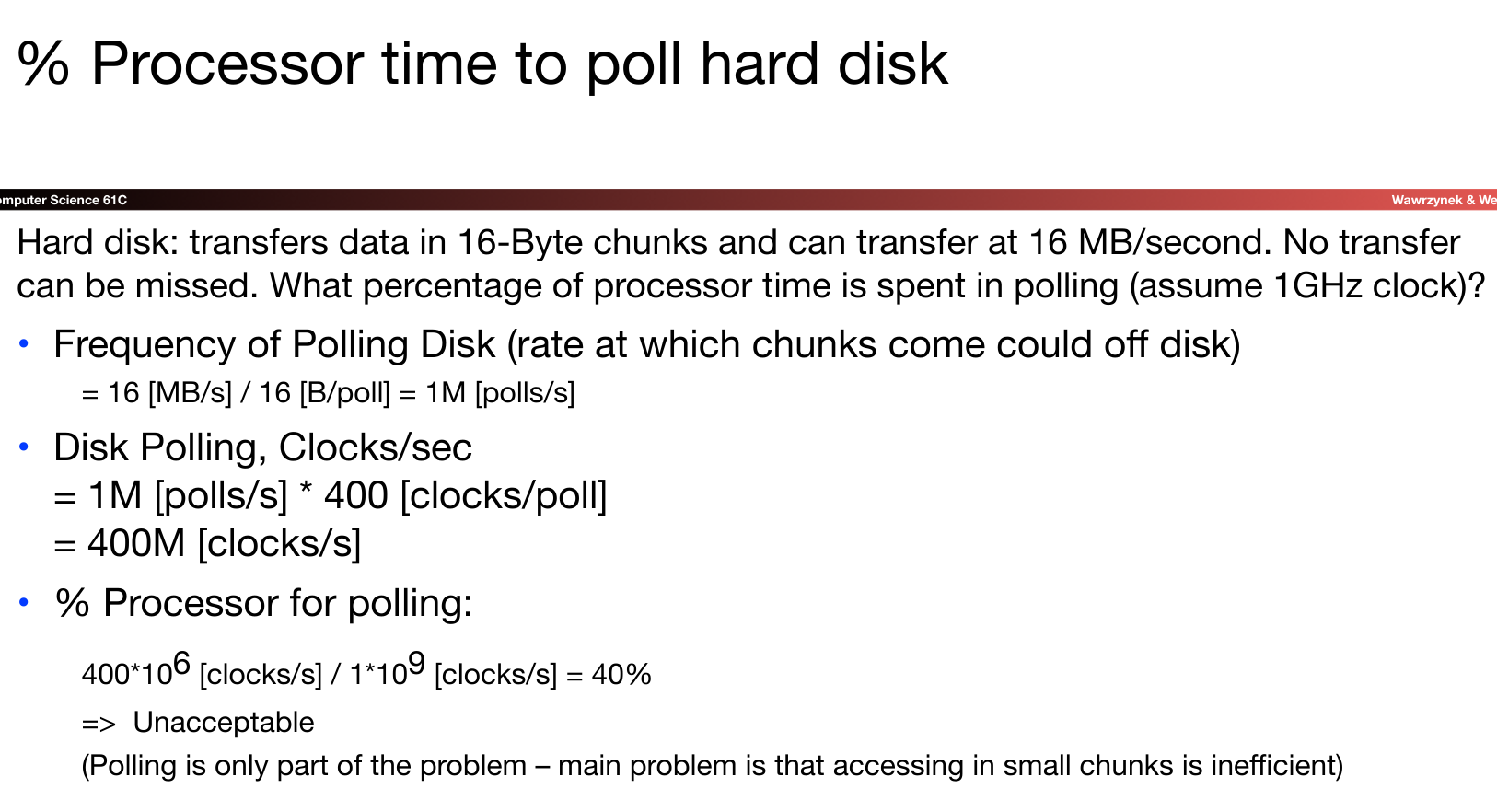
我们可以留意一下这里的运算过程:首先我们计算得到在可以在1s内传输16MB数据的前提下,如果想在一块16-byte的块上在1s内完成这一传输过程,那么需要达到多少的polling频率?接下来就可以计算出1s内polling占了多少个时钟周期,从而可以得出占比。
所以,我们有替代方案吗?
interrupts
我们可以使用interrupts:

当然,实现interrupts的代价还是很大的,不像polling只需要一直不停的循环等待就好了。所以在实际实现中,我们采用如下的解决方案:

Virtual Memory
Virtual Memory Concepts
虚拟内存是我们构建的计算机结构金字塔的下一层:
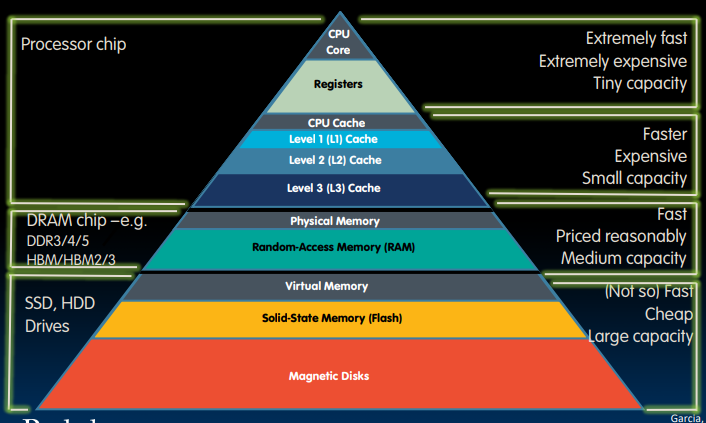
Provides program with illusion of a very large main memory: Working set of “pages” reside in main memory - others are on disk.
具体来讲,虚拟内存提供一种Demand paging(按需页面调度)的思路:
Demand paging: Provides the ability to run programs larger than the primary memory (DRAM)
从每个进程的角度出发,它们认为它可以获取全部的内存。但虚拟内存除了作为一个存储层级结构并提供上述功能外,更重要的是虚拟内存可以为不同的进程提供保护(protection)。这一点我们在之后会详细介绍。
而正是由于这些原因,我们通过利用虚拟内存对物理内存建立一种映射:
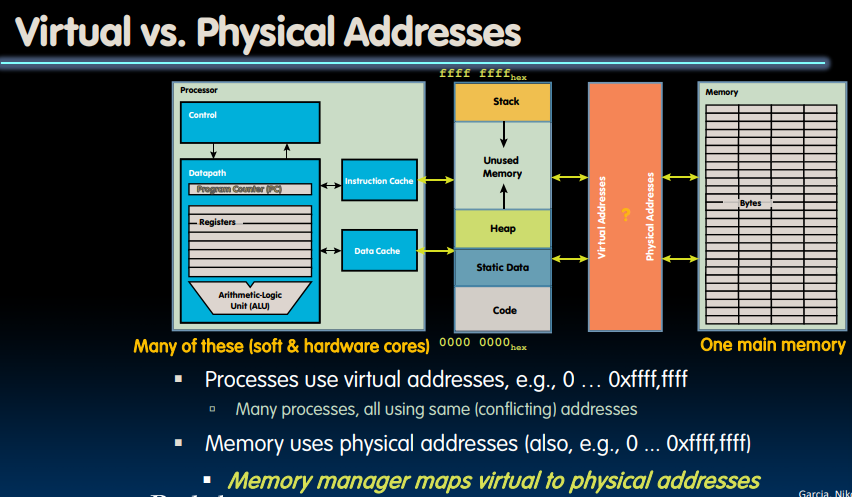

为了完成这种内存映射,我们需要建立page table.这就好比我们要从图书馆中获取书籍的过程:

一些小细节:
- 在page table中存在一个
valid bit,用于表示存储的page是位于DRAM中还是位于disk里 - 除了
valid bit之外,页表中还有一些status bit,其中包括用于告知how long we can check out the book的标志位
Physical Memory and Storage
在《深入理解计算机系统》中,详细介绍了几种不同的存储结构。在这里,我仅仅记录一部分在课程中提到的存储方式。
Memory
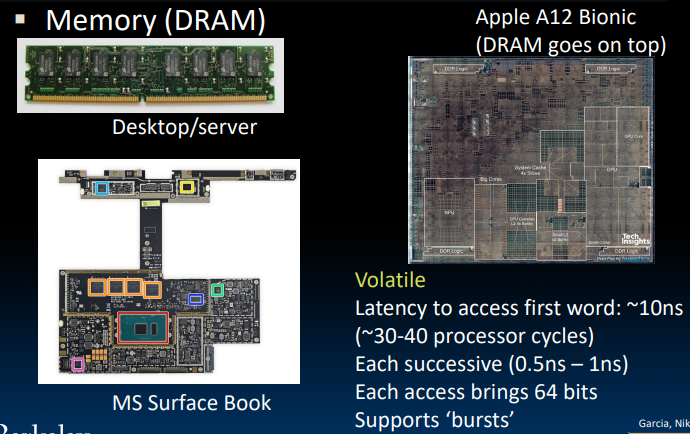
RAM可以分为静态RAM(SRAM)和动态RAM(DRAM),SRAM被用于cache中,由于它的bistable特性,只要有电,它就会永远保持它的值。即使有电子噪音等干扰,当干扰消除时,电路就会恢复到稳定值。
我们在主存中使用的是DRAM,DRAM速度比SRAM慢,但是它具有更小的存储单元(DRAM Cells),排列可以更加紧密。DRAM存储器对干扰十分敏感,所以每隔一段时间,与DRAM相连的memory controller就需要刷新一遍电荷,将电荷重新排布到他们应该在的位置上。在笔记本和服务器中使用的DRAM一般为DIMM,即Dual in-line Memory.
但不论是SRAM还是DRAM,都需要电压来保持数据,所以我们称这种存储方式为Volatile的。
从上图的数据中可以看出,对nearby place的读写耗费的时间远远小于一般情况。DRAM一般都支持一种burst mode,一次量可以获取8~16倍相对于64 bit的数据转移量,有点类似于cache中使用的prefetch技巧。
Disk(HDD-SSD)

常见的磁盘存储方式有SSD(solid state disk)和HDD(hard-drive disk)。SSD的数据读写速度远快于HDD,但是价格也更贵。由于在断电之后不会丢失数据,故被称为non-Valotile.
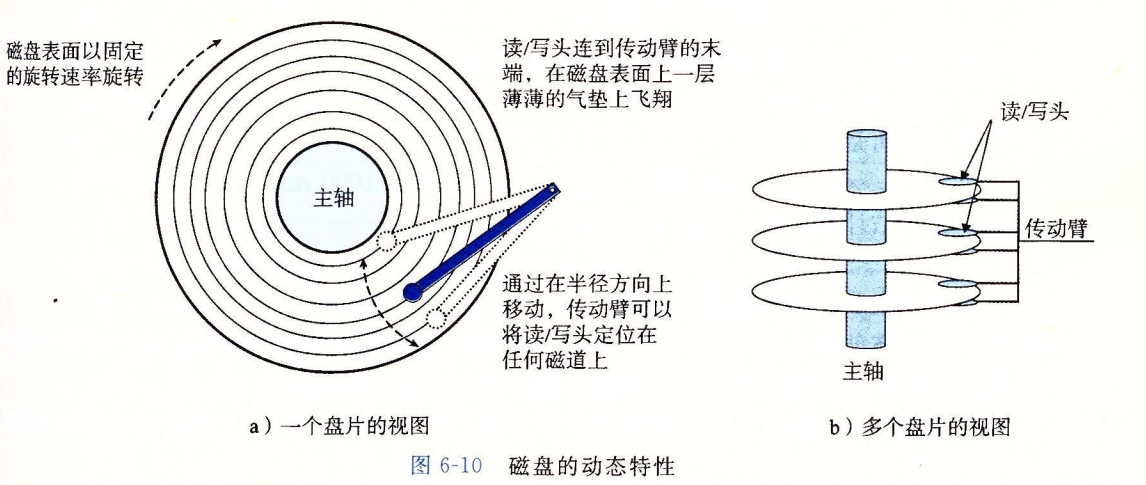
HDD的结构如图所示。磁盘用读/写头来读写存储在磁性表面的位,而读写头连接到一个传动臂一端,通过沿着半径轴前后移动这个传动臂,驱动器可以将读/写头定位到盘面的任何轨道上。读/写头垂直排列,一致行动。读/写头并不直接接触磁盘,而是在磁盘表面一定距离的气垫上“飞翔”。
每个表面被分为一组磁道(track),每个磁道被分为一组扇区(sector),每个扇区包含相等的数据位。扇区之间的间隙(gap)不包含任何数据位。如果读/写头遇到了灰尘,它会停下来撞到盘面,这被称为head crash。为此,磁盘总是密封包装的。

可以看出,disk的访问速度是很慢的。
在Linux系统中,我们可以通过fdisk -l来查看磁盘的扇区大小(block size),为512bytes.
与机械硬盘相对应的固态硬盘,使用的基于闪存的存储技术。其中没有移动设备。

一个SSD封装由一个或多个闪存芯片+闪存翻译层(flash translation layer)组成,闪存翻译层是一个硬件/固件设备,扮演与磁盘控制器相同的角色–将对逻辑块的请求翻译成对底层物理设备的访问。
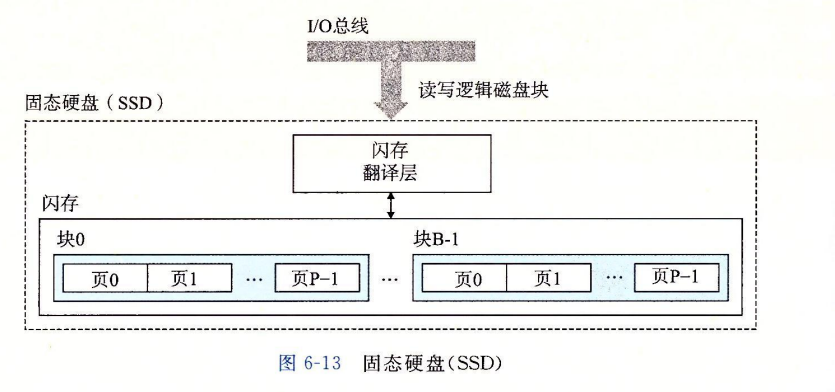
一个闪存由B个block的序列组成,每个block由P个pages组成。
对SSD的读写过程值得我们注意:数据是以page为单位读写的,但擦除是以block为单位进行的。只有在一个page所属的block被整个擦除后,才可以写这一个page.不过一旦一个block被擦除,快中每一个page就可以不需要再擦除而直接写。也正是因为这种频繁的擦除过程,SSD会因为擦除过多而损坏。
根据《深入理解计算机系统》,SSD的随机写过程很慢,因为需要毫秒级别的擦除,并且有可能需要将已有的数据复制到一个新的块内。
Memory Manager
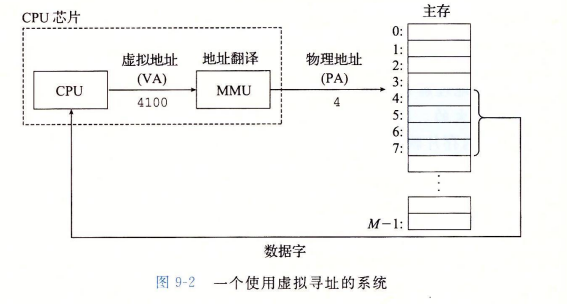
CPU芯片上的Memory Management Unit利用存放在主存中的page table来翻译虚拟地址,该表的内容由操作系统管理。在获取一块物理地址之前,MMU需要先检查if process has permission to access a particular part of memory.
具体来说,Memory Manager的主要功能如下:
- Map virtual to physical address
- Protection:
- Isolate memory between processes
- Each process gets dedicate ”private” memory
- Errors in one program won’t corrupt memory of other program
- Prevent user programs from messing with OS’s memory
- Swap memory to disk
- Give illusion of larger memory by storing some content on disk
- Disk is usually much larger and slower than DRAM
在这里,virtual memory也可以被视作一种cache,



如果我们真的超过了可用物理内存的限度,需要借助disk来完成工作的话,会产生一种thrashing的结果,因为我们需要将数据在主存和磁盘间来回搬运,速度很慢。
Paged Memory
也正是基于“虚拟内存将主存视作磁盘上的地址空间的cache”这一想法,我们对地址提出paged memory的想法,将虚拟内存表示为如下的形式:

上边地址格式中的offset告诉我们在主存/磁盘中的page memory中具体的地址位置;而前边的page number则帮助我们确定page table中的对应索引位置,让我们找到对应的Physical Page Number。每一个进程都有一个独立的page table:
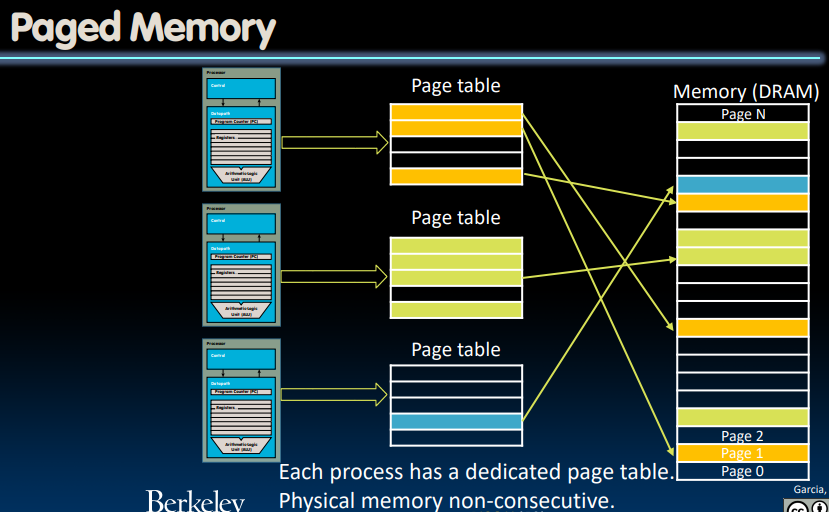
在任意时刻,**虚拟页面的(注意这里说的是page,不是page table)**集合分为三个不相交的子集:
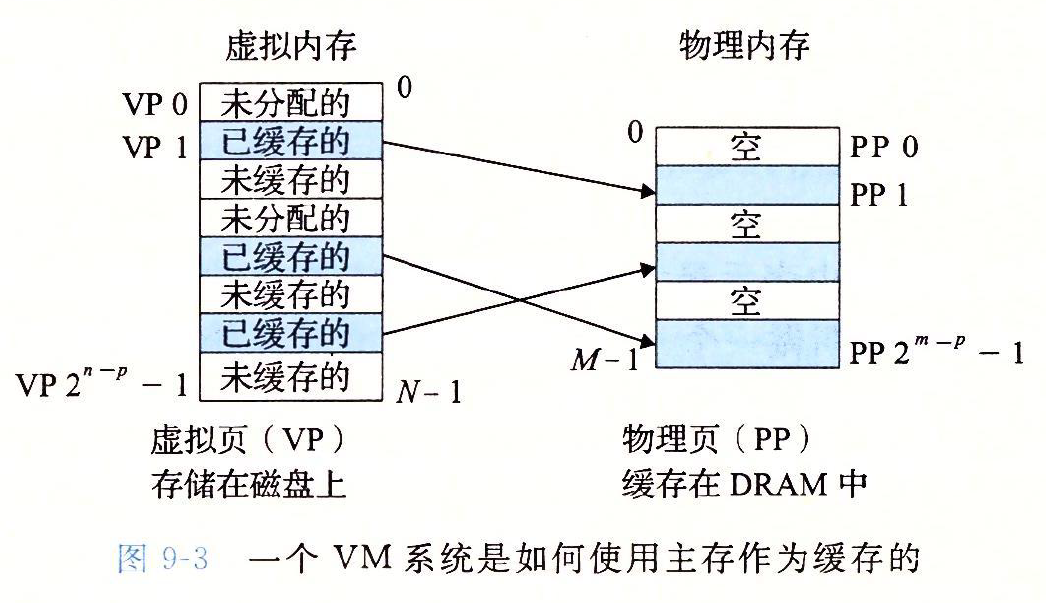
- 未分配的:VM系统还未分配/创建的页。未分配的块没有任何数据和他们相关联,所以不占内存空间
- 缓存的:当前已缓存在物理内存中的已分配页
- 未缓存的:未缓存在物理内存中的已分配页
需要注意的是,虚拟内存的大小未必要和物理地址的大小相同。
page table由操作系统在supervisor mode下管理,虽然通过这种page memory的方式实现了进程之间的isolation,我们可以通过设置sharing bit来通知the page is sharable.
此外,在page table中还有一些其他的status bit,这是一些控制字,比如告诉我们此时是否能向对应的page中写入数据。
Where Do Page Tables Reside?

我们假设page table中的一个entry(PTE)是4bytes. 通过计算之后会发现,我们需要的page table的大小只允许我们将它储存在主存里,而不能全部放在cache中。
而当我们面对诸如lw/sw这种指令时,需要跑两趟DRAM——先从主存中搞到page table,取得物理地址之后,再去到主存中取出对应地址中存储的数据。
为了减少这个过程的消耗,我们可以将经常使用的PTE储存到cache中(这可以直接利用cache的性质:LRU替换策略和每次以block传送的性质),而不经常使用的pages则被存储在secondary memory中—即swap partition里。
Page Fault

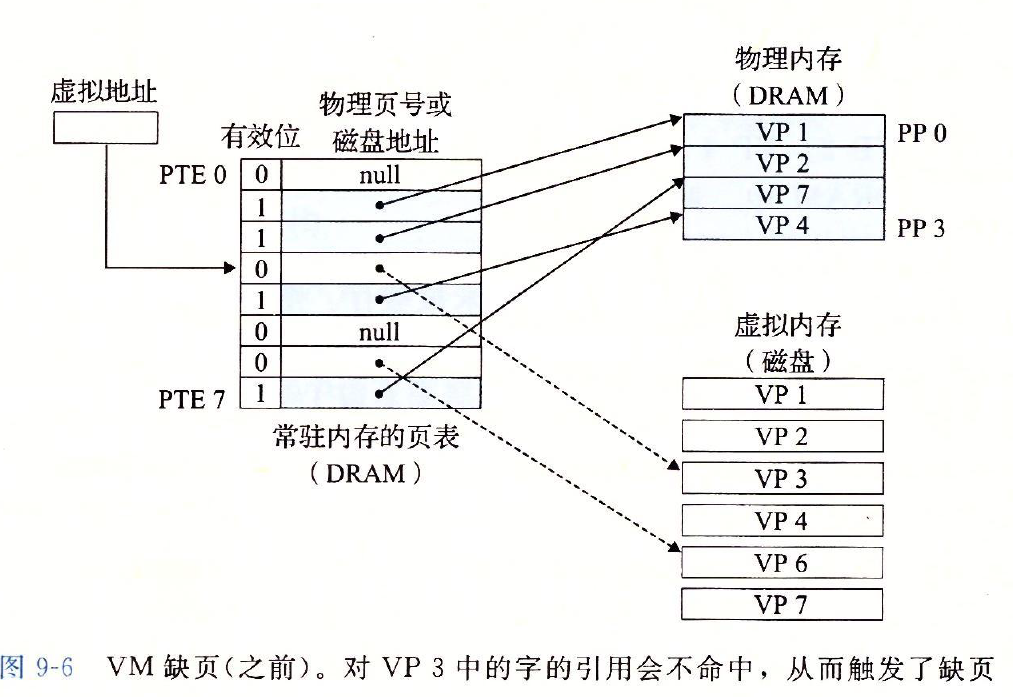
需要注意的是,page fault的对象是由page table->DRAM,而非VA->PA。
如果PTE的valid bit为0,则表明出现了page fault。
- 如果还没有分配(PPN/DPN为NULL)该虚拟页,则在DRAM中分配一个新的页(
unused page); - 如果虚拟页存在磁盘中,但没有缓存在主存中,按照当前
page table对应位置中存储的DPN索引到磁盘中找到位置并将其内容取出,存储到一个unused page中,过程如下所示:

- 如果DRAM中已经没有
unused page怎么办?我们需要选择一个牺牲页(page to evict),并根据牺牲页的dirty bit决定是否需要将该页的内容更新到磁盘中的swap分区里,如果不需要就直接丢弃。之后再更新对应的page table中的PPN为DPN.
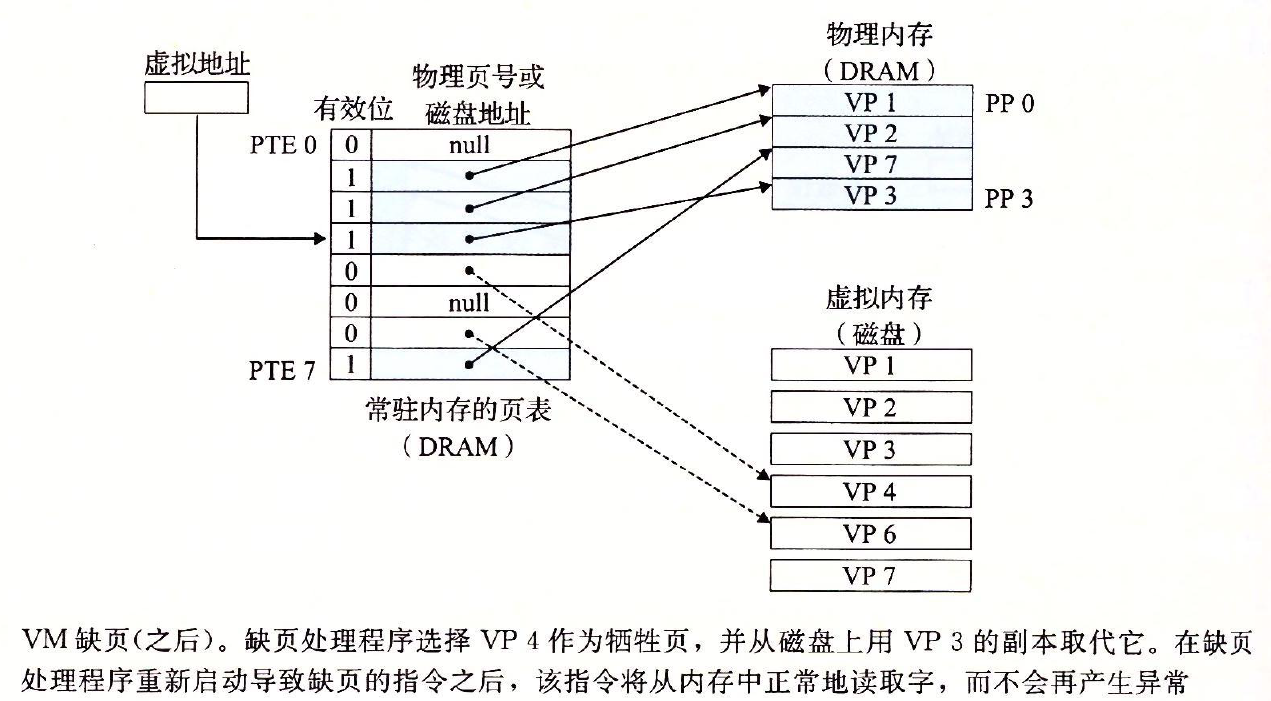
需要注意的是,当我们在page fault出现后更新page table外,还要将VPN-PPN/DPN的映射更新到TLB中。
那么我们该如何处理page faults呢?如同先前在OS部分简要介绍的,这是由操作系统负责的,它把page faults当做exception,使用handler来处理:

如果我们需要将页从磁盘中加载,那么可能需要进行context switch来完成此任务。最终,将我们把page处理好后,命令需要重新执行。
几种不同的
page fault类型:
出现
page fault的原因:


Hierarchical Page Tables
在先前关于page table大小的计算中,我们只考虑了一个进程对应的页表大小。但是实际我们面对的情况是几百个进程同时运行,如果我们把所有的page table全部存储在主存中,那么将会耗费大量主存容量,这显然是不可接受的。
而对于64-bit address,这就更显得不切实际了。所以我们要如何处理page table的大小呢?

- 增大
page size,相当于增加offset,这样一来PN就会减小;同时还带来一个问题,即太大的page意味着其中很多内存块都没有被使用。。。但是一直占着坑。 - 使用
Hierarchical page tables:
多级页表的好处有两个:
- 如果一级页表的某一个PTE是空的,则相应的二级页表根本不会存在。
在实际程序中,只有一小部分内存(最上边的一块与最下边的一块被使用)。但是在原本的单级
page table中间有很大的一部分正是对应着那些基本从来不会被使用的那部分DRAM。每个进程都有一个page table,如此一来我们对page table的储存就会造成极大的空间浪费。但是现在有了多级
page table,原本那些不被使用的内存对应的page因为一级page table的对应PTE为空而不存在,所以大大节省空间。这种存储方式使得我们可以不在DRAM中储存大块的连续存储,而是使用离散存储的方式。
- 只有一级页表才需要被一直存储在主存中;虚拟内存系统可以在需要时创建或调出二级页表,只有最经常使用的二级页表才被存储在主存中。
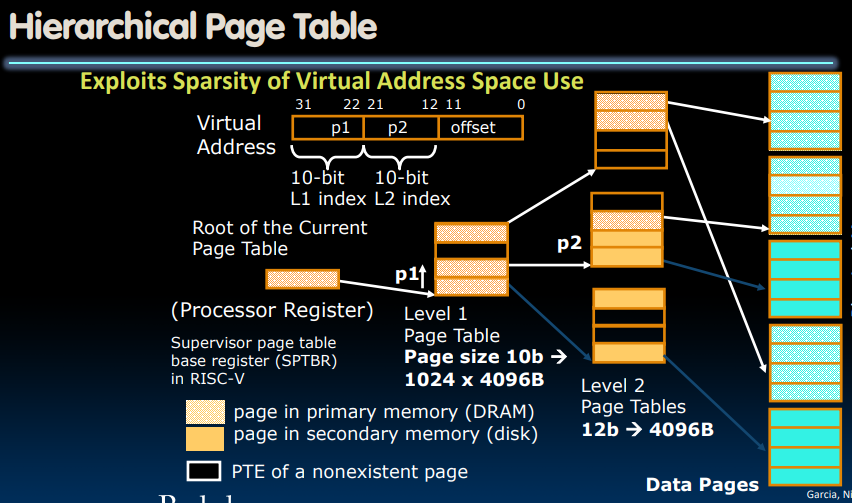
在32位系统中,我们分为两级page table,64位系统一般对应了四级page table.我们将原本20-bit的VPN,分为两个10-bit的VPN,分别对应了1级page table与2级page table.
当有新的用户进程开始活跃时,操作系统通过设置SPTBR寄存器来建立新的页表。这个寄存器保存了根页表的物理页号(PPN).
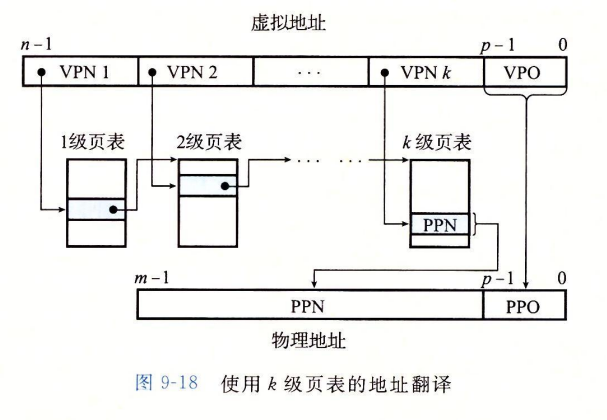
在
page table中存储的都是PPN而非VPN,VPN仅会在分割虚拟地址时被拿来描述
对于32位的RISC-V来说:
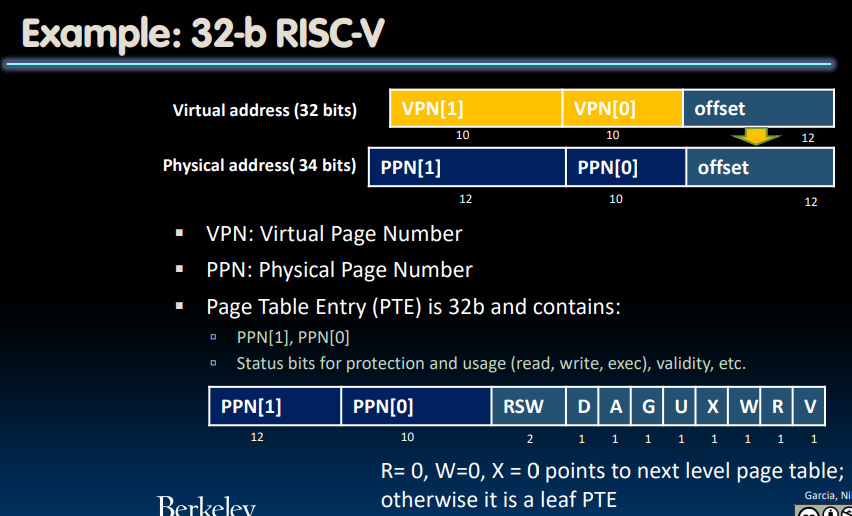
可以看到,在Page Table Entry的存储中设置了很多status bits:显然当$$R=0,W=0,X=0$$时我们不能够修改该page table的任何内容,这说明它指向下一级page table. 否则,这是一个leaf PTE(指向我们应当处理的page).
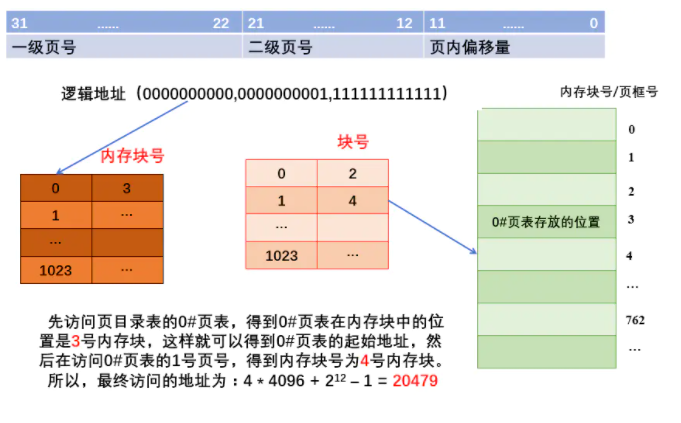
一个注意的问题:
若采用多级页表机制,则各级页表的大小不超过一个页面.
从知乎上copy一个回答:
作者:夏与冬 链接:https://www.zhihu.com/question/422716423/answer/1795166483 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1,为什么要对单级页表进行拆分?—-> 在不涉及快表,系统按字节寻址,并且采用分页式存储管理的情况下,一个进程对应的单级页表有可能过大,甚至大到占据了内存中的很多很多连续的页框,不仅会给内存分配造成压力,而且与离散分配的存储管理的思想向违背(降低了内存利用率),所以需要拆分页表,人们就让一组页表项刚好占据一个页框,就可以离散存储这些分组,然后建立上层页表来管理底层页表之间的逻辑顺序。
2,顶级页表这有一张这种树状结构是怎么来的?—-> 这样的拆分方式就像一棵树一样,每往上建立更高一层的页表,最高层就只有一张页表,也就是只有一个根节点,即专业术语中所说的顶级页目录表;当每往上建立一层页表后,该最高层的页表(即根页表)如果大于一个内存页框的容量,就又会往上进行拆分,建立更高层页目录表。
3,如果顶级页表设计成多张会怎样?—-> 如果顶级页表设计成了两张,甚至多张,由于每张页表的页号都是从 0 开始计数,所以需要区分查询的是哪一张顶级页表,这就对系统对从逻辑地址到物理地址的转换额外增加了压力和复杂性,如果不区分查询的是哪一张顶级页表,很显然页号会出现重复,这就是BUG了。
4,综上所述,顶级页表,甚至每一级的页表,都被设计成了一个内存框可以存下的样子,逻辑上是一个树状结构,符合离散存储的思想,具有内存利用率高的优点;但注意随着拆分层次变多,访存次数也会变多,需要权衡系统整体性能。
Translation Lookaside Buffers
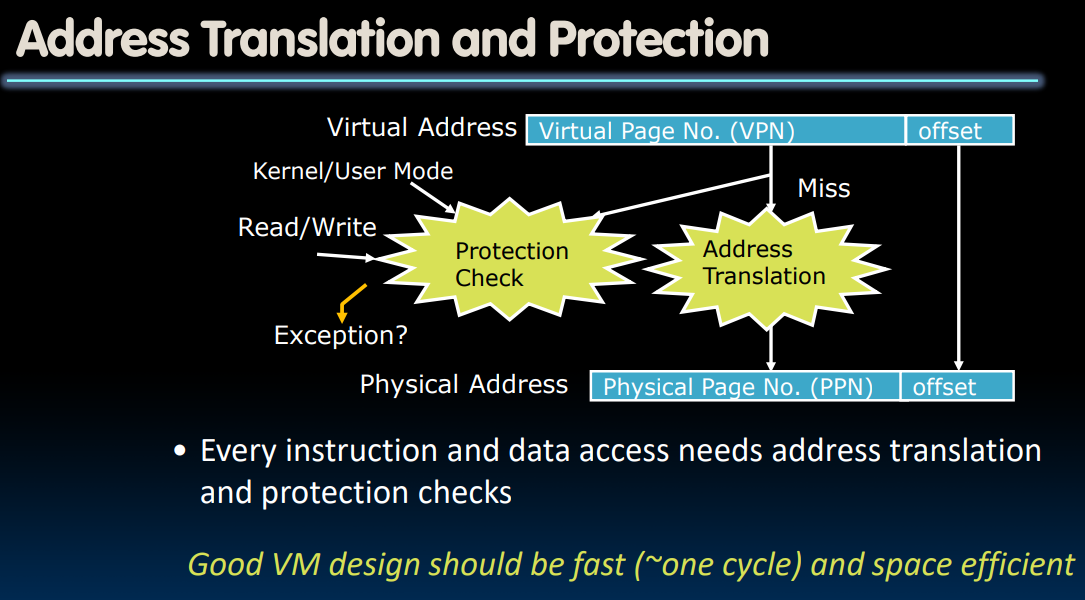
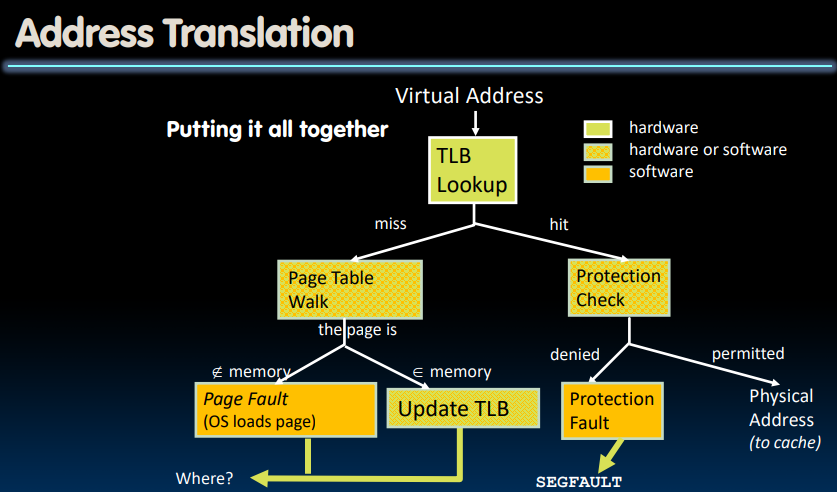
通过虚拟地址获取物理地址的过程中,我们首先要进行Protection Check,这一点在先前提到过。我们要确保想要获取的物理地址此时没有别的进程在使用(或者说正出于保护状态)、是否允许写入/读取该内存地址。如果发现不行,则抛出一个异常(throw an exception),并让操作系统来接管接下来的事情。
我们尝试把整个过程控制在one cycle以内。
但是问题是,Address translation是十分昂贵的!
In a single-level page table, each reference becomes two memory accesses.
In a two-level page table, each reference becomes three memory accesses.
即使是在借助cache的帮助下,可能也要花费1-2个时钟周期;而如果我们真的需要从DRAM中取出对应的page table信息,那么可能会耗费上百个时钟周期。
于是我们想是否可以借助于cache的思想?避免还需要从cache中取出PTE(其实实际上,TLB的提出要早于cache)
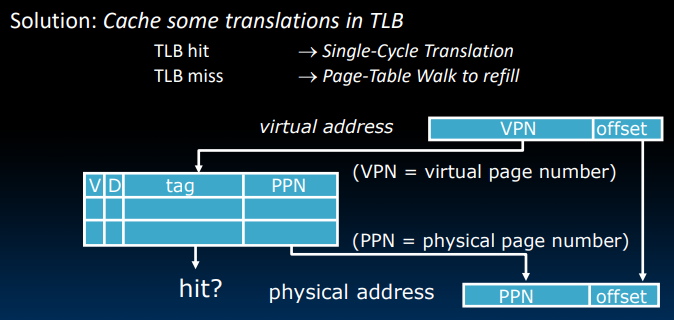
上图很清晰的表示了TLB的搜索过程。tag对应了VPN. 那么它是如何设计的呢?

TLB通常具有32-128个entry,通常被设计成fully-associative。有时在较大的较为复杂的TLB中,我们会使用4-8 way set-associative来做权衡。
对于TLB的替换策略,一般使用的是FIFO或者random,因为对于我们目标的one clock cycle而言,LRU策略的时间成本有点高。
“TLB Reach”: Size of largest virtual address space that can be simultaneously mapped by TLB
但即使是使用FIFO的替换策略,TLB的hit rate仍能够达到**99.9%**以上。
这里的关键点在于TLB可以帮助我们直接由VA得到PA,由于现代操作系统通常使用的是多级页表,在读取数据时(即使有cache也是一样),需要多次从主存/cache中获取页表数据。但是依靠TLB的存在,我们可以直接由最终映射的虚拟地址,获取真实的物理地址,显然这大大提高了我们的效率。
Where Are TLBs Located?
显然,TLB有充足的理由把自己放在cache前边,因为我们想避免的是从cache中取出Page Table Entry的过程。
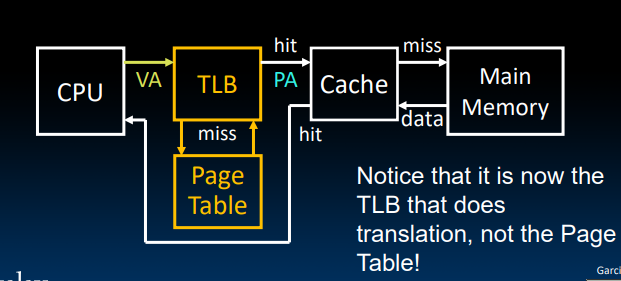
需要注意的是,此时执行address translation的不是page table而是TLB:
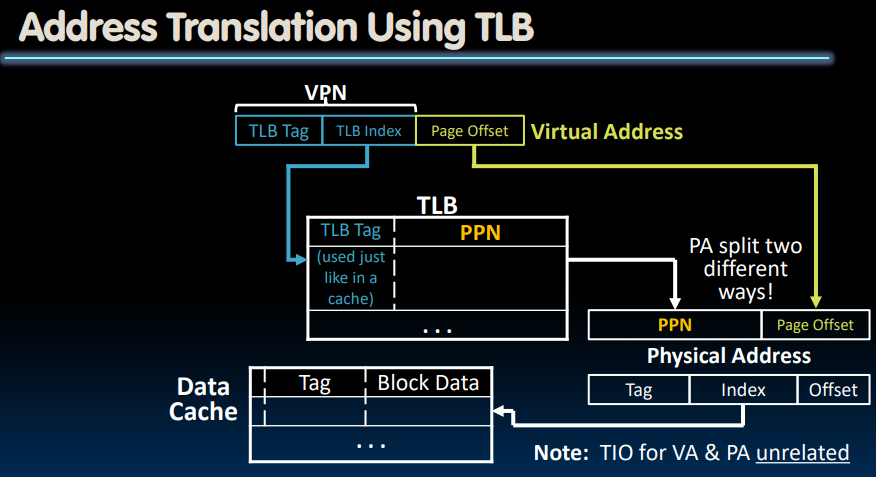
采用与cache中相同的策略,我们首先将virtual address中的VPN分成TLB tag和TLB Index。
cachestores the actual contents of the memory.
TLBon the other hand, stores only mapping.TLBspeeds up the process of locating the operands in the memory.
TLBs in Datapath

处理TLB miss的方法通常是硬件处理;在前边的操作系统简介中提到过,page fault也是一种异常模式,属于trap类型。我们提供precise trap,故可以通过使用software handler在缓存对应的page后恢复状态。
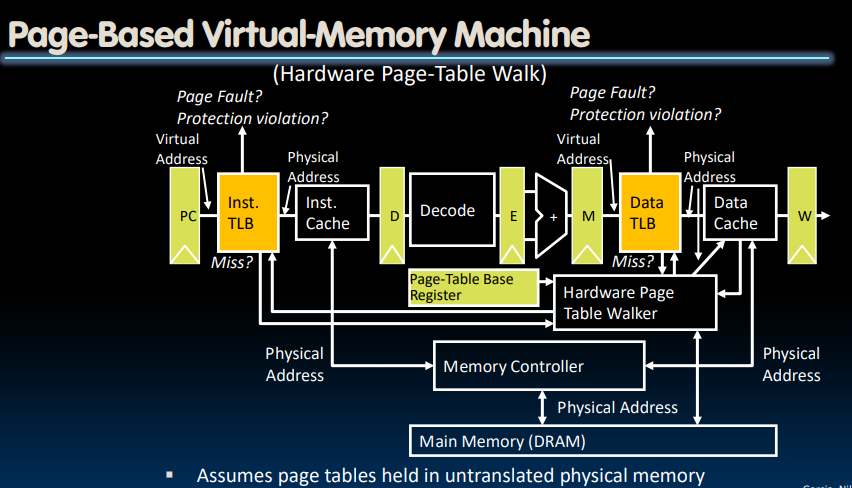
这里的memory controller借由CPU负责控制读写DRAM以及cache。

在进行context switch时,除了之前提到的存储寄存器状态之外,我们还需要改变SPTBR寄存器中的内容。而此时,由于TLB中存储的对应着不同的进程,我们需要将它们全部设置为invalid.
VM Performance
我们仍可以使用cache的评价标准来评判virual memory.即可以利用AMAT作为评价指标。



通过计算“需要从磁盘中获取数据”这一情况的AMAT,我们发现$$HR_{Mem}$$必须极为贴近1,才能够AMAT保证达到可以接受的程度。
VM Tricks
Copy-On-Write Duplication
根据维基百科:
“写入时复制“是一种计算机程序设计领域的优化策略。其核心思想是:如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
当我们在virtual memory中使用该优化策略时,该过程作如下细化:

当我们生成一个子进程时,仅复制一份page table和对应的状态寄存器内容,并将page table的原本和副本都设置为read-only,只有当我们尝试向某个进程中写入时,因为此时想要写入read-only memory,就会在protection check时进入protection fault handler,由于知道了具体需要写入的page,就可以复制一份page:
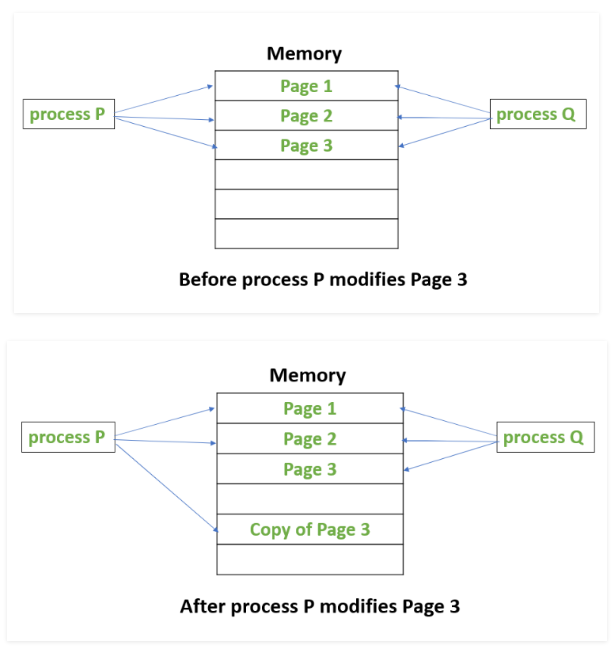
并将这两个page table中对应着PPN设置为可写.以后,如果我们还要更新Process P的page 3的内容就可以直接更新了。
如果我们需要处理一整个page table对应的内容,由于每一次都要经由protection fault handler的OS处理,所以是很慢的。但是全部使用的情况是很少的,所以我们每一次将代价控制在仅复制一个page table的处理还是可以接受的。
通过延迟私有对象中的副本直到最后可能的时刻,写时复制最充分的利用了稀有的物理内存。
Shared Memory Communication
有三种方法可以实现不同进程间的通信:
- 文件(要经过磁盘,很慢)
- pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- shared memory–相同的物理内存可以对应着不同的虚拟内存,也即“共享内存”:
Linux虚拟内存系统
Linux为每个进程维护了一个单独的虚拟地址空间:
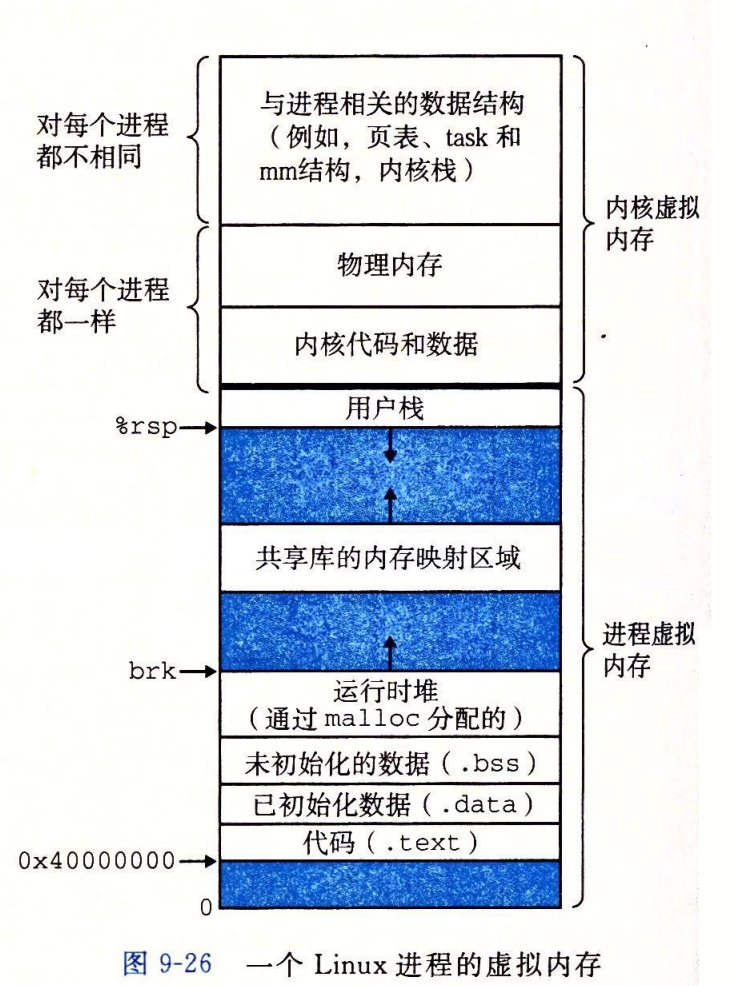
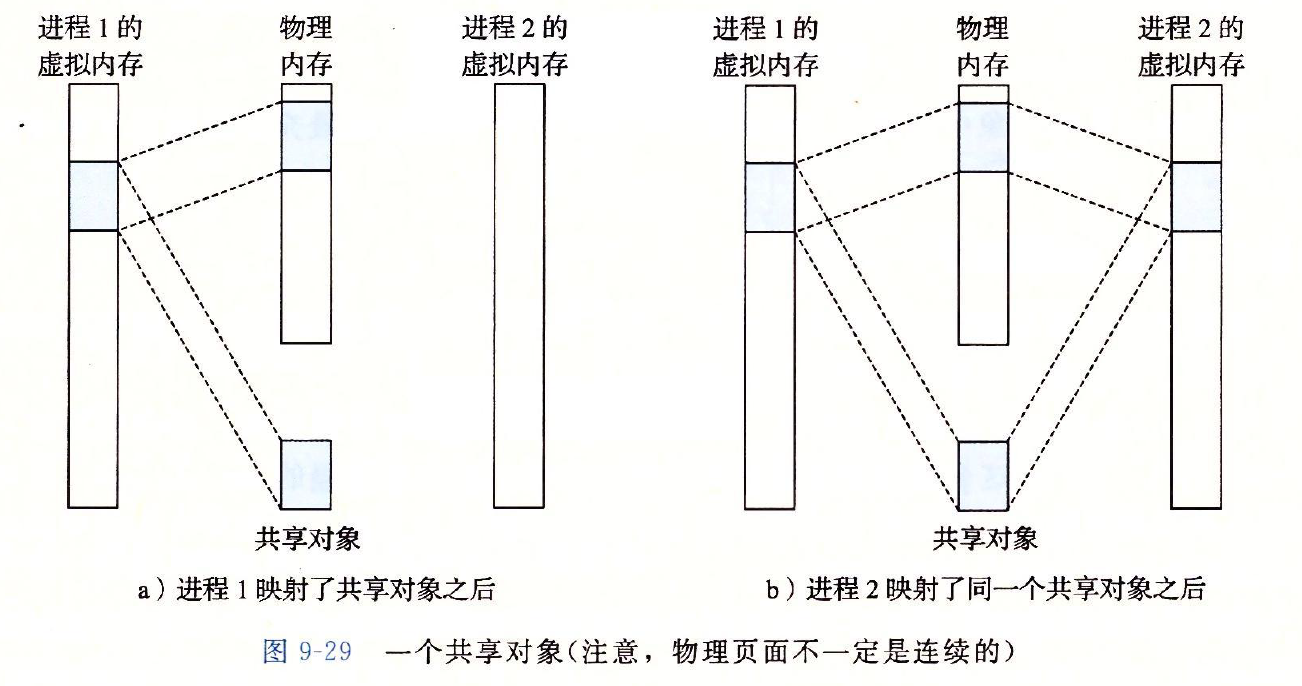
一个对象可以被映射到虚拟内存的一个区域,要么作为共享对象,要么作为私有对象。如果一个进程将一个共享对象映射到它的虚拟地址空间的一个区域内,那么这个进程对这个区域的任何写操作,对于那些也把这个共享对象映射到它们虚拟内存的其他进程而言,也是可见的。而且,这些变化也会反映在磁盘的原始对象里:
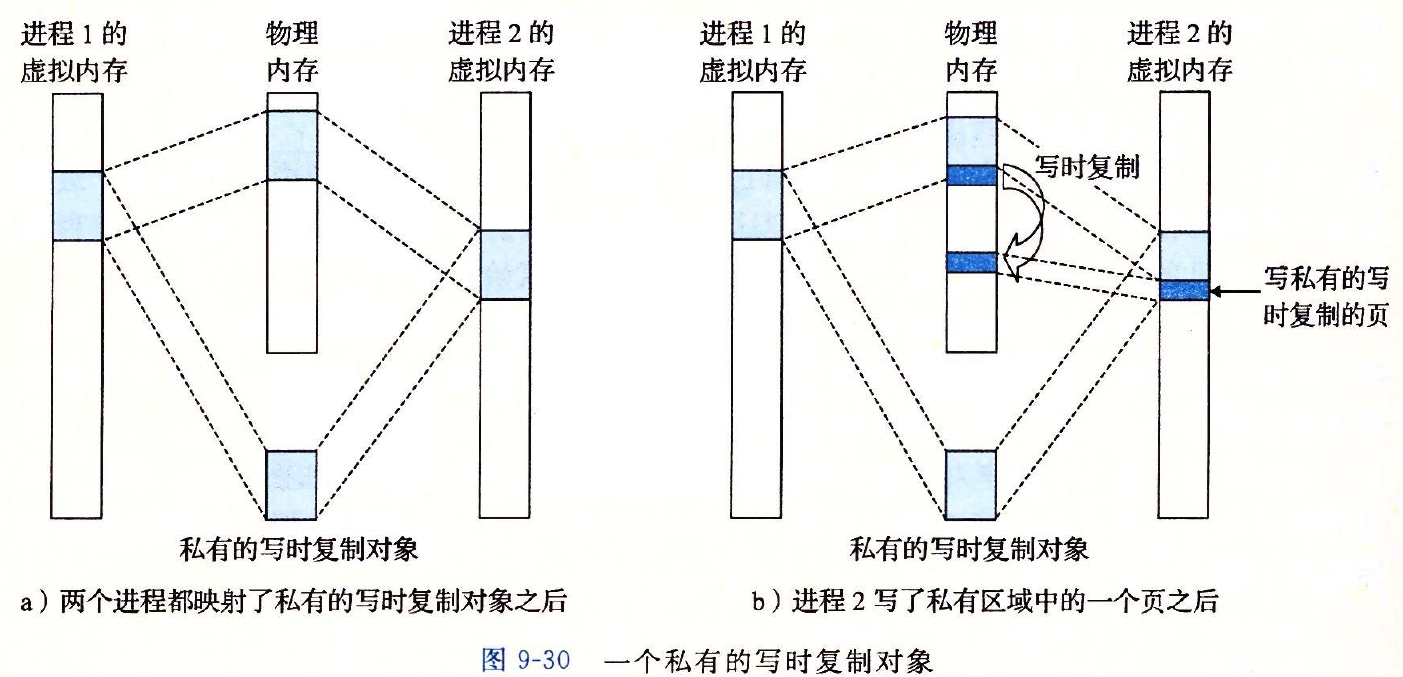
另一方面,对于一个映射到私有对象的区域做的改变,对于其他进程来说是不可见的,并且进程对这个区域所做的任何写操作都不会反映在磁盘的对象里;私有对象正是使用Copy-On-Write技术被映射到虚拟内存中:
此外,信号(signal)以及分布式中的套接字(socket)也是可以实现进程通信的方式,这里不详细描述。
Memory Mapped I/O
上一节提到,一直从磁盘中读写文件是很慢的,因为每次读取一行,都要跑到磁盘中读取一下。所以我们是否可以借助缓存的思想,每一次转移一大块文件内容到内存中,减少前往磁盘的次数?
当然可以的,virtual memory就可以用于实现这个目的——因为它一次将一个page的内容搞到内存中,这也是我们使用前边介绍的Memory mapped I/O带来的一个潜在益处 :
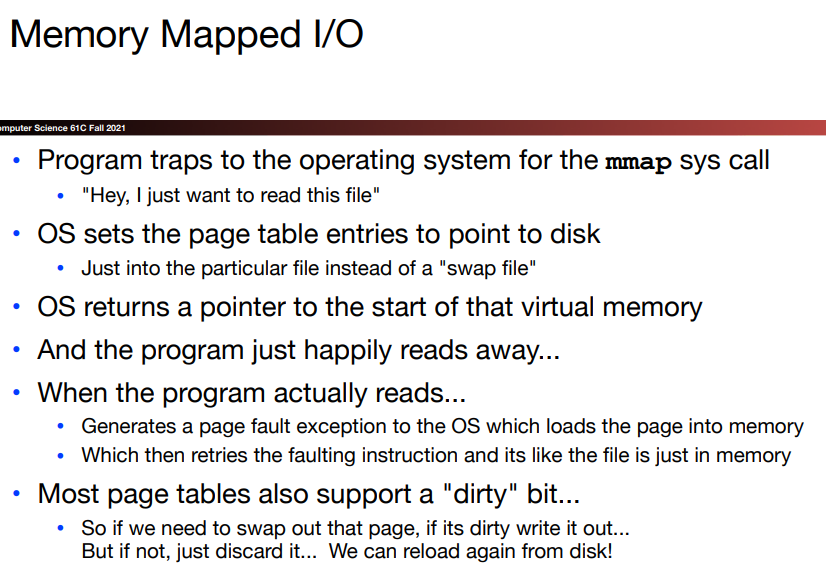
关于mmap这个函数,它要求内核创建一个新的虚拟内存区域,并将文件描述符fd指定的对象的一个连续的片映射到这个区域:
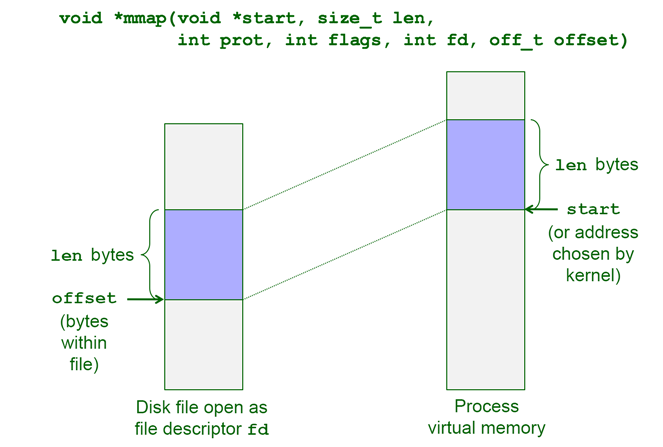
这里的一个关键点是映射的页面在被引用之前实际上并没有被载入物理内存。因此mmap()可用于实现将页面延迟加载到内存中(Demand Paging),这可以帮助我们节约内存和时间。
此外,mmap函数还可以将文件操作的速度大大提高,正如我们先前所说,传统的文件读写方法每次在磁盘和内存之间进行数据交换,涉及大量系统调用,其使用的read(),write()函数也需要对内容进行错误检查,并且他们的数据读取是需要通过Linux中的高速页缓存的等等:
这一小节的内容涉及一些Linux文件系统和内核的知识,我还没有专门学过,所以日后有机会再来补充吧。(这里好像有一篇不错的mmap的介绍文章)但之所以这种I/O被称为Memory-Mapped I/O,也是因为它把文件当作内存来用。
同时,page table也支持dirty bit,当我们写入文件时,如果需要该页换出时,dirty bit被设置,则将其页内容写入磁盘中;如果没有,则直接忽略这一个page的存储内容。
I/O
这部分大部分的内容存储在该文件中,不再博客中单独列出,仅就一部分关键知识点记录:
Bus & Switch
两种不同的interconnect结构:
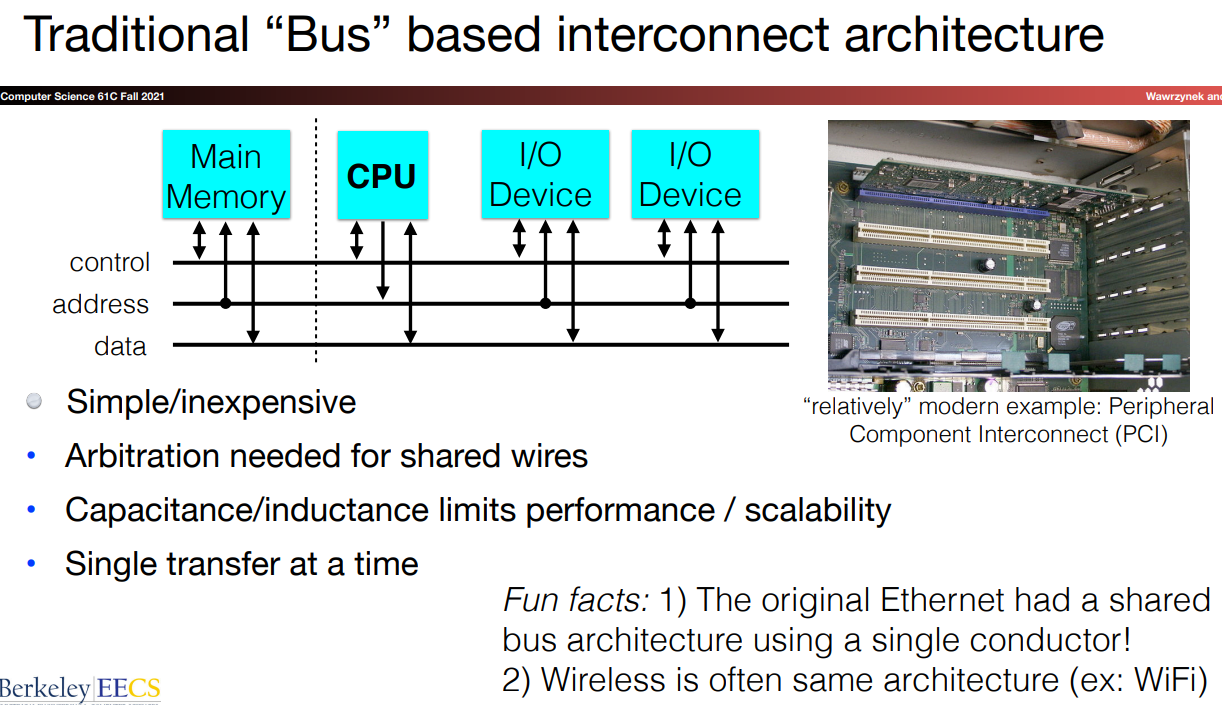

需要注意的几个点:
- 总线式设计需要考虑电线本身的电阻等品质,不能够过长
switch设计可以避免bus设计时one at a time的特点,可以做到同时上下/同层交流,所以也就有更好的表现。并且,由于这种电线的分离式设计,导线长度不会成为较大的干扰因素switch可以做到分离式控制- 由于
switch式设计有更好的性能表现,故当前的ETHERnet, PCle等都是用了这种processor interconnect结构.
PCI & USB
PCI-e一般用于计算机内部,不同模块之间的“高速数据通信”。注重的速度和稳定性,USB主要用于外接设备,注重的是兼容性和简洁性。

simplex意为
one direction
这种switch point-to-point的传输每次仅传输一个bit,但是他的速度是很快的!
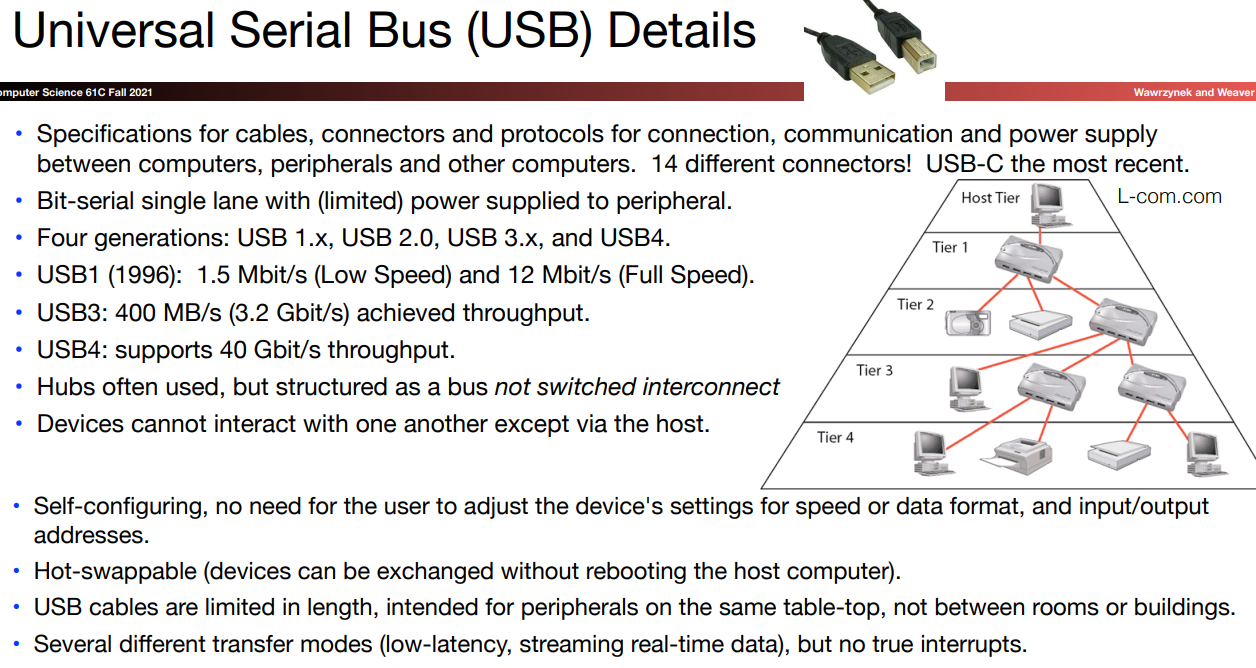
USB可以被组织为一个bus/hub,并不是一个switched interconnect,hub/bus不可以终止一个连接。USB使用同一条导线来发送和接收数据,所以不能够设计过长的长度,否则延迟也是一个很大的问题。但是虽然它不比PCle般可以并行传输数据,并且不支持过长的设计长度,但是他所建立的连接是极为稳定和鲁棒的。
DMA
我们的目的是不想让CPU把所有的事情都做了,因为数据传输的过程原本也由处理器全部控制,CPU要负责把数据在内存和设备之间来回搬运。现在,我们尝试让CPU聚焦在computing上。数据传送的工作交给DMA controller。
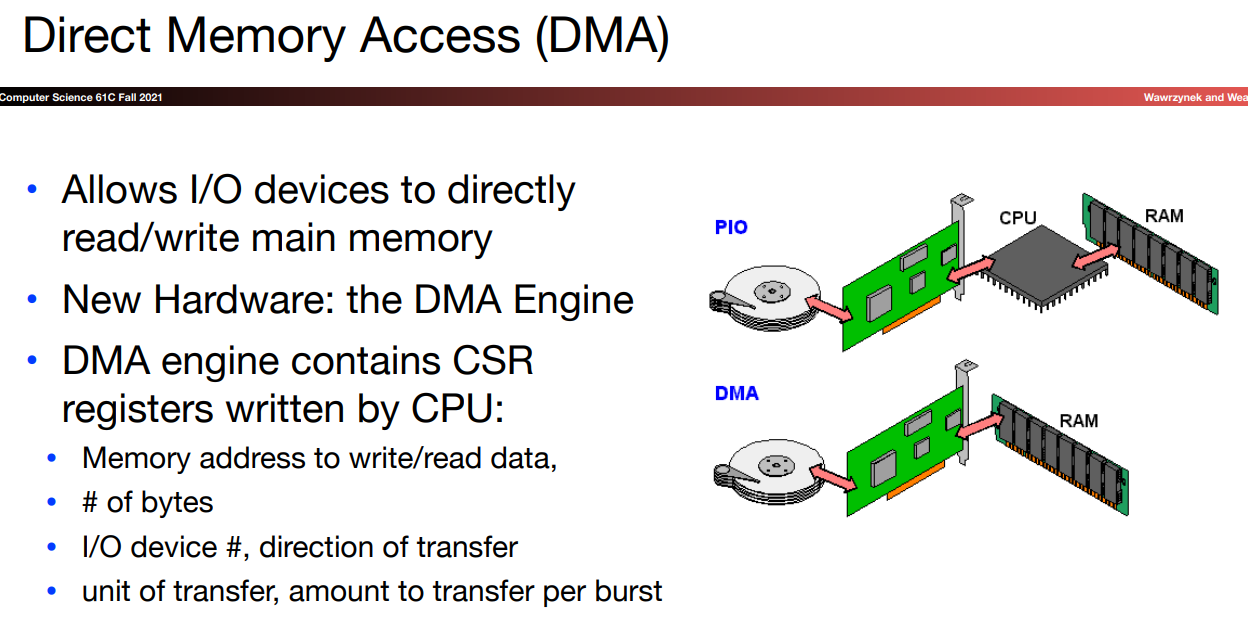
CPU需要向DMA Engine提供读取/写入地址、数据大小、转移方向等等信息。总得来说,CPU负责initiate the data transfer.数据传送过程如下图所示:
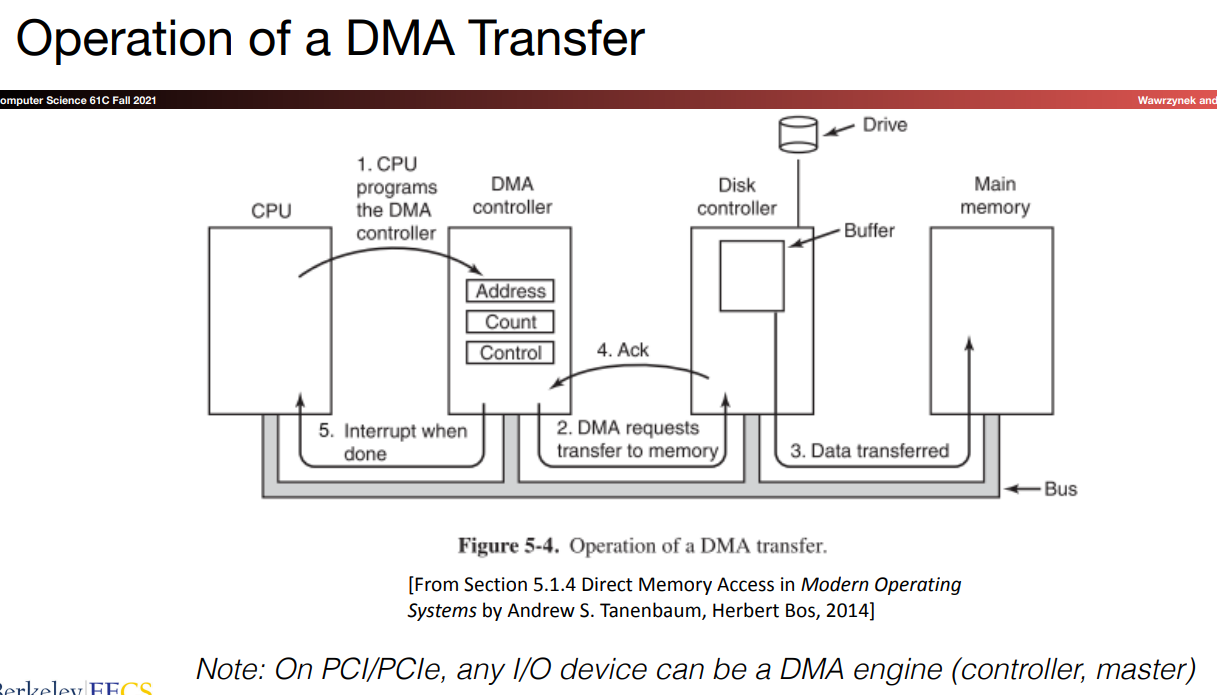
在后边我们会提到,disk中靠近
disk controller处一般都有一个cache-like structure,或者称之为buffer,我们将数据储存在其中,以增快数据传送的速度。
当数据传送结束后,disk controller发送给DMA controller一个ACK(Acknowledgement)信号,DMA controller再给CPU一个中断以表明传输结束。


confirm that externl device is ready By reading its CSR
Where to put DMA?

Disks
这部分内容参见课件。
Networking
本部分参见此文件。
根据维基百科:
互联网协议套件(英语:Internet Protocol Suite,缩写IPS)[1]是网络通信模型,以及整个网络传输协议家族,为网际网络的基础通信架构。它常通称为TCP/IP协议族(英语:TCP/IP Protocol Suite,或TCP/IP Protocols),简称TCP/IP[2]。因为该协议家族的两个核心协议:TCP(传输控制协议)和IP(网际协议),为该家族中最早通过的标准[3]。由于在网络通讯协议普遍采用分层的结构,当多个层次的协议共同工作时,类似计算机科学中的堆栈,因此又称为TCP/IP协议栈(英语:TCP/IP Protocol Stack)[4][[5]](https://zh.wikipedia.org/wiki/TCP/IP协议族#cite_note-5) 。
这里对TCP和UDP进行了一些介绍,这里有一些相关的说明。
内存I/O延迟
最后,再来提一嘴内存I/O。根据这里的文章,内存延迟有四个关键参数:
- CL(Column Address Latency):发送一个列地址到内存与数据开始响应之间的周期数
- tRCD(Row Address to Column Address Delay):打开一行内存并访问其中的列所需的最小时钟周期数
- tRP(Row Precharge Time):发出预充电命令与打开下一行之间所需的最小时钟周期数。
- tRAS(Row Active Time):行活动命令与发出预充电命令之间所需的最小时钟周期数。也就是对下一次预充电时间进行限制。
需要注意的是,在实际计算时,tRAS很可能会
cover掉CL+tRCD+tRP,因为tRAS往往较大,在一次发出行活动命令->预充电->访问列->取出数据后,我们不能立即做下一次的数据读取和存储,正是因为tRAS限制了两次预充电命令的时间间隔。
也正是因为这些个数据的存在,使得内存的随机I/O要比顺序I/O慢出不少,因为如果行活动指令给出的定位不同,我们必须重新加载(预充电)等等之后才能做新的I/O操作。
Parallelism
最后一部分内容聚焦并行计算。
Flynn Taxonomy, SIMD Instructions
本章节内容以dgemm(double-precision floating-point general matrix-multiply)为切入点,介绍并行计算的基本问题和基本方法。
我们一般的矩阵表示模式如下:

我们可以将矩阵$$a[][]$$表示为row-major:
$$a_{ij}:a[i*N+j]$$
或者column-major:
$$a_{ij}:a[i+j*N]$$
Fortran使用column-major的表示方法,所以在示例中我们遵循column-major的表示方法。
下边开始对dgemm进行逐步优化:
- Python

- C
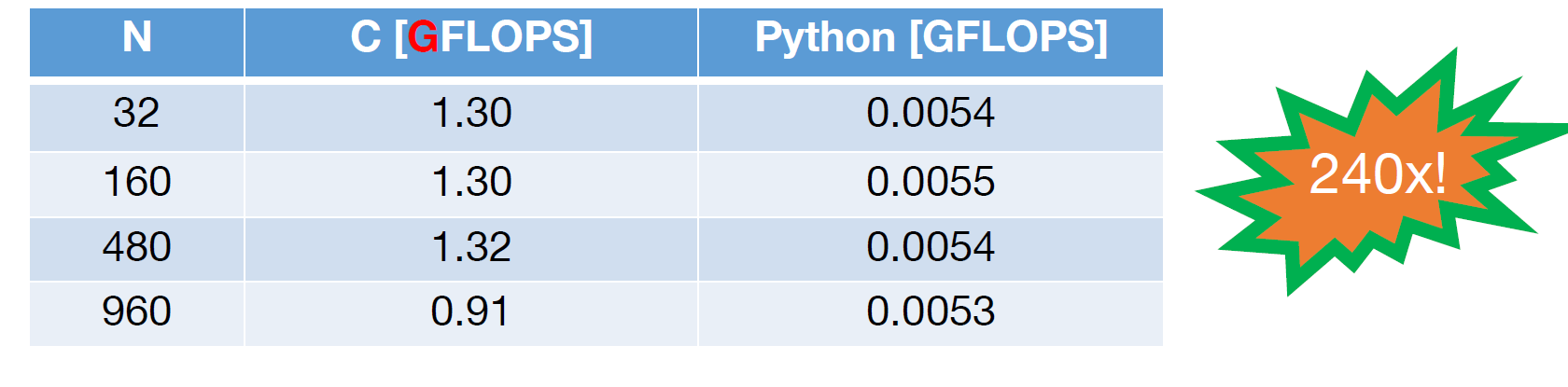
但我们还可以做得更好!
Why Parallel Processing?

对于“并行”,我们一般有两种基本方法:较为简单的是Multiprogramming,即并行运行多个项目。而更难实现的是Parallel computing,即如何让一个程序运行的更快。
Flynn Taxonomy
接下来,我们有几种计算模式:
- SISD

- SIMD(
sim-dee)
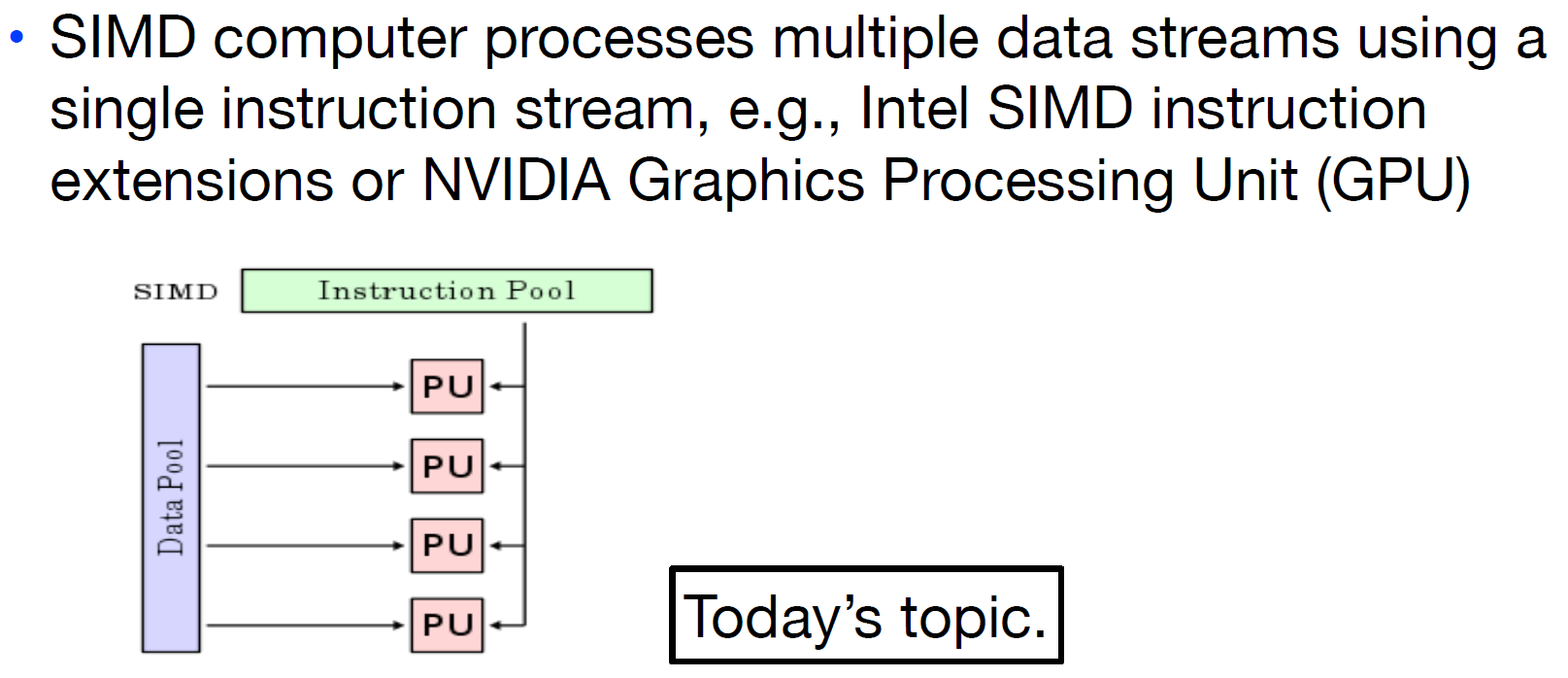
- MIMD(
mim-dee)
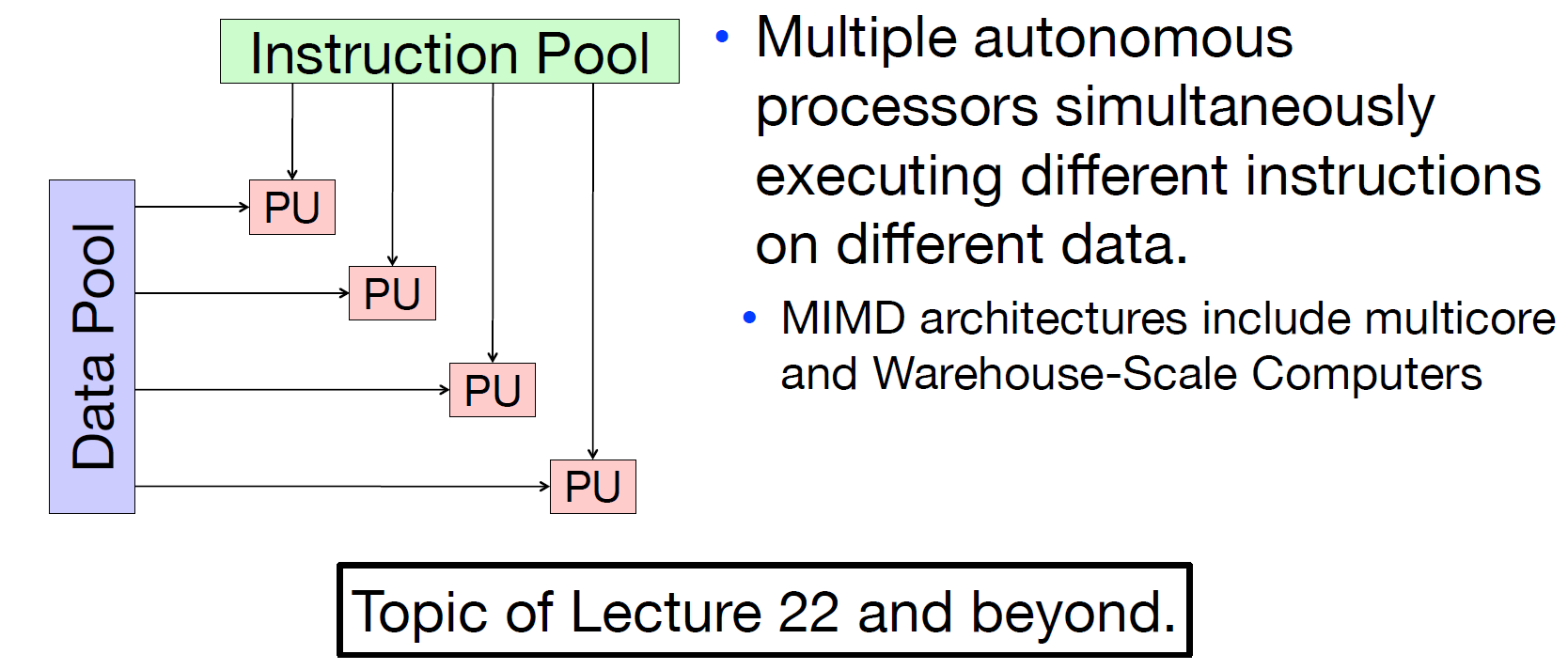
- MISD
No examples today.
而所谓的**费林分类法(Flynn's Taxonomy)**正是根据information stream分为指令和数据两种,又将计算机类型分为了如上四种。
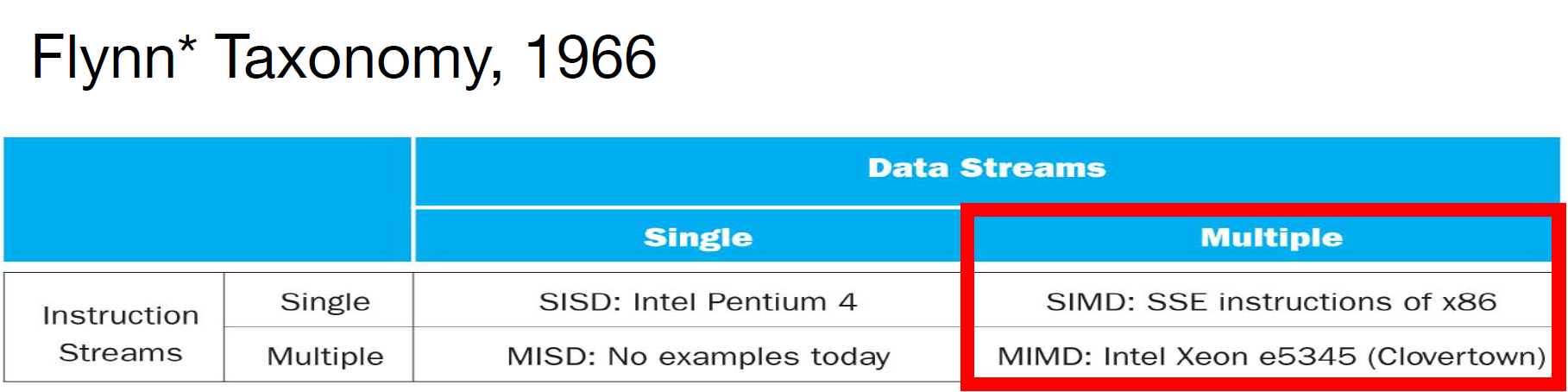
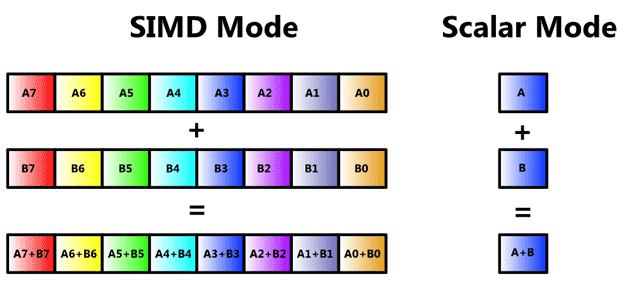
SIMD Mode/history
SIMD处理器的发展也经历了诸多变革:
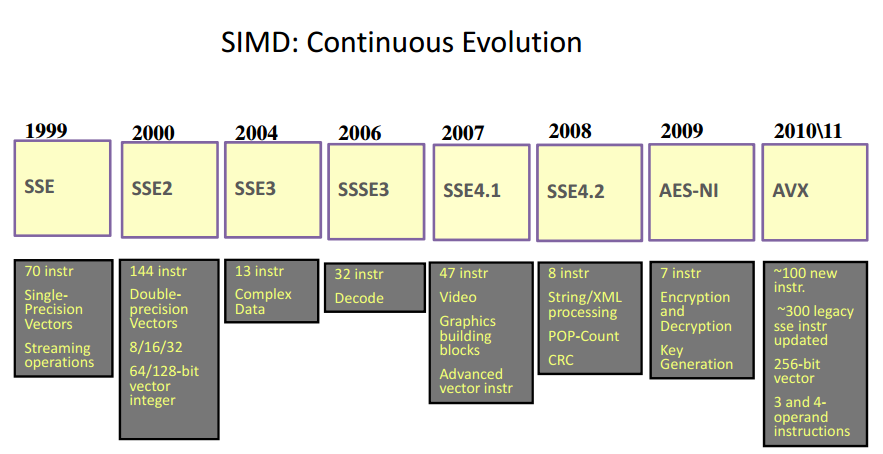
其中,AVX,即高级向量扩展指令集也经历了如下变革。

这里有一篇资料详细介绍了其发展历程:

简略来说,我们单独准备了一套SIMD寄存器,比如对于256-bit SIMD register来说,我们可以输入4个64-bit的数据,这样便可以并行计算这4个数据:
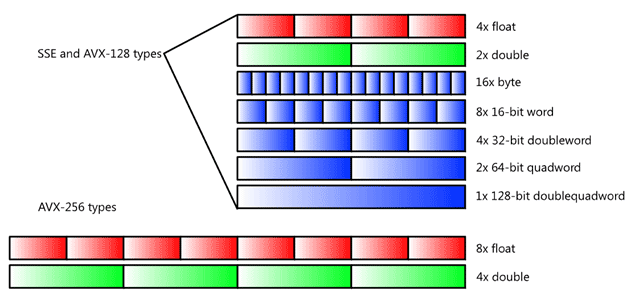

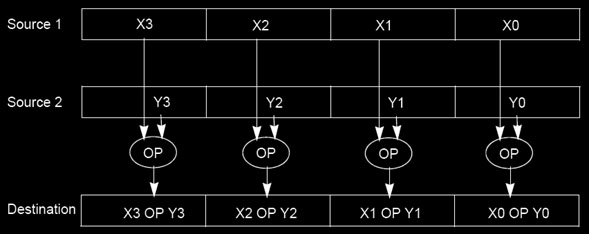
SIMD on matrix multiplication
可以查阅x86 SIMD “Intrinsics”
在先前我们对比了C与Python写出的degmm代码的FLOPS性能,虽然C较Python的提升较大,但是我们可以通过计算Peak double FLOPS来判定我们距离目标还有多远:
假设我们使用的是i5-5557U的处理器,则其Clock rate为3.1GHz,对于double类型的数据,从上面的图中可以看出,一条指令可以允许我们进行4次算术运算。
$$3.1GHz\times inst/cycle\times mults/inst=24.8GFLOPS$$
所以截至目前,我们还离预期很远。所以我们尝试利用AVX-256指令做些事情:

或者也可以写成如下形式:

我们将上述代码表示成图的形式:
通过上述代码,我们达到了一条指令可以处理4个数据的目的,所以预想大概是会快了四倍:
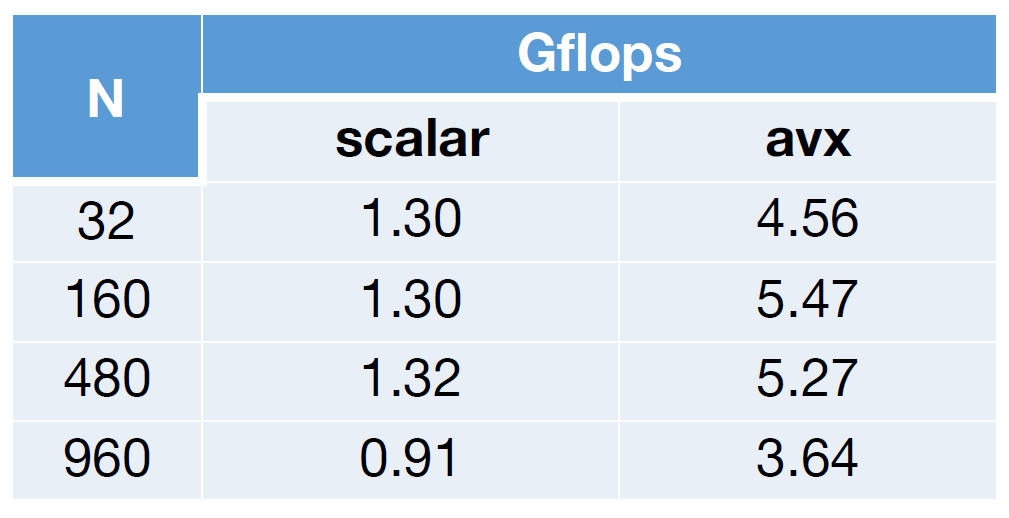
但是这离目标还很远啊!
Loop Unrolling
loop unrolling可以帮助我们继续提高性能表现!


我们在循环内部设置一个小循环(从而外部循环的递增模式也要随之改变,每次递增4个)。这样做的好处有:
- 注意到该实现中,存在许多的dependencies,比如
mul依赖于load,add又依赖于mul。这就会产生data hazards,我们必须在pipeline中做多个stall已解决问题,显然大大降低了性能表现。而当我们设置一个UNROLL的内部小循环之后,由于编译器可以提前得知UNROLL的值,故编译器会将这个小循环的代码展开,并使用先前提到的另一种解决data hazards的方法,即reorder——(e.g. load, load, load, load, mul, mul, ..., add, ...)并利用处理器的super-scalar结构提升运算效率! - 由于内部UNROLL循环的存在,$$i$$每次增加的值就不仅仅是4了,而是$$UNROLL\times 4$$.这会降低我们进行条件跳转判定的次数,进而减少发生control hazards的可能性!
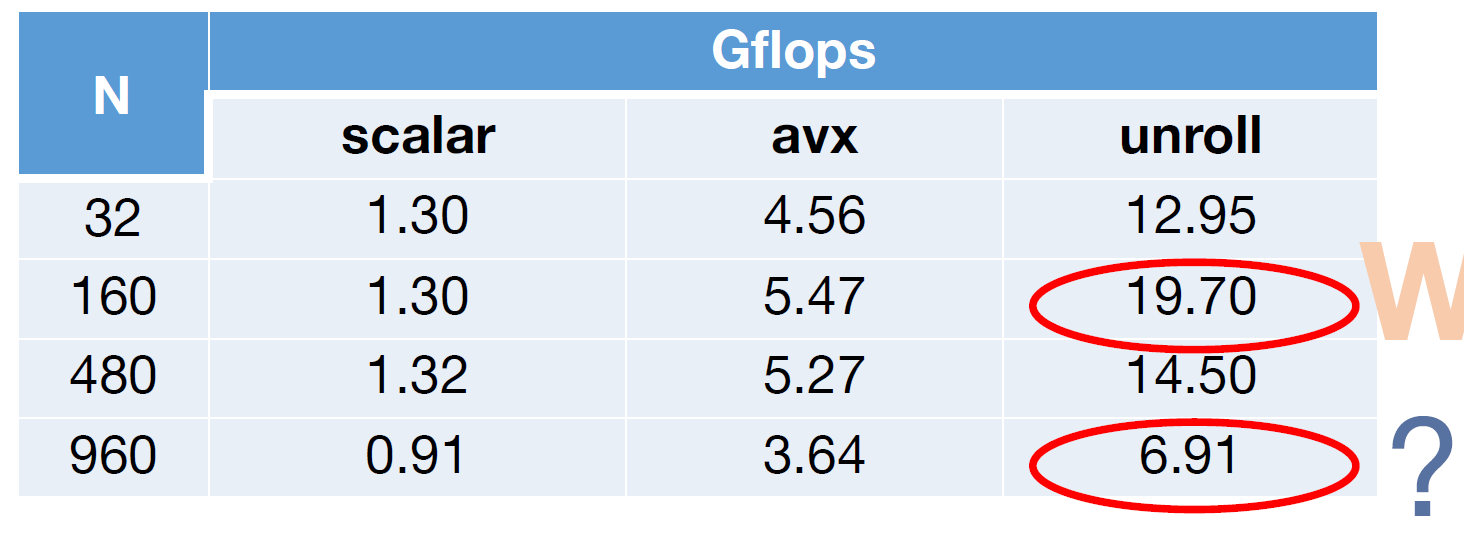
现在,当$$N$$不太大时,结果已经接近最佳,但是在最后却出现了fall off a cliff,这是为什么呢?
Memeory access strategy - blocking
首先,假设每个矩阵的每一个元素都只需要从DRAM中获取一次:

显然,这是一个不错的假设,因为$$\frac{2}{3}N$$的结果意味着后续大量的数据运算都不需要再从内存中搬运了。但是事实果真如此吗?

事实上,我们需要ld/sw的次数绝对不止每个元素一次。这就带来一个问题:如果我们每次都要从DRAM中搬运数据,将会产生不可接受的时间代价!这也是为什么cache的相关优化十分重要了。
这就回到了先前在cache部分介绍过的Blocking Matrix Multiply方法(实际上是分治思想的运用):

再看下此时的性能指标表现:
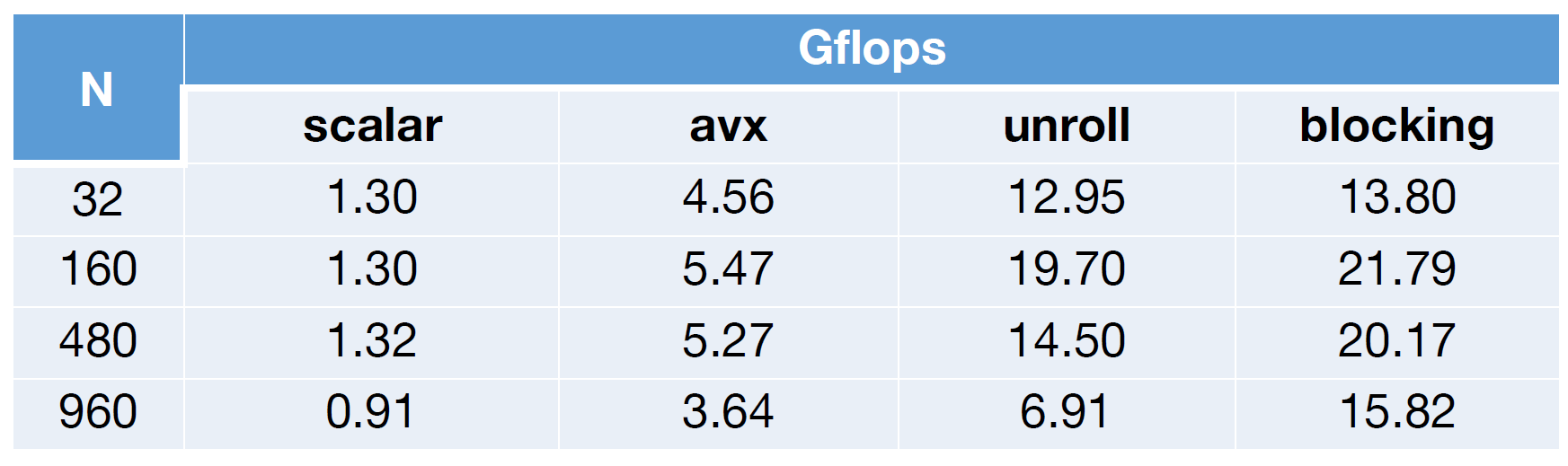
在$$N$$为960时的性能断崖不复存在了。
Thread-Level Parallelism
Amdahl’s Law
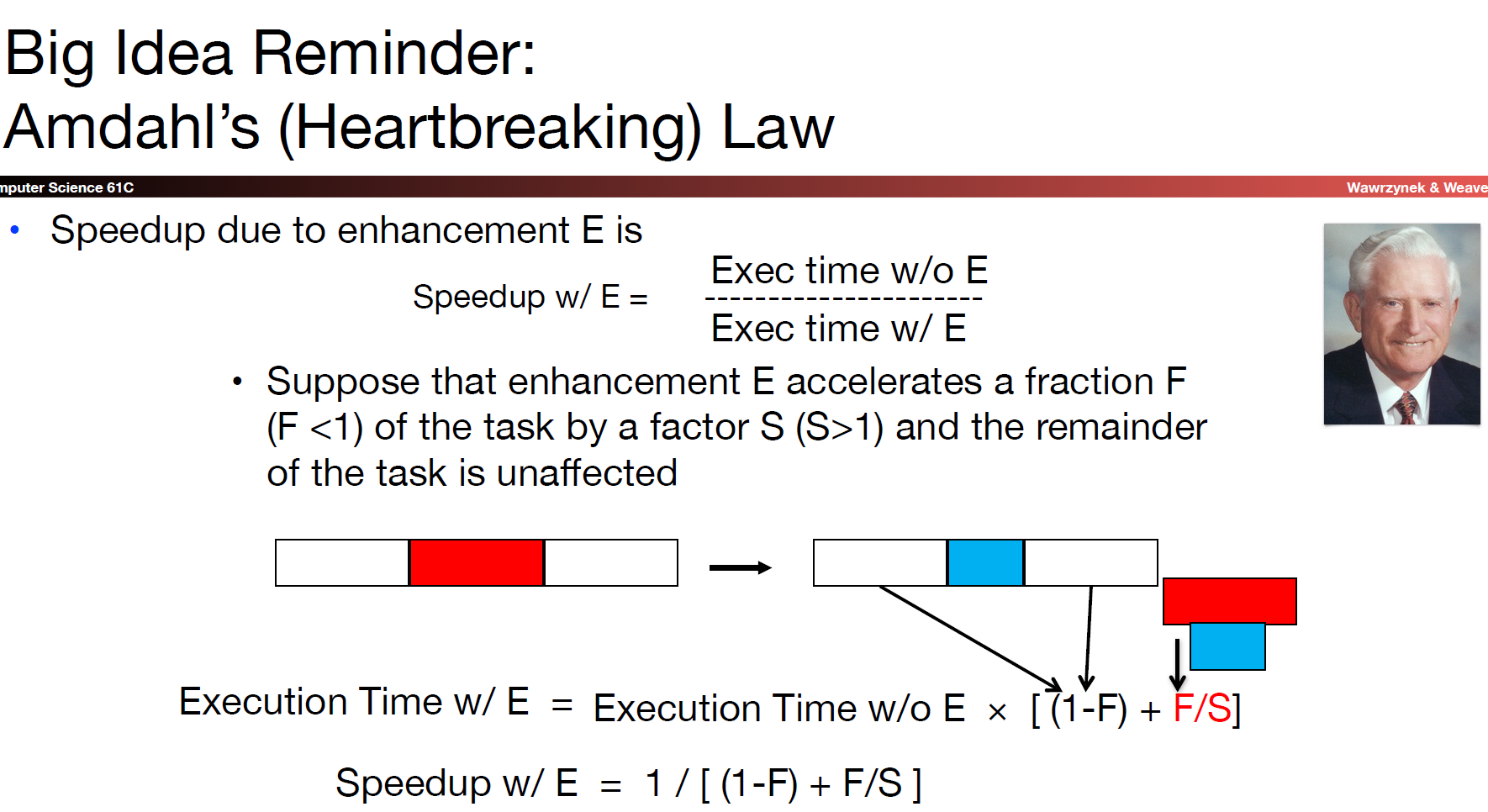
上图中的最后一个等式就是阿姆达尔定律的数学表示形式。阿姆达尔定律告诉我们,即使我们对系统中的并行部分做再多的功夫来提升其性能,最终bottleneck还是在于系统中剩下的串行部分的表现。如果串行部分占比很大,那么即使将并行部分优化到极致,对于系统整体性能的提升效果也不会很明显:
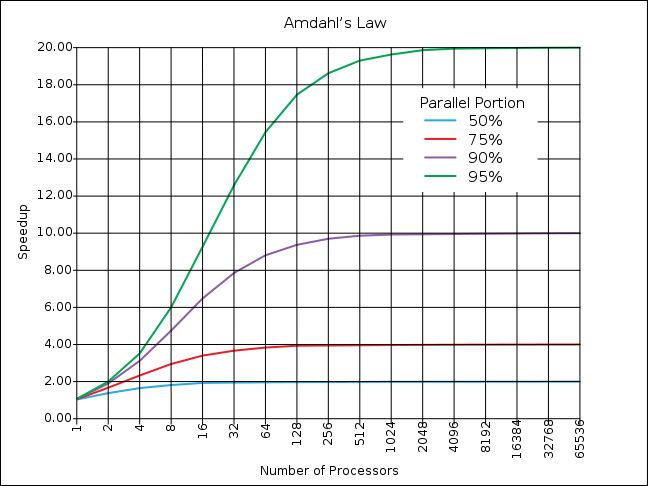
所以我们当然想把整个系统都变成并行运行的。
阿姆达尔定律在现实中也有许多应用场景:

Parallel Computer Architectures
为了提升计算机的性能表现,我们有如下几种方式:

首先,关于时钟频率,这里多提几句。根据这里的文章,我们有核心频率,数据频率和时钟频率这三个常用频率。其中,核心频率是内存电路的振荡频率,是内存工作的基石。时钟频率用于传输数据;核心频率用于颗粒内部对这些数据的处理,比如发送数据前,需要对颗粒bank激活、然后读取数据,然后预充电,这些数据处理相关的工作,都是工作在核心频率下。其余两个频率是在核心频率的基础上,通过各种技术手段放大出来的。其中数据频率是时钟频率的两倍,因为在时钟信号的上沿和下沿均可以传输数据:

而核心频率本身受制于工艺技术问题,已经多年没有实质性进展,因为随着晶体管尺寸越来越小,半导体工艺的提升逐渐逼近极限,单纯提升芯片的工作频率越来越困难。
multiprocessor(multicore)的结构意味着我们有多个独立的处理器,其中各自具备一套完整的Datapath+control,除了下图所示的结构外,我们注意还需要花费一些功夫来处理先前提到的cache coherency miss问题:
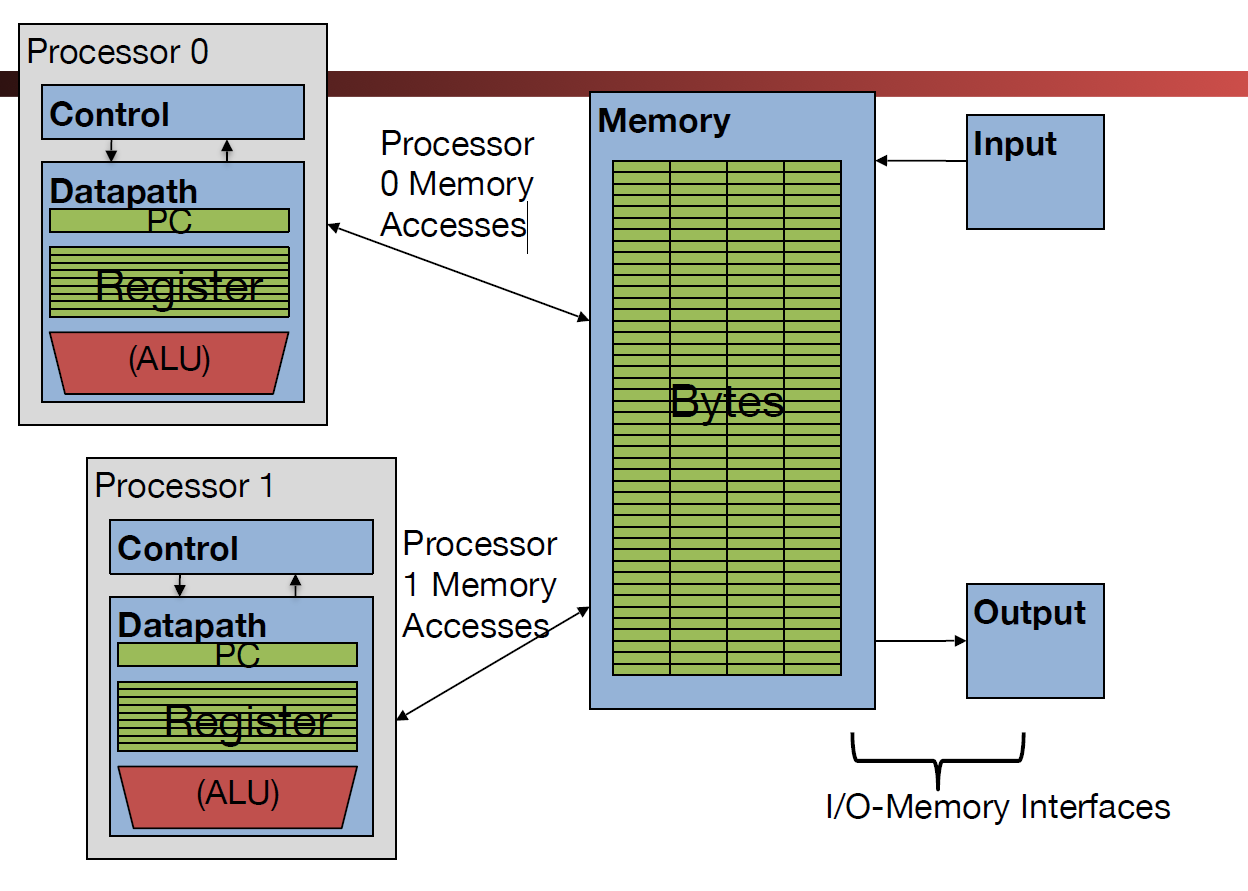
- Each processor has its own PC and executes an independent stream of instructions(MIMD)
- Different processors can access the same memory space, each “core” has access to the entire memory in the processor (Processors can communicate via shared memory by storing/loading to/from common locations)
一般来讲,使用multicore的方式有两种,一是每一个核负责独立的工作(job-level parallelism);第二种是对于同一个程序,将其运行在多个核中(parallel-processing program).第二种正是我们目前打算研究的主题,如每个核负责一部分矩阵乘法运算。
另一方面,所谓的parallelism的方式也有两种,即我们提到的SIMD与MIMD。
- A SIMD-favorable problem can map easily to a MIMD-type fabric
- A MIMD-favorable problem will not map easily to a SIMD-type fabric
并且,SIMD的设计相比于MIMD要更加简单,且性能更高!
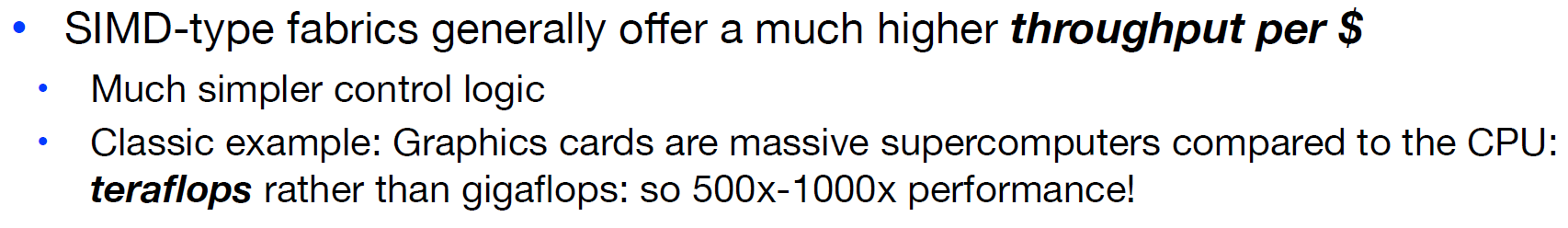
Strong and Weak Scaling

Multiprocessors & You

这里需要注意的是,如果我们目前处在scale up的状态,那么一定可以scale down:比如一个运行在12核的程序一定可以也可以在4核处理器上体现出它的并行优势,但是如果程序本身就是最多4核运行,我们想让它在12核处理器内取得较高的性能表现并不是那么容易。
Threads
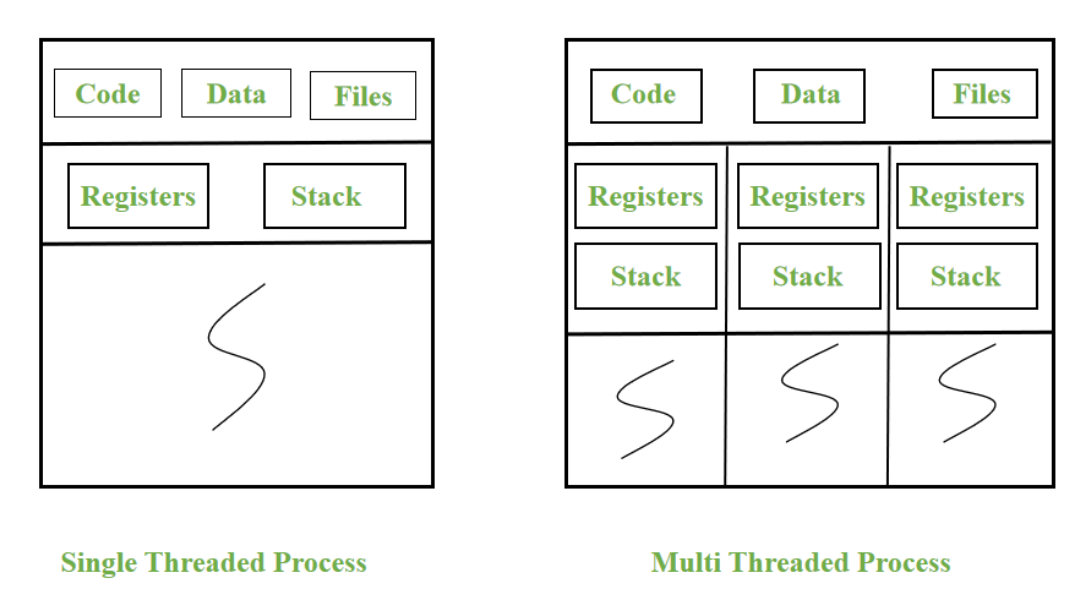
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。线程又分为软件线程和硬件线程;

进行到这里,我们来解决两个问题:
- 进程与线程的关系(区别)
- 硬件线程与软件线程(由操作系统调度的)有什么联系
首先,关于进程与线程,这里的回答说的比较清楚:

在多线程环境下,每个线程拥有一个栈和一个程序计数器。栈和程序计数器用来保存线程的执行历史和线程的执行状态,是线程私有的资源。其他的资源(比如堆、地址空间、全局变量)是由同一个进程内的多个线程共享。
其次,关于硬件线程和软件线程:
- 软件线程,可以分为内核线程(
klt),即operating system threads,以及用户线程(ult)。这里我们主要讨论klt,klt会被映射到硬件线程上,但由于硬件线程的数量有限,所以某些软件线程会处于waiting的状态,那么软件线程的工作机制大致如何呢?

- 我们会在两种情况下将某一些软件线程从硬件线程上换出:
blocked threads以及按照固定时序要求的线程置换(这也是我们能够在单核非超线程的硬件机制下执行多线程程序的原因,即time sharing):

线程的切换也使用了类似于进程切换的context switch的方法,但是需要保存的状态内容相对较少。
关于硬件线程,我们不想让CPU在遇到cache miss后等待数据传送过来的过程中什么也不做,所以想要切换到别的线程上,而硬件线程的设计可以帮助我们更好的解决这个问题——由于硬件线程结构设计的存在(
redundant hardware),我们无需在每次thread switch时保存对应的context.正是基于上述原因,每一个处理器内核可以提供一个或者多个线程,这里的“线程”指的是硬件线程。比如目前我们常在Intel的处理器指标里看到
2 threads/core,这种设计又被Intel称之为超线程技术(Hyper-Threading(HT)/Simultaneous Multithreading(SMT))。在一个处理器内核中有多套PC寄存器等:
当超线程技术处于激活状态时,CPU会在每个物理内核上公开两个执行上下文。这意味着,一个物理内核现在就像两个“逻辑内核”一样,可以处理不同的软件线程。
如上图所示,超线程技术也共享某些资源,比如cache,execution units等等.
截至目前,我们知道multithreading有两种实现方式:

ult & klt
前边提到,软件线程又可以分为内核线程以及用户线程。之后我们使用的openMP由于基于GCC,使用的就是klt。简单来说,用户线程通过某种手段映射到内核线程上,内核线程再被操作系统映射到硬件线程上得以实际运行。
ult与klt之间存在多重映射关系,包括一对一、多对一、多对多(N-M),以及两层设计(多对多 & 一对一)方式。在Linux中使用的是一对一的映射模式.(下图表示的是多对一的映射模式)
根据这里的回答,并且在Linux中比较特殊的一点是,Liunx内核不提供任何特殊的调度信息和数据结构来表示线程。线程本质上就是一个进程,只不过该进程和其他进程共享某些资源。这一点可以从Linux“线程”的创建和普通进程的创建上得到验证:进程在内核由对应的
task_struct数据结构表示,创建线程调用的clone()函数不过是指定了创建的新的进程中父子进程共享了更多的资源,如地址空间、文件资源、文件描述符和信号处理函数。
关于进一步的描述这两者之间的联系,可以看这几个参考资料:
但简而言之,用户线程需要映射到内核线程,因为内核将线程调度到CPU上执行,因此它必须知道它正在调度的线程。对于一个简单的进程,内核只知道进程的存在,而不知道在其中创建的用户线程,因此内核只会将进程的线程(这是内核线程)调度到CPU上,进程中的其他用户线程则必须一一映射到指定给创建进程的内核线程上(具体的映射模式可以是多对一,一对一等等)。
用户线程和内核线程的优劣各自互补:ult由于是在user mode下由用户程序直接进行管理,在进行I/O操作时需要频繁切换到内核态;也正是由于此原因,线程间通信也需要支付额外的系统调用成本。而klt虽然拥有较高的执行权限且I/O无需进行系统调用(因为本身就在supervisor mode下),但是它创建的时候需要进行系统调用,且相比ult其扩展性要差一些。
Latest modern processors: Big/Little design

- efficiency cores: energy efficienct
- Why M1 Pro has only 1 thread/core?
- Simultaneous multithreading only works well when the twos have same working set.
- The chip size improves about 6%~10%, which will have bad effects on the cache.
OpenMP
关于OpenMP的使用,这里不单独列出。
Data Races & Synchronization

一个线程尝试向内存中写入数据,那么此时最终的结果是不确定的!(无论另一个线程是想要向内存中写入数据还是读取数据)这取决于哪个线程先完成它的工作。
为了解决Data Race,我们可以使用lock synchronization。基本思想是在一个线程已经读取该位置并且尝试改变两个线程的共享变量之前,留下一个note,即加一个锁。如果另一个线程此时也尝试读取/写入该共享变量,我们就告诉它等一等,等前一个到达的线程把锁解开之后你再来处理该变量。如此一来,我们的行为就是确定性的了:

一个简单的lock synchronization逻辑如下:

Possible Lock Problem

如何解决上图所说的这种问题?
Hardware Synchronization
如何处理上述问题?这需要硬件与软件的结合工作。这里,我们主要介绍软件层面的指令方案:

RISC-V option one

只要在
load reserved之后有对该内存位置的读/写,reservation bit就会变为invalid。接下来的store conditional就会失败(即不发生)。

我们可以利用这两个指令来完成*Test-and-Set*的过程,即实现lock operations:

li t2, 1
Try: lr t1, s1 # load state & set a reserve bit
bne t1, x0, Try # check if unlocked?
sc t0, s1, t2 # if unlocked, try to own & lock
bnez t0, Try # lock operation successful?
Locked:
# critical section
Unlock:
sw x0, 0(s1)
RISC-V option two
Atomic Memory Operations(AMOs):

所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何context switch(切换到另一个线程)。

Deadlock

Limiting Parallelism

Shared Memory & Caches
Multiprocessor Key Questions
- Q1 -
How do they share data?
Single physical address space shared by all processors/cores
- Q2 -
How do they coordinate?

- Q3 -
How many processors can be supported?

Let’s talk about caches again
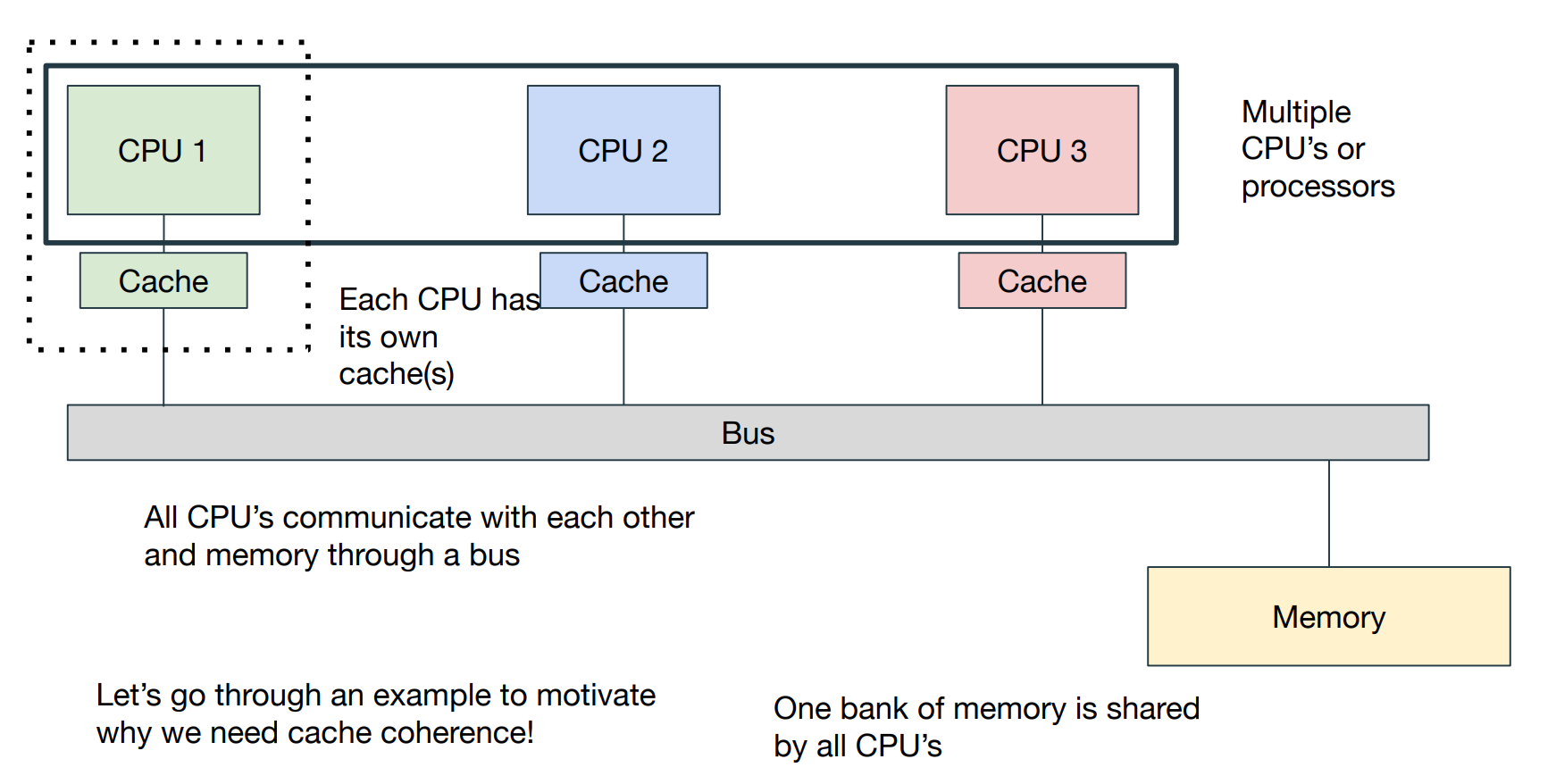

MOESI
在这里,我们引入了MOESI模型:


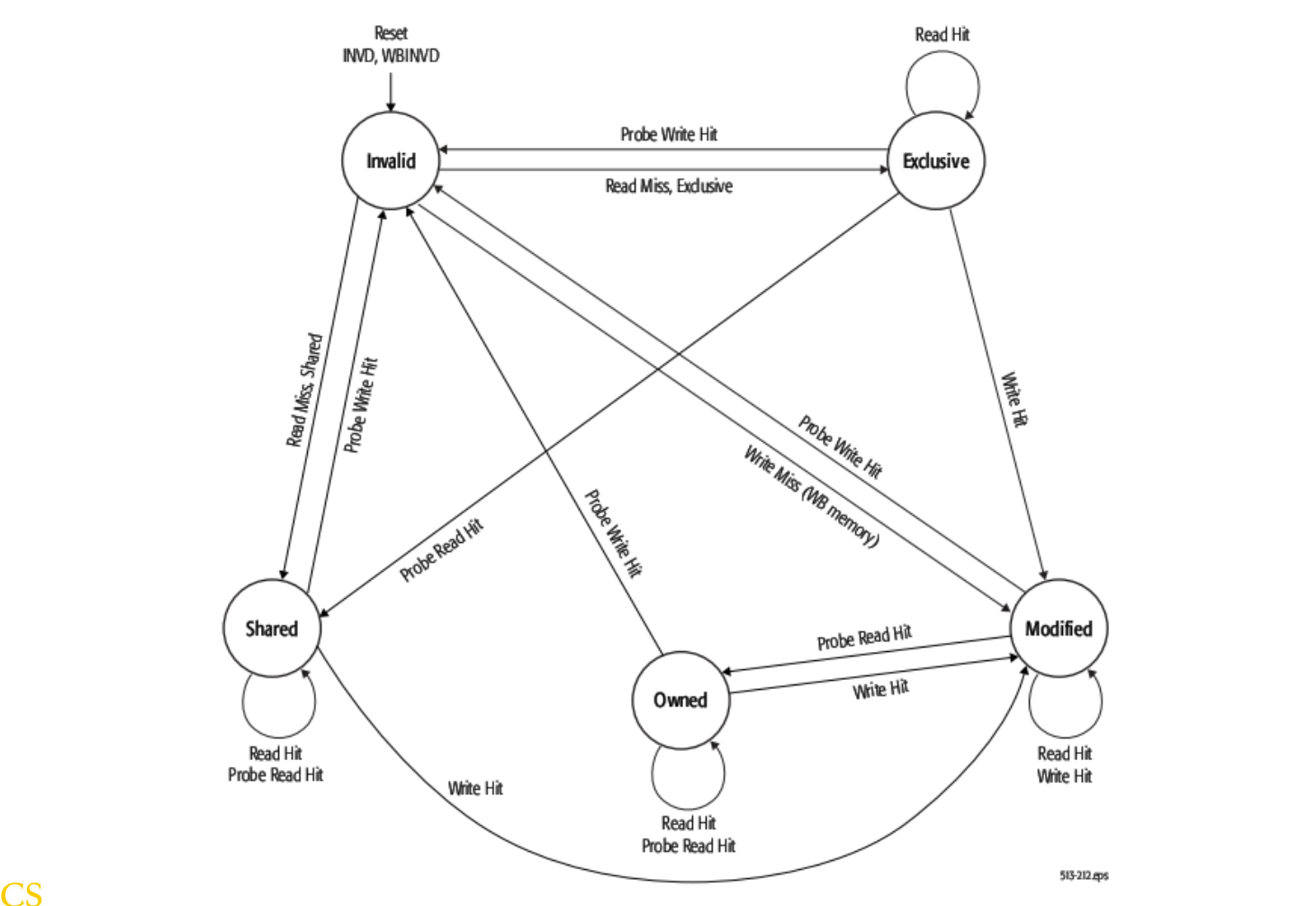
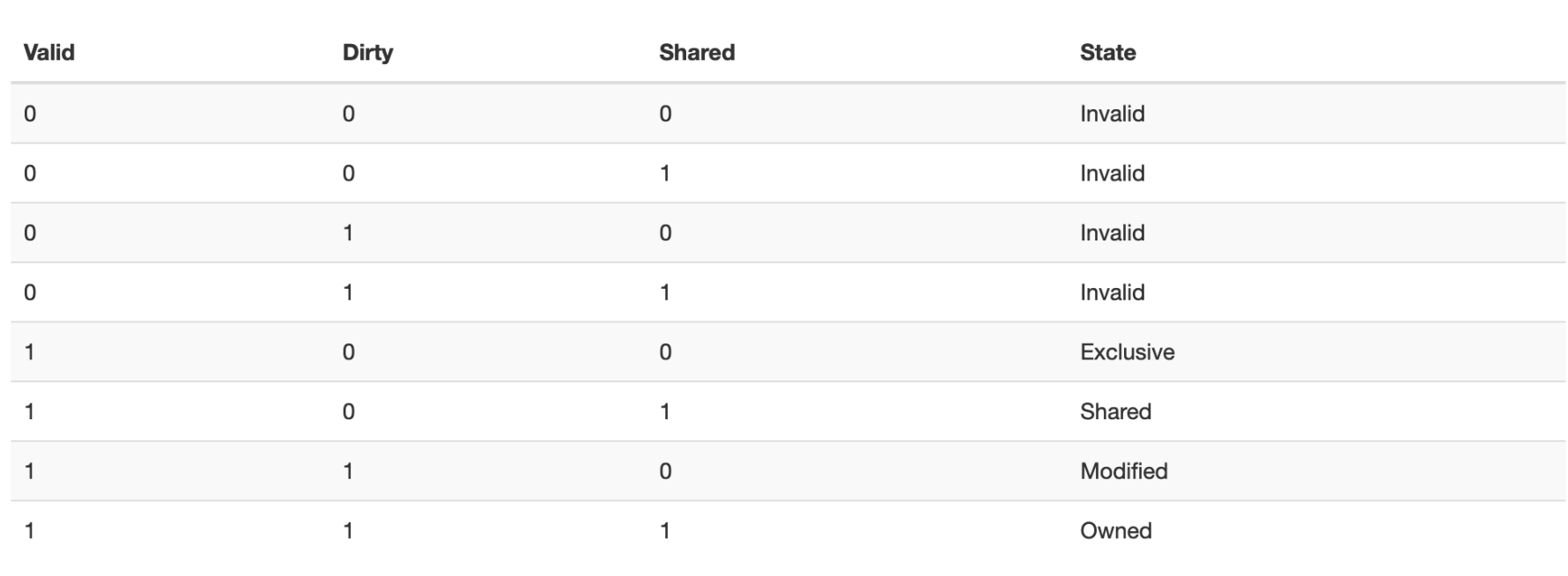
需要注意的是,进入owner状态的途径除了自身循环外,只有modified这一种状态。当cache处于owner状态时,它与其余的(也包含该数据的)cache组成了dirty sharing of data:
This cache is one of several with a valid copy of the cache line, but has the exclusive right to make changes to it. It must broadcast those changes to all other caches sharing the line. The introduction of owned state allows dirty sharing of data, i.e., a modified cache block can be moved around various caches without updating main memory. The cache line may be changed to the Modified state after invalidating all shared copies, or changed to the Shared state by writing the modifications back to main memory. Owned cache lines must respond to a snoop request with data.
MOESI模型帮助我们实现了lr与sc指令的工作机制:对于lr来讲,我们只需要做一次与往常一样的load操作即可,之后cache处于E/S/M/O状态中。
而在sc之前(这时要写入操作),由于使用了write-back的写机制,我们必须保证对应的内存位置当前被保存在cache中。那如果cache的状态为E/M,我们只需要向cache中写入提供的新数据即可;如果cache此时位于S/O的状态下,那么我们需要将写入操作做broadcast.
自然地,当处于S/O状态下,我们需要做设计避免出现两个cache在同一个cycle内写入数据的情况,这也是为什么要保证多核处理器的正确工作并非易事。
Sharing & False Sharing

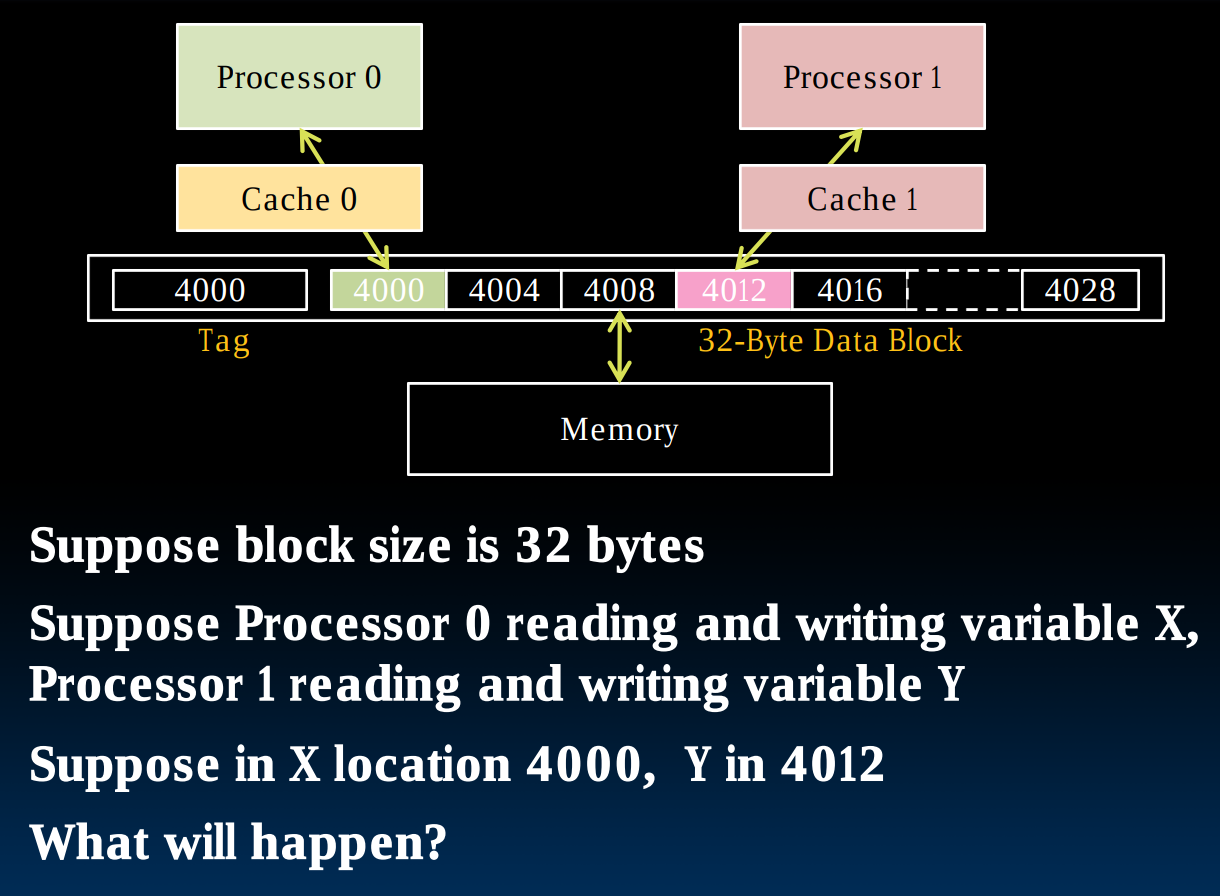
上图所示的情况,就是伪共享(False Sharing).此时的cache会处于我们先前提到的Block ping-pongs状态中,出现Coherence Miss/Communication Miss。为了避免这种情形的出现,我们应当尽量避免几个不同的cache向同一个cache line中写入数据。在并行程序中,除非我们要使用线程共享变量,否则最好将不同的线程写入的位置控制不同的cache line中。
MapReduce & Spark
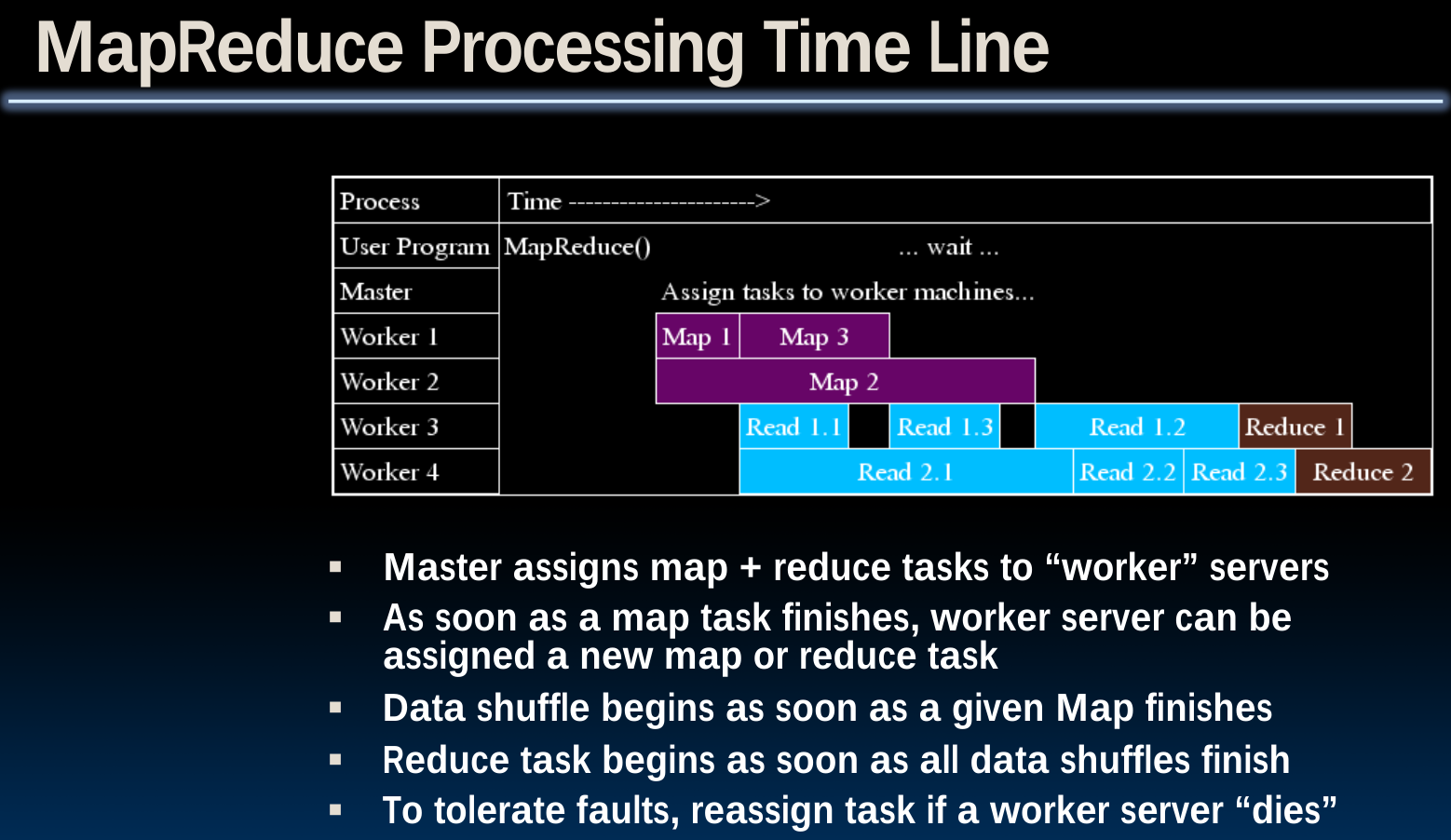
Warehouse Scale Computers

Power Usage Efficiency

显然,PUE的值会大于1,但是超过1的部分越小,说明电能使用效率越高。
Dependability

这里我们主要解决Runtime Failures.主要思路是利用redundancy带来的dependency解决问题。
在上图中,多个logic block就是使用Redundancy的实例,简单来说,这种硬件结构提供了一种voting机制:
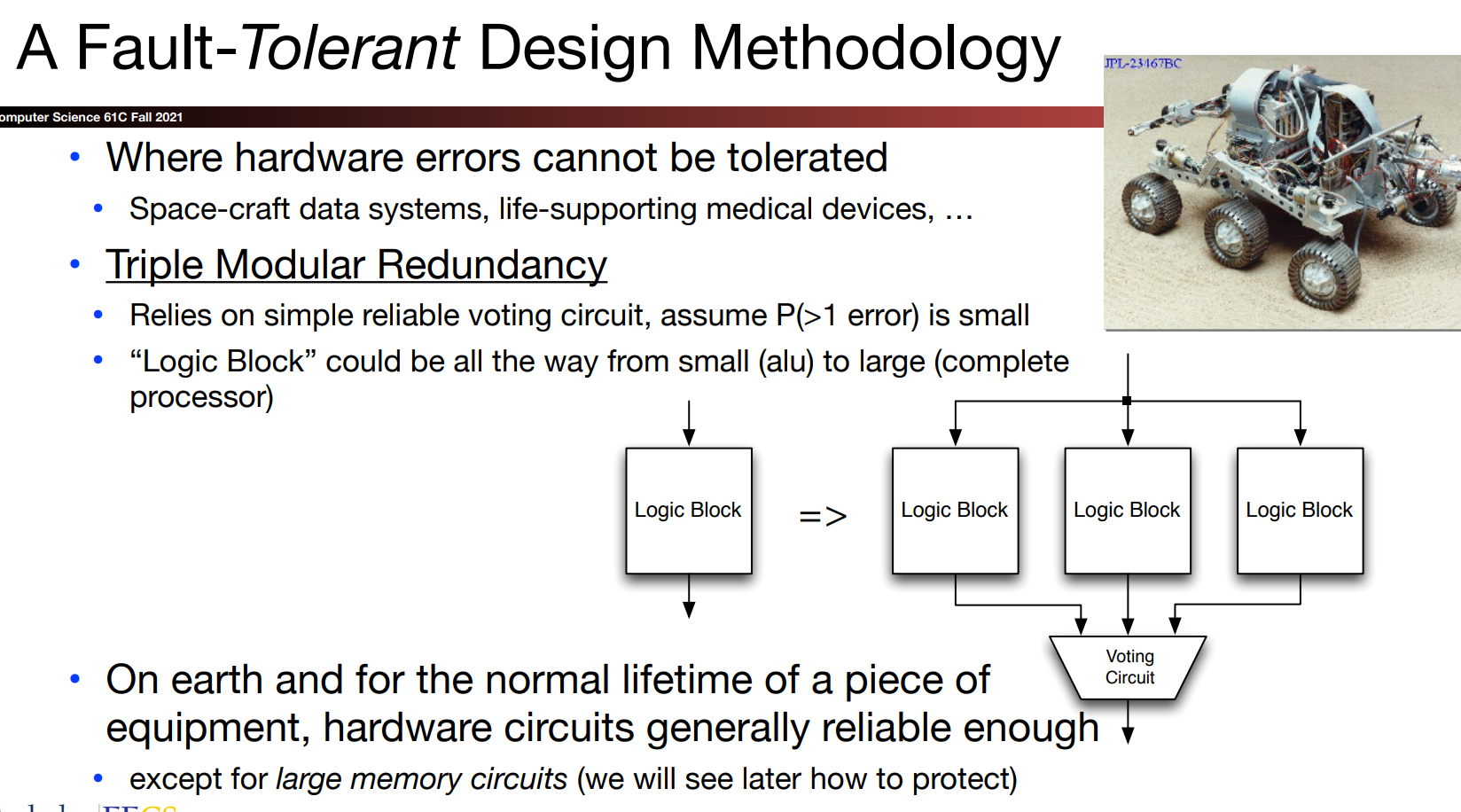
Time vs. Space

Dependability Measures

根据上图所示的计算公式,我们一般采取两种方式来衡量可靠性:
number of 9s of availability per year

Annualized Failure Rate (AFR, average number of failures per year)
我们将大致的Failure Rate随时间的变化绘制成曲线:
Error Detection/Correction Codes (EDC/ECC)
由于我们在计算机中所使用的主存为DRAM,这种存储方式会在每一个bit对应的位置上依靠少量电荷来存储bit.如此一来,就会产生两种error:
- “Soft” errors occur occasionally when cells are struck by alpha particles or other environmental upsets
- “Hard” errors can occur when chips permanently fail
Problem gets worse as memories get denser and larger.
Parity Bit
而如今的内存正是使用EDC/ECC的策略来应对上述问题。基本的思路是除了我们用于存储数据的data bits之外,增加一些用于判定是否出错以及具体出错位置的bits:即所谓的Parity Bit(s):

上图所示的方法是一种很基础的Error Detection方法,即奇偶校验位。我们通过增加一个0/1的奇偶校验位的方法来确保从前到后的1的次数是偶数个。如果在检测阶段,我们发现1额次数变成了奇数个,那么就说明出现了错误。
而硬件上实现此操作的方法也很简单,我们需要两个XOR,第一个异或门用于确定Parity Bit是0还是1;第二个异或门用于检查有没有发生错误:

需要注意的是,在这种简单的奇偶校验位的错误检测方法里,我们只能够探测到odd numbers of errors are detected的情况,如果翻转的bit为偶数个,那么无法检测到。另一方面,即使我们检测出发生了错误,那么我们也无法更改错误内容(无法定位)。
所以我们有没有更高级的EDC/ECC方法呢?这里引入Hamming Code.
Hamming Code
Motivation

基本的思路是从$$2^N$$个模式中选出$$2^M$$个作为valid code words,除此之外,所有的中间状态均为invalid code words。那么如果在检查时我们发现面对的是一个invalid code word,那么可以根据一定的准则来找到原本的正确的数据,这也就是我们所说的ECC。

我们可以用如下的形式表述Hamming Distance以及ECC的过程:
上图表明,为了能够探测出1-bit error,我们必须仅使用000与111这两个Hamming Distance为3(Minimum Hamming Distance is 3)的数字作为valid code word。能够探测到的bit errors共计两位。(从一个valid code word走到下一个valid code word总共需要3次)
- 2-bit Error Detection
- 1-bit Error Correction
这种情况也代表着Hamming code的Minimum Hamming Distance为3,因为数据位最小只有一个,在Hamming code中我们需要两个Parity Bit来检测错误,恰好为上图所示情况。
需要注意的是,虽然我们可以检测出仅仅发生1-bit error的数字所对应的正确值是多少,但是如果允许出现2-bit error,我们仅能够探测到,但是并不能够确定它对应的正确值是哪一个。
Rules


我们将Parity Bits排列在1,2,4,8,16...的位置,穿插在原本的Data Bits中。这些Parity Bits将整个的数据分成了不同的组,我们要保证没一个组内满足even parity;分组规则上图所示,需要注意的是,Hamming code中的数字标识是自左向右的。和先前一样,在硬件结构上,我们只需要在这不同的组别中使用异或门即可。
一个栗子:
- 计算
Parity Bits:

- 检查错误(
check):

接下来的问题是,在计算出如上图所示的检查结果后,我们如何确定需要更改的(发生错误的)位置。
根据线性代数:

当然,我们也可以从另一个角度尝试解释这个运算方法,我们可以将上图倒转过来便会发现,从Parity bit 8 Group到Parity bit 1 Group,组成的1010的数组序列恰好对应了横轴上Bit Position为10的位置:

Hamming ECC Cost

我们正是通过$$2^r\ge m+r+1$$来计算冗余位数。
Bonus Slides
目前介绍的Hamming code是:
- Single Error Detection
- Single Error Correction
如前所述,在立方体的例子中提到的
2-bit Error Detection并不等同于Double Error Detection。原因我们先前也描述过,当允许同时出现两个位置的错误时,我们无法得知其对应的正确值是哪一个。
我们可以通过如下方法来进行Double Error Detection:

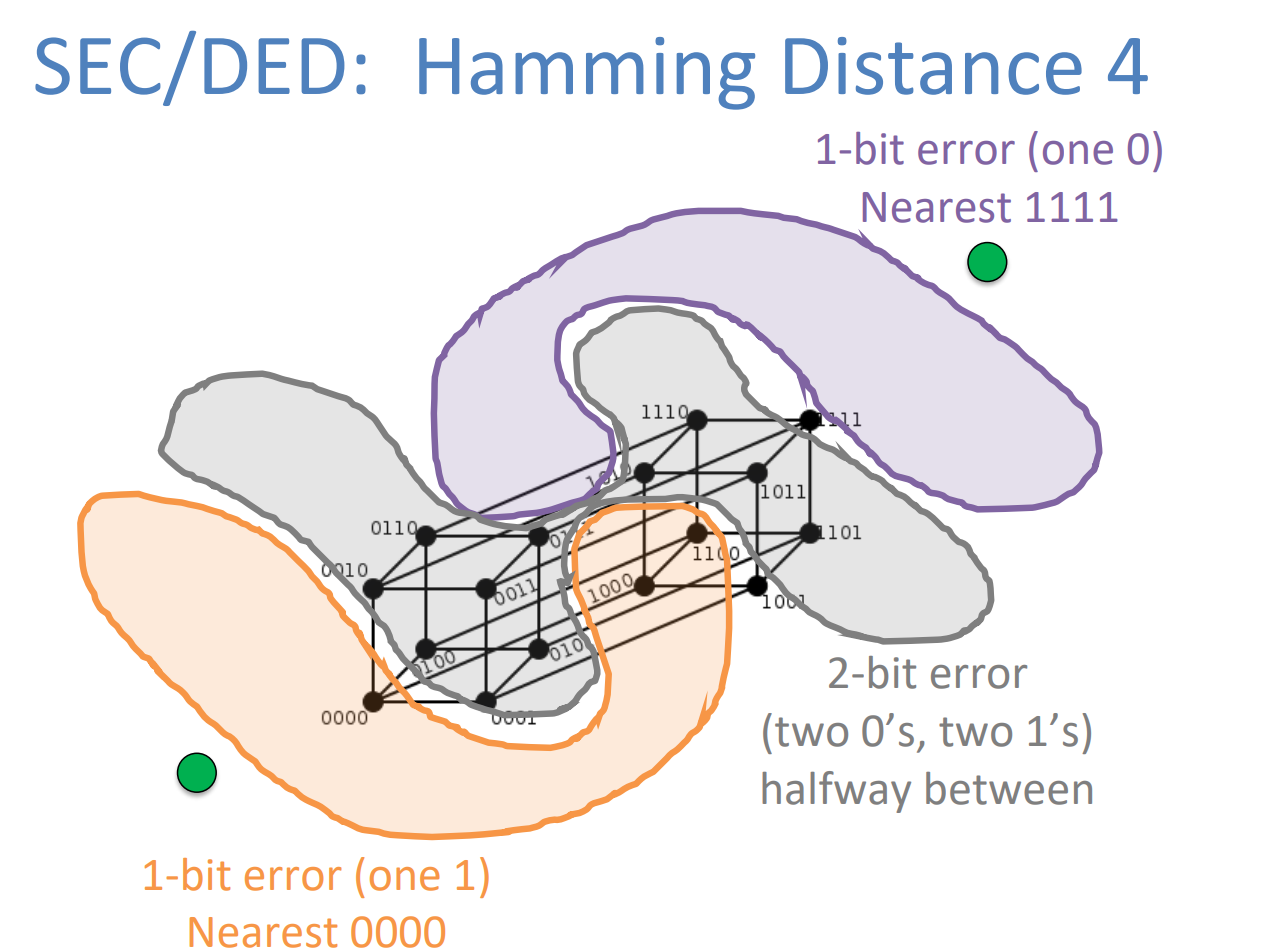
在现代的DRAM设计中,我们正是采用了这种DED的错误探测机制:对于64-bit的Data Block来说,根据公式$$2^r\ge m+r+1$$我们需要7个Parity Bit来处理Hamming code;那么对于DED,就要使用8个Parity Bit。所以code word共计72-bit。
other codes

RAID
EDC/ECC可以帮助我们解决内存中的错误,即通过一些Redundancy Bits建立一套规则来提升Dependability。
同样地,在disk中我们也可以通过Redundancy来形成High Data Availability:
Service still provided to user, even if some components (disks) fail.
RAID全名为Redundant Array of Independent Disks,简称磁盘阵列,常见的方案有:RAID0、RAID1、RAID5、RAID6、RAID10等。
RAID的基本思路是将同一份文件stripe到不同个磁盘中,这样即使某一个磁盘发生了数据损坏,我么也可以根据其他磁盘中的内容保证文件不发生丢失。
RAID0
这种存储方式其实并不算做真正具备Redundancy,它只是将数据分散到了不同的磁盘中:
不过由于我们可以并行处理多个磁盘内容,这种数据分布方式要比将文件全部存储在同一个磁盘中更快。
RAID1
这种方式又被称为Disk Mirroring:
RAID 2-4
这三种方式主要基于Data Striping + Parity的模式,分别使用了不同的数据大小stripe在磁盘中:
- 2:bit
- 3:byte
- 4:sector(block)
RAID2使用多个check disks,这种设计完全基于ECC/EDC的思路,通过check disks确定错误位置。而在RAID3中,考虑到当前的磁盘本身就带有错误检测机制,所以在已知出错磁盘的前提下,我们可以仅使用一个Parity Disk,如果某个磁盘出错,将其余Data disks和Parity Disk进行异或即可得到正确数据:
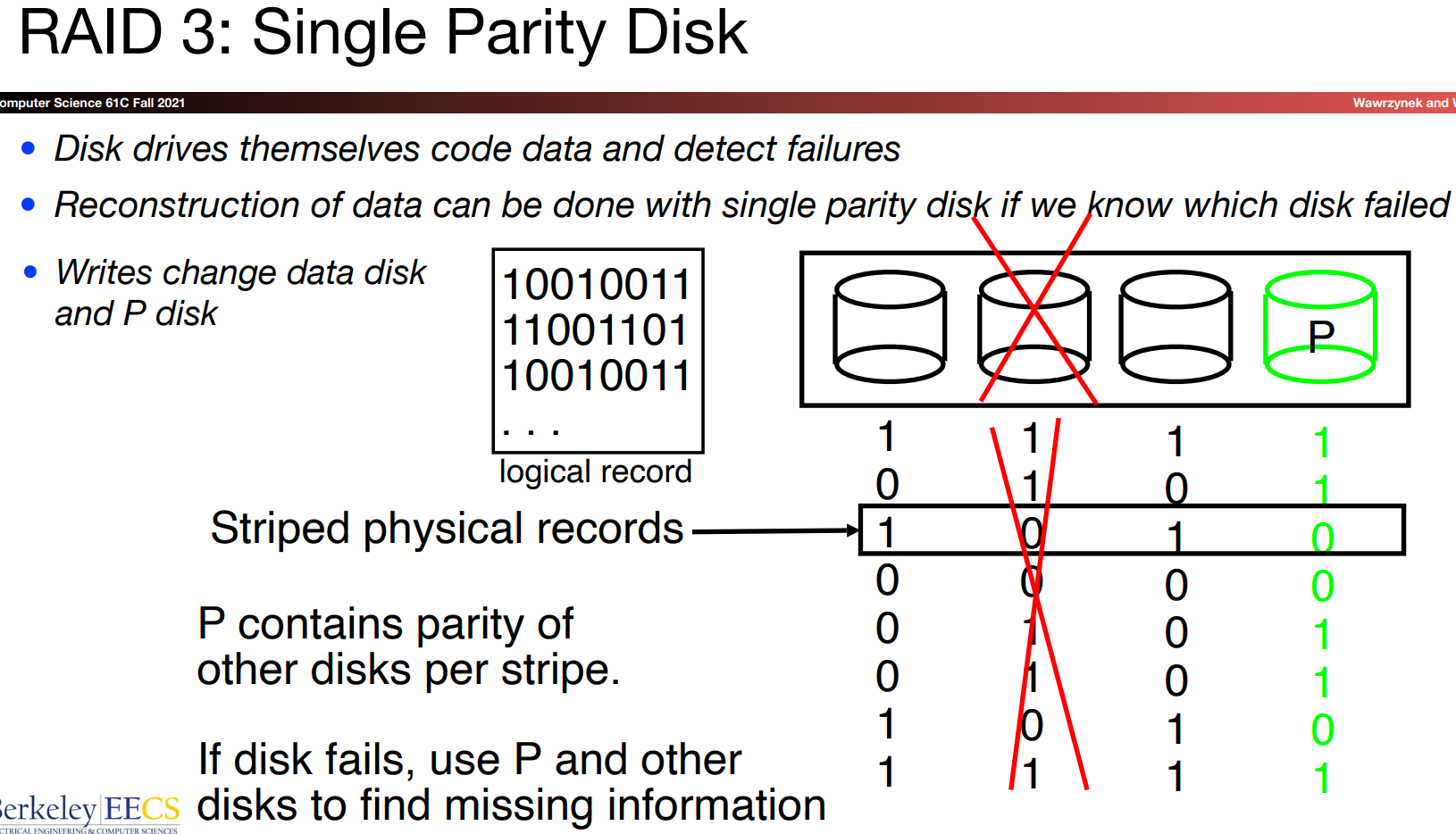
于是在RAID4中我们更进一步,将sector/block作为一个disk的存储单位,这允许我们进行更快速的数据并行和存取操作:
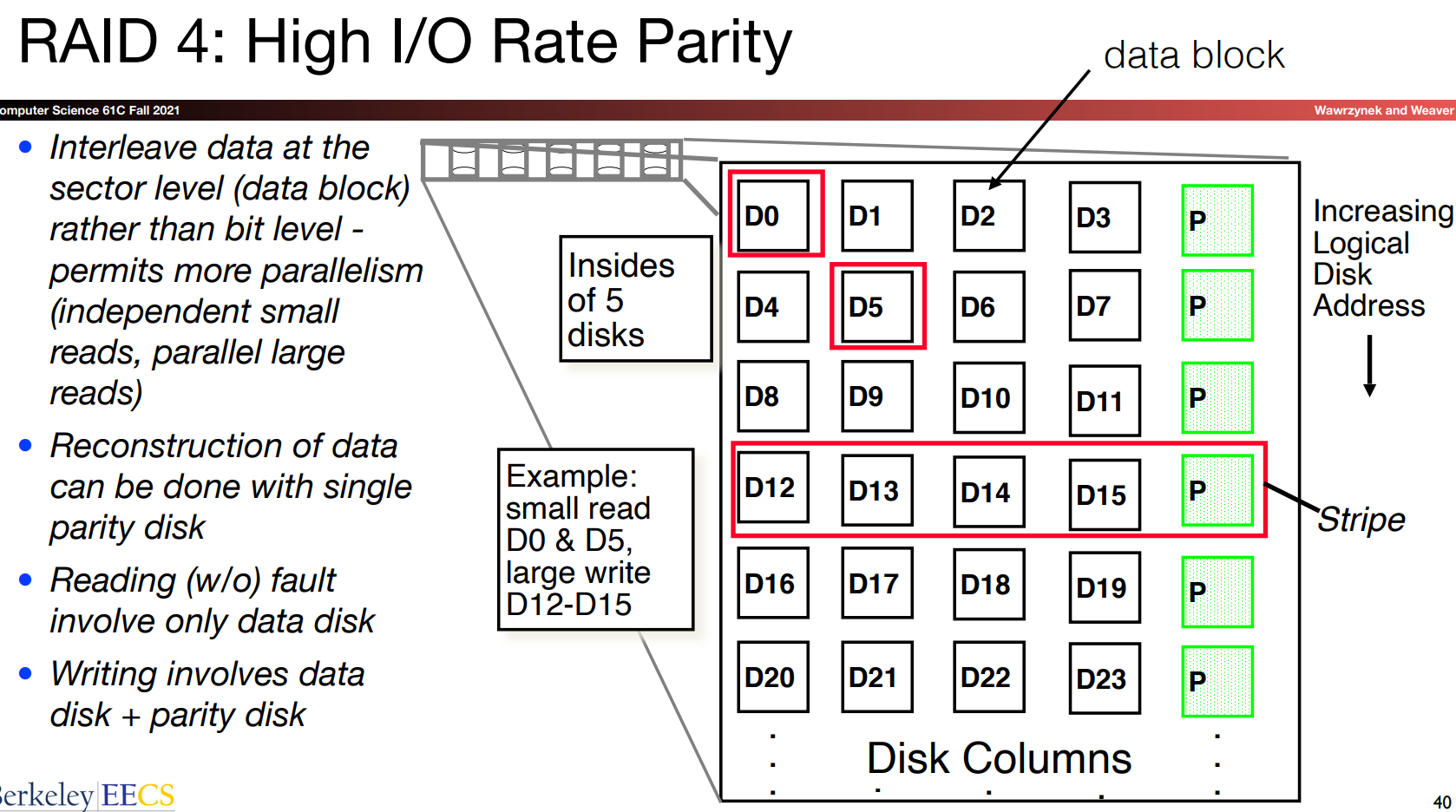
如果尝试向磁盘阵列中写入数据,则需要更新data disk以及parity disk:
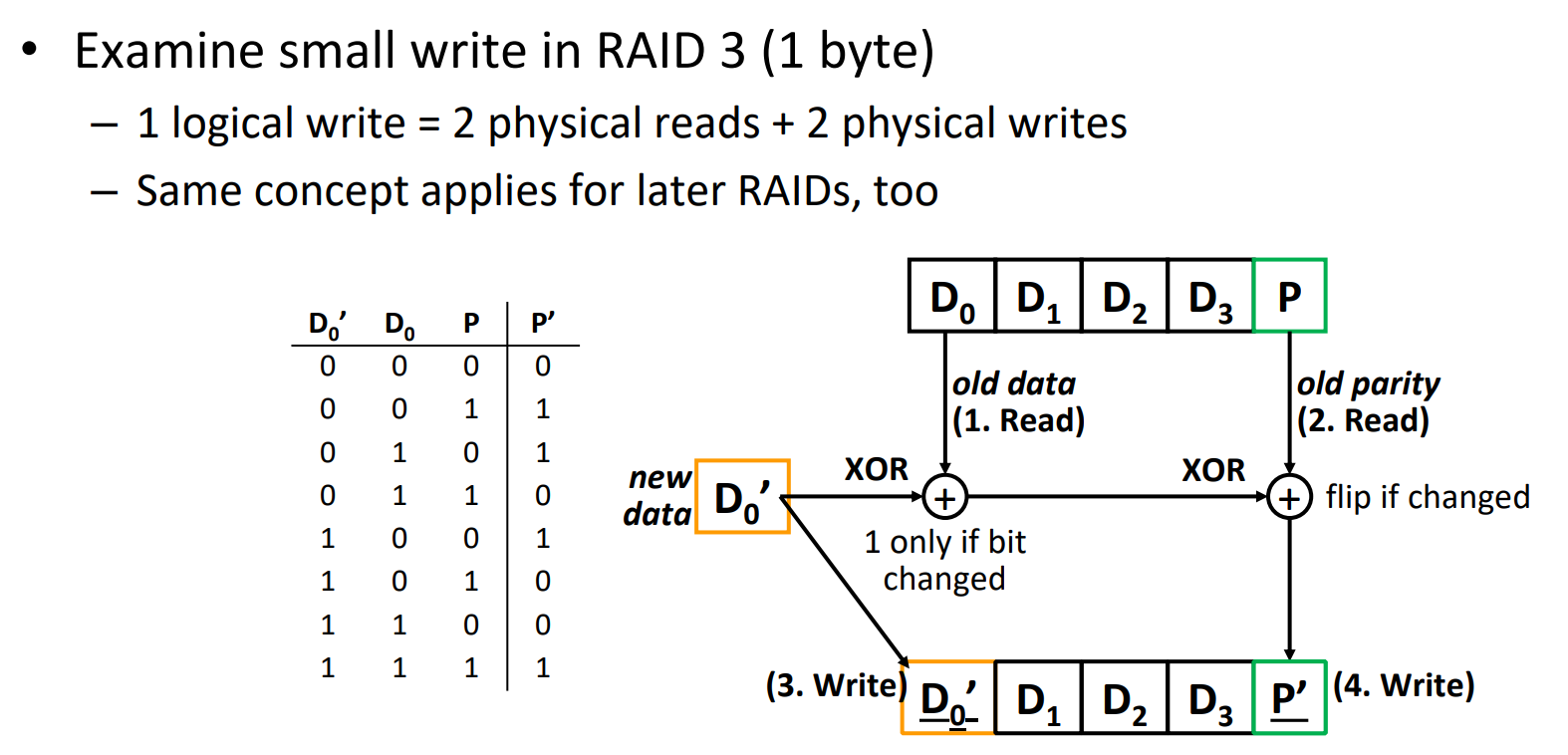
RAID5
所以我们的RAID4存在什么问题?
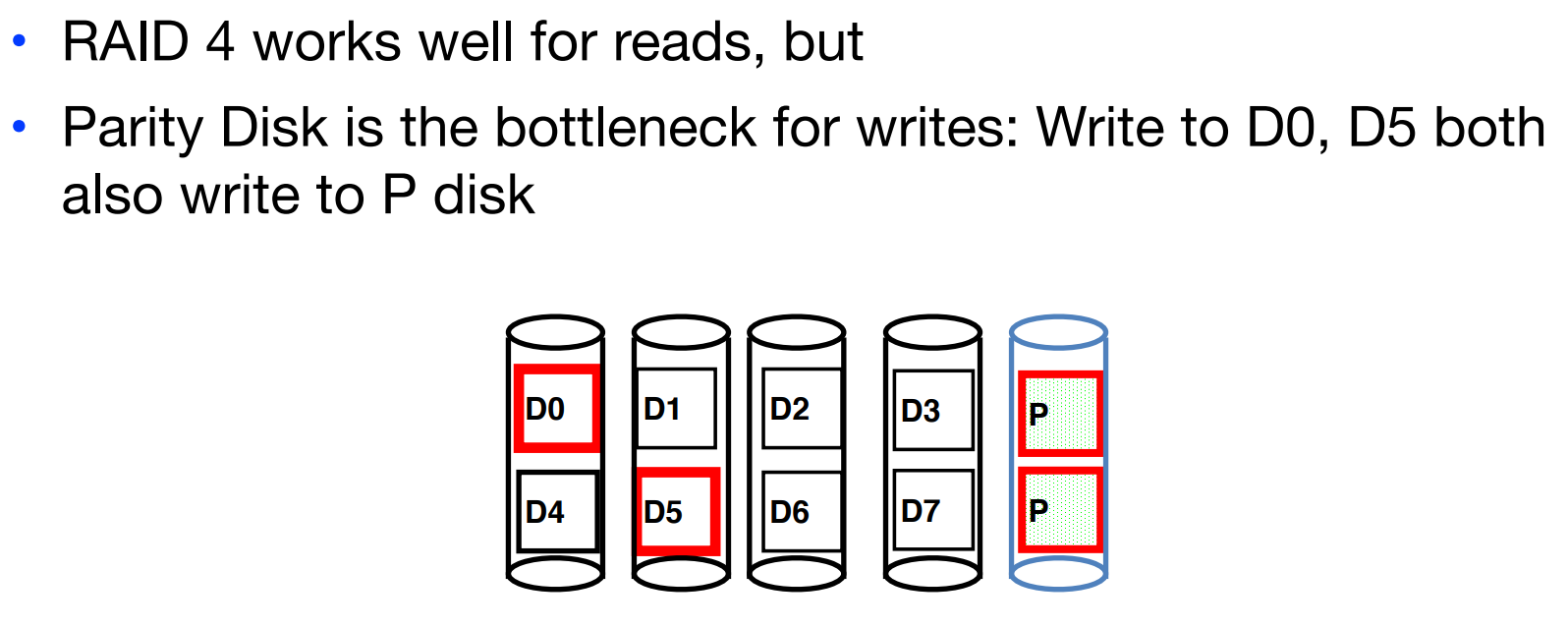
为了能最大程度利用数据并行处理的优势,并且避免同一块磁盘因为过于频繁的数据读写出现损坏,我们最好不要把对于Parity Bit的读写集中在一个磁盘中。正是基于这种想法,RAID5使用了Interleaved Parity的办法,减少更新同一个Parity Disk的可能性:
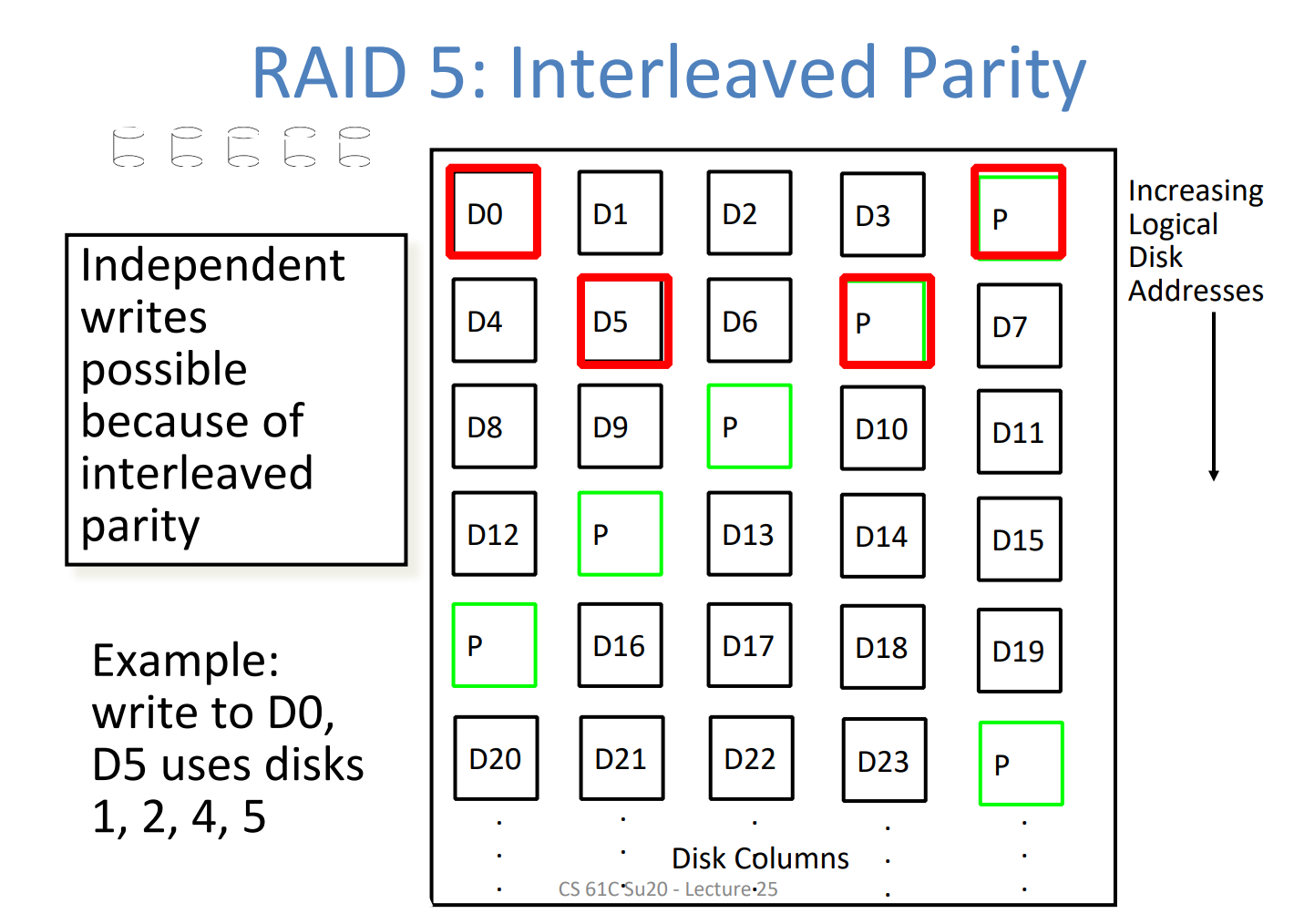
Newer RAID
