本文写在61C的并行计算部分后。
Lecture 2: A Modern Multi-Core Processor
这节课的内容可以大致分成两部分。首先讲述了如何提高峰值并行效率,其次讲解了如何缓解/减少由于内存访问带来的并行效率下降的问题。
Coherent execution
SIMD指令与multi-core不同,SIMD指令运行的指令一定都是一样的(只是输入不一样),但多核可以并行运行完全不同的指令,所以在SIMD遇到分支时就会产生一些问题。
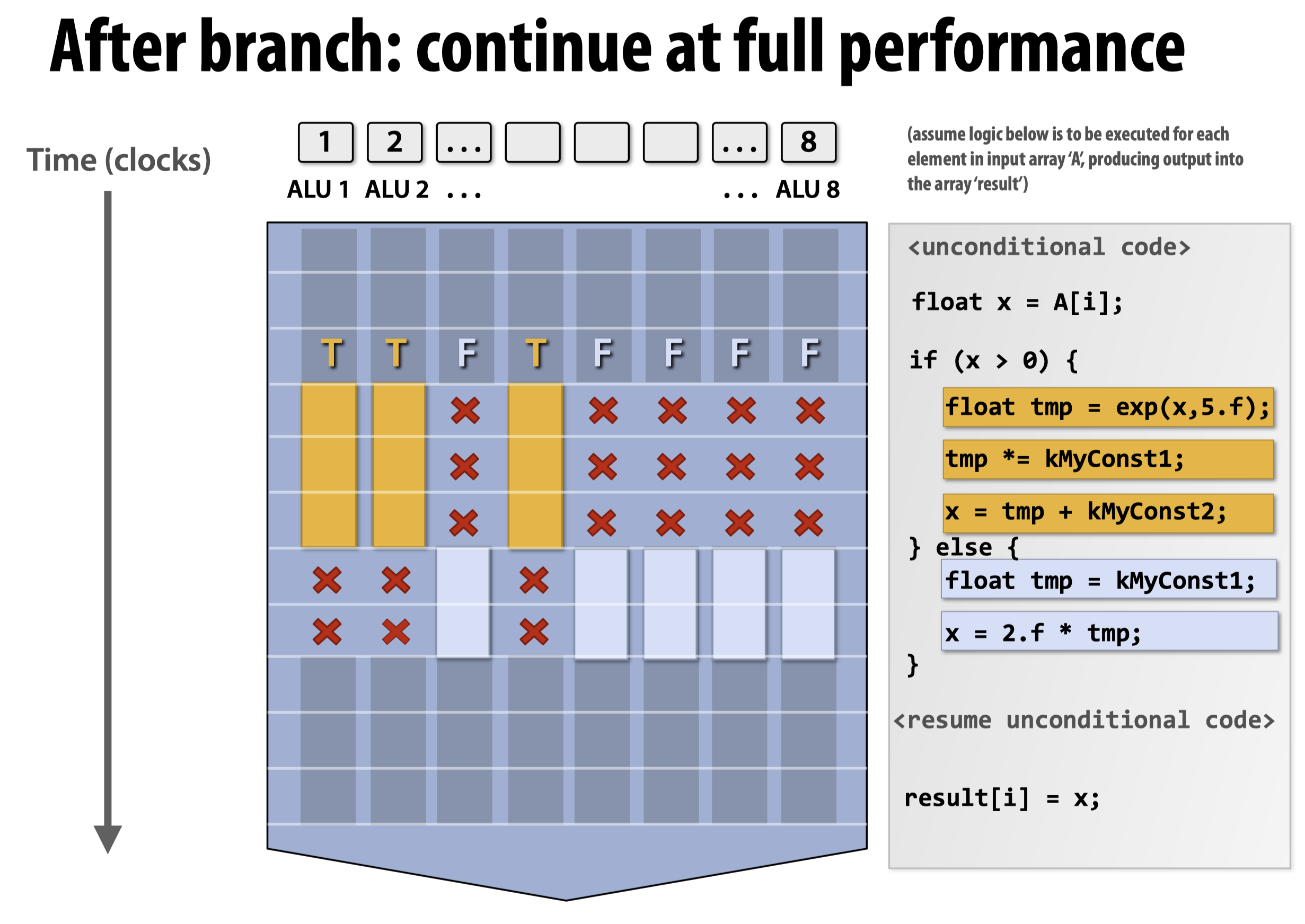
如果循环体内部含有分支语句,意味着对于不同的输入,并不能够在一开始就确定走if还是else,所以SIMD指令不能直接利用。此时我们可以将指令重排列,从而将走if的语句安排在一起,走else的语句安排在一起。而如果不想重排指令,我们就要使用如上图所示的方法,即分别对if和else做一次SIMD运算,然后根据输入设定mask,来决定到底将哪些对应的计算结果输出。我们能够预想到的最坏情况发生在两个分支的代码复杂度相差较大时,并且此时绝大多数数据都走向了复杂度较小的分支。那么因为对于两个分支都要进行一遍SIMD运算,就会导致我们在无用的运算结果上花费了大量时间。换句话说,SIMD的高效运算取决于避免上述情况的发生,我们将这种先决条件称为Coherent execution。

summary of parallel execution
我们有三种并行运算的思路:
- Multi-core (thread-level)
- SIMD (instruction level)
- Superscalar
其中
Superscalar着重在一个内核中对一个instruction stream执行多个独立指令的并行运算

需要注意的是,SIMD指令是比“多线程”更加底层的技法,他的指令执行由计算单元完成,只需要一个线程就可以执行,并非需要多个线程来并行SIMD的向量化计算过程。
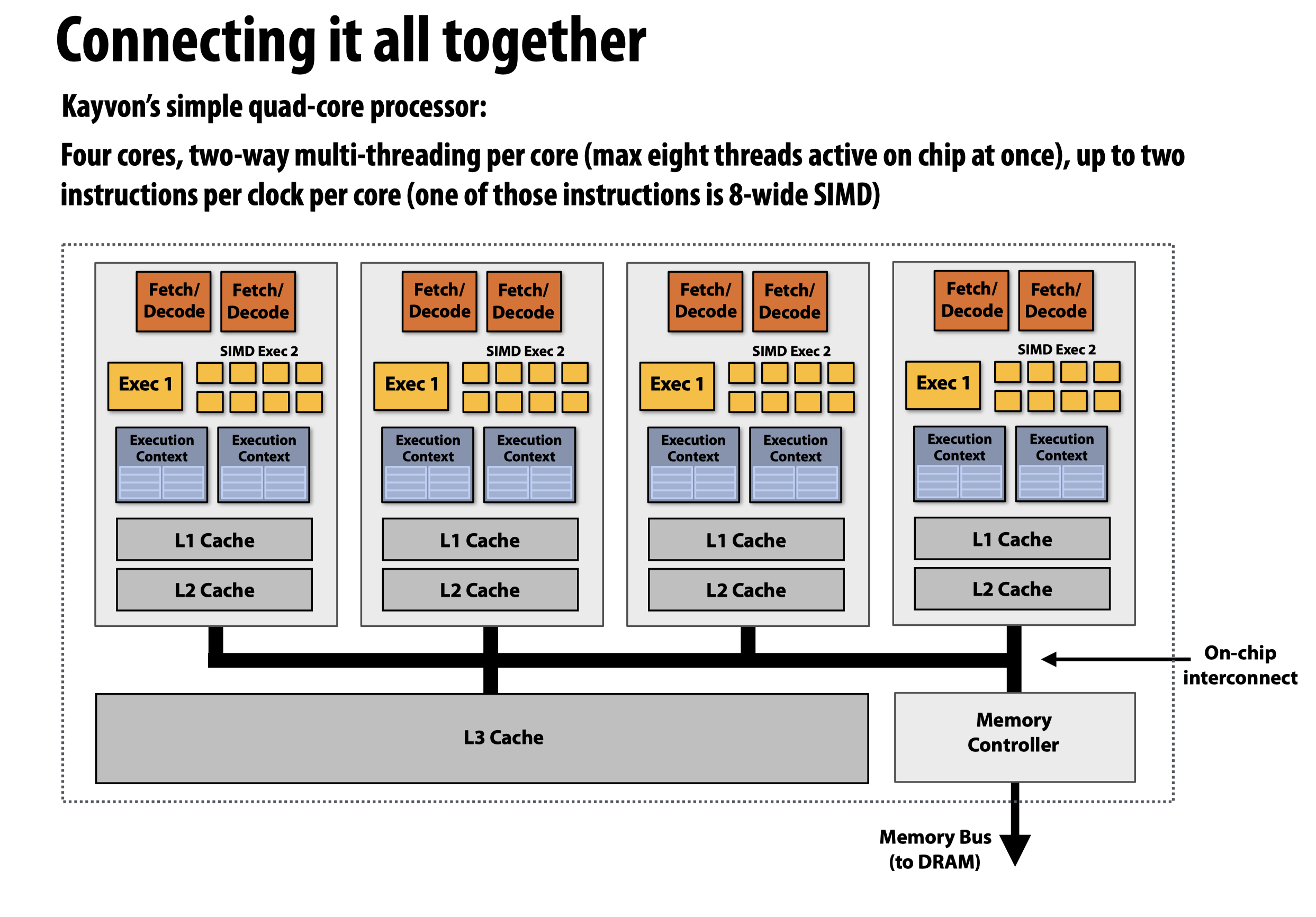
注:在这幅图中,核内的两个硬件线程允许一个核从两个
instruction stream中抓取并同时执行两条指令,其中一个是SIMD指令,被分配到SIMD Exec上
Lantency & Bandwith

越高的内存带宽不等价于更高的内存延迟:虽然一次性能够和内存交互更多的数据,但一次存取数据(load/store)需要花费的时间可能更长。
Latency
有两种手段处理延迟:
- reduce latency
- hide latency
降低延迟的方法包括使用多级缓存,隐藏延迟的方法包括:
- prefetching
- multi-threading (interleave processing of multiple threads on the same core to hide stalls)
Multithreading
如何理解硬件多线程
硬件多线程,顾名思义,是需要硬件支持的多线程(当然也需要OS的配合来实现),在程序中使用的“多线程”是软件多线程,我们可以把硬件多线程理解为软件多线程的实体(但这不意味着两者具有一对一的映射关系)。硬件级别多线程设计的存在能够让系统的线程执行效率更高:处理器会为线程执行准备几个execution context区块,并由处理器决定当前执行哪个(硬件)线程,而非操作系统。
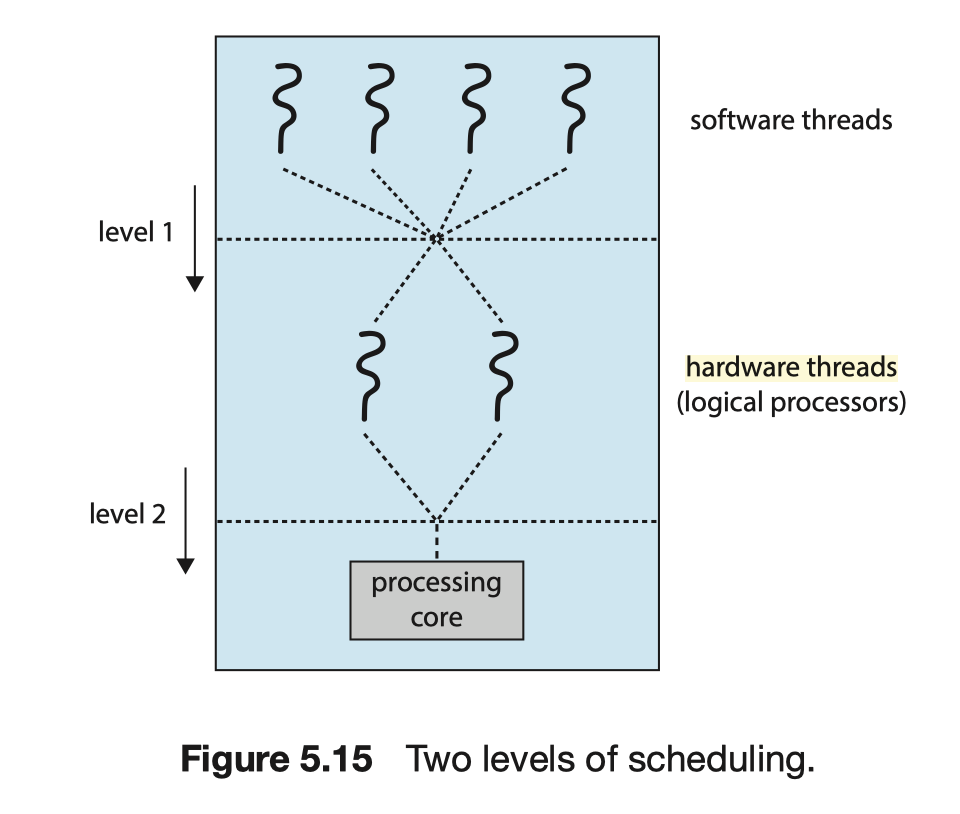
如上图所示,当我们在程序中生成了两个线程后,操作系统会负责将pthread(software threads)映射到处理器的thread execution contexts(hardware threads)上,接下来就是处理器的事了。
多线程的trade-off
当使用多线程时,存在几个trade-off:
首先是当interleave多个线程时,单个线程的执行时间变长了,但是系统整体的吞吐量提高了:
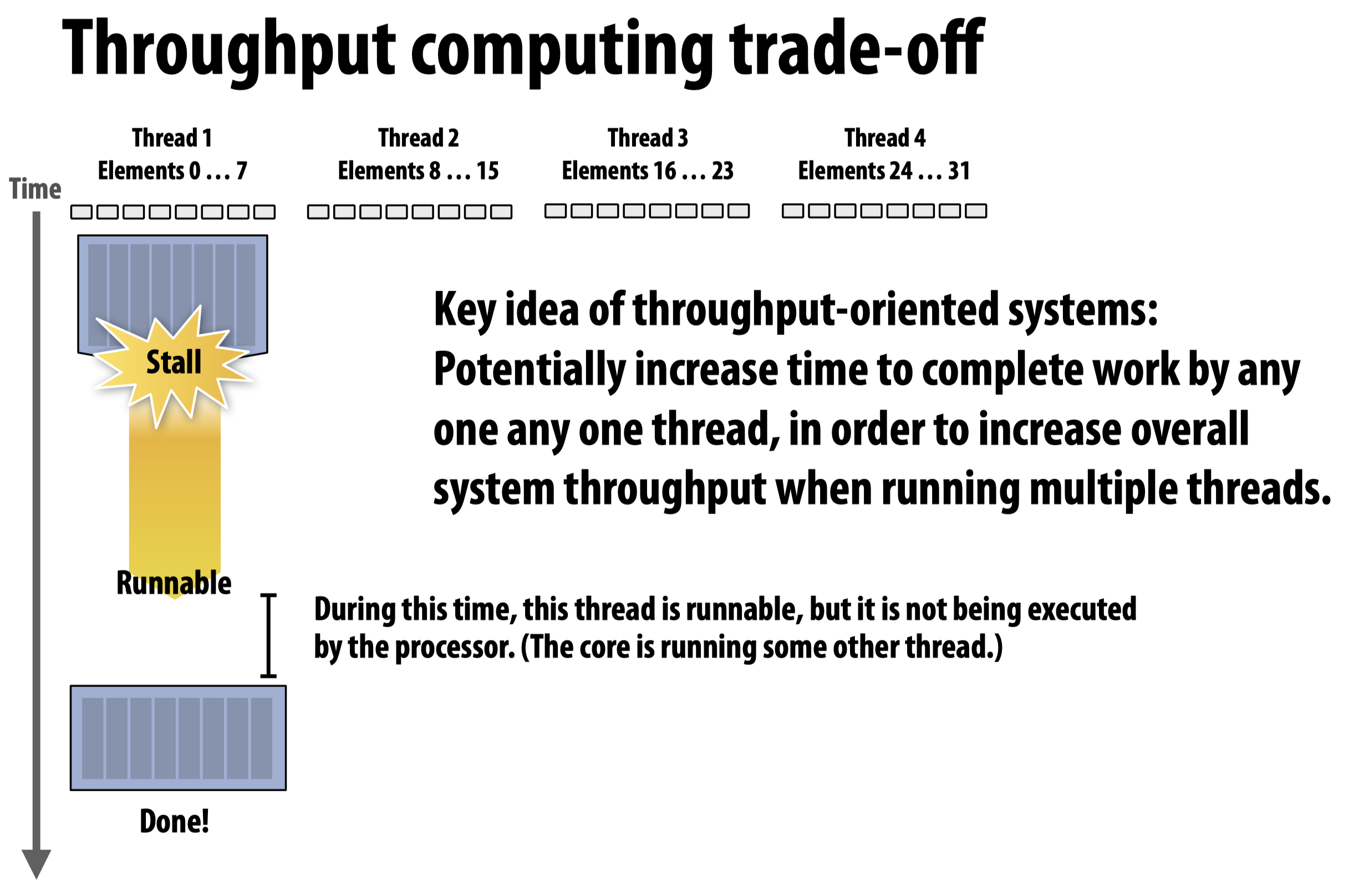
其次是当拥有较多数量的线程时,意味着系统有较强的hiding latency的能力;当可分配的线程数量较少时,单独的线程会拥有更大的work set,也就意味着cache中可以分配给每个线程的内存更多了。
多线程设计模式分类
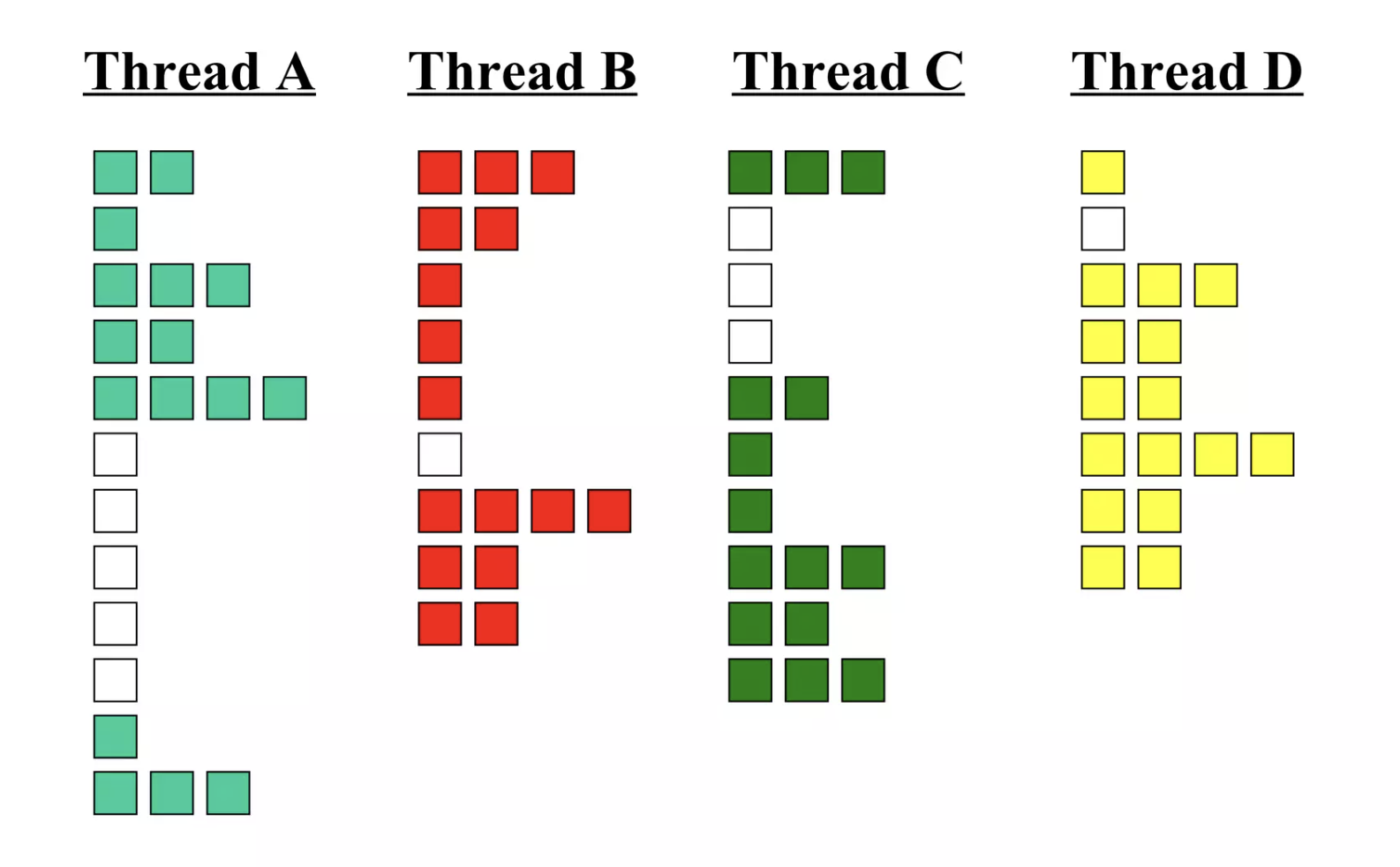
多线程的设计方法可以被分成两类:
- Interleaved Multi-threading (Temporal Multi-threading)
这种多线程模式意味着在每一个时钟周期内,每一个核只执行一个线程,这种设计模式还可以划分成两种子类:
- Coarse-grained Multi-threading
在这种模式下,每个线程会一直执行到发生costly stall的时候(比如2nd cache miss),对于shortly stall并不关心。(每个线程需要独立的PC, register file等硬件支持)
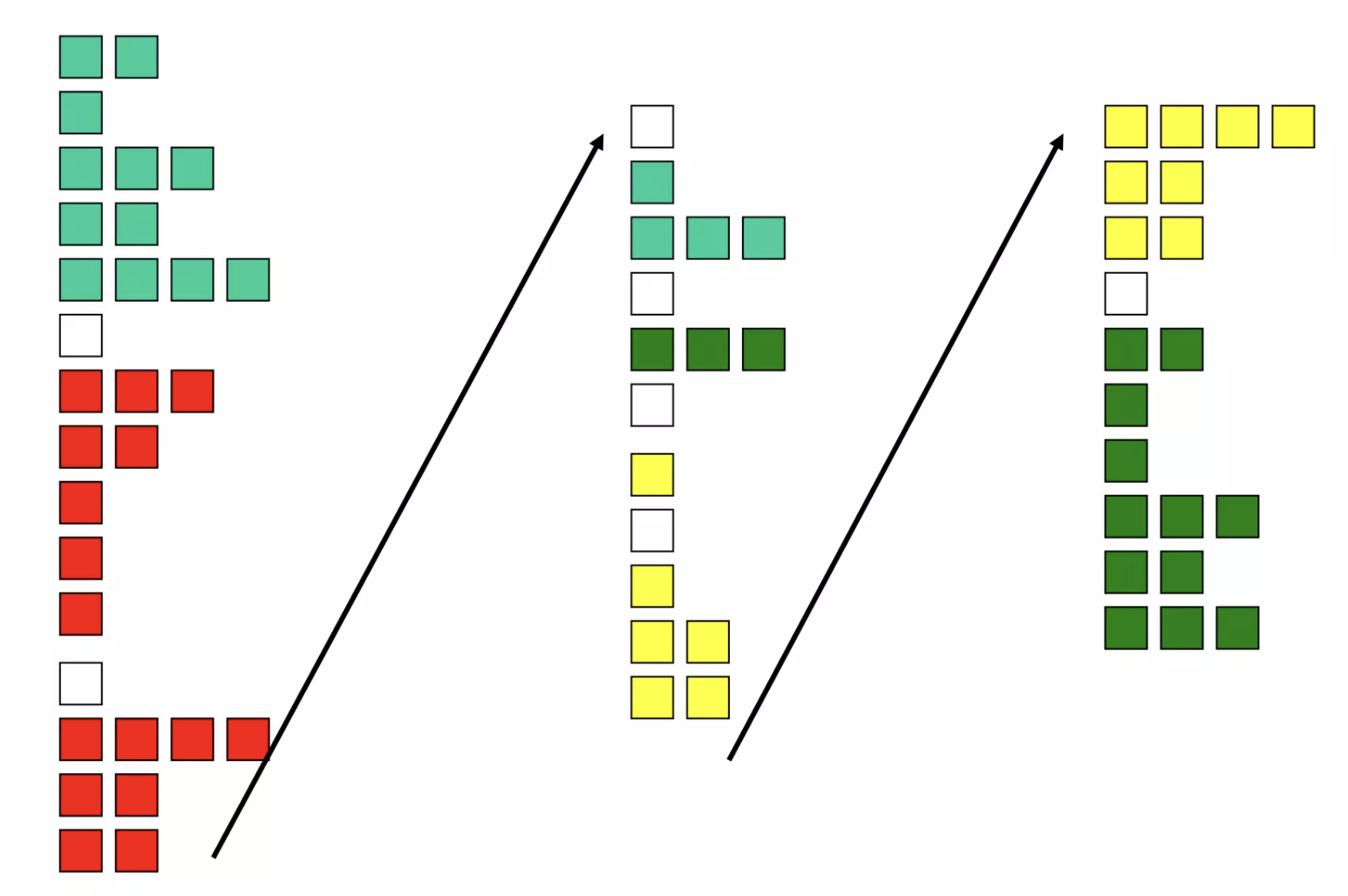
- Fine-grained Multi-threading
在这种模式下,多个线程使用robin-round等方法interleave各自的instruction,当遇到发生stall的线程则会直接跳过。在这种模式下,不会单单等到某一个线程发生costly stall时处理器才让另一个线程来接管他。(每个线程需要独立的PC, register file等硬件支持)
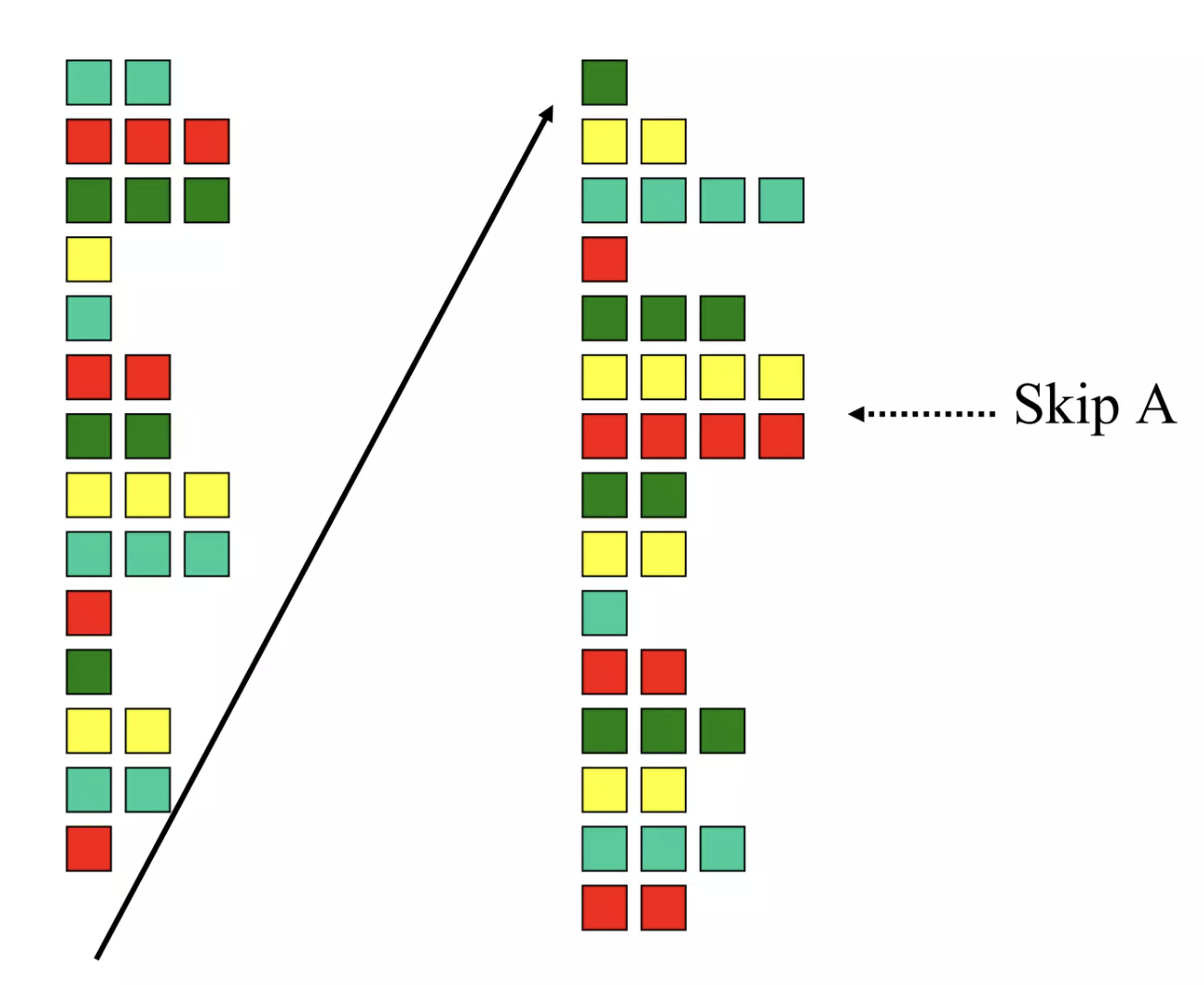
- Simultaneous Multi-threading (SMT)
Intel的Hyper-threading就是基于SMT的典型设计之一。在该模式下,一个物理核被分为多个逻辑核,这意味着在同一个时钟信号内,系统允许处理器同时执行多个线程。(每个线程需要独立的PC, register file等硬件支持)
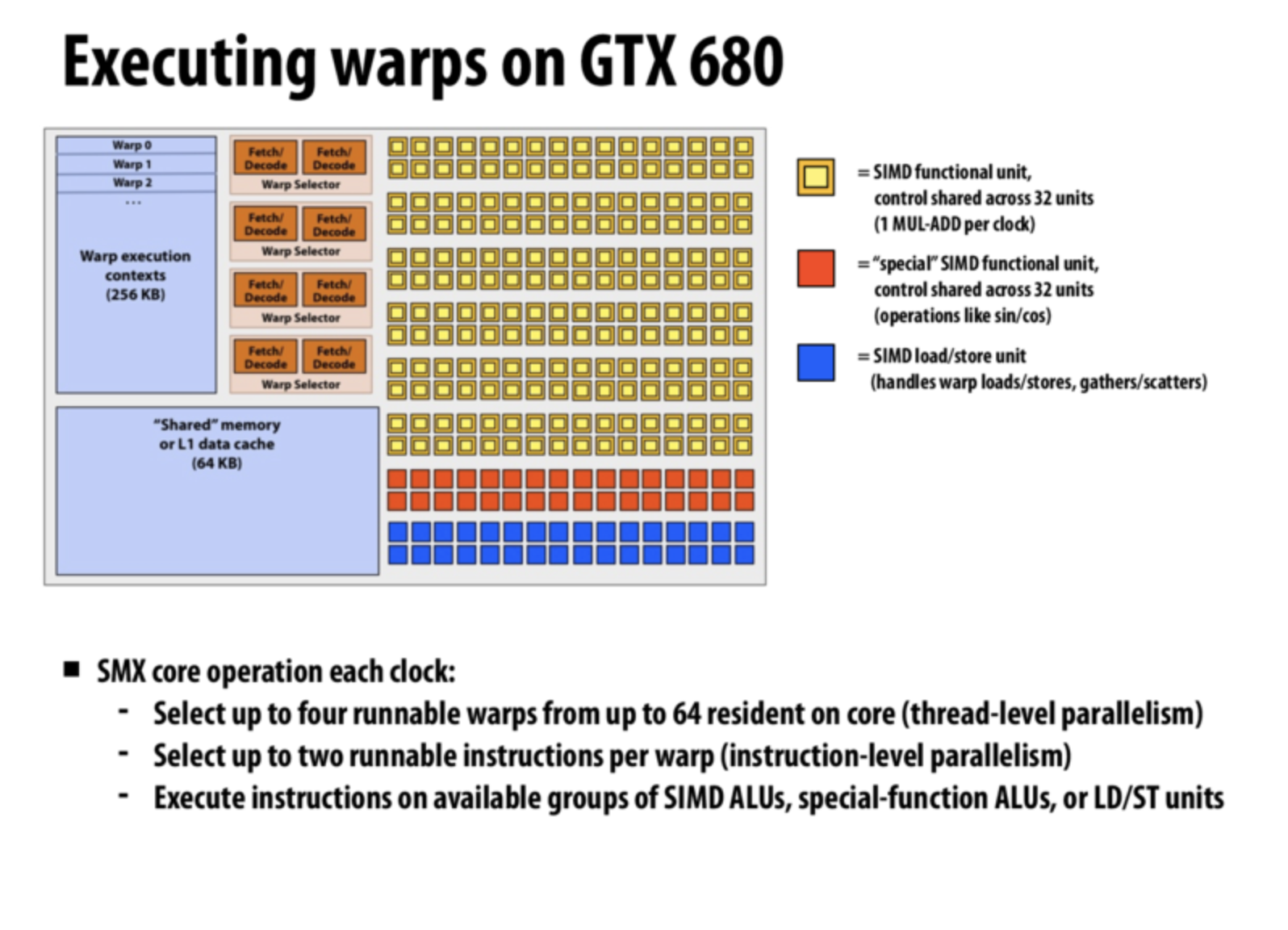
在SMT模式下的多线程因为要在同一时刻,在同一个内核中执行多个指令,所以可以理解为一种基于Superscalar设计的扩展。但SMT和Superscalar并不一样,Superscalar机制由于不具备独立的Execution Context,所以只能从一个instruction stream中选择独立指令,但是SMT允许处理器从多个instruction stream中选择独立指令(这也是Hyper-threading想法产生的原因,即想要从同一个指令流中选择多个独立的指令并不容易,所以Intel想要借助多个线程来从多个指令流中选择独立指令)。这也意味着SMT和Superscalar可以同时使用(虽然Intel的Superscalar机制实际上是用来帮助实现Hyper-threading了),以GTX 680为例(Warp在这里表示instruction stream):
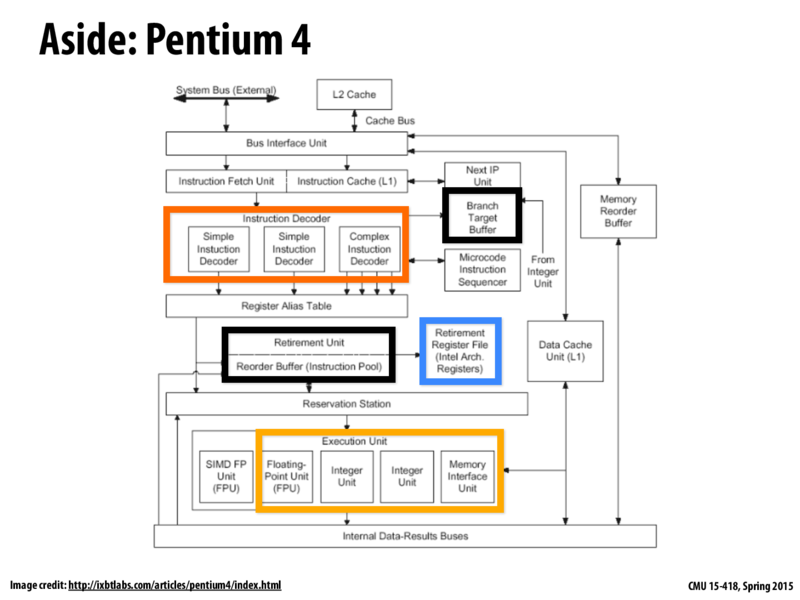
superscalar processor:
Intel’s Hyper-threading implementation makes sense if you consider the context: Intel had spent years building superscalar processors that could perform a number of different instructions per clock (within a single instruction stream). But as we discussed, it’s not always possible for one instruction stream to have the right mixture of independent instructions to utilize all the available units in the core (this is the case of insufficient ILP). Therefore, it’s a logical step to say, hey, to increase the CPU’s chance of finding the right mix, let’s modiy our processor to have two threads available to choose instructions from instead of one!
需要注意的是,SMT具备从多个instruction stream中选择独立指令的能力并不意味着它一定要这么做,处理器会找到能够利用核心内所有执行单元的最佳方案,这种方案可能会从同一个线程中选择多个指令(this thread has sufficient ILP)同时执行,这会让处理器表现的像interleaved multi-threading一样。
当然,超线程的使用未必就比单线程的执行效果更好,因为多个线程共享一个cache可能会导致更多的cache miss。不仅如此,在同一个physical core内,不管处理器提供了多少可能的硬件线程,他们的很多计算资源都是共享的(这也是为什么即使在多核时代还是会在同一个核内设计多个逻辑核的原因—-我们只需要对原有结构做不多的改动,就能够提高很大的性能指标,比如奔腾4增加HT技术只需要多花费5%的核心面积,就可以增加15-30%的多线程性能,而如果增加物理核心,增加多少性能,就至少要增加多少比例的核心数量)。而且还会有因为线程隔离不到位导致的线程安全问题…
所以,当操作系统想要将pthread映射到硬件线程上时,会尽量将两个线程(很大可能没有资源的交互,即完全独立)映射到两个不同的physical core内以确保最大可能的并发(否则每一个线程由于同一个内核内的计算资源共享,可能只能达到1/2的运行效率)。
CPU & GPU
- CPU

64=16*4
512=64*8
- CPU vs. GPU
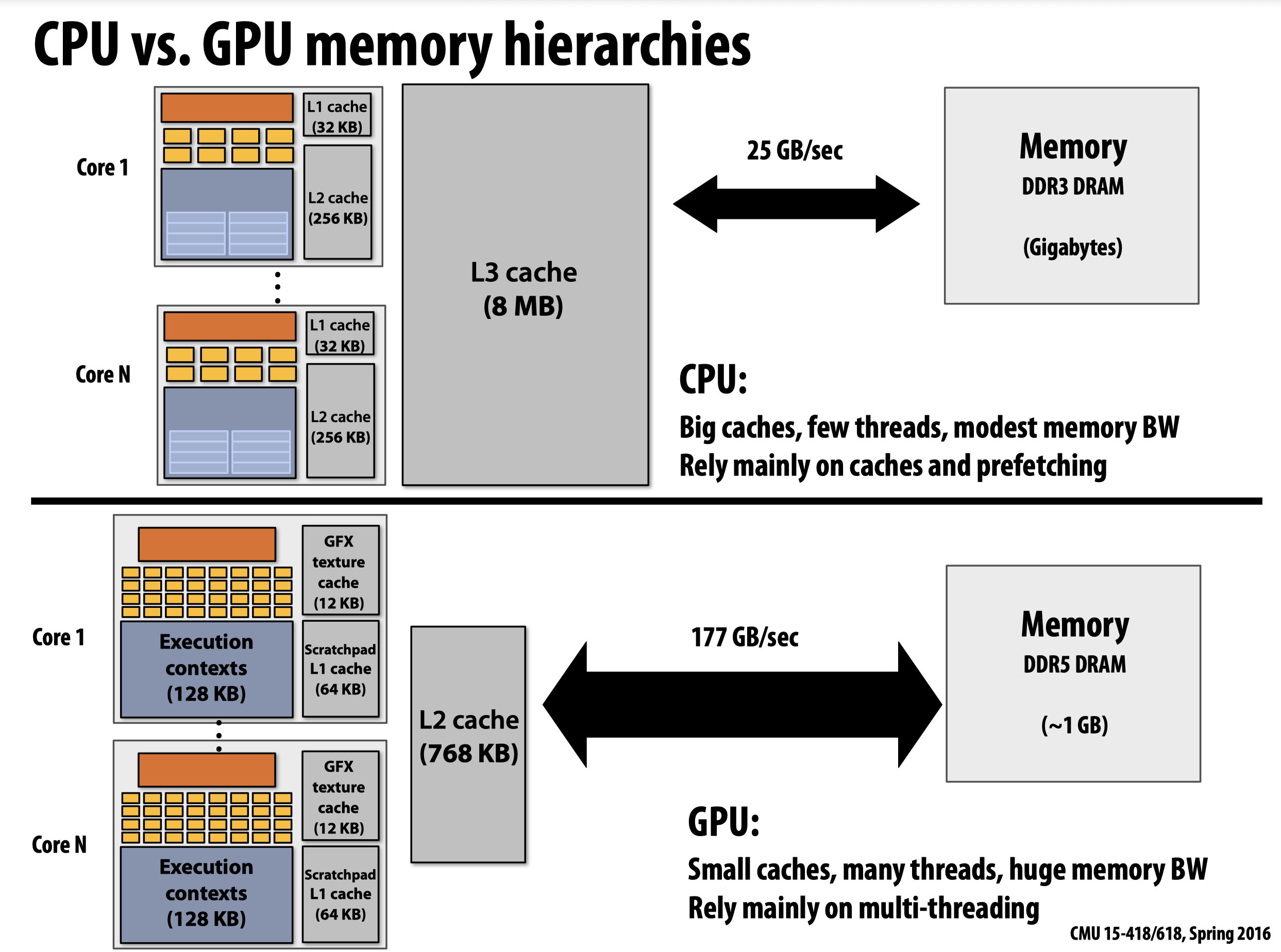
上图表明,CPU会利用更大的缓存来降低延迟,同时使用指令预抓取的方法隐藏延迟。而GPU则将更多的资源集中在了多线程上,它只配备了很小的缓存。进一步的计算可发现,想要完全利用GPU自身提供的多线程/SIMD/多核机制时很难的,换句话说我们需要花费很大的代价才能让GPU keep busy,其所需的bandwith远超上图的177GB/sec(一秒钟内转移多少数据才能让下一秒的GPU一直干活,如此循环往复)。这种现象的原因被称为bandwith limited。
Lecture 3: Program Abstractions
ISPC
ISPC实际上是SPMD(Sing-Program-Multiple-Data)模式的一种编程抽象。
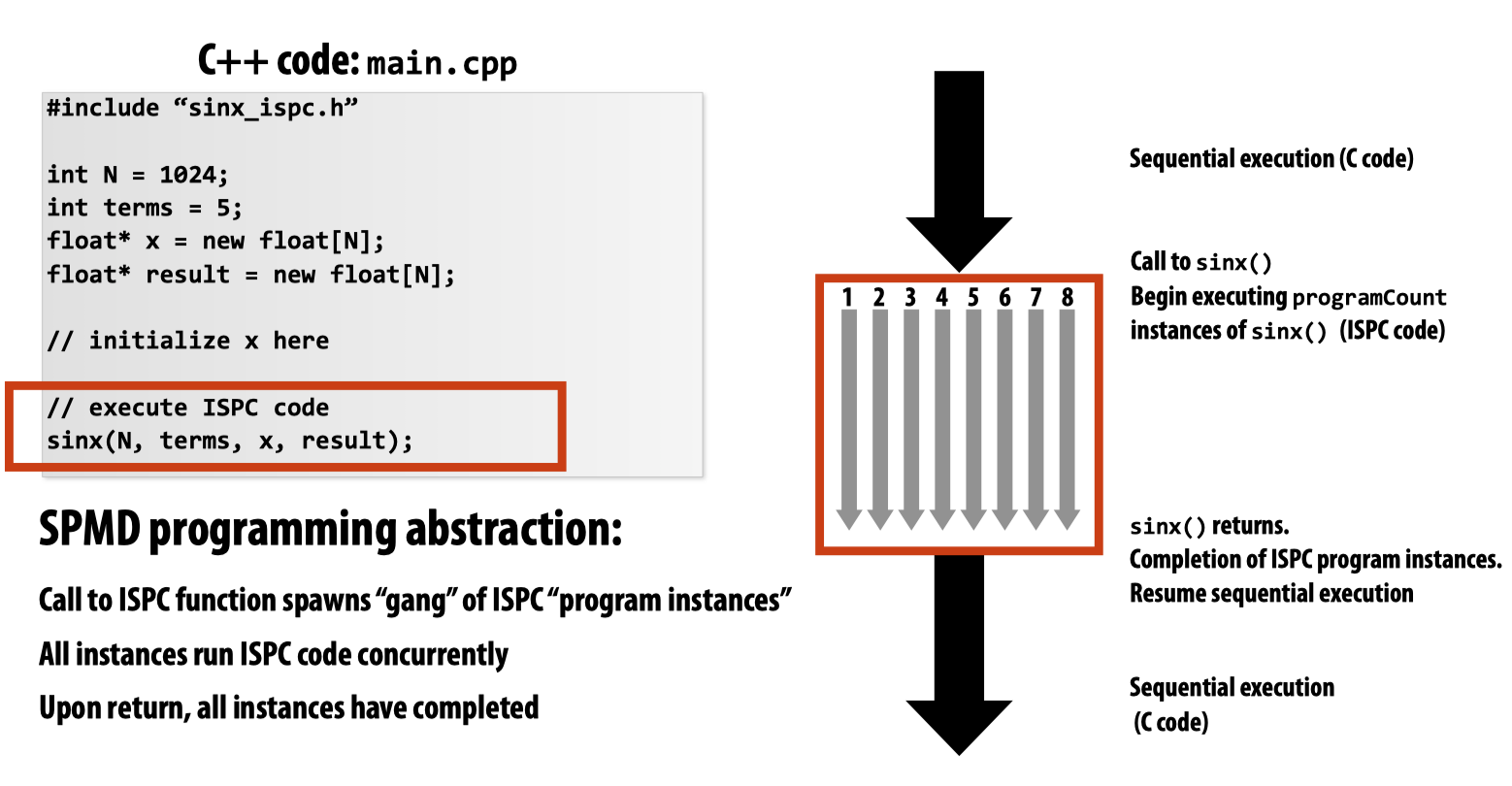
ISPC代码调用的时候会生成多个program instances,我们可以利用programCount和programIndex来获取在一个gang中的实例总数以及当前所在的实例。此外,uniform可以用作确保所有实例只使用变量的同一个副本。

ISPC可以考虑两种实现方式,除了上图所示的方法外,我们还可以把代码写成如下的形式:

第一种方式要优于第二种,因为第二种方式想要利用SIMD指令进行加速必须先将不同位置的数值gather到一起,以下两幅图清楚的展现了上述两种方法的模型抽象:
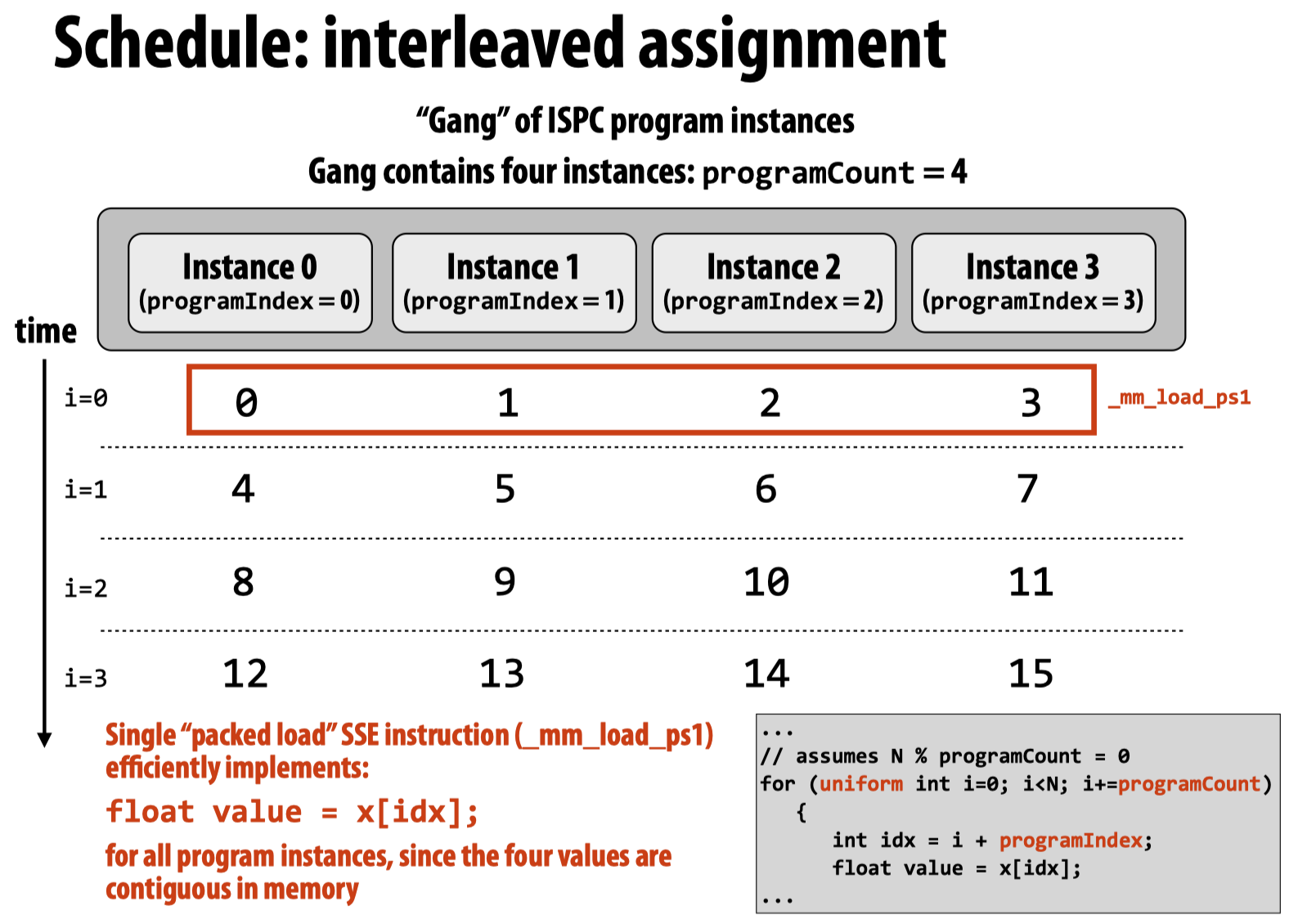
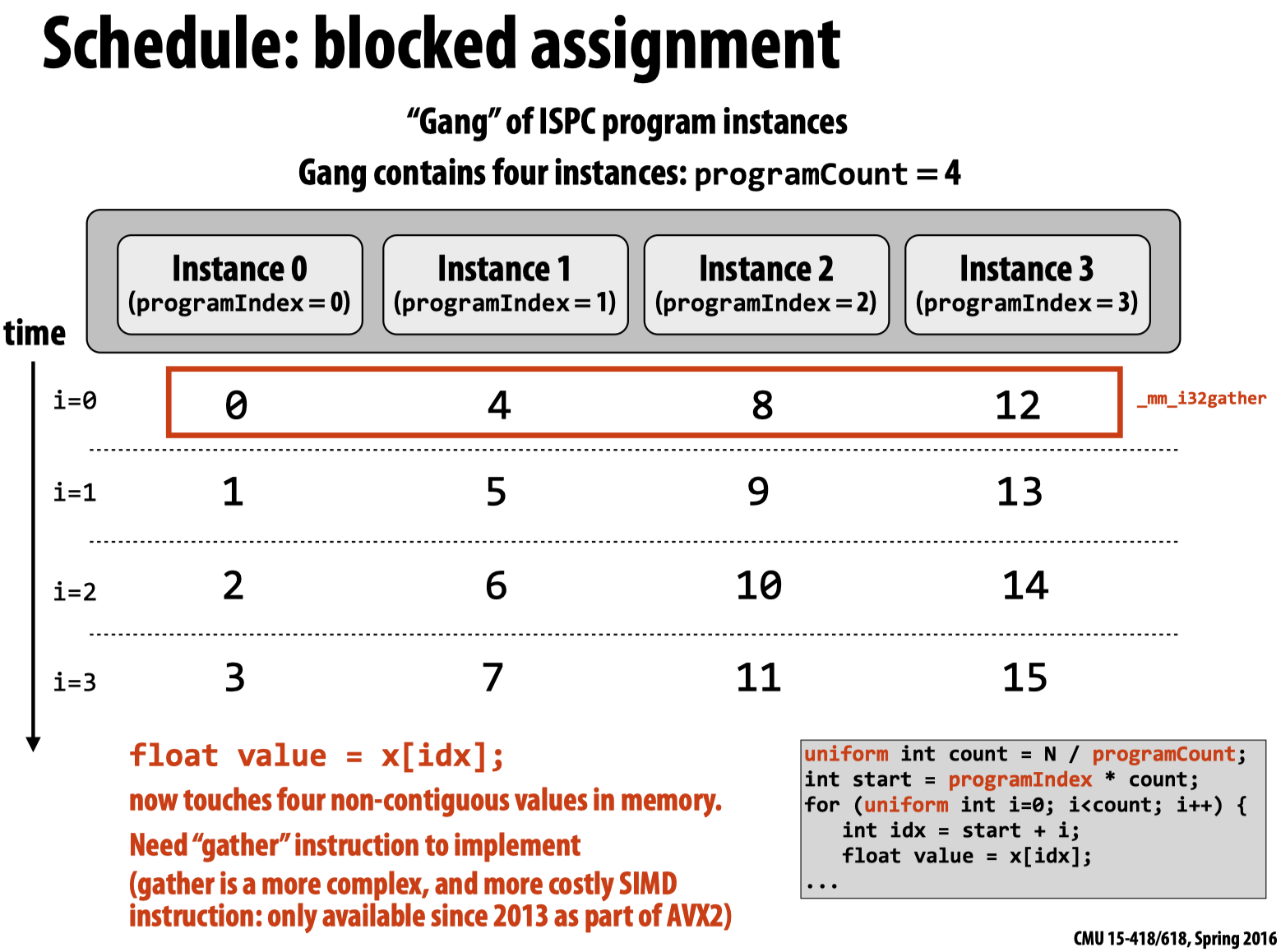
而在通常的ISPC编程中,可以直接利用foreach (i = 0 ... N)来实现(内部采用的是第一种方法),更加简洁。
总结一下,不论将循环写作foreach还是我们自己利用programCount和ProgramIndex处理循环的内部逻辑,在同一个Program Instance内的for循环都不会被被编译器parallel,只是在程序启动时生成的多个program instances会根据我们代码的逻辑选择如何执行以及执行哪一部分的循环(每个实例有不同的ProgramIndex),同时会利用SIMD指令对指令做隐式parallel。
要注意的问题
这张图说明了可能存在的问题:

以上的代码和这段SIMD指令效果相同:
float sumall2(int N, float* x) {
float tmp[8]; // assume 16-‐byte alignment __mm256 partial = _mm256_broadcast_ss(0.0f);
for (int i=0; i<N; i+=8)
partial = _mm256_add_ps(partial, _mm256_load_ps(&x[i]));
_mm256_store_ps(tmp, partial);
float sum = 0.f;
for (int i=0; i<8; i++)
sum += tmp[i];
return sum;
}
多核ISPC
以上讨论的情况全部是单核中的ISPC模型,会使用SIMD进行指令加速。此外,ISPC还可以利用tasks来实现多核的指令加速(利用多线程)。
这里首先要注意的一个问题是,ISPC中的tasks并非等同于thread,当我们调整任务数量的时候会发现,在任务数量等同于CPU的逻辑线程数量的时候并非是加速比达到最大,如果继续增大任务数量,加速比会继续提高。
根据官方文档的说法,我们应该启动比逻辑线程更多的任务数量,以确保更好的负载均衡和性能。
Tasks are independent work that can be executed with different cores. Contrary to threads, they do not have execution context and they are only pieces of work. The ISPC compiler takes the tasks and launches however many threads it decides.
In general, one should launch many more tasks than there are processors in the system to ensure good load-balancing, but not so many that the overhead of scheduling and running tasks dominates the computation.
// slightly different kernel to support tasking
task void mandelbrot_ispc_task(uniform float x0, uniform float y0,
uniform float x1, uniform float y1,
uniform int width, uniform int height,
uniform int rowsPerTask,
uniform int maxIterations,
uniform int output[])
{
// taskIndex is an ISPC built-in
uniform int ystart = taskIndex * rowsPerTask;
uniform int yend = ystart + rowsPerTask;
uniform float dx = (x1 - x0) / width;
uniform float dy = (y1 - y0) / height;
foreach (j = ystart ... yend, i = 0 ... width) {
float x = x0 + i * dx;
float y = y0 + j * dy;
int index = j * width + i;
output[index] = mandel(x, y, maxIterations);
}
}
export void mandelbrot_ispc_withtasks(uniform float x0, uniform float y0,
uniform float x1, uniform float y1,
uniform int width, uniform int height,
uniform int maxIterations,
uniform int output[])
{
uniform int rowsPerTask = height / 25;
// create 2 tasks
launch[25] mandelbrot_ispc_task(x0, y0, x1, y1,
width, height,
rowsPerTask,
maxIterations,
output);
}
The launch keyword in
ISPCprovides a way for a “task” to execute asynchronously. These tasks can run concurrently on multiple cores, and there is no guarantee about the order in which they will execute, especially if there are more tasks launched than available threads. Maybe a good way of thinking about a task is just a “thing to do” and threads are just workers that “do the things”.
Three parallel programming models
共享内存(Shared address space)
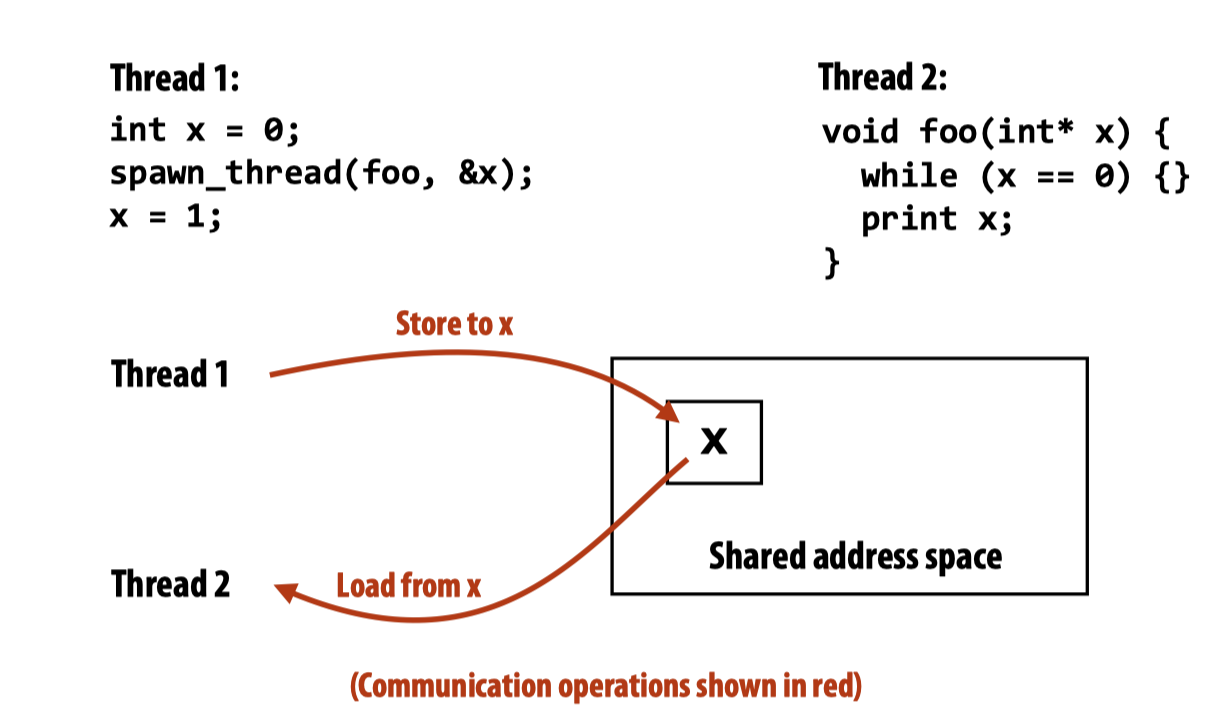
操作系统的课里我们看到的锁的实现,实际上也是利用了共享变量的编程模式来实现Synchronization primitives.
共享内存的高效实现需要硬件支持,为了将不同处理器的local memory连接到一起,可以用多种设计方法:
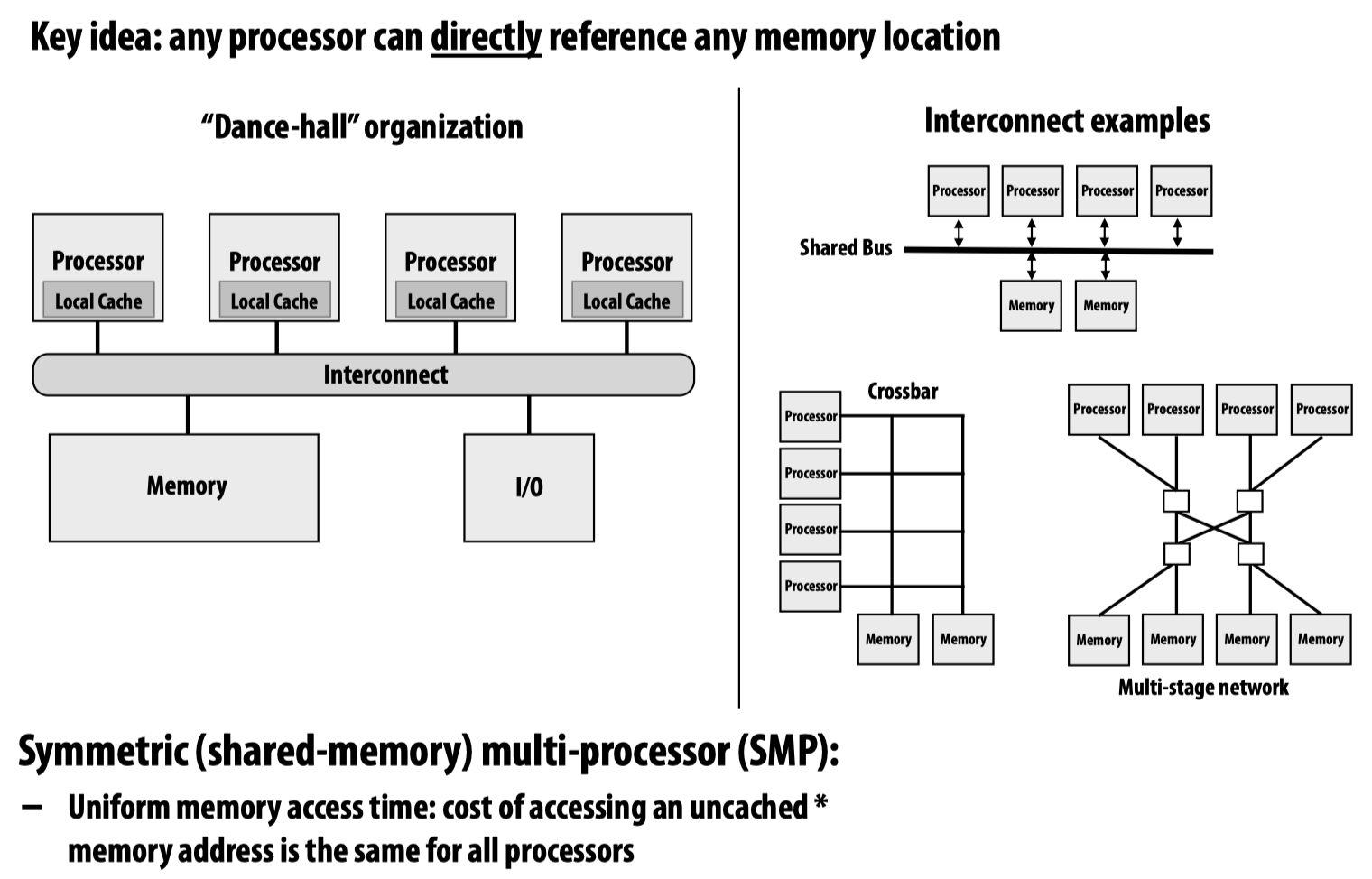
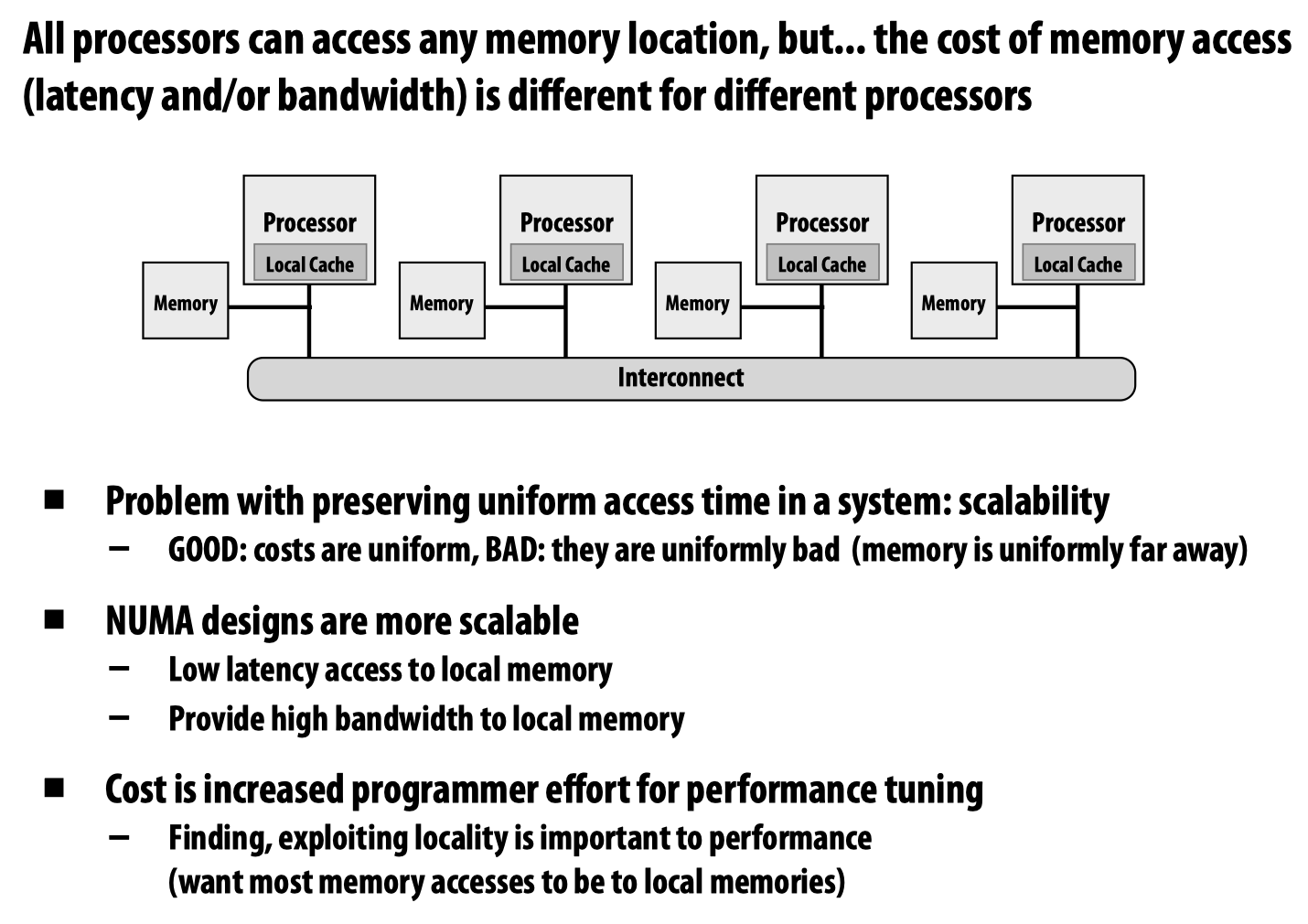
上边的设计方法目的在于保证对于每一个独立的处理器,其访问任意一块内存的代价应当是一样的,当然这不是必需;还有一种Non-unifomr memory access (NUMA)的设计方法:
消息传送(Message passing)
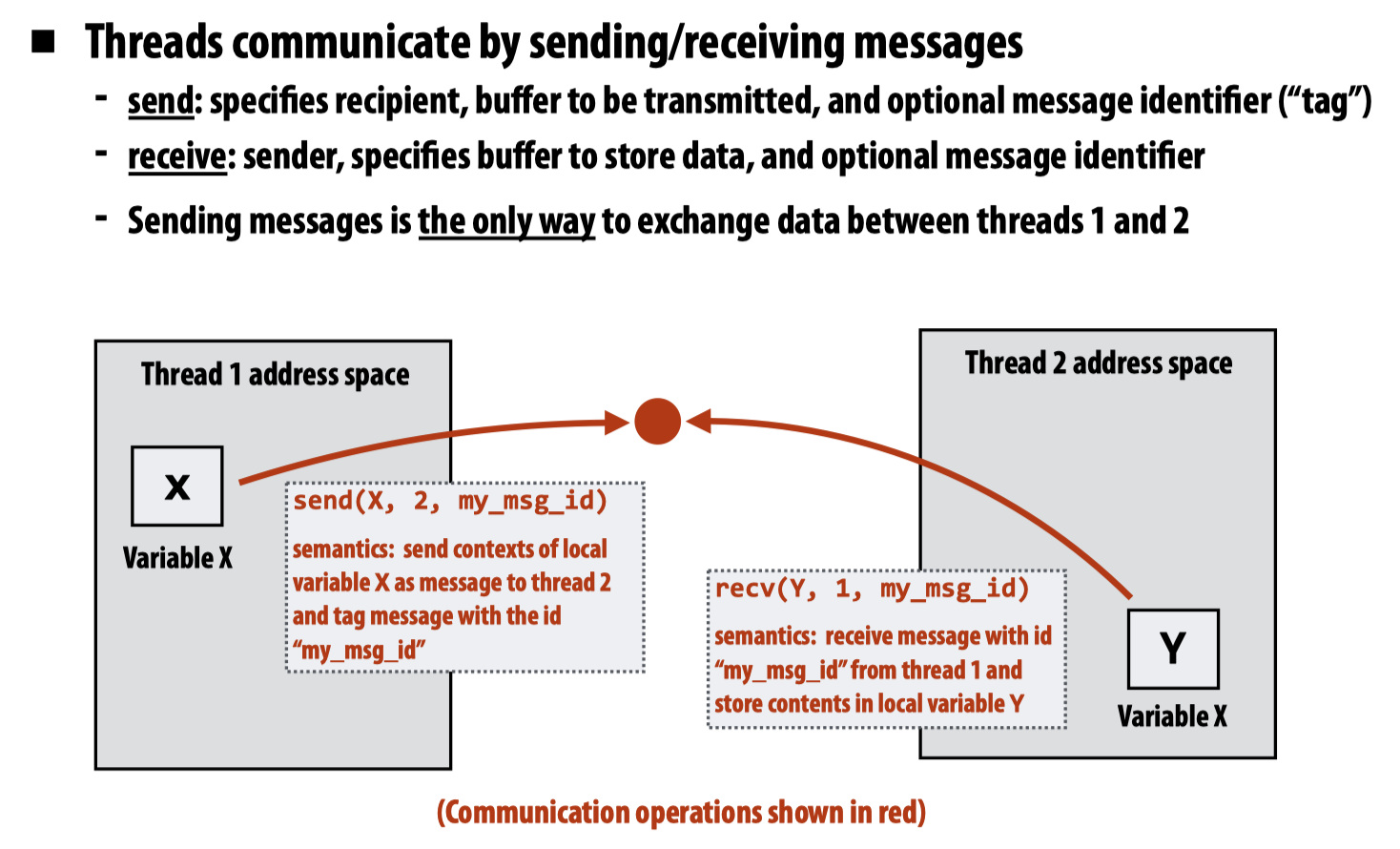
这种通讯方法在先前的操作系统课程中,类似的有pipe以及在处理外设输入输出的ring buffer,都是通过消息传递的方法实现了线程(在上述情景下是进程间通讯)间的通讯。
MPI(
message passing interface)就是消息传送并行的实现之一
基于消息传递的并发模型可以分为两种:
- CSP(Communicating Sequential Process) – e.g. Golang channel
- Actor – e.g. Erlang
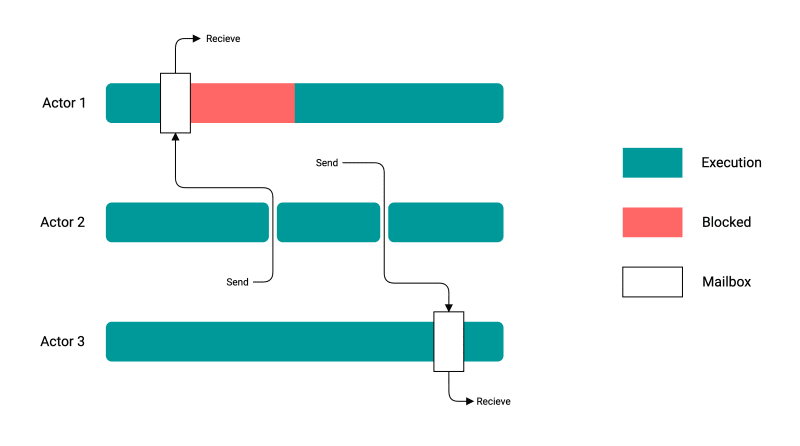
CSP模型的关键在于channel,他通过channel来实现消息传递,是一个同步模型,发送端会阻塞直到接收端读取消息。
Actor模型则通过mailbox实现消息传递,是一个异步模型,发送端在将消息放入接收端的mailbox后,就继续工作而不被阻塞。
| CSP | Actor |
|---|---|
 |  |
数据并行(Data parallel)
可以将数据并行模型的计算过程抽象成map(function, collection)。在ISPC代码中,就可以将循环体作为一个function,将foreach结构作为map函数,操作的X数组是collection:我们对X中的每一个元素调用function函数—-这正是map函数要做的事情。
这种并行模型容易产生的一个问题是:它并不保证执行顺序完全按照顺序执行(虽然这么说可能不太准确,但是如果有过多线程编程经验的应该知道是啥意思),比如对于如下的ISPC代码:
// ISPC code:
export void shift_negative( uniform int N, uniform float* x, uniform float* y) {
foreach (i = 0 ... N) {
if (i >= 1 && x[i] < 0)
y[i‐1] = x[i];
else
y[i] = x[i];
}
}
顺序执行当然不会产生问题,但注意到其中可能会发生对同一个内存位置的复写,由于并行模型(在这里是多个program instances)无法保证执行顺序(在这里是将数据存入y的顺序),所以该代码的结果是non-deterministic的,即即使对于同一组输入,可能也会有不同的输出结果。
Data-parallelism还可以理解为stream programming model:

这里,stream表示的是collection,kernel是我们需要的function。需要注意stream针对的是数据,而非函数(函数的流式运算一般被称为pipeline),以下这幅图可以更好的表示stream programming model:
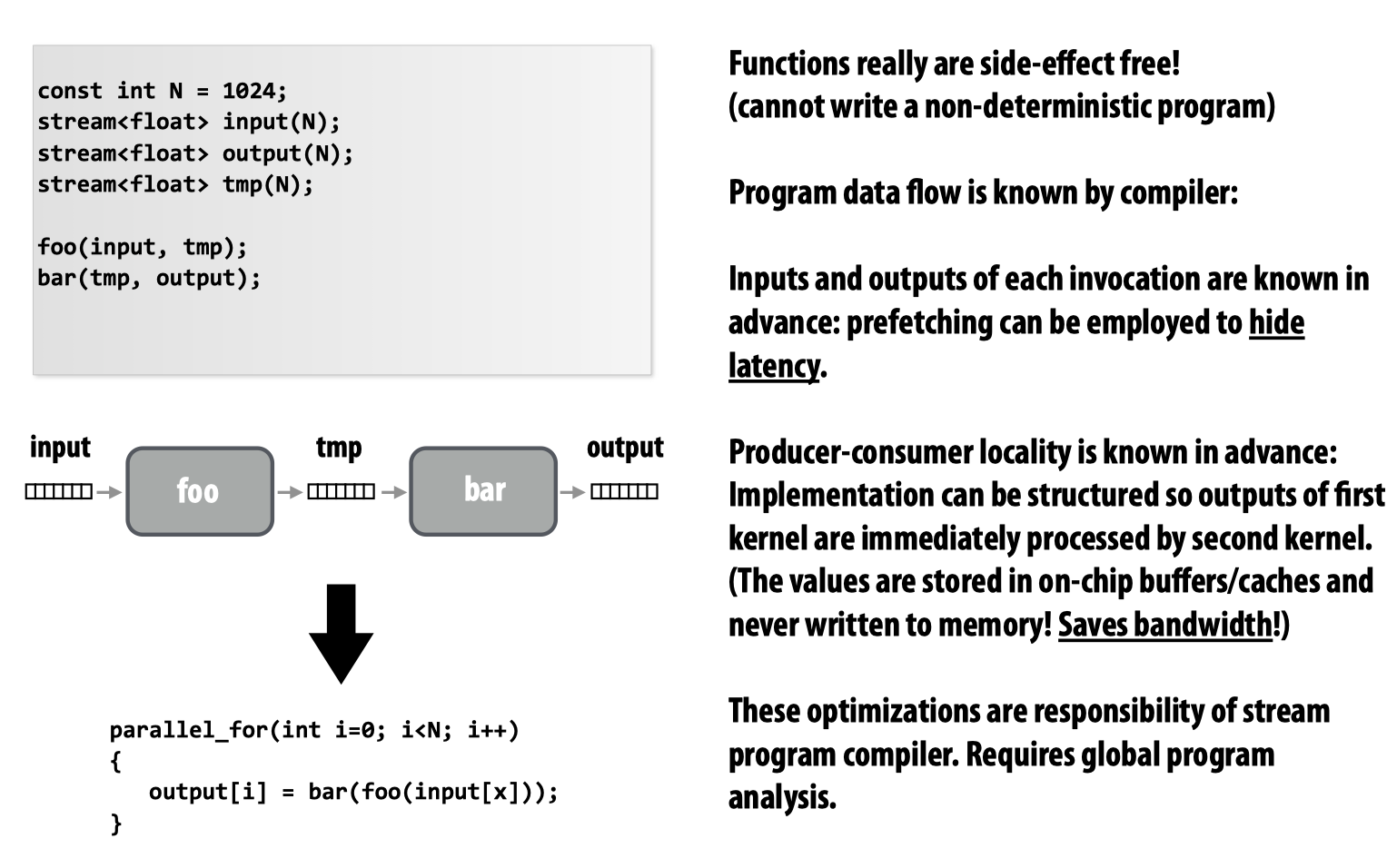
简而言之,这种方法由于不需要将中间的运算结果写入tmp文件,一方面减少了内存/磁盘的占用空间,另一方面节省了内存带宽(作为临时变量直接被下一个operator计算)。我们可以在一定程度上期望编译器为我们做出上图所示的优化。
当然这种模型要求我们提供很多的合适的operator来完成流式运算,该模型的一个tradeoff就是我们可能找不到合适的opaertor来完成运算。
两种经常用到的communication primitives:


Lecture 4: Parallel Programming Basics
Creating a parallel program
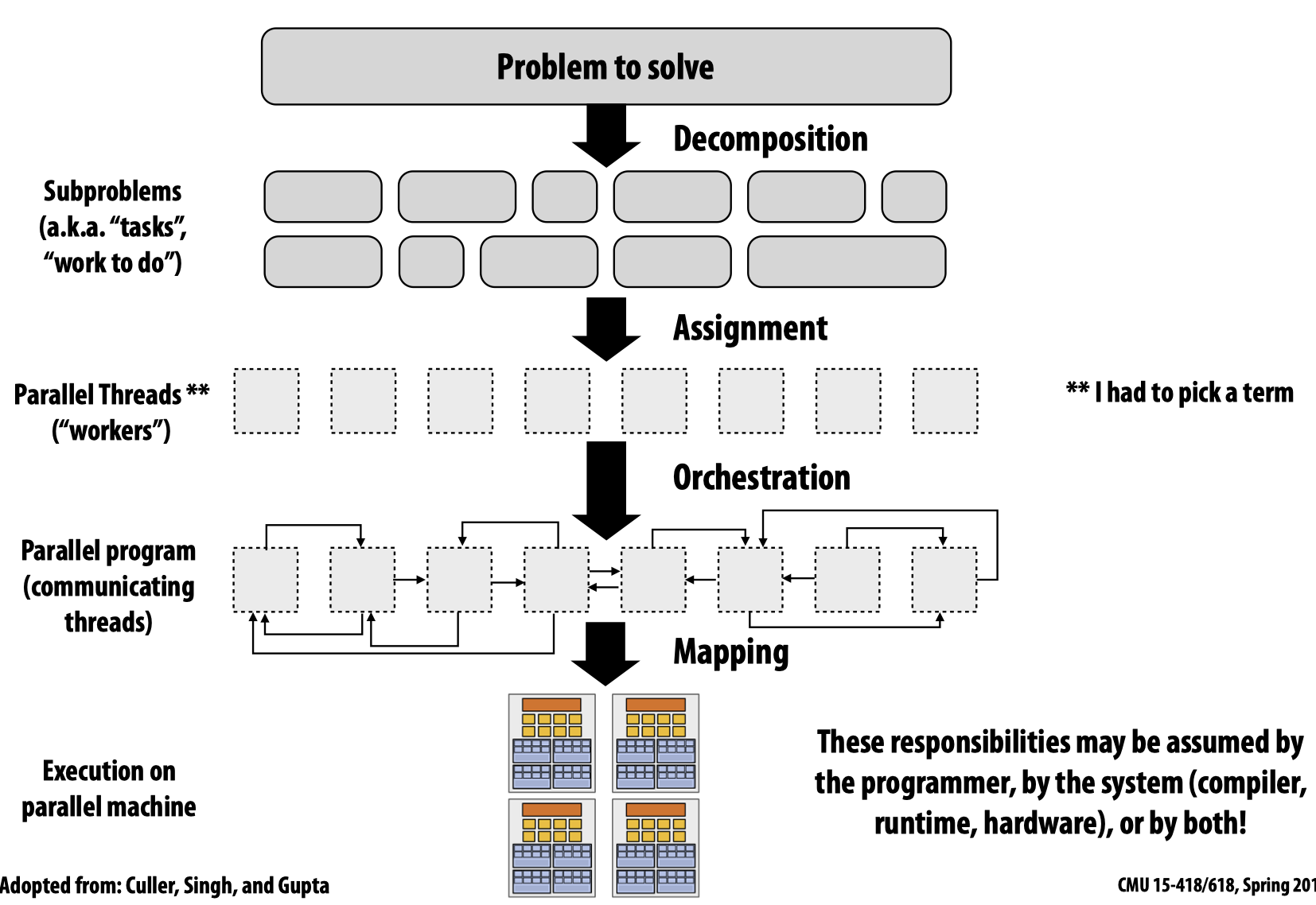
- Decomposition: Break up problem into tasks that can be carried out in parallel
无论是编写程序的人员还是编译器自动分解问题(现阶段大部分情况下都需要程序员来实现这一步),都应该本着创建的任务数量至少能确保所有的执行单元都有事情做
Key: Identifying dependencies
- Assignment: Assign
taskstothreads/workers(keep balance workload & reduce communication costs)
在这里,我将threads理解成软件线程。Assignment的过程可以静态实现,也可以动态实现。静态分配意味着哪一个任务被哪一个线程执行是确定的,或者说某一个线程执行某一个(某些)任务也是固定的,但动态分配不一定。
在ISPC代码中,不论是根据ProgramCount等内置变量来书写for循环内部逻辑,还是利用foreach ,都是Static assignment—-将iterations给到program instances。虽然foreach关键字这种抽象为dynamic assignment提供了空间,但在ISPC的实际实现上仍然是静态的。
当使用pthreads时:

而如果使用ISPC的tasks,则是典型的动态分配,在课上教授还可以了一个例子,用来比较两种线程-任务调度策略哪一个更好(分别是对于每一个任务产生一个线程来执行,例子中将其简化为不断的产生新的线程;另一个是先生成一个含有4个线程的线程池,之后不断的给线程池中的线程喂任务),最后的结论是第二种调度策略显著优于第一种。所以在ISPC的任务调度的内部实现使用的是第二种方法:
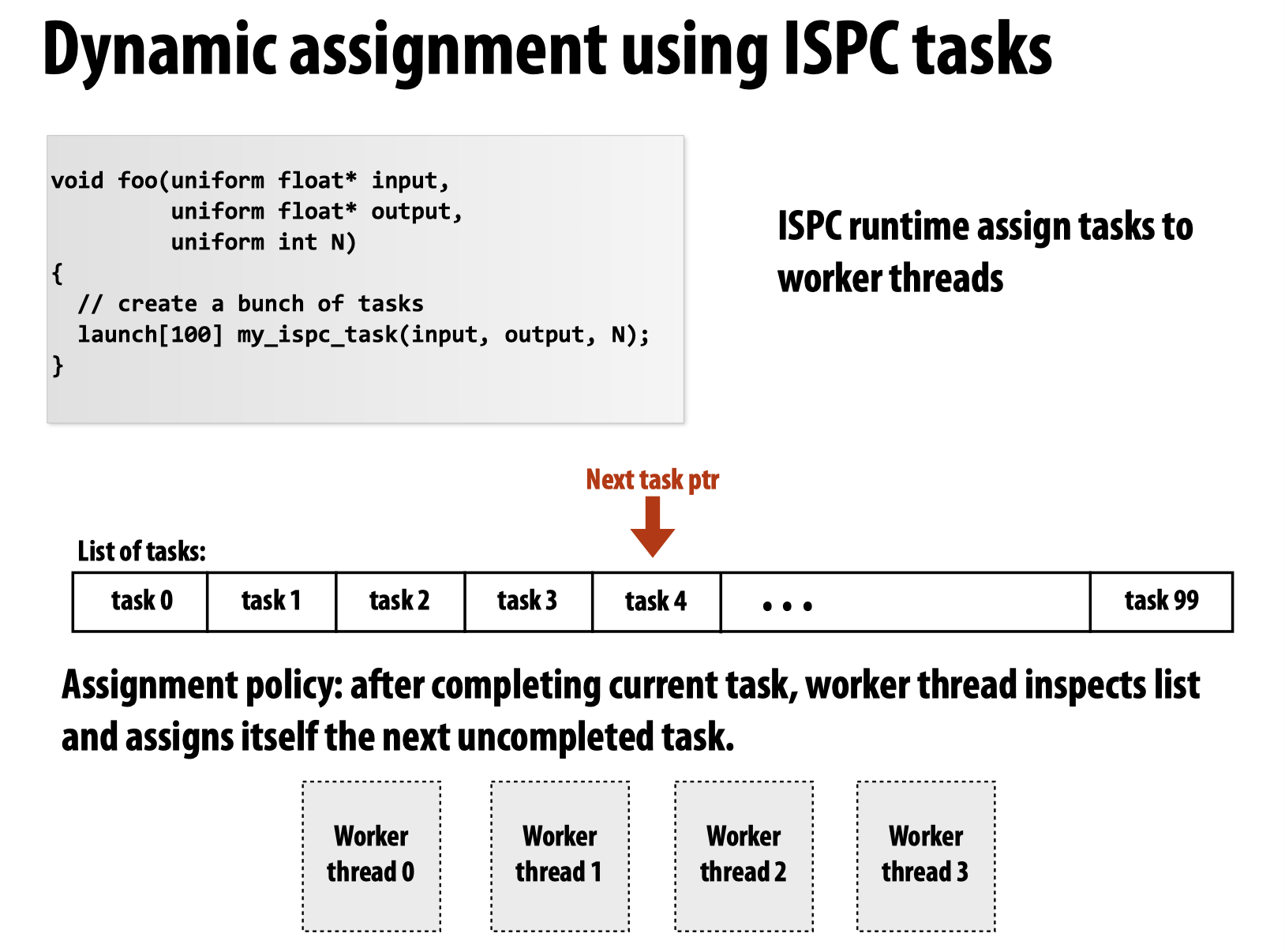
总结:
Many language/runtimes are able to take the responsibility. It could be done statically by programmer (Pthread workload assignment by programmer), statically by compiler (ISPC foreach) and also can be done dynamically (ISPC tasks).
- Orchestration

- Mapping

Amdahl’s Law
阿姆达尔定律的主要内容是:如果程序无法被并行的部分占比为s,那么程序的最大并行加速比不会超过1/s. 具体内容在计算机组成结构的课程中讲过,这里不再赘述。
Code Example (Lock & Barrier)

Assignment的过程是谁实现的?是如何实现的?
这里的分配是由系统实现的,一般来讲这里有两种实现方法:

到底哪种方法更好,取决于运行的系统,但是第二种选择显然要求处理器之间更多的数据交换。
Orchestration的两个位置都是在干什么?
第一个同步是为了将每一个worker的local_diff汇合到diff里,第二个同步是为了等待所有的worker工作完成后,代码进入顺序执行模式。
当然,除了上述Data Parallel的抽象外,还可以用Shared address space的方法抽象,这种方式和我们经常写的多线程代码比较类似,看起来比较易懂,下边会有几张幻灯片表示在这种抽象下,代码可以如何被优化:

如上图所示,注意到循环每执行一次,都需要对diff加锁更新,为了避免频繁上锁带来的性能损耗,可以为每一个线程都单独准备一个mydiff,当内部的两层for循环执行完毕后,只需要加一次锁更新全局变量diff即可:

而关于代码中的barrier,在先前的操作系统课程(MIT 6.S081)中实现过:
struct barrier {
pthread_mutex_t barrier_mutex;
pthread_cond_t barrier_cond;
int nthread; // Number of threads that have reached this round of the barrier
int round; // Barrier round
} bstate;
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
if (++bstate.nthread == nthread) {
// wakeup
round = ++bstate.round;
bstate.nthread = 0;
// 唤醒所有sleep在条件变量上的线程,让他们move forward
pthread_cond_broadcast(&bstate.barrier_cond);
} else {
// 释放互斥锁,同时sleep在条件变量上
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
// 函数返回时,该线程重新获得互斥锁
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}
通过如上的代码,即可实现等待所有的worker都完成工作后,代码继续执行。
在这个案例中三个barrier的职责分别是:
The first Barrier is to prevent the case that after some thread calculates diff, diff gets overwritten by other threads when executing diff = 0.f.
The second Barrier is to make sure that all threads has calculated their own diff, so the final diff is the sum we want before checking convergence.
The third Barrier is to prevent the case that some thread already on next iteration writes diff to 0, which will make the if statement true for other slower threads, leading to a wrong result.
在分析barrier的作用,包括分析多线程代码是否出问题时,我们可以在对某一个变量进行读取/写入的位置固定某一个假想线程的位置,让另一个假想线程继续执行,看是否会出现non-deterministic的执行结果。
在之前,我们看到了如何通过设置局部变量来减少lock的使用次数,从而优化代码,接下来看如何减少barrier的使用次数:

这里的diff[3]并不是随便选择的数字,假设现在几个线程被阻塞在循环内部的barrier处,此时线程池中最后一个线程走完这一轮,通知各线程可以开始下一轮了,于是会出现如下两种情况:
- 有的线程还没来得及执行
barrier下的if语句 - 有的线程一路执行到了下一轮的
barrier上方的diff[(index+1)%3]处
以上情况表明,程序编写者需要确保index, index + 1, index + 2这三个位置相互独立,所以至少需要三个diff。
Lecture 5: GPU Architecture & CUDA Programming
在章节的一开始,教授花了一些篇幅来介绍GPU的发展历史,这里暂且不表。我们只需要知道,GPU一开始被人们拿来用作与图形相关的计算,计算流程如下所示:

其中,经过不断的技术迭代,Vertex Processing和Fragment Processing的处理方式由一开始的指定颜色、材料的参数变为了通过将kernel function映射到input fragment stream上以提供更加多样的材料和颜色等选择。
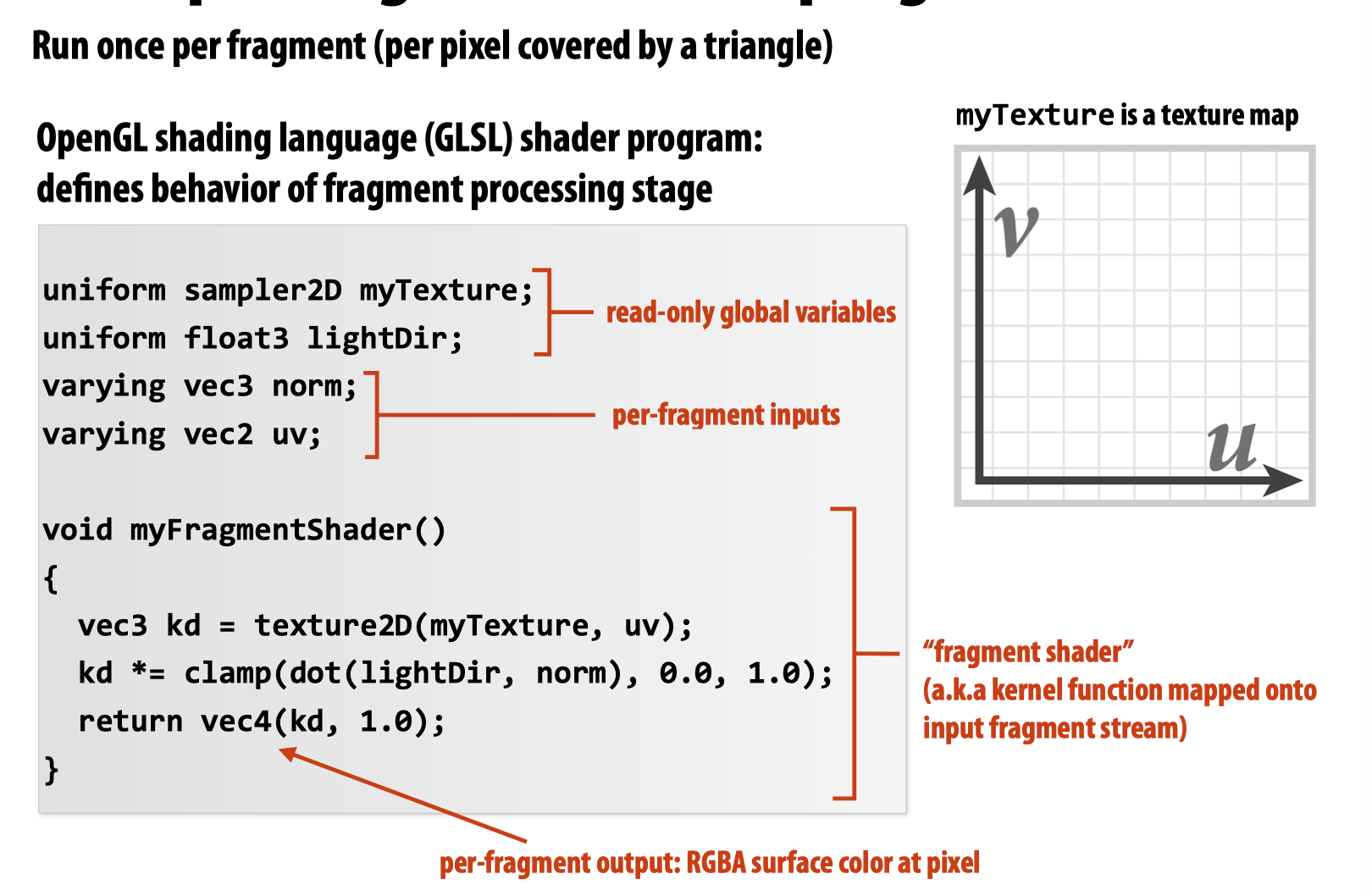
后来,人们发现了GPU在non-graphic-specific(compute mode)上的巨大潜能,这也是我们这堂课主要讨论的目标。
在compute mode下,计算流程与图形计算相比更加简单:
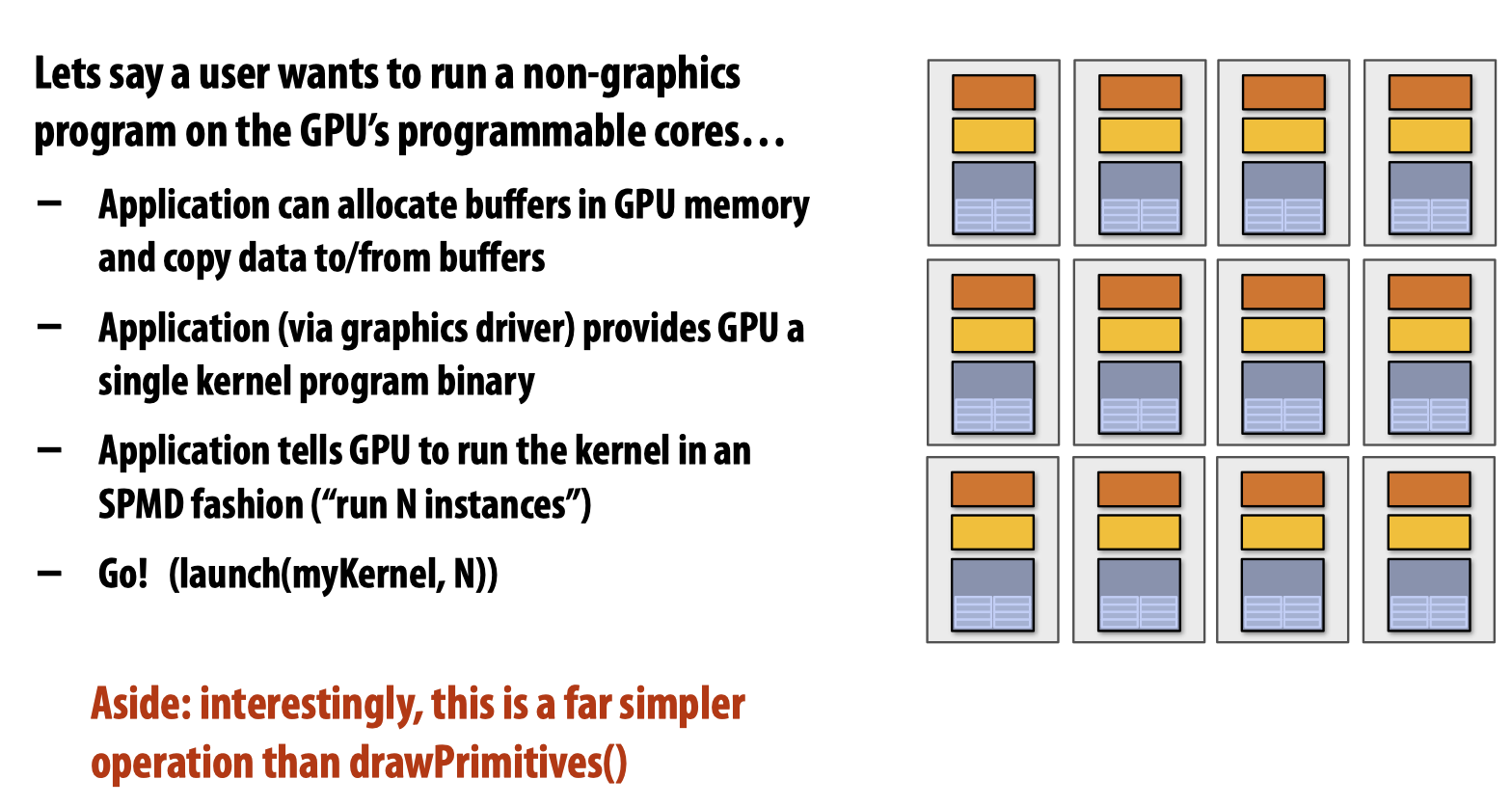
简单来说,我们只需要丢给GPU一个kernel program binary,告诉它运行N次即可!
CUDA Threads
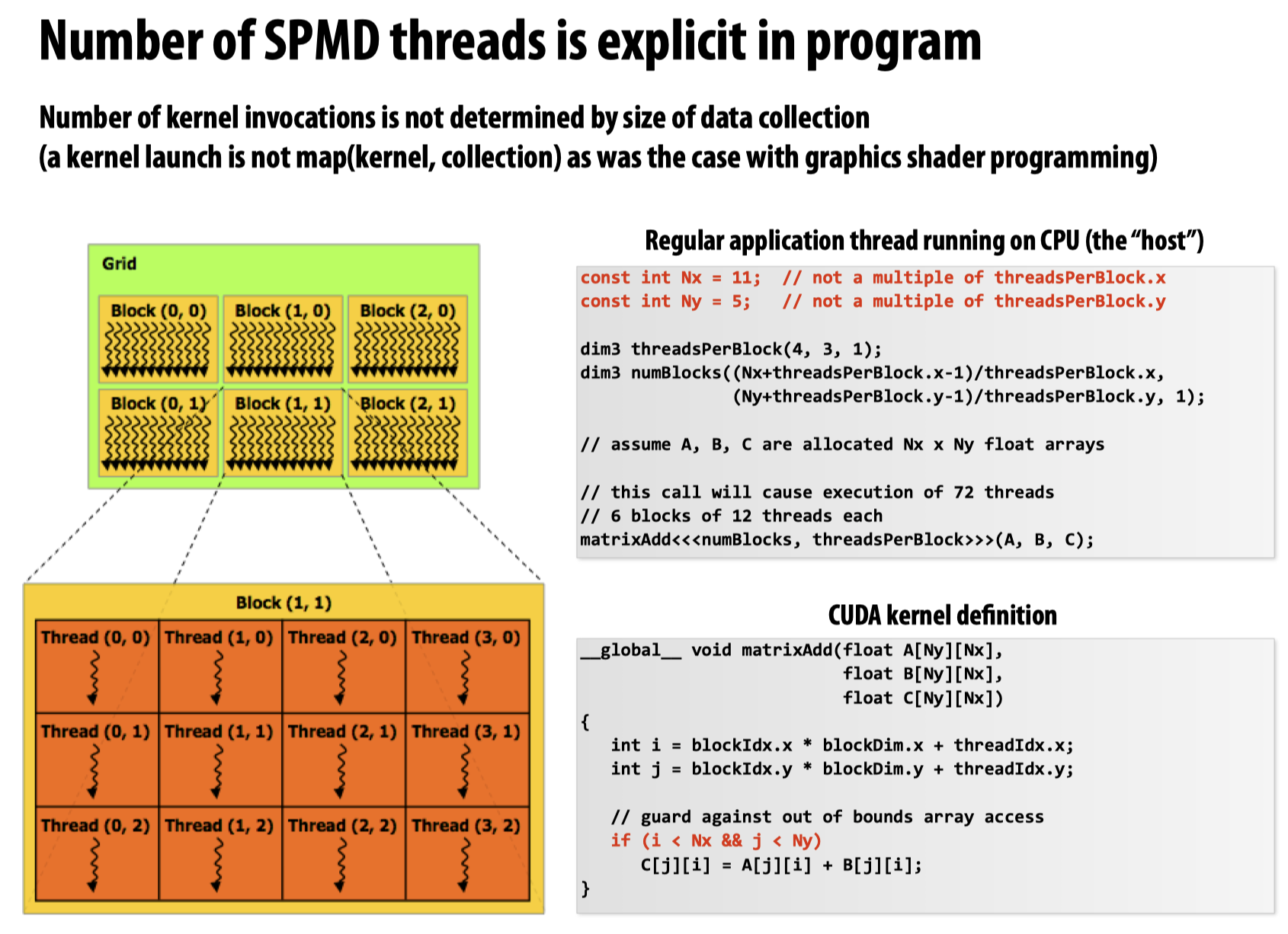
以下是一个基本的CUDA示例程序:

注意该程序是如何指定block数量以及一个block中的线程数量的。在CUDA中,最多可以指定3维的线程数量,如果不需要最后一维,就将其设置为1,同时可以通过.x/.y/.z来获取对应的线程数量。于是在这幅图里,每一个block里被安排了4*3*1=12个线程,总共设置了12/4*6/3*1=6个block。
在代码的最后,按照我们先前提到的GPU compute mode的计算方法,直接给入matrixAdd的kernel function,让GPU来计算,于是GPU按照给定的参数启动相应的block和CUDA threads。

global关键字表示这是一个CUDA kernel function,但是可以从host side调用,而device关键字则表示,该函数只能被cuda device侧的函数调用。
需要注意的是,CUDA threads和数据数量无关,它是由我们显式给出的,也就是说,kernel function的使用并非是以map(kernel, function)的形式调用的,在下边这张ppt中,教授主要表达的意思是:虽然Nx和Ny都不是线程数量的整数倍,但硬件还是会分配出与我们显式给出的线程数量一致的硬件线程,而非和Nx以及Ny匹配的线程数量,这就导致有一些线程啥也没干(不符合代码中最后if的条件):
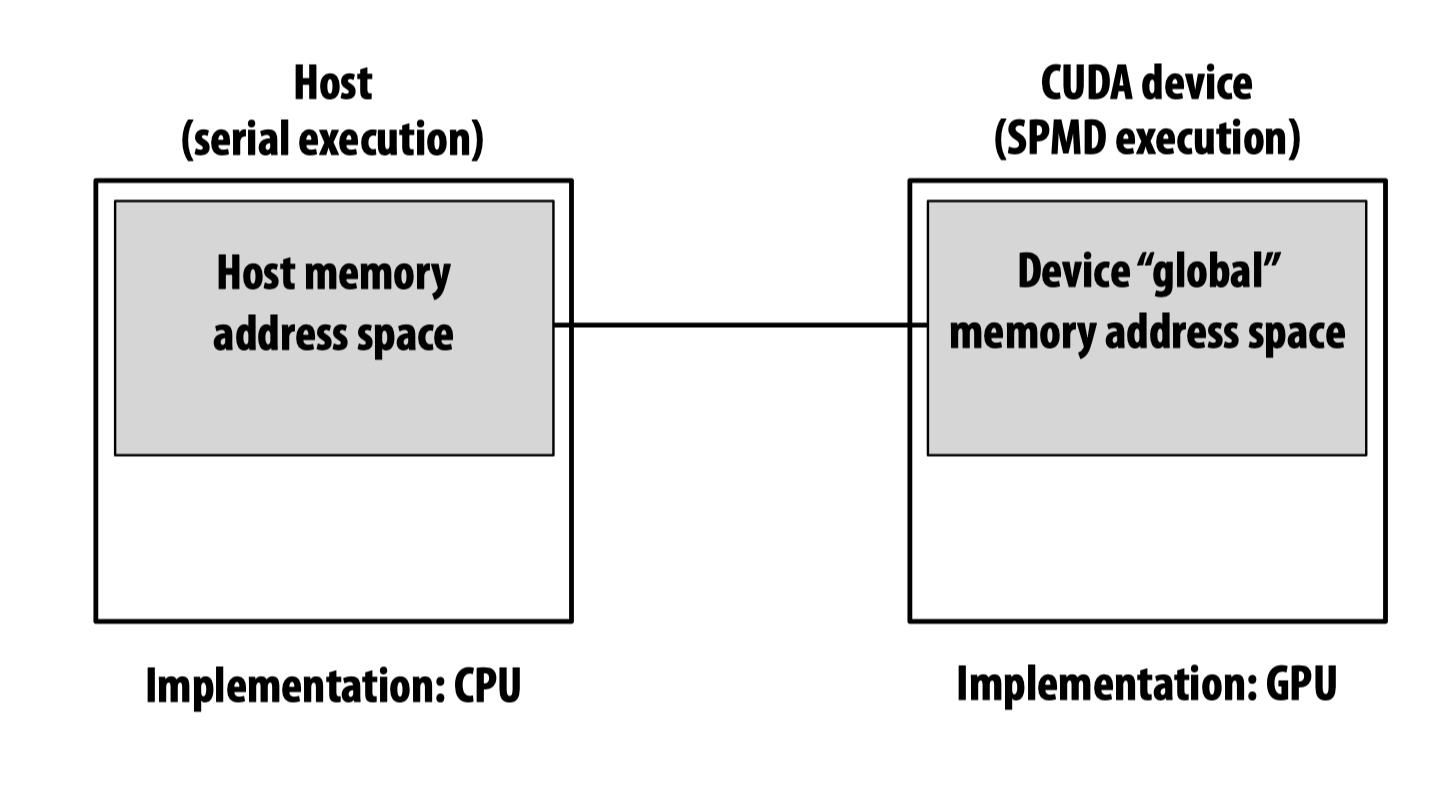
CUDA device memory model
我们来看下边这样一段代码:
float* A = new float[N]; // allocate buffer in host mem
// populate host address space pointer A
for (int i=0 i<N; i++)
A[i] = (float)i;
int bytes = sizeof(float) * N;
float* deviceA; // allocate buffer in
cudaMalloc(&deviceA, bytes); // device address space
// populate deviceA
cudaMemcpy(deviceA, A, bytes, cudaMemcpyHostToDevice);
// note: deviceA[i] is an invalid operation here (cannot
// manipulate contents of deviceA directly from host.
// Only from device code.)
- 为什么
cudaMalloc中的第一个参数,即分配内存的起始地址要以二级指针的形式给出?
因为需要被更改的是指针deviceA的值,而C中是没有引用的,为了在函数返回后,对应的参数中存储我们需要的值,就必须给入一个二级指针从而将值存入一级指针内。
- 为什么在代码中直接写
deviceA[i]是不合法的操作?
这个问题类似于之前在操作系统课程实验中接触过的在内核态中无法直接解引用用户态指针的问题,是因为解引用的过程实际上包含了硬件自动寻址—-即从VA利用页表到PA的翻译过程,但是kernel pagetable中并没有对应的user pointer(address)的映射,于是就会报错。
在这里,因为CPU和GPU两者处于不同的地址空间中,而deviceA[i]实际上等价于*(deviceA + i),所以也会出现一样的问题。
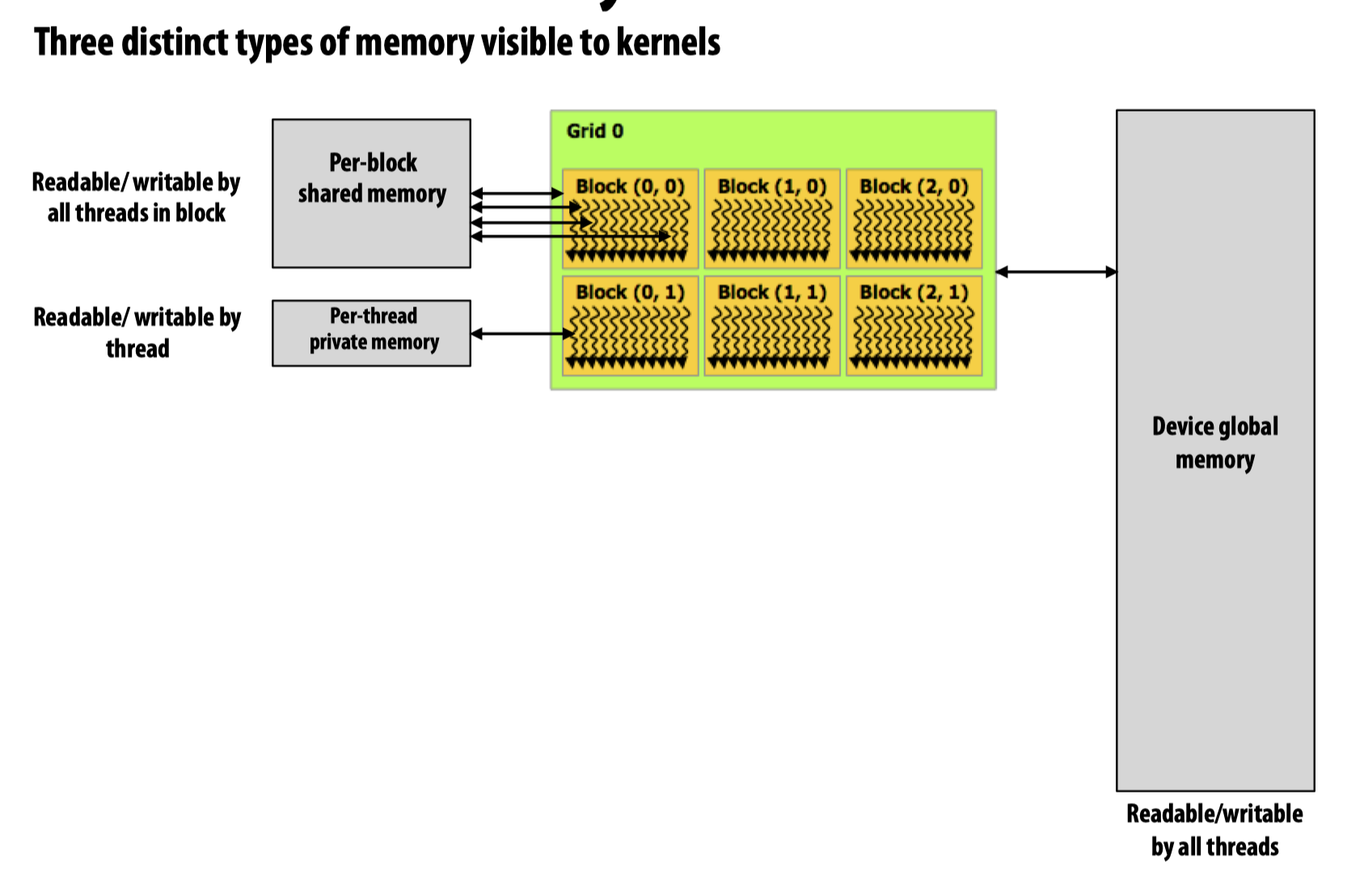
在CUDA device memory model中有三种类型的内存:
- Device global memory
- Per-block shared memory
- Per-thread private memory
Code Example (Shared Memory & Assignment policy)
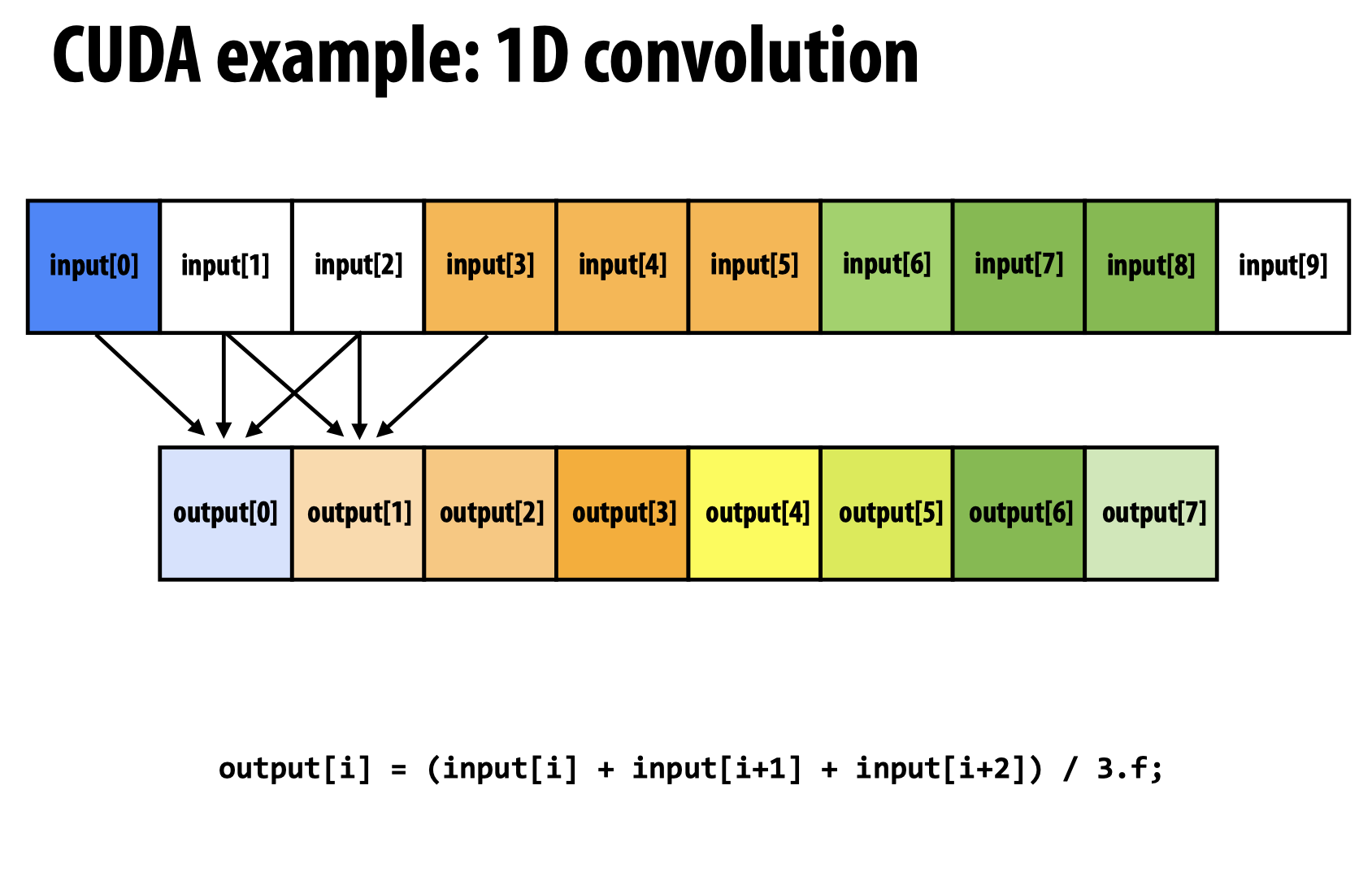
首先看第一种解决方案:
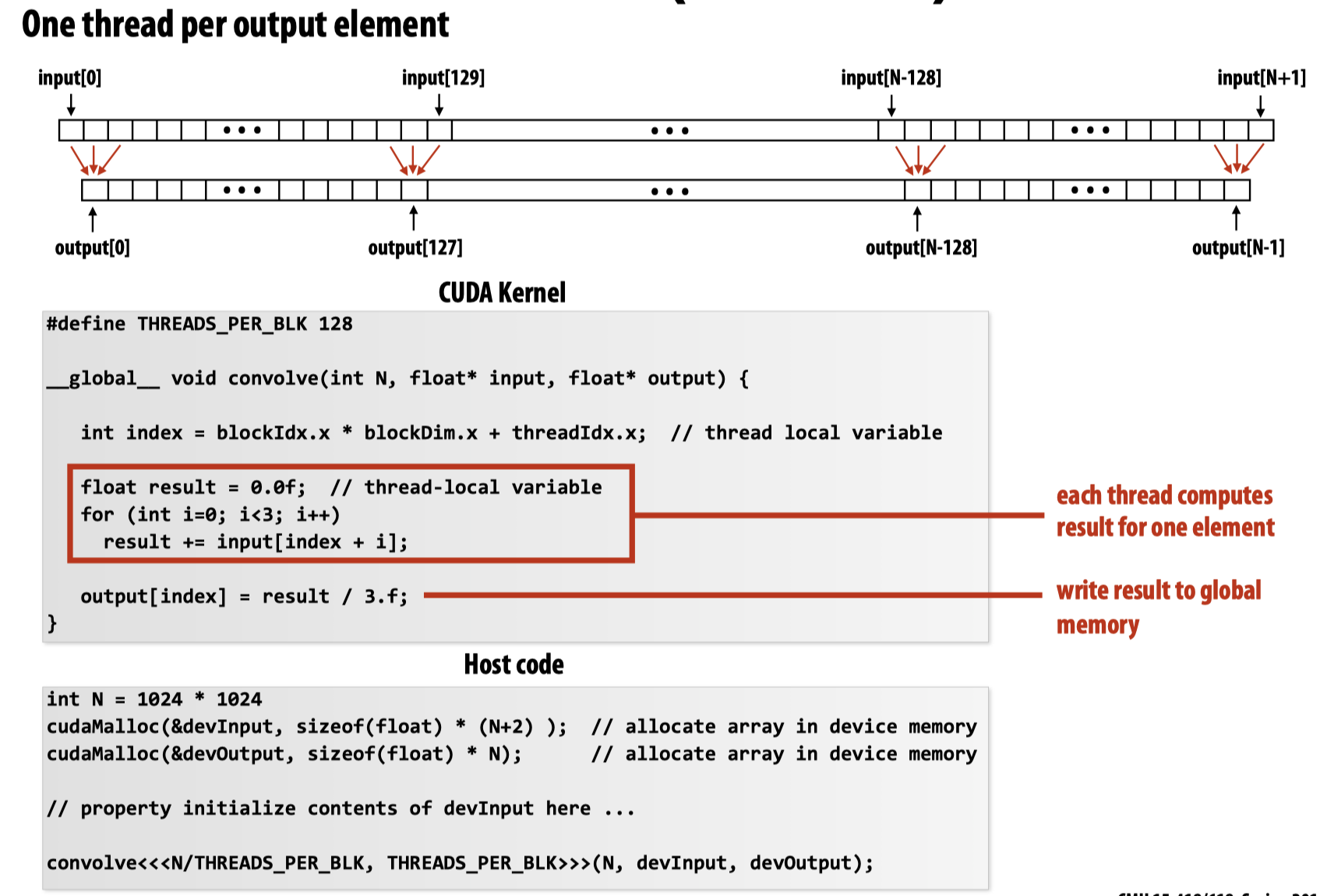
这种方法下,对于每一个block,都需要进行3*128次load指令加载(每一个线程都需要三次load操作来更新result)。
而对于第二种方案:
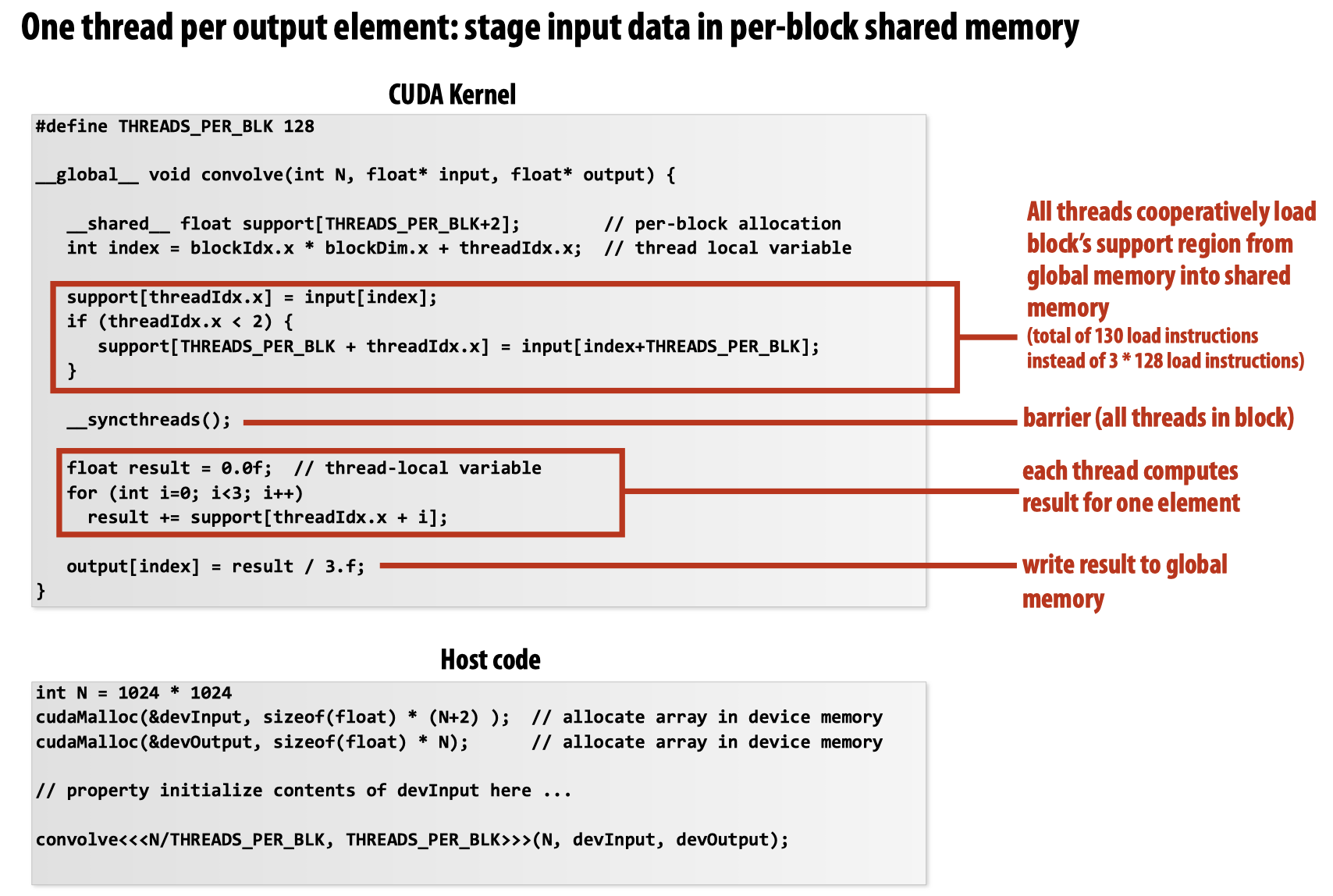
这段代码有点绕,可以用这幅图看得更加直观:
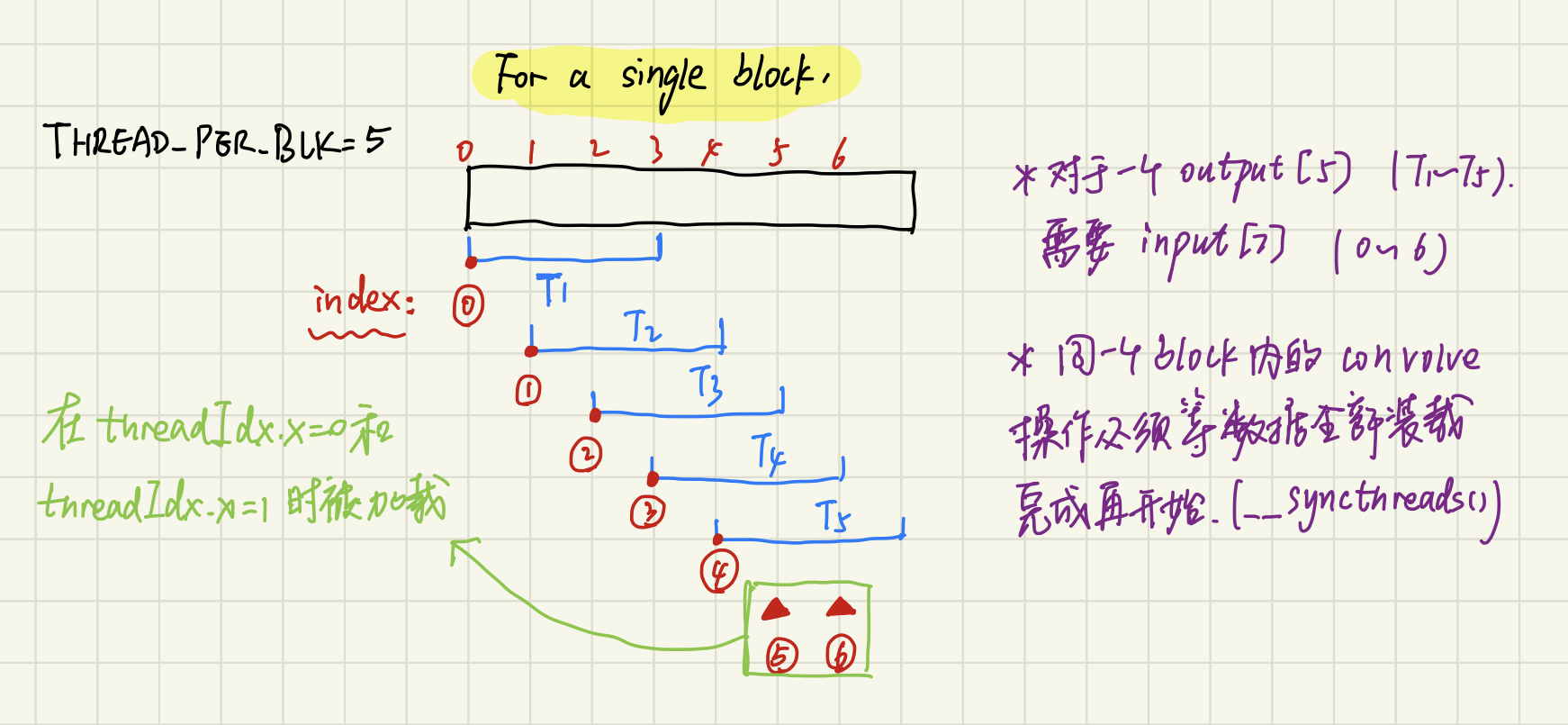
注意到这里在每个线程的起始都将global memory中的数据提前加载进block shared memory,此后该block中的所有数据都从这块共享内存中取出,进而将内存的加载次数减少为130次。
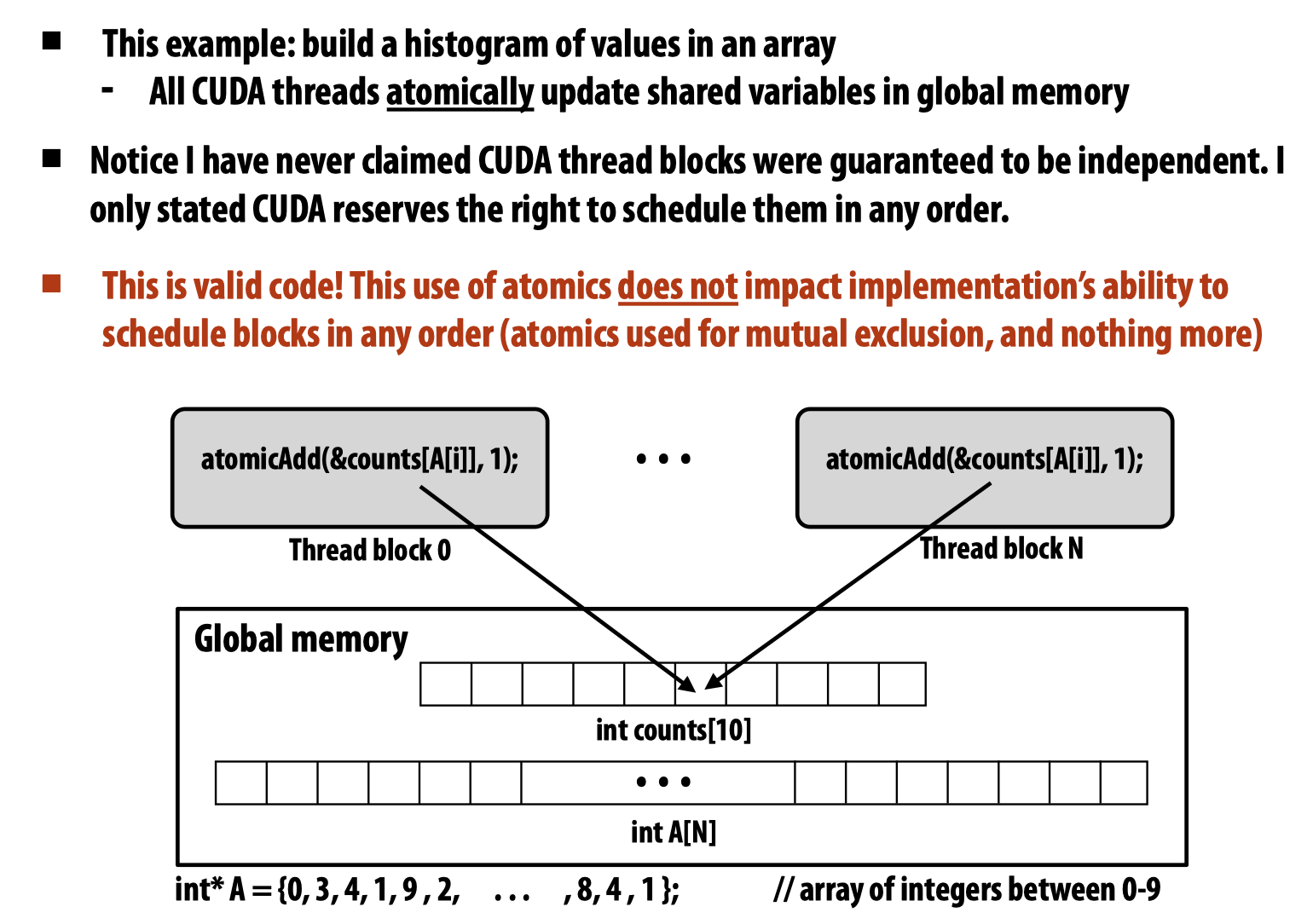
为了确保线程同步,使用了__syncthreads()方法,在CUDA中还有atomic操作可以使用,原子操作可以同时保证global memory以及shared memory的并发控制:
接下来思考的问题是上述代码的最后一行:
convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, devInput, devOutput);
当N的值特别大的时候,这可能会启动特别多的CUDA Threads,设想此时将每一个CUDA Threads理解成一个pthreads(当然这是不对的),那么这意味着程序会创建很多的局部变量以及线程栈,而根据上节课上教授给出的两种ISPC可能的执行任务方式的对比:
- 启动无数个线程来应对无数个任务
- 启动一个线程池并不停的将空闲的线程分配给未处理的任务
第二种方式的执行效率会明显优于第一种。
所以将CUDA Threads处理成类似pthreads显然不是一个明智的实现方式。于是,在上方代码启动了很多个threadblock后,GPU会将这些tasks不断的分配给片上的worker threads(也即第二种执行任务的方式):
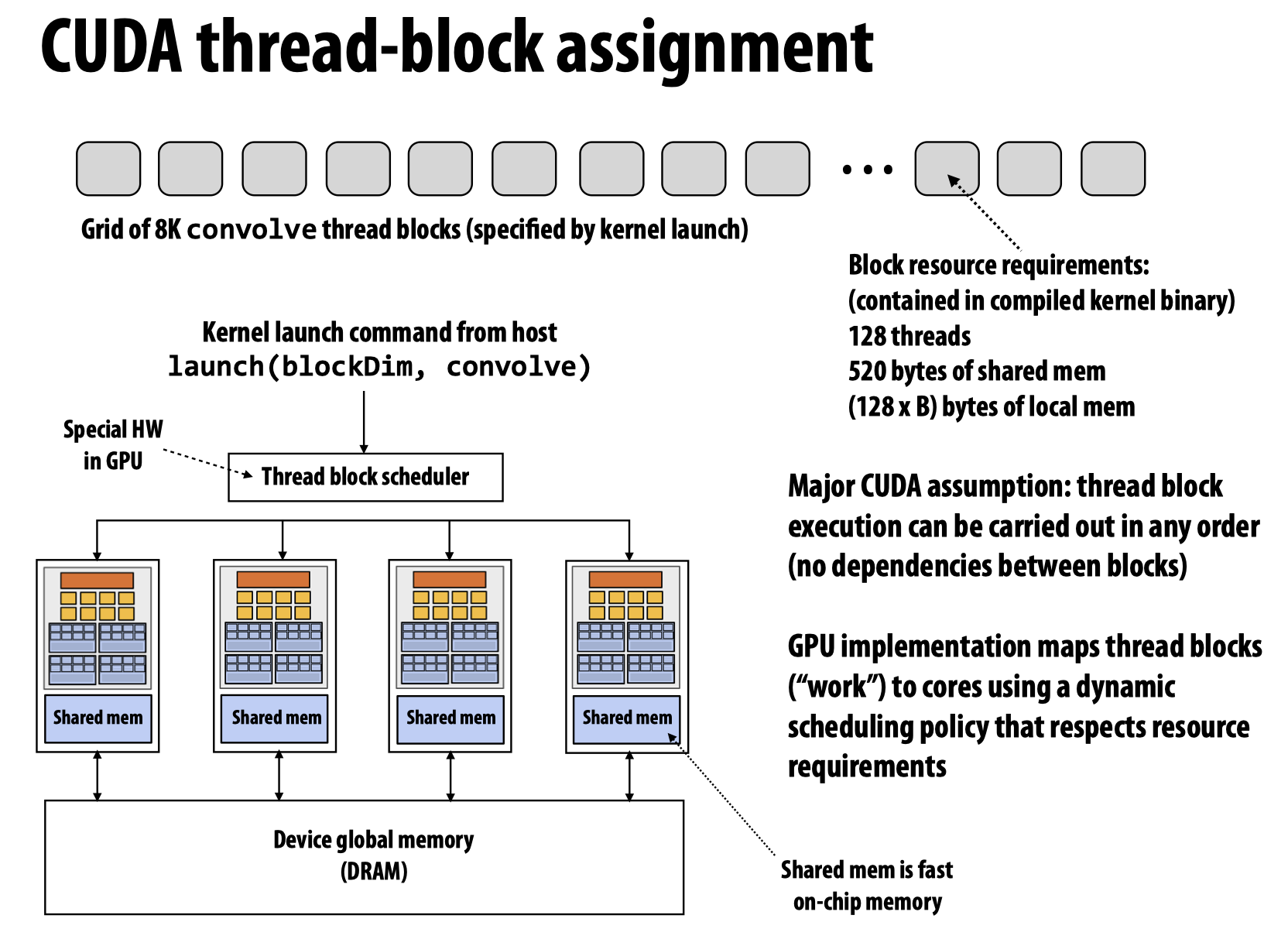
GPU Architecture
先来关注一个SMM core:

在前边的CPU章节有提到过,GPU中的warp就是常说的instruction stream,这里有两种理解方式:
- 按照先前的
SMT和superscalar,可以将每一个warp理解为SMT中的一个线程,在每一个线程中,又有superscalar的结构(Instruction Level Parallel) - 实际上,对于每一个
warp,其中都含有32个CUDA Threads,这32个CUDA线程被分配到右侧对应的32个SIMD lanes上,GPU中的SIMD执行单元和CPU上的类似,但是GPU中的向量宽度一般比CPU SIMD宽的多。

一个convolve block会被4个warp执行(所以总共有128个CUDA线程)。这里注意区分内核中含有的warp总数和支持同时运行(active)的warp数量,由于一个内核只支持同时运行四个warp,所以也只有4个32宽的SIMD Exec。
当前的GPU的基本结构就是包含了多个以上的内核:

GPU执行的两个特性
CUDA不保证block的任何执行顺序
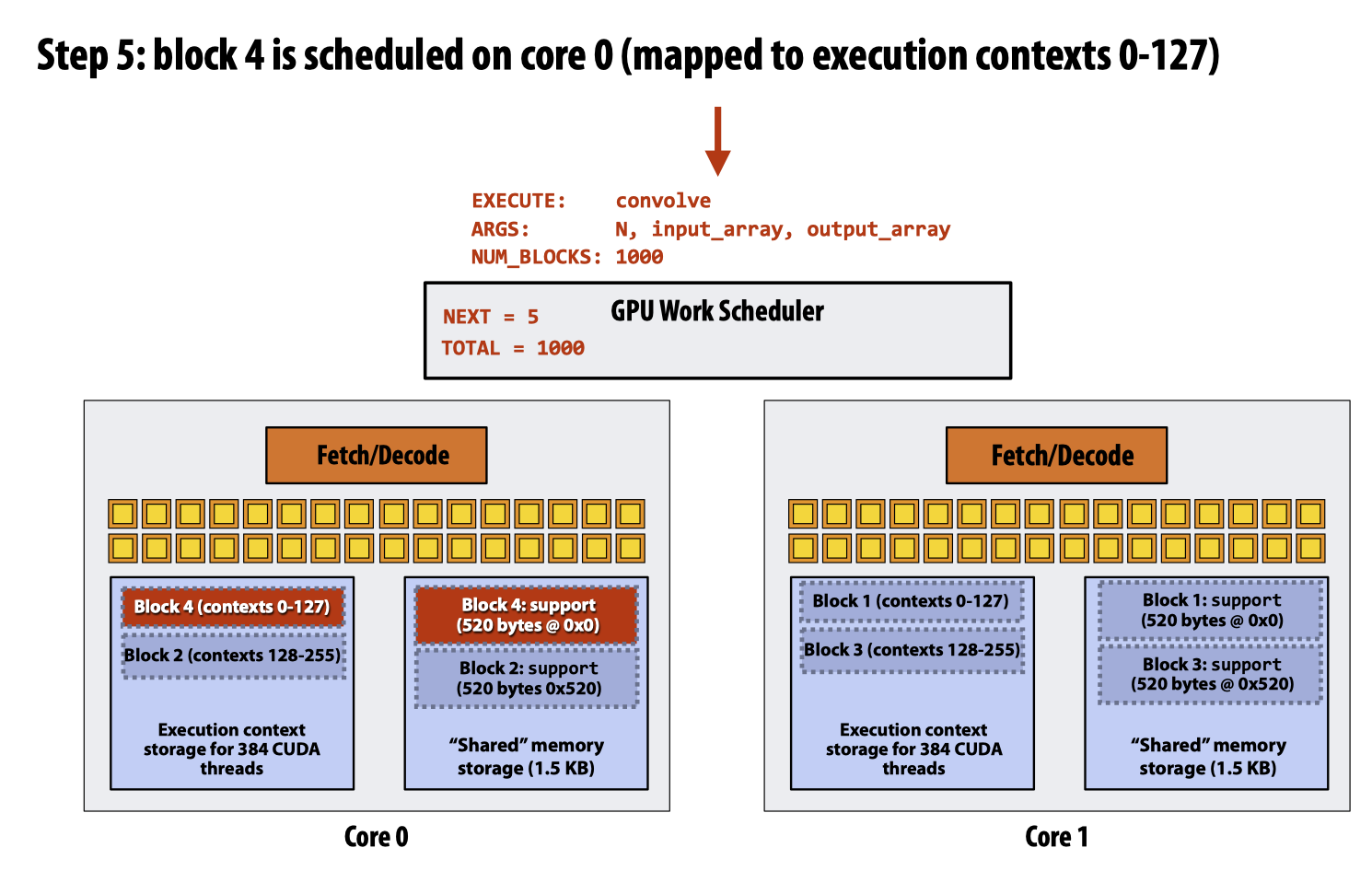
- GPU中不存在一个
block或者block中的线程执行了一半被stall转而让内核先执行其他任务的情况,只要一个block开始执行,就会执行到最后
根据这条性质,对于以下的结构和示例程序:
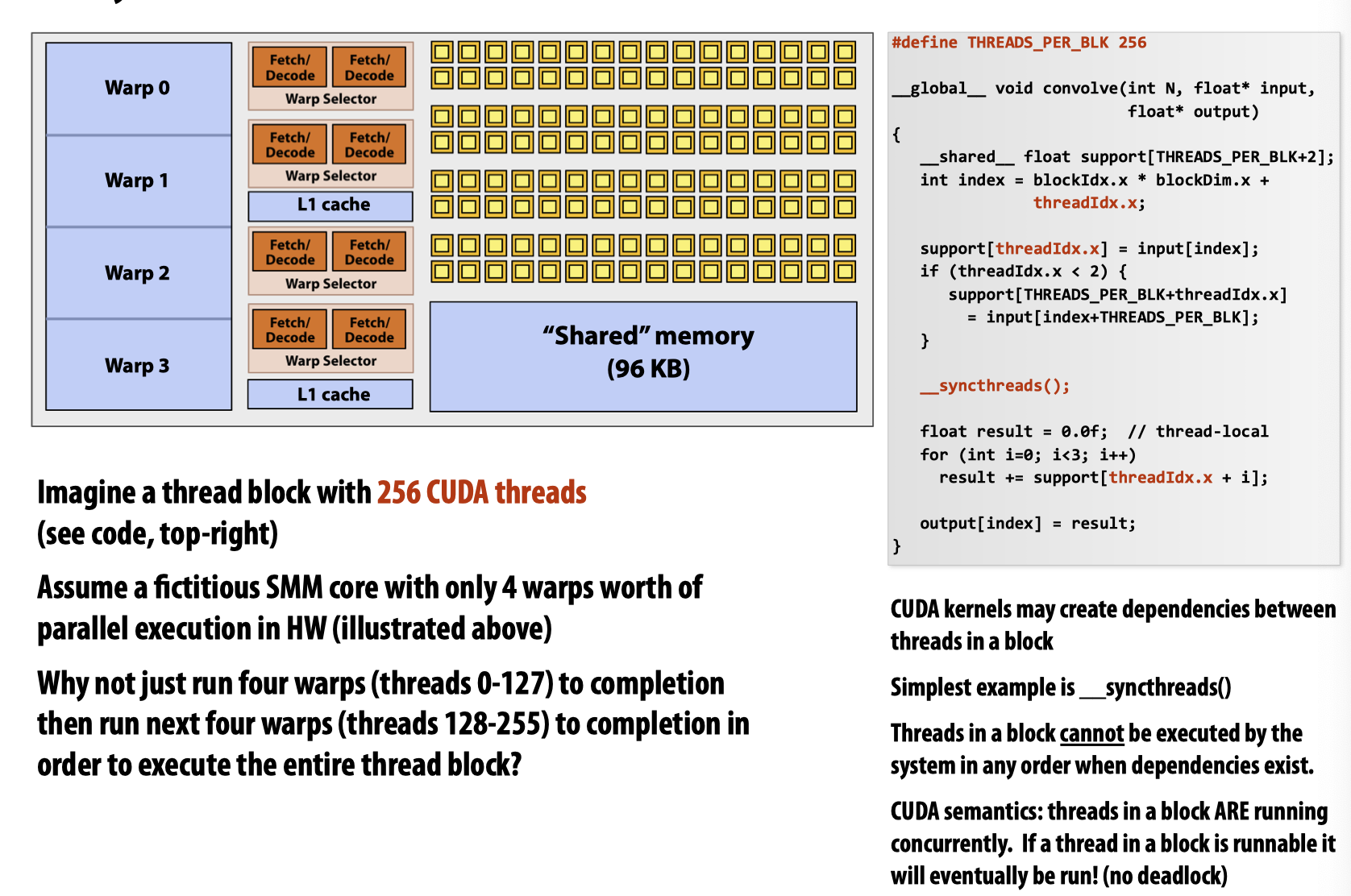
由于这里规定,一个block内需要分配256个线程,所以要想执行一个block,需要8个warp,但是根据左侧的图,一个核内只有4个warp,这意味着如果想要运行这份程序,就必须先让一个block内的128个线程先走,之后在他们运行结束之后让出内核,给到还未执行的128个线程。
而由于代码中有__syncthreads()的存在,这么做将会导致已经开始执行的线程一直处于等待状态,进而造成死锁!实际上,这份代码在该GPU架构上不会编译通过。
pthreads & CUDA threads
在最后,来解决一下教授在课件中提出的问题,pthreads和CUDA threads有什么区别?
pthreads是有自己的execution context的,但是CUDA threads并没有上下文这一概念,或者严格来说,他们的上下文存储在对应的warp中。pthreads一般具有独立的instruction stream,但是CUDA threads会在同一个warp内共享指令流。
CUDA Threads –> pthreads
这里讲的并不是两种方式实现上的转化,而是从不同角度出发理解方式的不同导致的代码范式的区别,来看下边这样一段代码:

先来分析一下这段代码什么意思,与先前的一位卷积代码又什么区别。
注意到宏定义中将BLOCK_PER_CHIP设置的值刚好是GTX 980能够处理(这么说并不严谨,一个SMM核心一次最多只能同时运行4个warp,这里的能够处理是考虑了所有的warp)的block数量(总共16个SMM核心,每个核心上有2048个SIMD执行单元,每一个block需要4个warp协助完成,每一个warp需要32个simd执行单元)
代码中的workcounter是一个CUDA device上的全局变量,所有block共享,用来记录当前卷积到了哪个位置。
在函数convolve内部,除了先前提到的support数组,这次多了一个startingIndex,对于每一个block,都只在它的threadIdx.x=0,即block内的第一个线程进入新的一轮迭代时递增workcounter(其实这里应该使用atomicAdd函数)THREAD_PER_BLK,然后返回workcounter的旧值到stratingIndex。这样一来,如果监测到startingIndex大于等于需要处理的总数N,意味着所有的格子都被处理完成,那就说明应该break了。
下边的代码逻辑和先前的一样,先把global memory中存储的数值转移到只针对该block的shared memory上,之后再逐个处理计算。
接下来解释这份代码中的两个问题:
- 三次
syncthreads的作用分别是什么?
从上往下,第一次线程同步是为了避免同一个block中除了第一个线程的其他线程先进入了接下来的计算环节,但是此时第一个线程发现计算过程实际已经结束,不需要继续更新,所以需要让其他线程等待这第一个线程更新完毕。
第二次线程同步是为了等待所有线程更新好support数组中的值,避免有些线程已经开始计算但是要计算的位置的support数组上的值还没有被填充。
第三次线程同步的作用我不是很确定,但个人猜测应该是为了提升并行效率为非保证正确性的,通过在最后添加线程同步代码,延缓该block中线程的更新频率,确保同一个block不会太久的霸占计算资源而导致其他block中的线程无事可做。
- 为什么要用
while循环在这里?
这就是教授想通过这份代码来传递的信息。通过while循环的形式,哪些线程应该计算哪些位置不再是由程序员通过将N分为与单元线程数量匹配的大小而确定的了,而是由类似pthreads的计算资源分配过程,即由系统自身决定的。
Lecture 6: Performance Optimization I: Work Distribution and Scheduling
Static Assignment & Dynamic Assignment
在将work/task分配到workers上时,有两种分配方式,在前边提到过:static assignment和dynamic assignment,这节课中更加详细的讨论了这两种分配方式。
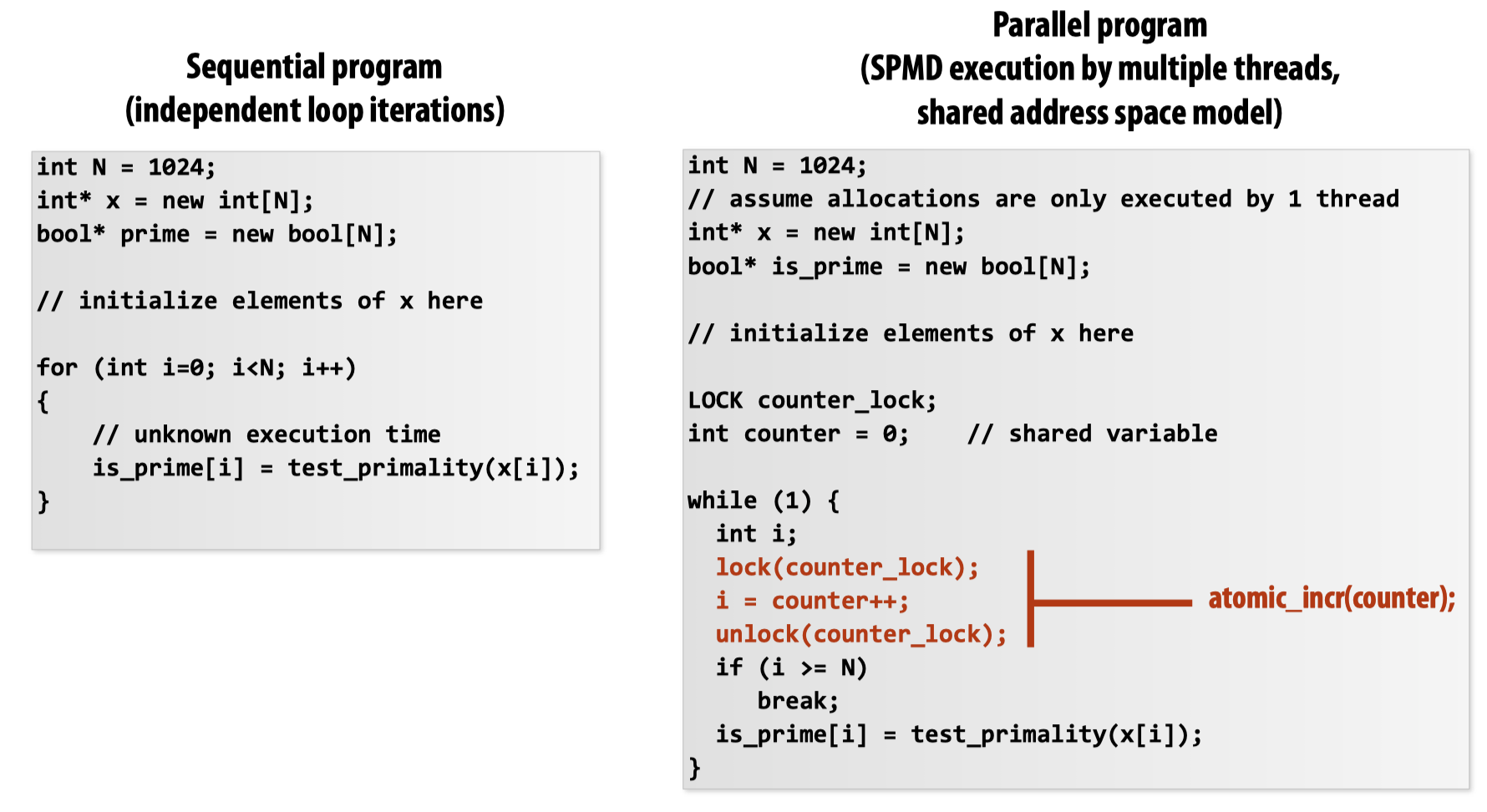
静态分配可以回想之前举过的solver例子:

静态分配一般在我们明确知道工作的执行时间和工作数量可以被预测时使用。而动态分配则是让程序在运行期间决定负载分配,比如如下的这个例子:
这个例子中的一个问题是锁的开销太高,我们可以通过增加任务粒度(task granularity)的方法来增加并行时间:

Choosing task size
在先前的ISPC章节也提到过,一般分配比处理器数量更多的任务可以更好的保证负载均衡。但是我们不能分配过多的任务,这会导致上下文切换的开销过大。
task scheduling
先来考虑这样一个场景:
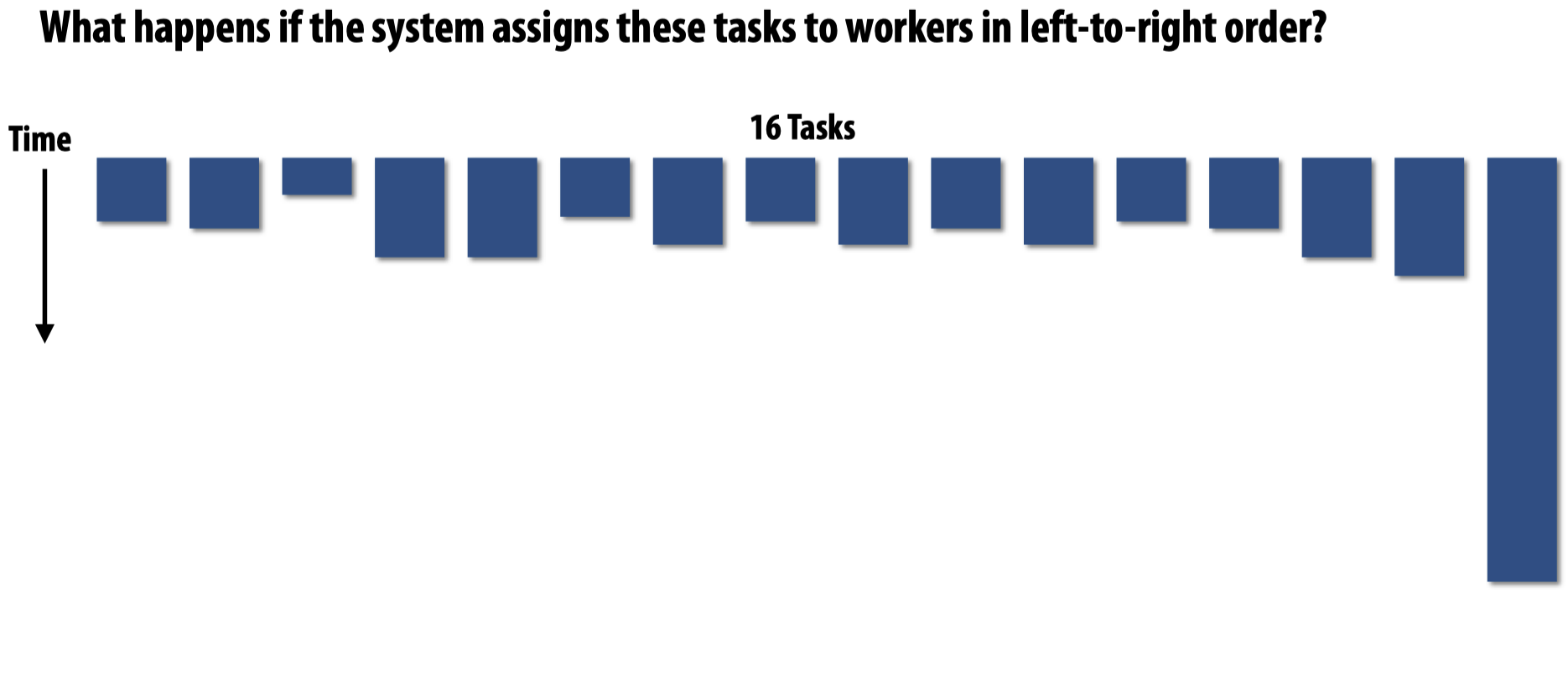
如果将需要运行时间最长的任务当到最后执行,会发生什么?
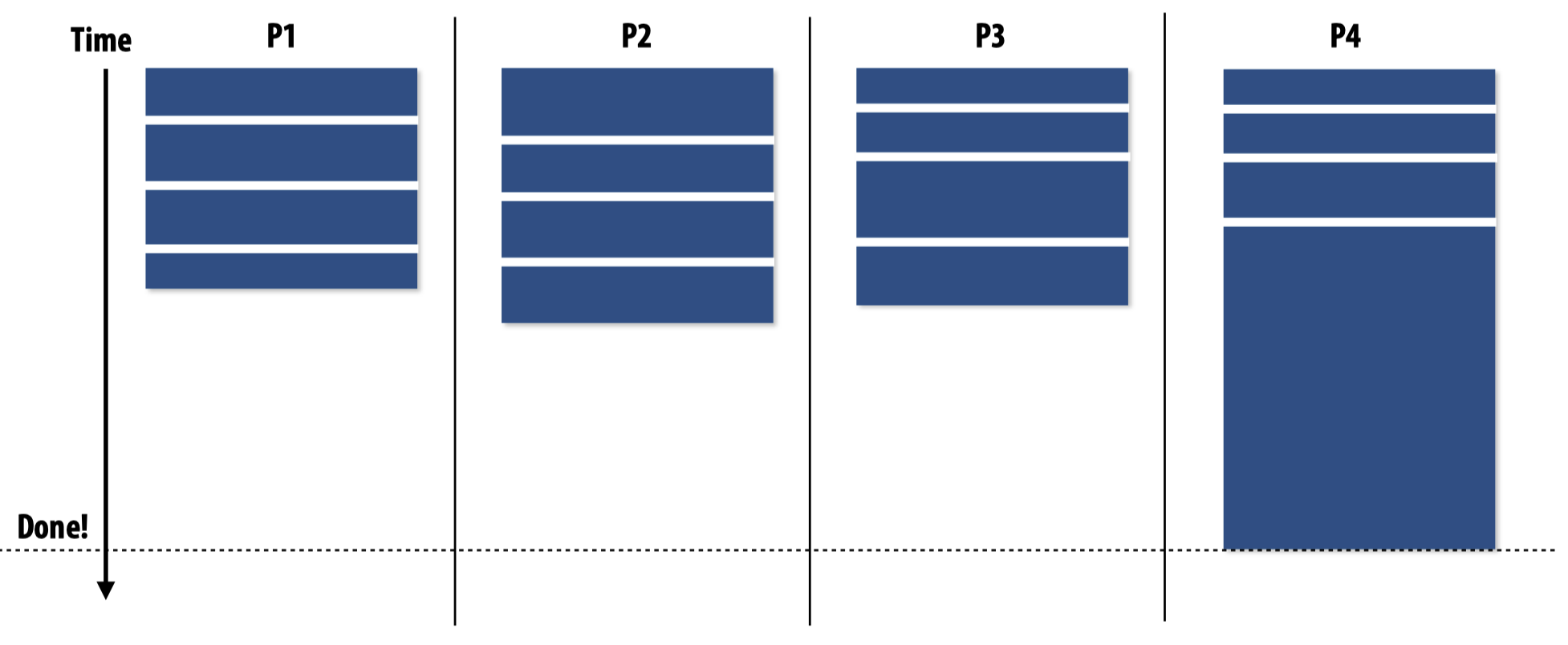
解决这个问题的一个可能办法是将任务划分成更小的子模块。或者还有一种办法,在进行task scheduling时,先运行这个需要较长时间的任务,这样一来别的worker就会自动被分配上其他任务,从而避免在其他所有任务都被执行完之后,某一个worker还需要较长的时间执行这个单独的大任务:
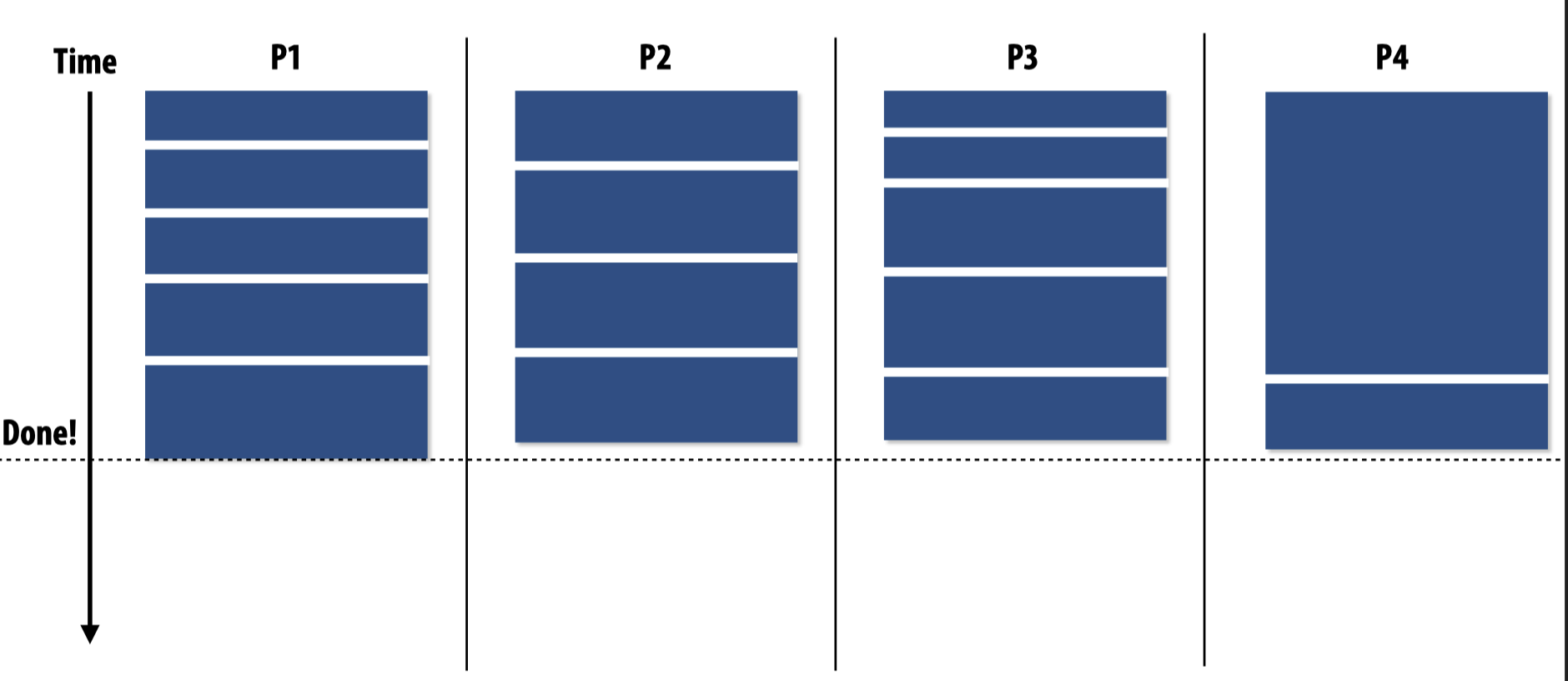
但毫无疑问的是,这种处理方法需要编程人员对workload有一定的知晓。
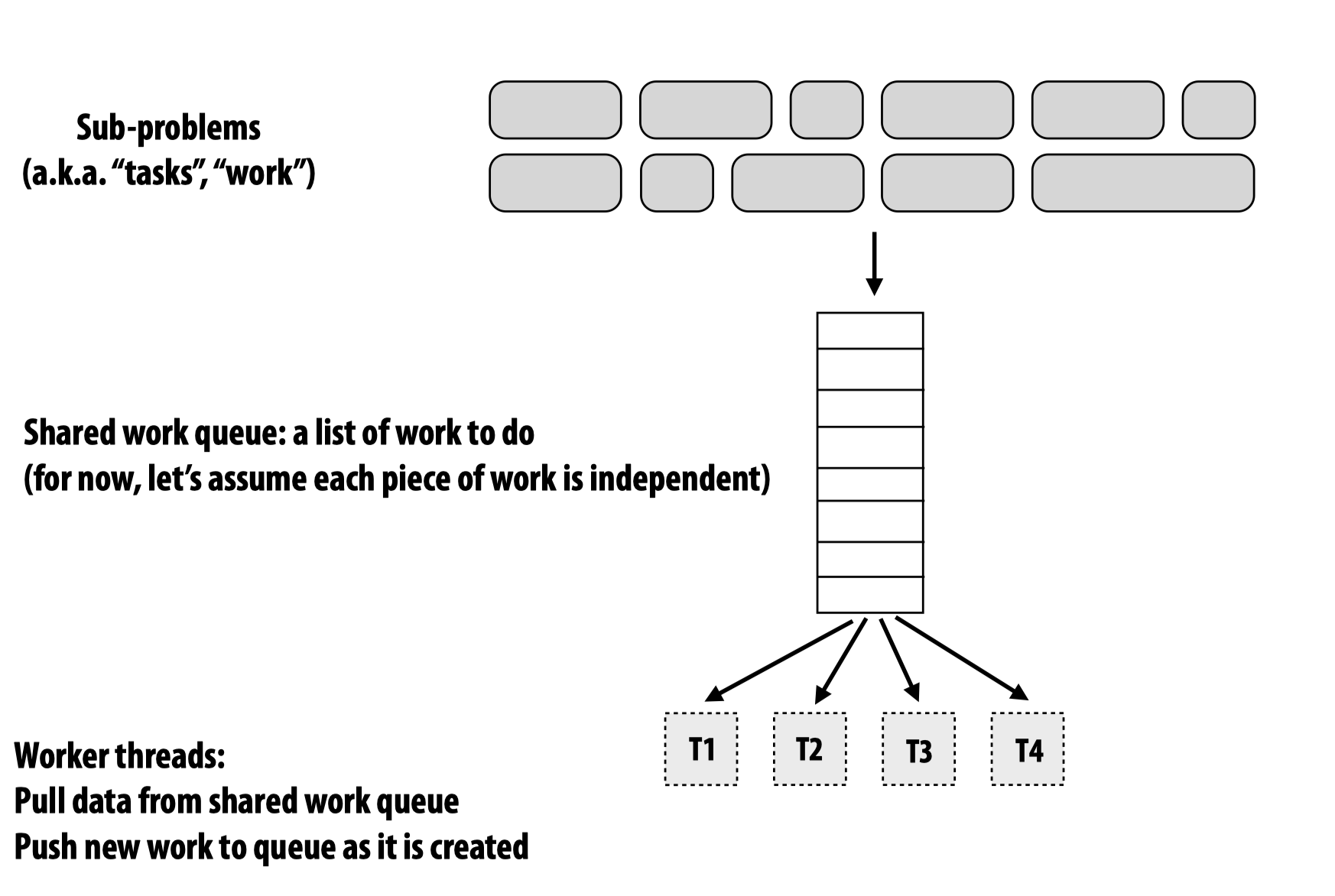
工作队列(work queue)
在对任务进行动态分配时,常用工作队列来进行任务分配:
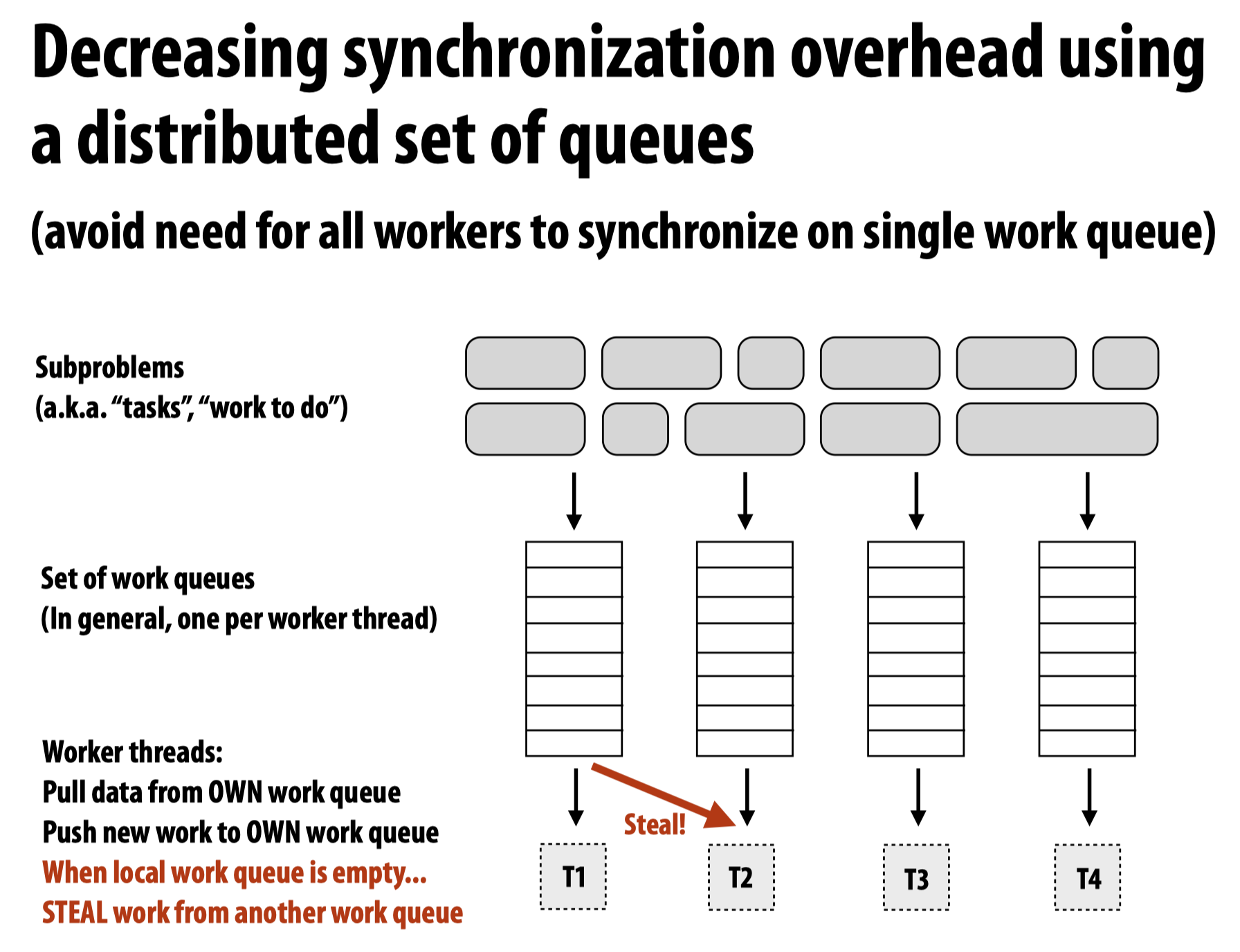
而一个更聪明的工作队列分配策略是,使用多个工作队列,当一个工作队列空,而另一个工作队列中含有未运行的任务时,就进行steal:
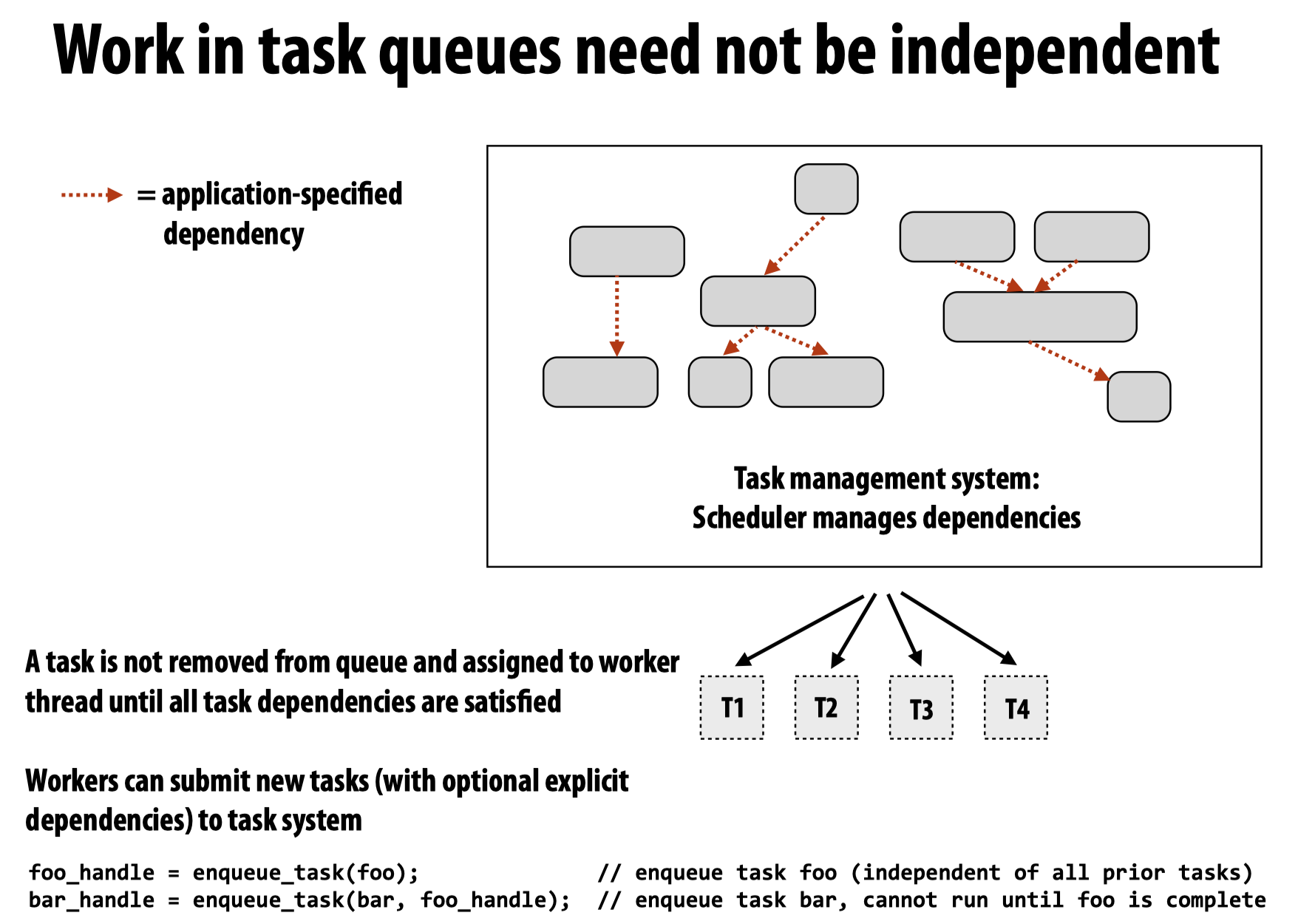
需要注意的是,工作队列中的任务并不一定要求是完全独立的,我们可以在代码中设置,让任务A只能在任务B执行完成后才运行:
Scheduling fork-join parallelism
目前为止,我们已经接触到以下几种并行编程范式:
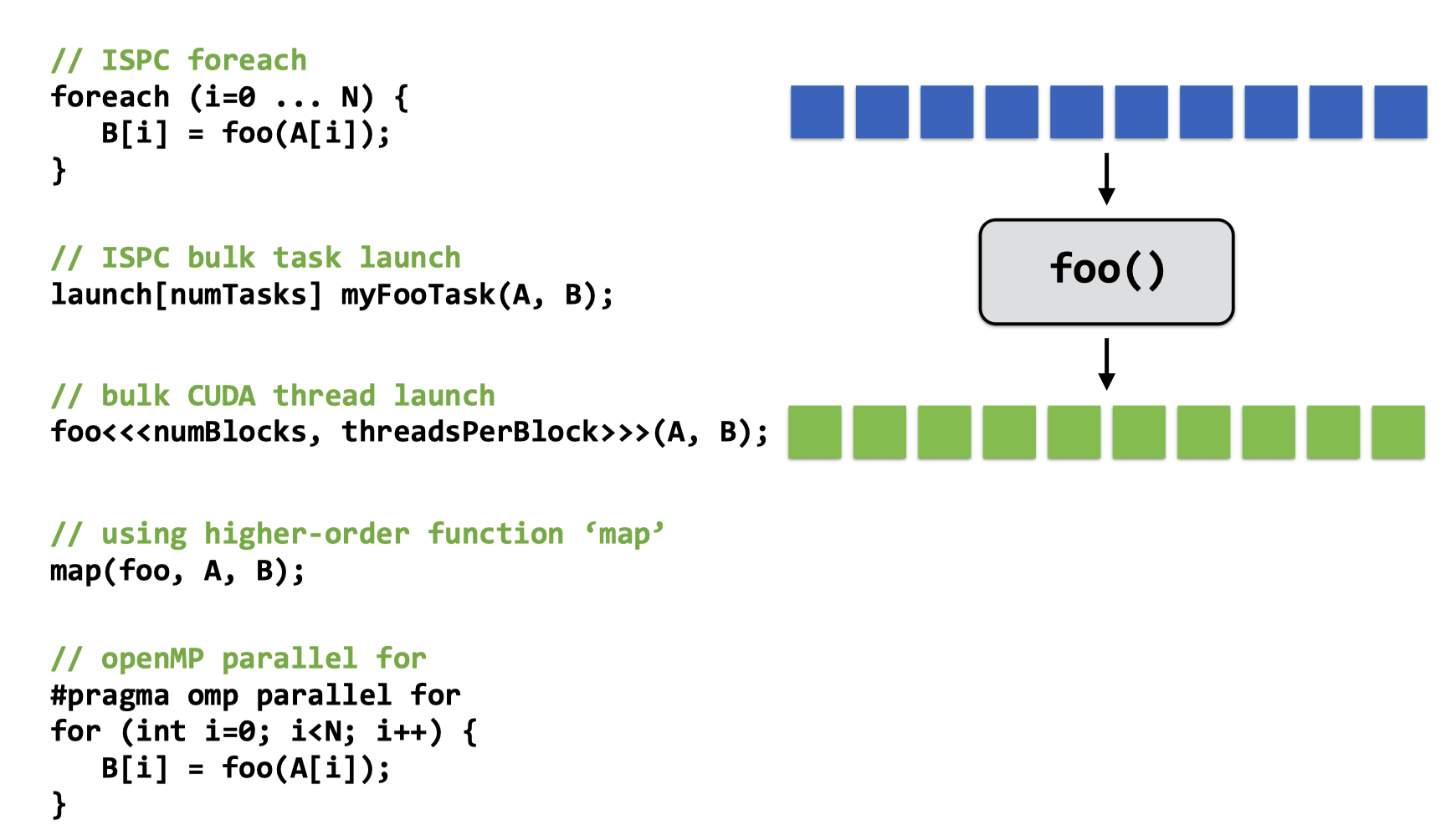
下边来考虑fork-join范式在分治(divide-and-conquer)算法中的应用。
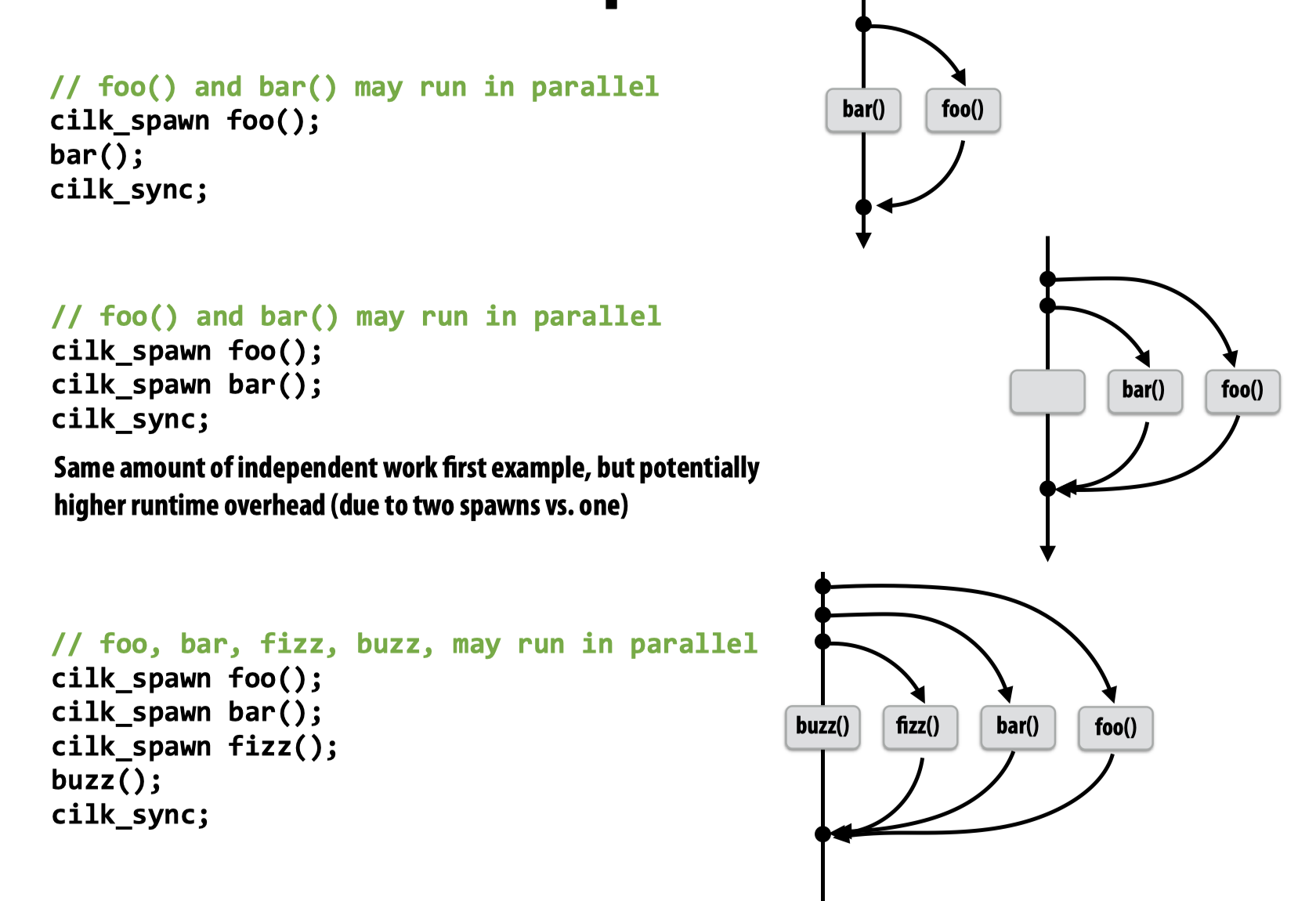
为了方便讨论,这里使用Cilk Plus并行代码,这是一种C++的语言扩展,可以通过使用如下的语句来实现fork-join:
cilk_spawn foo(args); // fork (create new logical thread of control), may (NOT must) continue executing asynchronously with execution of foo.
cilk_sync; // join, returns when all calls spawned by current function have completed
在每一个cilk_spawn函数结尾,都有一个隐式的cilk_sync,表示当前函数返回时,所有与该函数相关的工作都结束了。
可以用下图表示cilk plus的工作机制:
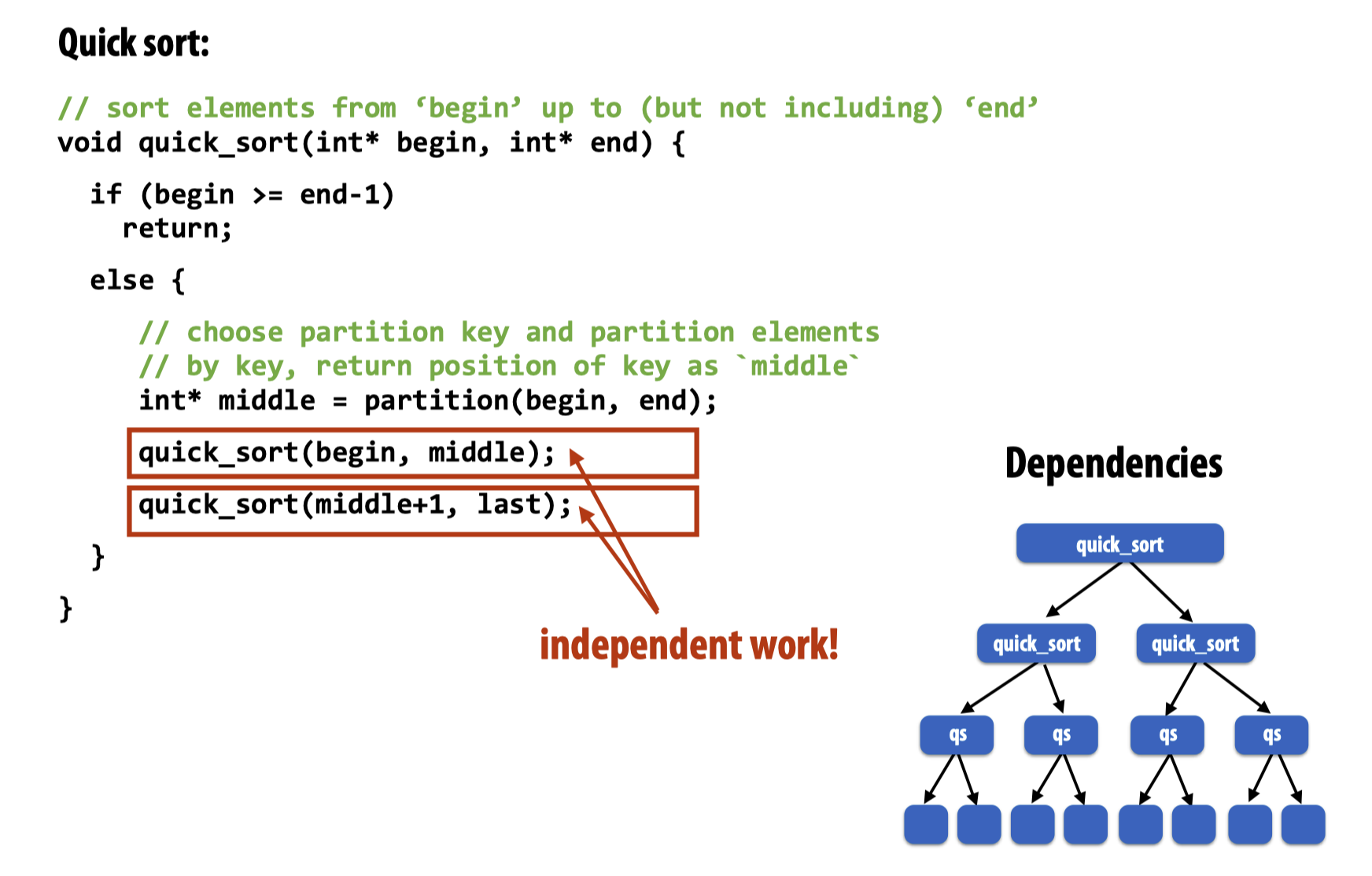
于是可以利用Cilk Plus来并行快速排序代码:
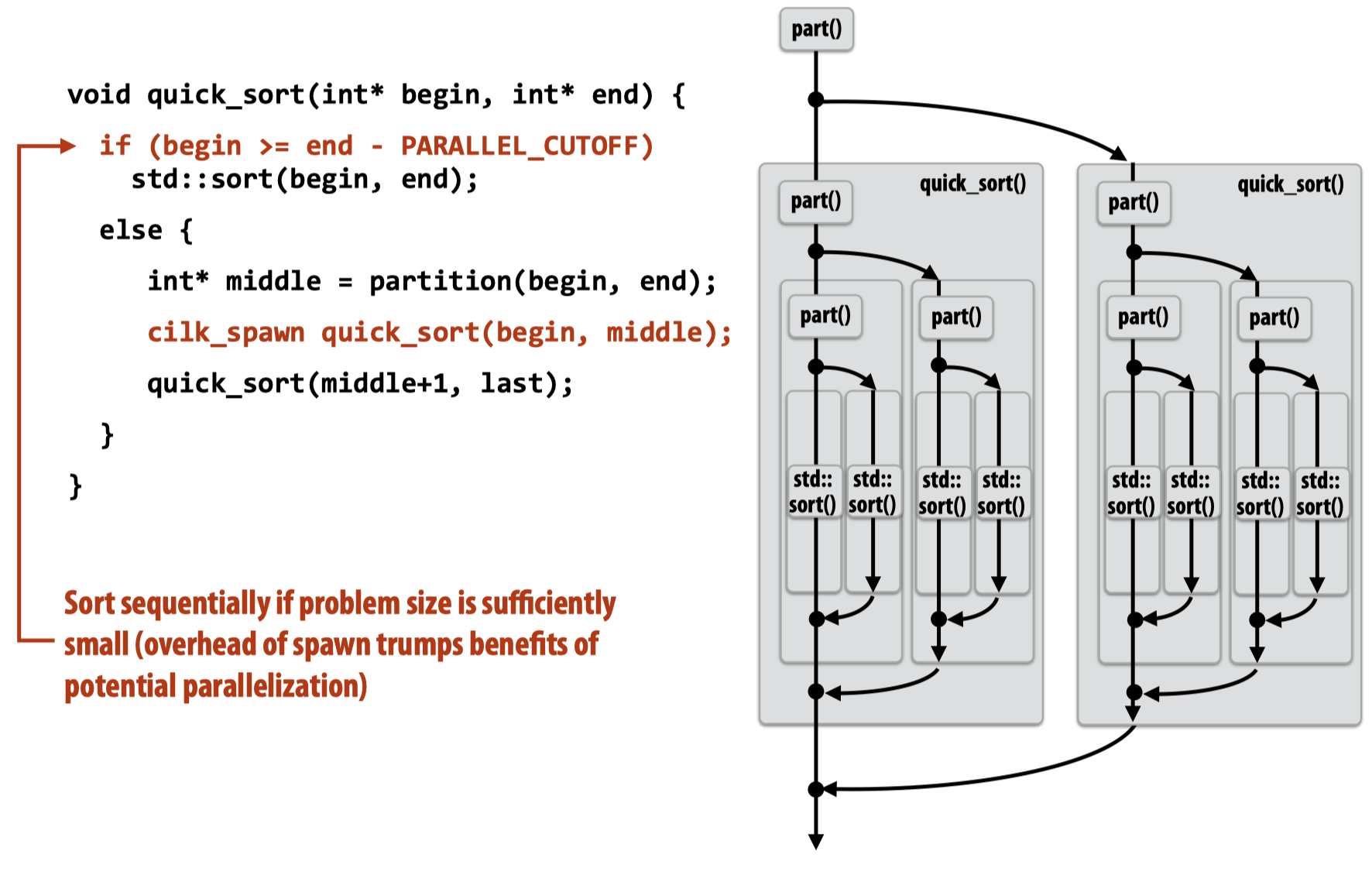
与先前讨论的各种并行工具使用的模式一样,Cilk Plus也会维护一个线程池(Pool of worker threads),并不断的将新的任务分配到空闲的线程上。
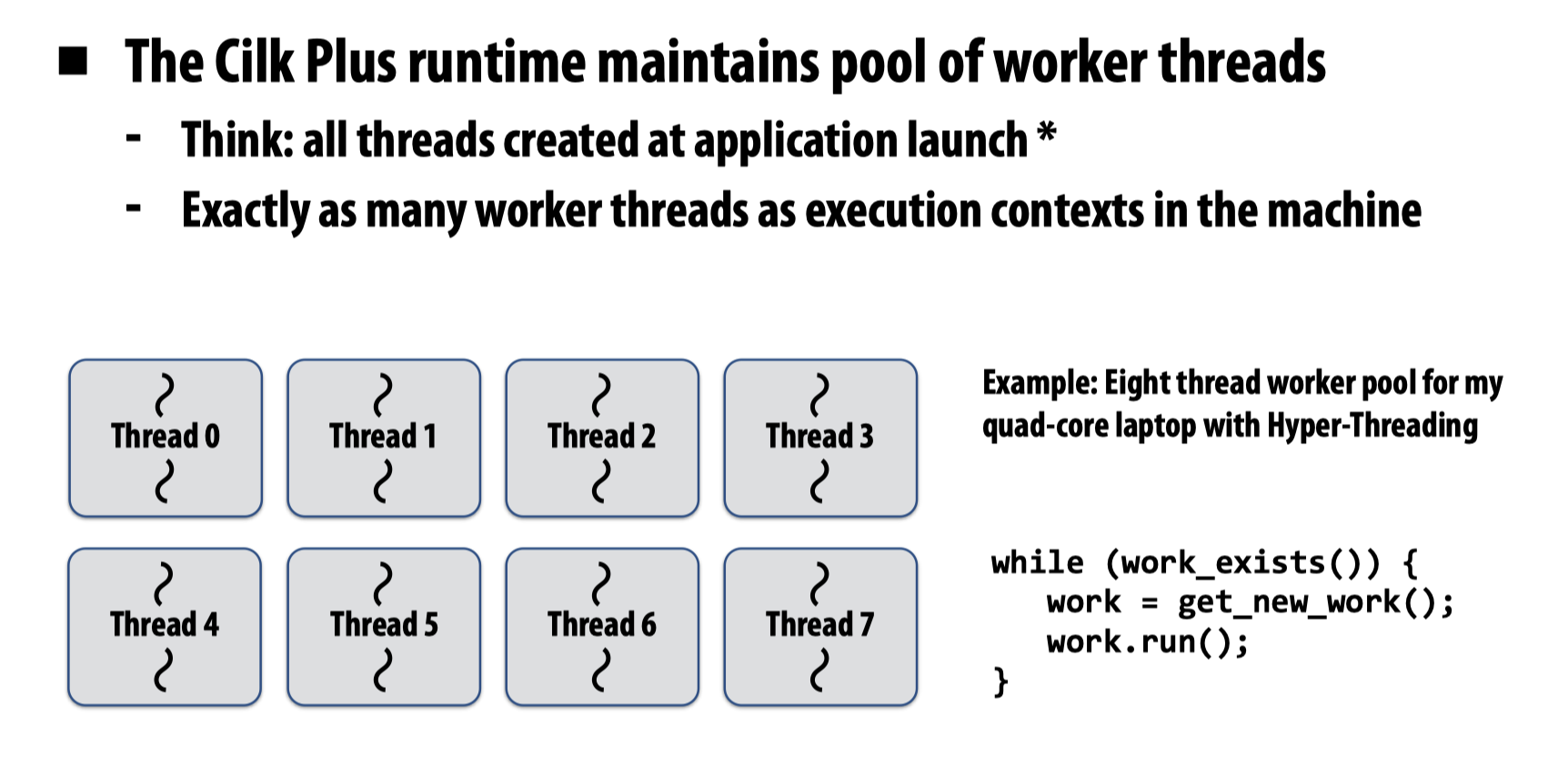
一个比较简单的想法是在程序启动时,就会预先创建这么多的线程,再将后来的一个个任务分配上去,但实际上,工作线程的创建是懒惰的,他会在遇到第一个cilk_spawn时初始化工作线程,这是一个经常被使用的实现策略,ISPC也是利用了相同的方法。
下边来考虑这样一个问题,如果现在cilk_spawn之后,有两个工作线程可以使用,那么应该使用什么样的策略来执行spawned child和continuation(rest of calling function)?
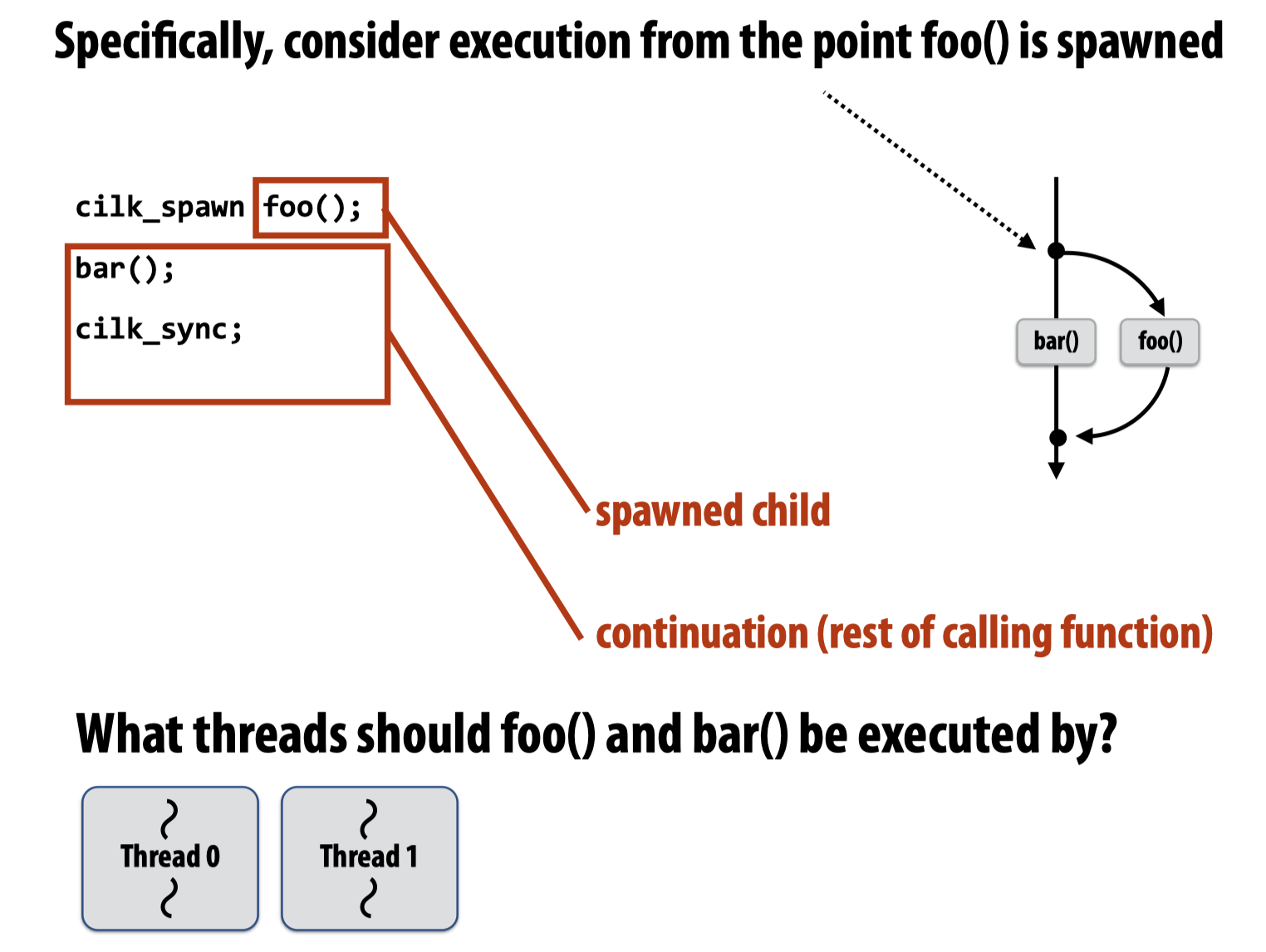
显然最好能够确保两个工作线程都不空闲,而起初的工作都是在主线程上被分配的,新创建的其他工作线程是空闲的状态,所有我们应该考虑这些空闲的工作线程能够把当前主线程分配了但是还没有开始执行的工作放到(steal)自己的工作队列中然后执行呢?
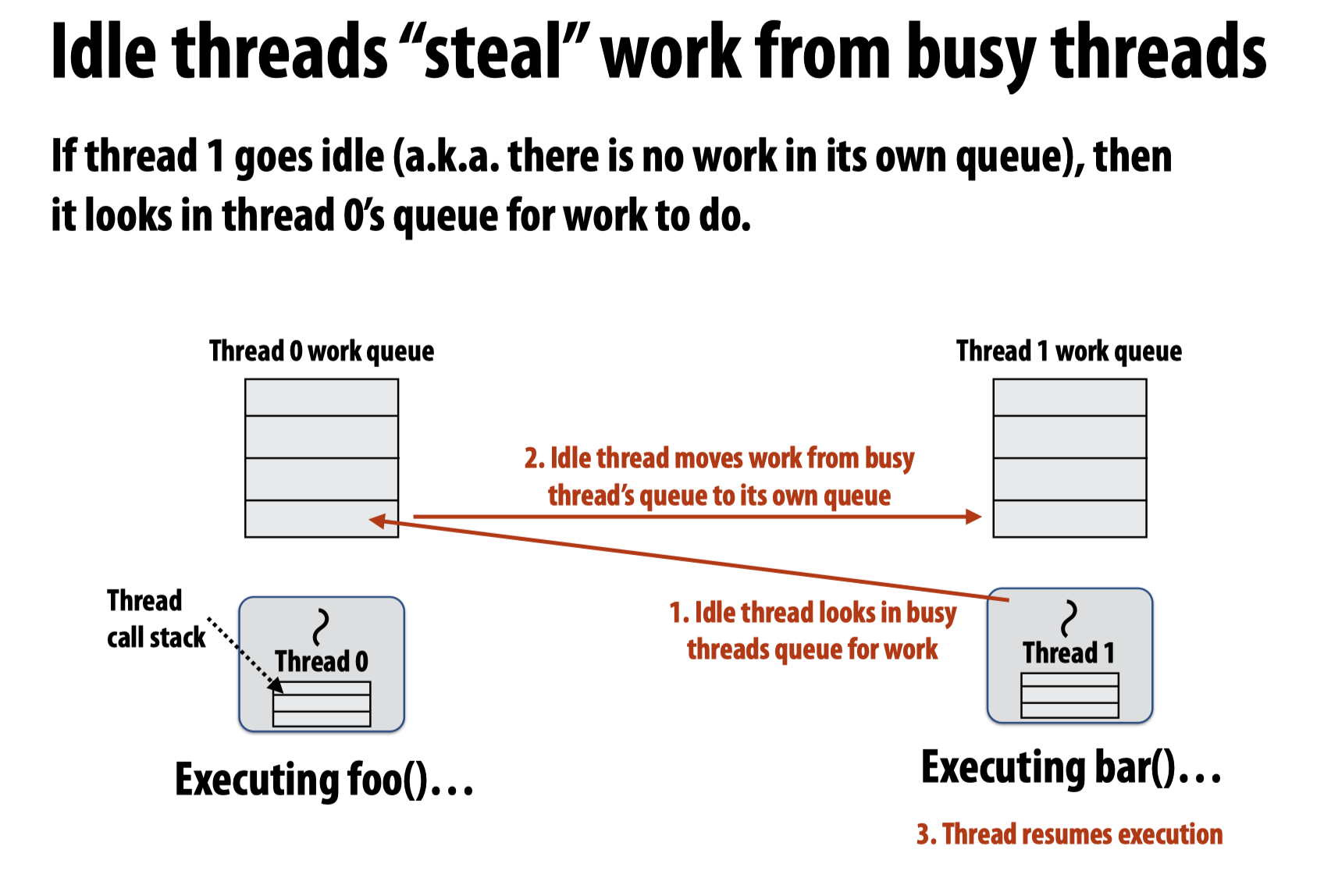
于是,就有两种相应的steal策略:
- Run continuation first: record child for later execution – child is made available for stealing by other threads (
child stealing) - Run child first: record continuation for later execution – continuation is made available for stealing by other threads (
continuation stealing)
下边,来考虑这两种fork策略哪一种更优。
fork-Continuation first

如果选择continuation first,那么程序会先生成所有的foo实例后,再执行。这个过程有点类似于BFS。如果不存在stealing的过程,那么执行顺序显然和没有并行时完全不同。
如果我们将该过程代入快速排序代码中,则会是如下的情景:
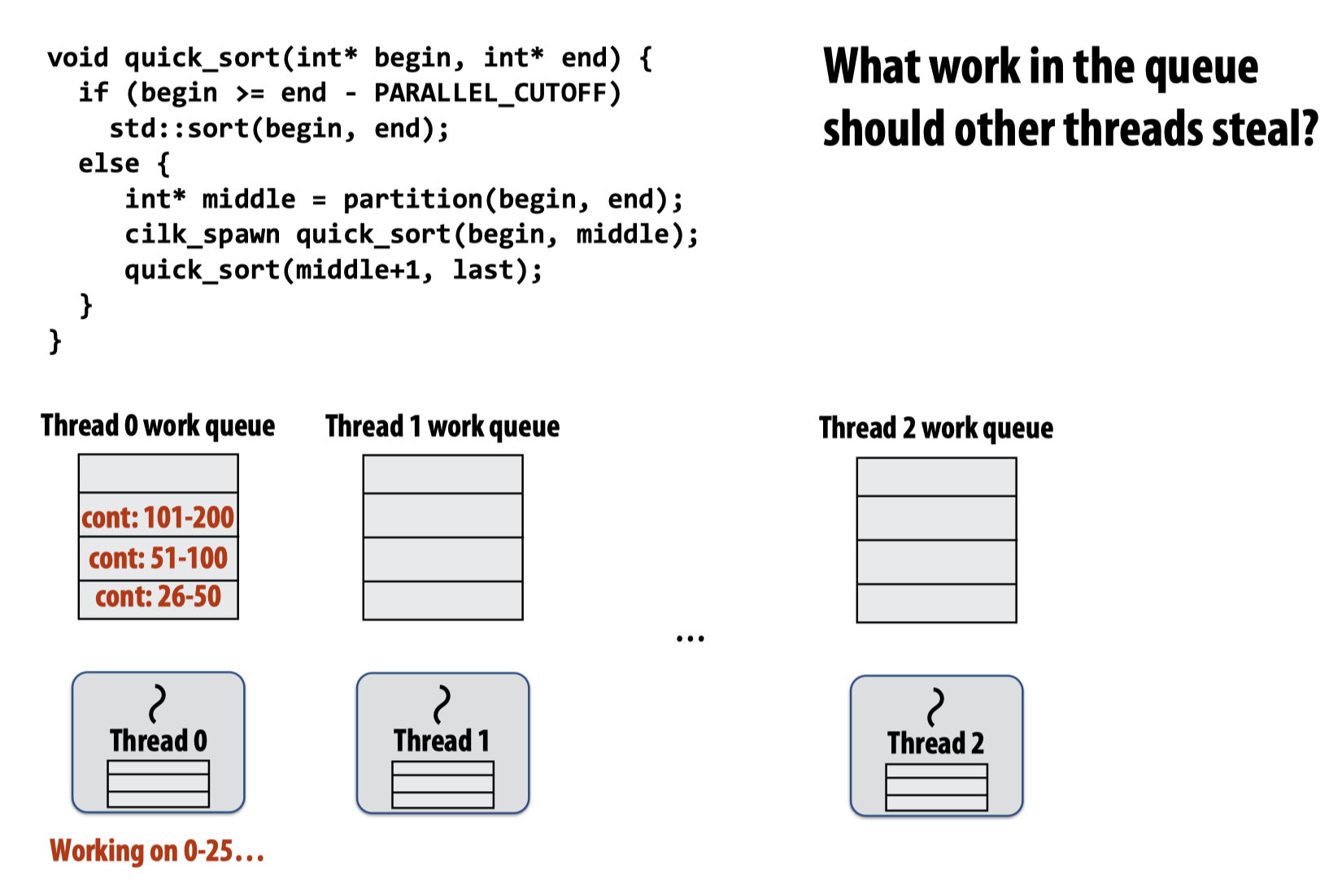
现在的问题是,其他工作线程应该选取主线程工作队列里的哪一个偷取?
这里直接放结论:应该自顶向下偷取,如图所示:
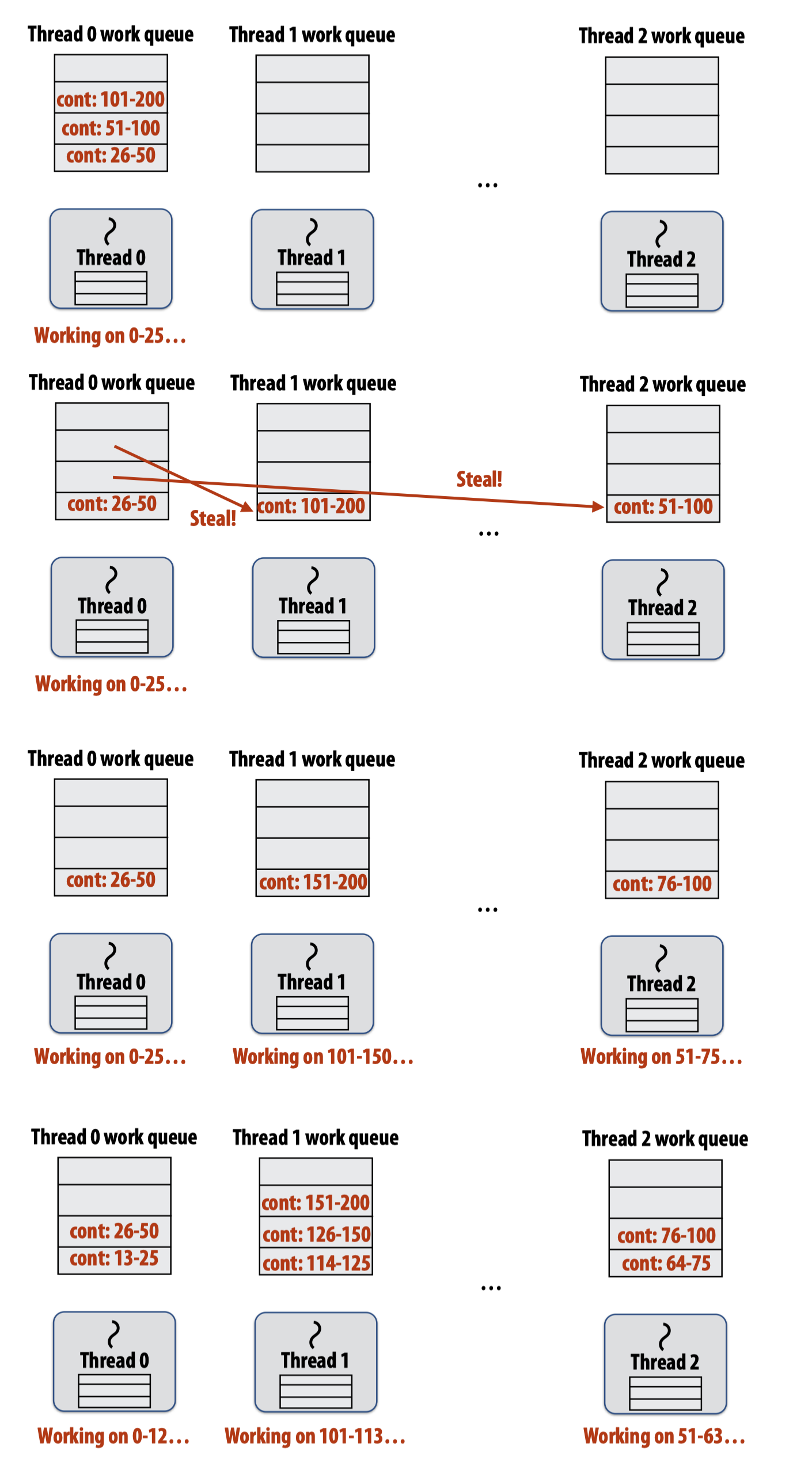
也就是说,工作队列的实现应该满足底部顶部均可出队,所以是一个双端队列(dequeue)。而其他工作线程从顶部偷取的好处有:
- Steals largest amount of work (reduce number of steals)
- Maximum locality in work each thread performs
- Stealing thread and local thread don’t contend for same elements of dequeue (efficient lock-free implementations of dequeue exist)
fork-Child first

如果主线程选择先执行child,那么其他工作线程就可以偷取continuation的部分,接下来continuation的过程就会在偷取的工作线程中发生:
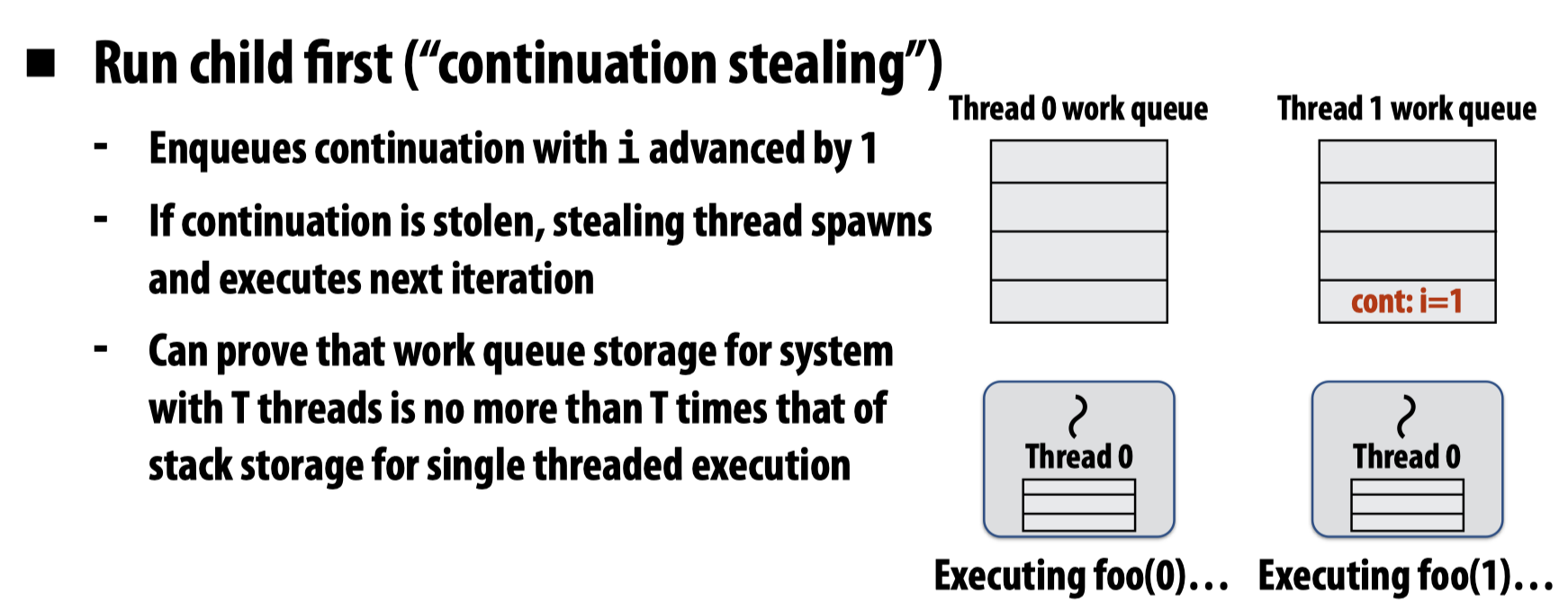
这个过程有点类似于DFS,并且相比于continuation first的执行过程,child first需要更少的存储空间。当我们将该范式应用到快速排序上时,就会发现它可以并行生成所有工作,这样一来就可以更快速的填充空闲的工作线程,所以要优于continuation first的处理方式。

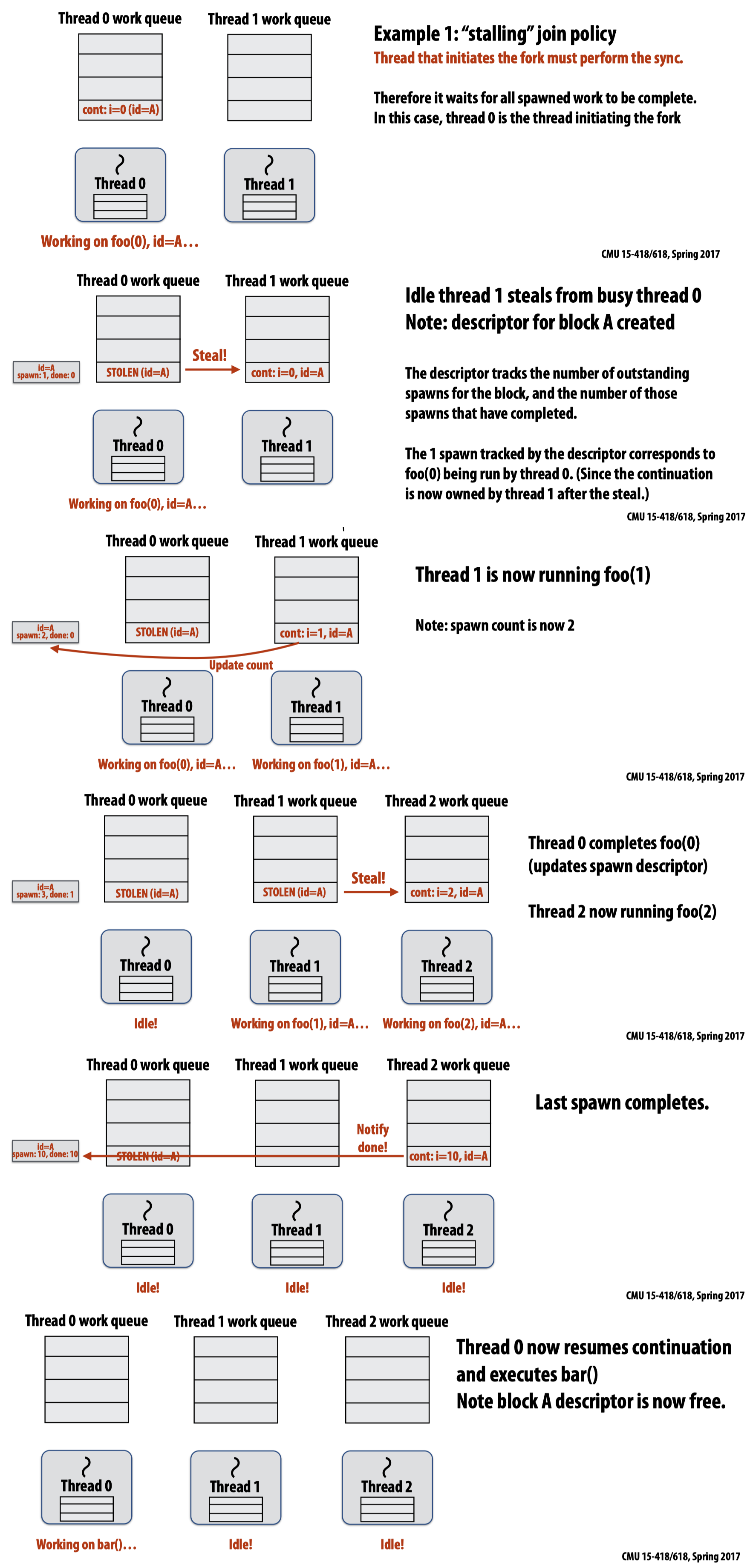
sync
- 假如没有工作被其他工作线程偷取,那么
sync不需要额外操作,即no-op. - 如果采用的是非
greedy式的fork方法,则初始化fork的那个线程应当维护sync:也就是说它需要等待其余所有生成的工作完成:
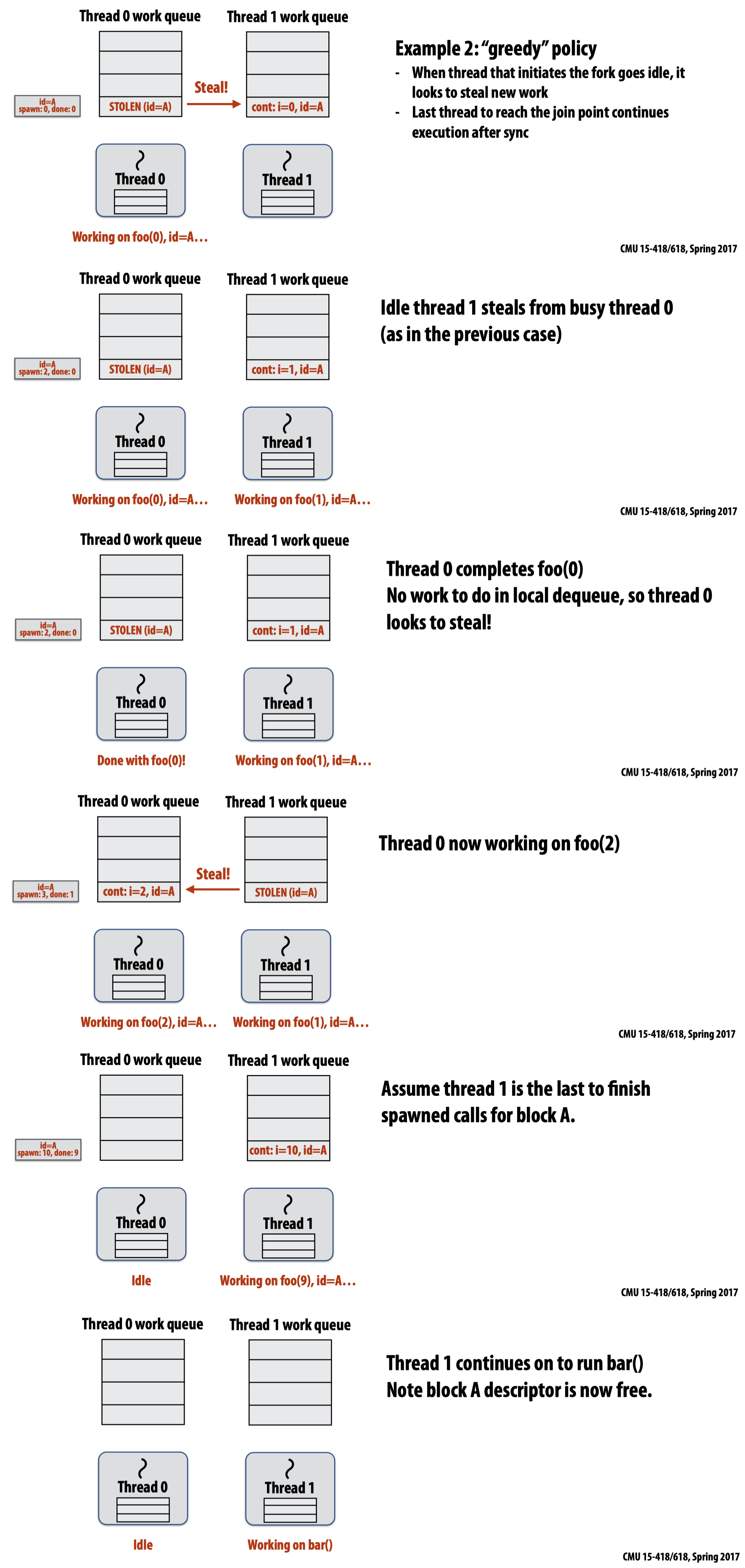
- 如果采用的是
greedy fork policy,即当初始化fork的工作线程空闲时,它也开始想要偷取其他工作线程队列中的工作。在这种模式下,最后一个达到join point的工作线程会继续执行sync之后的工作:
Lecture 7: Performance Optimization Part II: Locality, Communication, and Contention
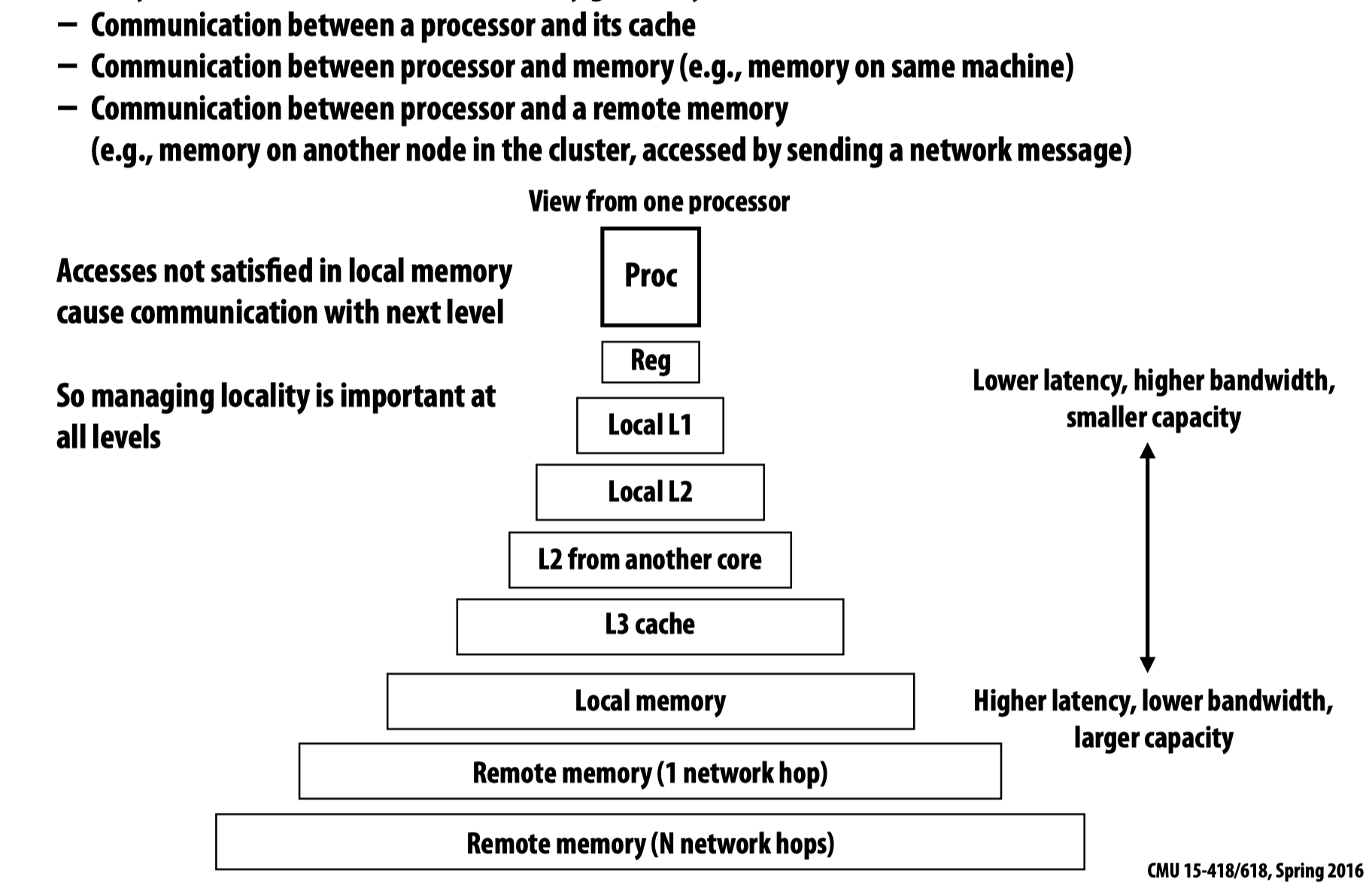
Message passing solver
在并行系统中,communication是一个绕不开的主题。对于先前的grid-based solver的例子:
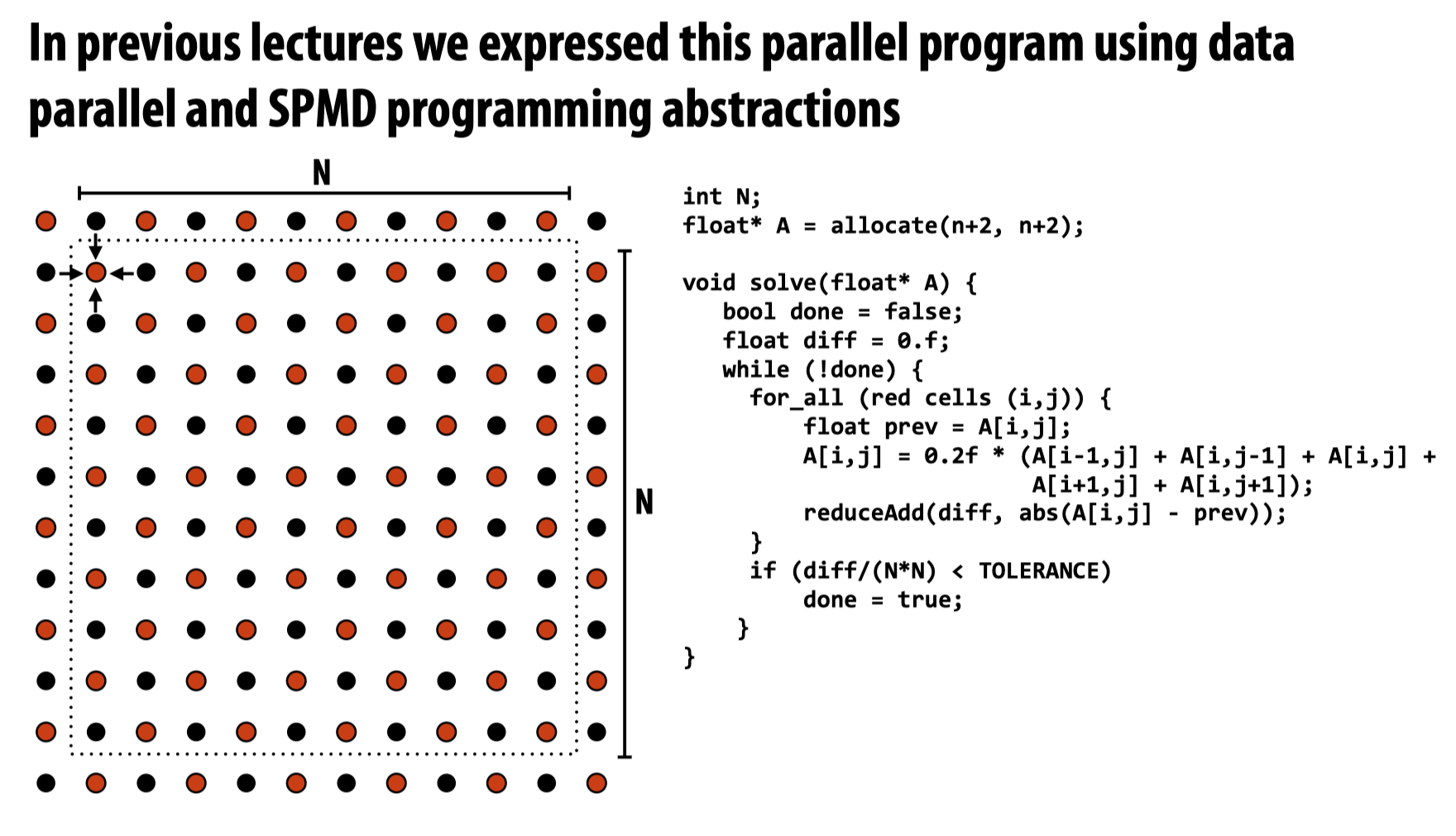
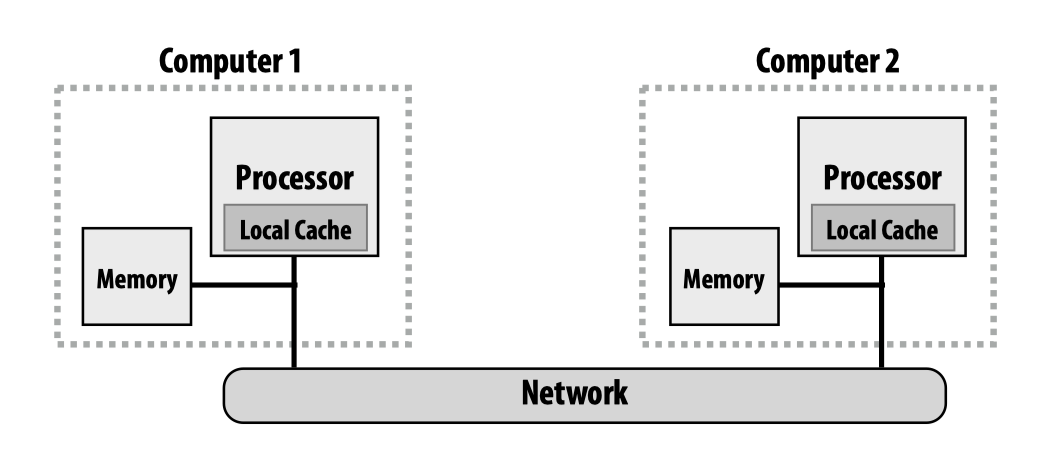
当试图利用communication模型实现这一任务时,可能会使用的一种消息传递的配置如下图所示,我们需要在独立的处理器的内存之间进行消息传送。
如果当前有四个线程,则将整个方形区块分成四个部分,每一个区块的第一行和最后一行需要将各自的值传送到临近区块:
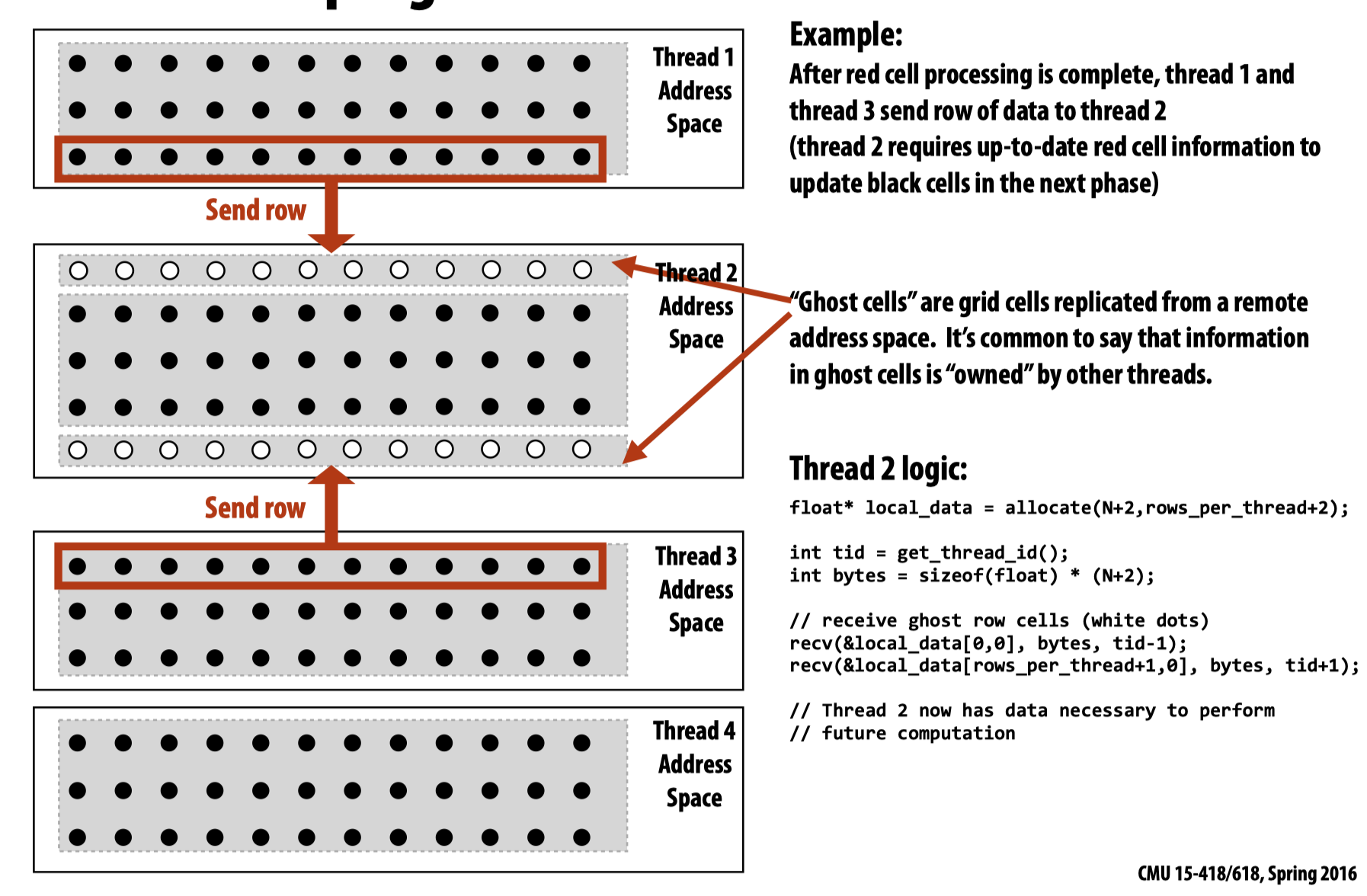
回到代码层面:
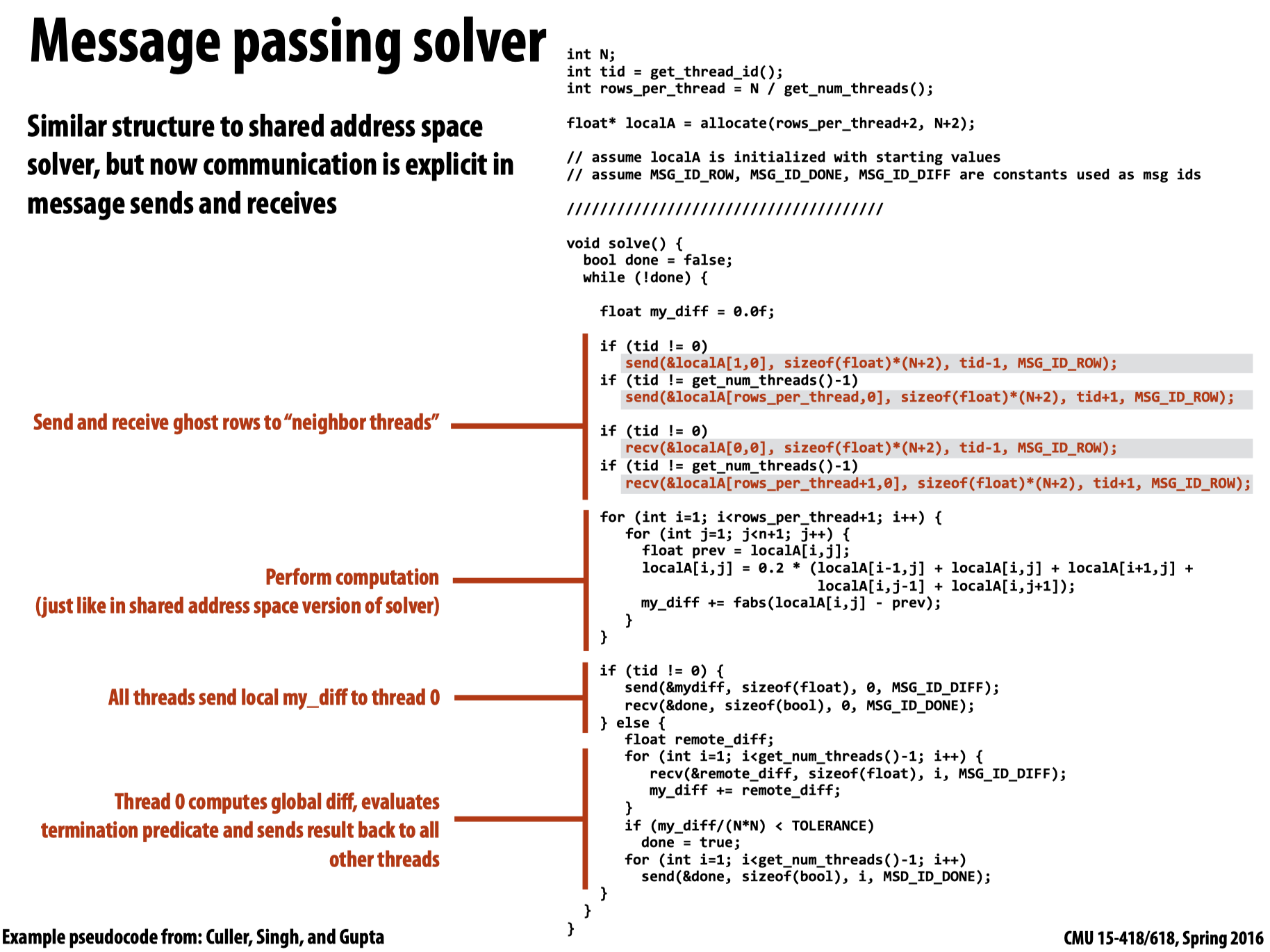
在一开始,先进行消息传递,之后对每一个区块内部进行处理,在计算完成后,每一个线程将计算结果传递给线程0,并等待接收一个叫done信号的到来。而线程0则会判断来自各个其他线程的my_diff相加的结果是否满足条件,如果满足条件,就设置done为True并传递给其他线程,其他线程在接收到done信号后,在下一次while循环开始时就会判定是否结束循环。
Notes on message passing example
- Computation: Array indexing is relative to local address space (not global grid coordinates)
- Communication: Performed by sending and receiving messages (Bulk transfer: communicate entire rows at a time, not individual elements)
- Synchronization: Performed by sending and receiving messages (think of how to implement mutual exclusion, barriers, flags using messages)
消息传递库经常包含一些high-level primitives:
reduce_add(0, &my_diff, sizeof(float)); // add up all my_diffs, return result to thread 0
if (pid == 0 && my_diff/(N*N) < TOLERANCE)
done = true;
broadcast(0, &done, sizeof(bool), MSG_DONE); // thread 0 sends done to all threads
Synchronous/Asynchronous send and receive
同步:即在确保另一端完全接收之后才返回当前线程

在这种模式下,Message passing solver的例子存在些许问题。因为在程序的一开始,所有的线程都在sending,没有任何一个线程处于receiving的状态,而线程因为消息没有被received就不返回,所以导致死锁。
为了解决上述问题,可以将代码写成根据奇偶区分发送/接收模式:

异步(Asynchronous):在这种模式下,发送与接收会立即返回。
需要注意的是,虽然函数立即返回,但我们并不能立即使用用来传递所需信息的buffer,因为消息可能还没有被完全传送,我们不想让原本需要被传送到值变成垃圾值。
同时,我们可以使用checksend/checkrecv来检查消息是否完成发送和接收。

Latency & throughput

Pipelining
这部分讲了pipelining如何提高系统的吞吐量,具体细节因为在先前的课程中学过,这里就不再赘述。
A simple model of non-pipelined communication
在这里,教授给出了非pipeline系统的communication时间计算公式:
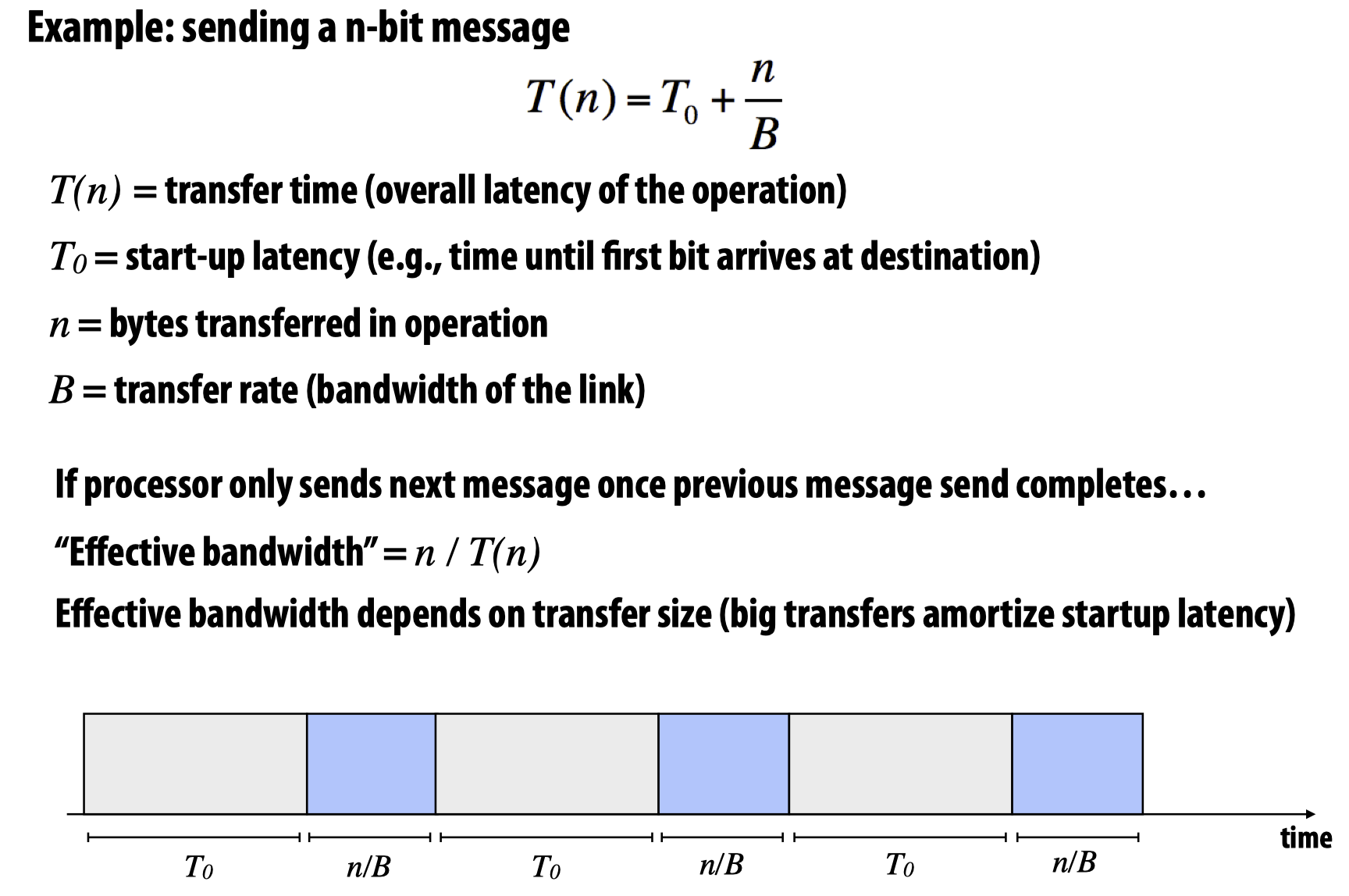
这个公式如何理解?第一部分很好理解,就是等待整个消息队列的头部到达指定传送位置需要的时间;而对于第二部分,由于B表示的是单位时间内允许传送的最大数量,所以n/B就会得到把所有的这些信息传送完成需要多少个单位时间。
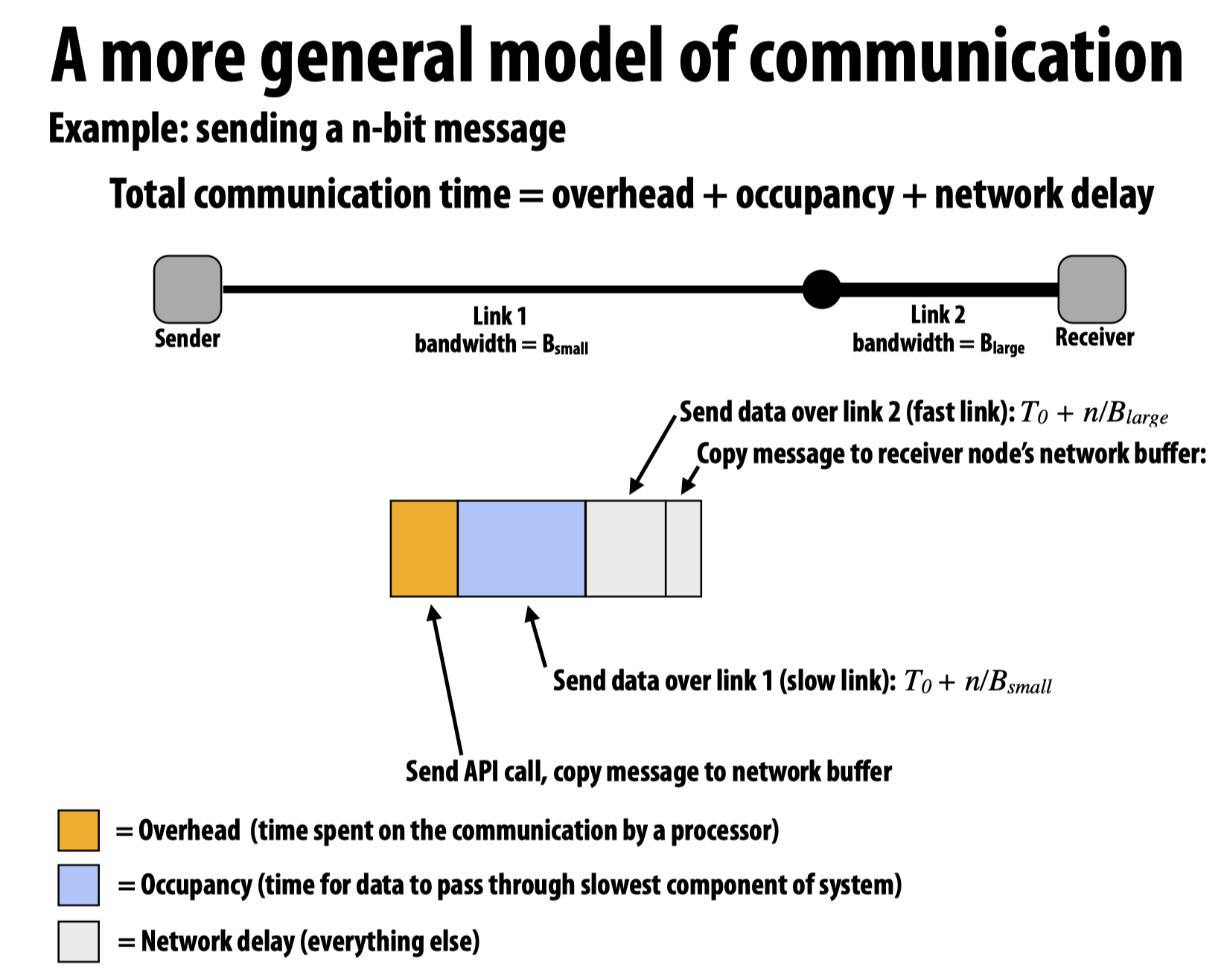
如果我们将上述模型应用到网络包的发送和接收机制上:
Pipelined communication
而如果将上图中的过程pipeline,则有:
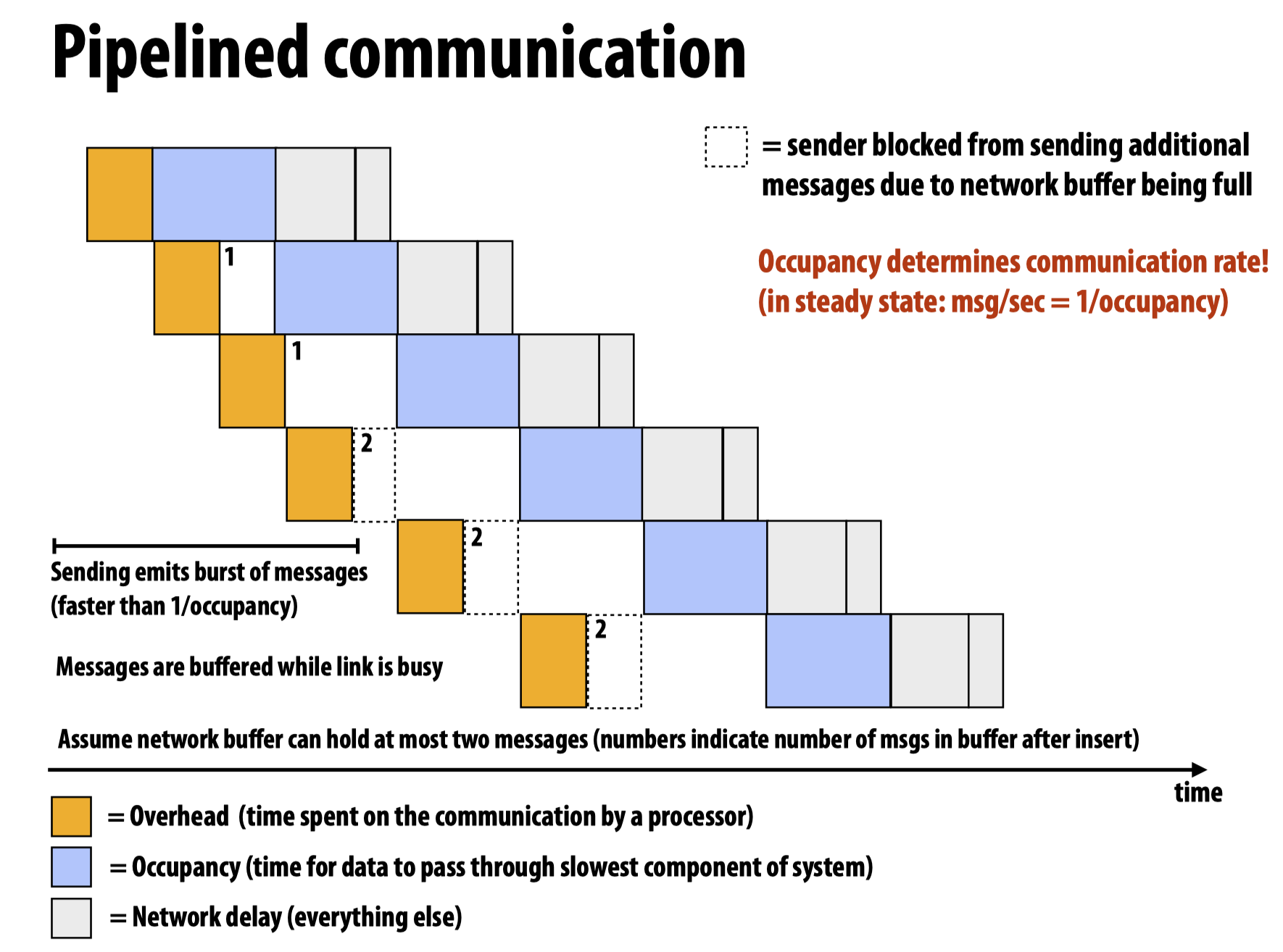
注意在上图中,有时候因为buffer被占满,导致必须stall整个流程,等待缓冲区空出来继续进行。
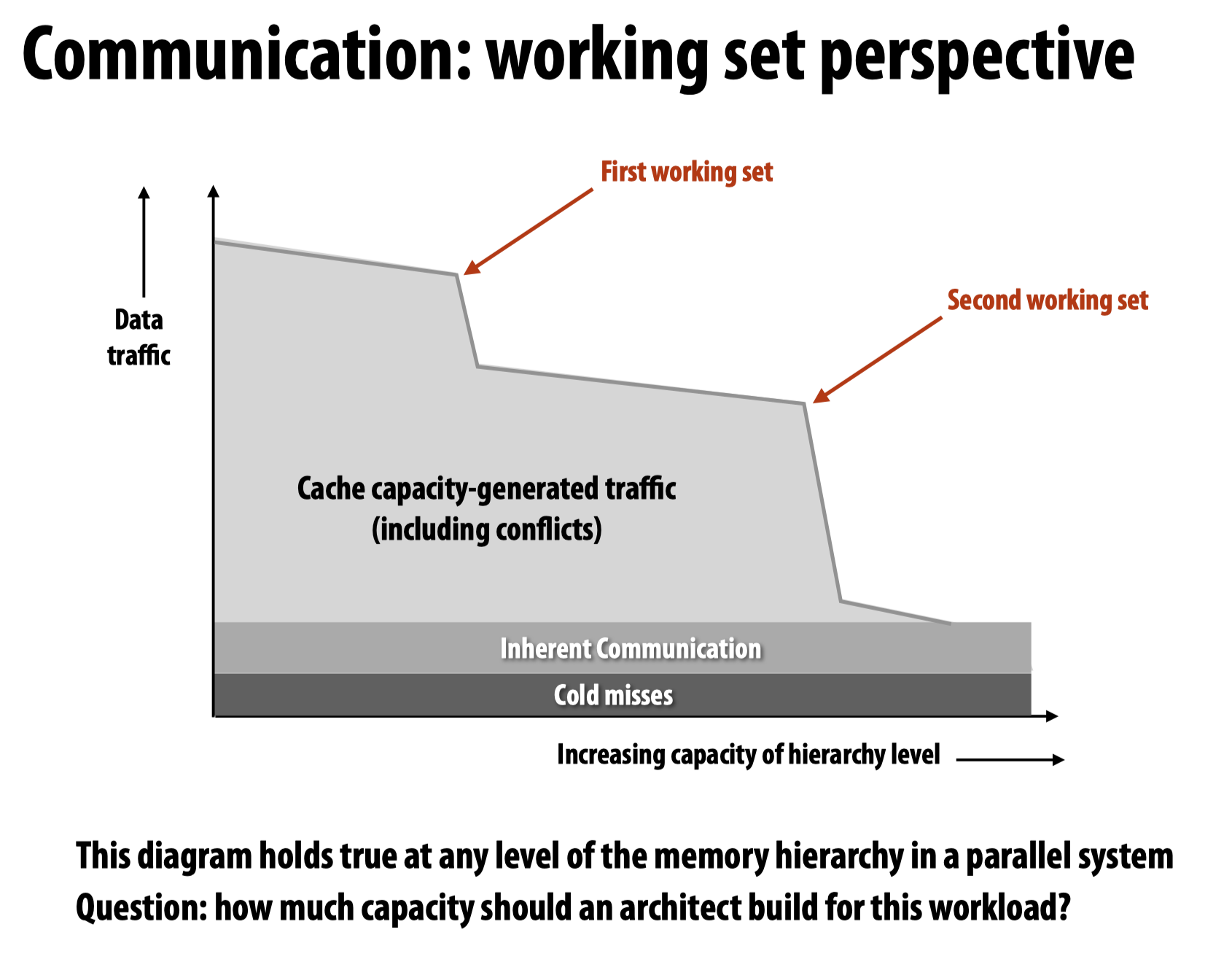
Two reasons for communication – inherent & artifactual communication
inherent communication
这种信息交流方式指的是在并行算法中必然出现的(fundamental to the algorithm),比如在先前的例子中的不同线程区块间的数据交互。
为了衡量算法的性能指标,我们使用Communication-to-computation ratio,并希望这个值越小越好。

为了减小inherent communication,可以比较几种算法设计:


显然,最后一种方法最好,这也是常用的block算法。
Artifactual communication
这种交互取决于系统在现实当中的具体实现细节。而先前的inherent communication则着眼于算法层面上一定会发生的事。

Cache miss
回忆先前学过的cache miss的类型。

Techniques for reducing communication
Improve temporal locality
这里提到了两种方法提高temporal locality,其一是改变遍历顺序:
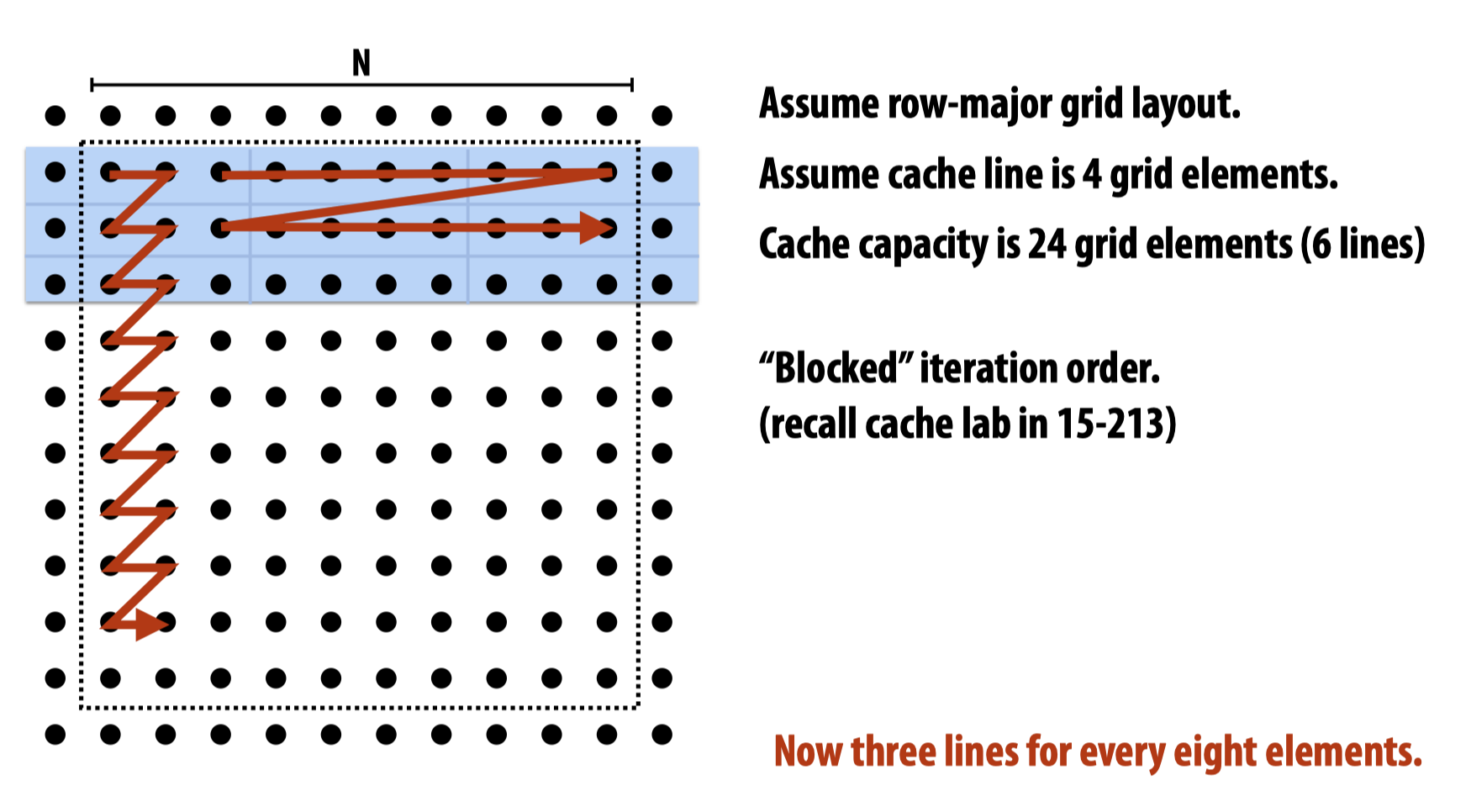
其二是利用pipeline机制做fusing loops:

Sharing data

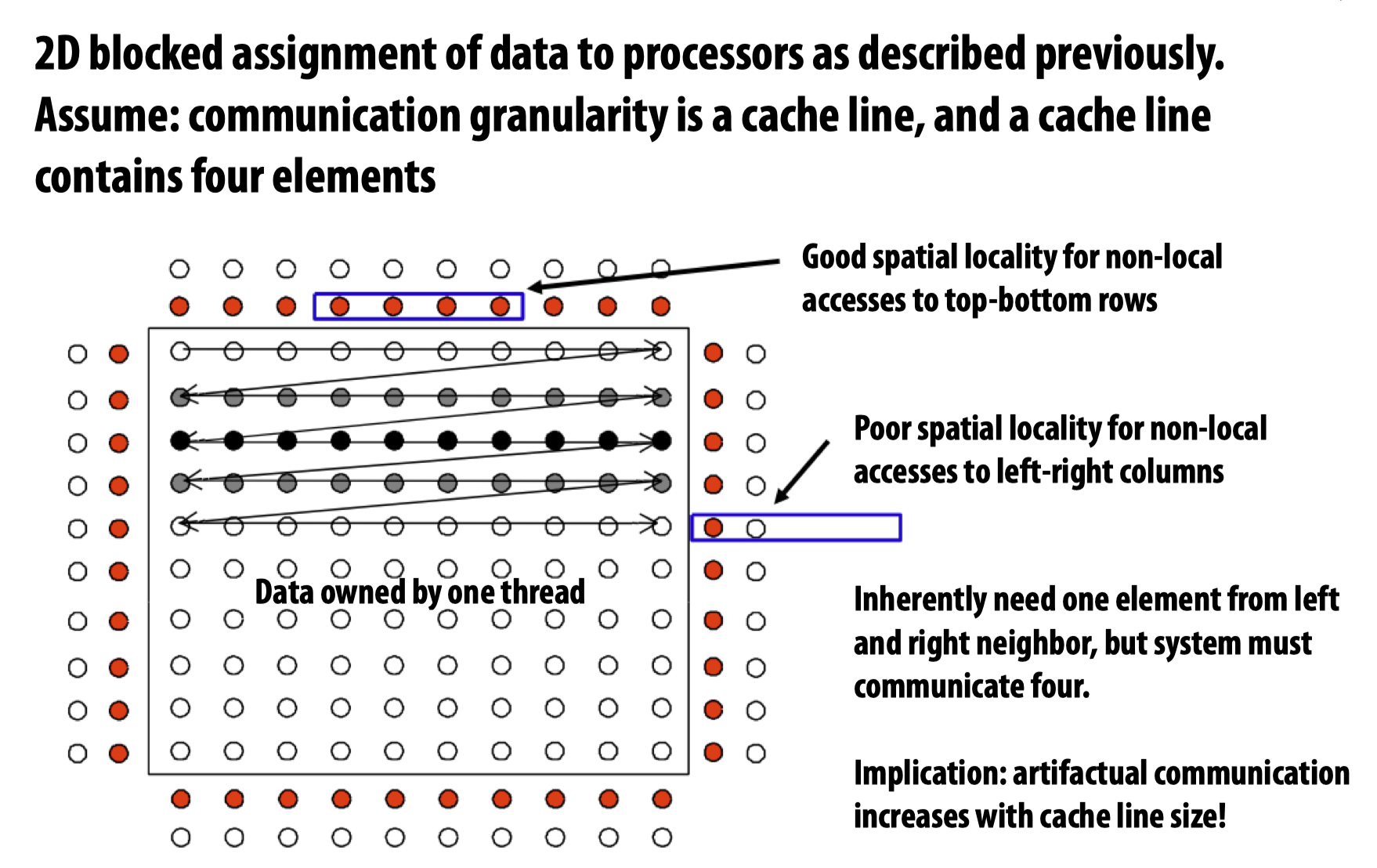
Exploiting spatial locality
关于spatial locality,这里教授提到了两个例子,用来展示有些时候spatial locality会导致不必要的communication,得到的结论是:
Artifactual communication increases with cache line size.
另一个例子则展示了当在不同的处理器中运行两个线程来处理同一个任务的两个子任务时,如果这两个处理器不共享cache,会出现的cache coherence miss,即在同一级的不同cache中可能存储了同一个位置的不同值。
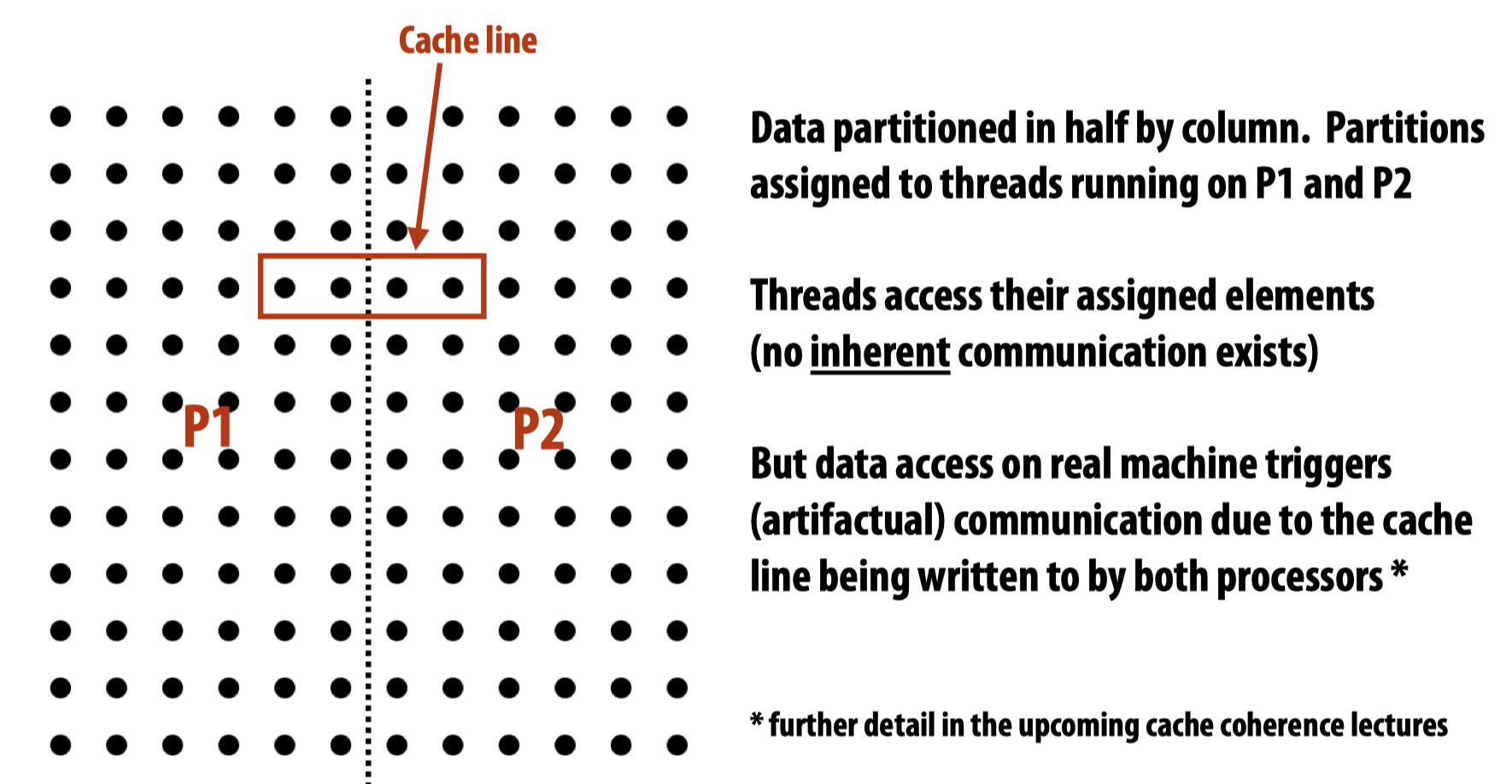
上述两个例子都会导致artifactual communication,解决方法可以做blocked data layout。需要注意的是,blocked data layout和先前一直提到的blocked assignment of work to threads并不一样:
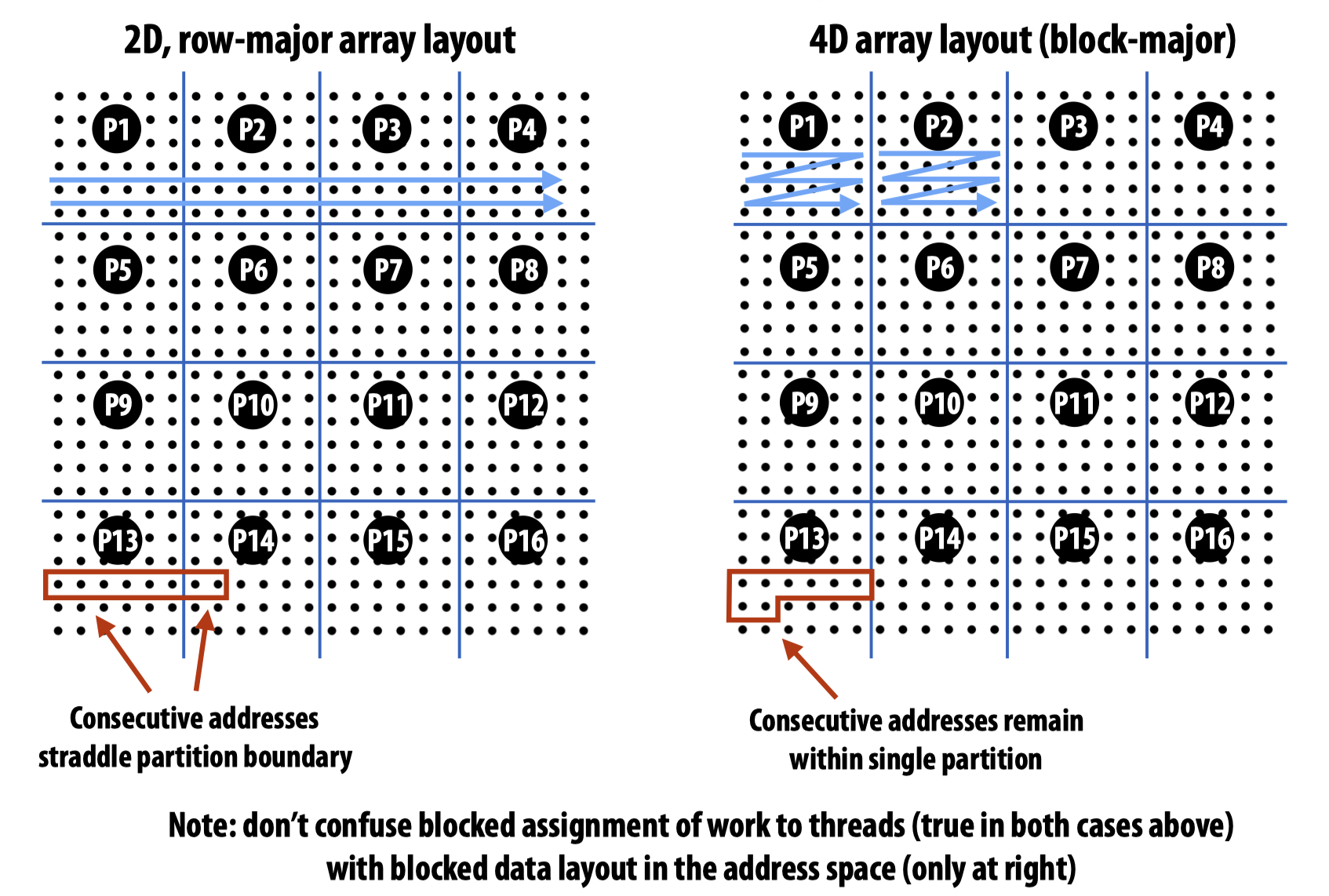
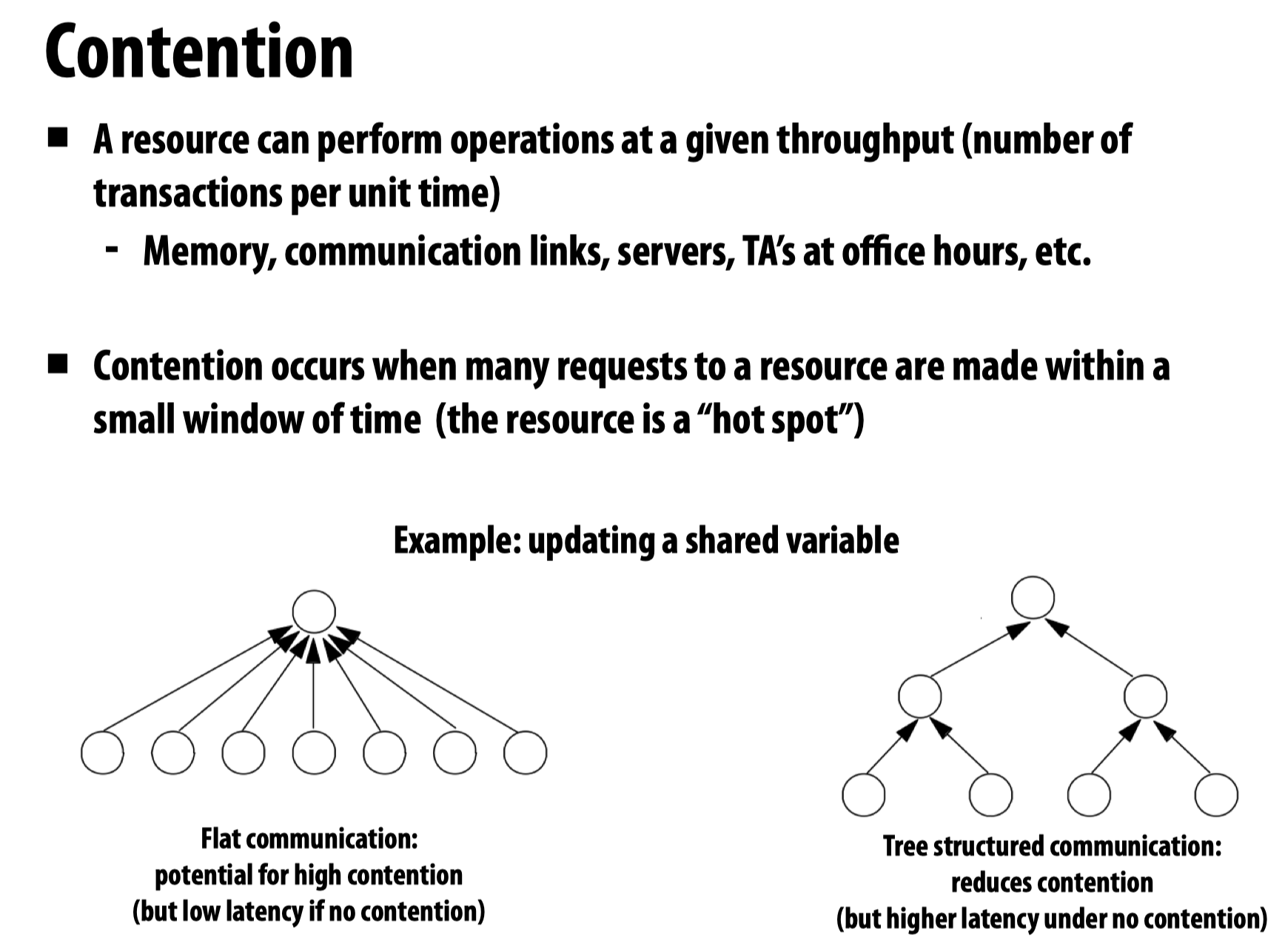
Contention