Fedarated Learning Defintion
Federated learning (also known as collaborative learning) is a machine learning technique that trains an algorithm via multiple independent sessions, each using its own dataset. [1] This approach differs from traditional machine learning methods, which combine local datasets into a single training session or assume that local datasets are uniformly distributed.
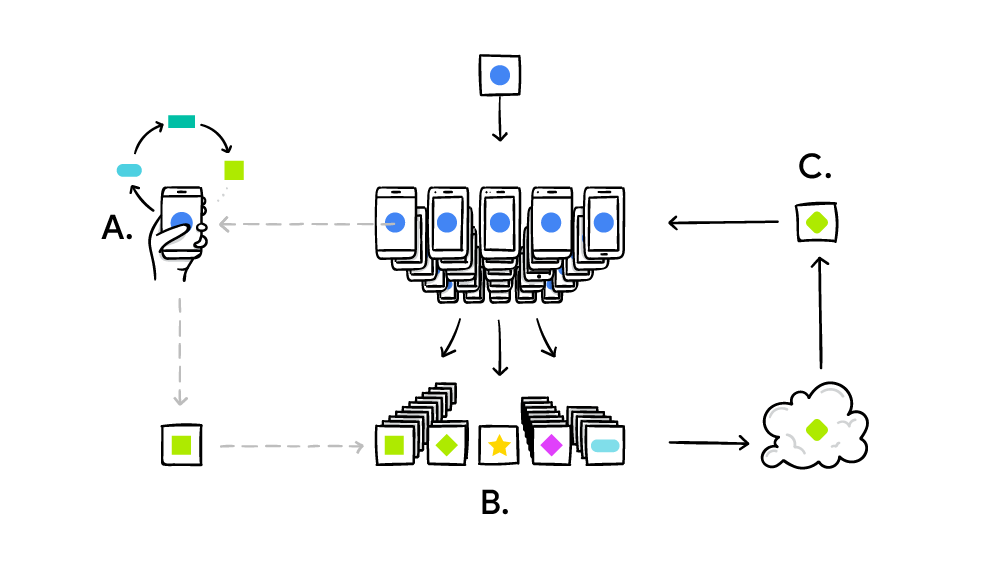
The procedure of Federated Learning can be descripted using the following figure:
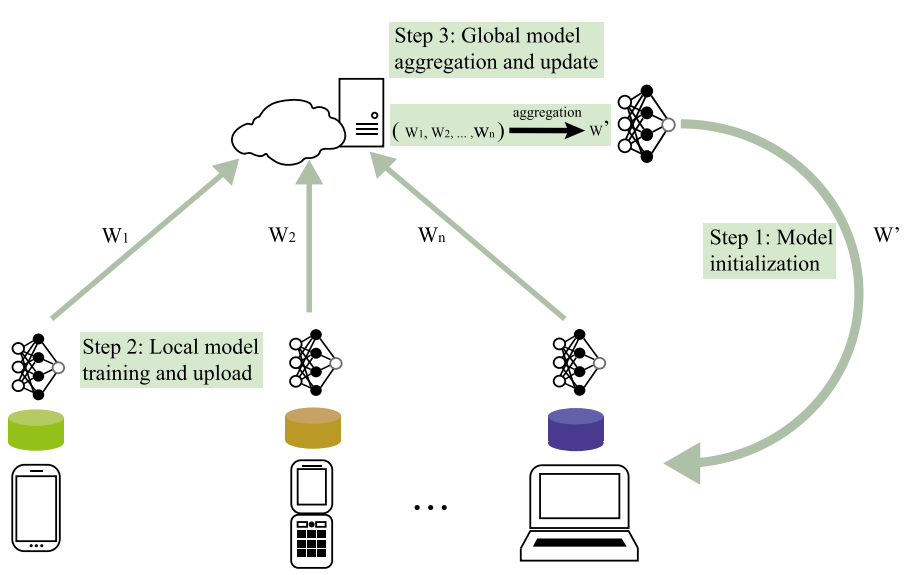
It involves local training, local model update, secure aggregation and glocal model update, which is quite different from the previous neural network training methods, why it is degisned like this? I will briefly explain it in the following.
Classification
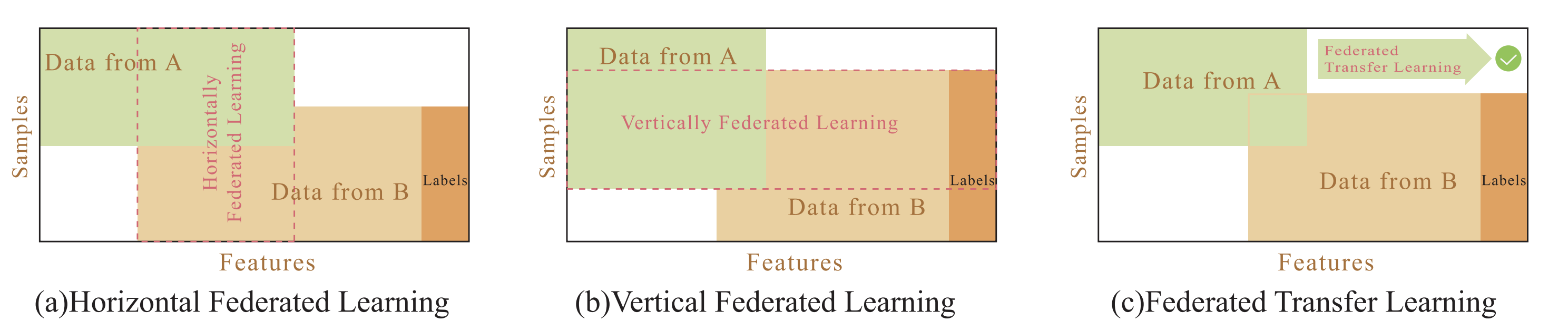
Federated learning can be divided into horizontal learning, vertical learning and transfer learning based on the distribution of data.[2]
- Horizontal Federated Learning: Suitable when the user features of the two datasets overlap a lot, but the users overlap little. This pattern allows the increasing of user sample size and improvement of model accracy.
- Vertical Federated Learning: Available when the user features of the two datasets overlap little, but the users overlap a lot. This pattern usually can be leveraged to increase the user feature dimension.
- Federated transfer Learning: Users and user features of the two datasets both rarely overlap. Transfer learning can be used to solve the problems of small label samples and small unilateral data sizes.[3]
As described above, Federated learning is designed to empower machine learning models to improve and adapt using data from various decentralized devices or data sources, all while ensuring that the data remains on those devices and is kept private. This approach eliminates the necessity to gather sensitive data into a central location, which could otherwise jeopardize data privacy and security.
Based on this initiative, privacy becomes a very important topic in the Federated Learning. Although the local data ensure some extents of “privacy” in the training process, the uploading of model information(parameters) might lead to the leak of privacy.
Privacy protection
Here I will introduce three methods of commonly used privacy protection in Federated Learning.
Model Aggregation
Each participant will train a local model using its own data and then share only the updates to the model parameters, rather than the raw data itself, with a central server. The central server aggregates these updates to produce a more accurate and refined global model.
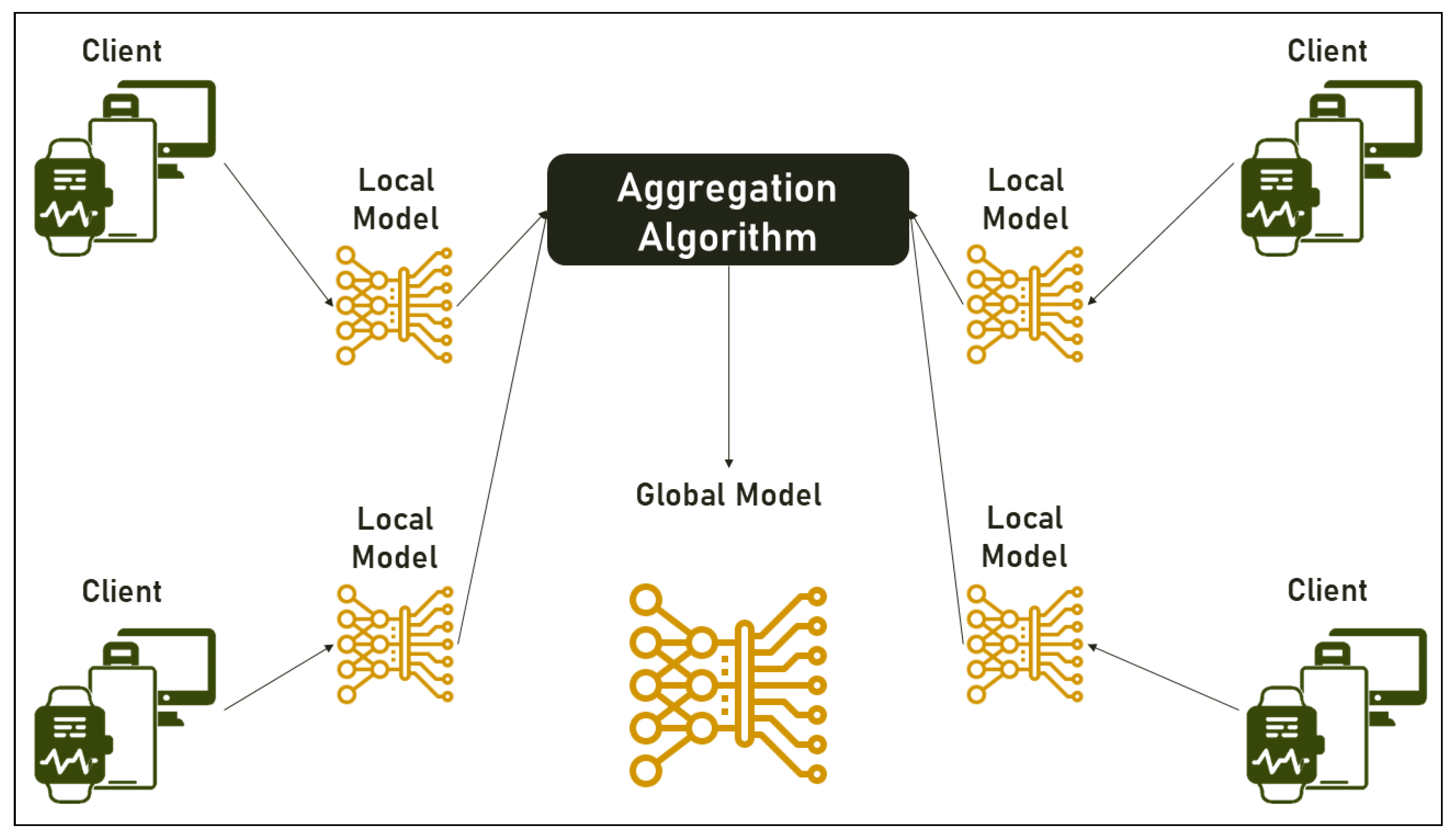
Model aggregation is a crucial step in federated learning because it allows information from different sources to be combined while preserving data privacy and security.
Based on the documentation of TensorFlow, there are always at least two layers of aggregation in federated learning: local on-device aggregation, and cross-device (or federated) aggregation.[5]
- local on-device aggregation: This level of aggregation refers to aggregation across multiple batches of examples owned by an individual client.
- cross-device (or federated) aggregation: This level of aggregation refers to aggregation across multiple clients (devices) in the system.
The choice of aggregation method depends on the specific requirements and constraints of the federated learning application, including privacy concerns, communication bandwidth limitations, and the need for robustness.
Homomorphic encryption
In homomorphic encryption, users must hold the key to get the information of the original data. More importantly, users can calculate and process the encrypted data, but no original data will be disclosed in the process, allowing performing computations on the encrypted data without decrypting it.[6]
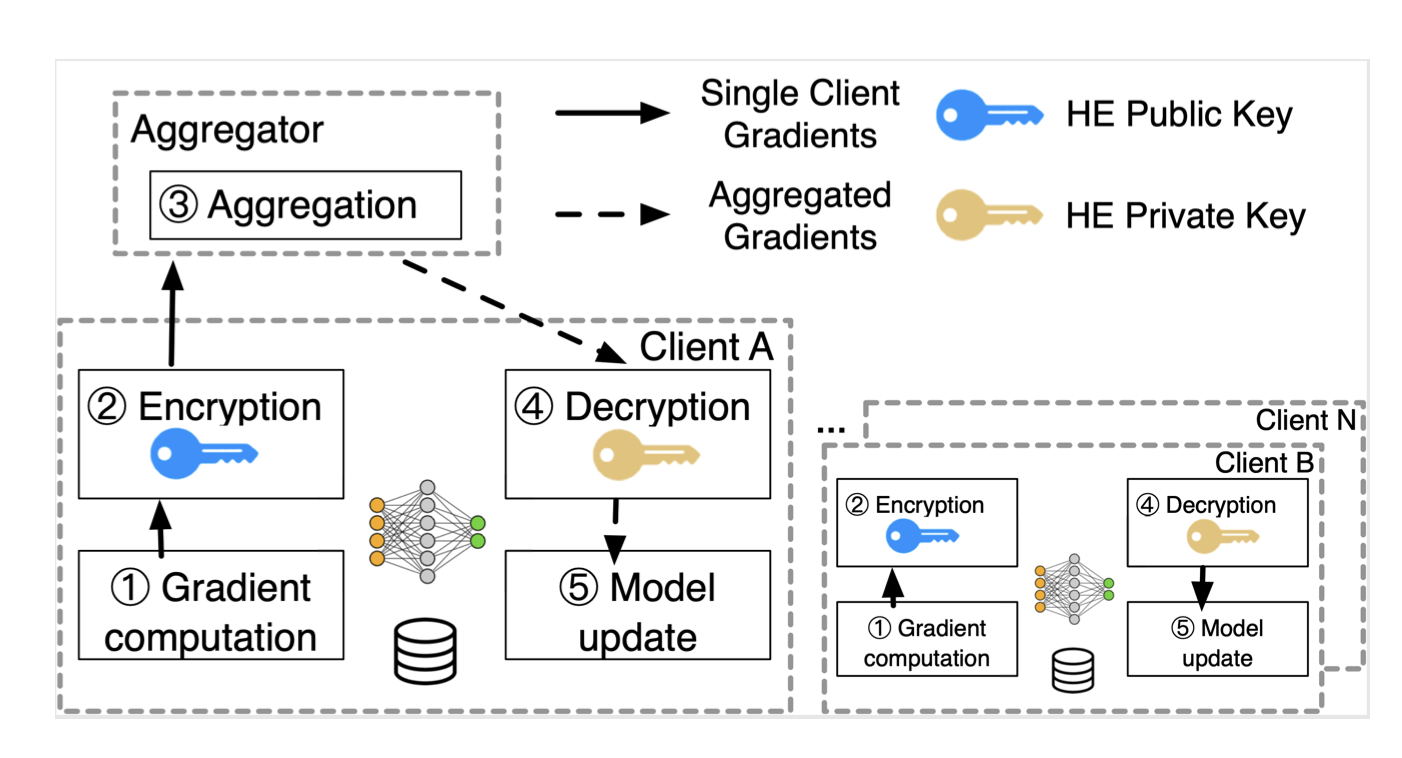
Homomorphic Encryption allows participants to encode their local model updates in such a way that even when these updates are sent to the central aggregator, they remain completely unintelligible. This process can be divided into four steps:[3]
- Homomorphic Encryption: Each participant applies homomorphic encryption to their local model updates before sharing them.
- Secure Aggregation: The central aggregator only receives these homomorphically encrypted model updates. It cannot decipher or gain any insights from the updates.
- Encrypted Aggregated Model: The aggregator combines these encrypted model updates to create an aggregated model, and this model remains encrypted throughout the process.
- Decryption and Iteration: The encrypted aggregated model is then sent back to the participants. Each participant has the decryption key to unlock this model, revealing the improved global model. The participants can then continue with the next round of training using this updated model.
Differential privacy
Differential privacy is proposed by Dwork [7] in 2006. Under this strategy, the data calculation results in the statistical database are not sensitive to whether new data is added to the database (because of the data volume and the size of a single data type), so even if the attacker tries to add new data to the database, It is difficult to influence the final calculation results. We can then apply this strategy to the data set, which means that the abnormal data added by the attacker will not have an uncontrollable impact on the final result when applying this strategy.
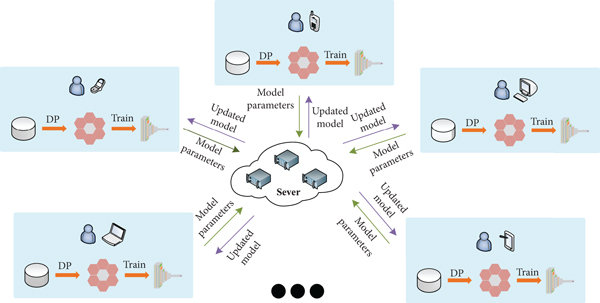
A traditional method is to add noise to the output to apply differential privacy when performing gradient iteration, to protect user’s privacy.[8] However, adding noise to the model will inevitably decrease the validity of the result. We need to figure out some methods to balance between privacy and validity.
For example, the TensorFlow provides users with interface of differential privacy on application of EMINST dataset[4], using the method of adaptive clipping method of Andrew et al. 2021, Differentially Private Learning with Adaptive Clipping to avoid adding unnecessary noise and reduce the penetration from the adding noise to the model.[9]
Network (nodes) structure
According to different coordination methods, federated learning can be divided into centralized topology architecture and peer-to-peer network topology architecture.
Centralized topology
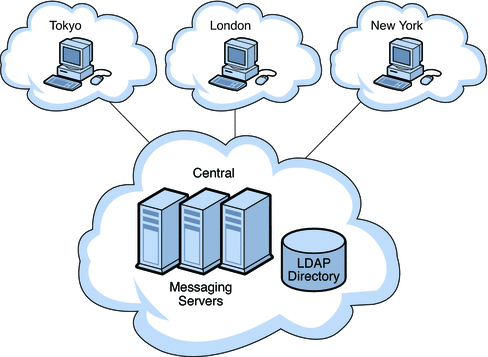
Different from traditional machine learning training conducted in data centers, the centralized training mode in federated learning still uses distributed nodes to complete local gradient updates. After the nodes encrypt the updated gradient parameters and pass them to the central server, the central The server will perform secure aggregation on it and then return the result to the node, which will perform gradient updates after decryption.
Centralized topology offers significant advantages, such as ease of deployment, direct control during training, and simple maintenance. However, it also has significant disadvantages: the central server can become a bottleneck, and there is an inherent risk of privacy leakage or vulnerability to malicious attacks on this central computing entity.
P2P
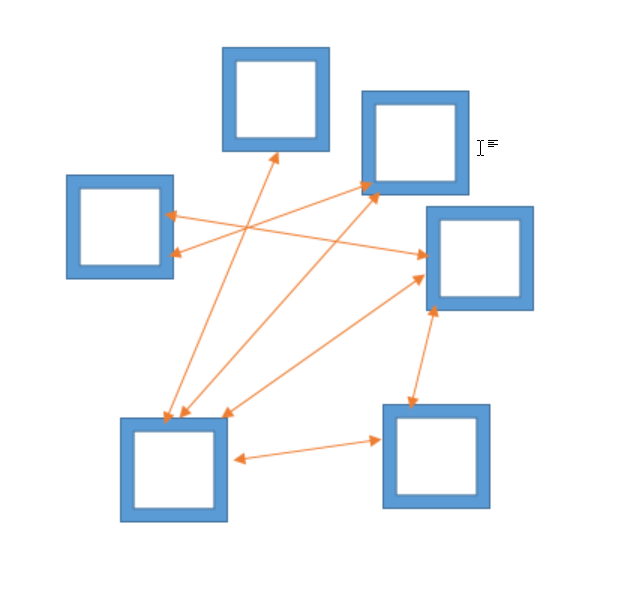
In a peer-to-peer network setup, lacking a central server for coordination, participants must establish a predetermined sequence for the transmission and reception of model parameter data. This is typically achieved through two primary approaches:
- Sequential Communication: Participants arrange themselves in a sequential, chain-like formation. Starting with the first in line, each participant transmits their trained model parameters to the next. Upon receiving the model, a participant updates it with their own data before passing the revised model to the following participant. This cycle continues until the model’s loss stabilizes.
- Stochastic Communication: In this method, once a participant, labeled as the kth participant, completes their training, they randomly choose another participant from the remaining pool to be the next trainer. The kth participant then forwards the model parameters directly to their selected successor. This procedure is reiterated until the overall model reaches stable.
Use Scenarios
A notable application of federated learning is the Internet of Things. With the widespread implementation of autonomous driving technology and the introduction of new smart homes and wearable devices, more and more companies are integrating artificial intelligence technology and LLM applications into their products. Especially for self-driving cars, it requires the model to be updated in real time based on the environment and data, while ensuring the privacy of vehicle driving data and automobile manufacturer parameter data. At this time, federated learning comes in handy: it can ensure that LLM is updated based on While making timely adjustments to the environment, the data security and privacy of car owners and car manufacturers are ensured.
To make sure the fedarated learning models can adapt to rapidly changing environments and heterogeneous hardware settings, there are also some works that demonstrate how to achieve this. For example, Hongyi Zhang, etc[10] proposes an asynchronous model aggregation protocol, which can significantly improve the prediction performance of local edge models while maintaining the same level of accuracy as centralized machine learning.
References
[2] Zhang C, Xie Y, Bai H, et al. A survey on federated learning[J]. Knowledge-Based Systems, 2021, 216: 106775.
[3] Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19.
[4] Federated Learning in Tensorflow
[5] Moshawrab M, Adda M, Bouzouane A, et al. Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives[J]. Electronics, 2023, 12(10): 2287.
[6] IBM Federated Learning with homomorphic Encryption
[7] Dwork C. Differential privacy: A survey of results[C]//International conference on theory and applications of models of computation. Berlin, Heidelberg: Springer Berlin Heidelberg, 2008: 1-19.
[8] Abadi M, Chu A, Goodfellow I, et al. Deep learning with differential privacy[C]//Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. 2016: 308-318.
[9] Andrew G, Thakkar O, McMahan B, et al. Differentially private learning with adaptive clipping[J]. Advances in Neural Information Processing Systems, 2021, 34: 17455-17466.
[10] Zhang H, Bosch J, Olsson H H. Real-time end-to-end federated learning: An automotive case study[C]//2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 2021: 459-468.