计算机网络的层级架构(这里使用五层)。
- 应用层(
application) - 运输层(
transport) - 网络层(
network) - 数据链路层
- 物理层
在本课程中,数据链路层与物理层被同一归于link层。

The Internet Protocol (IP)
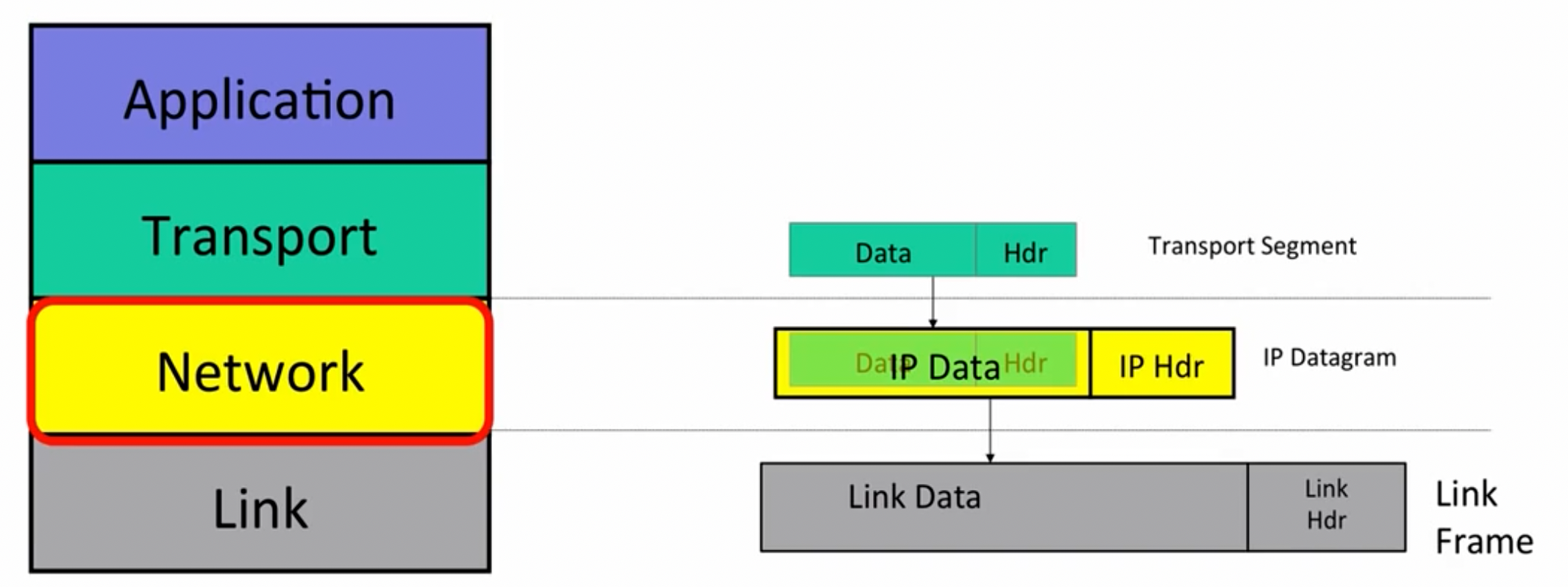

IPV4 Datagram:
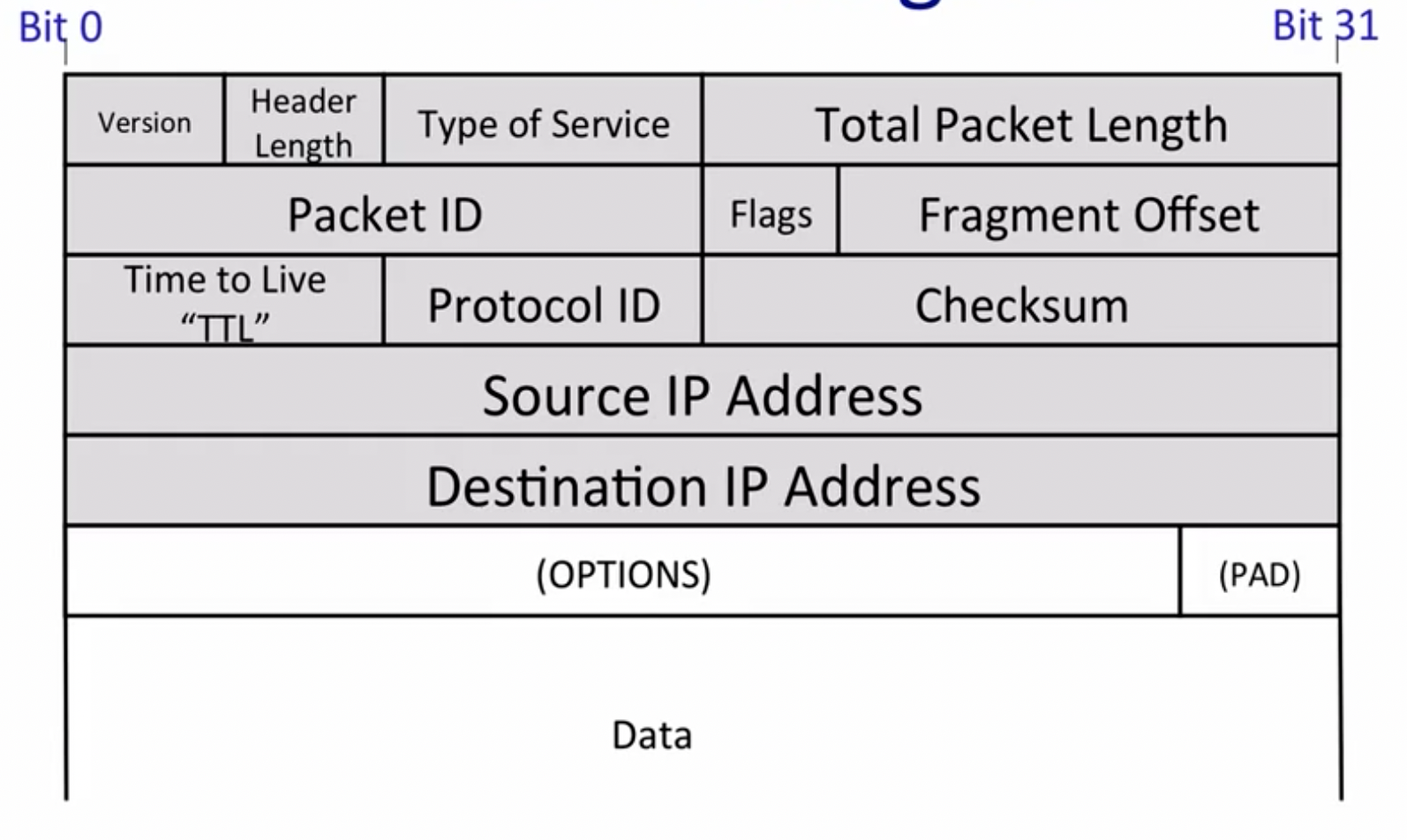
其中,TTL用来避免packets looping forever的现象。Protocol ID的作用是告知接收方对应的协议应该使用哪一种。
TCP Byte Stream
接下来,课程更加深入的带领我们了解了TCP Byte Stream,从三次握手(Syn,syn/Ack, Ack)的建立连接过程开始,建立由IP address和TCP Port这两个信息构建的客户端与服务端之间的连接。
- IP Address: network layer address
- TCP Port: Transport layer address
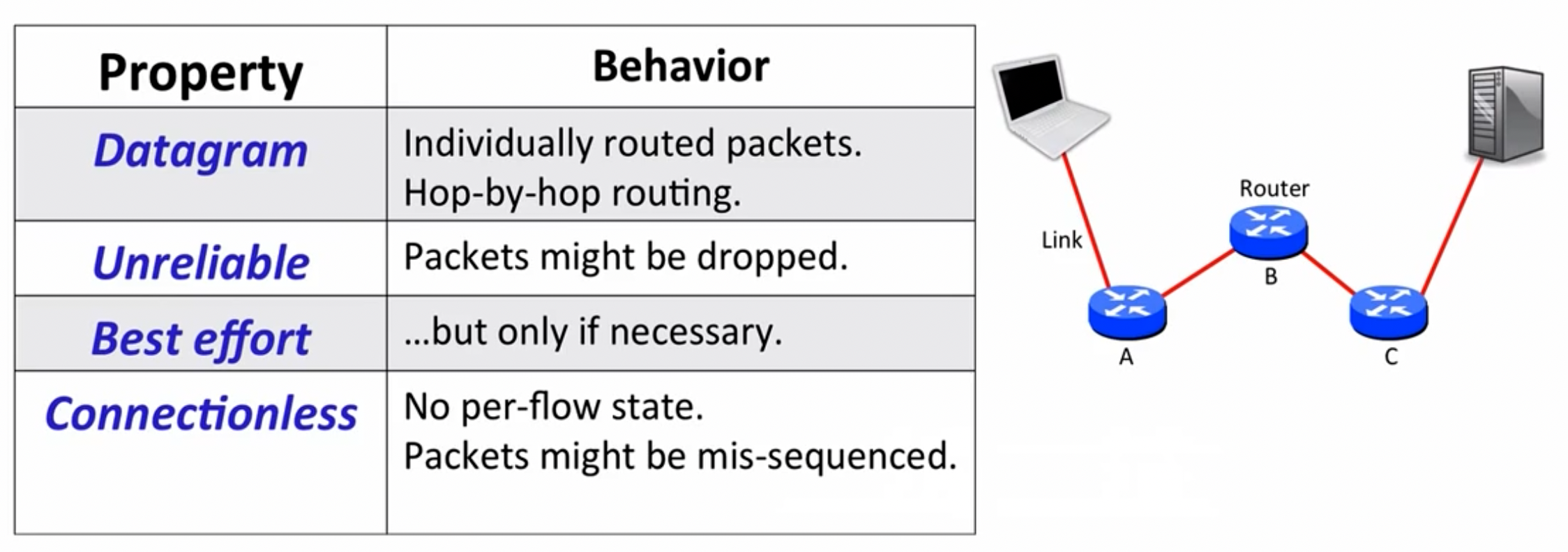
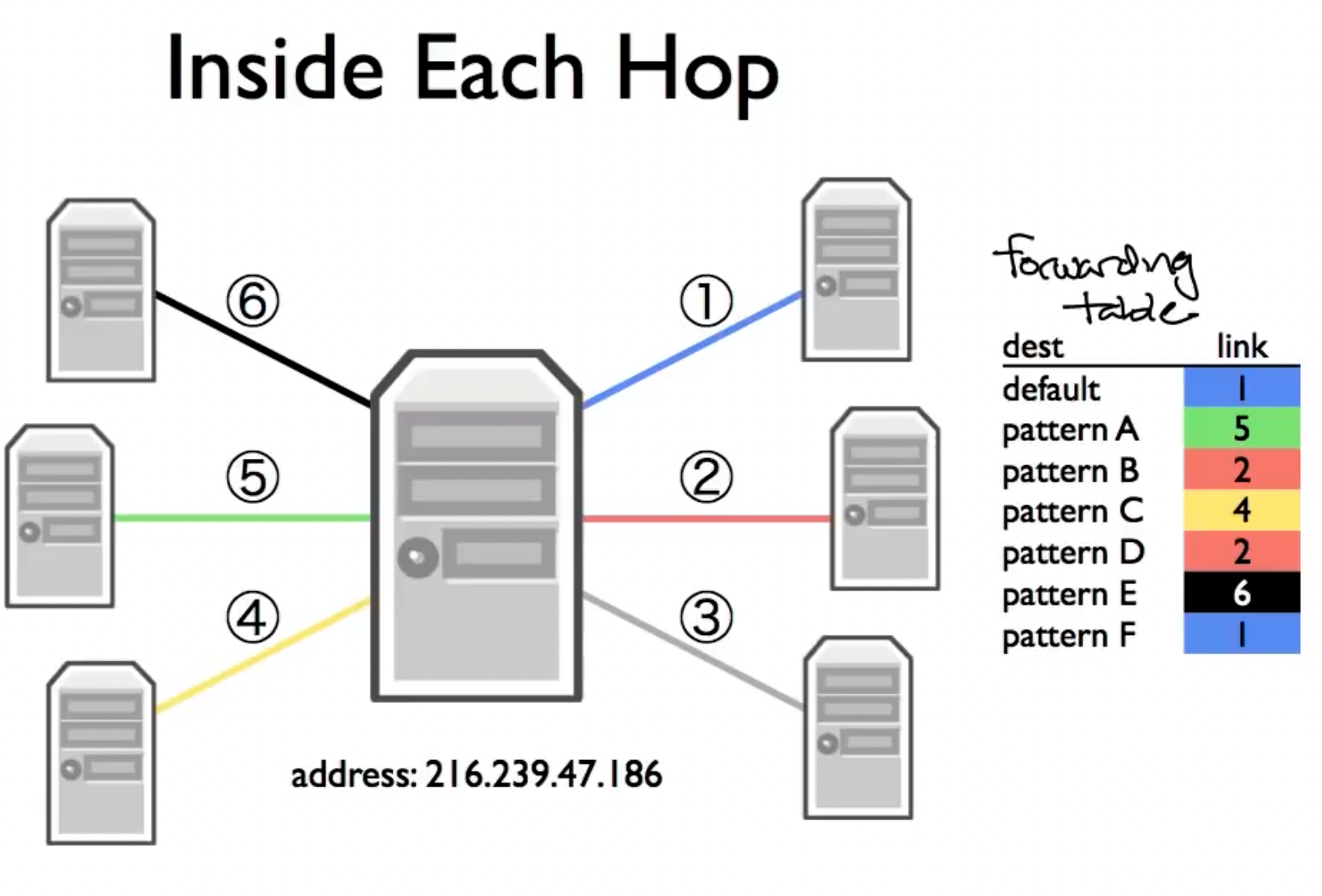
连接被建立后,在客户端与服务端之间通过许多routers不断跳转,这些跳转借由路由器中的forwarding table实现,通过选择匹配度最高的记录条目实现跳转(Default是最general的)
Two Principles
- Layering
- Encapsulation
Encapsulation的一个应用是VPN(Virtual Private Network):
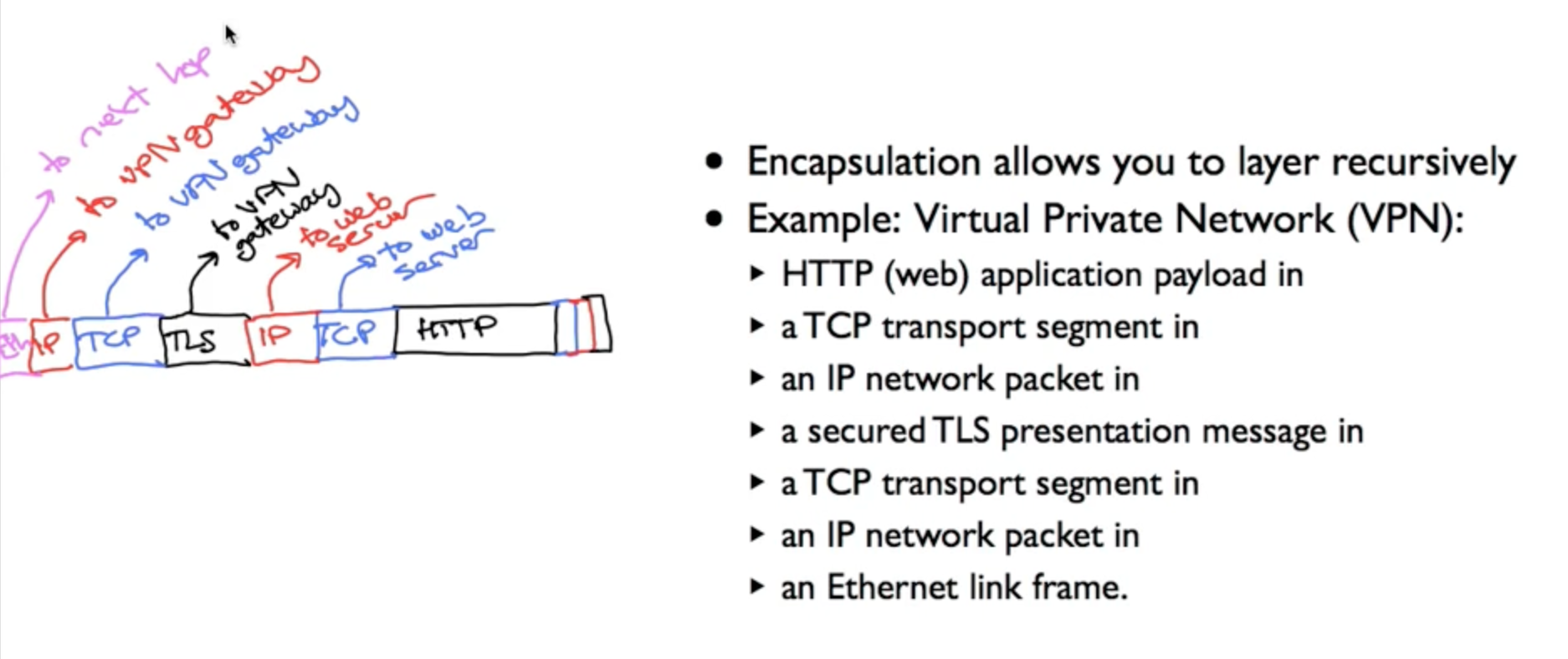
指向web server的数据包被封装在指向VPN Gateway的数据帧内。
Network Byte Order
由于不同的处理器有不同的endianness设置(e.g. x86是小端,ARM是大端),所以网络包的发送方和接收方需要在endianness设置上达成一致,所以规定:
- Network byte order is big endian

这可能会导致处理器本身的端序和网络包内的端序不一致,于是我们需要一些方法来比较和转化:


IPV4
IPV4地址为32位长度,通过使用netmask来决定机器是否位于同一个网络中:

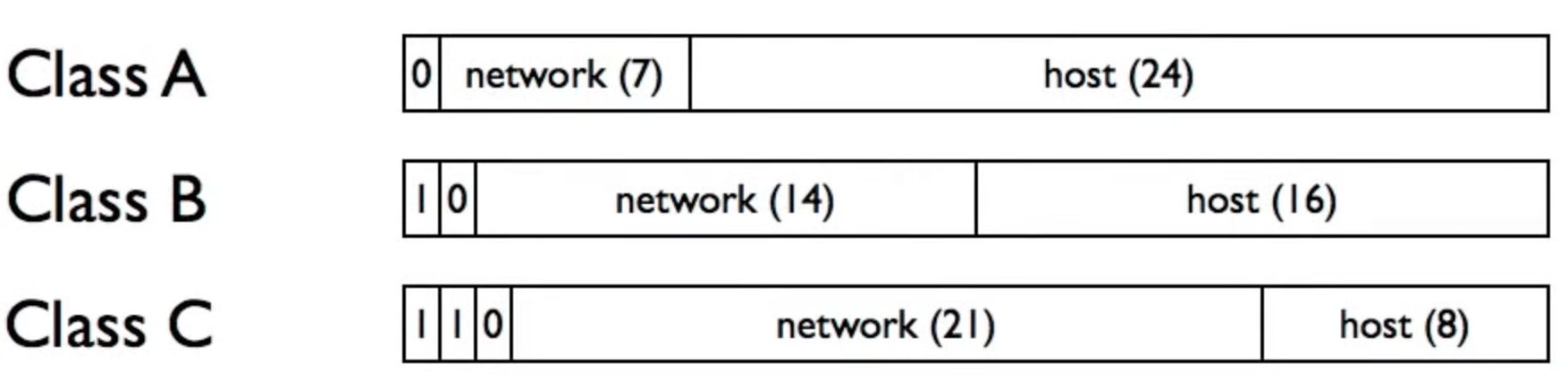
在传统的IPV4地址分配中,IP地址的分配把IP地址的32位按每8位为一段分开。这使得前缀必须为8,16或者24位。因此,可分配的最小的地址块有256(24位前缀,8位主机地址,28=256)个地址,而这对大多数企业来说太少了。大一点的地址块包含65536(16位前缀,16位主机,216=65536)个地址,而这对大公司来说都太多了。
Network + host
- Network to get to correct network (administrative domain)
- Host to get to correct device in network (within administrative domain)
Origianally 3 classes of addresses: class A, class B, class C
为了解决上述问题,Classless Inter-Domain Routing (CIDR)被使用,允许不局限于8/16/24位的前缀网络段被使用。

IPV4地址的分配如今由ICANN负责,这些任务曾由其它组织(特别是IANA)代表美国政府来执行。该机构将/8的网络地址段给予Regional Internet Registries (RIRs),RIRs负责地球上不同的地理区域(非洲,美洲,e.g.)
IPV6
IPV6有128位地址,按照IPV4一样的格式:subnet prefix+interface ID。

IPV6 address assignment:

如果当前subnet为/64,那么我们可以使用MAC addr生成IPV6地址中的interface ID part:

Longest Prefix Match

一般有两种方法在路由器中设计最长前缀查找:
Binary tries:
(图略)
我们将IP地址做成二进制trie树,找最长匹配,从第一个不匹配(没有被记录)的位置倒退回一个位置就是我们需要的最长前缀。
Ternary Content Addressable Memory (TCAM):
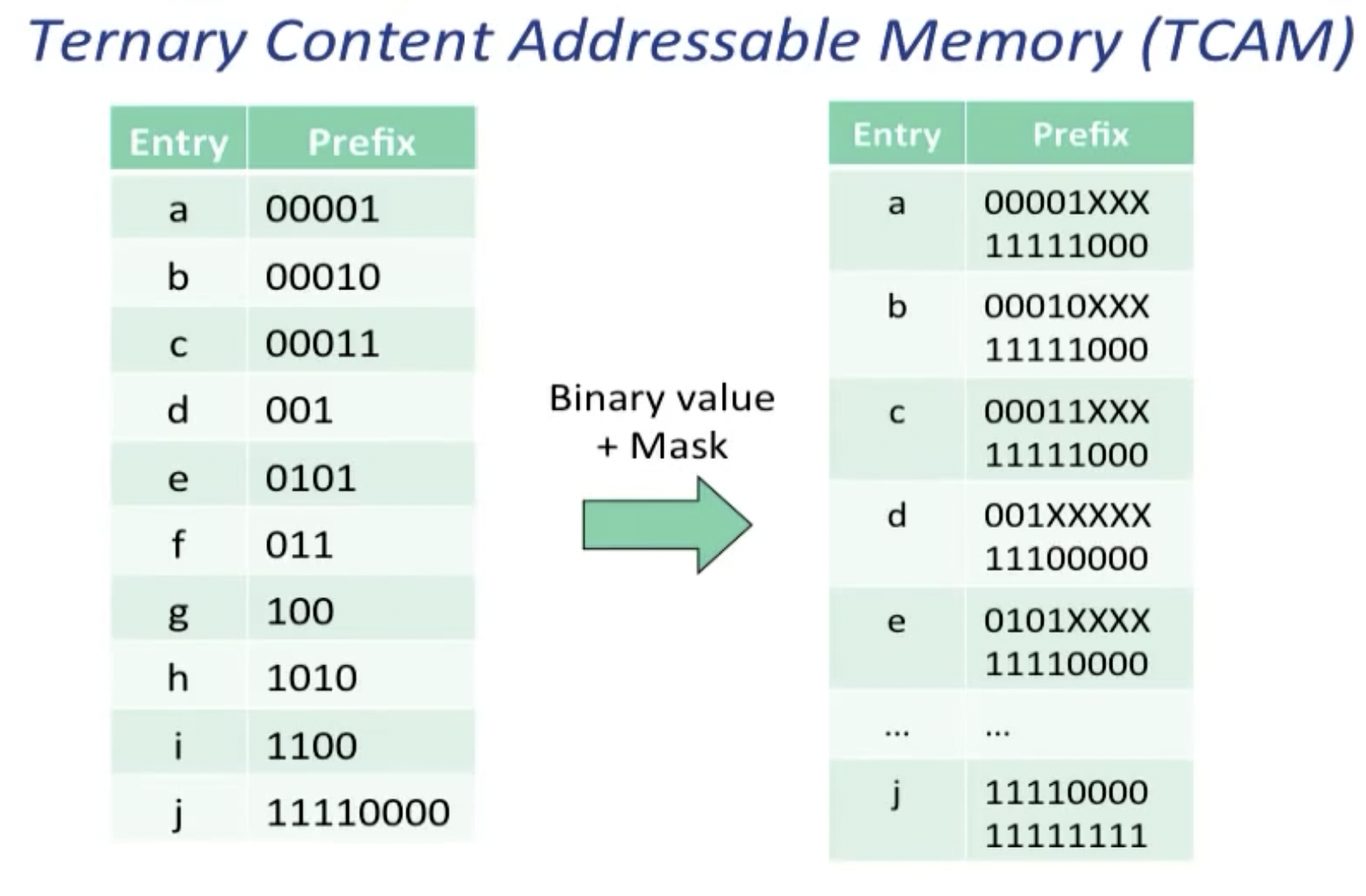
三进制 CAM 通常用于网络路由器,其中每个地址都有两部分:网络前缀(其大小可能根据子网配置而变化)和主机地址(占用剩余位)。每个子网都有一个网络掩码,指定地址的哪些位是网络前缀,哪些位是主机地址。路由是通过查询路由器维护的路由表来完成的,该路由表包含每个已知的目标网络前缀、关联的网络掩码以及将数据包路由到该目的地所需的信息。在简单的软件实现中,路由器将要路由的数据包的目标地址与路由表中的每个条目进行比较,与网络掩码执行按位“与”操作,并将其与网络前缀进行比较。如果相等,则使用相应的路由信息来转发数据包。对路由表使用三态 CAM 使查找过程非常高效。地址的存储方式不关心地址的主机部分,因此在 CAM 中查找目标地址会立即检索正确的路由条目;掩蔽和比较都是由 CAM 硬件完成的。如果 (a) 条目按网络掩码长度递减的顺序存储,并且 (b) 硬件仅返回第一个匹配条目,则此方法有效;因此,使用最长网络掩码的匹配(最长前缀匹配)
ARP
Address Resolution Protocol(ARP)协议用于寻找已知IP地址,确定对应的数据链路层地址。一般的数据链路层地址为48bit(Ethernet),由冒号分隔。
一个值得注意的点在于,虽然MAC地址和IP地址根据网络分层的概念,是完全解耦的,但在实际的应用中情况未必如此。比如,一种常见的情况是单个主机拥有多个IP地址,分配给他当中的每一个interface,这是由于网络掩码的概念导致的。

比如在上图中,如果网关的IP地址是唯一的,为了让网关和B处于同一网络段中,netmask必须为128.0.0.0,而这意味着A(192.168.0.5)也会和他们位于统一网络中,这显然不是我们希望发生的(netmask失去了意义)。正因如此,我们 常见到如下配置:网关或者路由器具有多个网卡,他们分别配备了不同的MAC地址和IP地址:
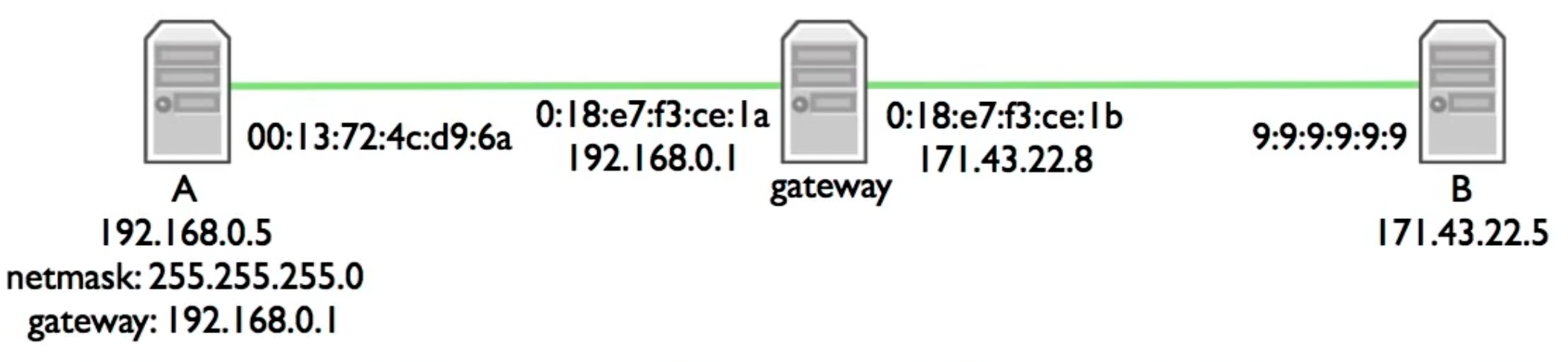
在实际的传输过程中,主机A想要发送一个网络包到主机B,发现B和自己不在一个网络中,于是先将网络包传送到A指定的网关内,即在destination link addr内填入网关的MAC地址,之后在从网关将数据包传送到B上,需要注意,无论在哪一个传送阶段,IP数据包内的目的地址始终是B主机。
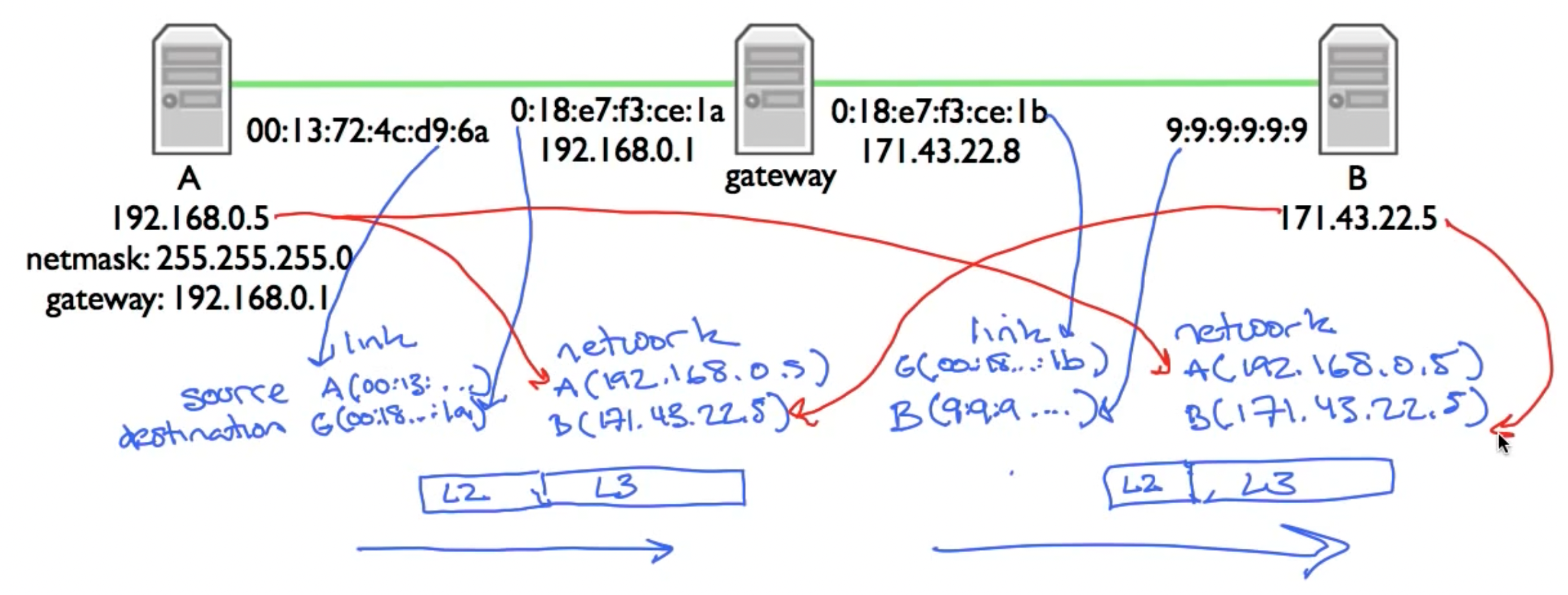
于是接下来的问题变成了,主机A需要向网关发送数据包,由于网关和主机A位于同一个网络中,所以数据包的发送是通过交换机中的MAC地址表实现的,那么网关的MAC地址要如何获取呢?这就是ARP的用途了。设备会维护ARP缓存表,其中的缓存香会在一段时间内过期。
ARP采用简单的request-reply方法:
- Request: Who has network address X?
- Reply: I have network address X.
请求通过广播(broadcast)的形式发送,回复一般采用单播的方法,仅发送给先前发出请求的地址。但一些其他的可能也包括广播回复,这样可以加速更新其他设备中的ARP缓存表。ARP缓存表会在request和reply时都(可能)进行更新。
无回报的ARP(gratuitous ARP),它是指主机发送ARP查询(广播)自己的IP地址,当ARP功能被开启或者是端口初始配置完成,主机向网络发送无回报的ARP来查询自己的IP地址确认地址唯一可用。作用:
- 确定网络中是否有其他主机使用了IP地址,如果有应答则产生错误消息。
- 无回报的ARP可以做更新ARP缓存用,网络中的其他主机收到该广播则在缓存中更新条目,收到该广播的主机无论是否存在与IP地址相关的条目都会强制更新,如果存在旧条目则会将MAC更新为广播包中的MAC。
ARP报文格式:
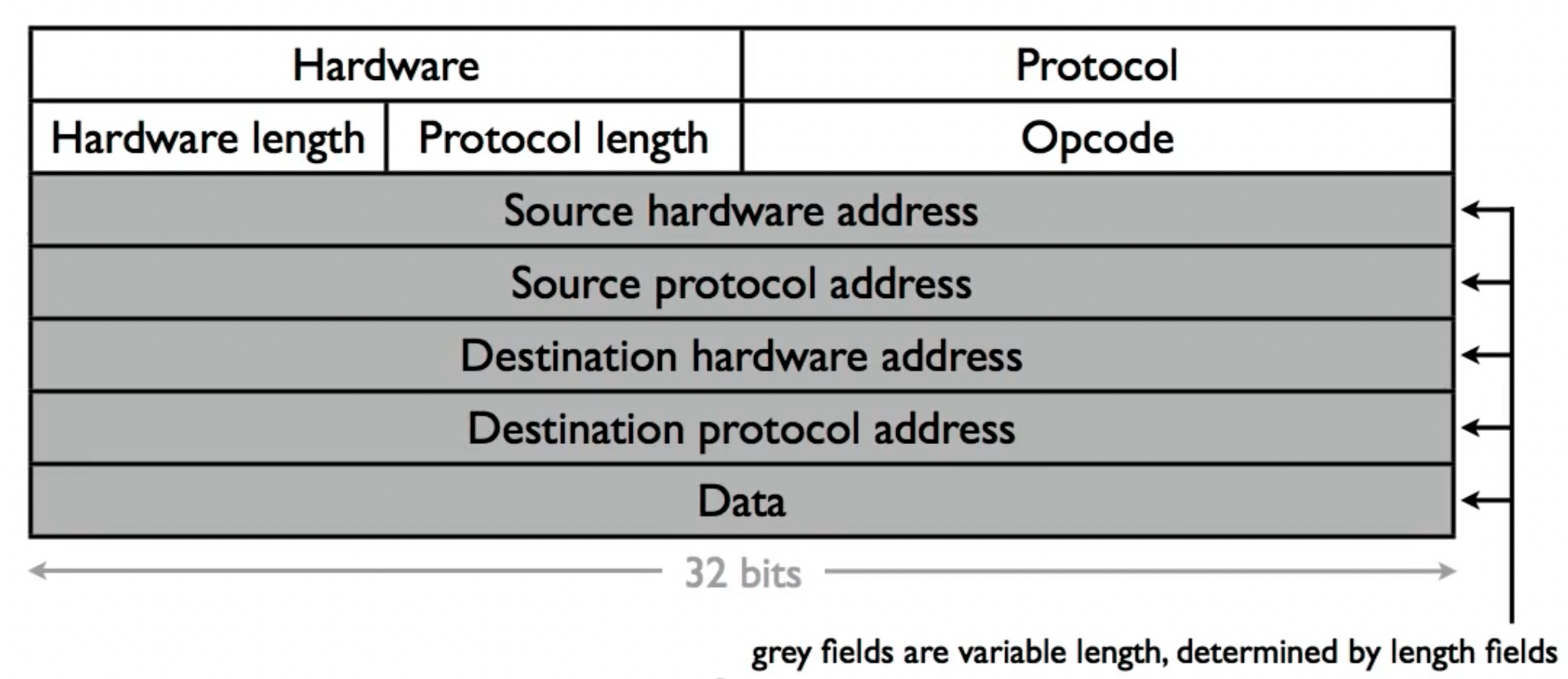
例子:
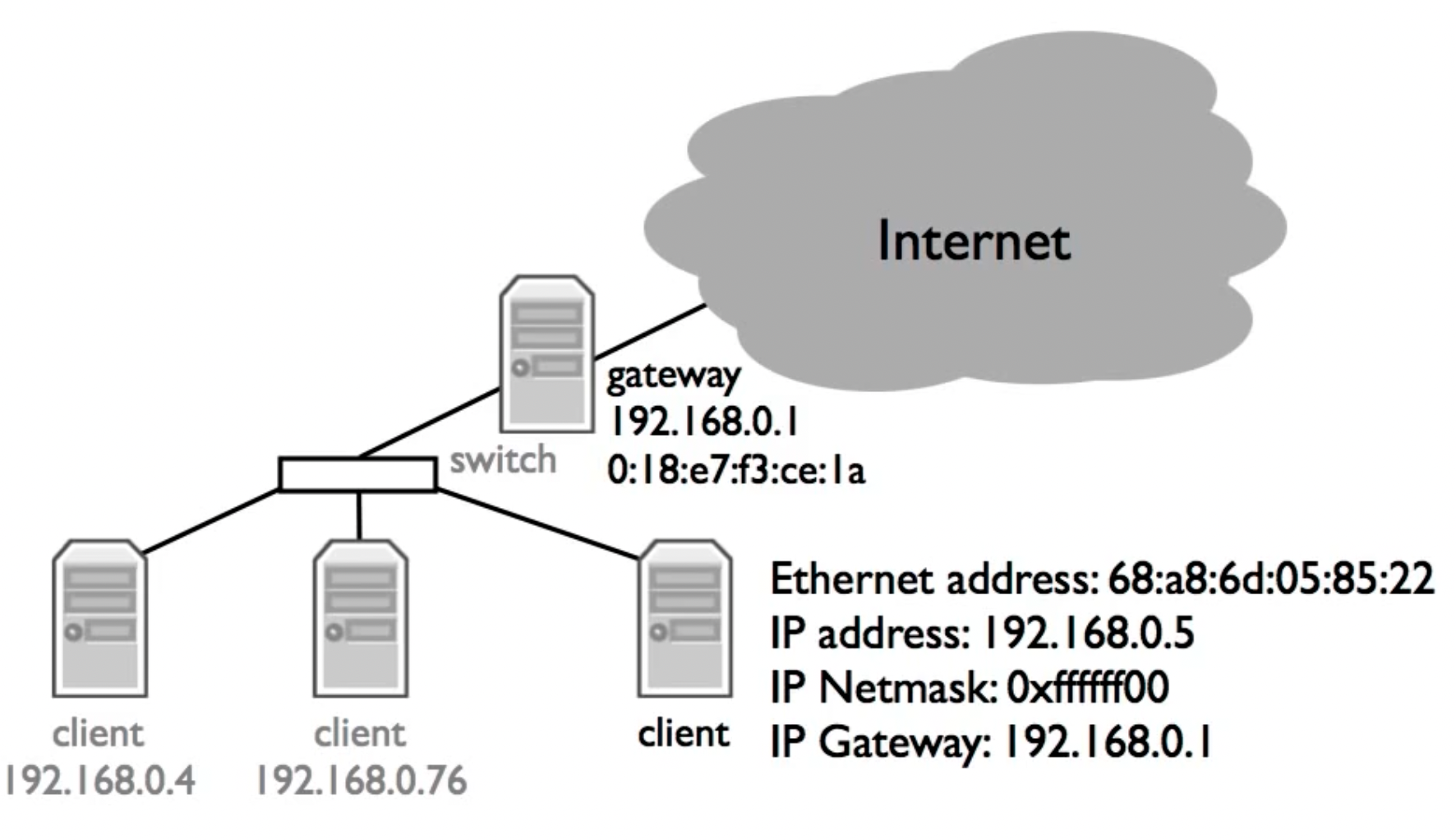
| Request | Reply | |
|---|---|---|
| Hardware | 1 (Ethrenet) | 1 (Ethrenet) |
| Protocol | 0x0800 (IP) | 0x0800 (IP) |
| Hardware Length | 6 (48bit Ethernet) | 6 (48bit Ethernet) |
| Protocol Length | 4 (32bit IP) | 4 (32bit IP) |
| Opcode | 1 (Request) | 2 (Reply) |
| Source hardware addr | 68:a8:6d:05:85:22 | 0:18:e7:f3:ce:1a |
| Source protocol addr | 192.168.0.5 | 192.168.0.1 |
| Destination hardware addr | ff:ff:ff:ff:ff:ff | 68:a8:6d:05:85:22 |
| Destination protocol addr | 192.168.0.1 | 192.168.0.5 |
TCP (stream)
三次握手建立连接:
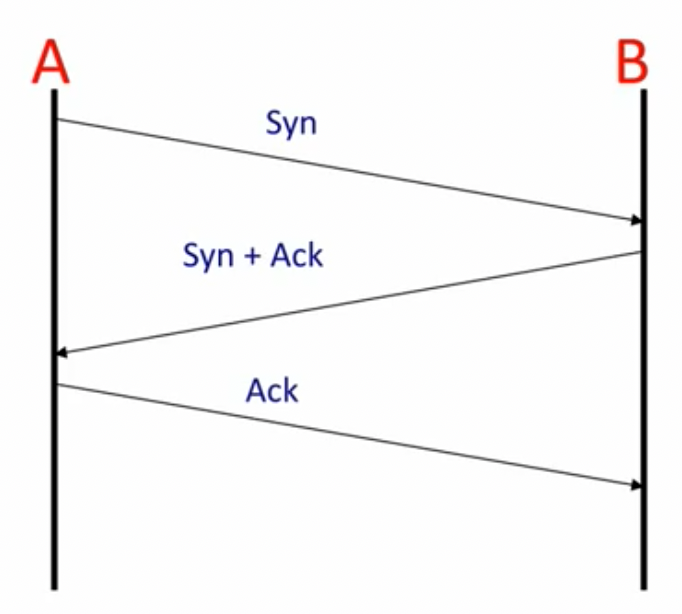
需要注意的是,最后一次ack可以捎带request,即不立即发送ack,而是和下次的数据一起发送过来。
四次挥手断开连接:
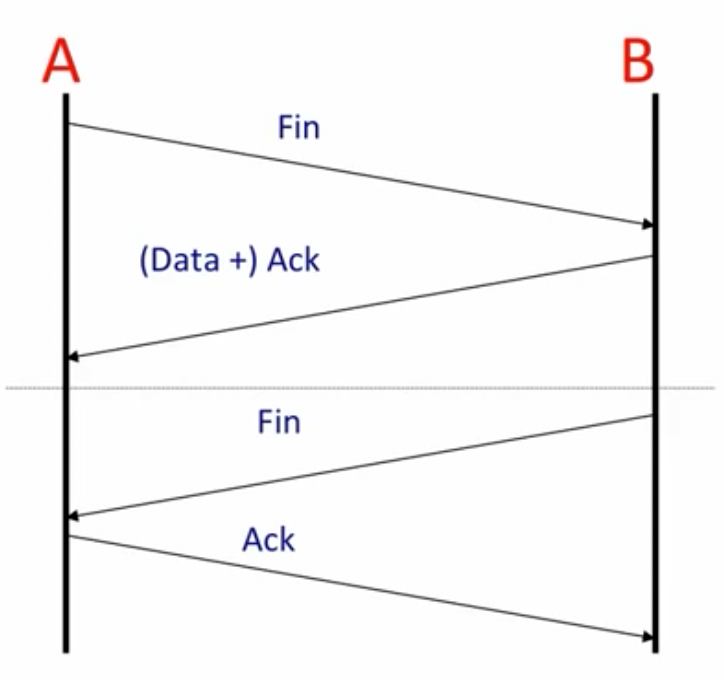
在TCP关闭连接时,系统需要确保能够安全的清理TCP连接,以避免因突然关闭socket而导致的如下问题的出现:
- Final ack lost in the network
- The same port pair is immediately reused for a new connection (but the socket has been closed by the system)
为了解决这个问题,我们就需要TIME_WAIT状态:
- Active close is sending FIN before receiving one
- Keep socket around for 2MSL (twice the Maximum segment lifetime)
TIME_WAIT也会带来问题,比如如果操作系统内有太多sockets处于该状态,那么其运行速度就会变慢。OS提供了一些可设置参数来解决这个问题:
- send RST and delete socket, set
so_LINGERsocket option to time 0 (noTIME_WAIT) - OS won’t let you re-start server because port still in use (set
SO_REUSEADDRoption to re-bind used port number)
TCP Service model

TCP通过4种方法确保可靠传输:
- 在接收到数据后,会发送确认消息告知发送成功;(REF: zhihu)
- 使用checksum检测数据是否有损坏
- 利用sequence number检测丢失的数据
- 利用flow-control防止发送者overrunning
TCP的拥塞控制机制会确保将网络流量均匀划分在该网络中的所有连接上。
TCP segment format
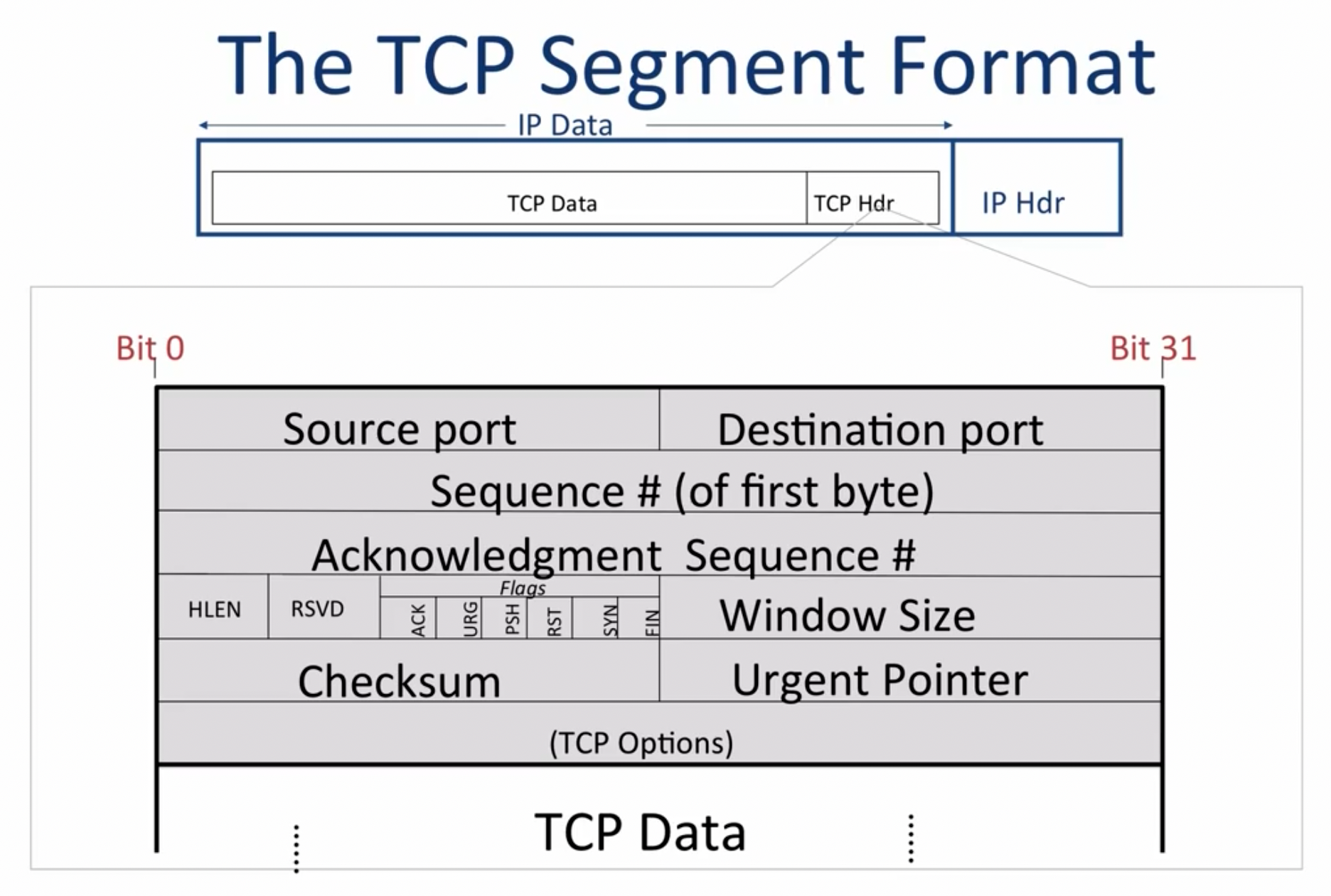
source port在另一侧的主机回复消息时,会作为destination port被传送。sequence number表示发送者即将发送的数据包的1st byte的位置(也可以理解为当前成功发送的数据位数),acknowledgement sequence #表示接收者期待的下一个byte的位置(当前成功接收的数据位数):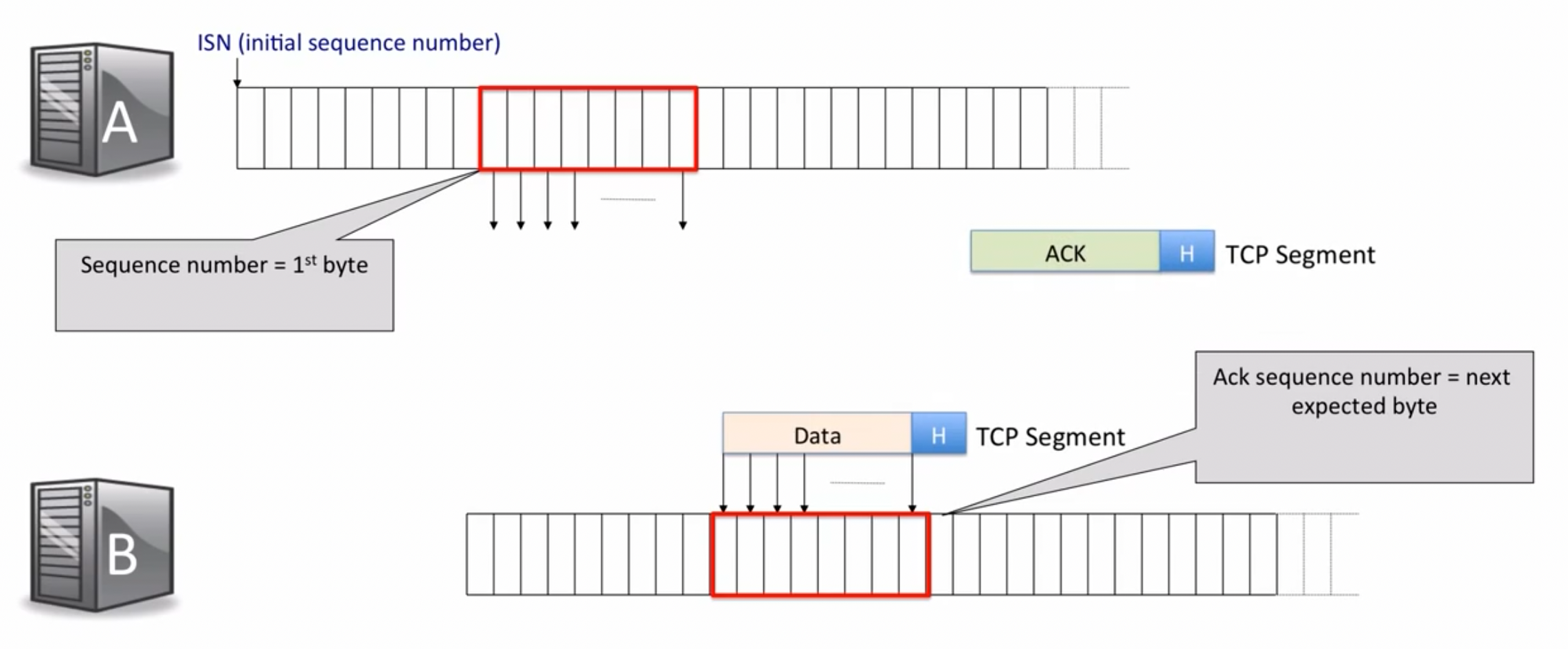
TCP协议拼凑接收到的数据包时,会通过seq来确定顺序,从而判断是否有数据包丢失。而在每一次发包、收包的过程中,接收方如何告知发送方数据已经收到?通过接收方的ack=发送方的seq+发送方的len。
checksum计算的是entire header+dataACK字段表示acknowledgement number字段是否有效SYN:part of the three-way handshakeFIN: part of the closing signal of one directionPSH: 如果设置为1,则在接收到数据后尽快交付给上层应用,而不是等待缓存满了之后再交付(time-critical data)
Unique ID of a TCP connection
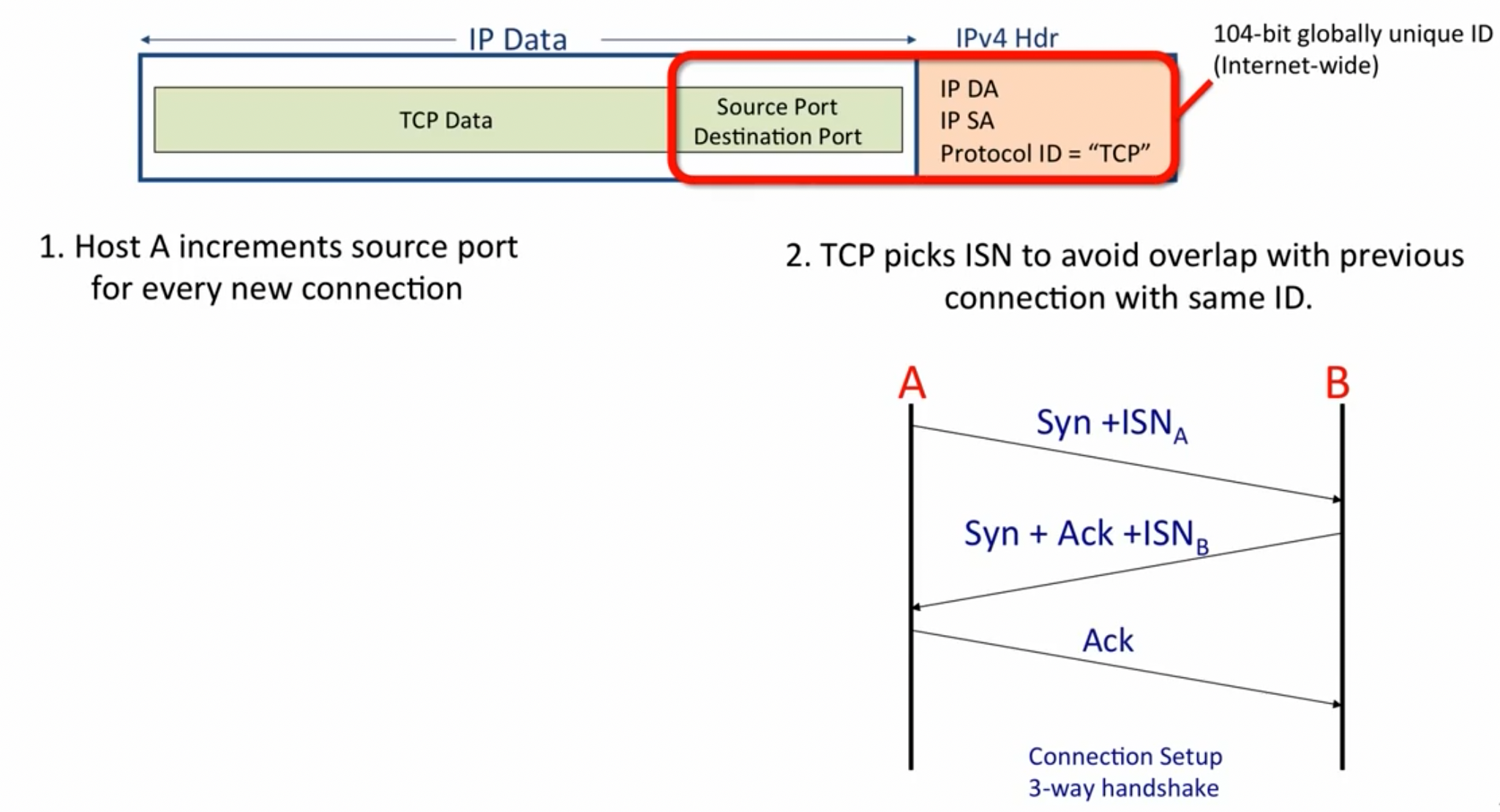
- 为了确保每次的ID是独特的,对于同一主机上的每一个新连接,都会增加
source port - 但当有大量连接突然出现时,上述操作仍有可能导致重复,所以还会利用ISN来减少重复的可能性,一个新连接的ISN是随机的
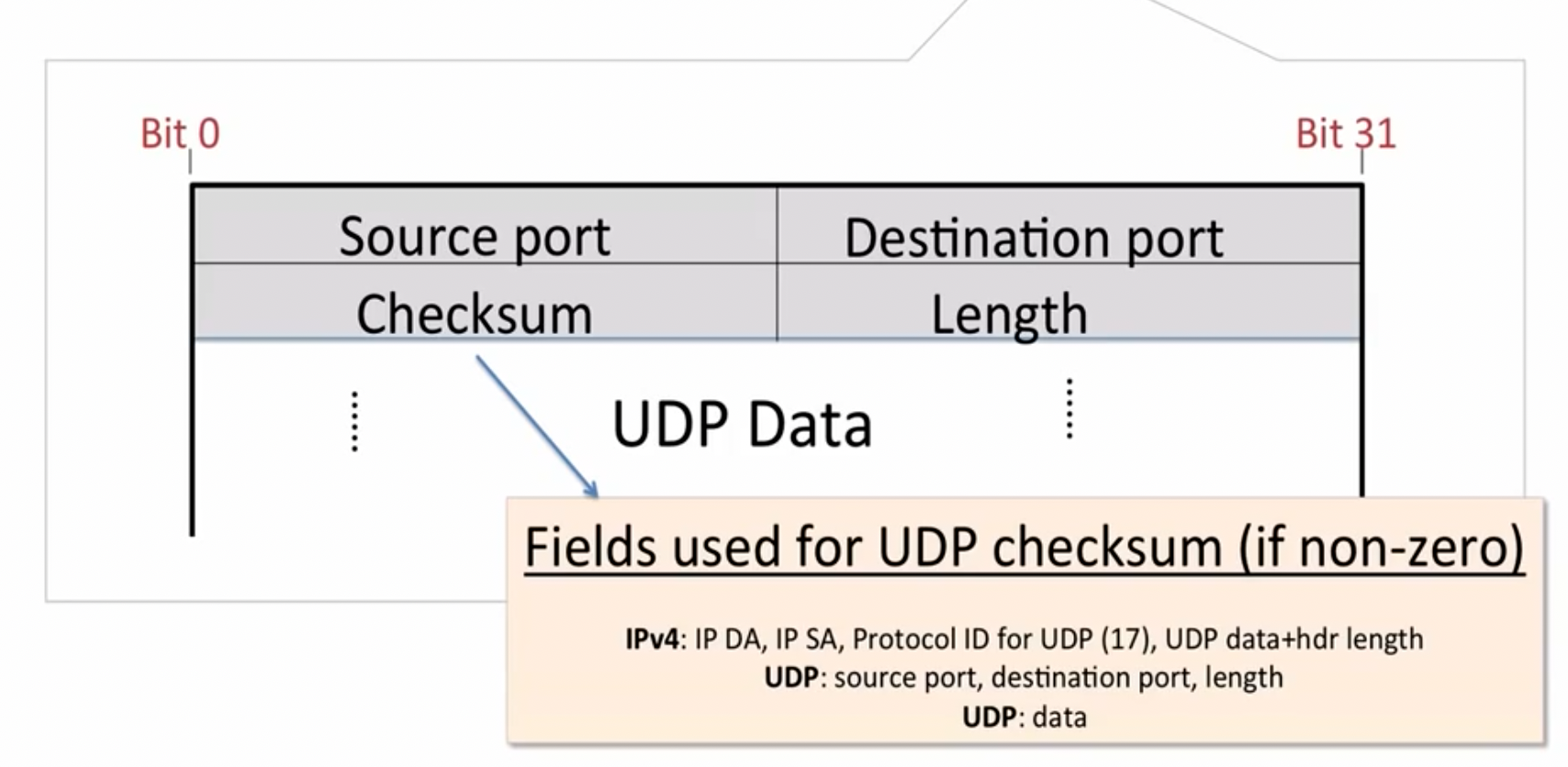
UDP (datagram)
UDP与TCP不同,他不是一个基于连接的协议。

当需要数据时,一个主机向另一个设备发送请求即可,企业不保证数据传送的有序性和一定到达。UDP的数据格式也比TCP简单很多。
ICMP
网络层依靠如下几个机制运行:
- IP: The creation of IP datagrams & Hop-by-hop delivery from end to end
- Routing Tables: Algorithms to populate router forwarding tables
- Internet Control Message Protocol (ICMP): Communicates network layer information between end hosts and routers & reports error conditions & helps us diagnose problems
ICMP协议在网络层之上运行(transport layer),一种常见的情况是当路由器在转发表内找不到对应的路径时,会通过ICMP协议向发送消息的主机发送一个Destination Network Unreachable的消息:

ICMP Service Model
- Reporting Message: Self-contained message reporting error
- Unreliable: Simple datagram service - no retires
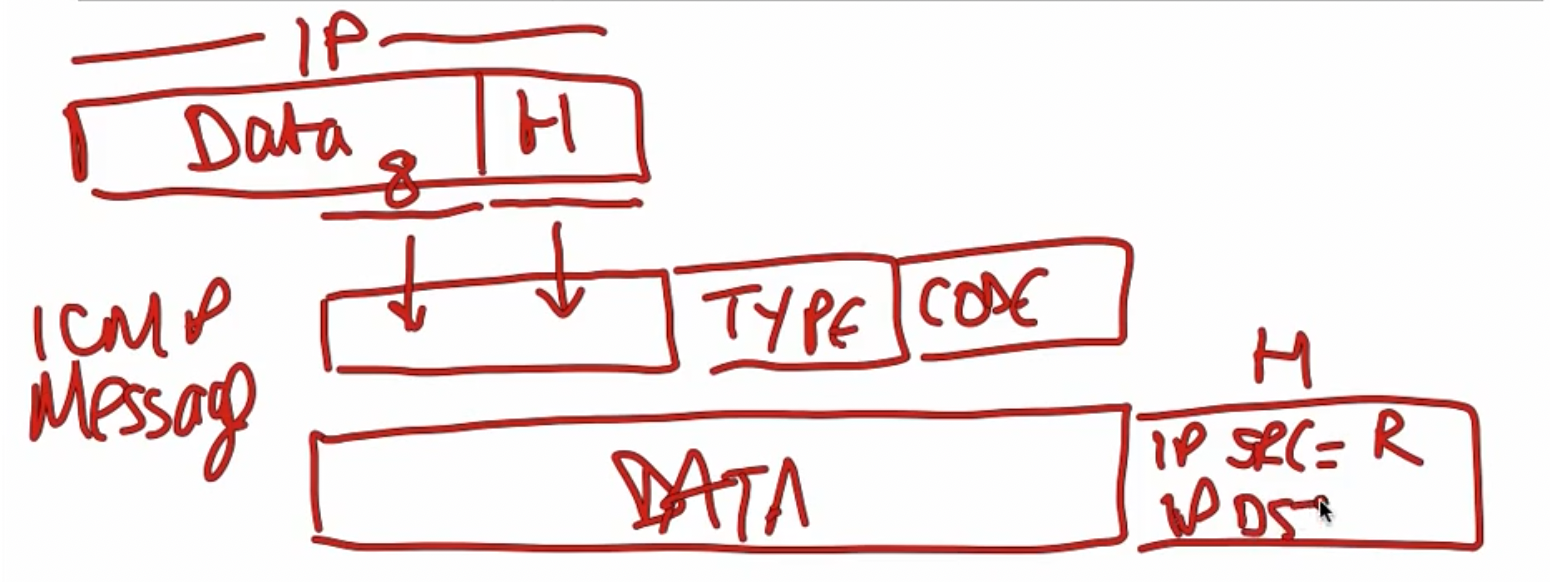
当路由器打算向主机返回一个报错信息时:
- 从接收的IP数据包中取出前8个byte,以及IP header,结合type+code组成ICMP message
- 将ICMP message放入新的IP data部分内,设定IP source addr为router,传递回原本的主机
一些常用的ICMP message type:
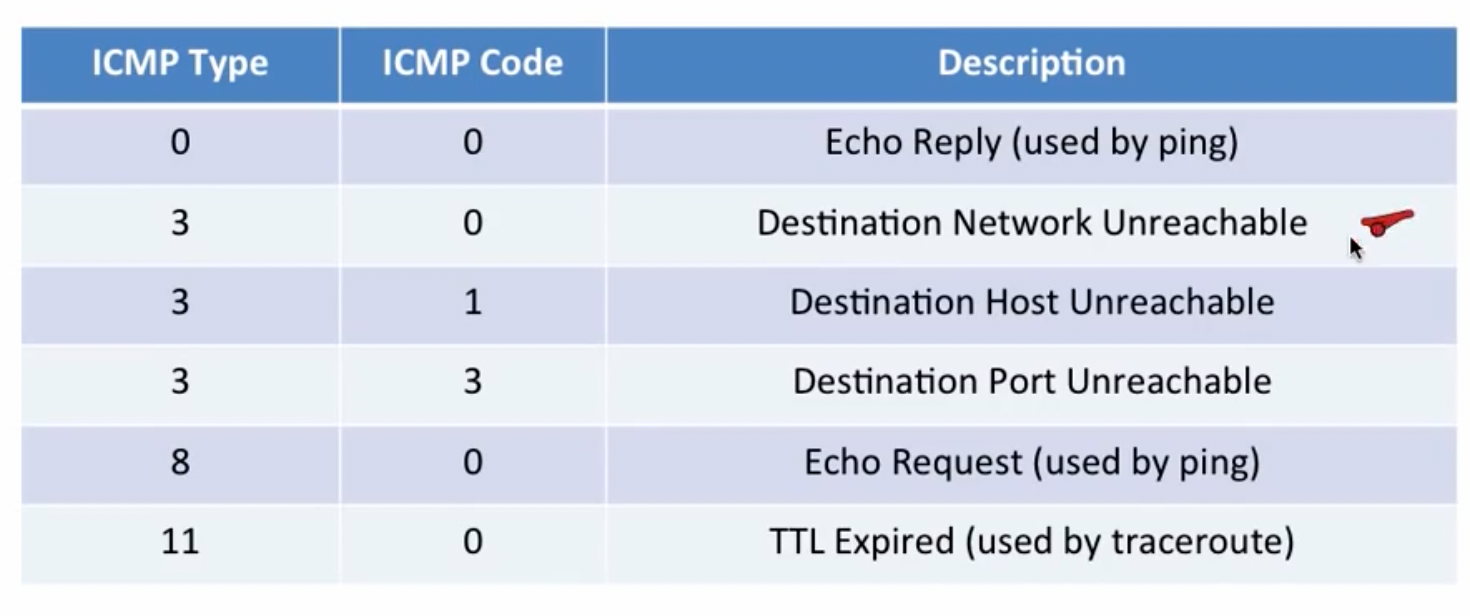
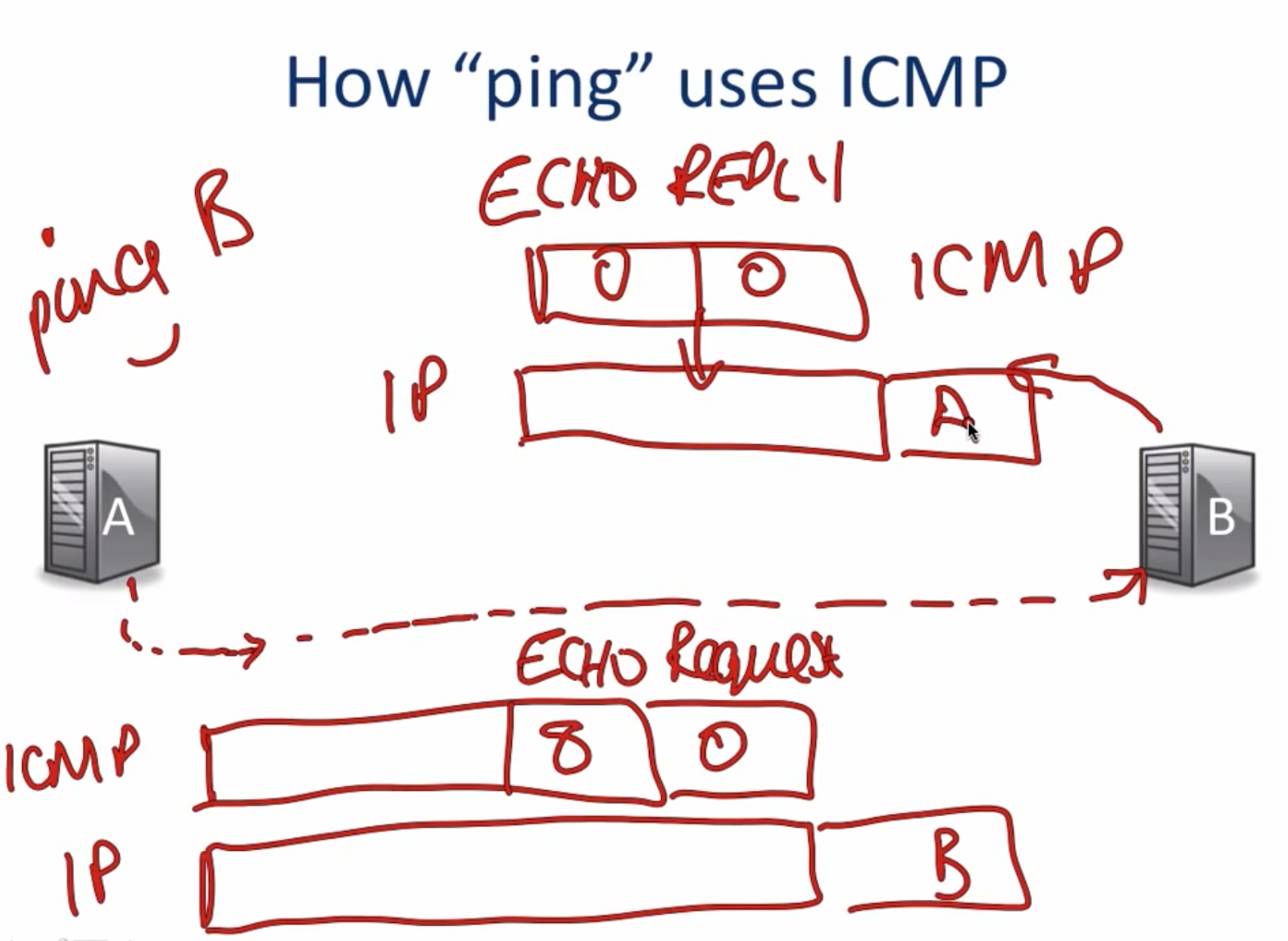
ICMP最常见的使用场景为ping和traceroute指令:
ping
traceroute
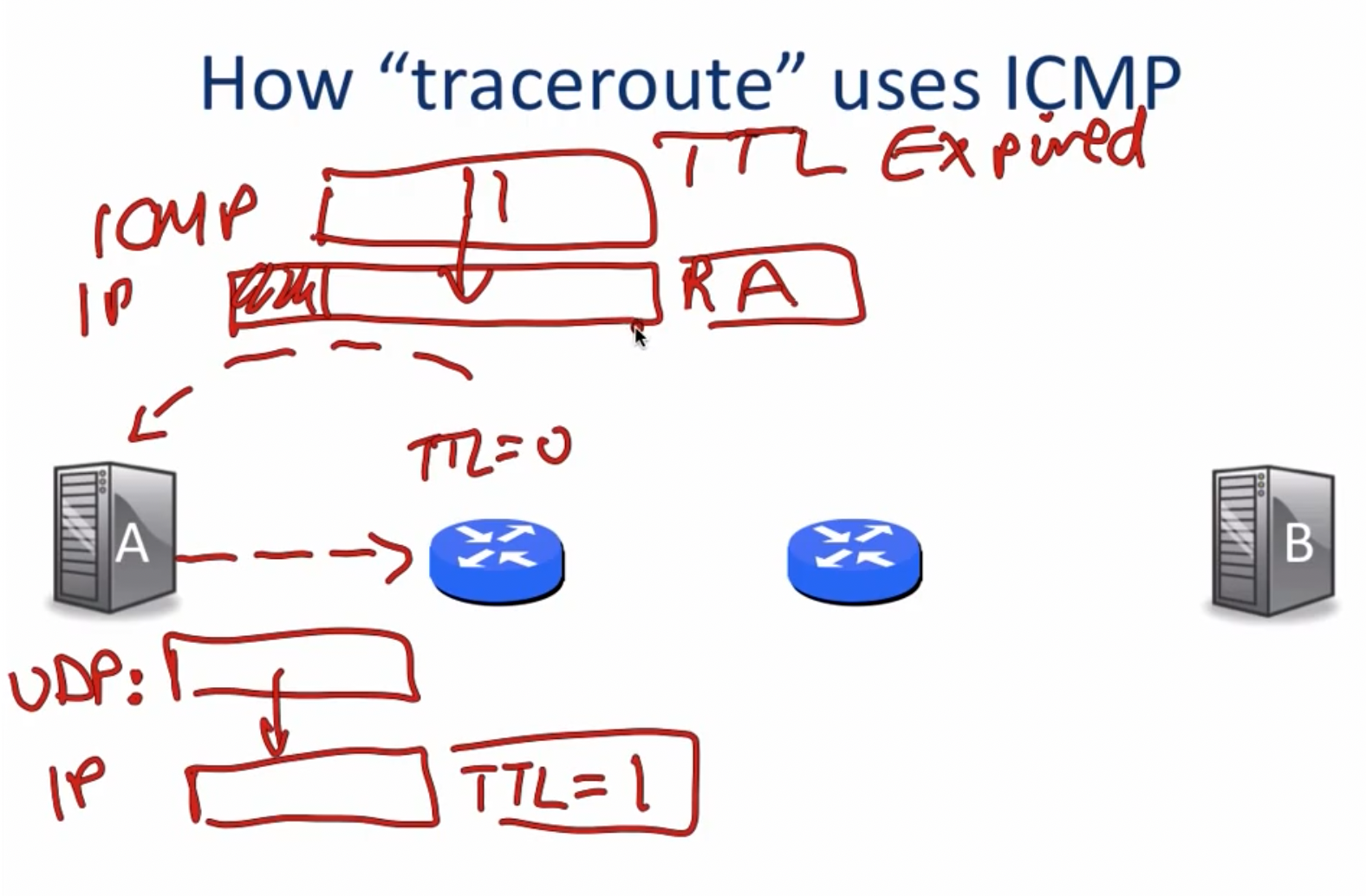
traceroute指令相对于ping则要稍微复杂一些,traceroute指令可以用于探测两个主机之间经过的传输路径和每个hop之间需要的传输时间。对于第i次指令传输的开始,主机A使用UDP进行传输,并将TTL(Time-to-Live)设置为i(第一次为1,第二次为2,以此类推),如此一来,当TTL为0时,路由器将强迫数据包返回,于是路由器会将ICMP的message设置为TTL expired对应的代码,并将数据传回主机A,主机A便可以借助其发出数据包的时间和接收到数据包的时间判定此次hop的传输时间。
traceroute在送出UDP datagrams到目的地时,它所选择送达的port number 是一个一般应用程序都不会用的号码(30000 以上),所以当此UDP datagram 到达目的地后该主机会送回一个「ICMP port unreachable」的消息,而当traceroute 收到这个消息时,便知道目的地已经到达了。
End-to-End Argument
这篇论文先前读过,具体就不在这里赘述。在原本的end-to-end argument中,允许在中间层添加一些机制来提高整个系统的运行效率,比如在Wi-Fi中,由于无线传输的TCP接收的成功率只有50-80%,远不及有线传输的99.99%,所以在另一侧的主机收到数据包后,会返回一个link layer acknowledgement给发送端,否则发送端会重复发送数据包。
但是在strong end-to-end argument中,禁止了在中间层添加这种机制,两者各有利弊。
Error Detection: 3 Schemes
三种错误检测的方法:CRC (ethernet)、MAC (TLS)、checksum (IP)。


checksum
IP, TCP, UDP均适用ones’s complement checksum算法,该算法步骤如下:
- 将校验和设置为0,之后将数据的每个16bit的字相加
- 对于进位,使用循环进位,即添加到结果的末尾(e.g. 0x8000+0x8000=0x0001)
- 对结果取反,放到checksum位置中
校验步骤如下:
反码求和,结果应当为0xffff,如果不是,则说明发生错误。
校验和检测很容易计算,速度也比较快。但是他只具备检测single bit error的能力。
Cyclic Redundancy Check (CRC)
循环冗余校验码被用于数据链路层的ethernet错误检测,很容易在硬件中实现,并可以实现增量计算(incremental computation),也被称为多项式编码。
多项式编码的基本思想是将位串看成是系数为0或1的多项式,一个k位帧看成是一个k-1次多项式的系数列表;多项式的算术运算以2为模来完成,加法没有进位,减法没有借位(都等同于异或)。
使用多项式编码时,发送方和接收方必须先商定一个生成多项式
$$G(x)$$,其最高位和最低位必须为1,为了计算多项式
$$M(x)$$的CRC,他必须比
$$G(x)$$长。计算CRC的算法如下:
- 假设$$G(x)$$的阶为r,在帧的低位端加上r个0位,使得现在为m+r位,设新的多项式为$$x^rM(x)$$
- 利用模2除法,用对应于$$G(x)$$的位串去除对应于$$x^rM(x)$$的位串
- 利用模2减法,从对应于$$x^rM(x)$$的位串中减去余数(总是小于等于r位),该结果作为将被传输的带校验和的帧,设为$$T(x)$$
显然
$$T(x)$$可以被
$$G(x)$$除尽,如果不能,说明传输过程中出现问题。
CRC可以检测如下错误:
- 一位错误
- 两个独立的一位错误
- 奇数个位发生错误
- 带r个校验位的多项式编码可以检测到所有长度小于等于r的突发错误(突发错误:burst of errors, 初始位是1,然后是0和1的混合,最后一位也是1)
- 如果突发错误长度是r,不正确的帧被当作有效帧的概率是$$1/2^{r-1}$$
- 如果突发错误长度是r+1,…的概率是$$1/2^r$$
证明可以参考Computer Networks (Fifth version).
Message Authentication Code (MAC)

该算法主要用于保护敌对攻击,由于翻转M任意一个bit之后得到的C都是随机的,所以我们并不能确保一定能够检测出某种类型的错误,所以说他的检测效果实际上没有CRC好。

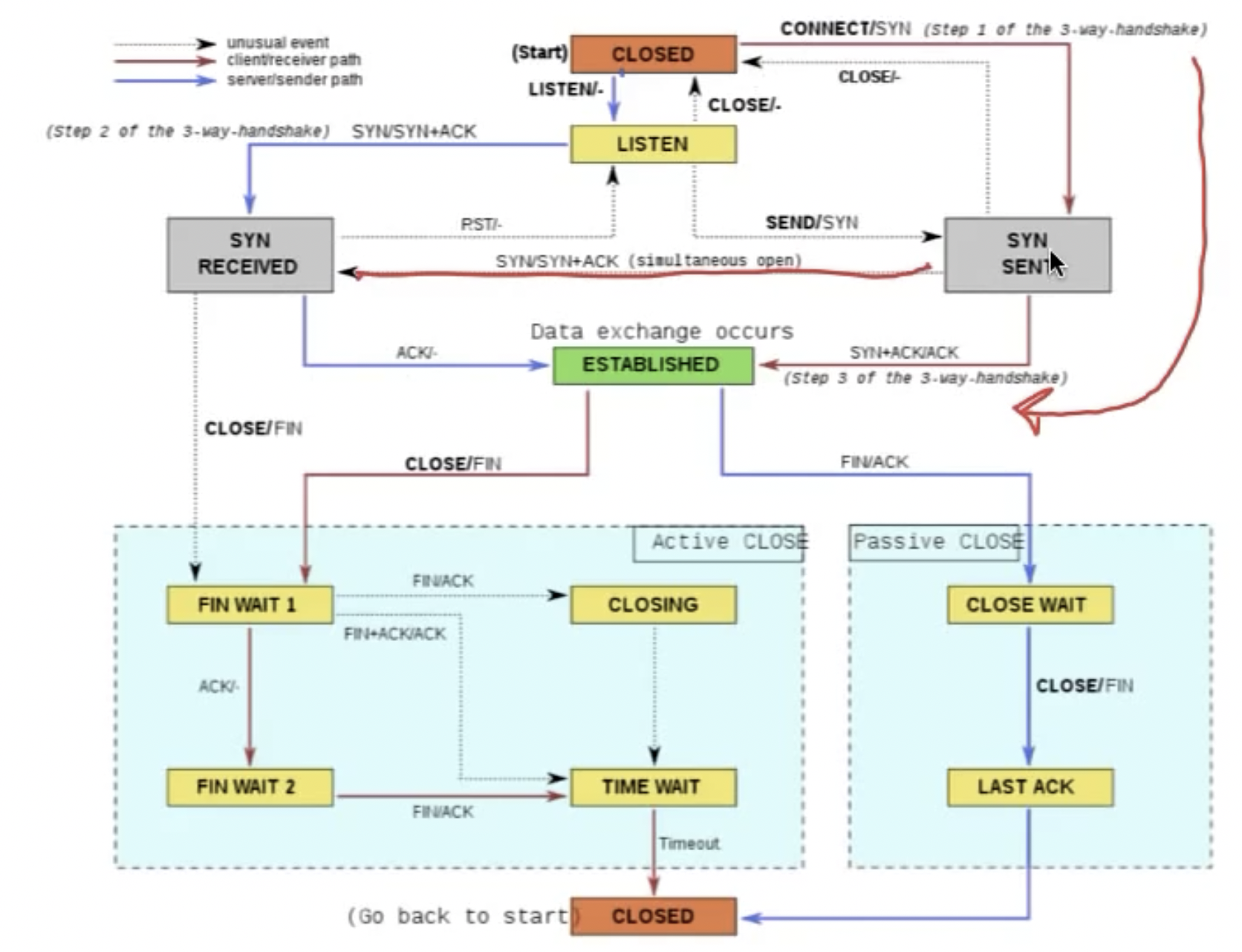
Finite State Machine (event/action)
以TCP为例:
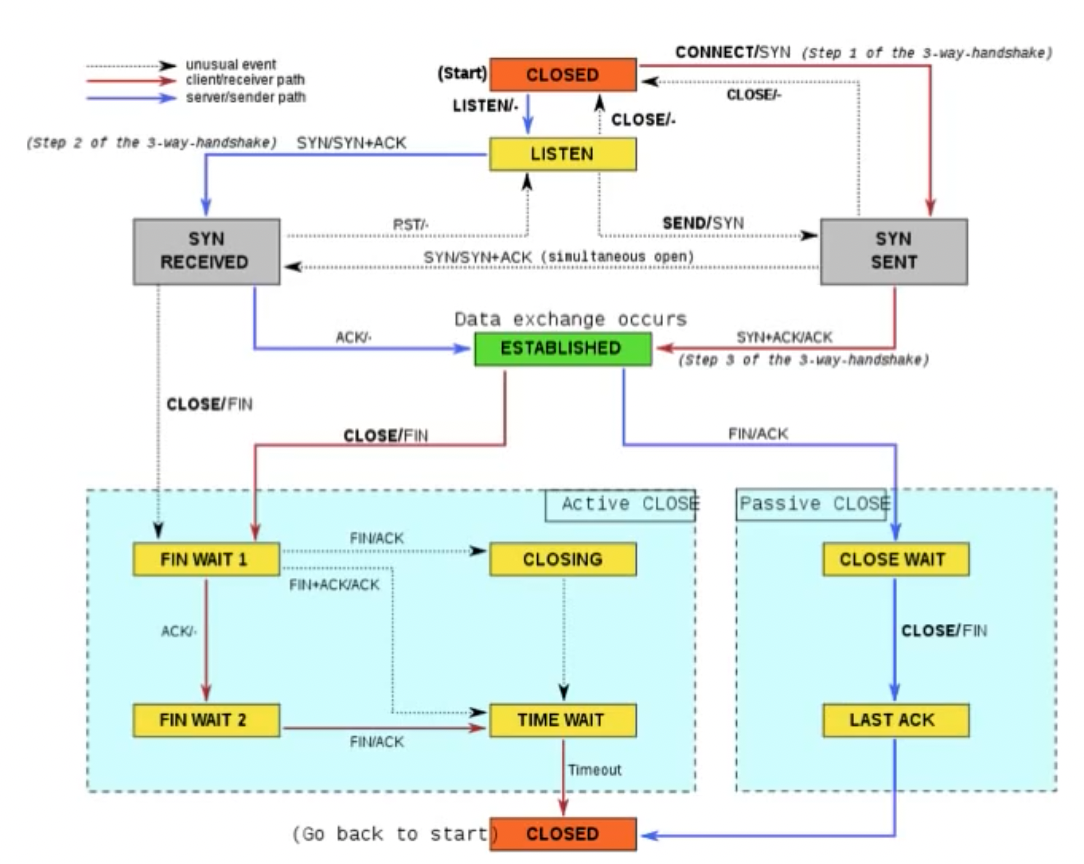
其中,上方的simultaneous open表示两方同时收到SYN,之后一起发出SYN+ACK,这种情况常见于P2P。在图的下方的TIME_WAIT即先前提到的为了安全清理而设置的状态,CLOSING与TIME WAIT的区别在于CLOSING没有收到对方返回的ACK。
Reliable Communications
为了实现流量控制,我们想要做到发送端的发送频率不要超过接收端的最大承载能力,这需要接收端给发送者反馈,一般有两种方法实现:
- Stop and wait
- Sliding window
Stop-and-Wait
在任意时刻,最多只有一个数据包在传送中;当发送端接收到ack后,发送新数据,如果其发现timeout,则sender重新发送当前数据。
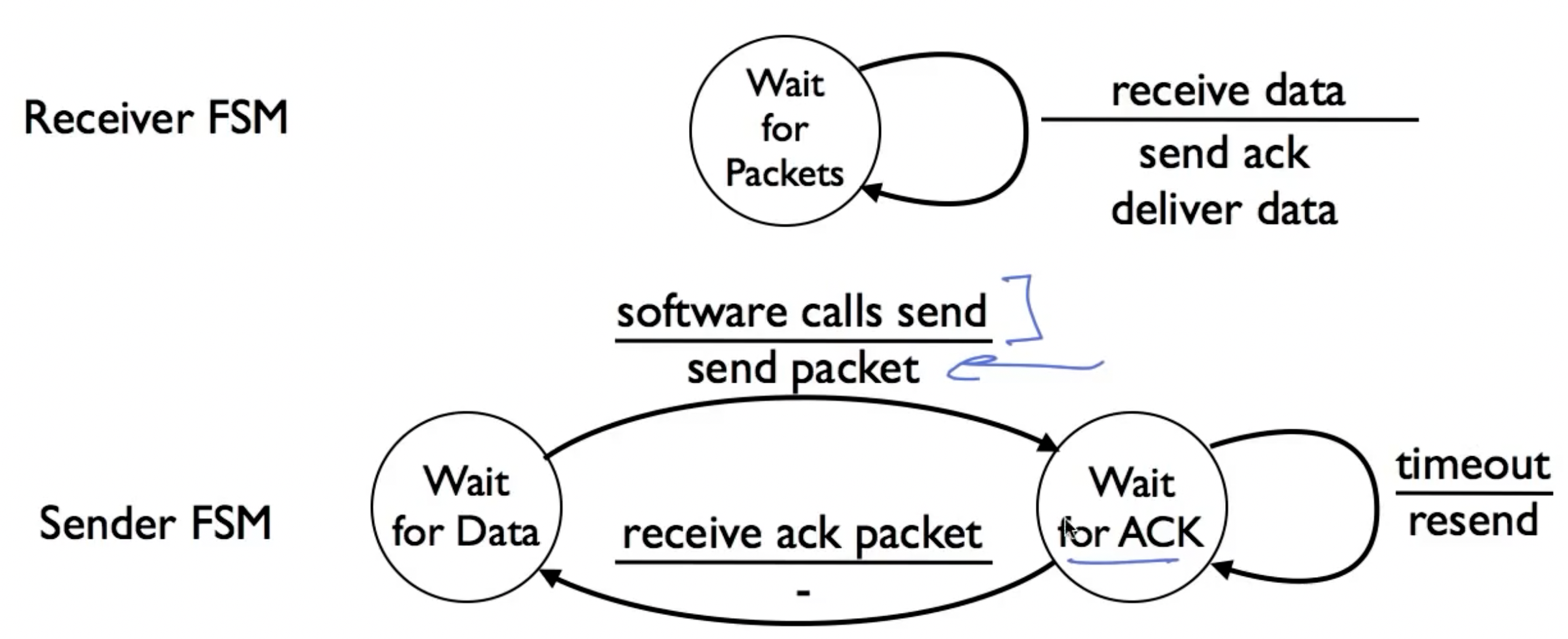
注意下图中的第四种情况:
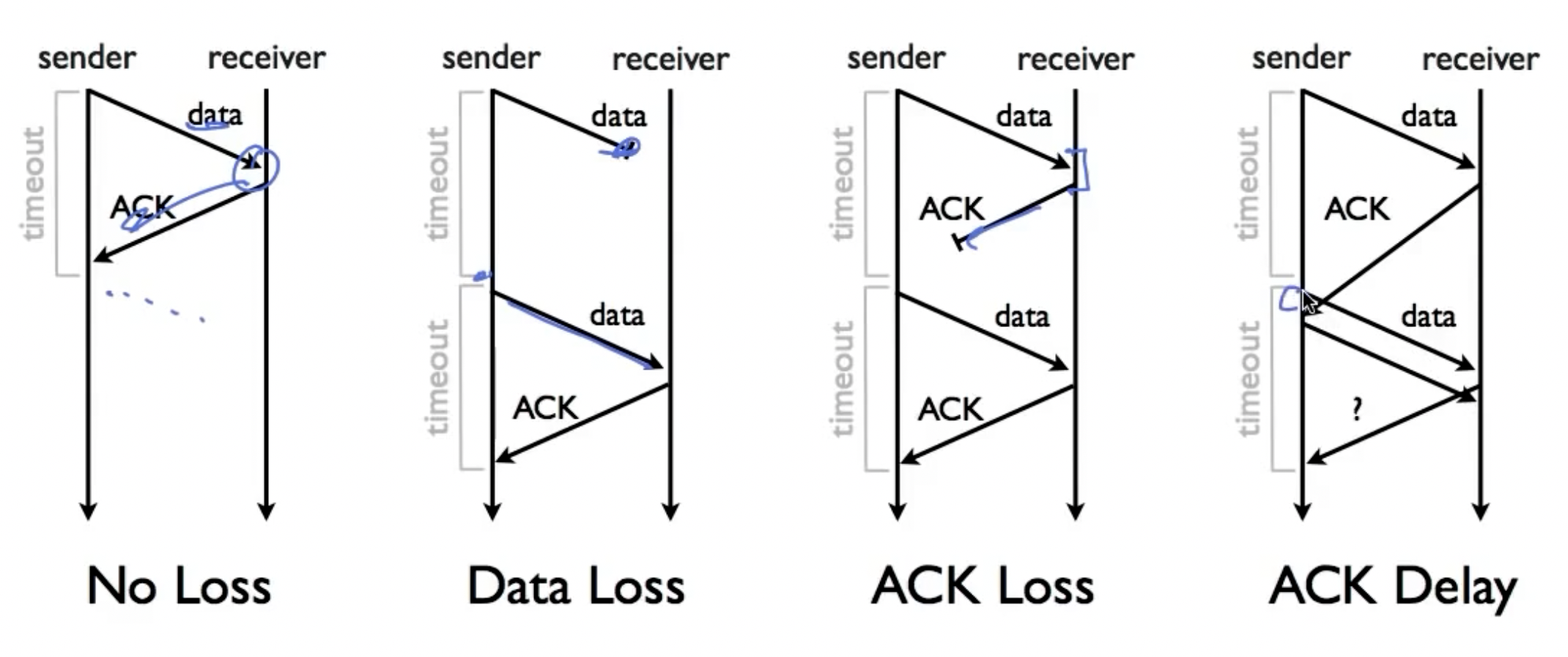
为了辨别发送的数据是重复发送的数据还是新数据,对发送的数据包和ack使用1-bit counter。

Sliding window
数据链路层和传输层都有滑动窗口协议,两者类似。
Stop-and-Wait的问题在于主机的计算资源没有得到充分利用,空闲时间太多(在等待数据包in flight的过程),滑动窗口协议的特点如下:
- Generalization of stop-and-wait: allow multiple un-acked segments
- Bound on numbewr of un-acked segments, called window
- Can keep pipe full
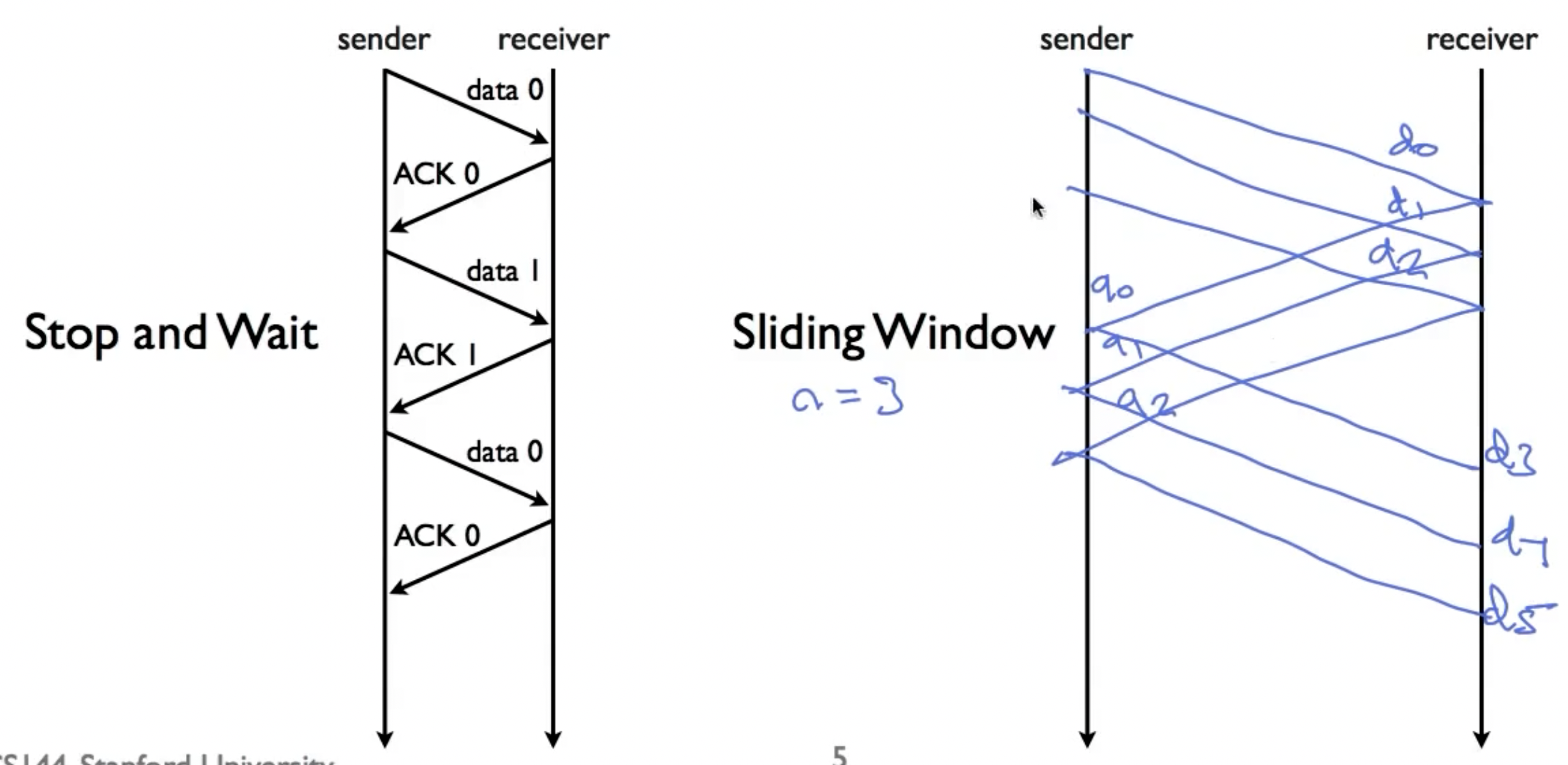
在TCP的滑动窗口协议中,发送者为每一帧配备一个序列号,就是先前提到过的sequence number。发送端维护三个变量:
Send window size(SWS, buffer up to SWS segments)Last ack received(LAR)Last segment sent(LSS)
并保证:
$$(LSS-LAR)\le SWS$$,即确保in flight的帧数不要超过窗口长度。
而对于接收端,也维护三个变量:
Receive window size(RWS)Last acceptable segment(LAS)Last segment received(LSR)
并保证:
$$(LAS-LSR)\le RWS$$,即确保in flight的帧数不要超过接收窗口长度。如果接收的数据包序列号小于LAS,则发送ACK。
不论是发送端还是接收端端窗口,本质上都是缓冲区。
滑动窗口协议可以分为两种,Go-back-N和Selective-Repeat。
- Go-back-N: 接收方简单丢弃所有到达的后续帧,而且针对这些丢弃的帧不返回ack。这种策略一般用于窗口大小为1的情形(因为相当于没有缓冲区)。这意味着如果在当前窗口内有一个分组没有被接收,则之后超时重传需要重传之后的所有分组。在该协议中,使用累计确认(
cumulative ack),即当帧n的ack到达时,我们认为前边的所有帧也已经被确认接收。 - Selective-Repeat: 不需要完全按照顺序ack,对于期望的分组(按照顺序无遗漏的)交付上层,如果期望的分组没有得到,就先缓存本地,这样之后超时重传也只需要重传丢失的那些分组即可,缓存的分组不需要再次ack。selective-repeat方法常与否定策略结合使用,即当接收方检测到错误时,就发送一个否定确认(NAK)触发该帧的重传操作,而不需要等到相应的计时器超时。
需要注意的是,这两种方法在发生packet loss时,都采用duplicate ack的方法告诉发送端哪个packed发生丢失。
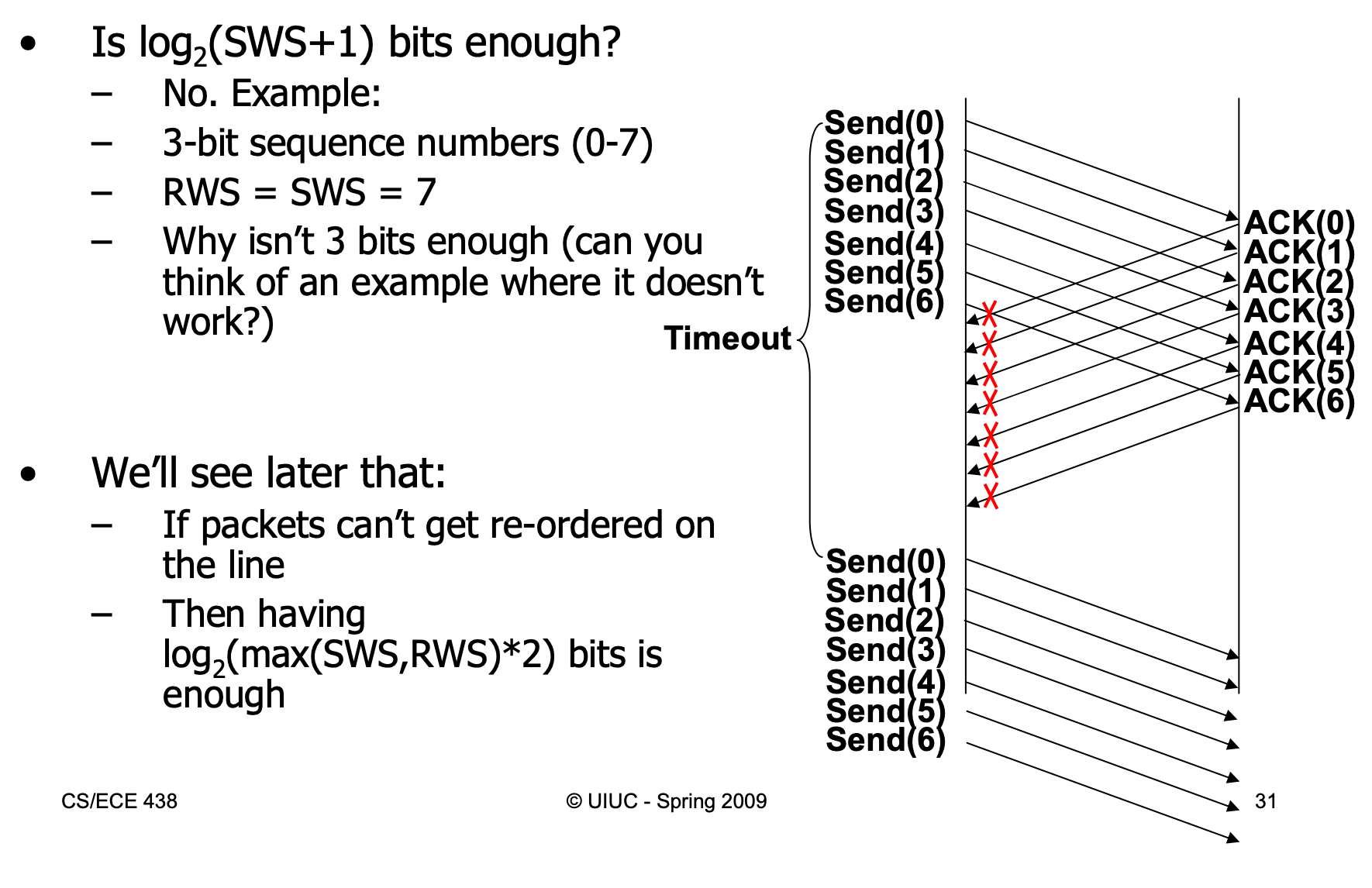
由于可能的超时重传的触发,滑动窗口协议对sequence space也有要求:

对于go-back-N协议下的序列空间,我们只需要SWS+1个序列空间号,参见《Computer Networks》 (fifth version, P 184)。 考虑RWS=SWS的情况,如果所有的数据包全部发出,但是所有的ack都没有传回,则我们需要让sequence space为RWS+SWS以便在下次接收所有数据包时知晓是所有旧的数据包还是新的下一组数据包:
Packet Switching
在包交换之前,先了解电路交换(circuit switching),当电话呼叫通过一个交换局时,在电话入境线路与某一条出境线路之间就会建立起一个物理连接,其重要特点就是在发送数据之前需要建立一条端到端的路径,但一旦建立连接,唯一延迟是电磁信号的传播时间,相当于在光纤链路上有成千上万的电话呼叫被复用,其为每一个建立的链路预留了带宽,这些对应于每一个连接的信息在连接关闭后需要被清除。
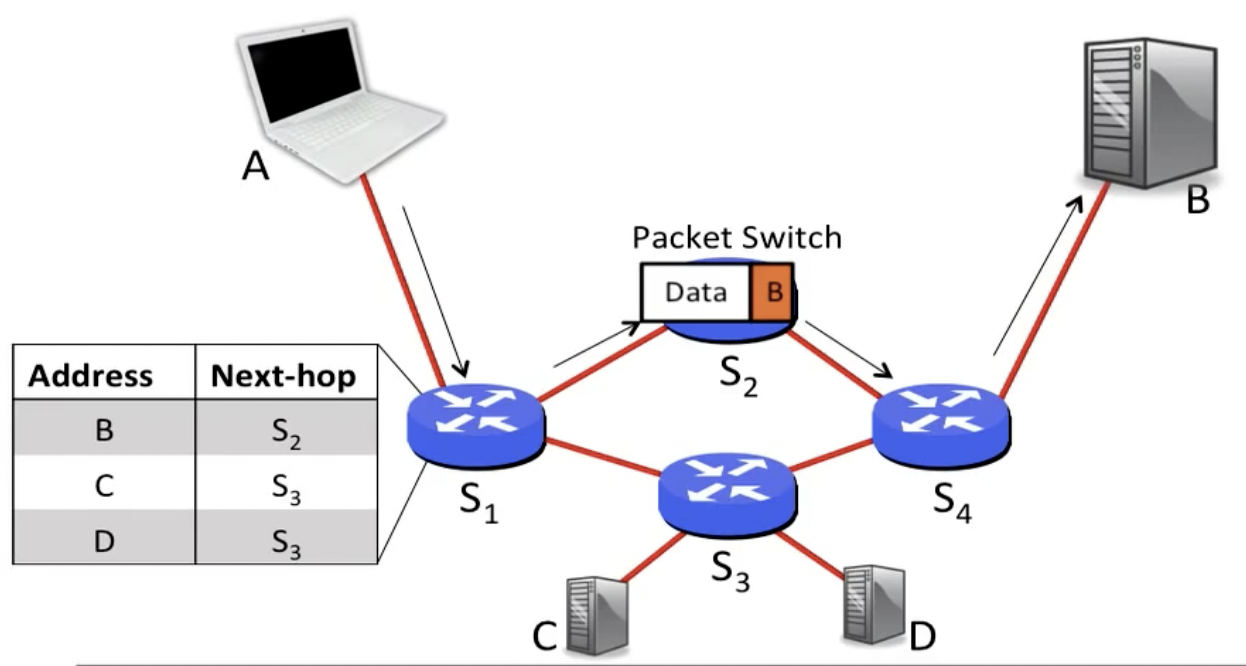
替代电路交换的方法就是包交换(packet switching),该技术使用路由器的forwarding table完成存储-转发任务(路由器带有buffer功能)。包交换可以更快的将包发出,无需事先建立专用路径,但是由于没有为每一个包预留带宽,所以可能会遇到排队延迟(queueing delay),需要等待一个包发出后,另一个包再出发。同时packet switching也具有更好的容错性:对于电路交换,如果一个交换机坏掉,那么所有使用它的电路都将被终止,但是packet switching可以绕过那个交换机。
在包交换的过程中的端到端延迟由三个类型构成:

End-to-end delay:
$$t=\sum_i(\frac{p}{r_i}+\frac{l_i}{c}+Q_I(t))$$由于其中queueing delay的不确定性,在诸如YouTube等在线视频播放工具中,常需要建立buffer来防止因过长的延迟导致不佳的播放体验。
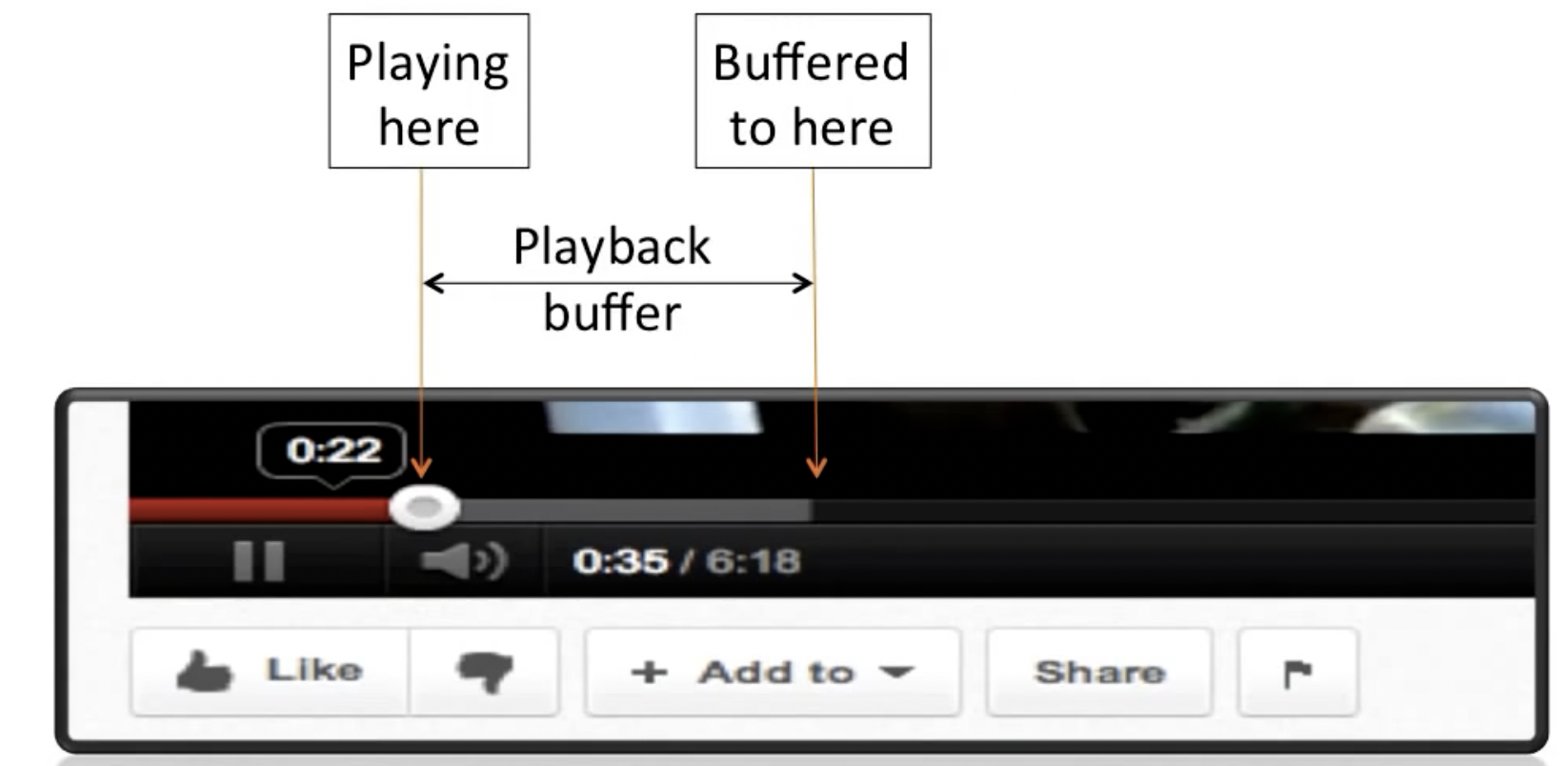
下图展示了playback buffer的作用:
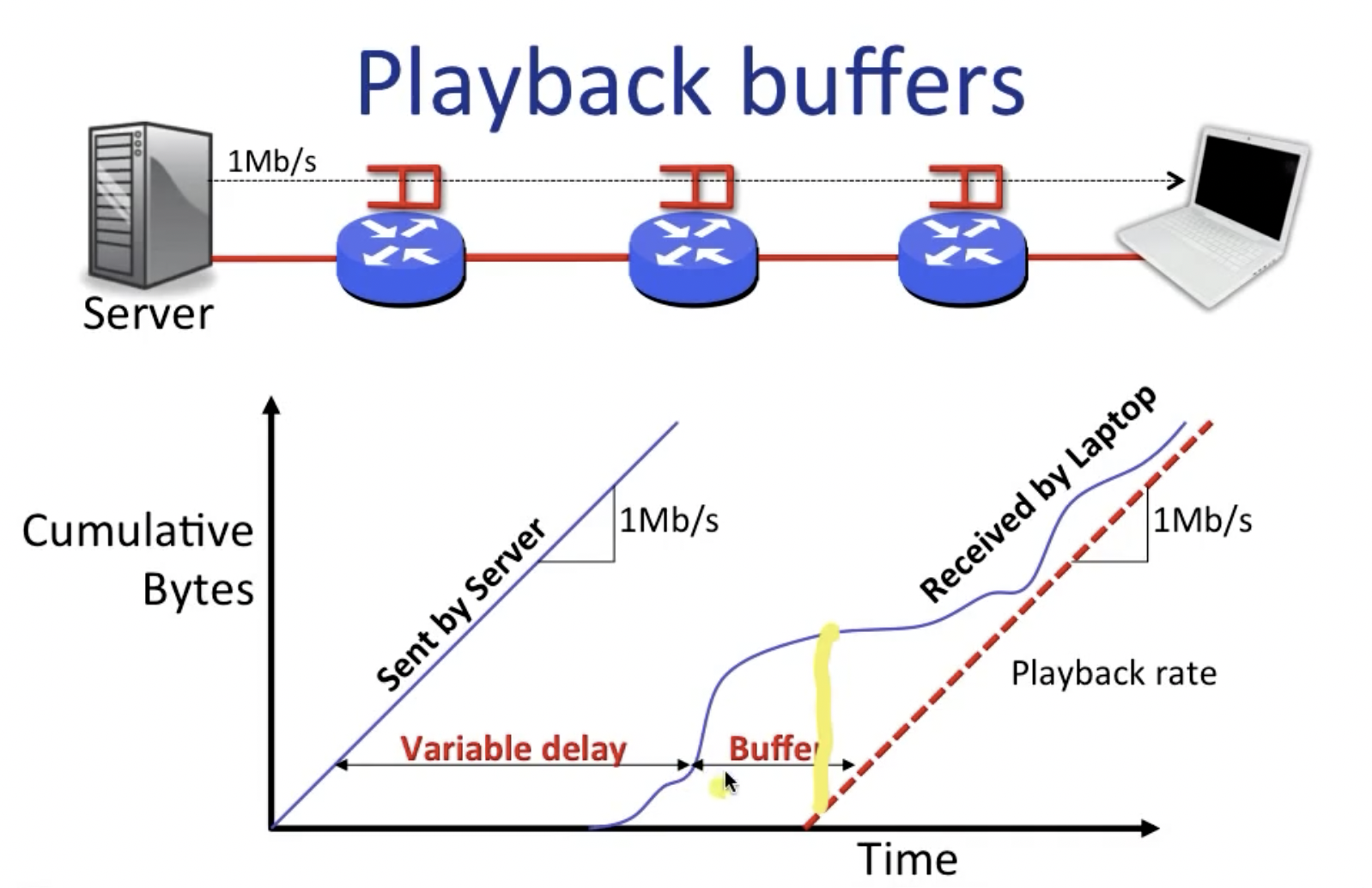
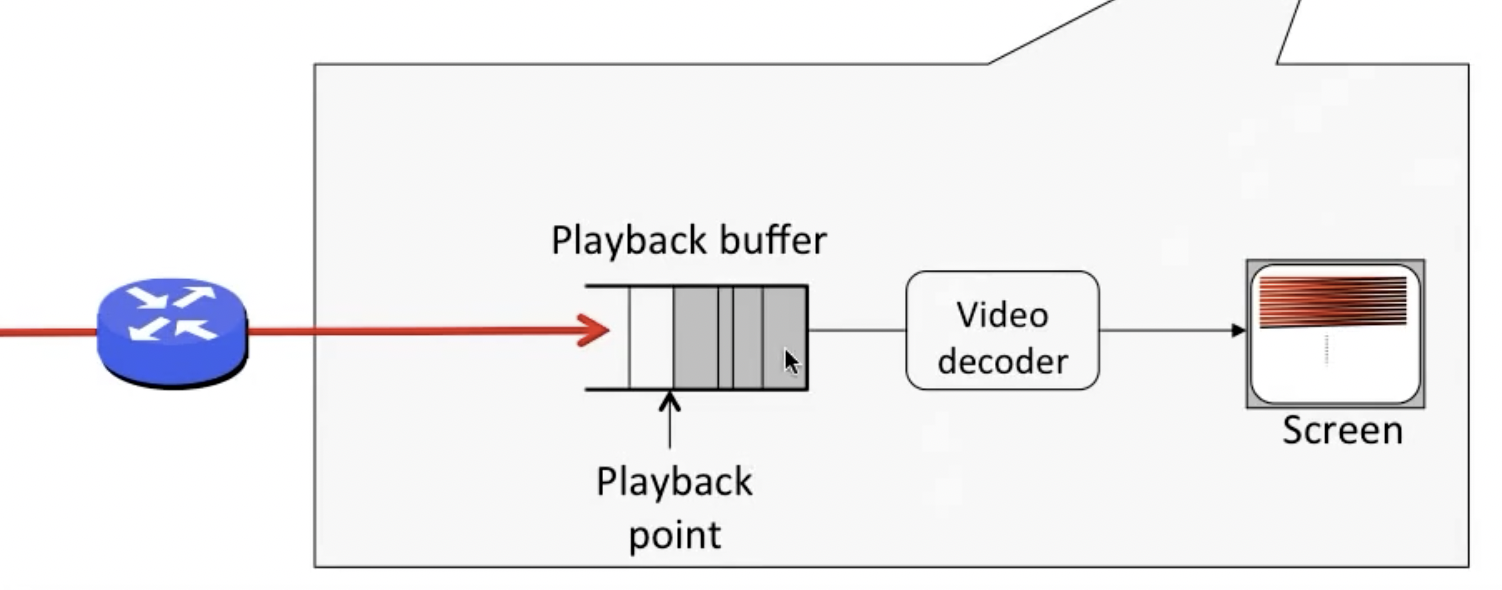
其中,playback rate可以理解成正常播放的速度,可以看到在视频进度条向前走之前,需要现在系统内积累一定大小的缓冲区,当达到playback point之后,会进行视频解码并向屏幕输出,即上图中黄线所标识的点位。
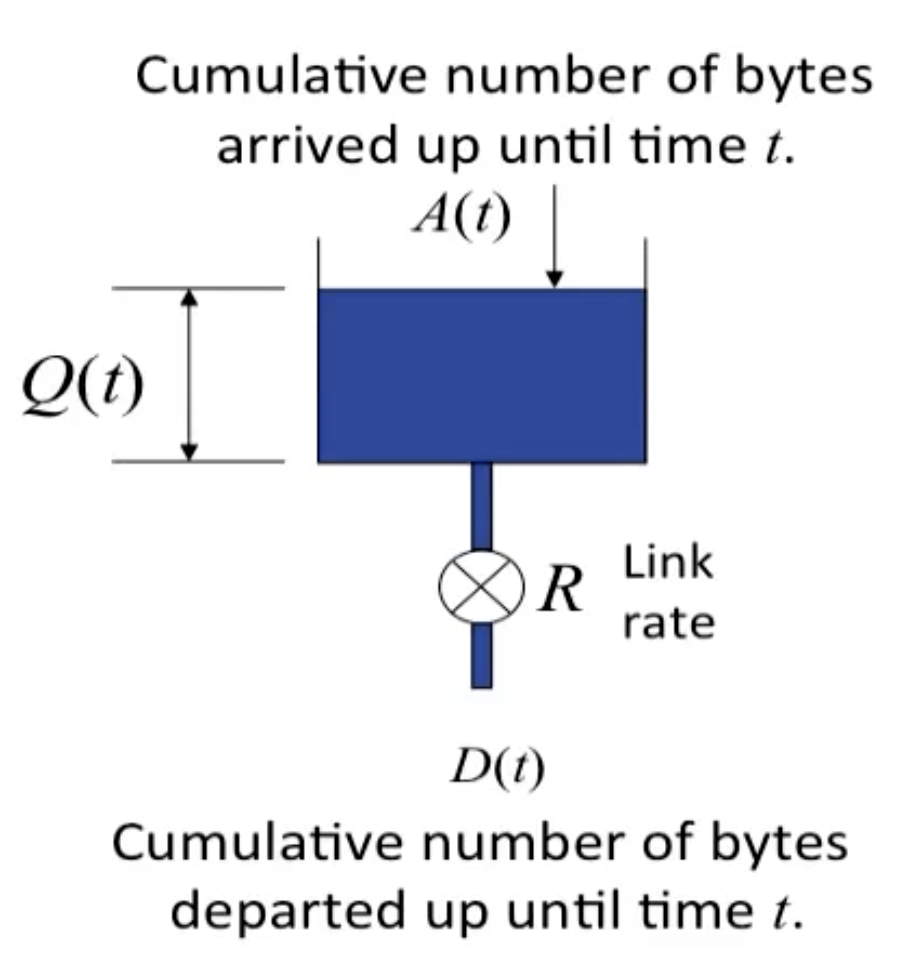
Queueing model
一个简单的队列模型如下所示:
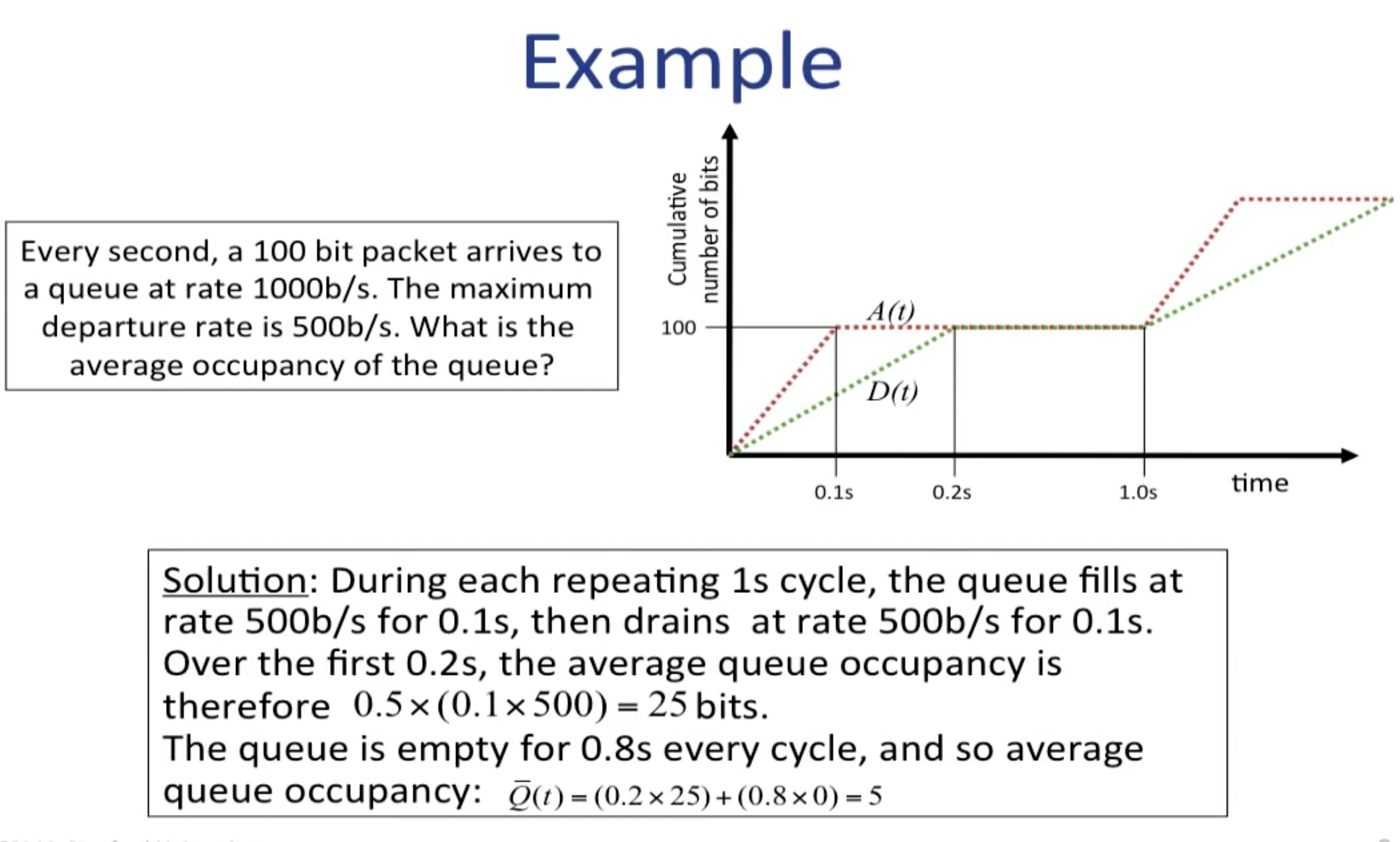
在包交换中,一整条信息会被分成几个包发送,之所以不将他们在一个包内发送的原因如下图所示:
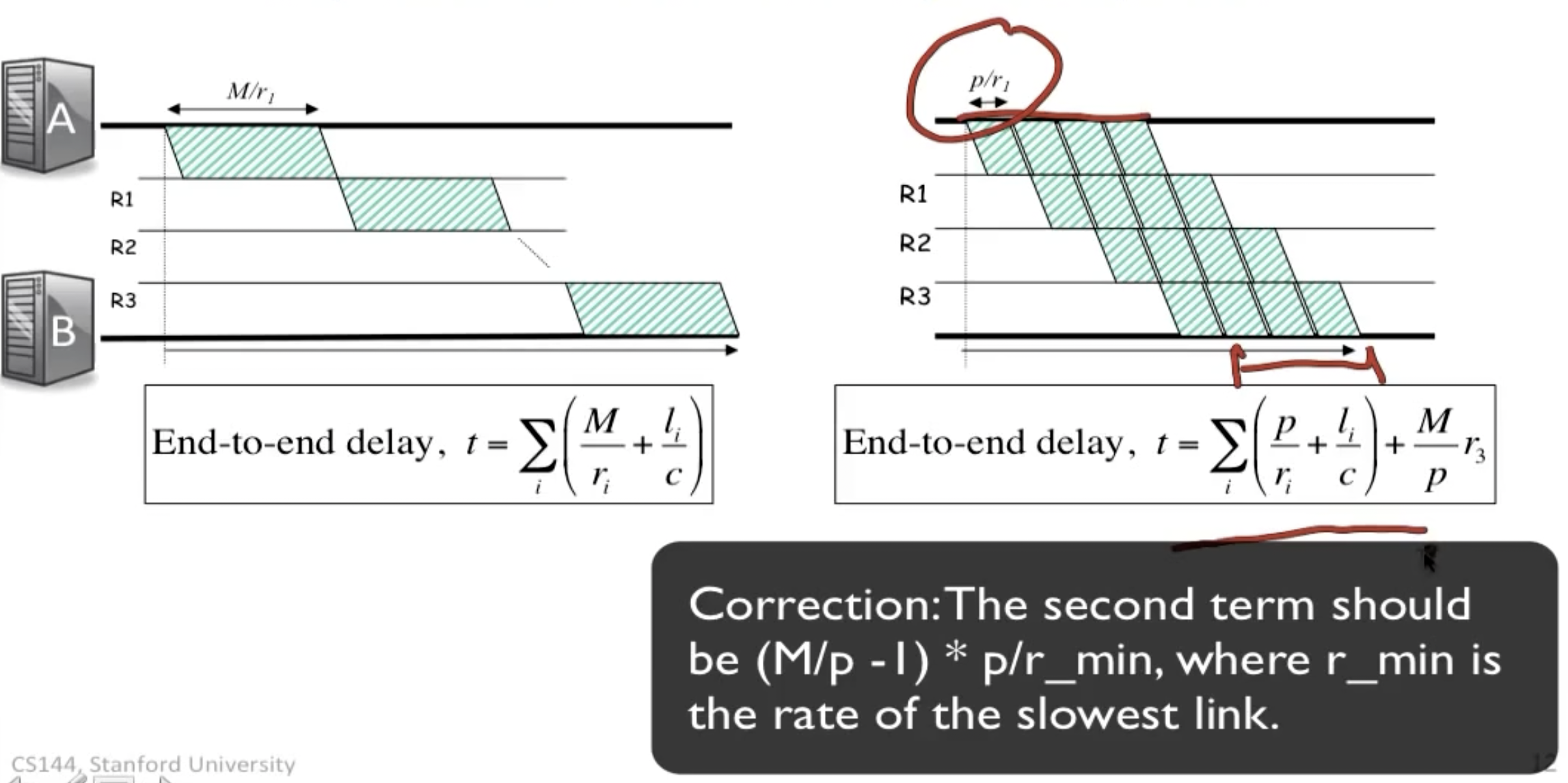
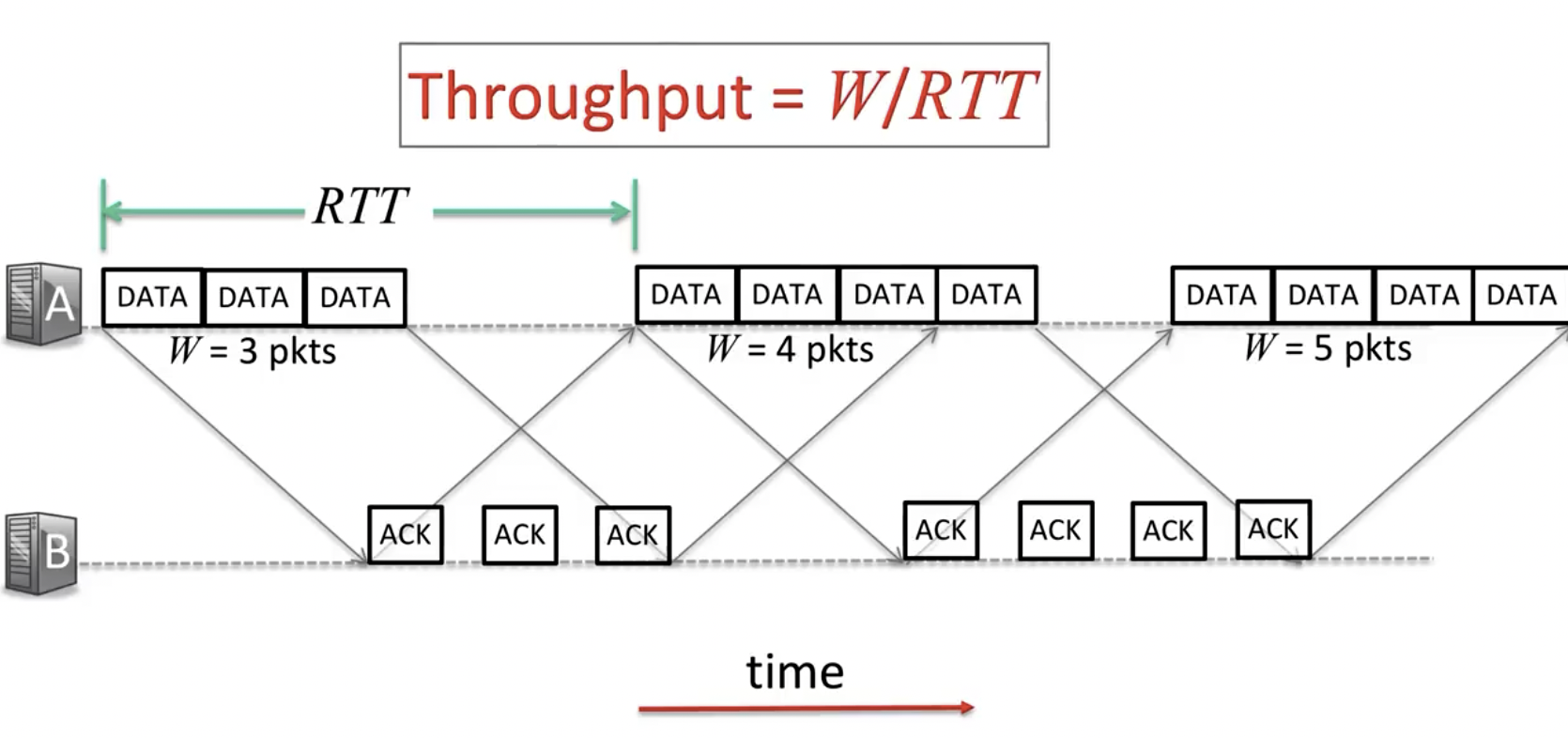
并行发送提高了发送效率,在上图右侧的公式第二项表示从R3出发时除了第一个包,其他的包最晚的packetization delay,即上图中红线标识的部分。
Statistical Multiplexing
统计复用的本质还是时分复用,意味着在不同时刻,根据负载的大小决定信号的占用率。(与之对比的是频分复用和码分复用)
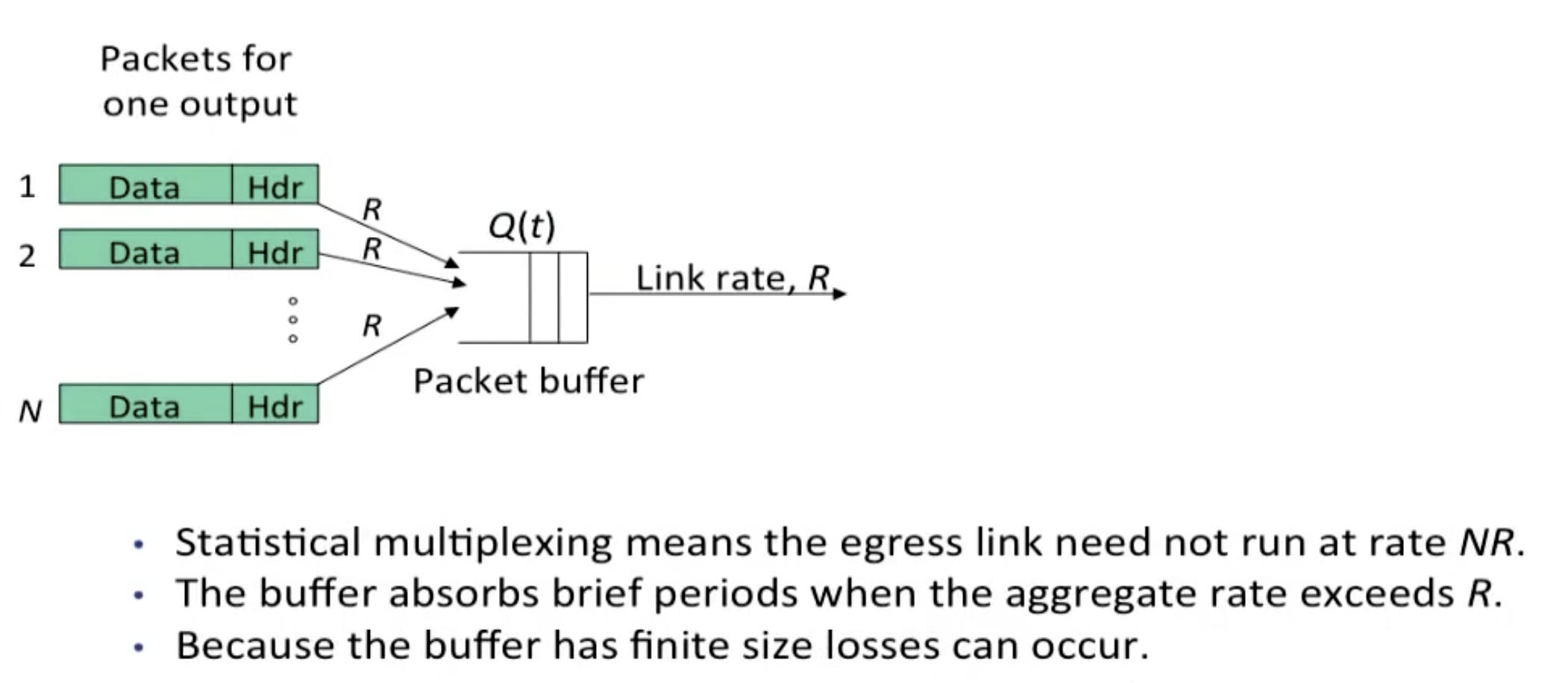
在完全理想的数学模型下,我们容易想到上图中的egress rate为NR,并且由于ingress rate为R,将会有(N-1)R的数据被浪费;事实上,由于statistical multiplexing的存在,如果平均速率足够低(不是每个始终保持R),我们可以在上述模型下避免输出过载。
同时,我们还可以借助缓冲区的存在来避免没有输出的那部分信息被浪费。
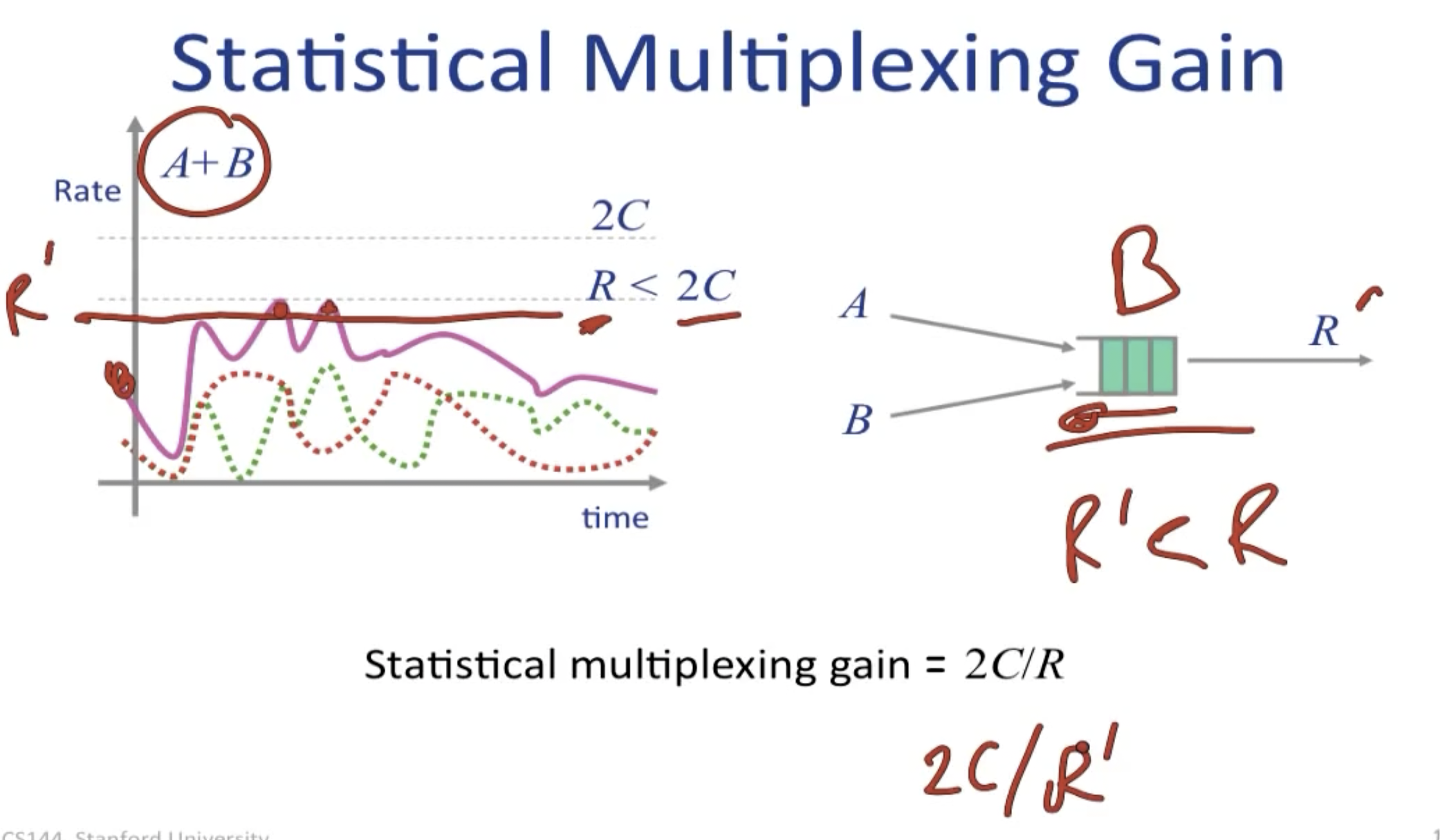
上图可以很好的说明统计复用增益的意义,当我们试图将两个独立的信道A和B合并时(这意味着他们的输出也被合并),在原本独立的情况下,A和B各自的max rate都是C,但是观察合并后的输出速率会发现,最大值远小于2C,这意味着合并后的信道可以允许更高的输入负载(来达到输出信道的最大承载),这种收益被叫做统计复用增益(statistical multiplexing gain),用
表示。
实际上的增益要大于2c/r,因为packet buffer的存在,我们可以允许使用一个限额更低的输出端。
Queueing Properties
- Burstiness increases delay
- Little’s result: $$L=\lambda d$$ (average occupancy = arrival rate * average delay)
- Packet arrivals are not Poisson, but some events are, such as web requests and new flow arrivals, and M/M/1 queue is a simple queue model
Switching and forwarding
一般的包交换需要经过三个步骤:
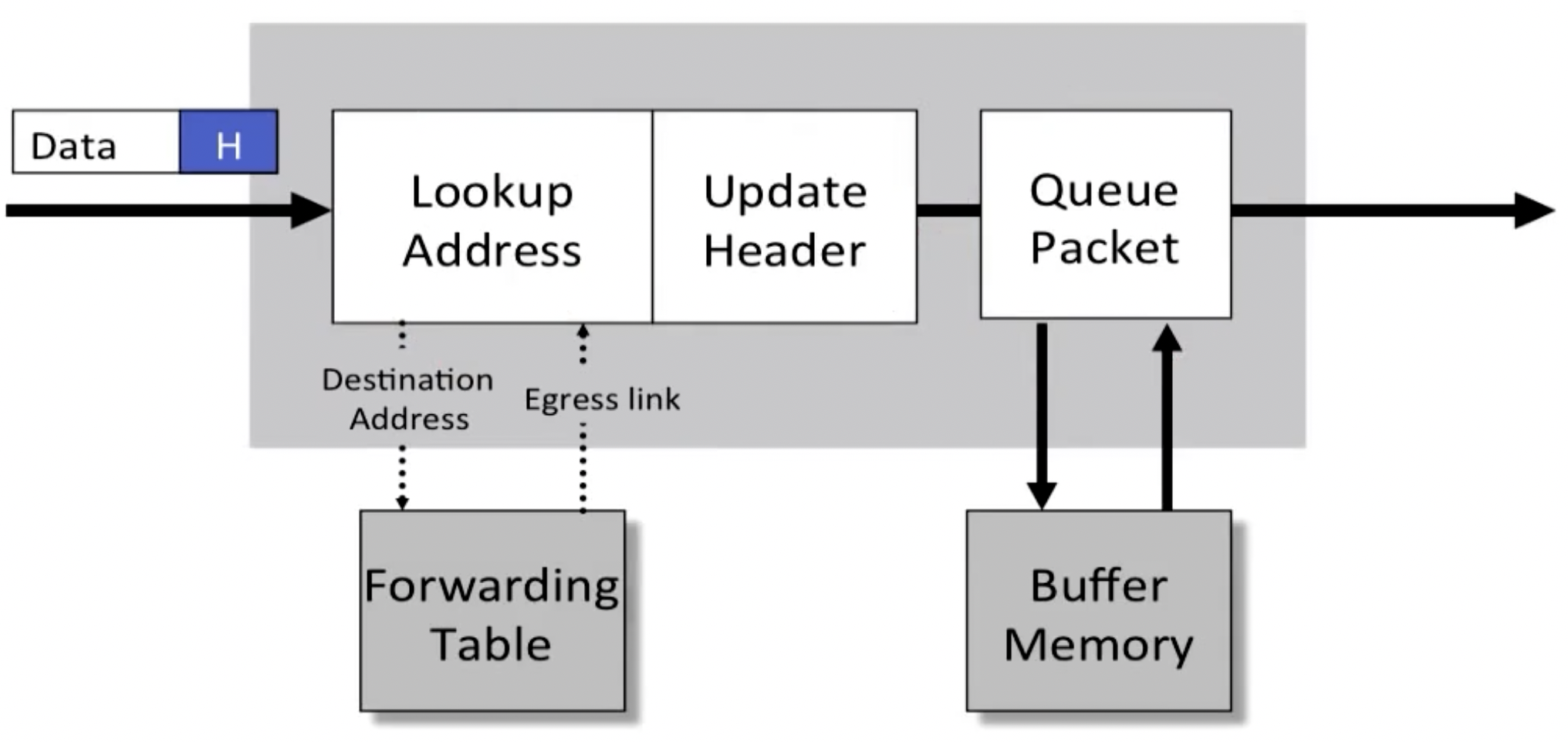
- 根据forwarding table中的destination addr查找转发的link
- 更新header(比如其中的TTL)
- 排队(被放入缓冲区)
Ethernet switch:

这里的forwarding table是MAC table;当广播后更新表的时候,使用的是返回的packet的source address。

Ethernet中的地址查找,一般将MAC地址放在hash table中,且每次都要查找exact match。
Internet Router:

需要注意的是,在router间传递时,发送端与接收端的IP地址并不会改变,始终是起点到终点,不同的只是MAC地址,即每个IP packet frame外包裹的Ethernet frame。

而在路由器中的查找过程是最长前缀查找。
Input/output queue packet switch
关于buffer memory的位置选择,可以放在输出端也可以放在输入端。
output queued packet switch:
将buffer memory放在输出端的问题是我们很难找到能够支撑(N+1)R的读写速率的内存。一个更合适的上限阈值是将输入端的速率限制在R,这样整体的速率就是2R。这种限制可以通过将buffer memory放在输入端得到:
input queued packet switch:
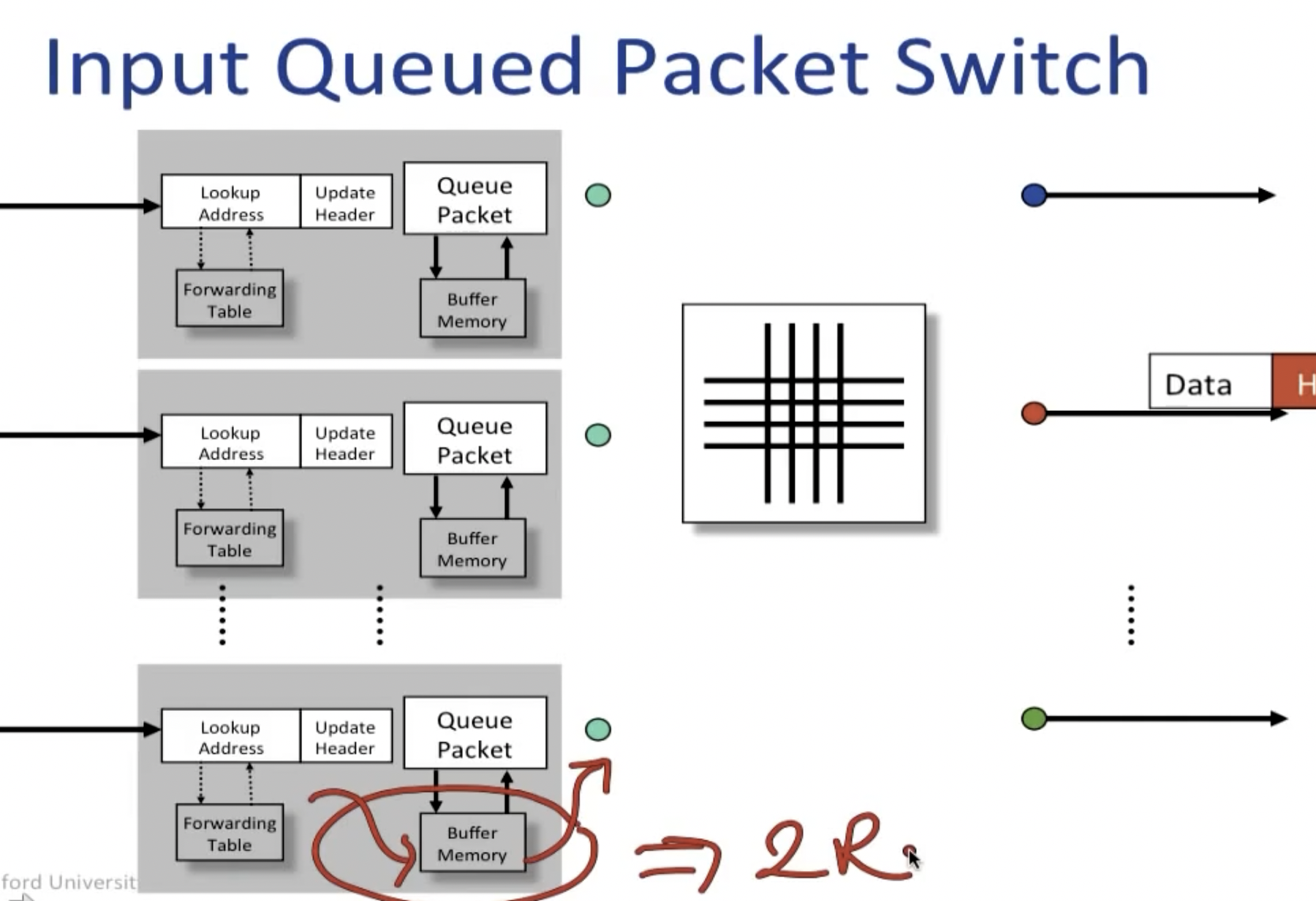
但是这样做也并非没有问题,比如课上提到的head of line blocking,即因为input上缓冲区队列的存在,导致一个队列中所有后续的packet,即使不走和head packet一样的link,也要在后边等待头部的包裹传送完毕后才能被传送:
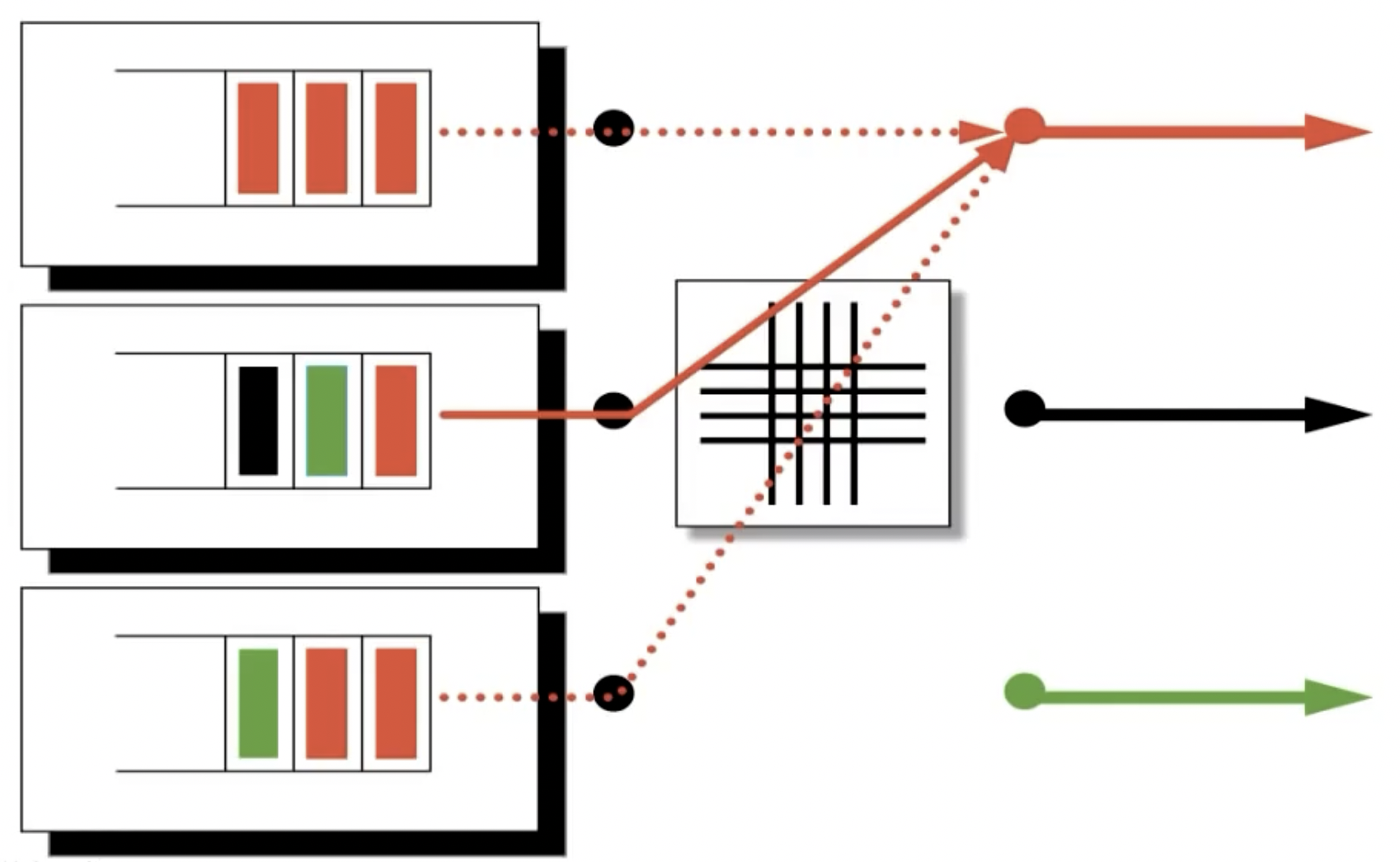
这可以通过virtual output queues解决,即为每一个走不同link的packet设立独立的缓冲队列。
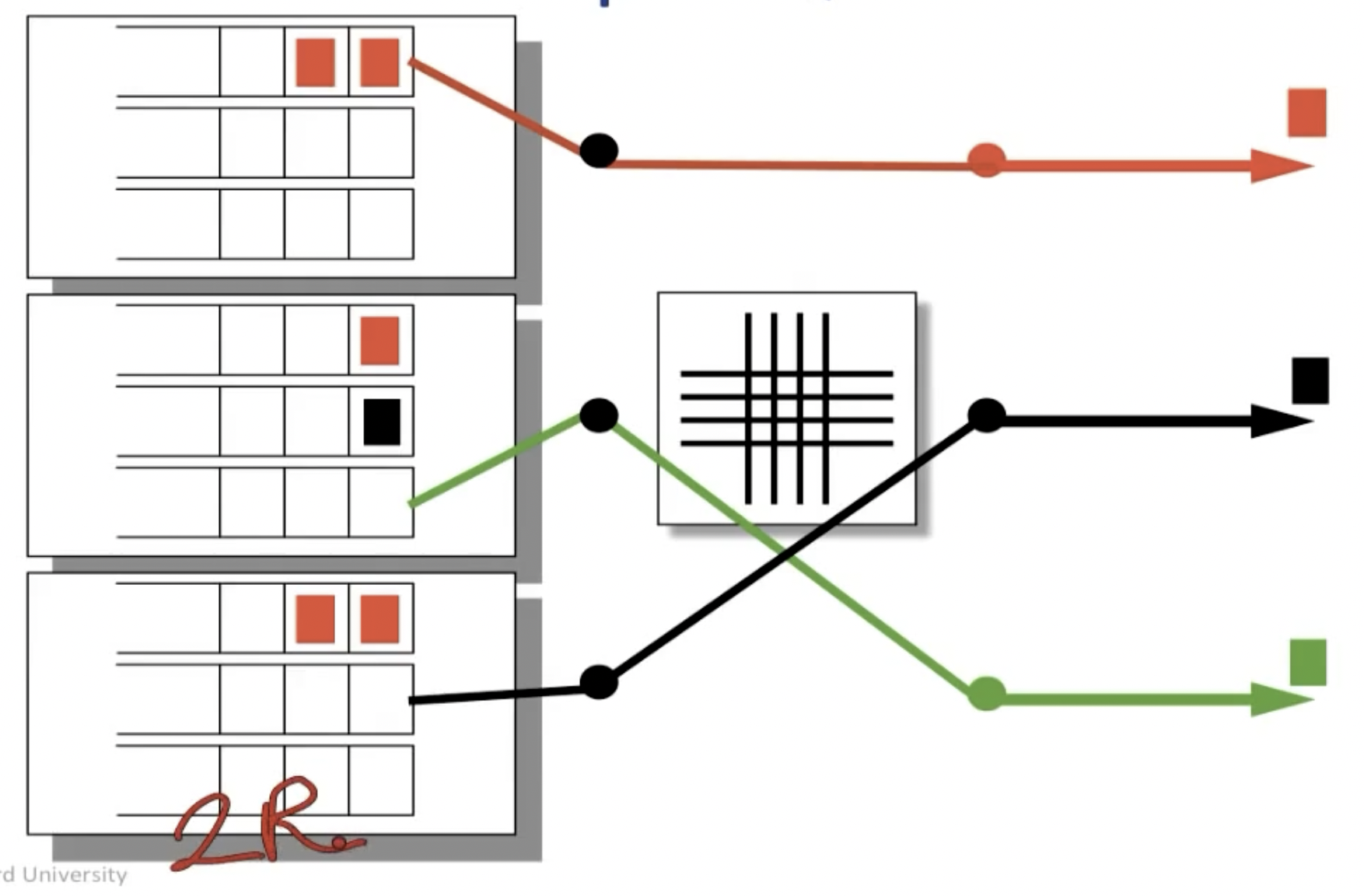
Different queue type
课程中提到了三种queue的类型:FIFO/Strict Priorities/Weighted Priorities
FIFO即最常用的先进先出,但这种方法没有任何的优先级区分和rate保证。
Strict Priorities:
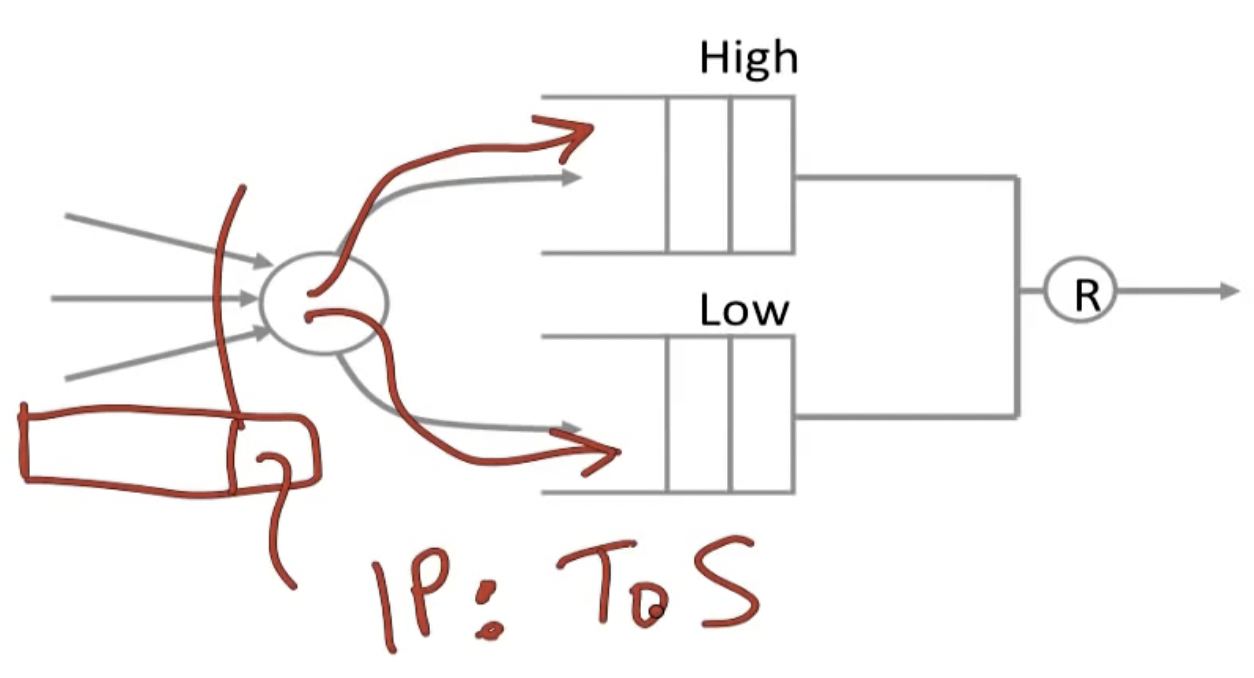
将buffer queue分成High priority和low priority两部分,只有当高优先级的buffer中没有数据时,才处理低优先级的部分。为了指定数据包走哪一个路径,可以设置IP中的ToS 字段可以指定数据报的优先级并请求低延迟、高吞吐量或高可靠服务的路由。根据这些 ToS 值,数据包将被放置在优先级传出队列中。
但这种方法显然是有局限的,容易starve low priority。为了解决这个问题,可以使用weighted priorities:(每一轮传输的bit数量)
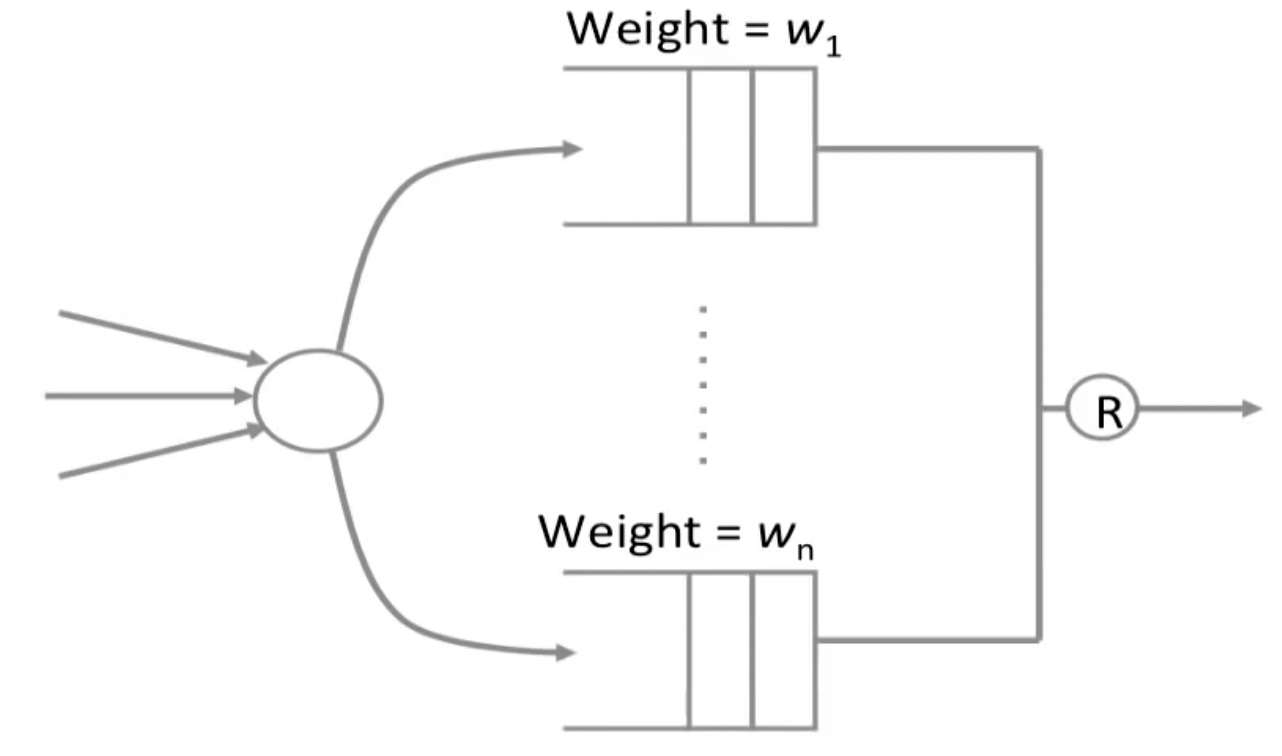
这种方法的一个问题是,这里的权重都是对应在bit上而非packet上的,所以如何确保在权重分配得当的前提下不破坏packet传输的完整性?
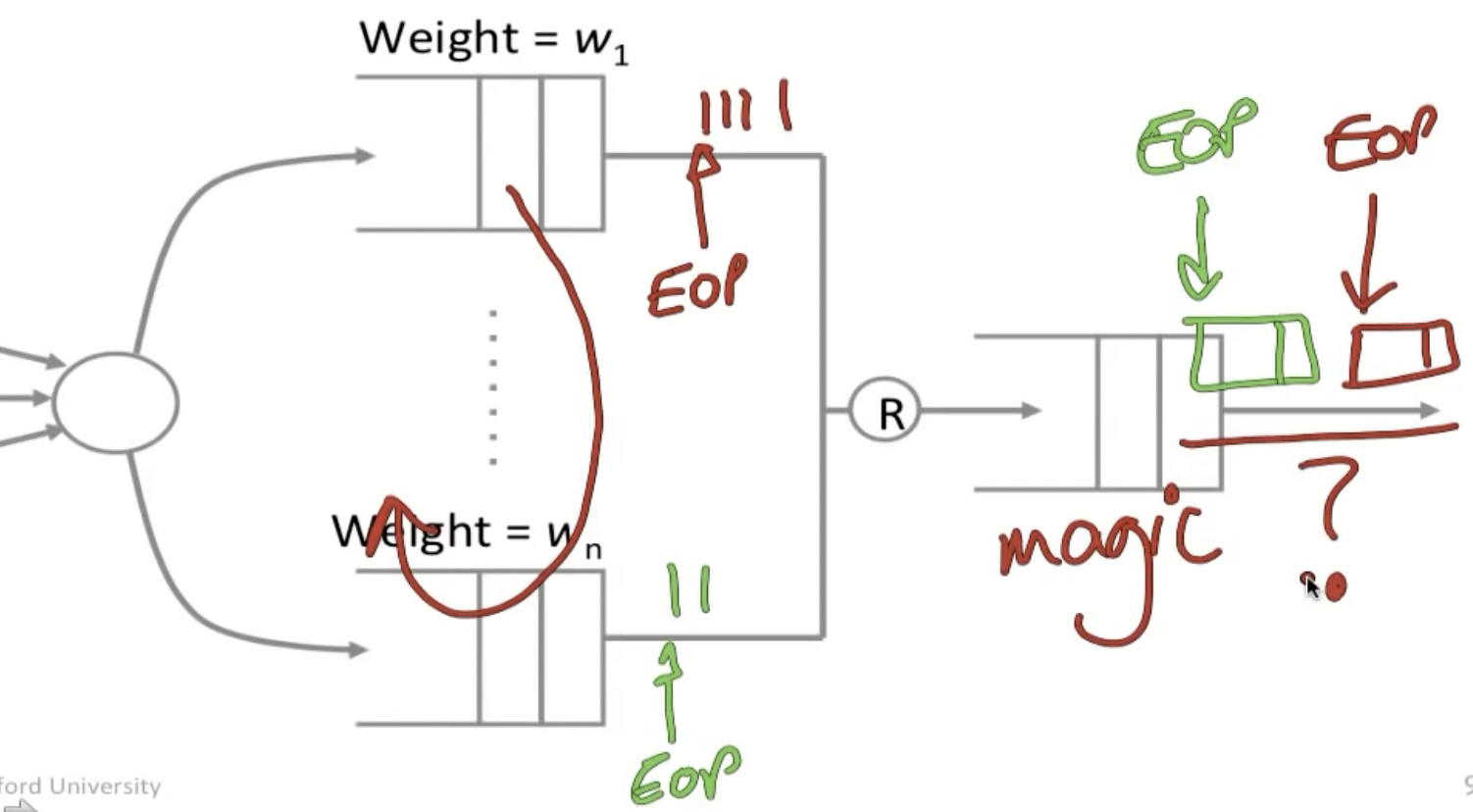
一个方法是在传输的bit上带上EOP,于是当输出端的Magic queue遇到EOP时便将数据组合输出。
NOTE: 剩余的rate guarantees和delay guarantees等待后续补充。
Congestion Control
- Flow control: not overwhelmed the receiver
- Congestion control: not overwhelmed the routers and links by controlling the number of outstanding packets in the network
Goals for congestion control:
- HIgh throughput: Keep links busy and flows fast
- Max-min fairness
- Respond quickly to changing network conditions
- Distributed Control
Congestion: Packets -> Flows -> Users
这里我们关注flows。
在packet switching的时候,拥塞是不可避免的,但这并不意味着拥塞一定是不好的,如果buffer永远是空的,那么延迟会很小,但网络的利用率一定也很小;而如果buffer总是被占满,延迟会很高,但这意味着网络的利用率也会很高。
但是如果packet因为拥塞而被丢弃,则可能引发上游资源的浪费(因为packet必须从原来的路径重新被传送到现在的router)。所以我们需要定义一种fairness,来决定如何分配bottleneck link上的资源。
Max-min Fairness
“最大-最小”这个名字来源于这样的想法:算法使较小(或最小)流的速率尽可能大(最大化)。因此,我们对小流量给予相对较高的优先级。仅当流要求消耗超过 C/N(链路容量/流数量)时,它才会面临算法限制其带宽的风险。
定义:
An allocation is max-min fair if you can not increase the rate of one flow without decreasing the rate of another flow with a lower rate. (增加该流的带宽不会让那些本来就不太富裕的流的情况变得更糟)
只要已知网络的全局知识最大-最小速率就可以计算出来。一种直观的思考方式是想象所有的流从速率零开始,然后缓慢增加速率。当任何一个流的速率遇到瓶颈,就停止该流的速率增加:所有其他的流继续增加各自的速率,平等共享所有可用容量,直到他们也到达各自的瓶颈。
算法有一些基本定义:
- 资源需求由小到大排序
- 用戶所得到的资源必定不能大于该用户的需求
- 无法满足的用户则平分剩余资源
Basic Approaches
由于IP层不带有拥塞控制的功能,所以TCP做了end-host based的拥塞控制:通过dropped packet(可以利用ack的ack sequence number)告知发送端此时出现拥塞,并做出对应的反应。这种机制借助TCP的sliding window实现,并尝试找到网络可以支持多少个未完成的数据包(outstanding packets)。
下图表示了为什么通过控制滑动窗口的长度,可以控制网络的拥塞度:
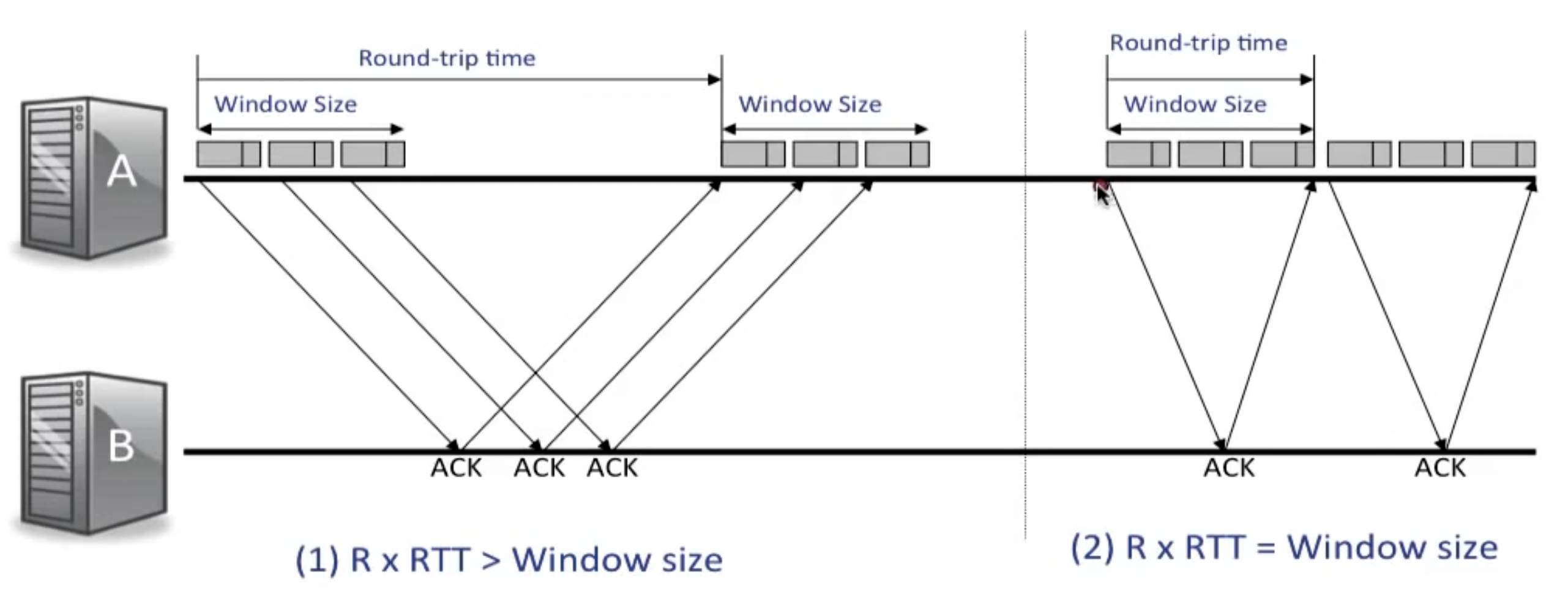
取:
Window size =
$$min(Advertised window/Receiver, Congestion Window/cwnd)$$
其中,advertisedwindow为流量控制窗口,表示接收端允许的最大缓冲字节数,congestionwindow为拥塞控制窗口,表示发送端此时允许发送的最大字节数。我们期望网络呈现右侧的状态,而不是左图中在每一段RTT内都需要很长的空闲等待时间,为了达到这个目的,我们使用AIMD算法。
AIMD (Additive Increase, Multiplicative Decrease)
For each packet, the width of cwnd:
- If packet received OK: $$w\leftarrow w + \frac{1}{w}$$(相当于每过一个round trip time,窗口长度增加1)
- If a packet is dropped: $$w\leftarrow \frac{w}{2}$$
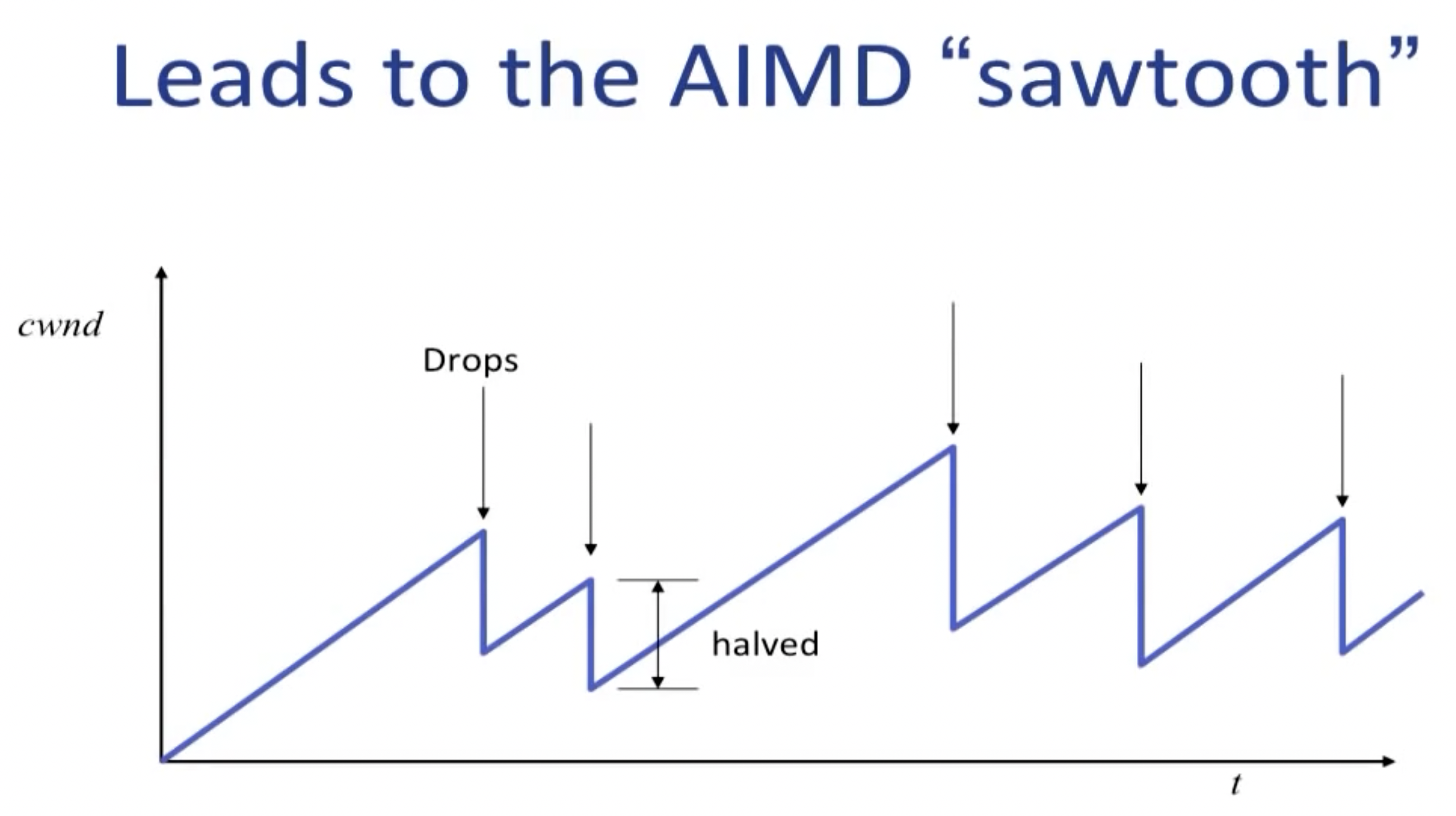
single flow AIMD
课程上给了一段动画,值得反复观看。
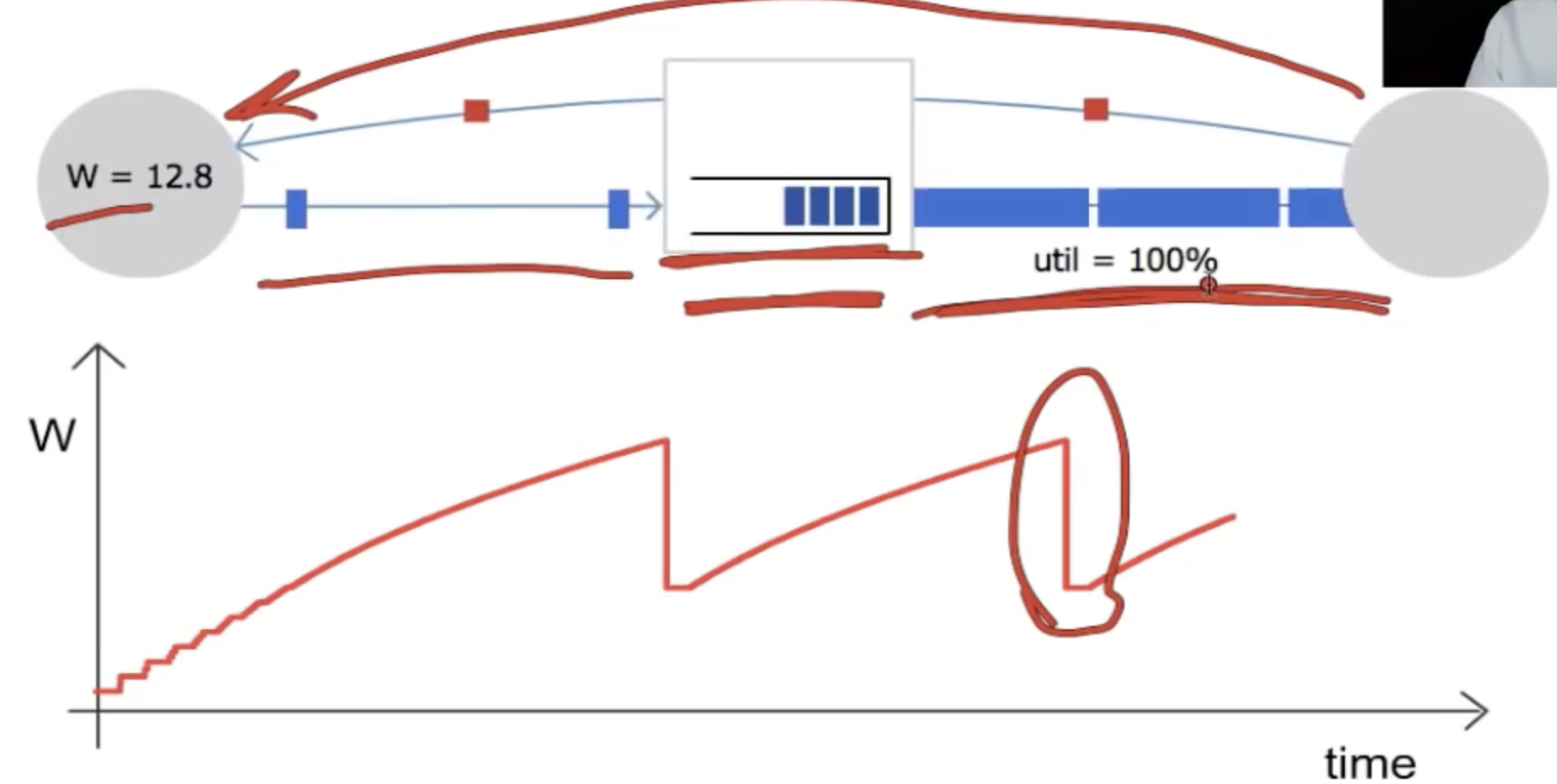
输入端link支持的速率要高于输出端,随着cwnd的不断变大,这将导致输出端的utilization rate逐渐变成100%,此后,router buffer中开始积累packets,当发生packet loss的对应的ack被传回输入端的时候,cwnd变成原来的1/2,由于此时的outstanding packets的数量要大于sliding window size,故而sender停止发送数据包,router buffer memory也会逐渐清空,发送端也会继续发送数据包并将上述过程循环往复。
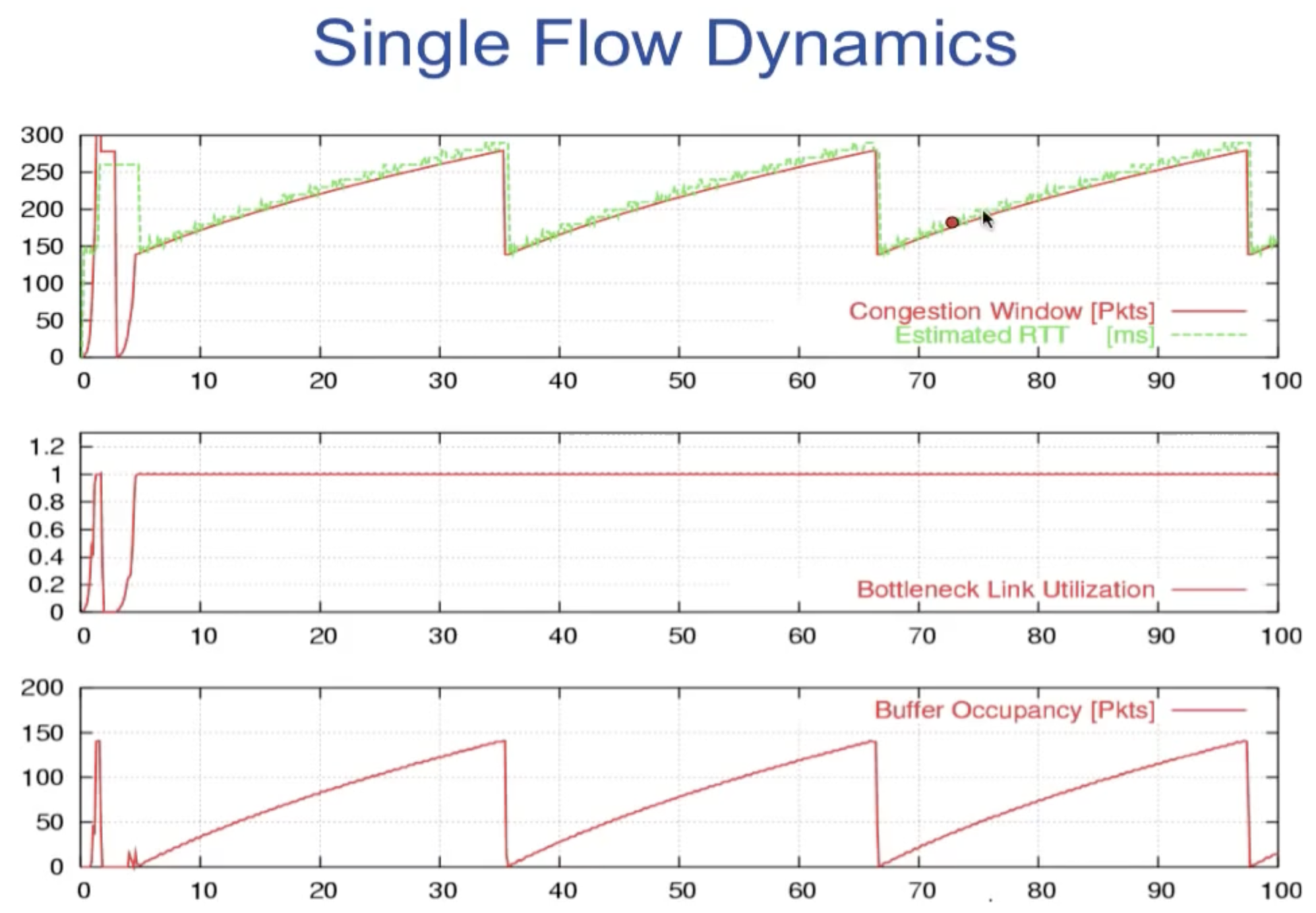
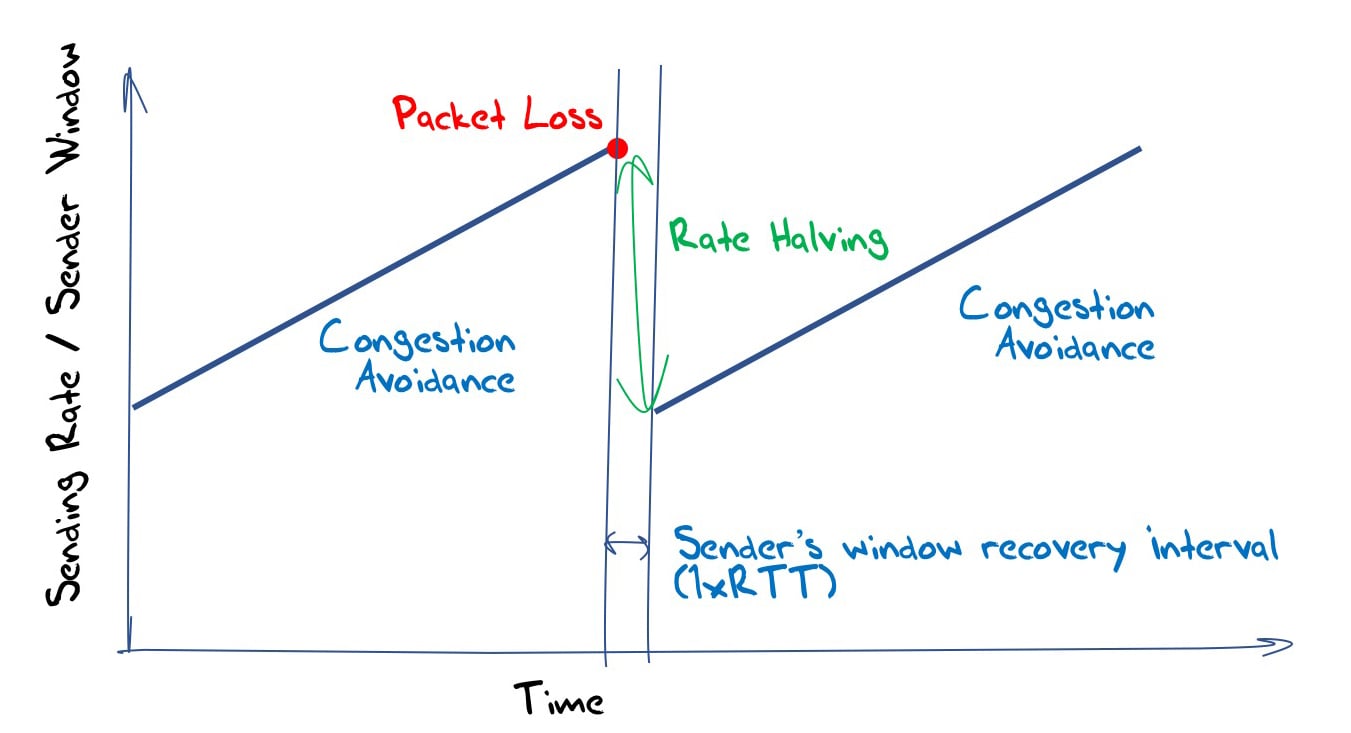
上图是只有当只有single flow时的对应指标的变化。
- 当buffer不为空时,RTT和cwnd基本上同步变化,这是因为当窗口变大的时候,buffer中的数据会积攒的越来越多,则网络中packet的RTT也会随之变长(需要更久的时间在buffer queue中等待)
- buffer occupancy的变化趋势与上述两者也基本一致
(达到右侧图的状态)
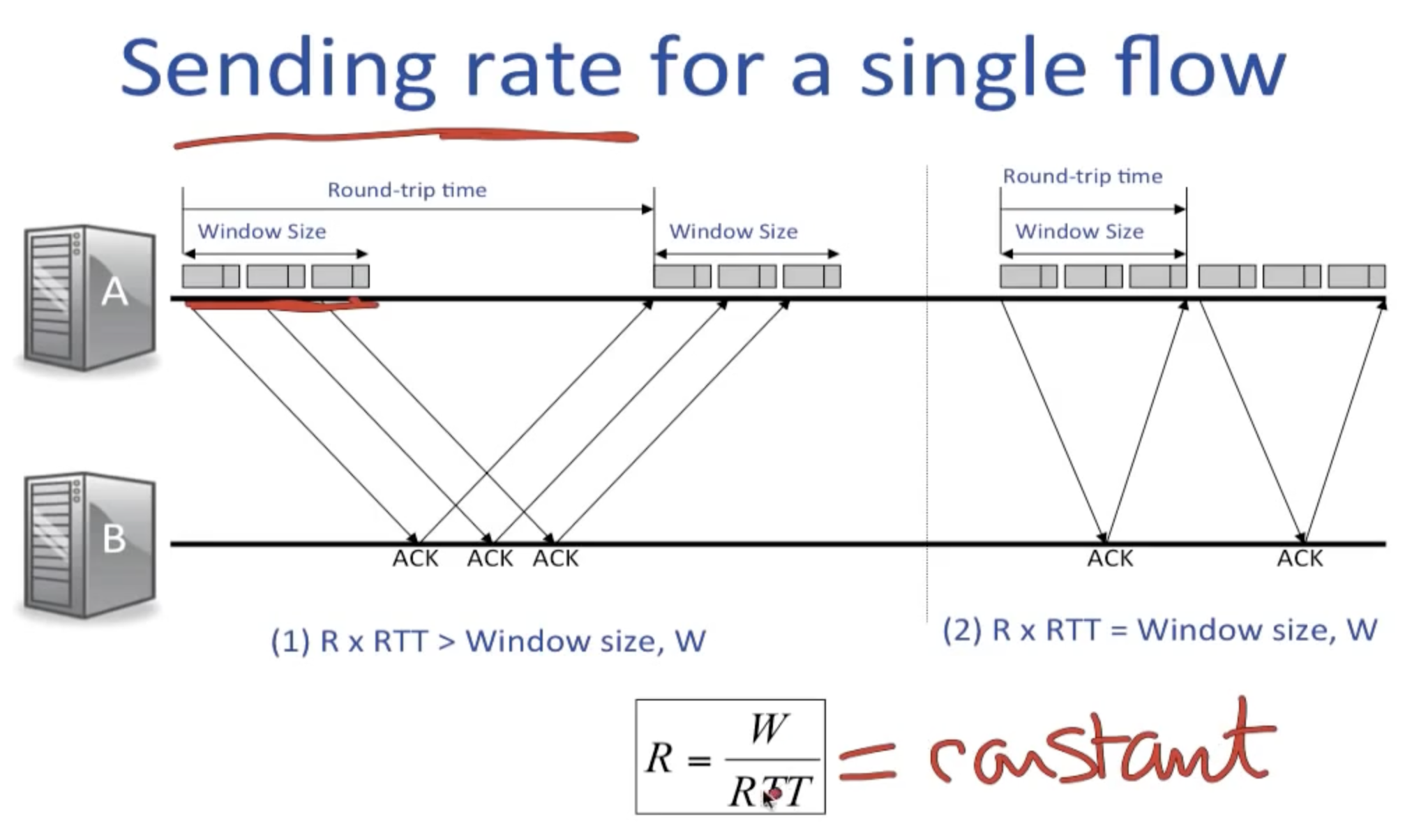
有趣的是,在single flow的情况下,只要buffer足够大(原因接下来会说),sending rate其实是一个常量(因为每过一个RTT,cwnd增加1,而R=W/RTT),这也表明了拥塞控制和流量控制的不同在于拥塞控制试图控制outstanding packets on the links而不是发送端的发送速率。
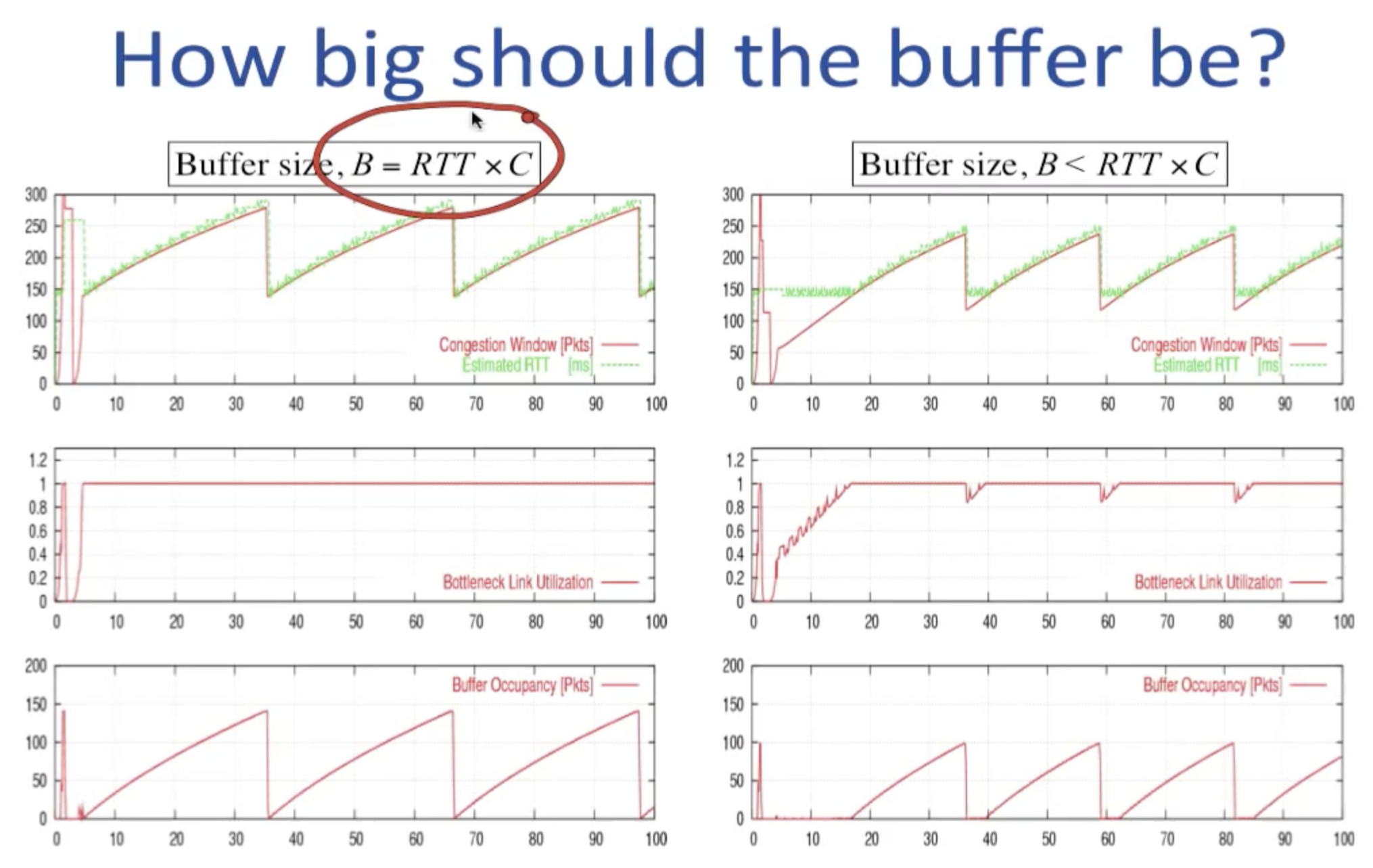
接下来的问题是buffer应该设置成多大才能最高效的利用links?上图给出了答案。上图中的RTT*C,对应于buffer为空->非空的临界点,这个乘积来自于D*BW,被叫做delay-bandwidth product,是buffer为空时,整条线路上允许存在的最大bit数,我们使用RTT*C来表示此刻的临界状态。
左侧的buffer size等于delay-bandwidth product,右侧的size则要小于此值,注意到无论在哪种情况下,buffer为空时的RTT都为150。由于左侧的buffer size等于DBP,在最高点时的delay-bandwidth product因为buffer处于满状态,所以为此时的D*BW为2*buffer size(RTT*C),根据AIMD将窗口大小减小一半,则轨迹中的垂直线段的长度恰好等于buffer occupancy/size(将两者均理解为bit), 同时伴随着buffer中的内容ack传回sender,outstanding packets的数量恢复到窗口大小的标准,其cwnd开始重新增大,此时由于egress link的utilization已经因buffer occupancy的倾巢而出达到100%(正是因为buffer size==DBP!),buffer重新开始被填充,bottleneck link utilization也始终维持在100%上。(PS:另一种理解方式:因为减半窗口大小后,RTT*C恰好为整条线路上允许存在的最大bit数,所以不会在buffer occupancy上出现水平的空隙)
而右侧则不然,因为buffer size小于DBP,在最高点时的delay-bandwidth product小于2*RTT*C,也就是说此时的网络线路中无法允许和左图最高点一样的cwnd大小,当AIMD减半窗口大小后,对应的D*BW < RTT*C,这意味着bottleneck link utilization达不到100%,所以会出现如右图所示的一段区域,buffer occupancy始终为0。(PS:另一种理解方式:因为buffer内的数据包数量本身不到RTT*C,所以不足以填满bottleneck link).
multiple flow AIMD
当网络内有多个flow时,情况和single flow有很大区别:
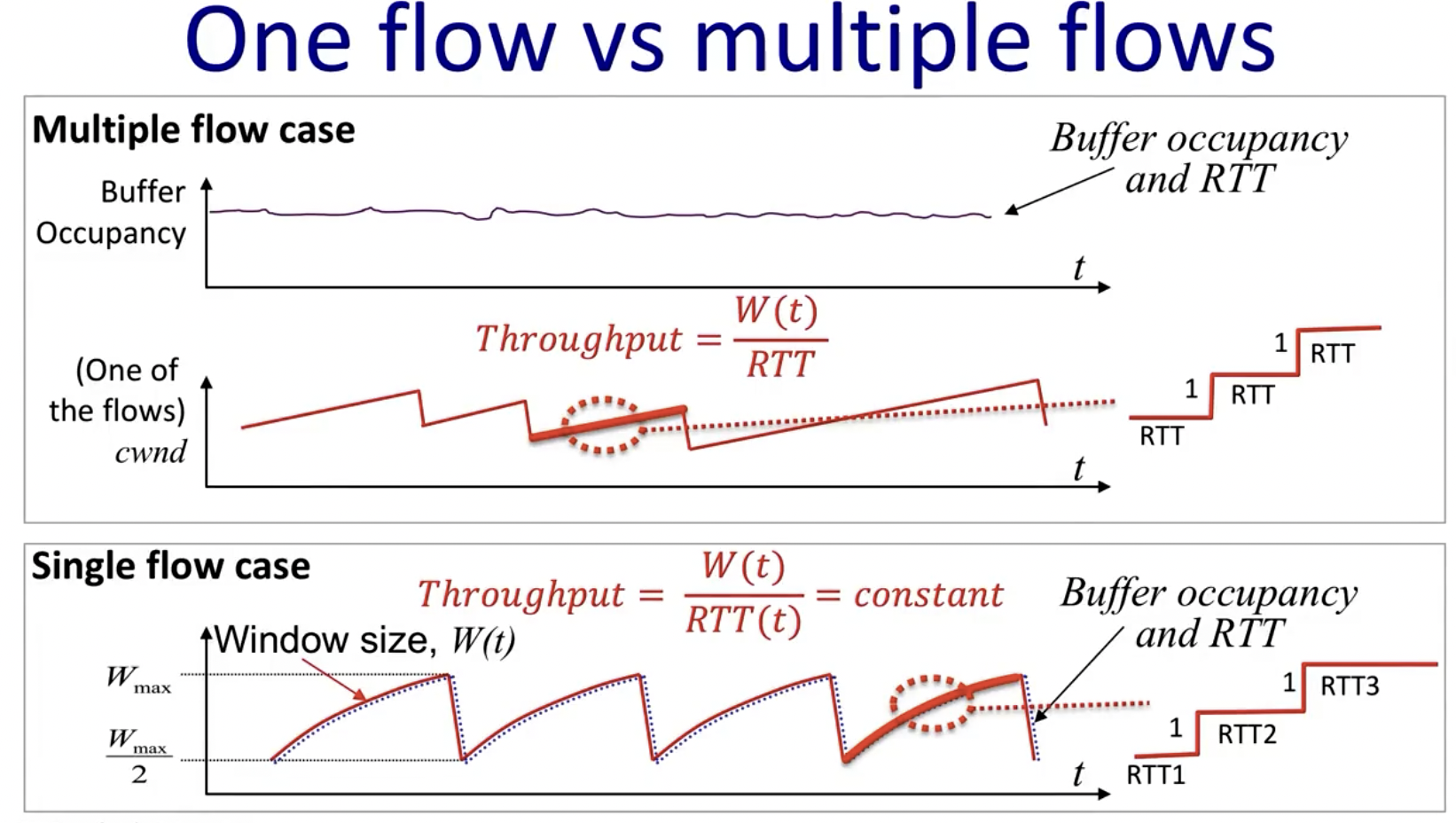
在multiple flow的情景下,我们可以认为buffer始终处于满状态,所以RTT会是一个常量,不同于single flow。同时由于multiple flow时的RTT是一个常量,从而上图中的是直线而非下边图中的曲线。
下图中的矩形表示了在这段时间内接收的packet数量(积分),而通过该图中的公式我们可以判断出:
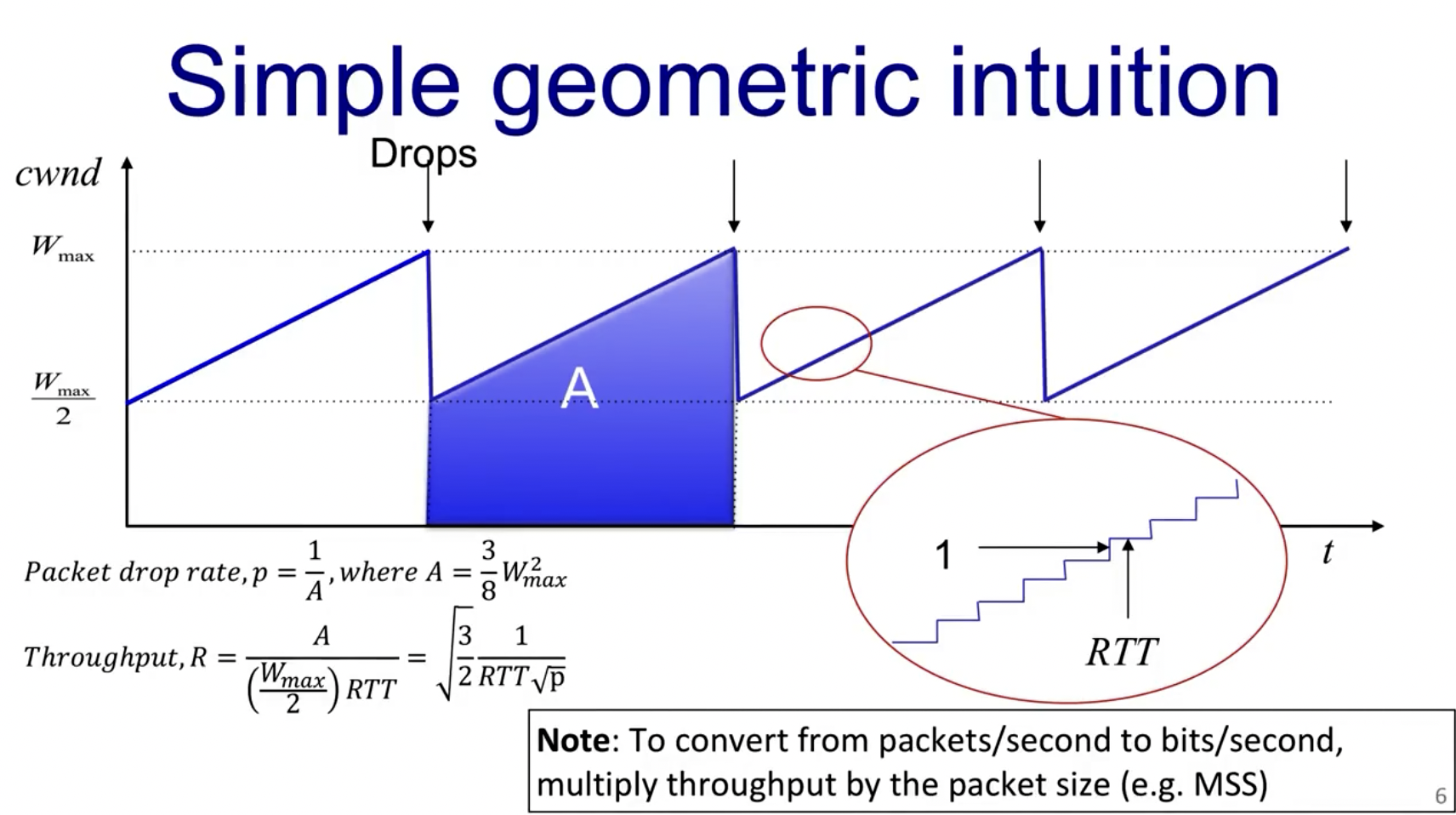
- $$RTT\rightarrow 0 \Rightarrow R \rightarrow \infty$$
- $$p\rightarrow 0 \Rightarrow R \rightarrow \infty$$
这意味着对于传输距离很远的线路(RTT很大),其throughput被限制在很小,这其实并不是我们想要的,所以这也是AIMD的一个缺点。
而当p,即loss packet的概率很低时,throughput会无穷大也恰好符合了AIMD算法,即sliding window size会一直变大。
TCP Tahoe
在TCP使用tahoe之前,internet的日益普及导致了第一次拥塞崩溃(congestion collapse)。
下边的讨论基于三个问题:
- When should you send new data?
- When should you send data retransmission?
- When should you send acknowledgements?
首先回答第一个问题。
在tahoe之前,TCP的拥塞控制设计如下:
- Endpoint has the flow control window size
- On connection establishement, send a full window of packets
- Start a retransmit timer for each packet
- Problem: what if window is much larger than what network can support?
这会导致如下所示的网络情况:
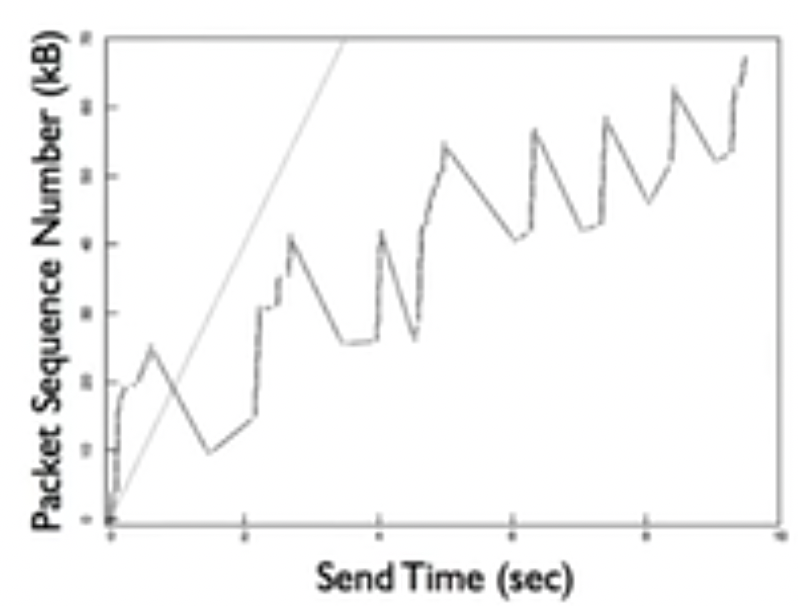
所以,做出了三点改进:
- Congestion window
- Timeout estimation
- Self-clocking
Congestion Window
TCP除了维护一个拥塞窗口外,还维护一个流量控制窗口(该窗口指出了接收端可以缓冲的字节数),如同滑动窗口那里提到的。
要并发跟踪这两个窗口,可能发送的字节数是两窗口中较小的那一个(即发送端认为的应该大小和接收端认为的应该大小中的较小者)。
现在的问题是,如果网络拥塞窗口从一个很小的规模开始,那么可能需要很长时间才能达到正常的传输速度;但如果初始窗口更大,则可能对于慢速或者短程链路来说有太大了点儿,可能造成拥堵。
为了解决这种情况,算法被分为两部分:
- Slow start: on connection startup or packet timeout
- Congestion avoidance: steady operation (AIMD)
慢速启动算法实际上根本不慢,他呈指数级增长,只是相比以前的一次性发送整个流量控制窗口大小的数据,算是启动的不快,该算法如下所示:
- 将初始cwnd大小设置为TCP的Maximum Segment Size (MSS)
- 每次ack的时候cwnd增加MSS
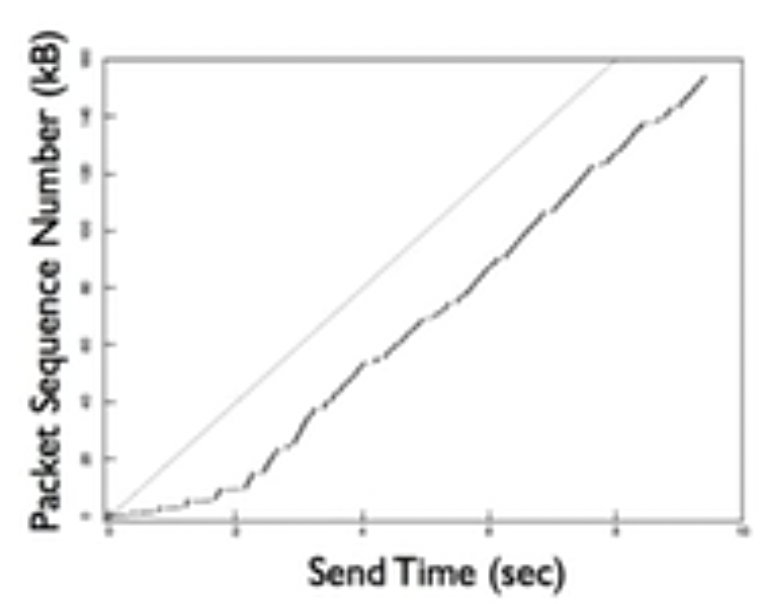
此后,如果窗口大小达到ssthreshold,进入congestion avoidance:
- 每次ack增大cwnd大小为$$MSS^2/cwnd$$ (这相当于每个RTT增大MSS,因为每个RTT有$$cwnd/MSS$$个ack)
通过这种算法设计,我们达到了两个目的:
- 使用慢启动算法快速达到network capacity
- 当接近network capacity的时候,使用congestion avoidance避免网络拥塞
现在的问题是,如何在这两种状态之间切换?以什么信号为标准?我们可以联想到TCP的三个信号:
- Increasing ack: transfer is going well
- Duplicate ack: something was lost/delayed
- Timeout: something is very wrong
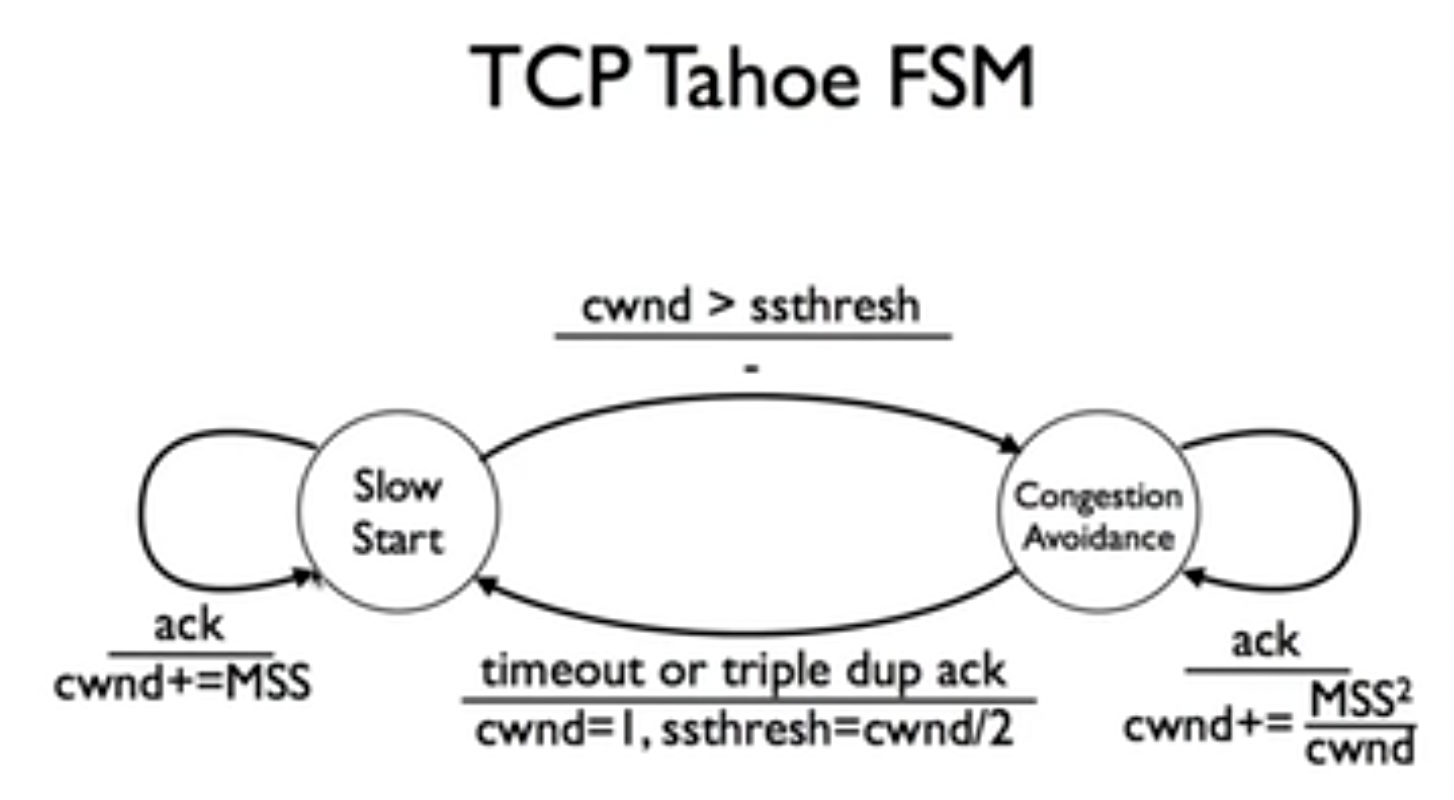
注意这里的triple dup ack,即丢失数据包的后续数据包到达接收端时,他们会触发给发送端返回确认,这些ack携带着相同的确认号,被称为重复确认(duplicate ack)。TCP比较随意的设置3次重复ack为丢包。
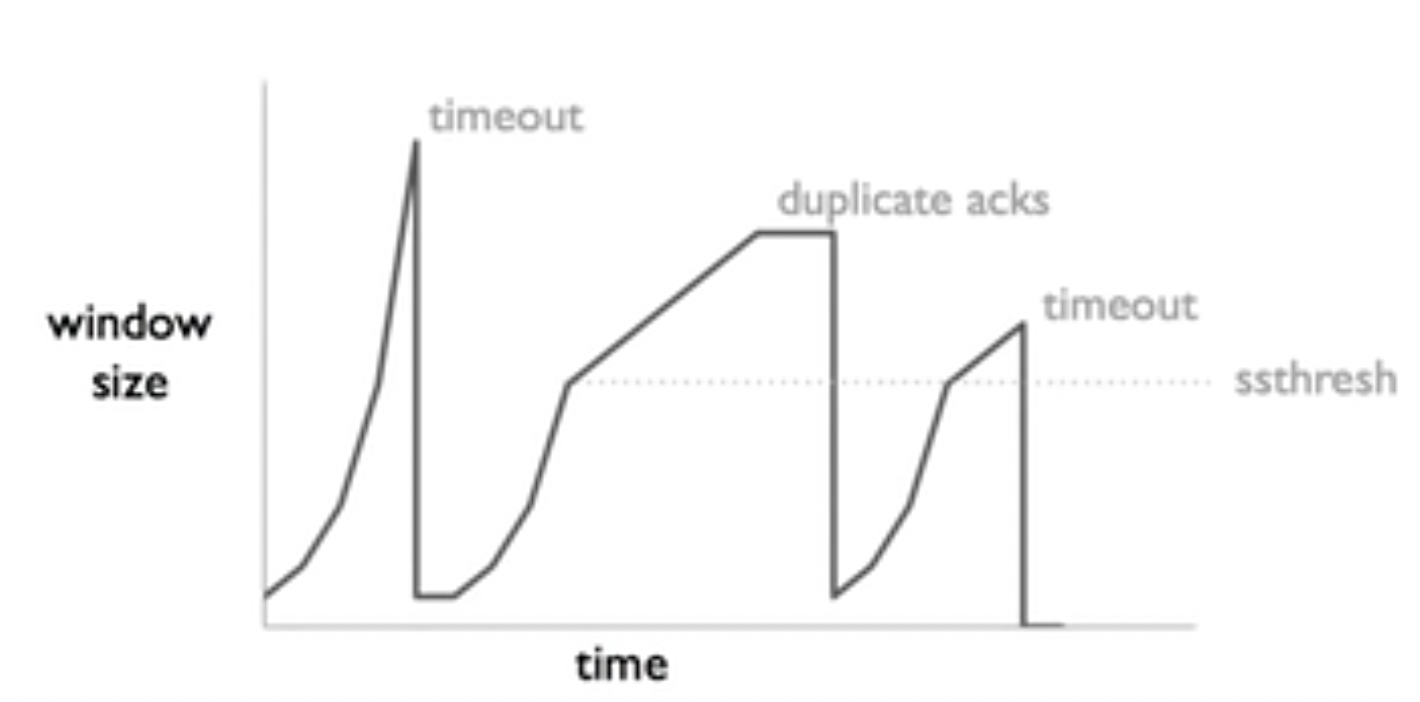
这回答了第一个问题:当min(receiver, cwnd)允许sender发送数据的时候,他就会发送数据。
Timeout estimation
为了解决第二个问题:When should you send data retransmission?
我们需要合理的timeouts的时间判定。在tahoe之前,TCP维护一个变量SRTT(Smoothed Round-Trip Time),他代表往返时间的最佳估计值。同时记录R,为最近一次测量的RTT,更新SRTT为如下:
这里的
$$\alpha$$被称为EWMA(Exponentially Weighted Moving Average),指数加权移动平均。一般取alpha为7/8。
TCP使用timeout时间为
$$2*RTT$$。
但是这种方法存在的问题是没有加入方差因子,他对于RTT的变化不敏感,如果方差很小,那么他的预测显得过于保守,会浪费很多时间在等待已经timeout的packet;而如果方差很大,那么他的预测就显得过于激进,会尝试重传很多仍然在网络中的packets。
为了解决这个问题,我们加入额外的方差因子RTTVAR(Round-Trip Time VARiation):
,其中beta即EWMA。
最后取Retransmission Timeout为:
$$RTO=SRTT+4*RTTVAR$$这种算法在发生大量拥塞的时候,会让timeout呈指数级增长,同时预测效果要比pre-tahoe好很多:
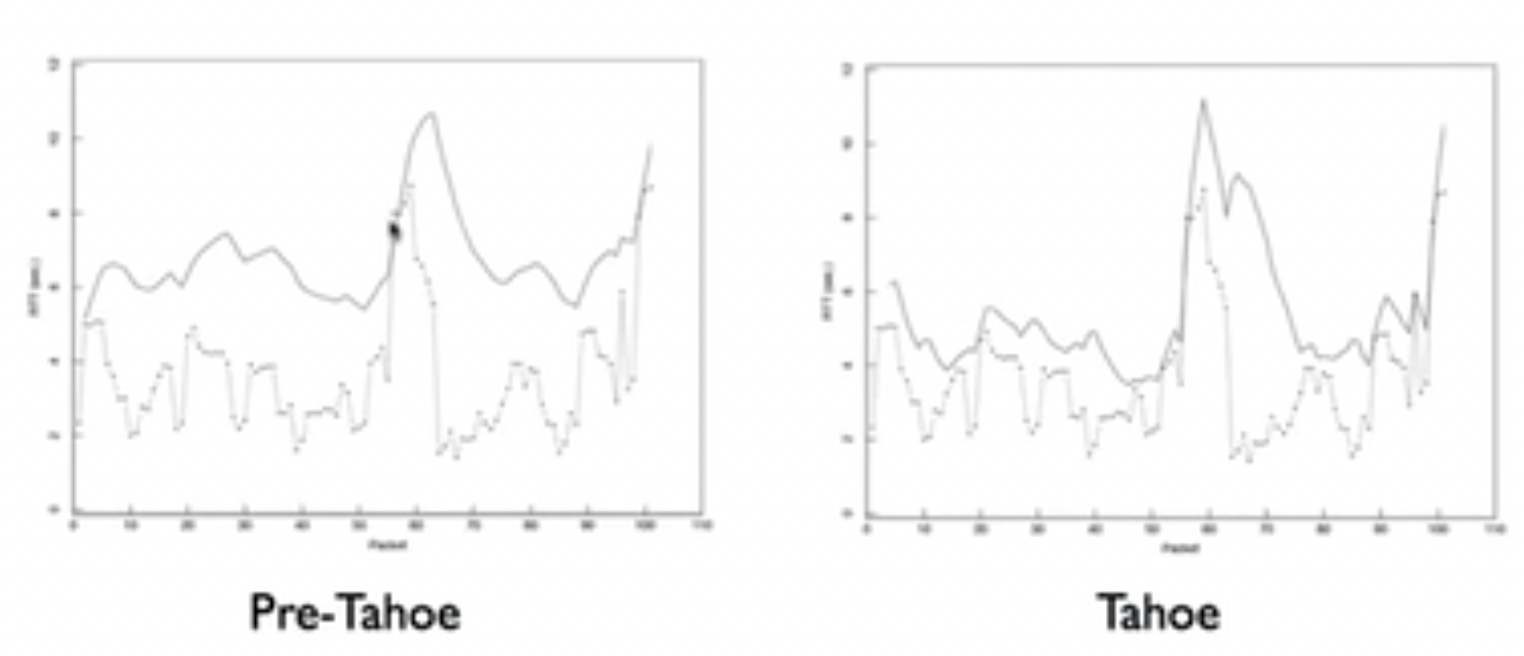
Self-clocking
现在来解决第三个问题:When should you send acks?
TCP利用的是Self-clocking机制。
- the source sends a new packet only when it receives an ack for an old one and the rate at which the source receives acks is the same rate at which the destination receives packets.
- Send acks aggressively, as soon as it receives packets
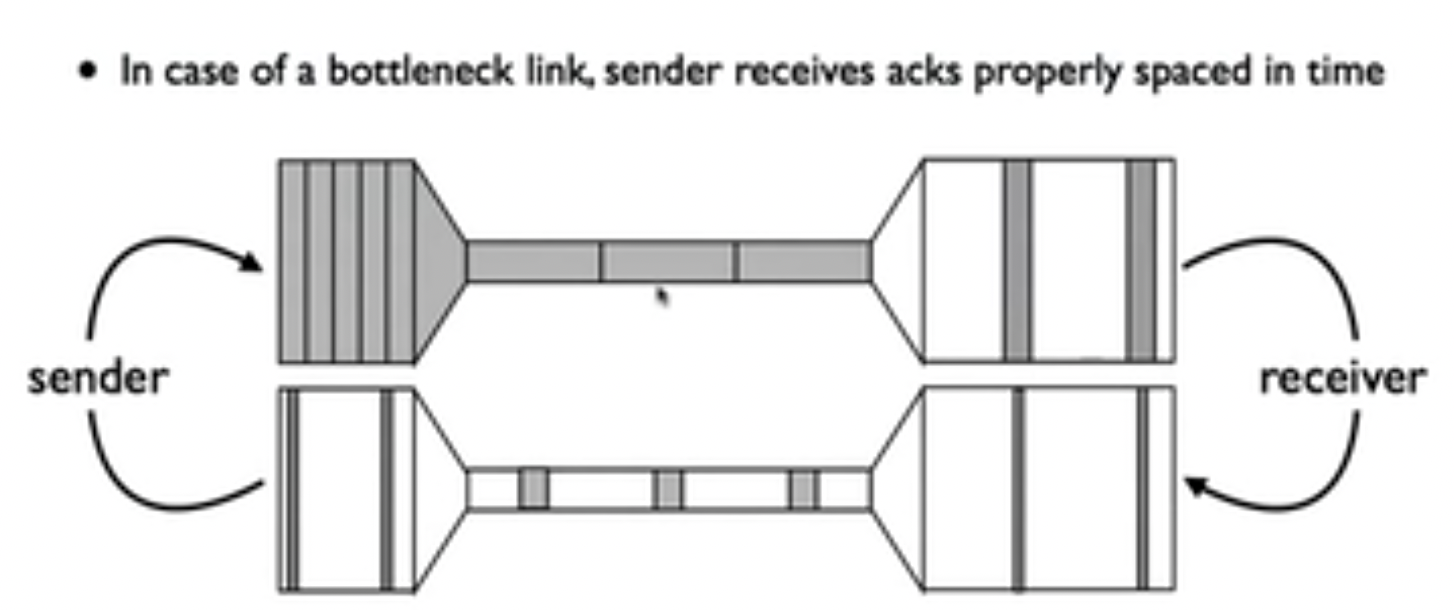
这里放上一个动画网址,很清晰的展示了TCP滑动窗口的工作过程:
https://www2.tkn.tu-berlin.de/teaching/rn/animations/gbn_sr/
TCP Reno
在TCP tahoe中,我们有提到快速重传机制(Fast retransmit),即不需要只有在timeout的时候才重传packet,在收到三次duplicate acks的时候就重传。
但是在tahoe中,每次这种操作都会让系统进入slow start阶段,并将cwnd设置为1,意味着系统需要很长时间才能恢复到正常状态,于是在TCP reno中,引入了快速恢复(Fast Recovery)机制:
- 如果收到三次dup acks,cwnd减半,只有在timeout时才设为1,并进入slow start状态
- 处于fast recovery状态时,每次收到一个ack,就将cwnd增大1,这意味着如果old cwnd是c,进入fast recovery是c/2,那么在收到c个packet ack后,窗口大小会变成3c/2,相当于发送了c/2个新的packet,这种方法的好处在于增大了网络的利用率,在快速重传过程中的packet需要RTT时间来让发送端收到新的ack并推进cwnd,这段时间内按理说可以传递更多的packet在网络中,所以才会出现这种
congestion window inflation的设计(don’t wait for an RTT to send new data)
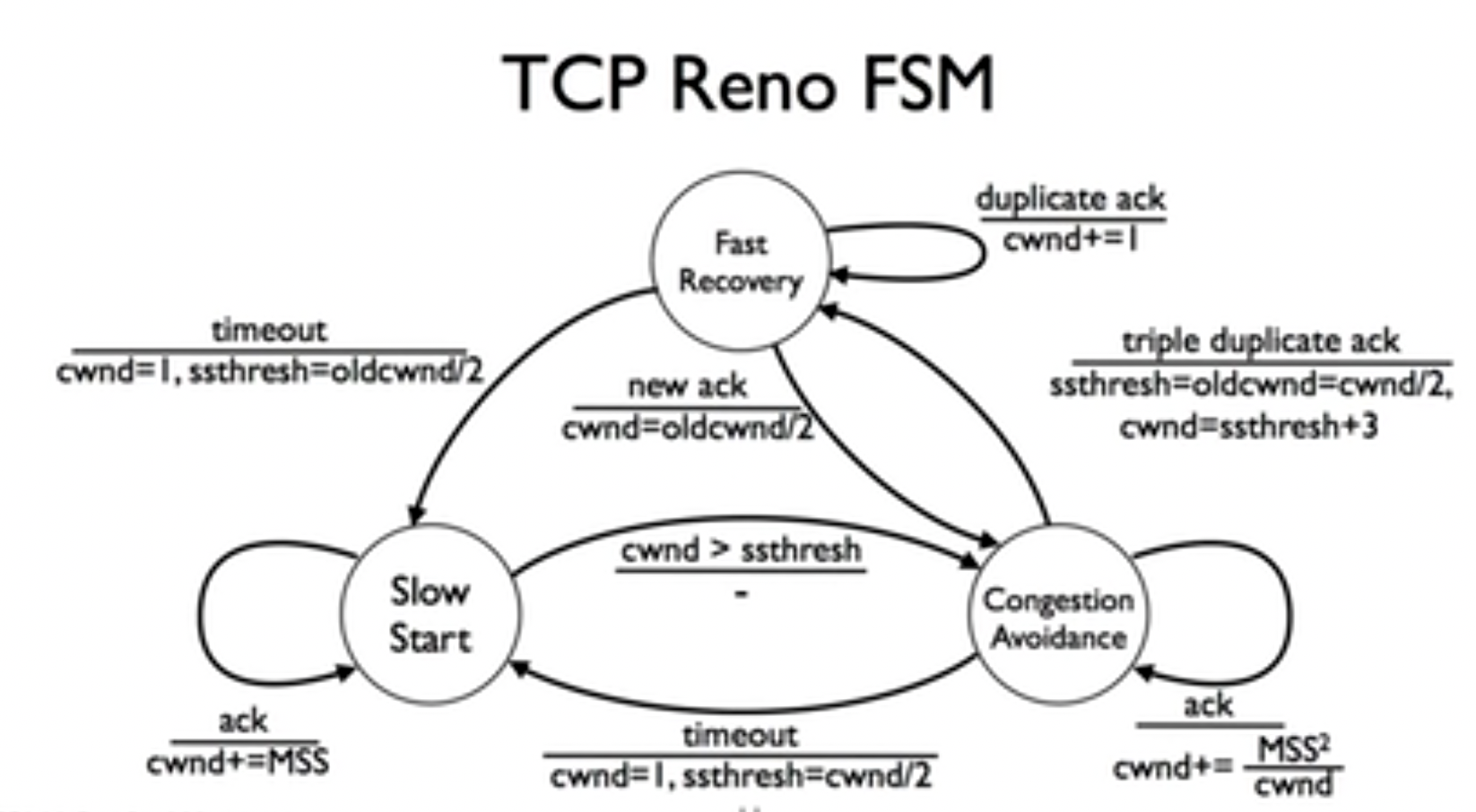
于是在FSM中,加入了一个新的状态fast recovery,从congestion avoidance到fast recovery的过程需要将cwnd设置为ssthresh+3,3来自于triple dup acks。而当在fast recovery时收到新的ack的时候就将cwnd恢复到原本的一半,并返回congestion avoidance状态。

需要注意的是,如果发生timeout,则仍然回到slow start状态。
Chiu Jain Plot
AIMD算法为什么能够保证不同用户之间的公平性?
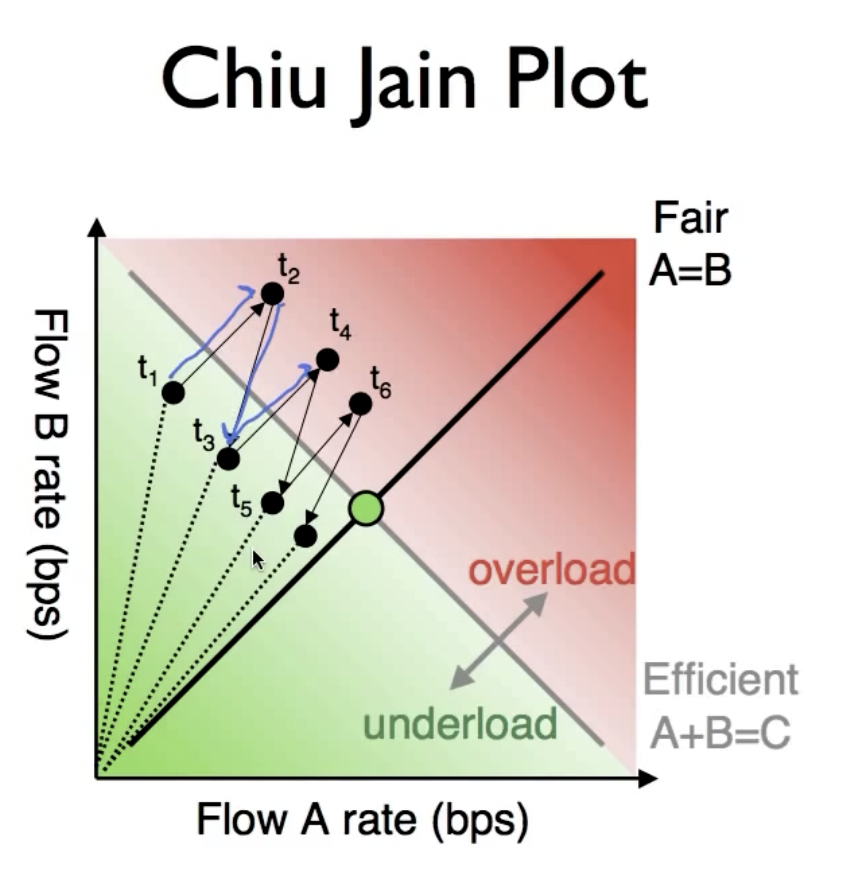
该图的中心点就是我们期望的最佳fairness位置,可以看到在使用AIMD后的流量分配走向,趋近于中心点。
Application
Network Address Translation (NAT)
NAT负责在局域网边缘进行私有socket和公有socket(IP+Port)的转换,通过在内部维护mapping的方式。
- What packets does a NAT allow to traverse mappings?
- how and when does a NAT assign mappings?
几种不同的NAT:

NAT内部的地址是IP为NAT保留的三个不允许在internet上出现的地址段,而每个NAT内部的地址,在该NAT内部随意使用(可以和其他NAT内部的地址重复)。
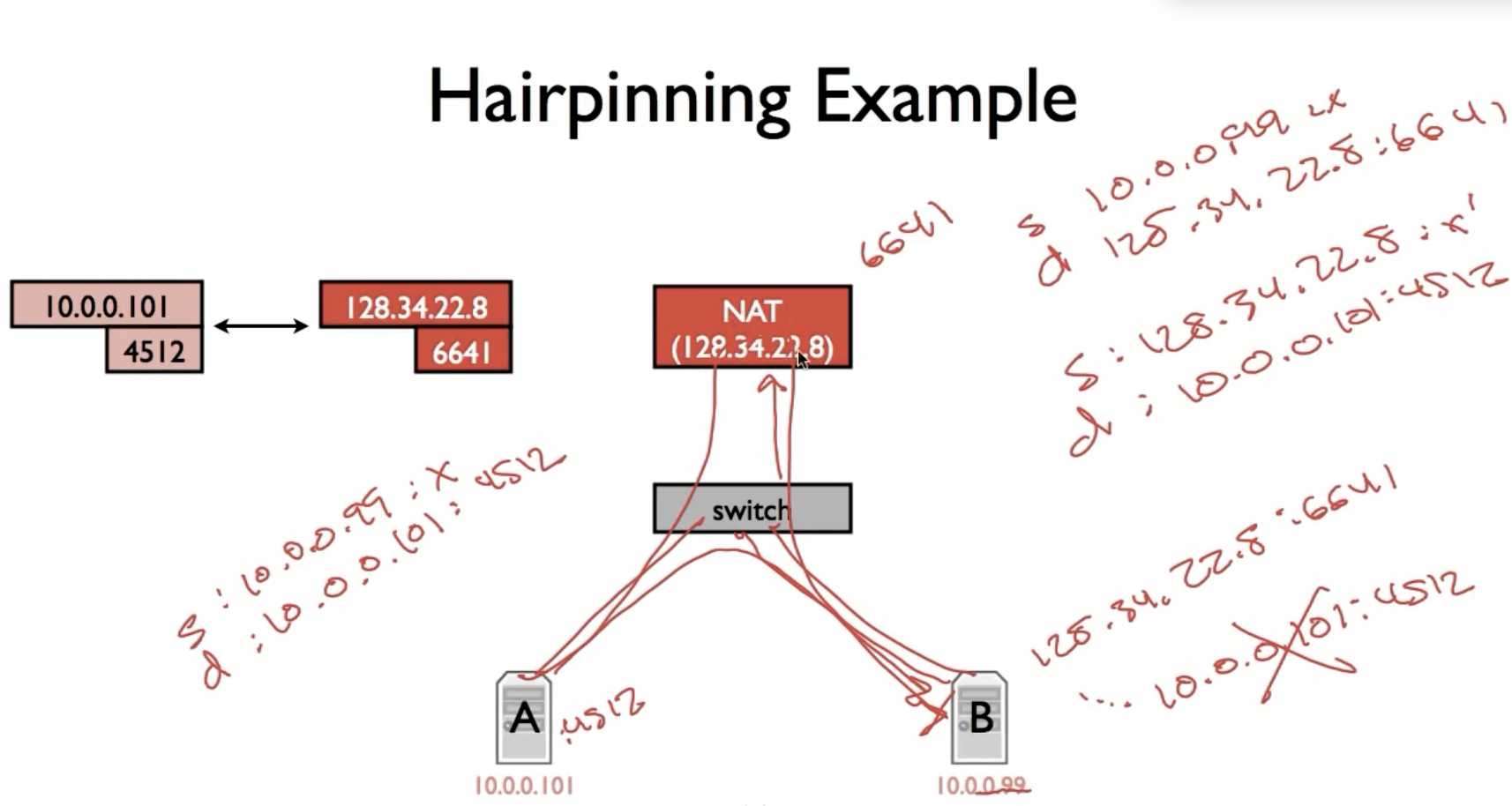
Hairpinning:
Hairpinning是两个都在NAT后边的主机试图通信,B向A发送数据包,两者由switch连接,switch通过NAT连接到internet上。B一开始发送的数据包(由于只知道A的公网IP):
saddr: 10.0.0.99
Daddr: 128.34.22.8
在NAT内部,daadr(+port)被翻译成A的socket(ip: 10.0.0.101)
现在的问题是saddr是否会被翻译?
如果source address仍然保持B的private ip,这意味着B在收到A的ack时不会经过NAT转换,因为其daddr是原本的saddr,它是B的private ip,所以B会收到一个来自10.0.0.101的数据包,这不是我们想要的结果。
所以B发给A的数据包,在经过NAT时也要被转换:
Saddr: 128.34.22.8
Daddr: 10.0.0.101
如此一来,当A返回ack时,其路径就会经过NAT,并将源地址和目的地址翻译成正确的ip。
NAT的使用会带来很多问题,比如我们需要利用一些tricks来实现两台主机之间的通信,仅仅因为其中的某一台(或者两台)被藏在了NAT的后边:
connection reversal:

对于除了full cone NAT的NAT,由于B不能直接和A建立连接(一开始NAT中没有对应的mapping),所以B需要和某一个能与A通信的服务器R,之后A收到B想要建立连接的信息后,主动向B发起通讯,所以被叫做connection reversal。
Relay:

如果两台机器都被放在NAT之后,则两台机器都需要通过R进行信息交换和通讯,这种机制被称为relay。
当然在这种情况下,我们还有其他的选择来建立两者之间的通讯,比如NAT Hole-Punching:
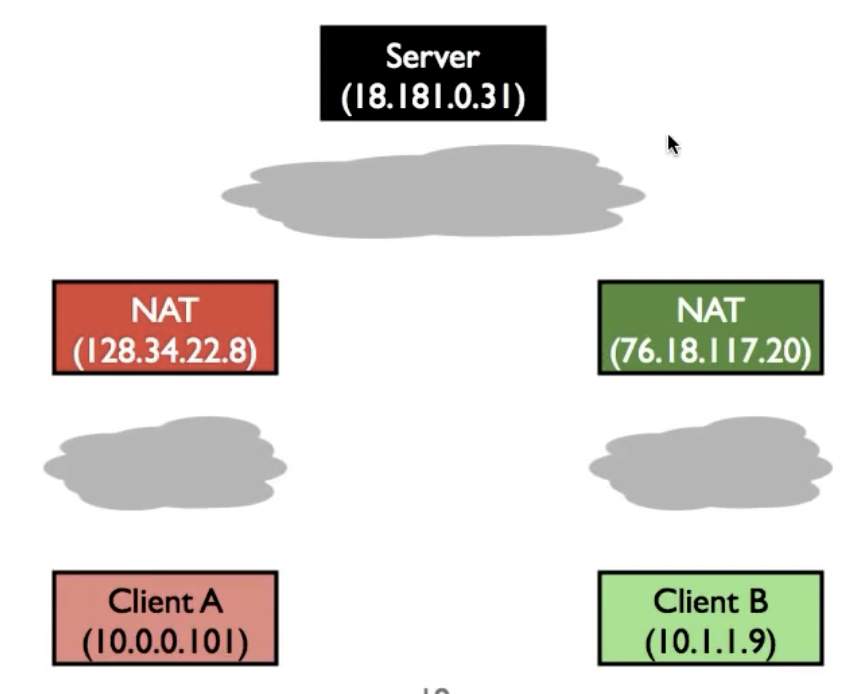
如果是full cone NAT,情况比较简单,A和B在向internet主动建立通信后,即可向Server索要B或者A的socket信息,此后可以越过server直接与另一端建立通信。
但如果不是full cone NAT,情况就变得更加复杂:在完成了上述步骤之后,A与B可以通过同时(simultaneous open)向NAT发送想要与B或者A通信的packet,来向NAT中添加对应的mapping,当packet越过NAT到达接收端时,就可以通过刚添加的mapping信息成功建立通信。
Symmetric NAT无法通过这种方式建立通信,因为A或者B在与server通信时被mapping的socket信息与尝试直接向B或者A通信的socket信息不同,mapping不奏效;比如对于A,其携带的B上的NAT external addr是通过B与server之间建立的连接时被记录在server里的,但此时B因为尝试与A直接连接,所以其NAT external addr发生改变,这将导致A无法找到对应的ip。
而NAT的使用也导致了未来很难再有新的传输层协议出现,因为这样的应用会导致NAT无法识别(先有鸡还是先有蛋的问题)。

HTTP
HTTP是一个简单的请求-响应协议,他通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。它是一个应用层协议。
比如对于浏览器和服务器,最常用的方法是服务器机器上的端口80建立一个TCP连接,使用TCP的意义在于浏览器和服务器都不需要担心任何处理长消息、可靠性和拥塞控制,所有这些事情都由TCP处理。
HTTP内置许多请求方法,包括GET,DELETE,POST,HEAD等。
GET filename HTTP/1.1
HTTP/1.1 200 OK

HTTP/1.0:
- Open connection
- Issue GET
- Server closes connection after response
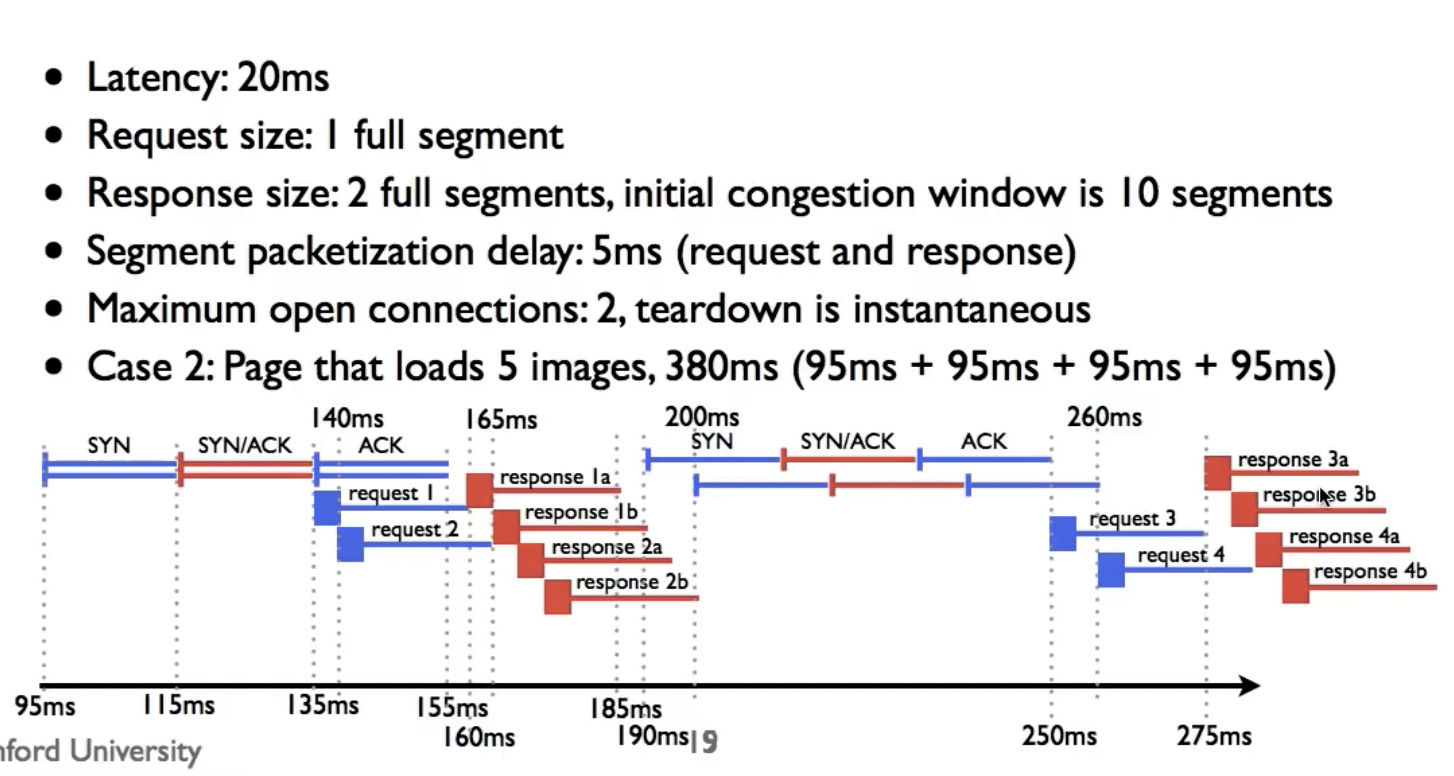
课程中给出的示例很有意思,注意到:
- 上图中没有使用连接重用(
connection reuse)技术,因为这是HTTP/1.0 - request1和request2之间的间隔相比于request3和4的间隔要更小,也就是说随着reponses因为queueing被delaying,further requests也被delay,所以随着时间的增长,这自然让requests和responses space out,减少了queueing delay。
HTTP/1.1 Keep alive
HTTP/1.0的连接被建立起来后,浏览器只允许发送一个请求,响应被发回来之后,连接就会关闭,这导致开启很多连接,速度变慢,同时congestion window根本不会增长。 而HTTP/1.1支持增加了如下支持,尤其是keep-alive:

SPDY
- Protocol proposed by Google to speed up the web
- Request pipelining
- Removes redundant headers
- Becoming basis of HTTP/2.0
BitTorrent
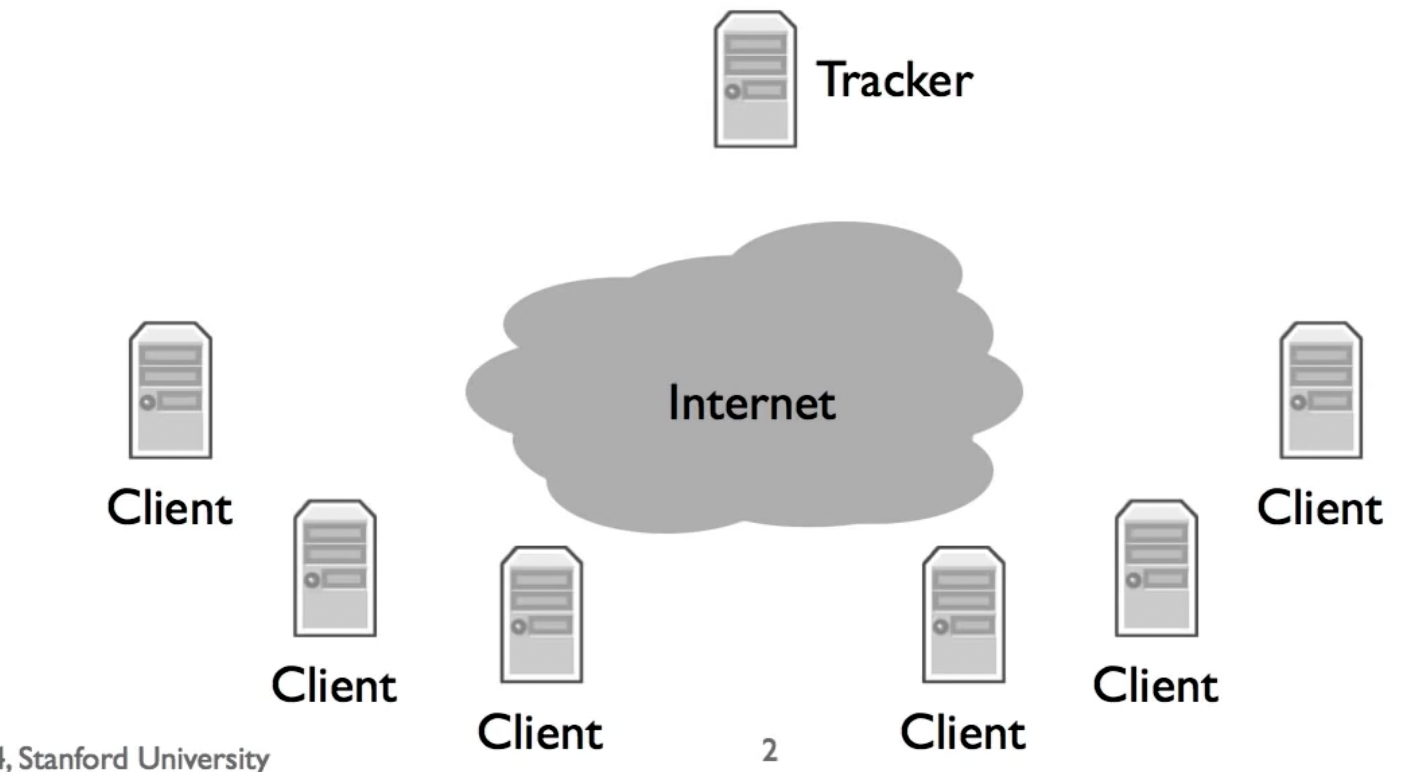
BitTorrent用于在对等系统中共享信息,它为每个内容提供商创建一个内容描述,即种子文件(torrent),其中包含如下信息:

在有tracker的情况下,swarm内的机器通过联系tracker开始peer之间的通信。而如果没有tracker,则会使用DHT进行信息交换(P2P,如chord)。
BitTorrent将一整个大文件分成N个比较大的pieces(256KB-1MB),方便TCP的cwnd增长到合适长度来增大throughput;同时他也会将一个大piece分成几个subpieces,从而允许他们在不同peers上被下载来减小latency。
Torrent文件中包含了每一个块的SHA-1哈希,用来检验数据的完整性。如果一个peer发出了太多不完整的,损坏的(可能是恶意的)pieces,则会被加入黑名单。
peers会互相交换信息,在下载过程中,按照rarest first policy下载pieces,尽量减少因为pieces所在的位置太少或者丢失从而导致没有用户可以下载成功。唯一的例外是在整个文件的最后几个pieces时,会向多个peers来请求,避免下载到最后在等待最后一个piece的时候速度太慢。
Tit-for-Tat (TFT)
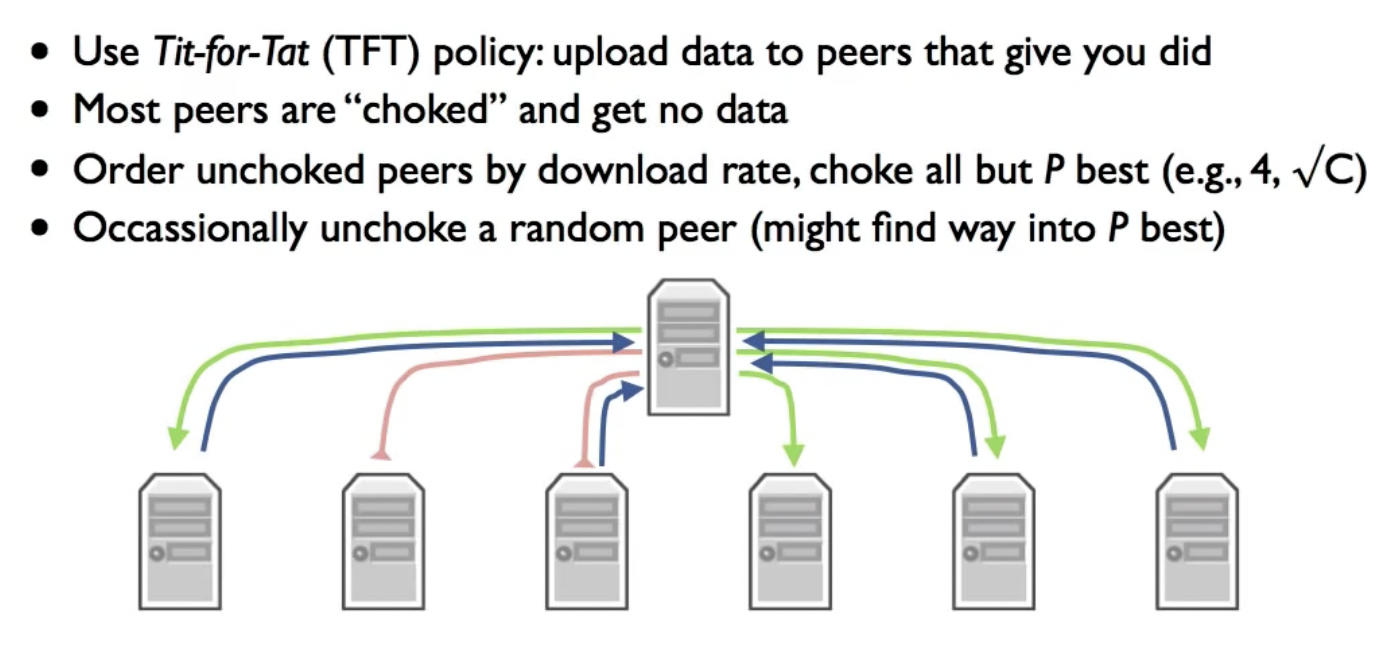
大部分节点被阻塞,只向那些曾经给过你资源的节点传送资源(贡献越多,回报越大)。但为了避免有些节点只有在你向他们传送数据之后才会以很快的速度给你上传数据,每间隔一段时间,都会将一个随机节点非阻塞,这也给了那些初始加入集群的节点机会。
但这种方法还可以继续被优化,因为如果节点A决定把资源分配给3个提供给他最大的下载速度的节点BCD,那么BCD会获得全部的A要发出去的资源,但实际上,A可以采取这样的策略:

这种机制被称为BitTyrant,可以获得70%的性能增益。
Domain Name System (DNS)
DNS将name和IP对应起来,这使得即使IP地址发生变化,我们仍然能够访问到原来的网站。
History:

DNS在实现的时候,需要考虑到distributed control: people can control their own names,同时必须对单节点的failure具备鲁棒性。
DNS具有两个很明显的特征:
- Read-only or read-mostly database: hosts look up names much more often than update them
- Loose consistency: changes can take a little while to propagate
这使得DNS很适合做extensive caching。
DNS被组织成多个独立的层级:
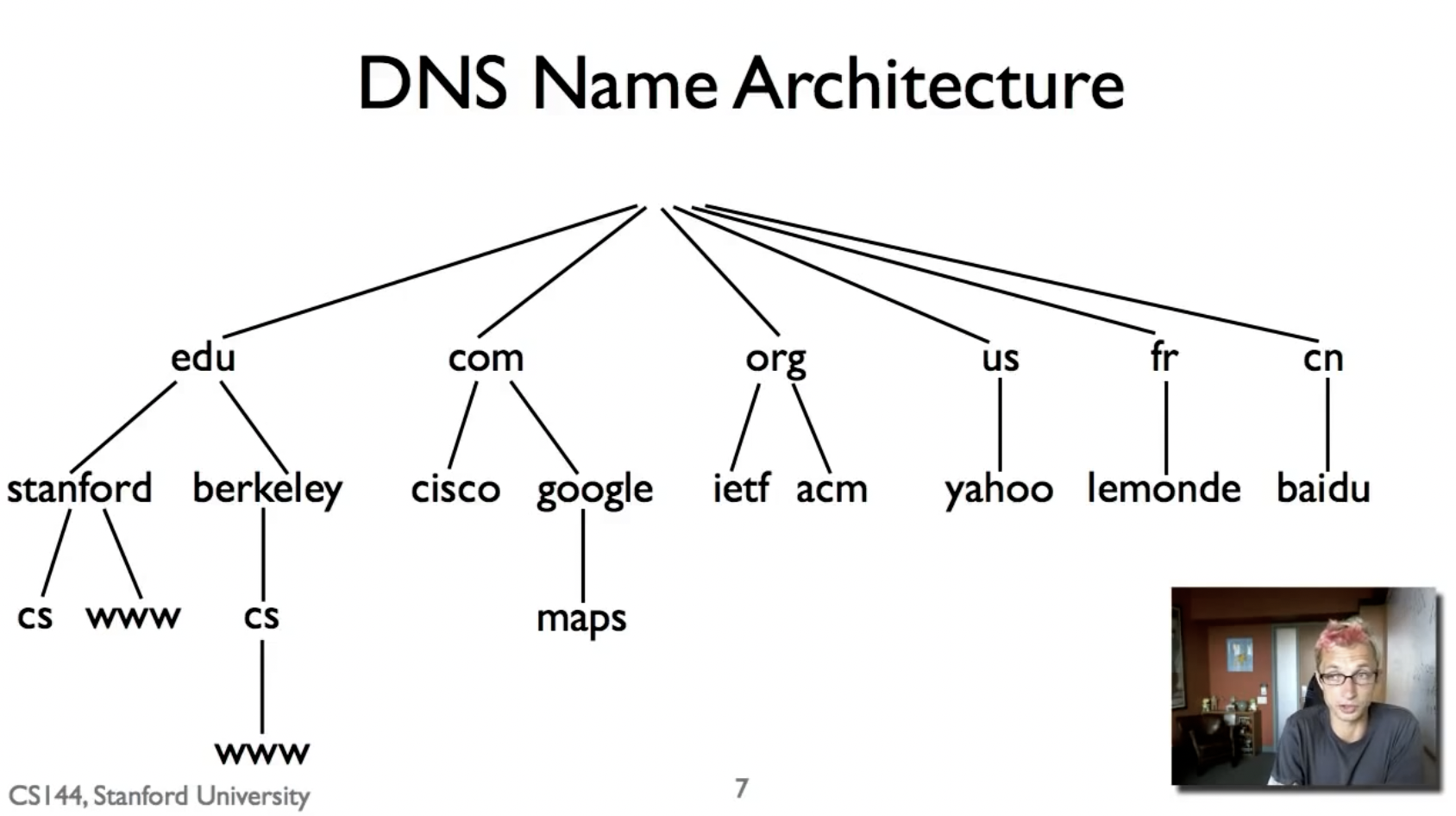
- Each zone can be separately administrated
- Each zone served from several replicated servers
对于根服务器,总共有13个,分布在世界各地(a,b,c,…,m),这13个服务器每一个都被做了replication,他们通过anycast的手段进行了复制。
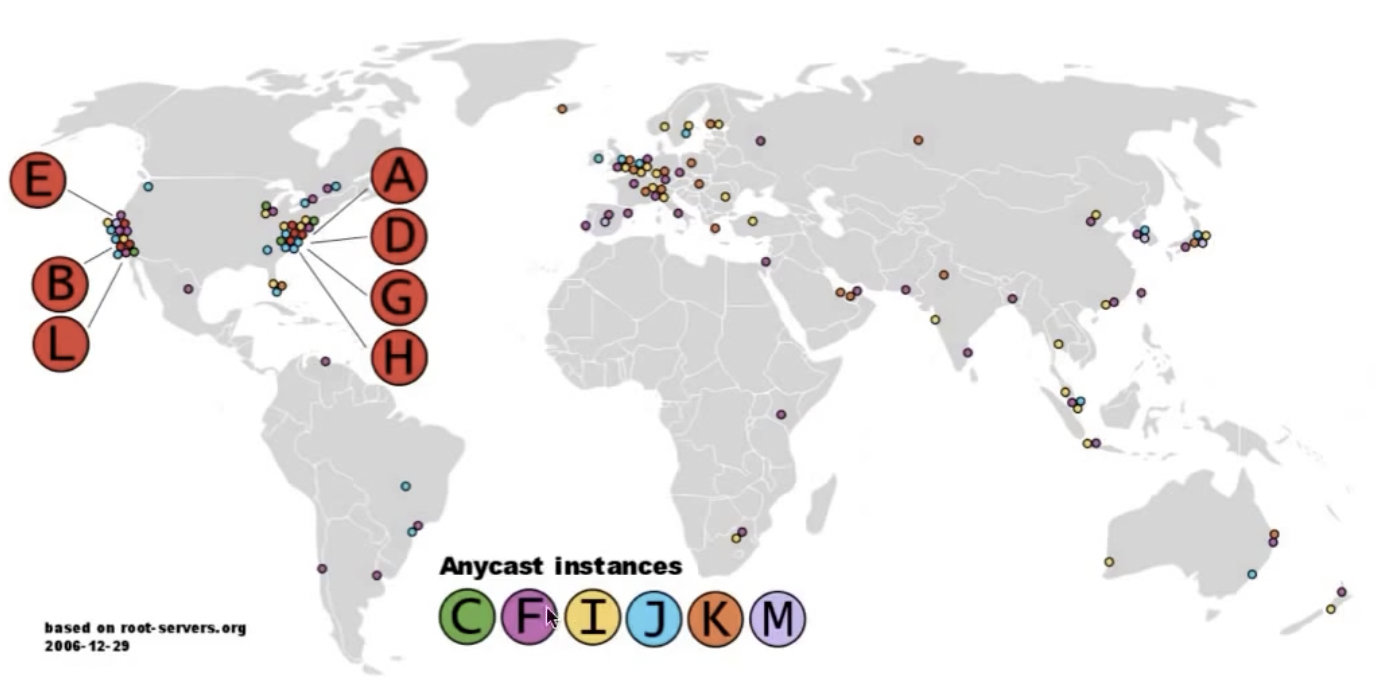
DNS query
- client通过DHCP找到resolver(本地域名服务器)上存储的DNS root server的IP地址,并进行递归查询。
- 而对于root server以及后续的每个服务器,他们并不递归的查询服务,而是将结果返回给resolver,让他继续查询,所以被叫做迭代查询。
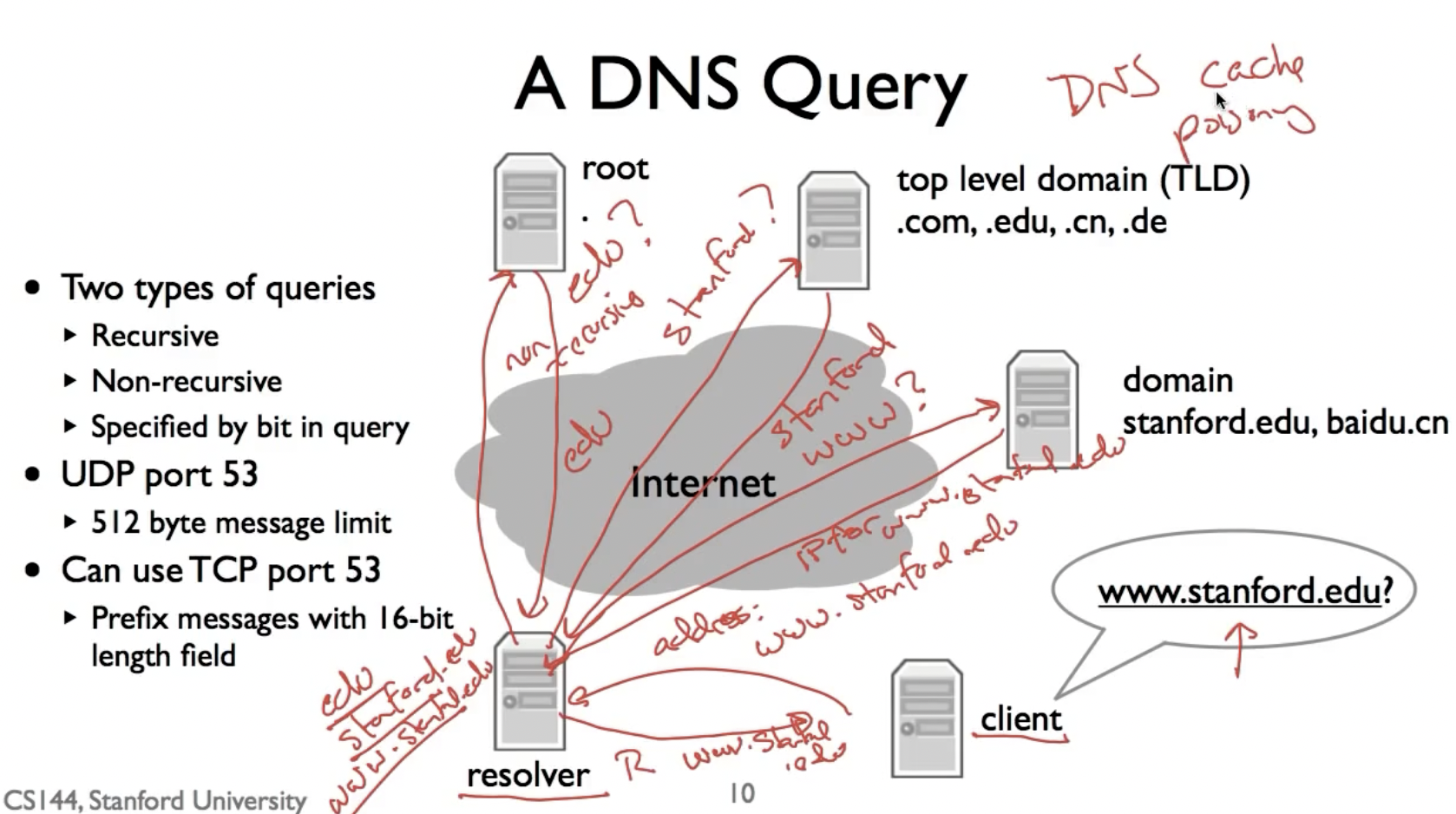
注意,一般DNS query都使用UDP port 53,我们也可以使用TCP进行此操作,但是需要在DNS message的前边加上一个16bit的长度信息告诉发送端信息的长度,因为TCP基于stream而不是UDP类似的有长度限制的datagram,他有可能将一个message分成几个packet发给我们,所以我们必须具有长度信息才知道如何处理response。
最后,resolver会将结果缓存(root cache file)起来并转发给client,如果下次再有别的client需要向resolver查询同一个DNS query,他可以直接使用自己的caching。
而我们常说的DNS污染就是在resolver中,缓存被替换成了不匹配的IP地址,导致找不到对应的服务器位置。
DNS queries and Resource Records
DNS的记录格式如下:
name [TTL] [class] type rdata
- Name: domain name (e.g. www.berkeley.edu)
- TTL: time to live (in seconds)
- Class: for extensibility, usually IN 1 (Internet)
- Type: type of the record (e.g. A/AAAA, NS, CNAME)
- Rdata: resource data dependent on type
dig tool
之所以要有TTL,是因为高速缓存的答案不具备权威性,在某一个权威记录上做的变化不可能传递到全世界所有知道他的缓存,所以缓存的表项不应该生存的太长。
几种常用的消息类型:
- A: 对应的IPV4
- AAAA: 对应的IPV6
- NS: 用于所在域和子域的name server,可以用来进行该域内的域名查询处理
- CNAME: 别名,相当于宏定义,如果一个域名有了CNAME记录,则不能添加其他类型的资源记录,但是可以有多个CNAME记录
- MX: 域内mail server的名字(同时也会记录对应的A record),因为不是域内的每个计算机都做好了接受电子邮件的准备,所以必须以此记录加以说明愿意接受电子邮件的邮件服务器 (如果mail-server-name没有对应的A record,比如有一个CNAME记录,则邮件无法被接收)
- ……
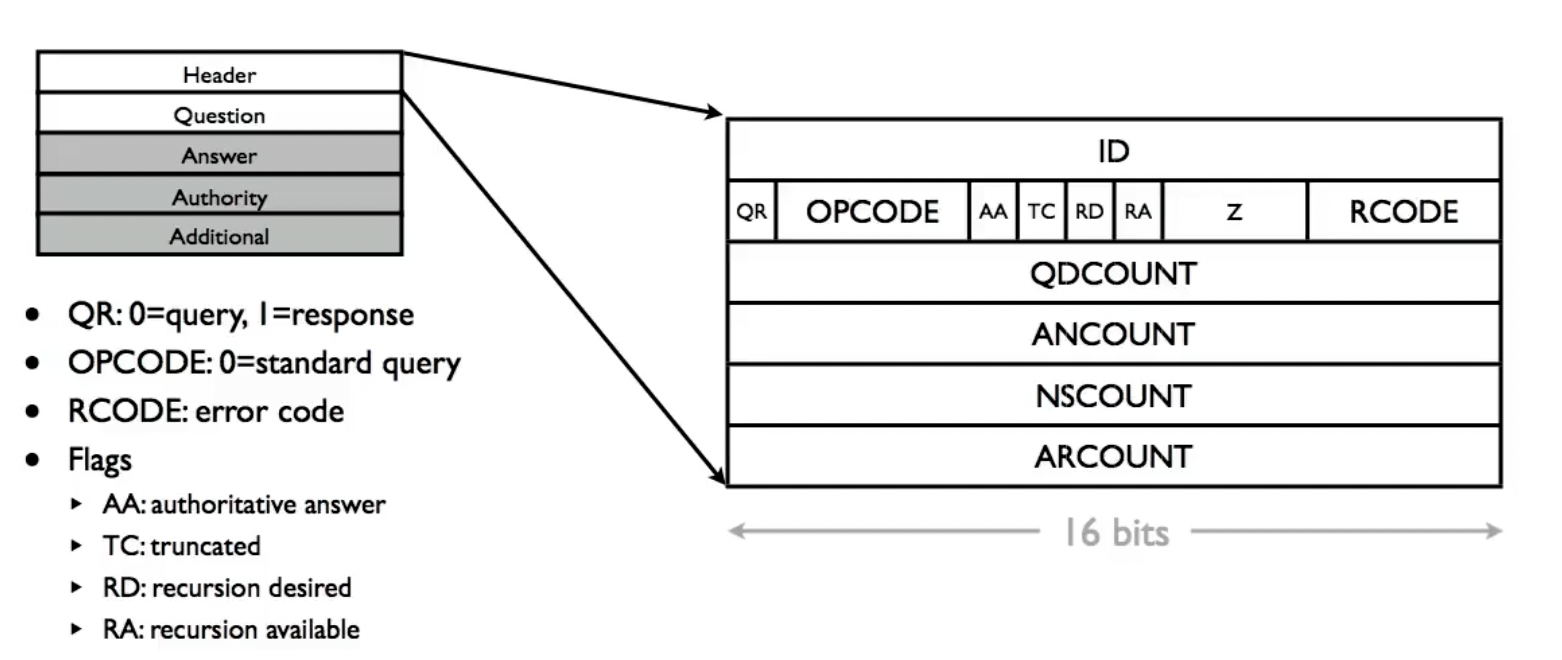
ID: pair query and responses
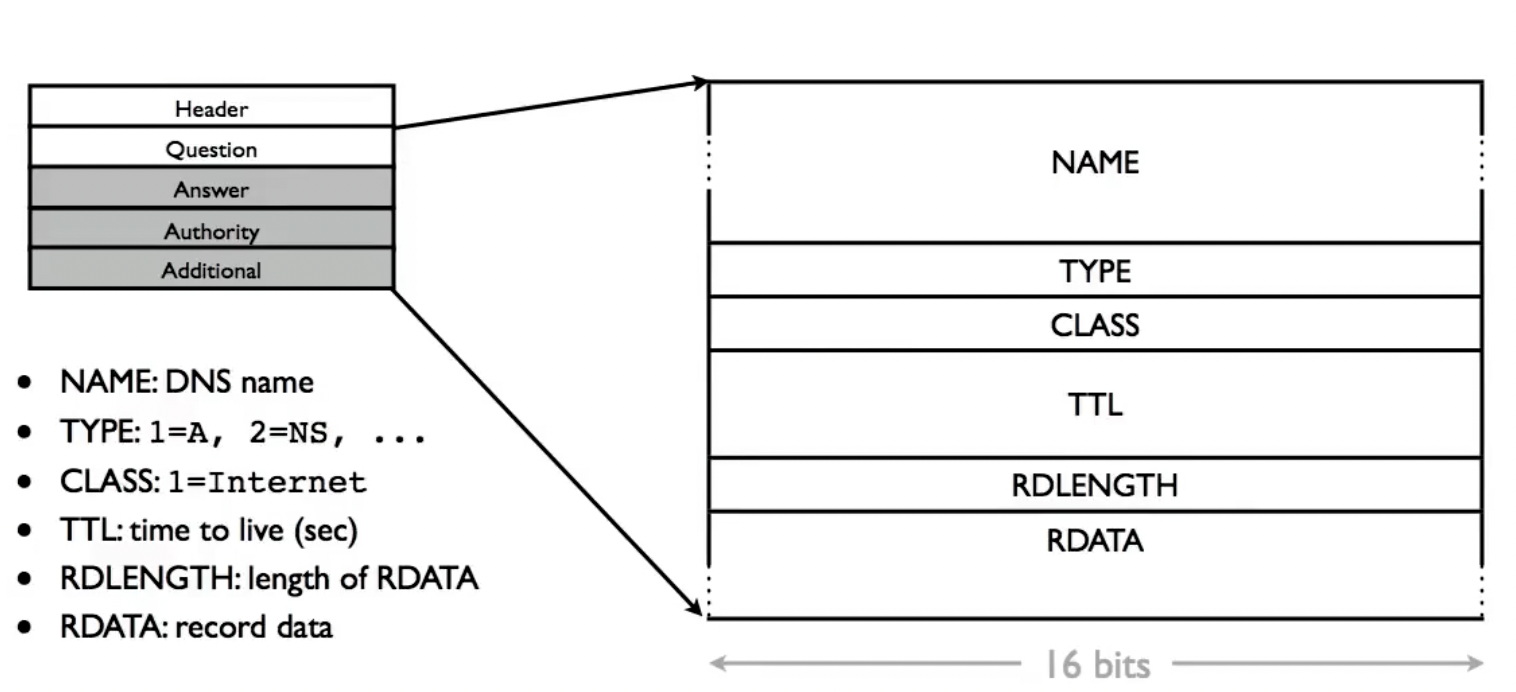
DNS Name Compression:
因为DNS消息中,域名可能会在多个地方多次出现,所以可以进行压缩:消息全部使用ASCII表示,下图中展示了其记录域名的方法和压缩方法,即在域名长度大于192bit时,用最后的14个bits记录域名在整个消息中的偏移位置,相当于坐标。这种压缩方式不仅可以用来压缩完整的域名本身,当消息中包含了该域名的根域名时(e.g. eecs.berkeley.edu -> berkeley.edu),也可以利用偏移量进行定位压缩。
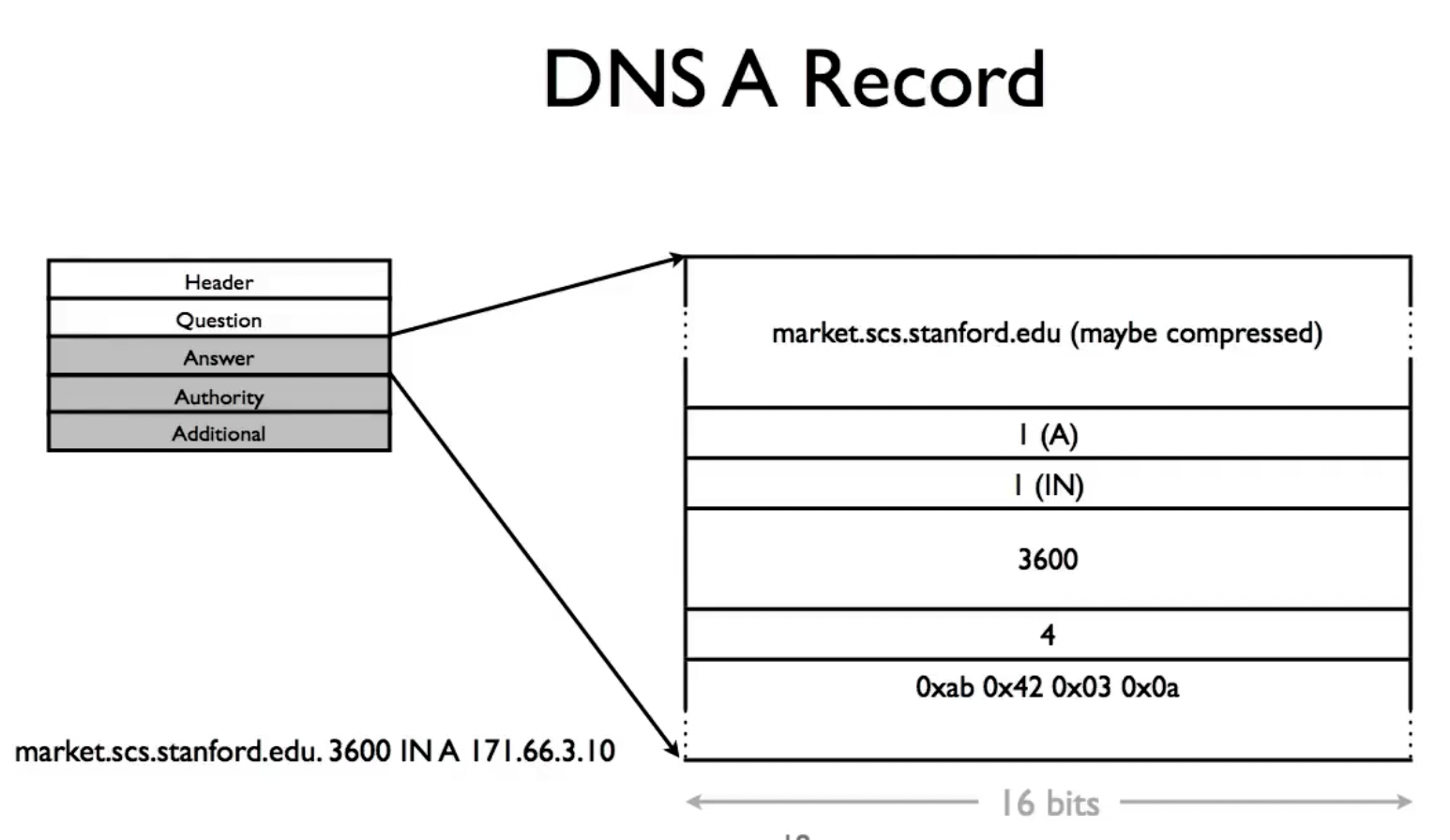
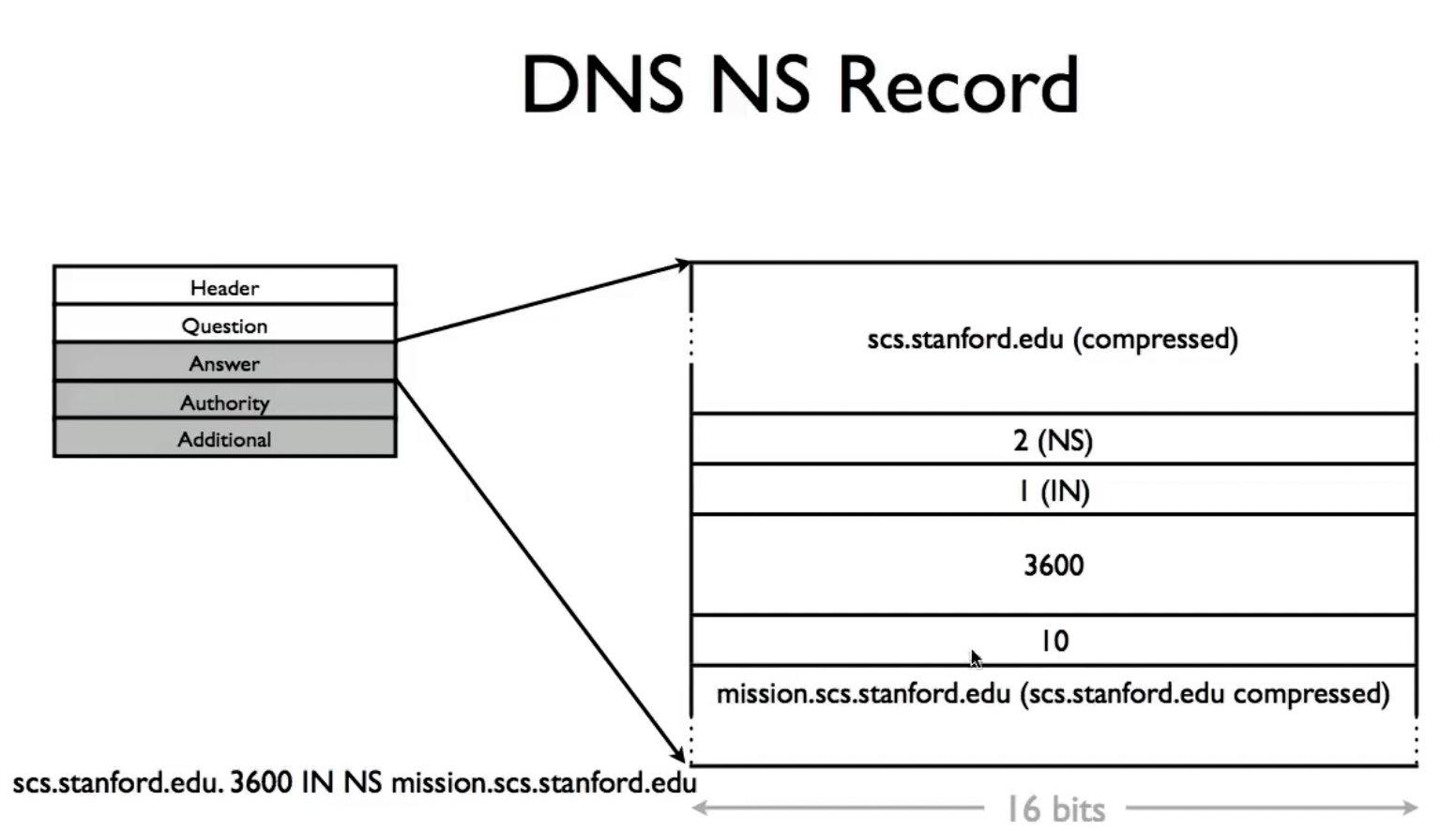
关于NS的一个细节问题是,在query到某一个层级的域名服务器时,他会给出我们想要查询的子域的NS(domain name),但我们要如何找到这个NS呢?
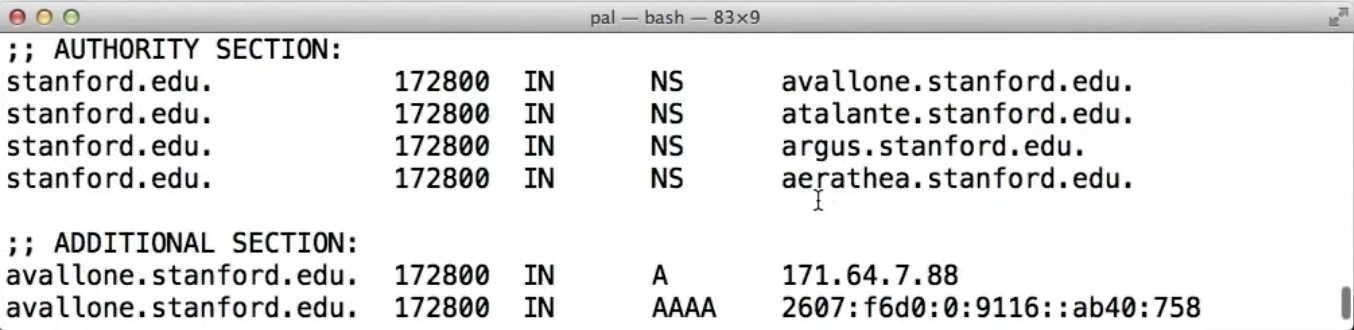
所以,该域名服务器还会把想要查询的子域的A record记录在服务器中,这被称为glue records:

Dynamic Host Configuration Protocol (DHCP)

在DHCP出现之前,人们往往需要手动分配这些信息,但这很不灵活;DHCP解决了这个问题,动态分配IP, netmask,并给予这些信息一个lease term,当信息过期时,client可以选择向DHCP服务器re-acquire或者在某一时刻选择release lease。DHCP的请求流程包括:discover,offer,request(从多个offer中选择一个),ack, release:

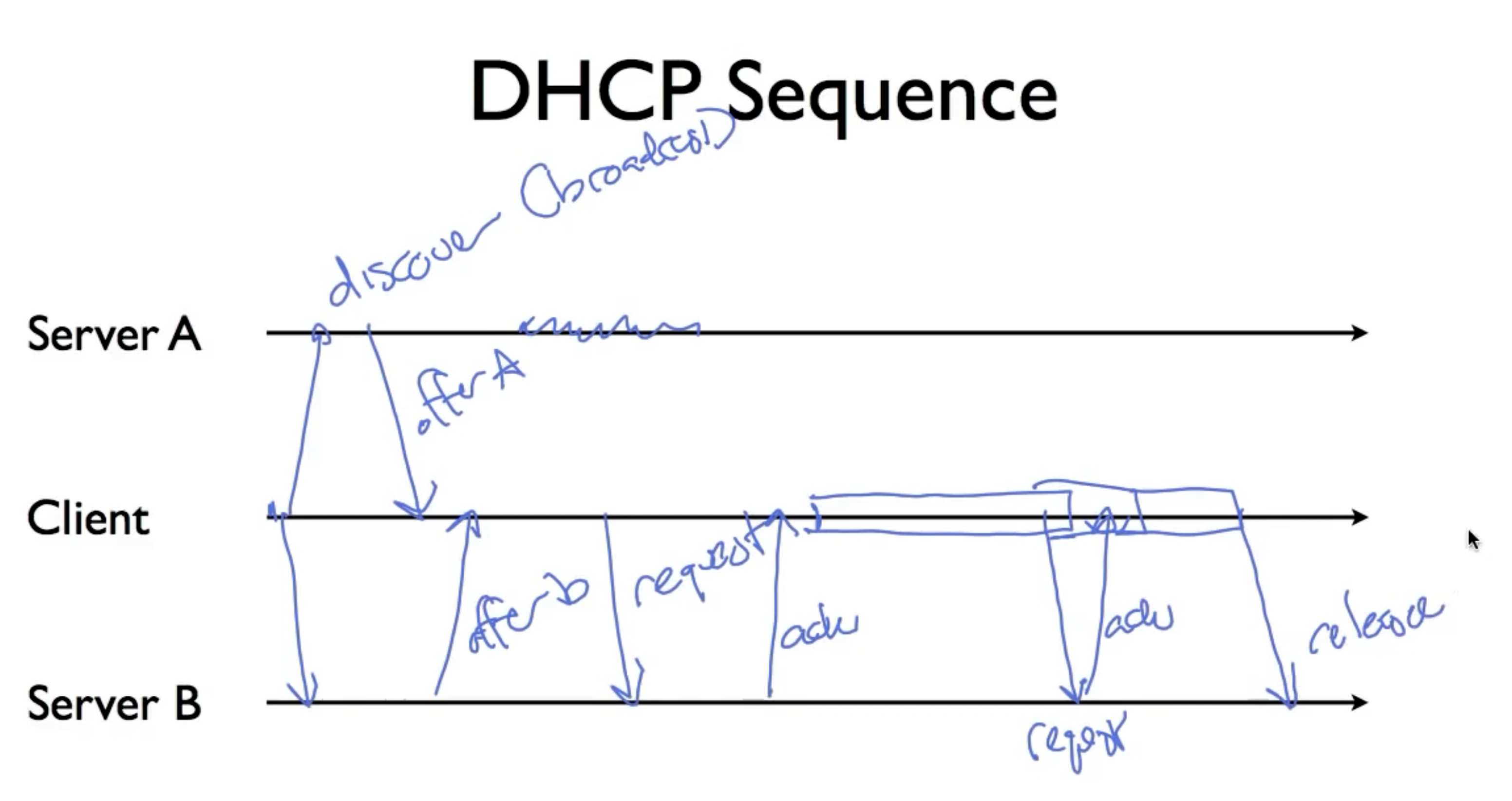
由于DHCP被用来分配IP,所以其IP地址在发送时使用的是默认地址0.0.0.0,也即没有使用IPV4(因为此时还没有IP地址),client通过UDP在68 port发送给server的67 port;同时因为client不知道DHCP服务器的地址,所以他会选择向IP地址255.255.255.255 broadcast。由于DHCP服务器可能和client在不同的link上,所以使用relay方法进行通信(用于在距离太远而无法直接发送信息的两个设备(如服务器和计算机)之间发送信息)。
Routing
几种不同的路由算法:
Basic Approaches
- Flooding
泛洪算法,将每一个入境数据包发送到除了该数据包到达的那条线路以外的所有其他出境线路。flooding算法显然对于大多数数据包来说不太实际,但是其鲁棒性很好,即使大量路由器被炸成碎片,其依然可以找到一条路径。其次,其需要的安装很少,只需要知道自己的邻居即可。
- Source routing
主机携带所有信息(end-to-end solution),packet携带一个address列表,end-host必须知道网络拓扑并选择对应的最佳路由。
- Forwarding table
这种方法可以被看作是source routing的一种优化:我们让network负责hop-by-hop routing,这需要routers populate forwarding tables,其相当于维护了一个per-destination state,而非先前的per-flow state.
- Spanning tree
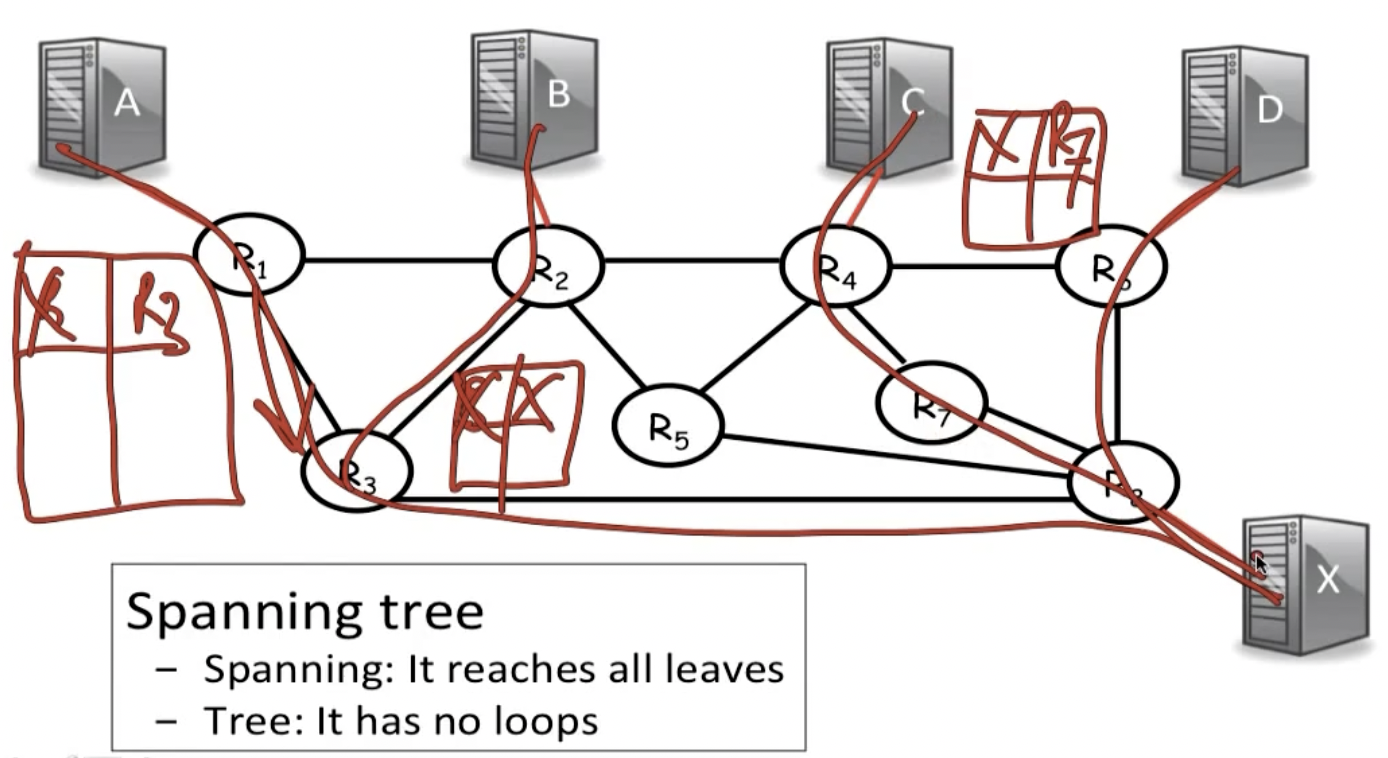
- Multipath
这种方法的主要目的是为了避免某一条link因为过大的load导致速度变慢,所以会尝试在不同的路径上分摊负载。
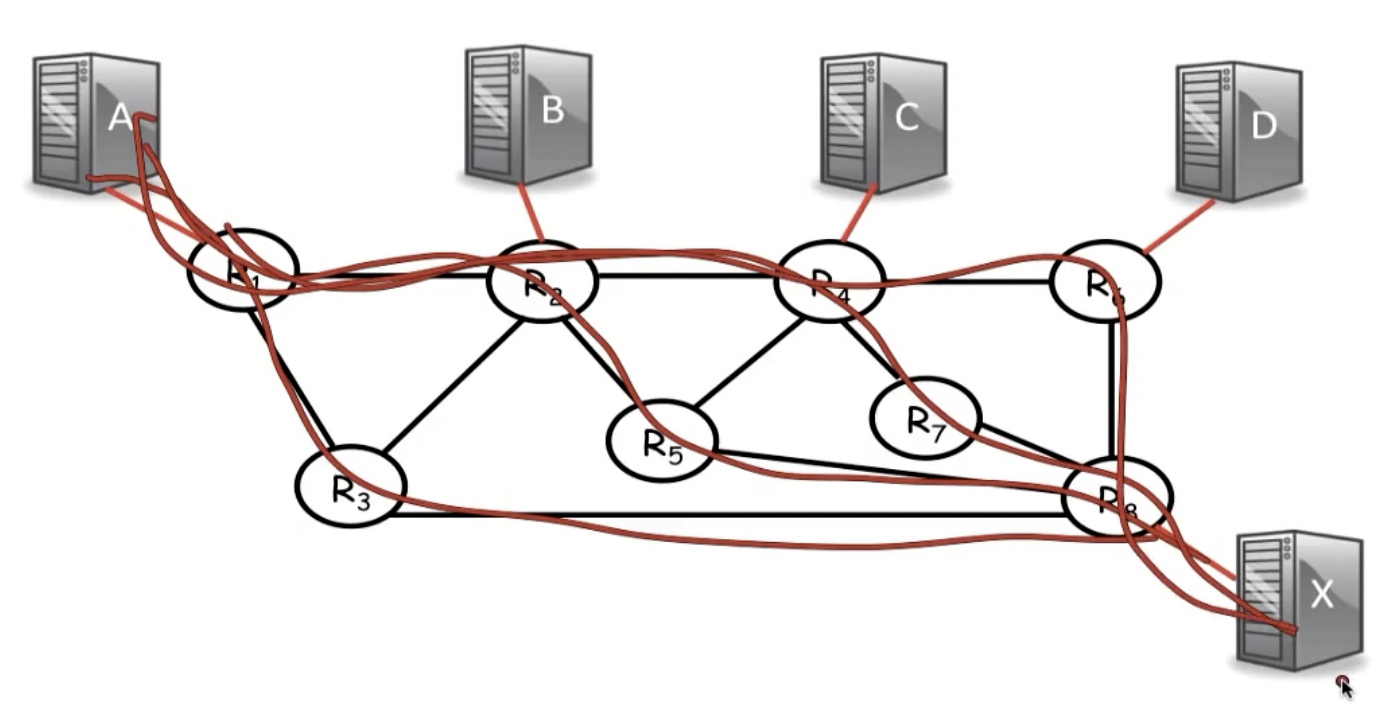
- Multicast
很多情况下,我们并不只想把一个packet上传到一个位置(unicast),而是要上传到多个hosts中,这需要将packet进行复制,这种路由操作被称为multicast。
Distributed Bellman-ford algorithm
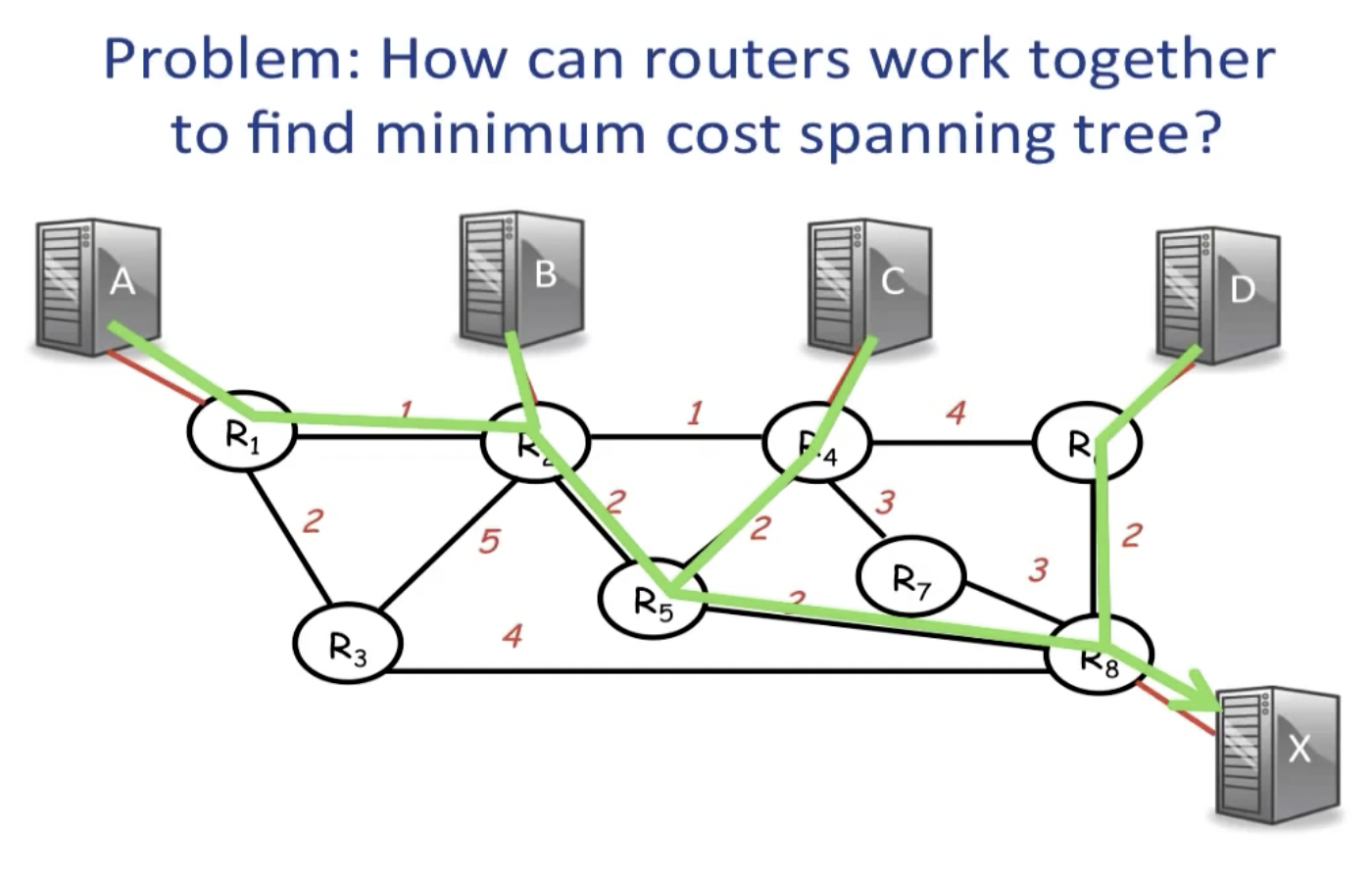
这等价于找到routers之间的minimum cost spanning tree。
Bellman-ford算法属于**距离矢量路由(distance vector routing)**的一种:每个路由器维护一张表(即一个矢量),表中列出了当前已知的到每个目标的最佳距离,以及所使用的链路。这些表通过邻居之间相互交换信息而不断被更新,最终每个路由器都了解到达每个目的地的最佳链路。

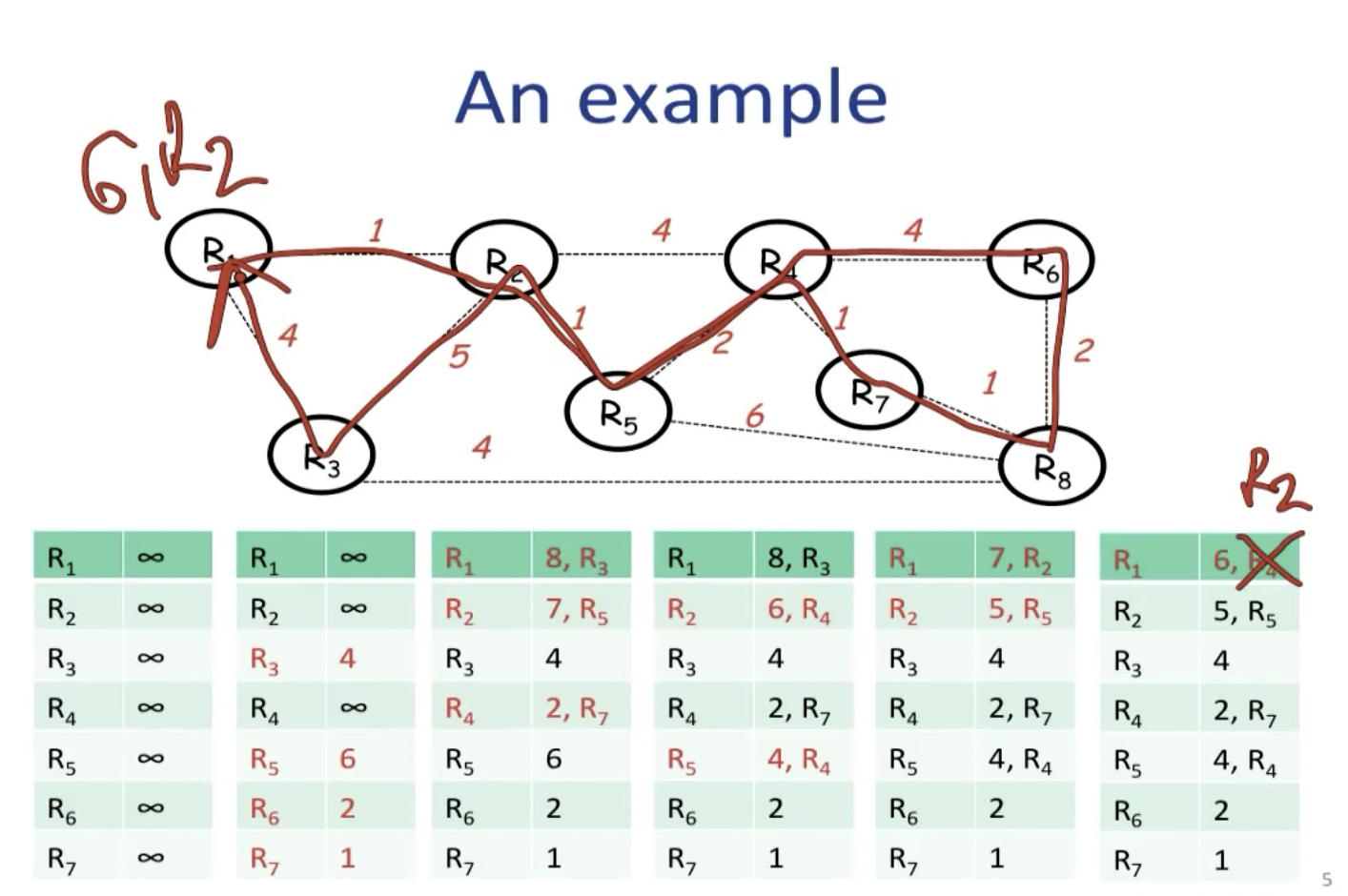
算法的终止条件是什么?我们只要达到最远的两个routers之间的距离就ok。
整个网络的最佳路径的寻找过程被称为收敛(convergence),因为路由器可以在所有路径中有选择的计算出一条最佳路径,但该算法有一个严重缺陷:Bad news travel slowly。
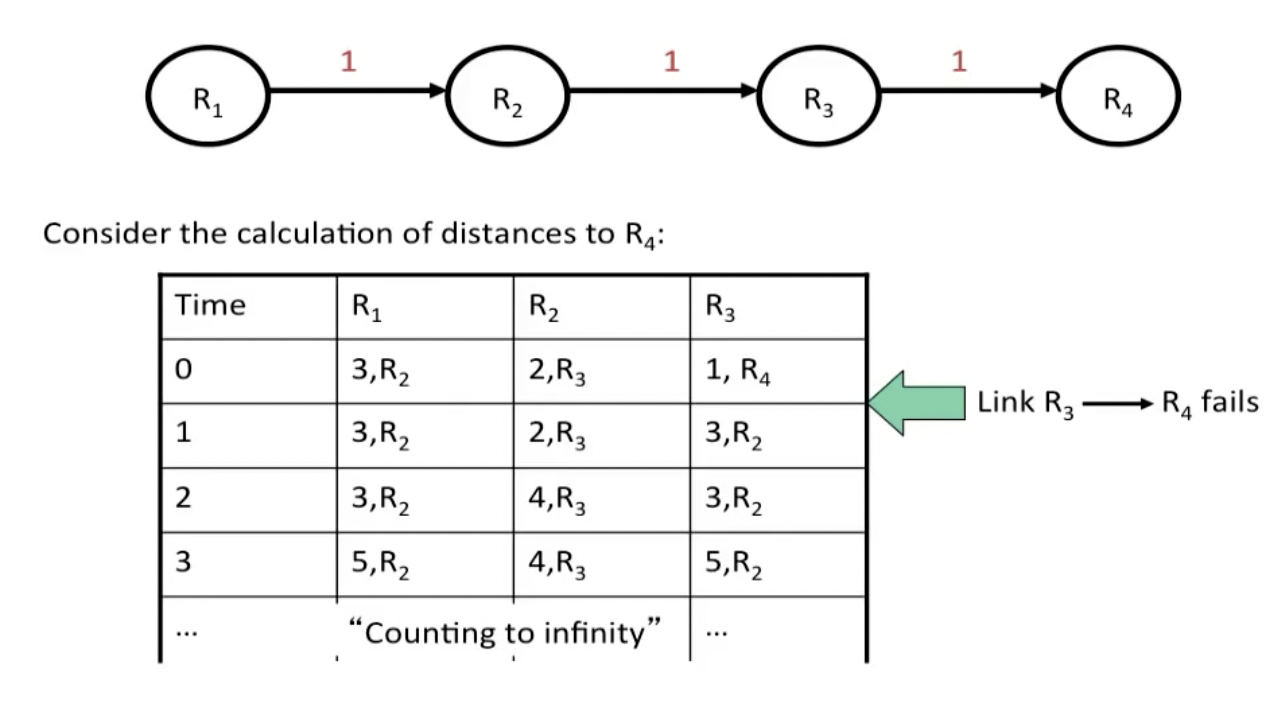
对于如上图所示的情况,如果R3和R4之间的link坏掉,则下一步R3会尝试从最近的R2连接R4(因为他发现R2说自己可以用cost 2到达R4),而在此之后,R2发现他的邻居R3的距离发生了更新,所以继而更新自己的cost,如此循环往复。这个问题被称为**无穷计数(count-to-infinity)**问题。
为了解决该问题,我们可以将infinity设置成一个小一点的数,或者限定R2和R3之间的传播关系:

Dijkstra‘s algorithm
该算法隶属于链路状态路由算法(link state routing),该算法要求每一个router拥有全部的路由信息(可以通过flooding获取),这样一来每个router就可以独立运行Dijkstra算法:

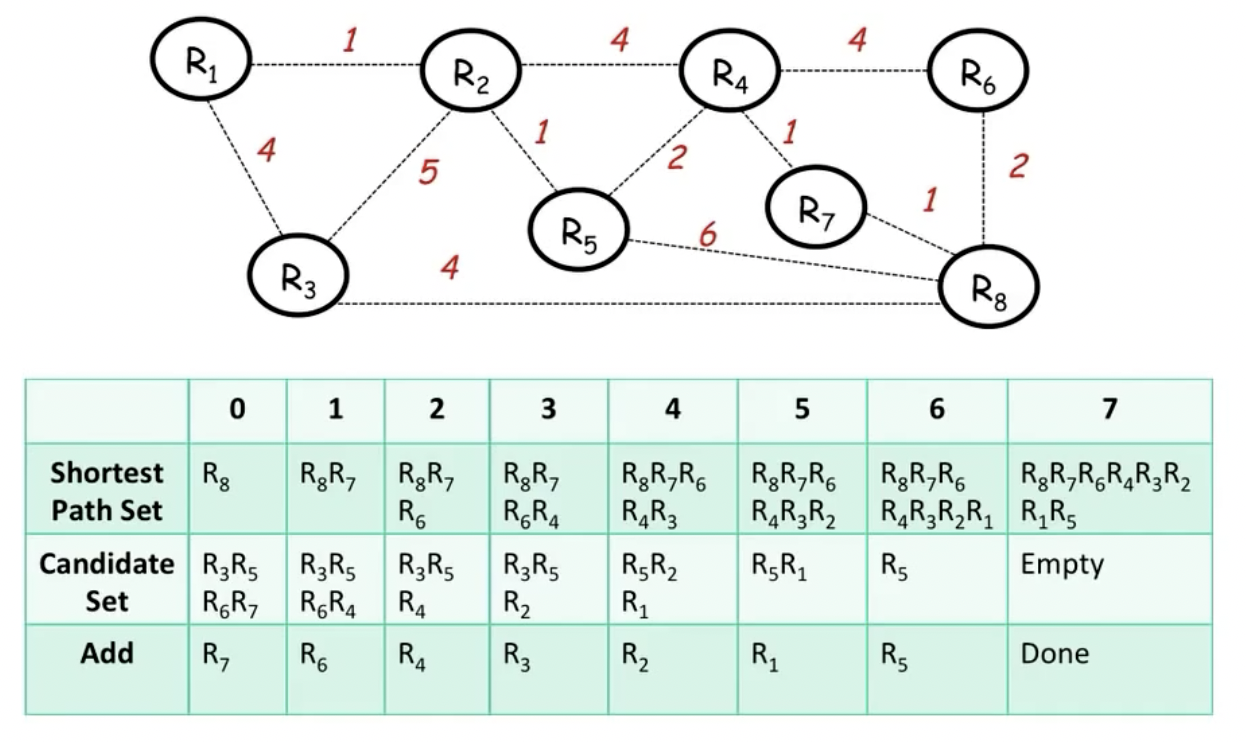
该算法在我们已经包含了所有的router,即数量达到之后,就可以停止。
RIP & OSPF
Internet由大量的独立网络或者**自治系统(Autonomous System)**构成:
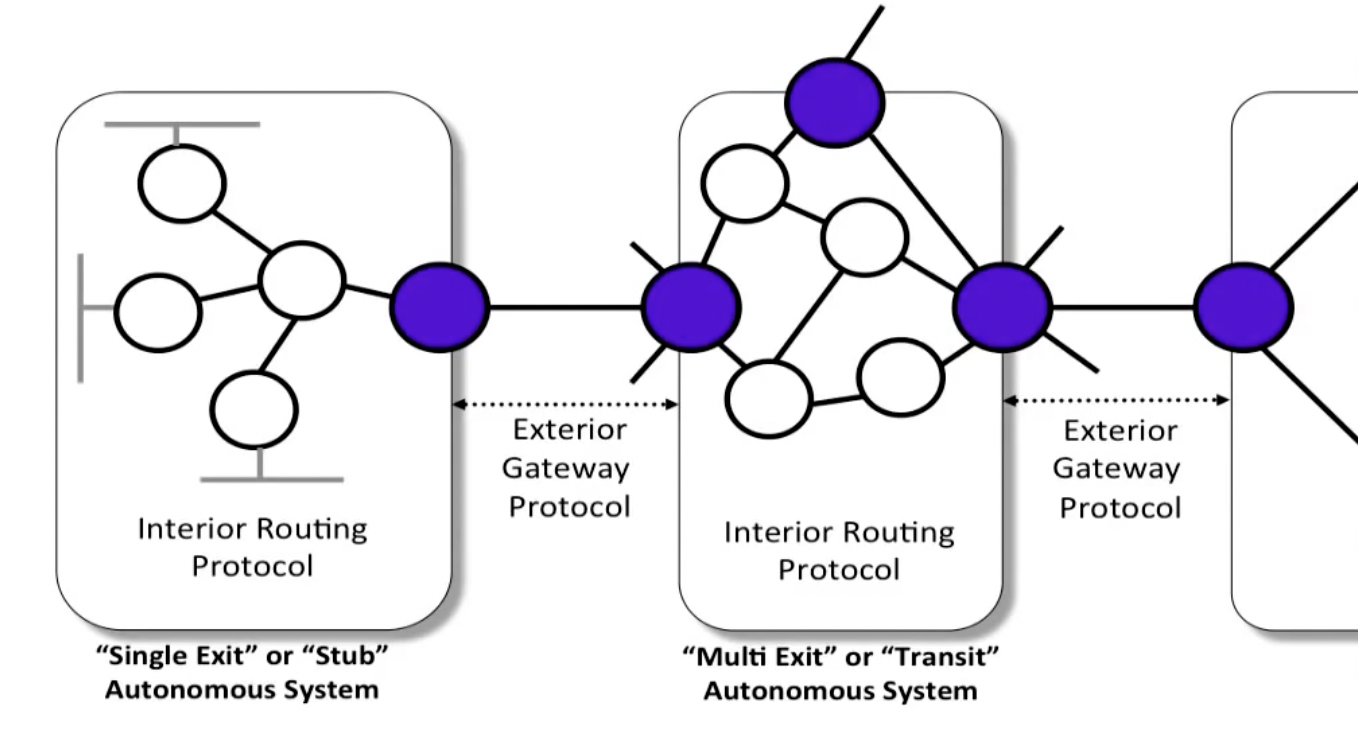
AS内,组织使用自己的路由算法(intradomain routing),AS之间则使用域内路由(introdomain routing),或者叫做exterior gateway protocol,Internet采用的域间路由协议是BGP-4.
我们可以使用如下方法查找需要的AS number:

早期的域内路由协议使用了距离矢量的设计思想,基于分布式Bellman-Ford算法的RIP(Routing Information Protocol)被使用,但在大规模网络系统中工作的不是很好,同时受到无穷计数问题的影响,收敛速度一般很慢,因为这些问题,OSPF(Open Shortest Path First)借鉴了IS-IS协议,成为ISO标准。

OSPF协议使用flooding交换路由信息,之后利用Dijkstra算法构建spanning tree来计算最佳路由线路。同时,他实现了负载均衡,即避免像以前的协议一样把所有的数据包都通过最佳线路发送出去,即使存在两条同等程度好的线路也只选择一条使用。OSPF同时提供了一定程度的安全性,并可以将一个AS划分成多个区域,每个区域是一个网络或者一组互联的网络。区域不能互相重叠,但也不必面面俱到,也就是说有些路由器可能不属于任何一个区域。
在课程中,将AS分为single exit AS和multiple exit AS两种,关于AS和area更详细的介绍,可以阅读相关参考书,但这里按照课程给出的介绍:


对于只有一个exit的存根(stub)网络,如果routers对于转发进来的数据包不知道如何处理,只需要把他分发到forwarding table中的Default分支即可,但是对于multiple exit的AS,由于存在多个exits,所以路由器必须知道如何处理那些不属于该AS的packets,这也增加了routing table的大小。
关于上图中的approach1/2以及如何应对packets prefix不属于该AS的情况,之后的BGP中会详细讲述。
网络结构整体上如图所示,遵循Customer-Provider Hierarchy.
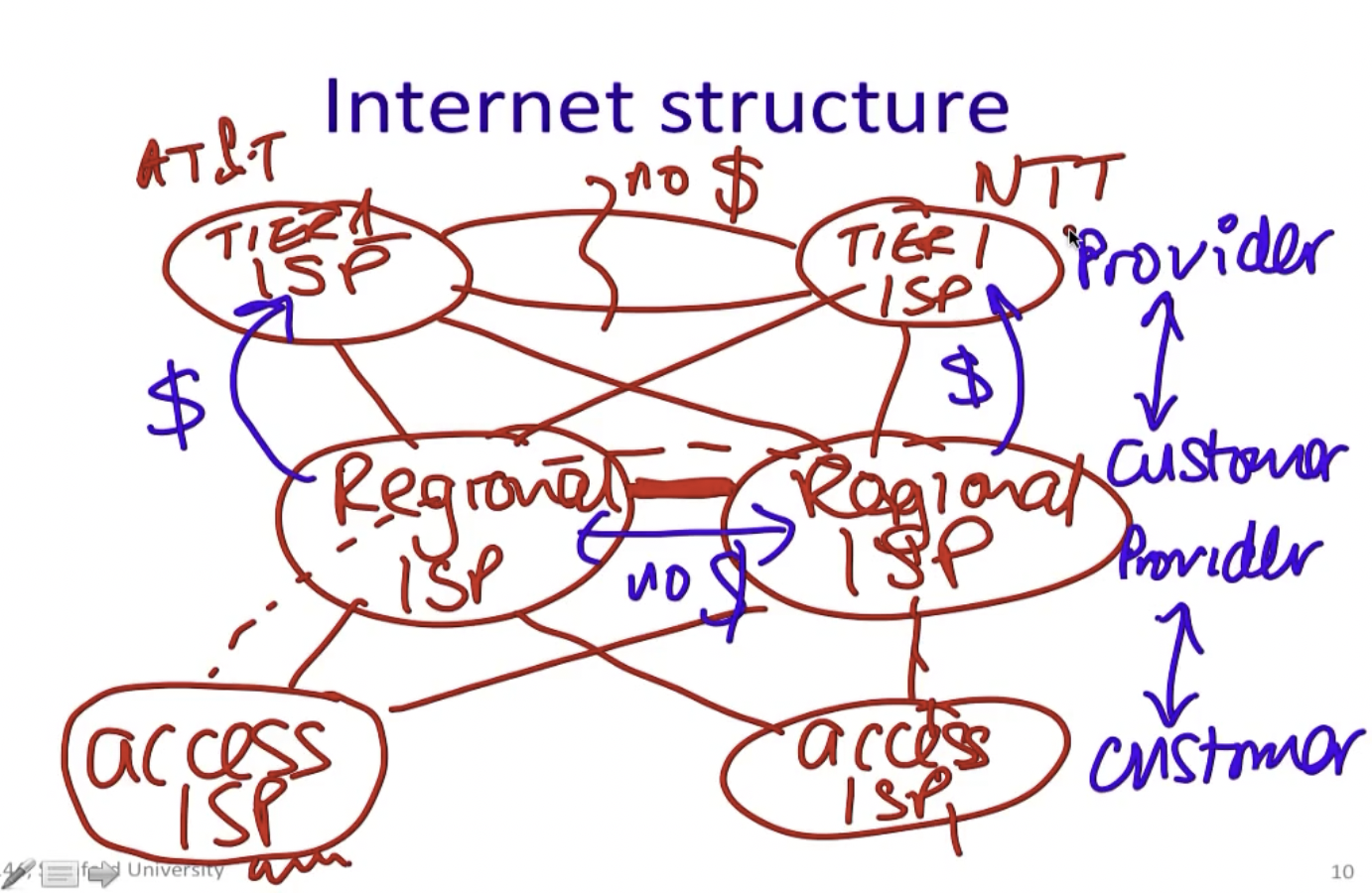
Border Gateway Protocol (BGP)
在一个AS内部,推荐使用的路由协议是OSPF或者IS-IS,**在AS之间,则需要不同的协议,因为域内协议需要做的只是尽可能很有效的将数据包从源端传递到接收方,他不必考虑政治和其他方面的因素,**所以我们需要一种新协议:BGP。

BGP是距离矢量协议的一种形式,但它与域内距离矢量协议不同:首先,他使用政策而不是最小距离来选择使用哪些路由,同时每个BGP路由器还跟踪所使用的路径(AS_PATH, e.g. {AS1, AS5, AS13}),路由通告消息中携带完整的路径易于让接收路由器发现和打破路由循环。这种方法称为路径矢量协议(path vector protocol)。
给出一个AS列表来指定路径是非常粗糙的方式,但是由于不同的AS之间可能使用不同的路由协议,且其成本无法比较。这正是域间路由和域内路由在方式上的不同所在。

同时,由于我们仍需要一些方法将BGP从AS的一侧传播到另一侧;虽然这个任务可以由域内路由承担,但由于BGP善于扩展到大型网络,因此通常使用BGP的一个变种,即所谓的内部BGP,iBGP(internal BGP),以区别于常用的外部BGP,eBGP(external BGP)。
当有link/router fail的时候,路径withdrawn。
The Peering Relationship
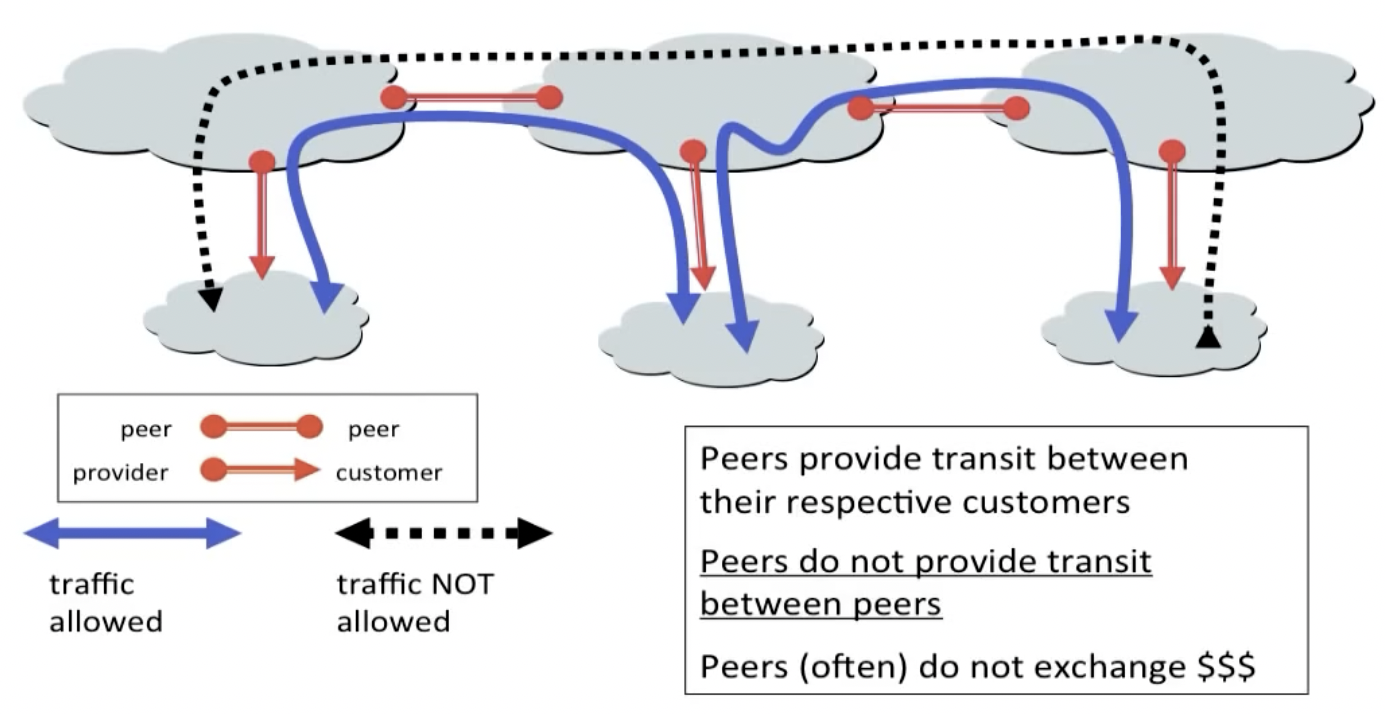
底层AS需要向顶层AS购买中转服务(transit service),而如果同级别AS愿意,他们可以直接给彼此发送免费流量,这一政策被称为对等(peer)传输。
需要注意的是,对等传输不能跨peer传输,比如上图中最左侧的AS想要直接给最右侧的AS途径中间的AS发送消息,因为中间的AS不想浪费自己的流量,他们不会从A和C的通信中拿到报酬。
BGP Messages
下边展示BGP是如何建立路径的。

其中的local preferences表示有些AS会有不能通过的路径和其他因素考量,比如在经济选择上customer>peer>provider。通过传递路由通告消息,途经的AS就可以反向建立路径,比如:
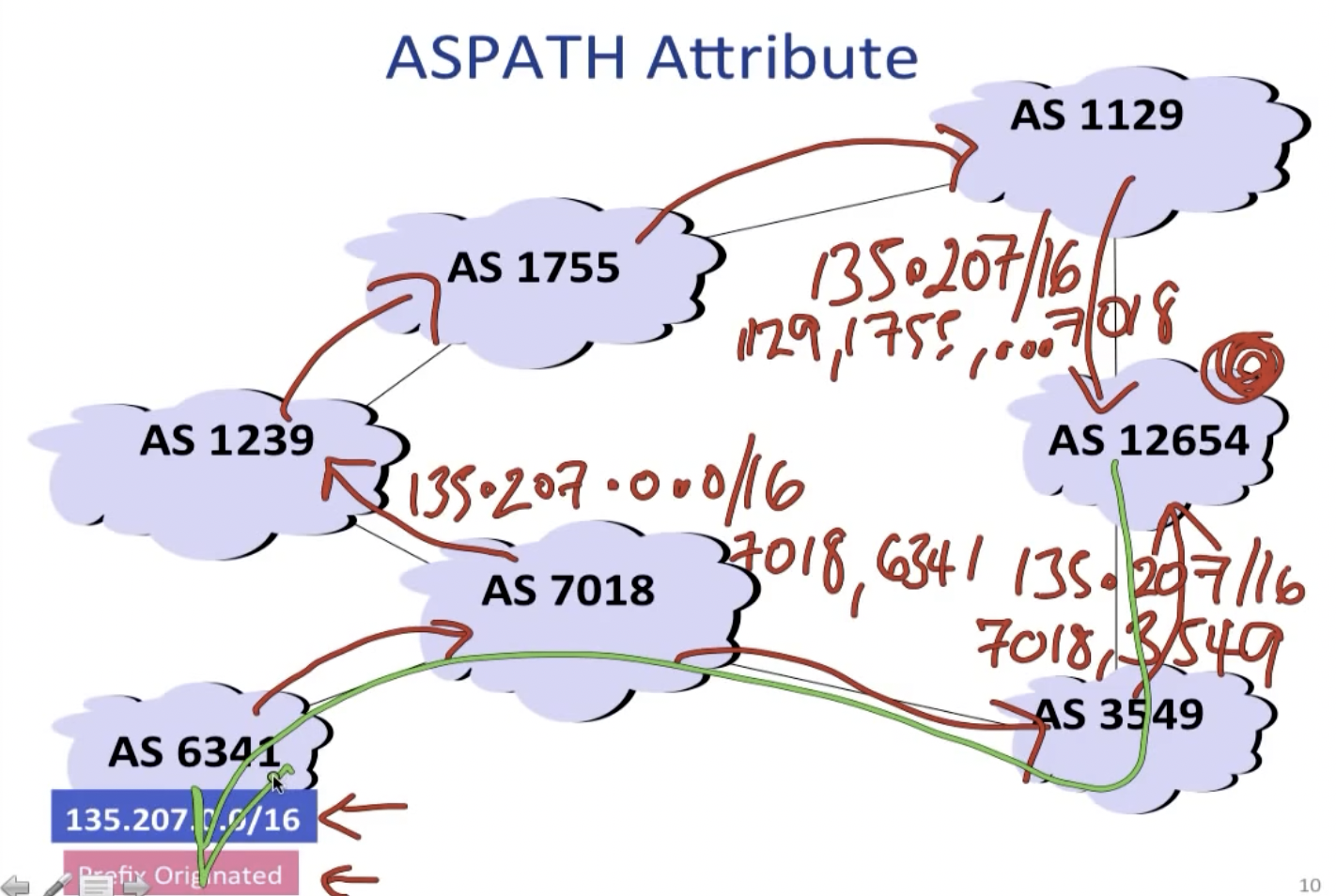
假设AS 12654从AS 6341接收了BGP announcement,该数据包会经由上下两条路径到达12654,之后12654发现下方的路径更短,且没有其他AS携带的local preference信息,所以他知道以后要向AS 6341发送数据包的时候,走下方的线路。
BGP的路径选择依据如下:
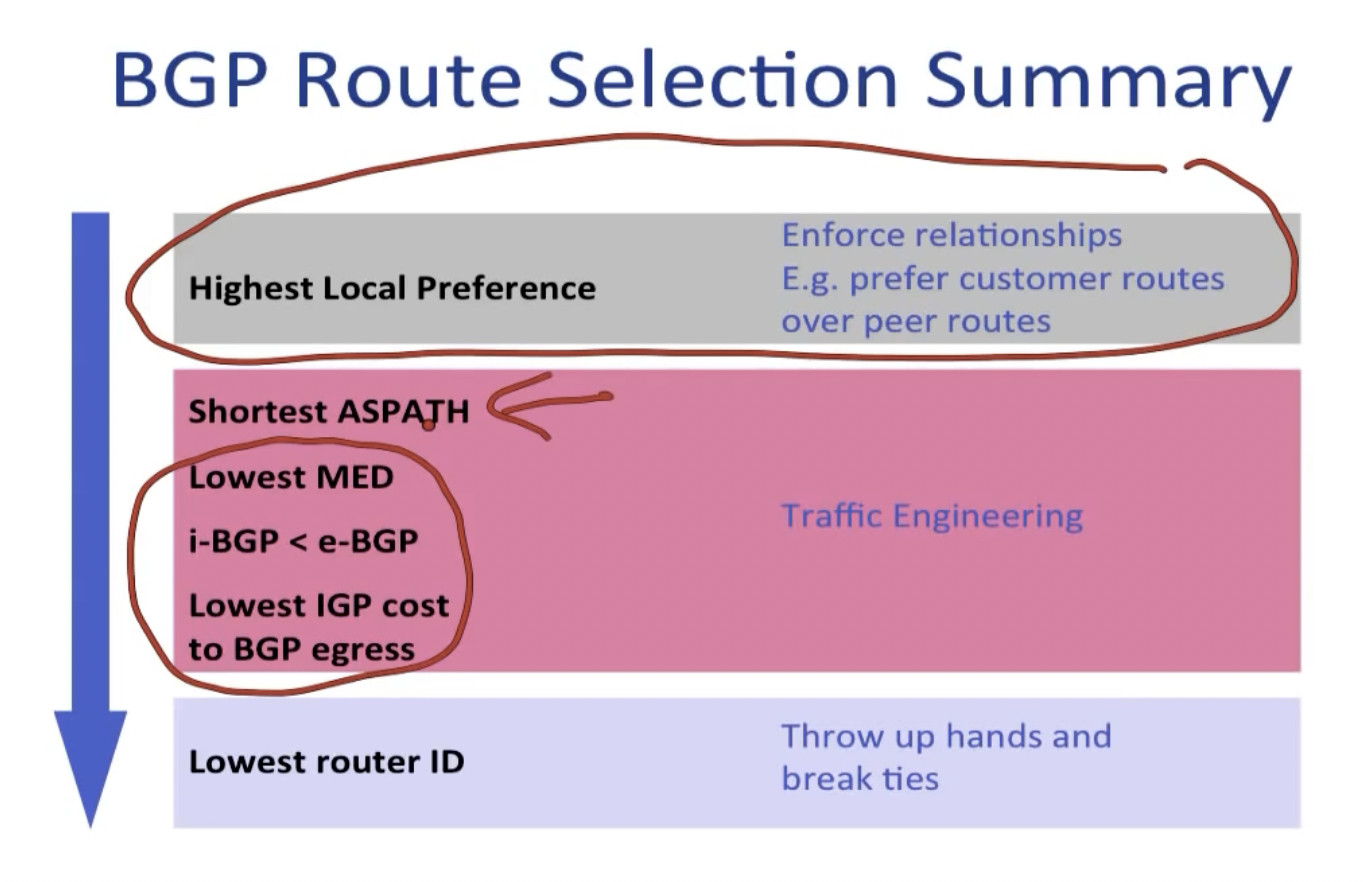
这里有一篇文章给出了比较不错的例子。
最后,再来看一下iBGP的工作方式,在ISP内部传播路由有一定的规则:位于ISP边界的每个路由器为了一致性,要学习所有其他边界路由器看到的路由,不管数据包从其他AS如何进入ISP。
在上一节中我们提到,在multiple exit AS内部的路由表常常十分复杂,因为需要处理到底从哪一个exit给到其他AS的问题,而iBGP中的early exit和hot-potato-routing方法可以缓解该问题,这种工作方式使得数据包进入AS内部时会尝试尽快离开该AS(send to closest exit)。
总之,BGP按照AS粒度来选择路径,OSPF选择每个AS的内部路径。
Multicast Routing
组播,用于满足一个发送方同时向多个接收方发送消息。我们可以利用flooding实现这项技术,但显然spanning tree是更好的方法。
Reverse Path Broadcast (RPB) + Pruning
这种技术也被称为Reverse Path Forwarding (RPF),通过域内路由算法构建的生成树判断。规则如下:判定multicast时接收packet的interface是否是unicast时向source address发送数据包的interface(这一步根据由spanning tree构建的forwarding table entries来判断)。如果是,就继续将packet传播到其他所有的interfaces;否则舍弃。
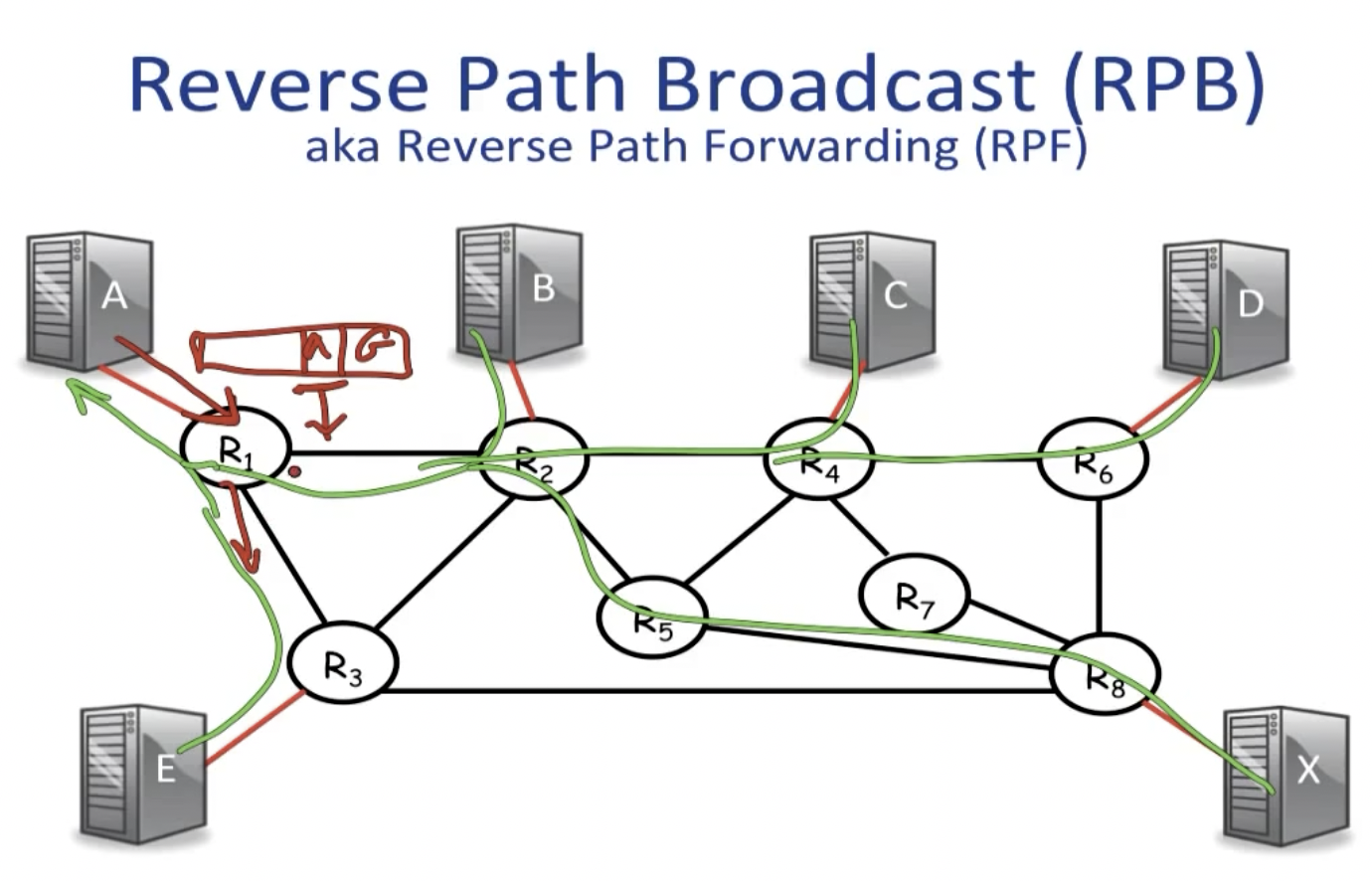
由于我们可能不需要将数据包传递到所有的sources上,那些不需要packets的可以向邻居发送prune message,这会将他们踢出multicast的spanning tree。

这里有一个潜在的问题是,我们是否需要建立多个spanning tree来满足每一个router的multicast需求?
一般的方法是选择一个rendezvous point,以该点为中心建立spanning tree,每一个multicast的数据包都先发送到该router上,再由该router负责转发。
Practice (IGMP+DVMRP+PIM)
IP用D类IP地址来支持一对多的通信,IP地址224.0.0.0/24范围内的地址保留用作本地网络组播,在这种情况下,不需要路由协议的支持。带有一个组播地址的数据包被简单的广播到LAN上,从而达到组播的目的。局域网上的所有主机接收广播数据包,只有属于组成员的主机才对该数据包进行处理。
而在其它情况下,就需要一个路由协议。
首先,因为组播路由器必须知道有哪些主机属于某个组的成员。这里用到了**IGMP(Internet group management protocol)**协议。

接下来,在Internet中,我们可以选择DVMRP或者PIM协议来建立组播生成树:

其中,DVMRP采用了我们之前提到过的RPB+pruning的工作模式,而PIM在稀疏模式下,因为需要发送pruning的节点太多会严重降低工作效率,进而采用了建立汇合点的方式工作。

Spanning Tree Protocol (STP)
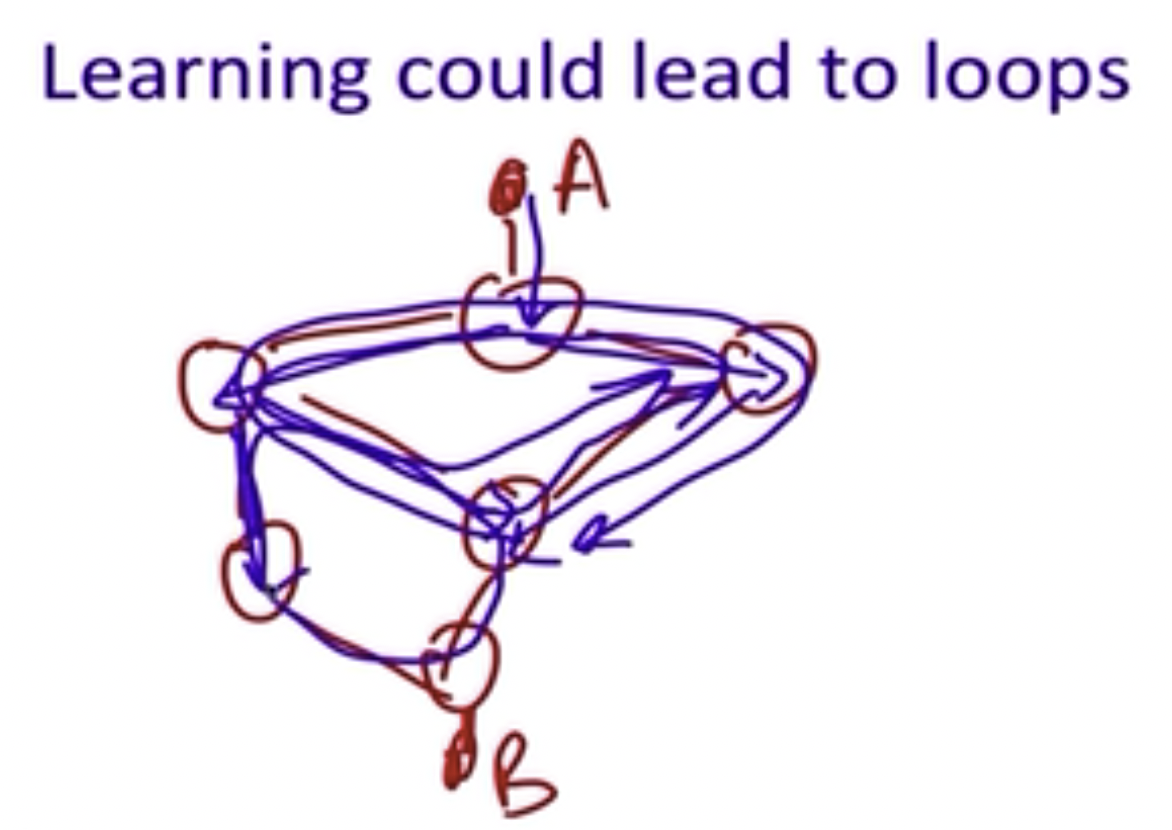
不仅路由器会路由packets,数据链路层的Ethernet也会路由packets。这里需要解决的问题是:我们虽然知道如何获取address,但是如何才能避免路由循环的出现?
为了解决这个问题,Ethernet也构建了一个spanning tree来限定packets forwarding的路径。
首先,Ethernet通过如下方式转发packets,当从port A接收到来自主机B的packet时,交换机就知道以后通往主机B的packet应当向port A转发。

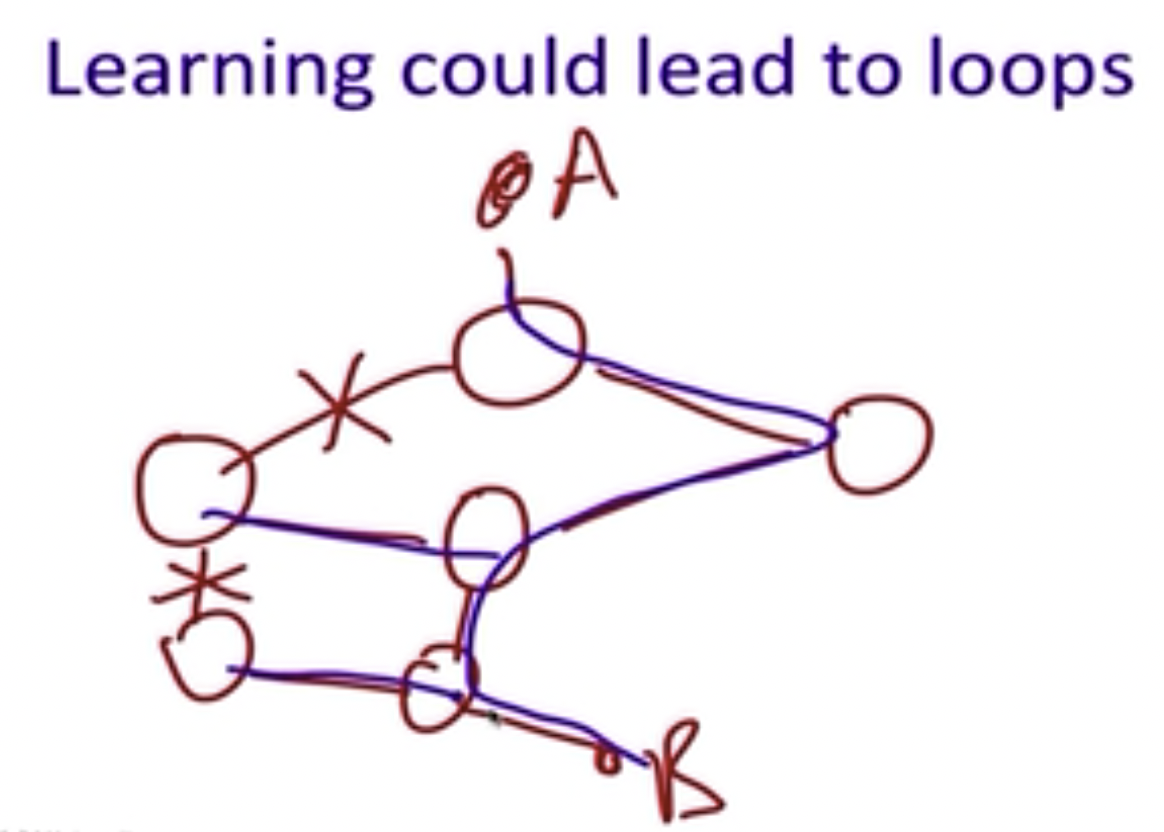
但上图中的第三步的学习过程容易导致路由循环:
为了解决这个问题,我们需要在原图中找到一个没有loop的spanning tree,其需要包含所有的节点:
The distributed protocol decides:
- Which switch is the root of the tree
- Which ports are allowed to forward packets along the tree
比如,我们可以按照如下方式构建spanning tree,即每一次只向距离root最近的节点传播数据包:
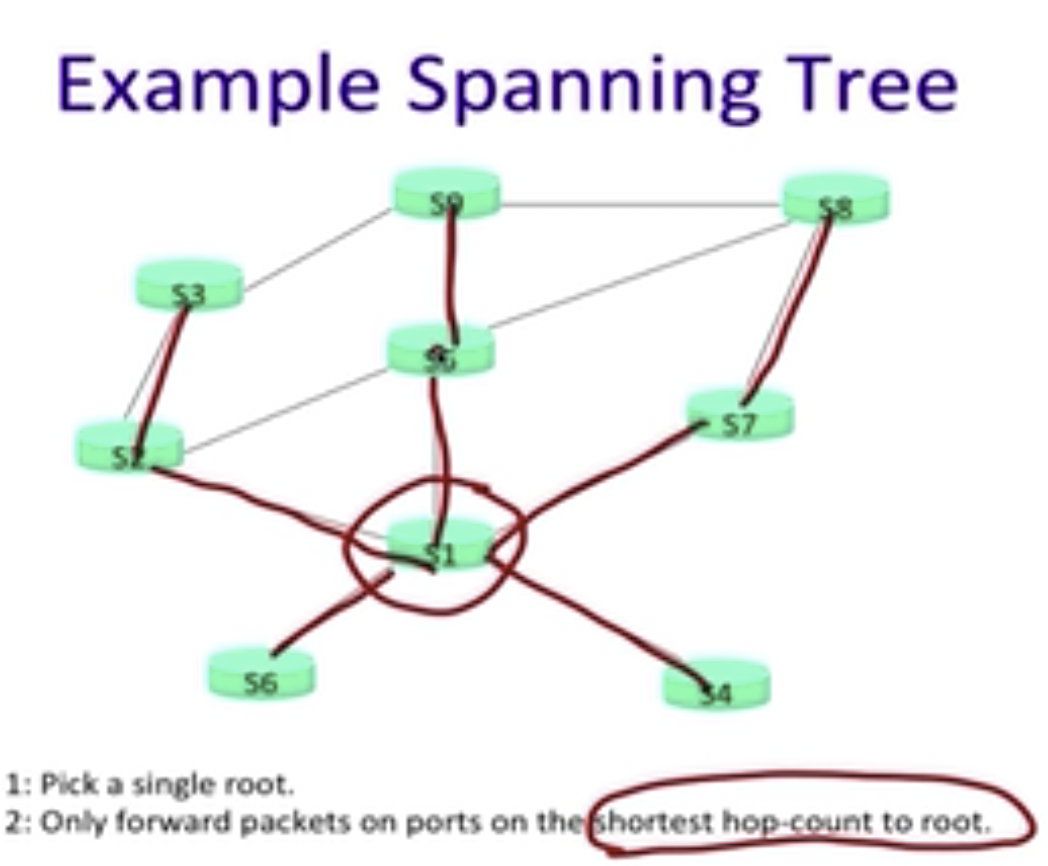
STP的工作流程如下所示:

所有switches周期性的广播BPDU,该消息由以下部分组成:
- ID of sender
- ID of root
- distance from sender to root
一开始,所有的switch都宣称自己是root,并将distance设置为0;之后如果其接收到“更好的”信息,就负责将这条更好的消息继续转发:sender是自己,将root替换为获取的新的root,并将对应的距离+1。
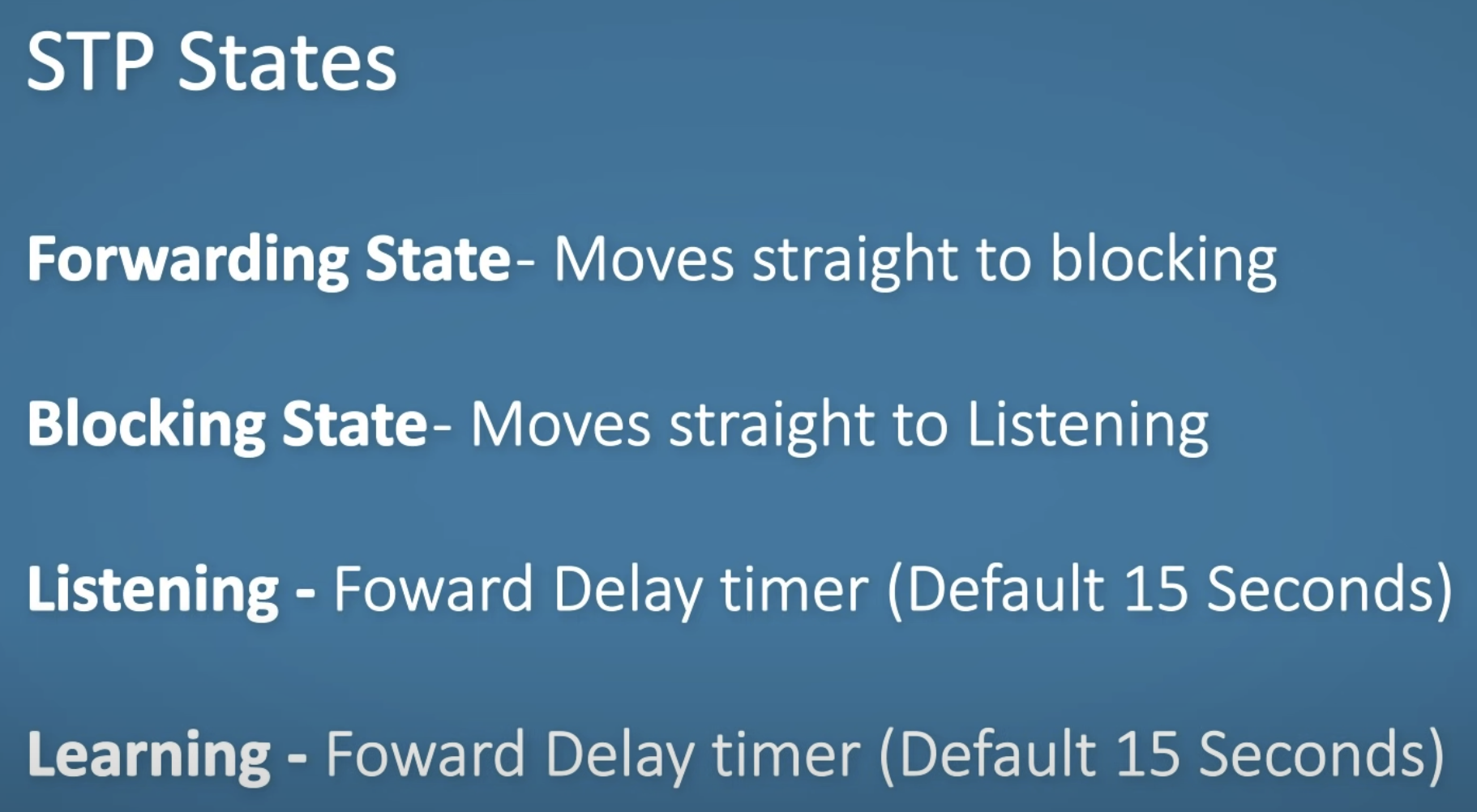
最终,系统会收敛到只有一个root,并且只有该root向外发送配置信息,其余switches全部只retransmit该消息。root bridge会每隔一段时间向其余switches发送消息,告知运行正常,其余switches如果在一段时间内没有等到消息,就会重新进入listening、learning、forwarding的选举阶段(这也是为什么STP收敛的很慢),并重新构建链路。

- Hello: Root bridge create and send hello messages
- MaxAge: the max time interval others can stand for receiving MaxAge (TIMEOUT)
- Forward Delay: timer set for the listening and learning state respectively 在root bridge election之后,BPDUs仍然会继续被发送,确保系统可以应对动态变化,其中会携带如上所示的信息,来keep alive system。以下是port对应的几种状态:


source: https://www.jannet.hk/spanning-tree-protocol-stp-zh-hant/#Listening
root port:距离root bridge最近的port
designated port:不正面对root bridge,但是以尽可能低的成本转发来自neighbor的packet;在root bridge election之后,其负责接收和转发forwarding packets以及BPDUs
其余所有port均被阻塞,注意对于root bridge,不存在被阻塞的端口。
除了root port和designated port之外的port都不会负责forwarding packets,但他们还会继续接收BPDUs,以此应对系统可能出现的动态变化:比如没有接收到root bridge的消息时,或者系统中有新的更低sender ID的交换机加入。
再后来,STP逐渐被RSTP(可以更快的收敛)和SPB替代:
