Consistency & Coherency
A detailed explanation of consistency and coherency in architecture & distributed system
Table of Contents
本文讨论一些我觉得自己会忘记的点,不作为完整的对于Coherency和consistency(memory order)的入门文章,如果想要完整的入门这部分,可以参见我文章最后给出的references。
在开篇,简单的描述一下这两者之间的关系。
- Coherence定义了一个读操作可以获得什么样的值。
- Consistency定义了一个写操作的值何时会被读操作获得。
Coherency
这里我们主要讨论Cache Coherency。中文名为缓存一致性,这是通过MESI协议保证的,在讨论更Consistency模型之前,我们应该对此协议有基本的了解,包括总线嗅探(snooping)机制以及几种状态的对应。
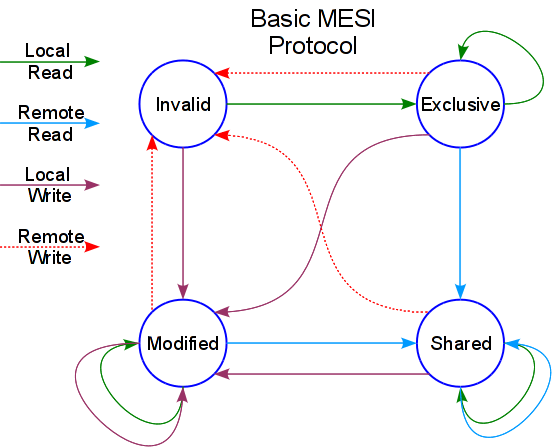
Cache Cohenrence保证了对多核CPU中的一个Cache中的一个地址的读取一定会返回那个地址被写入的最新值。
我们可以讨论一下因为缓存一致性而带来的False Sharing问题。
- False sharing occurs when we unintentionally share data
- Symptom of data layout and architecture
- Unrelated data can get mapped to the same cache line
- Data gets transferred at the cache-line granularity

如何避免写出False Sharing的代码?使用C++11及之后的版本,可以这么写 [5]:
struct alignas(64) AlignType {
AlignType() {val = 0; }
std::atomic<int> val;
}
需要注意的是,如果对数组使用
alignas,则对齐的是数组的首地址,而不是每个数组元素;并且alignas关键字只能做静态内存的对齐,如果需要堆上的内存对齐操作,则可以使用C++17支持的operator new/delete的参数align_val_t重载版本.
即利用padding的思路,使得不同变量处于不同cache line上。
我们可以使用perf record或者valgrind来检测False Sharing情况。
Consistency
对于分布式中的一致性问题,我们暂且不表,先来讨论体系结构中的一致性问题,更准确地说是在多线程环境下编程时的consistency问题。
从Atomic开始
std::Atomic<T>其实就是对Cache line加锁:
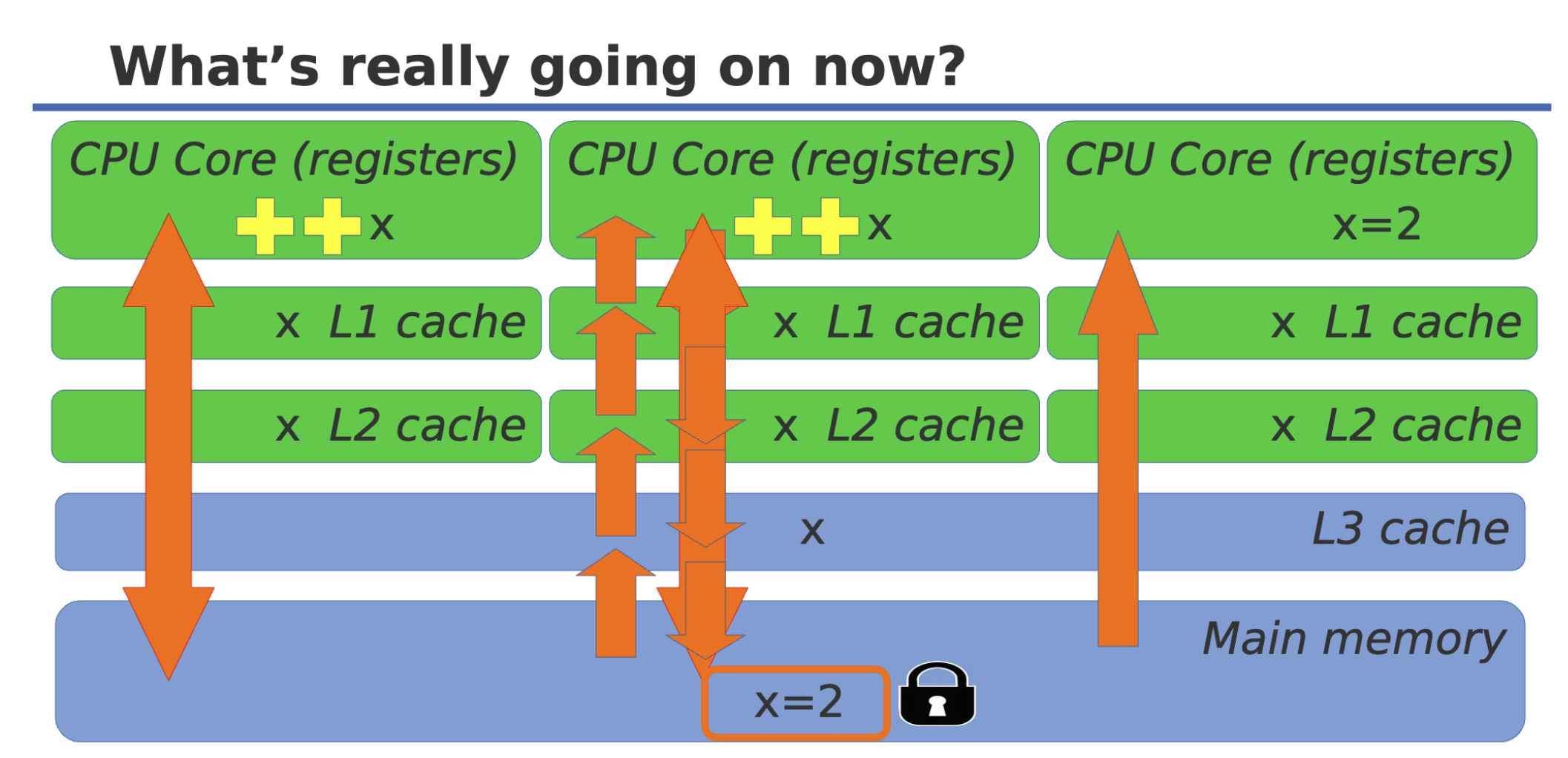
From C++ Atomics, From Basic to Advanced , CppCon 2017, by Fedor Pikes [2]
在这个talk里,提到了很有意思的一个点,这里也记录一下:
当我们对如下类型使用
Atomic<T>时,哪些才是lock-free的?如图所示,仅有能够使得单条
mov指令完成的操作,才可以实现lock-free,也就是说atomic不是在所有情况下都等同于lock-free,比如这里的第三个例子,就因为内存对齐的原因,达到了16byte的大小,故而可以直接一条mov指令解决;但是第四个例子虽然只有12byte,一条mov指令是没有办法搬运12个字节的,这意味着即使Atomic<T>会对Cache line加锁,也没有办法确保单个线程对该结构体的原子操作,就会产生race condition。同时,仅有满足内存对齐条件才可以成为lock-free,这也是为什么is_lock_free函数是run-timefunction,因为有些地址只能在运行时(比如由linker)或者动态分配在堆上 的内存只有在加载时才能知道具体情况 [1]。如果想使用编译器函数,在C++17中提供了is_always_lock_free。

指令优化

From Herb Sutter: Atomic Weapons
我们通常讨论的指令优化有两种:
- 编译器优化
编译器优化包括指令重排序(reorder)以及remove等,对于重排序,一个引用的例子是:
//reordering 重排示例代码
int A = 0, B = 0;
void foo()
{
A = B + 1; //(1)
B = 1; //(2)
}
movl B(%rip), %eax
movl $1, B(%rip) // B = 1
addl $1, %eax // A = B + 1
movl %eax, A(%rip)
From Zhihu: C++中的内存模型
该代码的调优借助寄存器的帮助,减少了Cache miss的可能性。
而removal则包括编译器优化掉一些未使用的变量等。
- CPU优化
这部分主要包括流水线为了减少data hazards进行的指令重排,对分支预测语句的提前执行(control hazards),对读取内存的耗时操作进行的预读(在多核下可能读取另一个核心写入的陈旧值)等。
以上的优化操作在多线程执行时均有可能导致inconsistency,我们可以通过使用内存栅栏来解决 [4]:
// 编译器barrier: 阻止编译器重排
asm volatile ("" ::: "memory")
// CPU & 编译器 barrier
asm volatile ("mfence" ::: "memory")
// 等价于
__sync_synchronize()
当然,除了以上原因导致多核多线程编程出现问题外,还有一些硬件设计上带来的问题,这个我们接下来会讨论。
现在我们需要了解的是,对于乱序执行,其基本规则是不能破坏单个指令流,也即代码必须像每条指令都按照原本的程序顺序执行一样运行 [6],但是对于多核的情况下(我们就有了多个指令流,这里不考虑SMT, e.g. Hyper-Threading),所以乱序执行的正确性保证并不适用。
对于单核多线程的情况,CPU不会意识到这是两个线程,线程本质上只是一种基于上下文切换的软件构造而已,CPU还是按顺序查看某些指令.
个人观点:我们也可以从另一角度理解,因为在单核情况下,事实上不涉及任何Cache之间的信息交流,我们也就不会因为延迟而产生关于store buffer,store forwarding等带来的问题.
正是基于如上所述的原因,我们也可以说在单核的情况下,我们确保了sequential consistency,这引出了我们后续要讨论的memory order.
memory barrier
显然我们需要一些方法来保证多核多线程的某种一致性,于是内存栅栏应运而生。
在经典引文[8]中详细介绍了读屏障(smp_rmb),写屏障(smp_wmb)以及读写屏障(smp_mb)。我这里简单的总结如下:
首先,我们有一个原始的CPU,他不做任何优化(不包括store buffer,store forwarding以及invalid queue)。一个显而易见的问题是,当我们尝试第一次向某一个Cache line写入的时候,会发生如下的情况:
 | 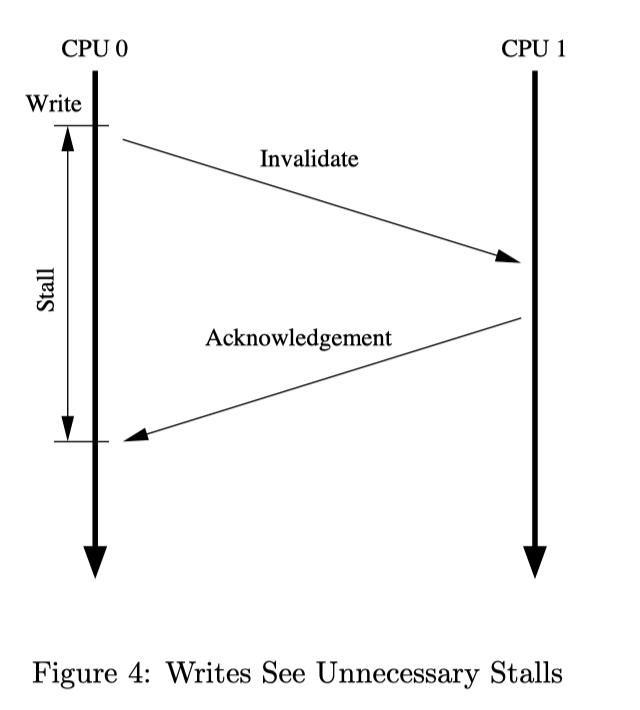 |
CPU0向CPU1发出invalidate,CPU1回复invalidate acknowledge,在此期间CPU0必须stall,而这段stall显然是不必要的,因为不管CPU1传回来什么数据,CPU0都会把它覆写。于是我们考虑添加一个store buffer,如果当前Cache中没有这个数据,CPU0就可以先将写入的值存在store buffer中,当CPU1的信息返回后,再将store buffer中的值写入对应的cache line(不一定马上写入)。

经过论文的探讨,我们发现这种方法,即使是在单线程的情况下,因为store buffer和cache存放的数据版本可能不一致,而每次加载我们只会从cache中取出数据,就会读到旧的数据,于是进一步为硬件增加了store forwarding,即每次加载的时候可以从cache以及store buffer中寻找数据,这样就会找到最新的数据:

但这种方法仍然是存在问题的,根本原因在于CPU不清楚变量之间是如何关联的,设想这样一种情况:对于CPU0而言,其cache中有b,但是没有a,那么如果我们分别对a和b进行写入,则a的写入会进入store buffer,而b的写入会直接更新到Cache里;此时CPU1来读取b,拿到最新值之后发现满足while条件,自己可以跳转到下一条指令了,但此时CPU0对a的更新发出的invalidate可能还没到,于是断言失败。而正确的做法是,我们不应该允许a的新值对CPU1可见之前,让b的新值对CPU1可见,也即CPU0对a的写入必须在其对b的写入之前被其他CPU观察到。
这就需要使用写屏障(smp_wmb),确保写屏障前后的写操作不能调换顺序,本质上是通过在继续处理后续写入操作之前情况store buffer:
cause the CPU to flush its store buffer before applying subsequent stores to their cache lines. The CPU could either simply stall until the store buffer was empty before proceeding, or it could use the store buffer to hold subsequent stores until all of the prior entries in the store buffer had been applied.
在论文给出的例子中使用了第二种方法,其在看到写屏障指令后,给store buffer中现有的entry做上标记,如果后续的写操作发现store buffer中存在marked entry,就必须把自己放到store buffer里,等待所有marked entry对应的操作完成(被刷入到cache中)后才可写入Cache中。
至此,X86架构上的优化就已经完成了,而在一些其他的架构上,设计者还考虑了别的优化问题:
由于store buffer的大小十分有限,很多连续操作,尤其是在写屏障出现时,就会很快的将store buffer填满,这时我们就不得不等待C PU将store buffer中的东西全部刷到Cache里,意味着需要等待invalidations操作信息传输完成,异步操作退化成了同步,显然是不好的。而这种退化可以通过减少invalidate信息的传输延迟完成:我们不必等到Cache line真的被invalidate之后才返回,而是可以将信息放在一个invalid queue中,之后cpu在处理任何cache line的MSEI状态前,都必须先看invalid queue中是否有该cache line的Invalid消息没有处理:
One reason that invalidate acknowledge messages can take so long is that they must ensure that the corresponding cache line is actually invalidated, and this invalidation can be delayed if the cache is busy, for example, if the CPU is intensively loading and storing data, all of which resides in the cache. In addition, if a large number of invalidate messages arrive in a short time period, a given CPU might fall behind in processing them, thus possibly stalling all the other CPUs.
However, the CPU need not actually invalidate the cache line before sending the acknowledgement. It could instead queue the invalidate message with the understanding that the message will be processed before the CPU sends any further messages regarding that cache line.
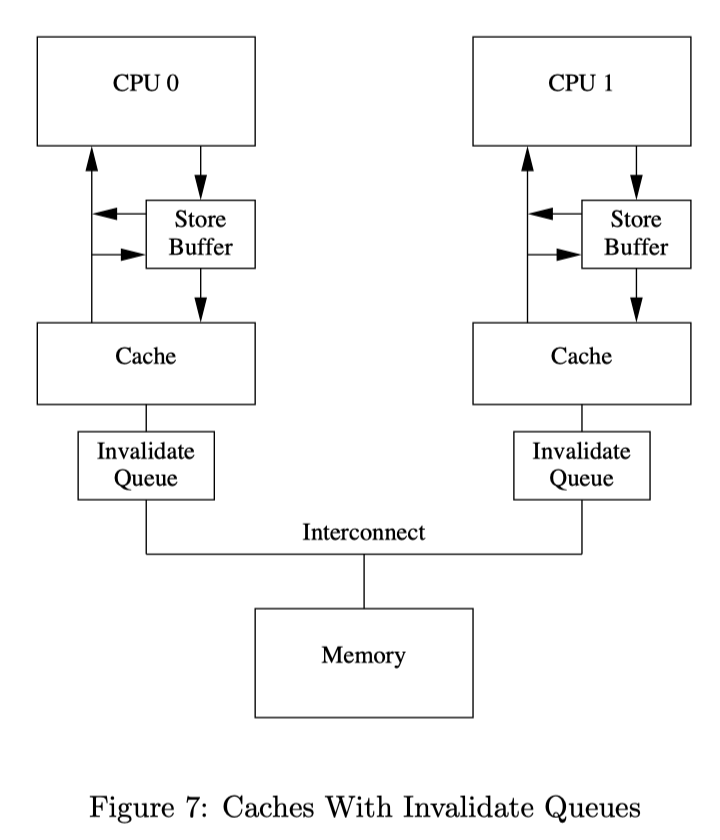
invalid queue的添加又增添了新的麻烦。比如对于语句assert(a == 1),可能当前CPU的Cache中就有一份a,但是由于不涉及任何MESI状态的变化,他会直接读取Cache中的值,然后断言错误,没有发现此时在invalid queue中还有一个invalid message没有处理。
此时我们就需要读屏障(smp_rmb),确保我们在看到对a的加载指令后,会先到invalid queue中看到一个marked entry a,应用其状态。
至此,几个优化和对应的屏障指令就结束了。所谓的全屏障(smp_mb)就是读写屏障的结合。简略地说,所谓的读屏障就是只标记invalid queue,写屏障只标记store buffer,而读写屏障两者都标记。读屏障的效果是确保对应的CPU上所有在读屏障之前的load操作都在后续的load操作之前完成;写屏障对称。读写屏障则确保了前后读+写操作均不能越过屏障。
所有这些硬件上的优化,无论是store buffer还是store forwarding,其实就相当于抽象层面的CPU指令重排序(CPU0上的操作在CPU1看起来变成了乱序的),这也是为什么先前我提到,有一些硬件上的设计也会导致指令重排序的原因。
memory order
在搞明白为什么多核多线程编程会出现内存一致性问题之后,我们可以开始讨论C++中的内存序了。不同的内存序对应着不同的一致性要求,从内部原理上,即是使用了不同层次的内存屏障来约束store buffer的行为实现的。
C++中的memory order是一个相当庞大的主题,本文引文中的[7]给出了一个相对容易理解的完整表述,所以这里仅做简述。
- Sequencial Consistency (SC)
这是最严格的一致性模型,要求单线程内部完全按照代码给出的顺序执行;并且多线程之间看到的代码执行顺序完全相同。比较有意思的是因为SC也是由Lamport提出的,所以在他的定义上,和分布式系统中的happens- before十分类似。由于这种内存一致性要求过于严格,所以其他一些更加宽松的模型被提出。在X86中使用的就是TSO (Total Store Order)模型,这种模型确保了以下三种执行顺序:
- Load-Load
- Store-Store
- Load-Store
唯独Store-Load可能被重排。
- Happens-before
Let A and B represent operations performed by a multithreaded process. If A happens-before B, then the memory effects of A effectively become visible to the thread performing B before B is performed.
No matter which programming language you use, they all have one thing in common: If operations A and B are performed by the same thread, and A’s statement comes before B’s statement in program order, then A happens-before B. [12]
按代码顺序,若语句A在语句B的前面,则语句A Happens Before 语句B。对同一个线程来说,前面的代码Happens Before后面的代码。线程之间的语句也有Happens Before的关系,这需要借助我们后面讲的synchronizes-with来确定。
- Synchronizes-With Relation
the read-acquire to read the value written by the write-release. If that happens, the synchronized-with relationship is complete, and we’ve achieved the coveted happens-before relationship between threads. Some people like to call this a synchronize-with or happens-before “edge”. [13]
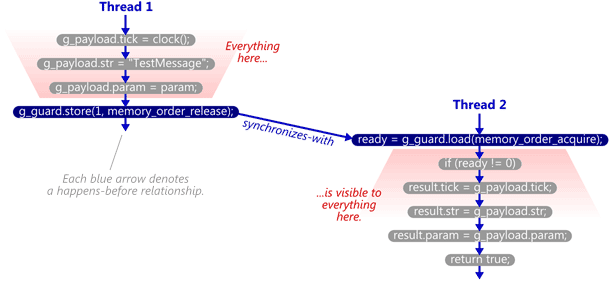
用于线程间的同步,通常借助原子变量的操作来实现。线程1对原子变量x进行写操作,若线程2对原子变量x进行读操作且读到了线程1的写结果,则线程1的写操作Synchronizes-with线程2的读操作。
- C++默认的内存模型(
memory_order_seq_cst)
C++默认的内存模型为SC-DRF(Sequential Consistency for data race free),这种模型并不完全等价于SC,它比SC稍弱,因为在屏障前后的指令在不影响执行结果的前提下可以进行指令重排,而SC要求完全按照指令书写顺序执行。
- Acquire-Release语义
理解Acquire-Release语义最好的办法就是想想我们是如何利用mutex书写critical section的,对于critical section的起始边界,进行acquire操作,意味着所有critical section内部的指令不能移到他的上边去;结束边界我们会做release操作,意味着所有critical section的指令不能移到他的下边去。又因为在critical section的一开始,我们想要把外界的状态加载到临界区中,所以acquire语义用在load操作上;相对应地,在critical section末尾我们想把写的内容让外界看到,即写到外界去,所以需要release语义进行store操作(是不是对应的英文单词也很匹配?)而memory_order_acq_rel则相当于两种操作的融合,上下的读写操作均不能越过它。
同时根据前边的synchronizes-with语义,acquire和release操作的成对使用如果一旦形成synchronizes-with就保证两个程序段的happens- before关系。
- seq_cst和acq_rel的区别
Seq_cst保证了所有CPU能够看到完全一致的内存顺序(global memory order),但是在acq_rel中我们一般只能看到synchronizes-with的关系,对于完全内存顺序不能做任何假设,在[7]中给了一个很经典的例子,也是出现在cpp reference上的,就只有使用seq_cst时才能断言成功。
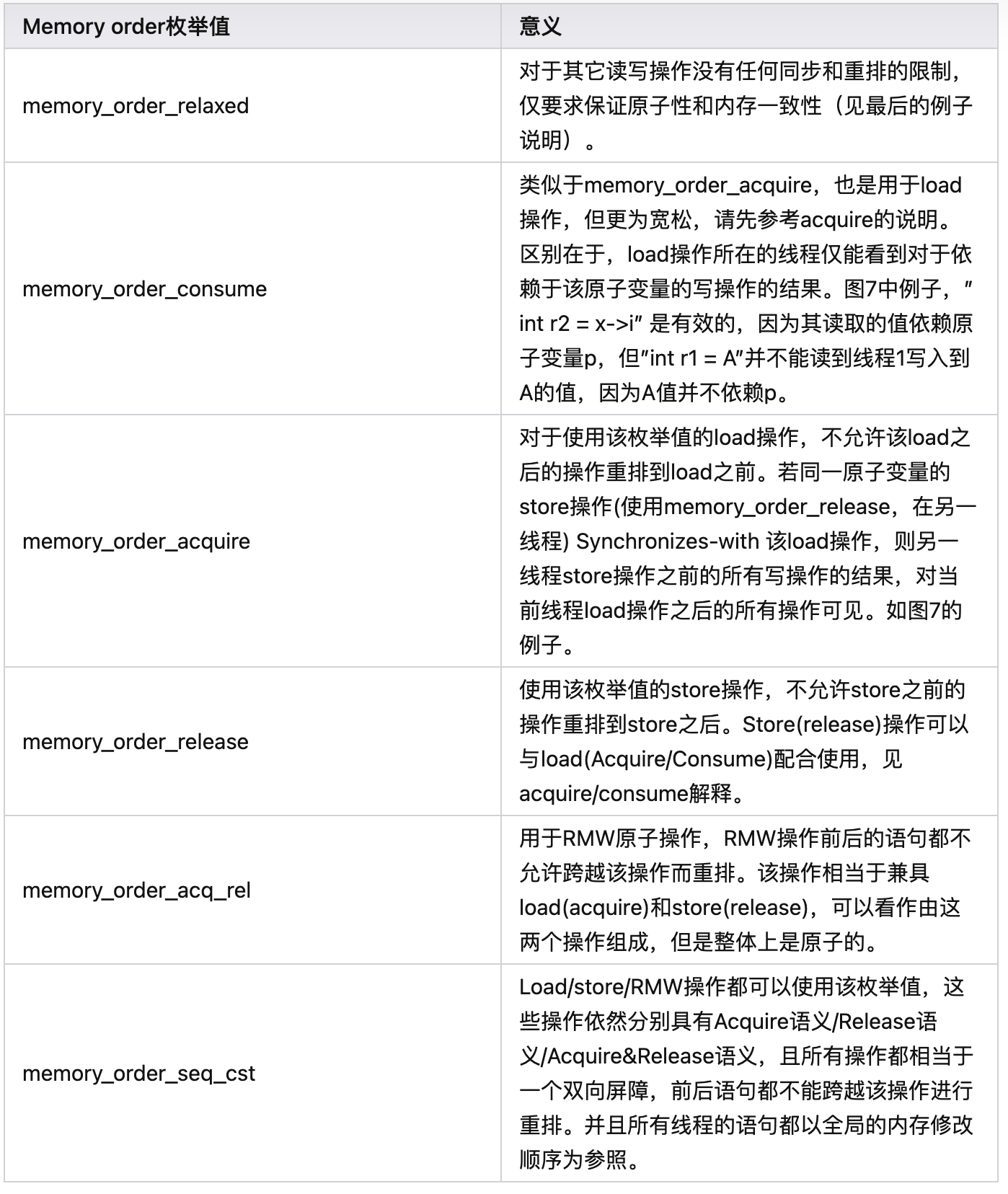
- relexed内存序有什么用
一般单纯用作计数器,我们不能对使用memory_order_relaxed的原子变量做任何依赖于其的关系假设。该内存序只能确保原子性和内存一致性,即对于同一线程中对于该原子变量的写入一定会被后续的读取读到。
- X86中的seq_cst和acq_rel都是如何实现的
如果我们查看汇编代码,会发现seq_cst的内存一致性由xchg实现,其实就相当于mov+mfence;这意味着acq_rel仅需要mov操作就可以达到(在X86上),因为X86本身就是一个store buffer+store forwarding+SC的系统,其事实上确保的TSO模型,保证了满足acq_rel语义的要求(仅有可能发生store-load重排序,但这并不影响acq-rel语义)。但是在别的平台上,如果我们需要手动指定(设置屏障),可以考虑std::atomic_thread_fence(),其提供了一系列基于不同memory order的屏障选择,这里不再展开。
From [7].
Volatile关键字
很多文章都会把volatile关键字和多线程语境下的一致性放在一起讨论,其实关键就是一点:
他告诉编译器不要做任何缓存优化!每次写操作都要写到内存,读取都到内存读取,这避免了如通用寄存器对内存读写的优化等,一个更详细的讨论见[11].
References
[1] Why is std::atomic::is_lock_free() not static as well as constexpr?
[2] CppCon 2017: Fedor Pikus “C++ atomics, from basic to advanced. What do they really do?”
[3] 当我们在谈论cpu指令乱序执行的时候,究竟在谈论什么?
[4] difference in mfence and sam volatile ("":::“memory”)
[6] Why memory reordering is not a problem on single core/processor machines?
[7] 现代C++的内存模型
[8] McKenney, Paul E. “Memory barriers: a hardware view for software hackers.” Linux Technology Center, IBM Beaverton (2010).
[9] 内存屏障的来历
[10] 为什么程序员需要关心顺序一致性(Sequential Consistency)而不是Cache一致性(Cache Coherence?)
[11] 剖析为什么在多核多线程程序中要慎用volatile关键字?
[12] The Happens-Before Relation