Lecture 1
Interpretation & Translation
根据维基百科上的定义:
A translator or programming language processor is a generic term that can refer to anything that converts code from one computer language into another.[1][2] A program written in high-level language is called source program. These include translations between high-level and human-readable computer languages such as C++ and Java, intermediate-level languages such as Java bytecode, low-level languages such as the assembly language and machine code, and between similar levels of language on different computing platforms, as well as from any of the above to another.
这是一种较为广义的Translator定义:就是说翻译器是将一种语言转化为另一种语言的处理器。在这种定义下,翻译器包含三个类型:
- Compiler:
A compiler is a translator used to convert high-level programming language to low-level programming language. It converts the whole program in one session and reports errors detected after the conversion. The compiler takes time to do its work as it translates high-level code to lower-level code all at once and then saves it to memory.
- Interpreter:
The interpreter is similar to a compiler, as it is a translator used to convert high-level programming language to low-level programming language. The difference is that it converts the program one line of code at a time and reports errors when detected, while also doing the conversion. An interpreter is faster than a compiler as it immediately executes the code upon reading the code. It is often used as a debugging tool for software development as it can execute a single line of code at a time. An interpreter is also more portable than a compiler as it is processor-independent, you can work between different hardware architectures.
- Assembler:
An assembler is a translator used to translate assembly language into machine language. It has the same function as a compiler for the assembly language but works like an interpreter.
CS 61C课上给出的Translator的定义更类似于对Compiler与Assembler这类的统称。
常见的解释器的例子有:
- Python Interpreter
- Simulator(e.g. Venus Simulator)
- Emulator
关于第二种与第三种,实际上他们是在软件中interpret machine code,仿真器(Simulator)使用软件解释机器语言,在软件中模拟硬件行为。
而模拟器(Emulator)则类似于苹果公司在改变指令集架构(ISA)后对旧软件的处理方法–这也是backward-compatible策略的体现,它允许我们让一个系统(host)像另一个系统(guest)一样运行,这其实也是要先通过在软件层面解释旧的指令,因为我们无法在硬件上直接运行旧程序:
Could require all programs to be re-translated from high level language. Instead, let executables contain old and/or new machine code, interpret old code in software if necessary (emulation)
模拟器的另一些例子比如我们使用的DOSBox或者街机游戏模拟器等等。
Basic Compiling Process
以下内容来自于CS 61C:
C/C++是一种编译型语言(
Compiler),而非解释型语言(如Python):“C compilers map C programs directly into architecture-specific machine code (string of 1s and 0s”.
而也正是基于编译型语言的原因,在编译阶段可以做许多优化:比如修改文件后编译器会指定(
Makefiles)只编译更改后的文件,而不是做修改后要把项目里所有文件都编译一遍。这是编译型语言的一大优点之一。但同时,编译型语言意味着编译生成的文件是
architecture-specific的:“Executable must be rebuilt on each new system”. 另一方面,由于我们每次更改文件后都需要经过编译->运行的过程,这可能会拖慢我们的速度,这一点可使用parallel compile的方法抑制:make -j.
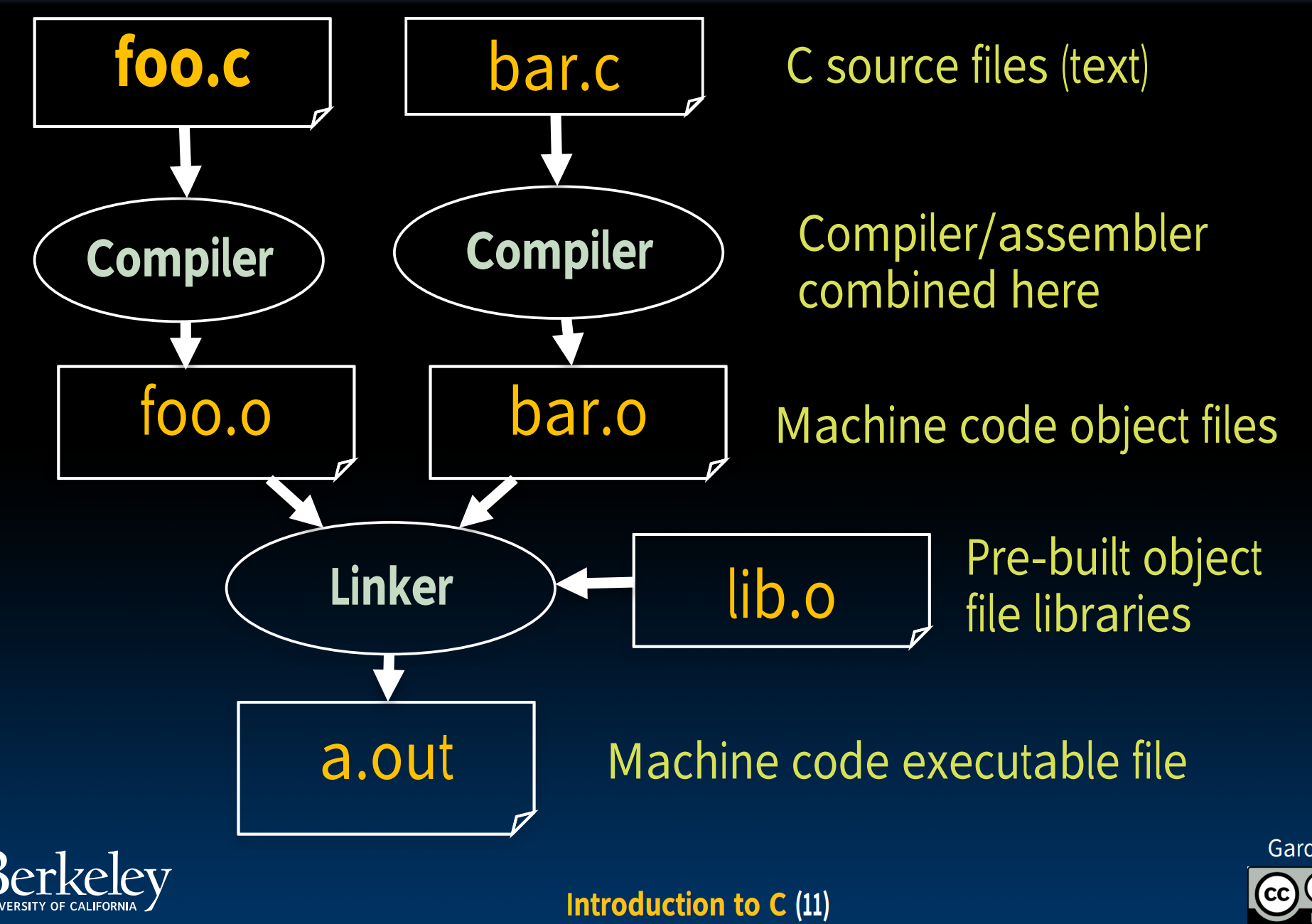
我们有许多编译器可以选择,比如clang, g++等等,如果我们想要编译的是C文件,那么可以使用gcc。编译过程包括:
- 首先预处理,转换为
.i文件,这一步需要展开所有的宏定义(做简单的文本替换)、处理#id/#endif命令、预编译#include命令(insert xxx.h into output directly)、删除注释(replace with a single space)等等,我们可以使用-save-temps来检查预编译文件。 - 之后把文件内容进行词法分析、语法分析,转化为汇编语言,即
.s文件; - 第三步为了让机器读取代码,还需要转化为机器语言,即二进制代码(也是所说的库)-
.o文件; - 最后链接目标代码,生成可执行文件.
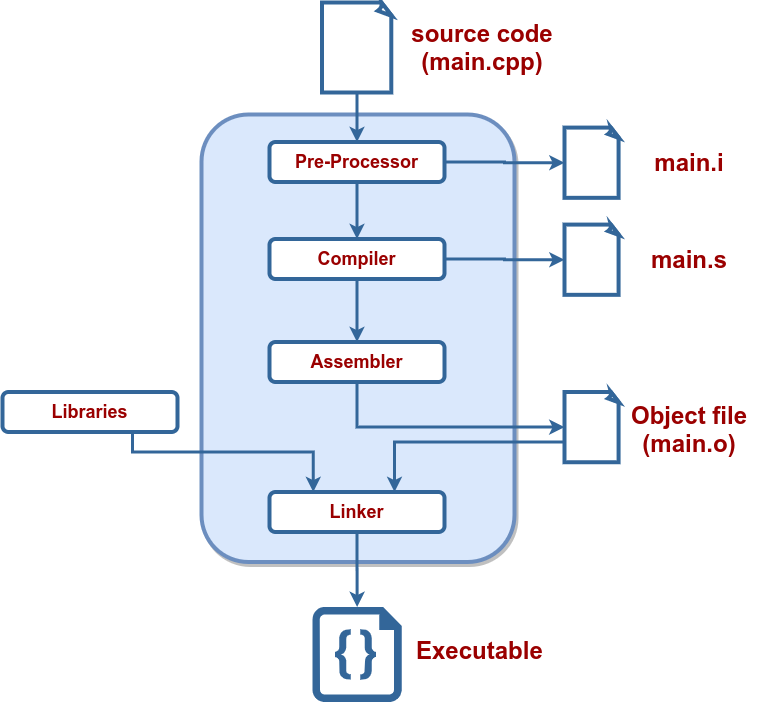
clang++ -E main.cppclang++ -S main.iclang++ -c main.sclang++ main.o -o main

优化主要包含进行跳转和延迟退栈两种优化,
O~选项将使编译速度减慢,但是通常产生的代码执行速度会更快
-Wall表示打印出警告信息,如果要关闭所有警告信息,使用-w
Concrete Compiling Process (CS 61C)
本章节记录了CS 61C课程中的编译流程部分。
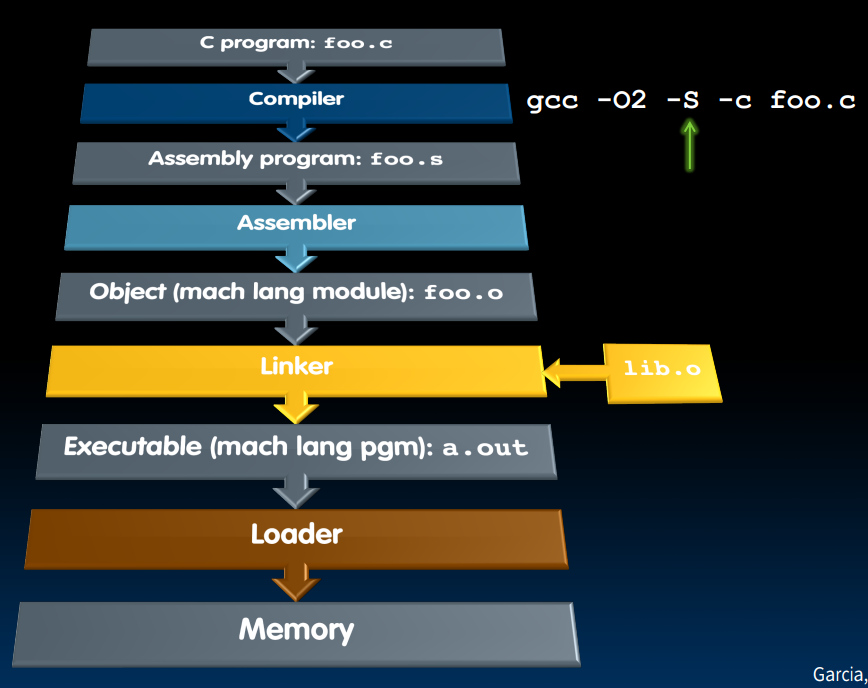
Compiler
Compiler的输入是一种高级语言,将其翻译为汇编语言,需要注意的是,在转换过程中,会产生Pseudo-instructions.
一般来说,编译器的处理包括如下几步:

Assembler
Assembler以汇编语言为输入,最终形成机器码(其中包含了information tables).
- 首先,
Assembler要阅读Directives:

需要注意的是,这些Directive并不会产生对应的机器码,它们只是相当于通知Assembler该如何做接下来发生的事情。
- 其次,
Assembler会替换先前在Compiler处理时产生的Pseudo-instruction.

- 现在,
Assembler可以尝试将汇编代码转化为机器码了:
- Simple Case

- Branches & Jumps?
对于分支和跳转,我们需要思考,他们能否直接生成完整的机器码?
首先,所有的PC-Relative寻址的指令都可以在这一步骤中生成完整的对应机器码。但是这里有一个Forward Reference的问题,就是跳转的地址位于我们当前位置的前方,也即代码还没有走到的位置,所以我们需要对汇编代码增加一次遍历:

接下来,我们要面对jal,jalr这些指令,以及lui,auipc等。

当jal指令想要跳转到其他文件中的位置时,我们无法给出完全对应的机器码,因为此时我们还没有进行link,不知道其余文件中的情况。
同时,我们也无法处理使用absolute address的指令,因为我们不知道这部分指令将被安排在内存中的哪些位置。
为了记录这些当前无法处理的部分,我们使用两个表:
| Symbol Table | Relocation Table |
|---|---|
| 存储了当前文件中可能被其他文件使用的东西,包括:Label: function calling; Data: .data section + variables which may be accessed across files | 存储了当前文件中需要提供地址的东西,包括:Any absolute label jumped to jal, jalr (e.g. External, Internal); Any piece of data in static section (此时我们也无法确定他们的地址) |
借由这两个表,我们可以在之后的linker步骤中根据他们的对应关系,补全真正对应的机器码表示。
Label Address sum 0x00061c00
- 经过
Assembler最终的表示:
按顺序:

一种标准的表示方法(格式)是ELF,我们可以自己在Ubuntu下写一个C文件试一下,如果我们利用VS Code中的hexdump插件查看生成的机器码,就是按照这种格式制定的。
需要注意的是,这一步产生的机器码常被称为
object code,在经过linking的步骤之后,变成machine code.
Linker
在拥有了许多个二进制.o文件后,我们想要把他们链接起来形成.out文件(executable)。而也正是这一步骤,允许我们在修改某个文件之后,不需要把所有的文件从头编译一遍。
根据在Assembler阶段我们构造的symbol table与relocation table,链接器将文件链接起来:
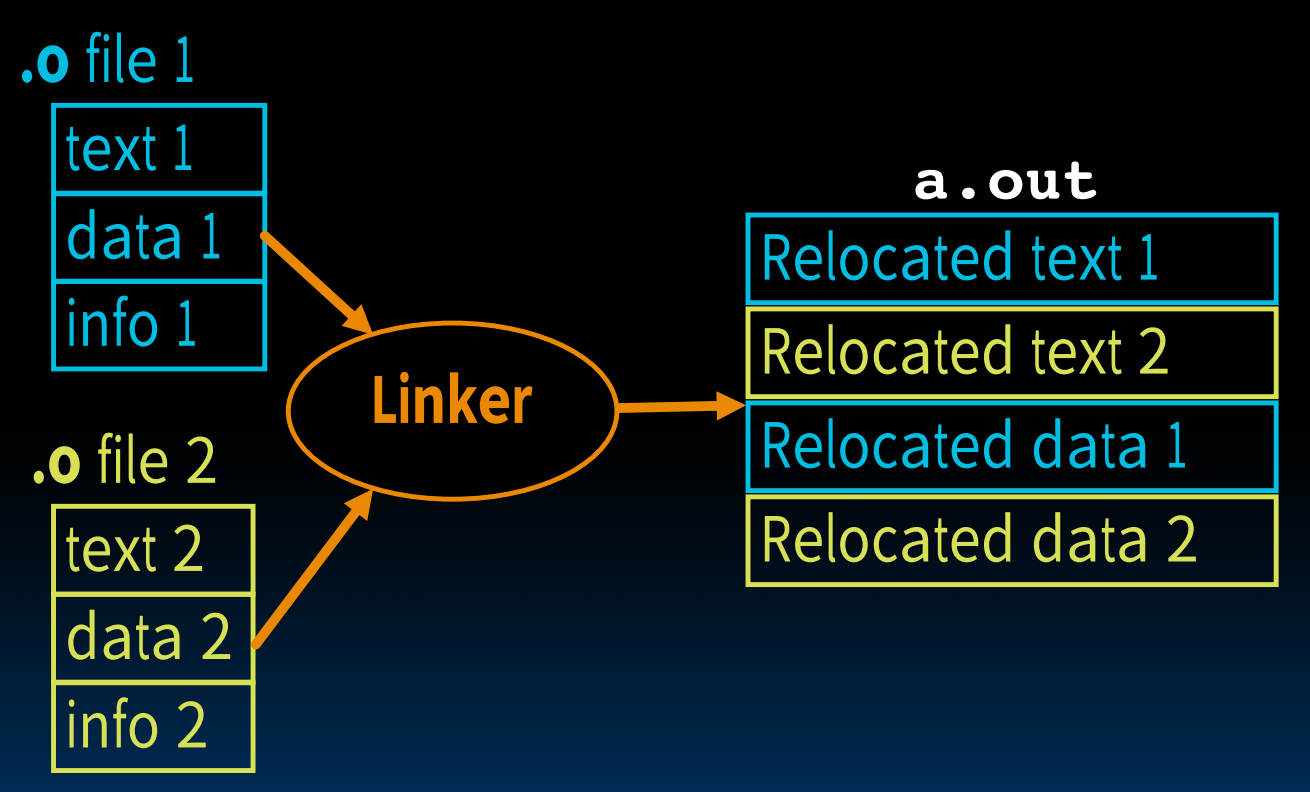
- Take text segment from each .o file and put them together
- Take data segment from each .o file, put them together, and concatenate this onto end of text segments
- Resolve references:
- Go through Relocation Table; handle each entry (fill in all absolute addresses)
Addresses
共存在四种类型的地址:

那么哪些种类的地址需要在这一步被处理呢?

jal指令被放在这里较为容易理解,虽然这种方法使用的是PC-Relative的寻址方法,但是只有我们将几个文件+所有的数据合并到一起,并安放到内存中时我们才知道所需要的offset是多少。而对于static area的load & store操作,我们需要注意的是,此时并不是我们先要给出汇编文件直接进行编译,而是我们提供了高级语言的源文件,机器负责将其翻译为机器码,那么如此一来,我们在源文件中使用的诸如static x = 10的语句,机器就必须要先定位static area,之后才能确定变量的地址。但是现在不知道他们的具体地址,所以在后边我们会看到,是采用了placeholder的方式生成汇编码与机器码,之后在linker这一步把机器码替换掉。
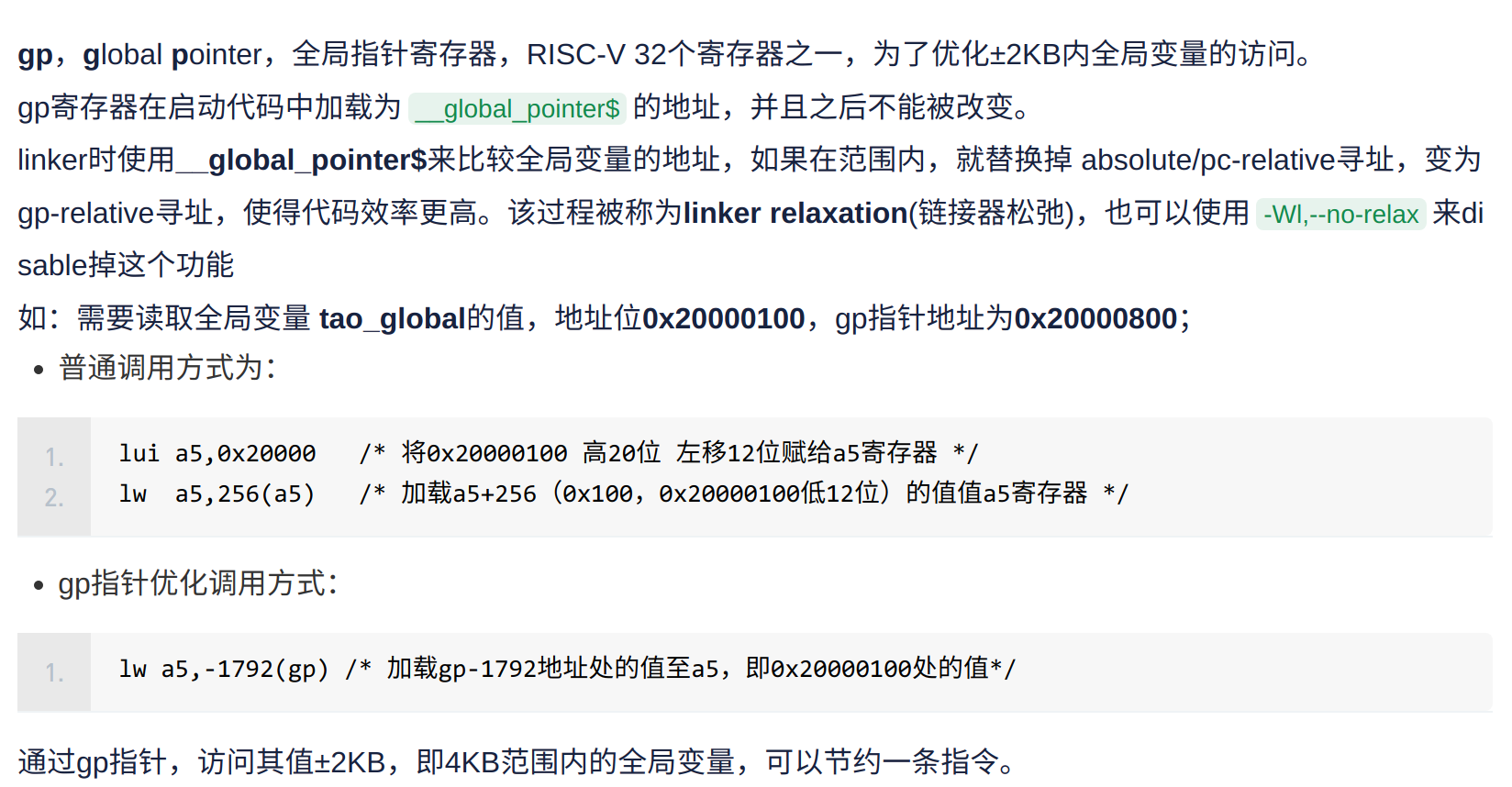
这里的
gp是全局指针寄存器,他可以用来优化$$\pm 2kB$$的全局变量的访问:
而对于条件跳转类指令,由于它们采用的计算方法全部为PC-Relative,所以不需要额外处理地址问题。
How to resolve references?


Static vs. Dynamic Linked Libraries
关于静态链接库与动态链接库的问题,我们在下边的C++部分也有提到,静态链接库将库作为可执行文件的一部分,而动态链接库则是通过在可执行文件中包含一条指向它的链接(linking at the machine code level,这是一种流行的做法,但并不唯一)实现的,我们会在程序运行时加载这些库,这也是loader需要完成的事情。动态链接的方法方便我们对库进行更新,而又不需要重新把原本的可执行文件的部分重新编译。但是动态链接库也有一些缺点,比如如果库文件损坏,我们的可执行文件即使没有发生任何改变也会导致程序无法正常运行,同时库文件的加载需要时间等等。

Loader
Loader其实就是操作系统(Loading is one of the OS tasks)!此时我们已经开始要运行文件了!它以一个可执行文件作为输入,输出是一个正在运行的程序,具体的步骤如下:

在一开始,需要把参数先拷贝到栈上,再拷贝到寄存器中,因为不知道参数的大小。
这里我产生了一点疑问,因为在之前linker的步骤已经把所有有关地址的问题处理好了,可是在装载(loader)的过程中需要将指令与数据从可执行文件中复制到新的地址空间里,这不会出现问题吗?这涉及到地址重定位问题,包括静态地址重定位与动态地址重定位方法,牵扯到逻辑地址空间与物理地址空间等,不做详述。但实质上,操作系统将disk中的文件复制到了memory中(DRAM),这一点在之后的cache介绍部分会提到。
关于变量的内存分配与初始化
通过上述章节我们了解到,在编译阶段(compile, assemble, linker),程序需要确定下来如何内存分配整个程序,并在接下来的加载阶段给程序分配内存(当然之后还会有一些内存分配的时机,比如malloc之类的)。
这意味着某些时刻我们必须明确的在编译阶段告知程序内存分配的方法,一个例子就是数组:我们必须在编译阶段确定下来数组的维度,否则编译器不知道如何给这块数组分配内存。
另一方面,变量初始化也是一个很重要的主题。初始化可能发生在不同的阶段:
- 编译阶段初始化-e.g. 全局变量为内置类型,且大小确定;或使用
constexpr等
int a = 10;
int main() {
}
- 加载阶段初始化-在
main()函数执行前,完成包括全局变量,静态变量的初始化。e.g. 在加载阶段会调用类的构造函数初始化类的静态成员等(显而易见,编译阶段无法调用类的构造函数) - 运行阶段初始化-指代实际程序运行期间对象(变量)的创建,包含那些动态创建的对象。
int main() {
int a = 10;
}
关于变量初始化,static关键字引发了多种不同的情况,这一点放在CS 106L的static关键字部分探讨。
An Example
#include <stdio.h>
int main() {
printf("Hello, %s\n", "world");
return 0;
}
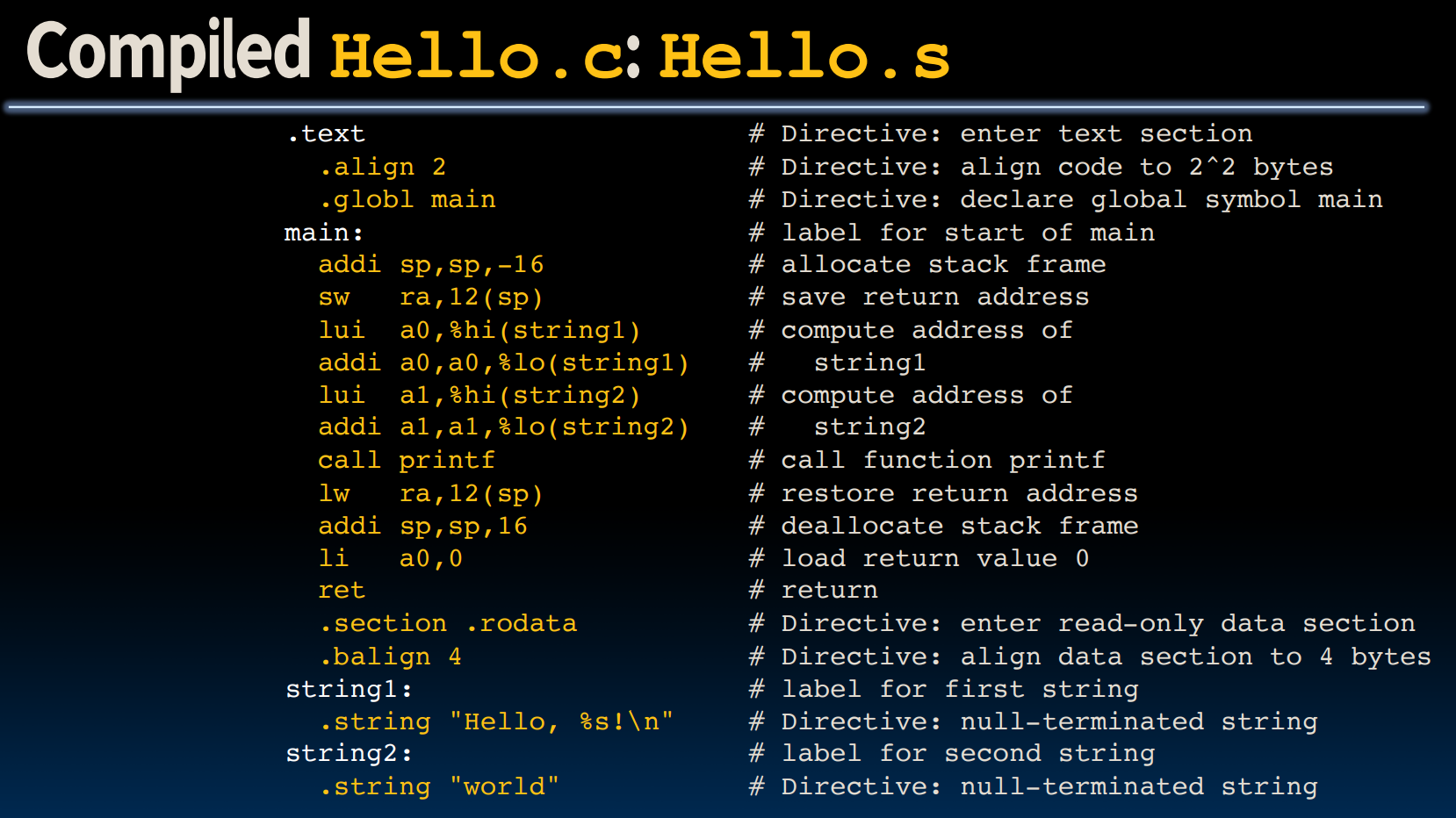
在
.align中,给入的是logX的结果,这与.balign不同。同时我们要注意给出变量低位地址(%lo)与高位地址(%hi)的方法。
现在,我们来看一下在linker发生之前,汇编代码是怎么样处理那些需要链接的值的:
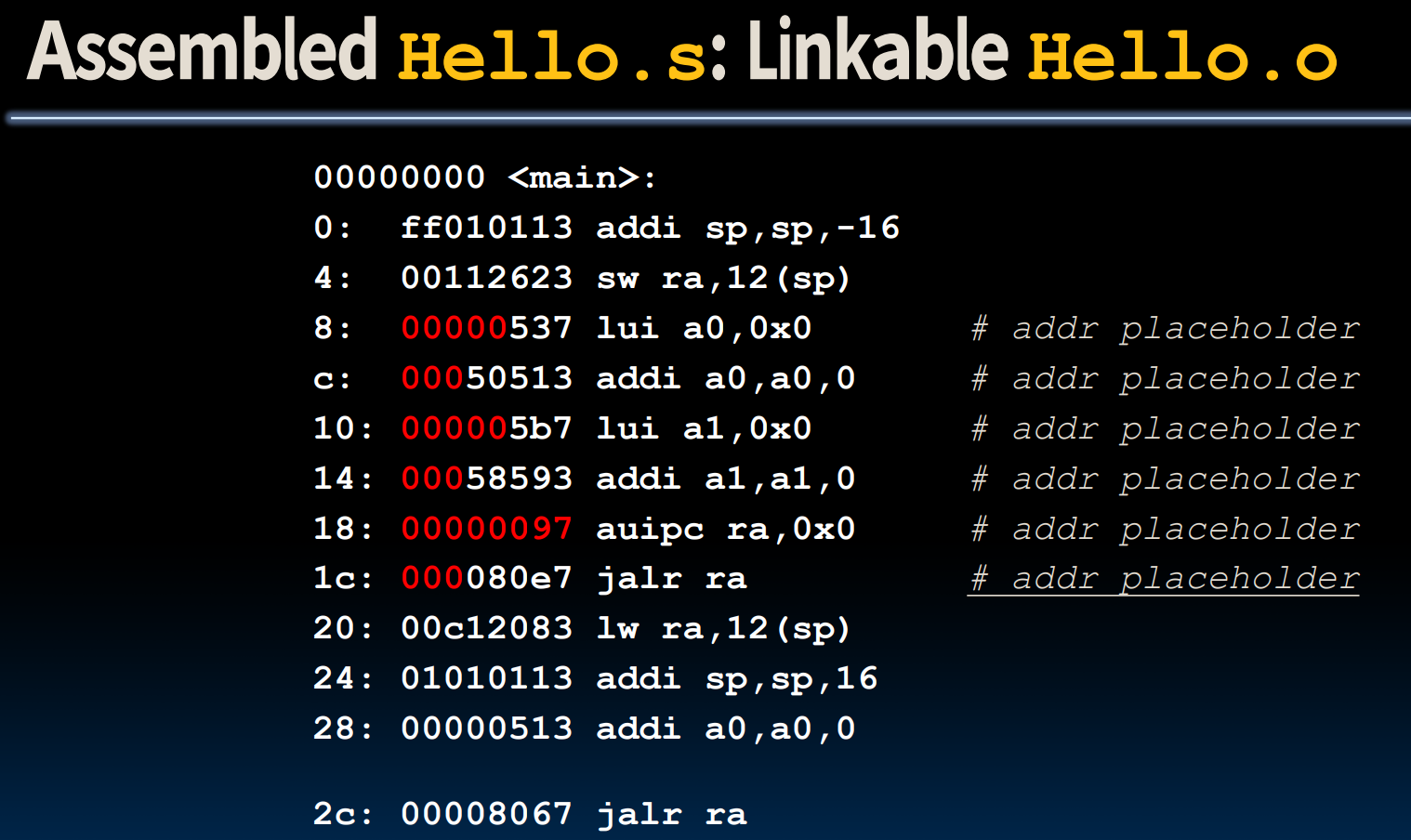
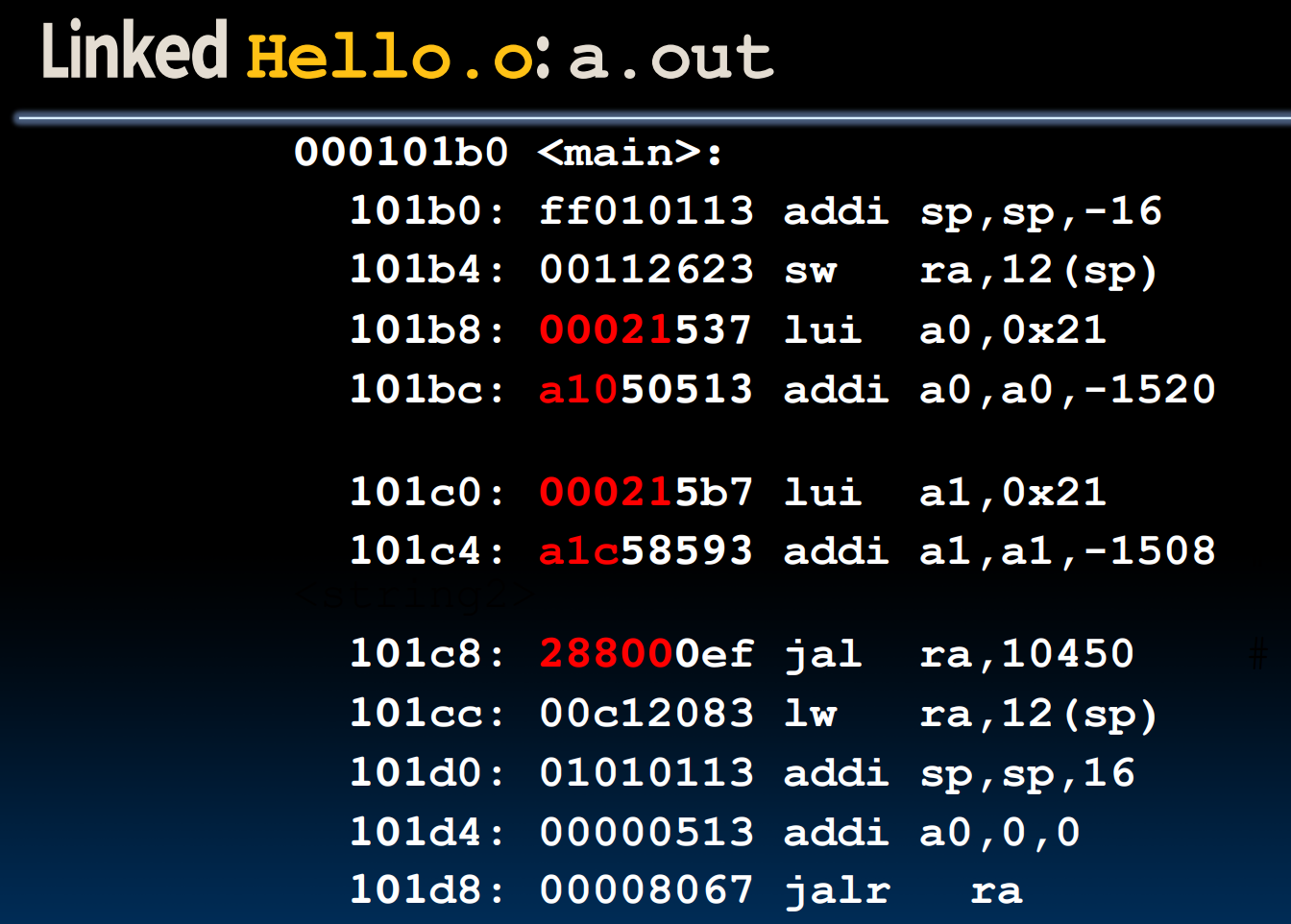
我们注意到,在经过linker的步骤后,所有原本由00000等placeholder占据的位置变成了实际的地址填充。
需要注意的是,指令LUI/ADDI会有立即数
sign-extend的问题:

至此,程序编译的全部流程便结束了.
Libraries
- library是什么?

在编译时,如果将函数的定义也放在头文件内,将会导致运行变慢,因为没有使用linker,每次调用都会直接使用定义在其中的函数。
link library

出现该错误的原因是我们在主函数文件program.cpp中包含的是tools.hpp,也就是说程序完全不知道到哪里去寻找函数SomeFunc()的实现,他只知道存在这个函数(该函数的实现被我们放在tools.cpp中,但是我们没有告诉编译器这一点)。
所以我们要做的是:先让编译器生成一个tools库;之后要把tools和program链接起来,这样当program.cpp中找到tools.h时,也就知道其中函数SomeFunc()的实现被放在哪里了。
对于这种较为简单的情形,我们可以做如下操作:
# 生成tools.o库文件(第三步:编译)
g++ --std=c++17 -Wall -O0 tools.cpp -c
# 生成main.o库文件(第三步:编译)
g++ --std=c++17 -Wall -O0 main.cpp -c
#链接两者!
g++ --std=c++17 -Wall -O0 main.o tools.o -o main
在做链接时,需要注意越是底层的库,被依赖的项,越往后边写。
当然,我们也可以在主程序直接包含tools.cpp,可以直接一步用-o搞定,不需要单独链接库了,但这不是一种好的方法。

也就是说,在linking时,会将函数声明定位到它的已经经过编译的实现上。而为了完成这一点,我们需要的library需要包括两个部分:
- 一个包含声明的头文件
- 经过编译的二进制代码库函数实现
How to build libraries
现在的情况是我们自己定义了库文件,并将库文件中的函数声明在头文件中:

-L参数用来指定程序要链接的库,-l参数紧接着就是库名
首先将库文件编译为一个object file,这一步对应着C++文件编译过程中的第三步,将文件转化为二进制代码;之后将其打包组合建立一个静态库(ar rcs),后边的.表示库所在位置,库里边是binary code,接下来把库链接到main文件里,即告知程序function/symbol的位置。
我们也可以用这种方法对上边的program&tools案例进行测试,结果是一样的,只不过我们先把两个.o文件打包成了静态链接库而已:
# 打包成静态链接库
ar rcs libtools.a main.o tools.o
# linking
g++ --std=c++17 main.cpp -L . -ltools -o main_1
Build systems
发展历程:

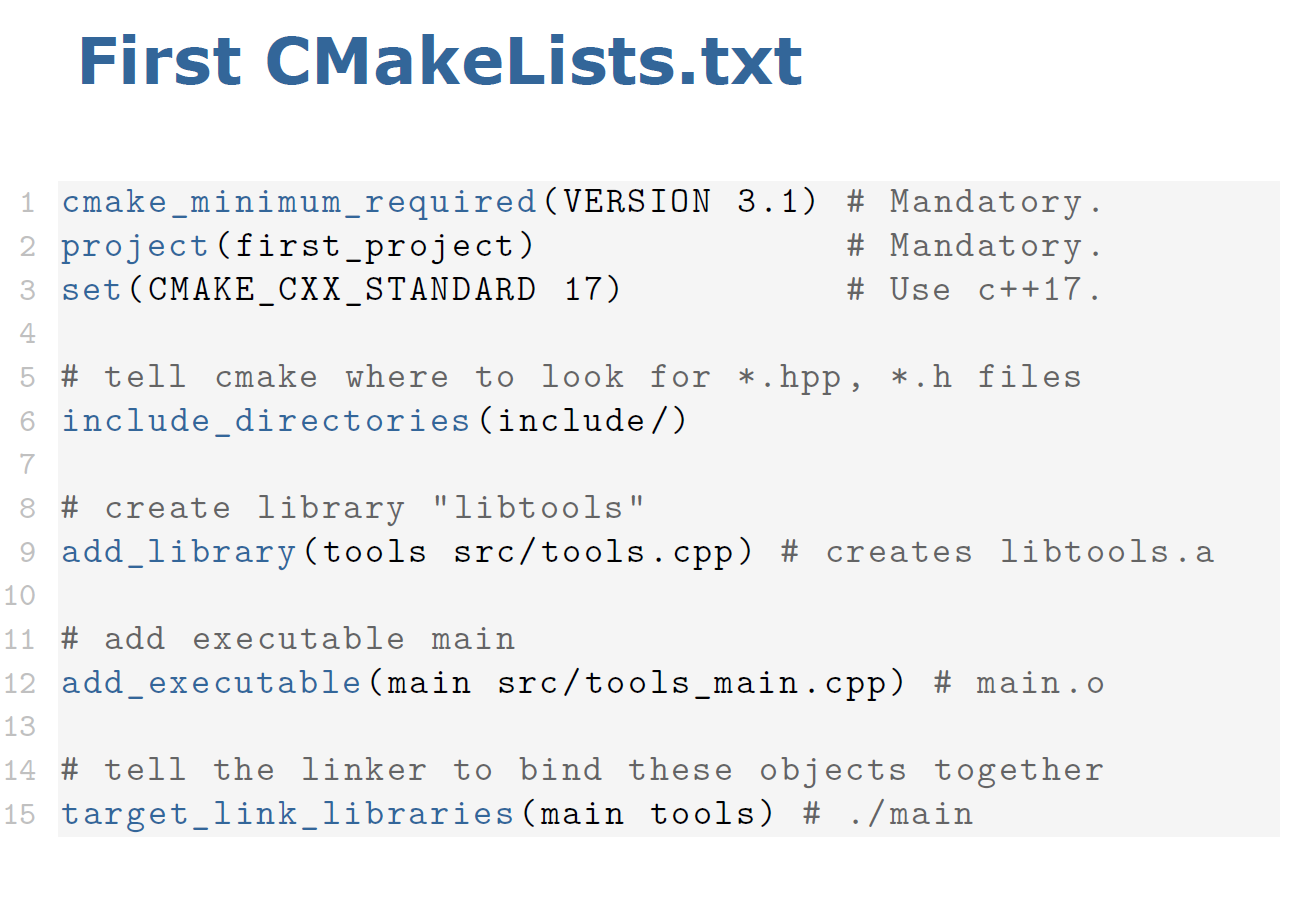
Cmake是一个MetaBuild System,通过我们写好的CMakeLists.txt生成makefile,系统会根据makefile当中的指令去编译和链接程序
cmake使用
cmake的教程可以参考这里.
cmake的官方文档写的有些过于晦涩,这个教程相对清晰明了,先掌握一些cmake的基本用法即可。
本节课作业中的内容对应着该GitHub教程的01-Basic和02-sub-project的部分内容。


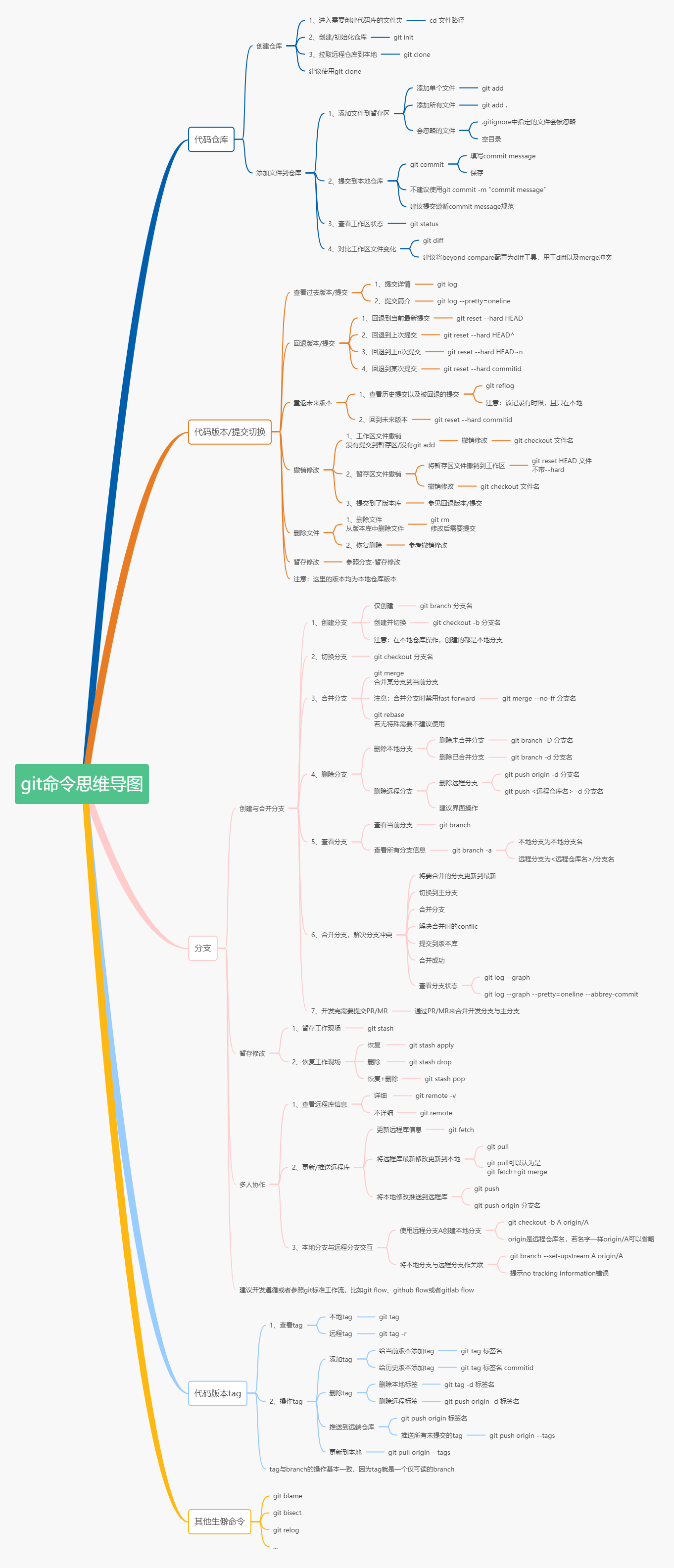
Git的使用
Git的命令介绍可以参考这里。
在一个机器上安装好Git之后我们需要使用如下命令初始化这台机器:
$ git config --global user.name "Your Name"
$ git config --global user.email "email@example.com"
本地仓库
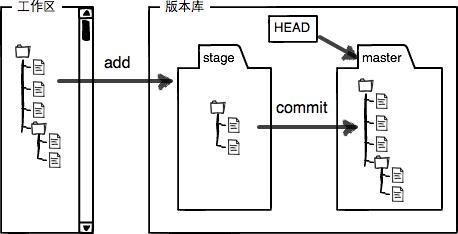
在学习Git过程中遇到的几个简易命令:
- 工作区、暂存区、版本库(
.git)
# 创建版本库(.git folder)
git init
checkout被替换
在创建或者切换分支时,使用switch命令代替:
# 切换分支
git switch newBranch
# 创建分支
git switch -c newBranch
在恢复文件内容时,使用restore命令代替,不论使用–worktree还是stage,我们指的都是需要恢复的区域:
# 撤销工作区(working tree)修改:如果暂存区有文件则恢复到暂存区的样子,如果没有,则恢复到上一次commit的样子,也即版本库master中的样子
git restore readme.txt
# 与上一个一样的效果,因为可省略worktree关键字
git restore --worktree readme.txt
# 撤销暂存区修改,从版本库master恢复暂存区(stage/index)
git restore --staged readme.txt
# 可以指定source关键字,从版本库master当前HEAD同时恢复工作区与暂存区内容
git restore --source=HEAD --staged --worktree readme.txt
reset用于版本回退+撤销修改
# 版本回退(已经提交到了本地的版本库master内)
# HEAD/HEAD^^/HEAD~100/commit-id(e.g. bavdc8743)
# 该命令把工作区(worktree)与暂存区(index/stage)的内容替换成指定的版本库master的内容,也即把他们回退到版本库的某个版本
git reset --hard HEAD^
# 使用reflog查看commit-id
git reflog
# unstage(撤销暂存区修改),该命令撤销git add的在暂存区的内容
git reset HEAD readme.txt
根据上述代码,我们不难发现--hard主要用来撤销工作区的内容,当我们使用--hard后,工作区+暂存区的修改都会回退掉。
diff的使用
# 比较working tree & index/stage
git diff readme.txt
# 比较暂存区与版本库
git diff --cached readme.txt
# 比较工作区与版本库
# HEAD如果指向master分支,也可以换成master
# HEAD也可以写作某个commit-id
git diff HEAD readme.txt
# 同理,我们可以比较暂存区与某个指定的commit-id
git diff --cached [<commit-id>] readme.txt
# 或者比较两个commit-id的差异
git diff [<commit-id>] [<commit-id>]
此外,git diff还可以用来打补丁(patch),这里就先不列出具体方法了。
- 其余一些基本命令
git initgit addgit commit -mgit rm(从版本库中删除文件)git tag <tagname>创建标签
远程仓库
push
- 注意一开始要在自己本地生成
SSH Key,这样Github才允许把远程仓库和本地仓库关联起来并进行后续操作 - 关联本地与远程命令:
git remote add origin git@github.com:michaelliao/learngit.git(本地有一个仓库,我们现在GitHub上创建了一个远程仓库,之后用此命令将其关联起来)
为什么是
origin?这是远程库的默认名字,而非仓库本身的名字,对于不同的远程服务器上的同样的仓库,名字应当不同(server-1,server-2,server-3…),一般来说就关联一个远程库,习惯命名为origin。
- 第一次推送:
git push -u origin master
git push <远程主机名> <本地分支名>:<远程分支名>在这里,远程主机名为
origin,遵循来源地:目的地,所以git push命令的顺序是本地分支:远程分支
- 如果远程分支被省略,则表示将本地分支推送到与之存在追踪关系的远程分支:
git push origin master
- 如果本地分支被省略,则表示推送一个空分支,等同于
git push origin --delete master,会将远程主机上的master分支删除:git push origin :master
- 如果当前只有一个追踪分支,则可以简略为
git push- 如果当前分支与多个主机存在追踪关系,则可以使用
-u选项指定一个默认主机,这样后面就可以不加任何参数使用git push
- 查看远程库信息:
git remote -v
- 解除本地与远程的绑定关系:
git remote rm origin
clone
当我们试图从远程库克隆到本地时,可以使用git clone命令,该命令的用法有以下几种:
用法1: git clone <repository> <directory>
用法2: git clone --bare <repository> <directory.git>
用法3: git clone --mirror <repository> <directory.git>

分支管理
参看廖雪峰老师的教程,这部分写的很清楚。
比如创建了一个分支并在此分支上提交了一次之后,分支结构就会变成下图所示的样子:
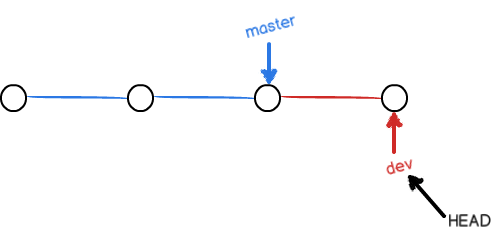
- 注意我们可能需要处理分支冲突,解决方法也很简单,我们只要让某个分支领先于另一个分支即可,这样一来便会直接使用
fast-forward模式进行合并 - 同时,我们不应该做回退分支合并,即不能让一个最新的提交往回合并(这其实也是没有意义的)我们只能把以前的分支合并到我们新的分支上:
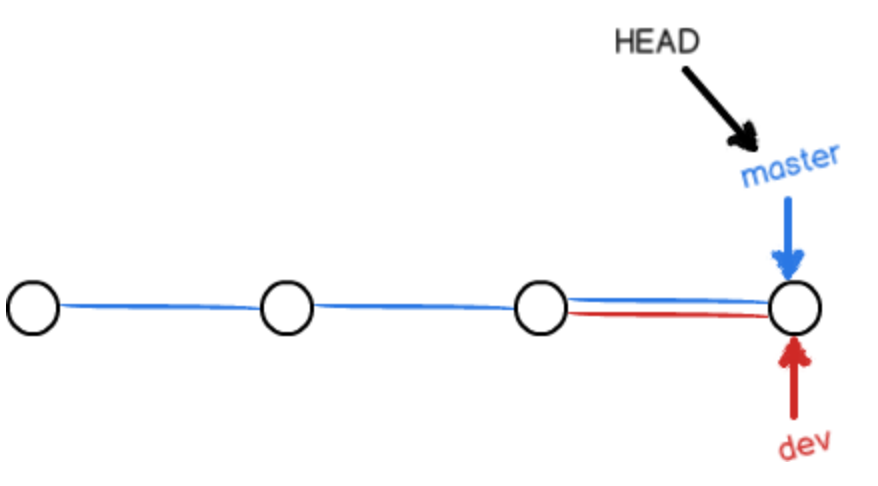
在这之后,我们可以将dev分支删除,于是便只剩下master主分支了。
需要注意的是,在切换分支时,要把当前分支的内容stash或者commit,如果直接切换分支,那么仓库并不知道文件发生了什么改动,所以在切换到新分支时,Git会把在旧分支工作区中做的改动复制到新分支上。
- 分支相关操作:
# 将dev分支合并到当前分支中
# fast-forward合并模式,将master指向dev分支的当前提交位置
git merge dev
# 查看分支结构
git branch
# 删除分支
git branch -d dev
# 强制删除分支(该分支可能还未被merge)
git branch -D dev
# 创建分支
git switch -c dev
# 进入分支, 此时会先查找本地是否存在此分支,如果不存在,则会查看远程仓库中是否有对应的分支,如果找到了,则会将远程仓库的对应分支拷贝到本地中 (MIT 6.S081)的多个分支结构就是这样设计和使用的
git switch dev
# 查看分支合并图
git log --graph --pretty=oneline --abbrev-commit
# 保留分支结构(普通模式),合并
git merge --no-ff -m "merge with no-ff" dev
什么时候无法使用fast-forward模式合并呢?当我们在两个分支上分别有提交的时候:
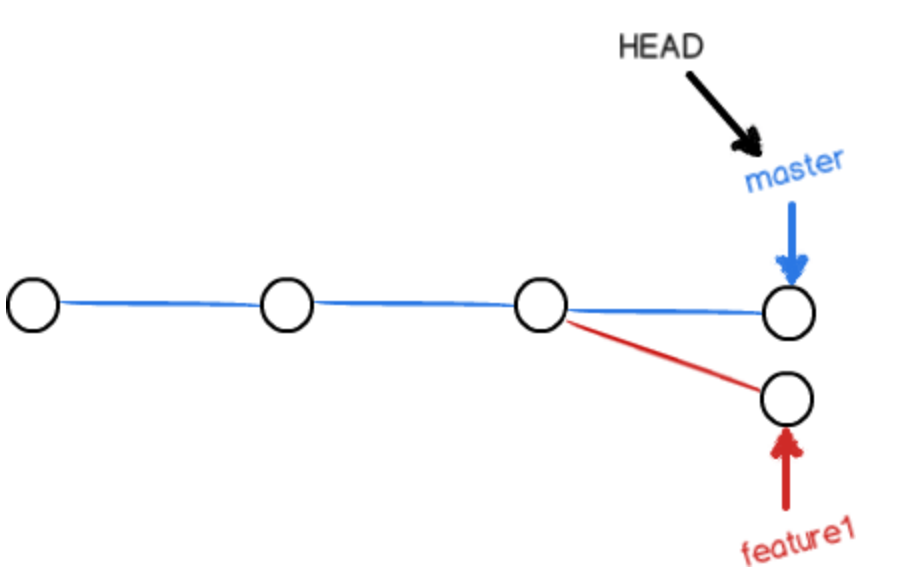
此时我们应当手动修改文件(文件中会显示提示内容)处理冲突,之后再进行分支合并。
通常,合并分支时,如果可能,Git会用
Fast forward模式,但这种模式下,删除分支后,会丢掉分支信息。如果要强制禁用
Fast forward模式,Git就会在merge时生成一个新的commit,这样,从分支历史上就可以看出分支信息。
$ git log --graph --pretty=oneline --abbrev-commit
* e1e9c68 (HEAD -> master) merge with no-ff
|\
| * f52c633 (dev) add merge
|/
* cf810e4 conflict fixed
...
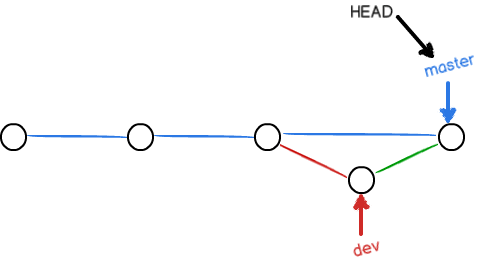
当我们使用普通模式进行合并时,代码结构如下:
- Bug分支
引入一个新命令:stash,作用如下:
Using the git stash command, developers can temporarily shelve changes made in the working directory. It allows them to quickly switch contexts when they are not quite ready to commit changes. And it allows them to more easily switch between branches.
# 在当前分支下,储存现场,使得git status为空,工作区是干净的
git stash
# 查看工作现场储存情况
git stash list
# 恢复工作现场,但不删除stash内容
git stash apply
# 删除stash内容
git stash drop
# 同时完成以上两项操作
git stash pop
需要注意的是,考虑到原本在master主分支中存在的bug也在dev分支中存在,所以我们需要同样修复dev中相同的问题,可以考虑在dev分支中复制修复bug的对应操作的commit-id,从而避免重复劳动。
git cherry-pick [<commit-id>]
在使用
cherry-pick之前,我们需要先将之前dev分支中使用stash暂存起来的、还没有commit的内容提交,否则会提示错误:error: Your local changes to the following files would be overwritten by merge
多人协作
- 创建本地对应的远程分支:
git switch -c dev origin/dev
因为当我们把远程仓库下载下来时,我们只能查看到master分支,要在dev分支上开发,就必须创建远程origin的dev分支到本地,用这个命令创建本地dev分支。
- 多人协作推送流程:

这里,git pull的作用相当于git fetch + git merge,先把远程库的内容下载到版本库中,之后在本地将分支合并。
一张大佬制作的Git命令图: